文章的合著者:Mike Cheng
Google Cloud Platform现在拥有专门针对深度学习相关人员设计的虚拟机映像。 今天,我们将讨论这些图像代表什么,它们为开发人员和研究人员带来的优势,以及当然如何基于它们创建虚拟机。
言外之意:在撰写本文时,该产品仍处于Beta版,没有适用的SLA。
Google进行深度学习的虚拟机映像是什么野兽?
来自Google的深度学习虚拟机映像是Debian 9映像,开箱即用即可提供深度学习所需的一切。 当前,存在具有TensorFlow,PyTorch和通用图像的图像版本。 每个版本在该版本中仅适用于CPU和GPU实例。 为了更好地了解您需要哪种图像,我画了一个小备忘单:
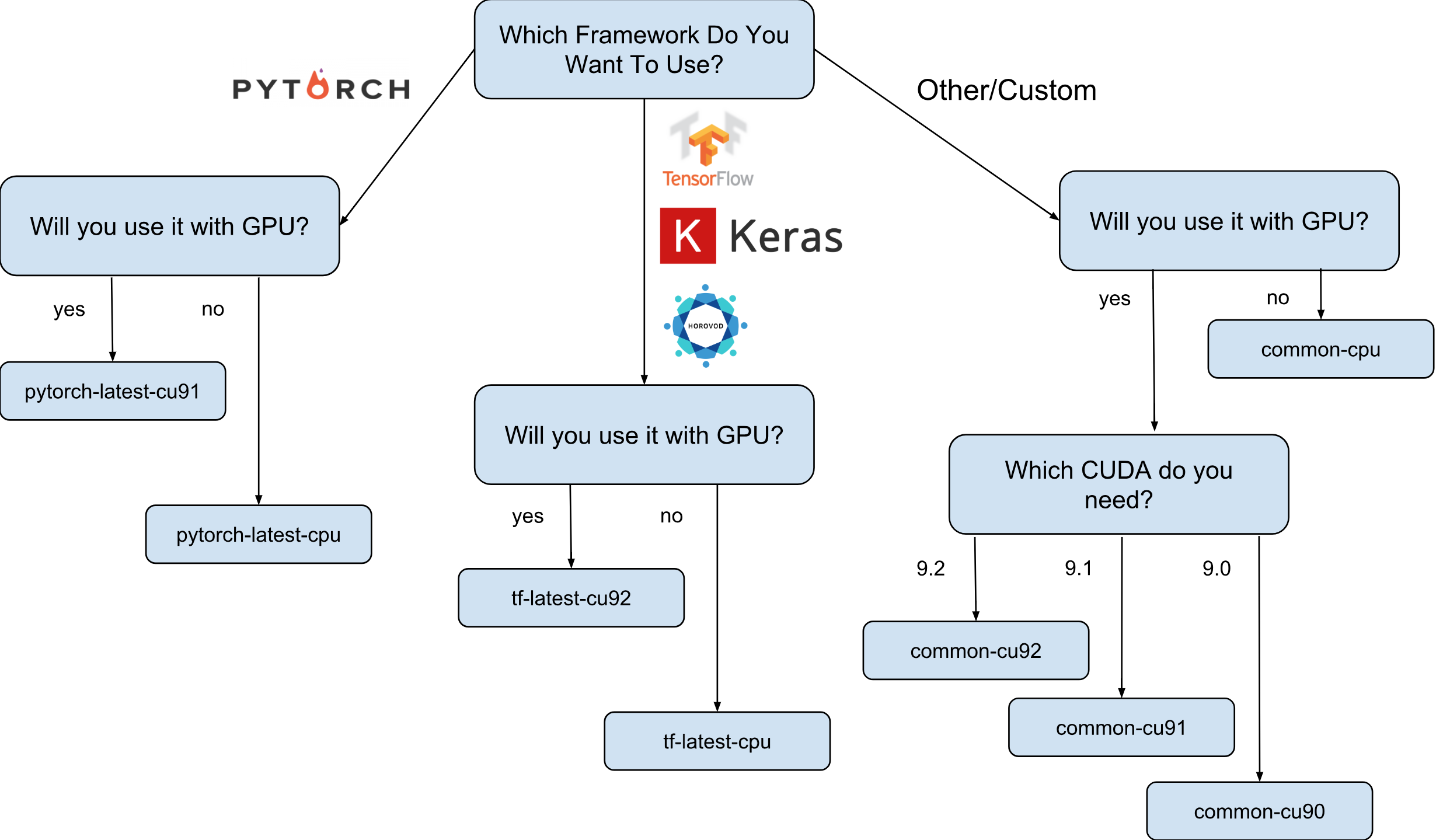
如备忘单所示,有8个不同的图像系列。 如前所述,它们都基于Debian 9。
图像上预装了什么?
所有映像均具有Python 2.7 / 3.5,并预装了以下软件包:
- 麻木
- 斯克莱恩
- 科学的
- 大熊猫
- lt
- 枕头
- Jupyter环境(实验室和笔记本)
- 还有更多。
从Nvidia配置的堆栈(仅在GPU映像中):
- CUDA 9. *
- CuDNN 7.1
- NCCL 2. *
- 最新的nvidia驱动程序
该列表会不断更新,因此请继续关注官方页面 。
为何真正需要这些图像?
假设您需要使用Keras(使用TensorFlow)训练神经网络模型。 学习速度对您很重要,因此您决定使用GPU。 要使用GPU,您需要安装和配置Nvidia堆栈(Nvidia驱动程序+ CUDA + CuDNN + NCCL)。 这个过程不仅本身非常复杂(特别是如果您不是系统工程师,而是研究人员),而且由于需要考虑到TensorFlow库版本的二进制依赖性而使该过程变得复杂。 例如,正式的TensorFlow 1.9发行版是使用CUDA 9.0编译的,如果您安装了CUDA 9.1或9.2的堆栈,则该发行版将不起作用。 设置此堆栈可能是一个“有趣”的过程,我认为没有人对此有争议(尤其是做到这一点的人)。
现在假设经过几个不眠之夜,一切都准备就绪并开始工作。 问题:您可以配置的此配置是否对您的硬件而言是最佳的? 例如,安装的CUDA 9.0和官方的TensorFlow 1.9二进制软件包是否确实在具有SkyLake处理器和一个Volta V100 GPU的实例上显示最快的速度?
如果不使用其他版本的CUDA进行测试,几乎不可能回答。 要确定答案,您需要以不同的配置手动重建TensorFlow并运行测试。 所有这些必须在昂贵的硬件上执行,随后计划在该硬件上训练模型。 好了,最后,一旦发布了新版本的TensorFlow或Nvidia堆栈,所有这些测量都可以被丢弃。 可以肯定地说,大多数研究人员根本不会这样做,而只会使用标准的TensorFlow组件,而没有最佳速度。
这是场景中出现Google深度学习图像的地方。 例如,具有TensorFlow的图像具有自己的TensorFlow程序集,该程序集已针对Google Cloud Engine上可用的硬件进行了优化。 它们使用Nvidia堆栈的另一种配置进行了测试,并基于显示最高性能的组件(破坏者:这并不总是最新的)。 好吧,最重要的是-您已经预先安装了研究所需的几乎所有东西!
如何基于其中一张图像创建实例?
有两个选项可用于根据这些图像创建新实例:
- 使用Google Cloud Marketplace网络用户界面
- 使用gcloud
由于我是终端和CLI实用程序的忠实拥护者,因此在本文中,我将讨论该选项。 此外,如果您喜欢UI,则有很多不错的文档,描述了如何使用Web UI创建实例 。
在继续之前,请安装(如果尚未安装)gcloud 工具 。 (可选)您可以使用Google Cloud Shell ,但请记住 ,当前不支持Google Cloud Shell中的WebPreview功能,因此您不能在此处使用Jupyter Lab或Notebook。
下一步是选择图像系列。 我将再次允许自己携带备忘单,并选择一系列图像。
例如,我们假设您的选择落在tf-latest-cu92上,我们将在下文中使用它。
等等,但是如果我需要特定版本的TensorFlow而不是“最新版本”怎么办?
假设我们有一个需要TensorFlow 1.8的项目,但同时已经发布了1.9,而tf-latest系列中的图像已经有1.9。 对于这种情况,我们有一系列图像,这些图像始终具有特定版本的框架(在我们的示例中为tf-1-8-cpu和tf-1-8-cu92)。 这些图像系列将被更新,但TensorFlow的版本不会在其中更改。
由于这只是一个Beta版本,因此我们现在仅支持TensorFlow 1.8 / 1.9和PyTorch 0.4。 我们计划支持将来的版本,但是在当前阶段,我们不能明确回答将支持旧版本多长时间的问题。
如果要创建群集或使用相同的图像怎么办?
确实,在许多情况下,有必要一遍又一遍地重复使用同一图像(而不是一系列图像)。 严格来说,直接使用图像几乎总是首选。 好吧,例如,如果您运行具有多个实例的群集,则不建议在这种情况下直接在脚本中指定映像系列,因为如果在脚本运行时更新了映像系列,则很可能会从不同的映像创建不同的群集实例。 (并且可能具有不同版本的库!)。 在这种情况下,最好首先为其家庭图像获取一个特定的名称,然后才使用特定的名称。
如果您对此主题感兴趣,可以查看我的文章“如何正确使用图像系列”。
您可以使用简单的命令查看系列中最后一个图像的名称:
gcloud compute images describe-from-family tf-latest-cu92 \ --project deeplearning-platform-release
假设特定图像的名称是tf-latest-cu92-1529452792,您已经可以在任何地方使用它:
是时候创建我们的第一实例了!
要从一系列图像创建实例,只需运行一个简单的命令:
export IMAGE_FAMILY="tf-latest-cu92"
如果使用图像名称而不是图像系列,则需要将“--image-family = $ IMAGE_FAMILY”替换为“-image = $ IMAGE-NAME”。
如果将实例与GPU配合使用,则需要注意以下情况:
您需要选择正确的区域 。 如果使用特定的GPU创建实例,则需要确保在创建实例的区域中可以使用这种类型的GPU。 在这里,您可以找到区域与GPU类型的对应关系。 如您所见,us-west1-b是唯一存在所有3种可能类型的GPU(K80 / P100 / V100)的区域。
确保您有足够的配额来使用GPU创建实例 。 即使您选择了正确的区域,这也不意味着您具有在该区域中使用GPU创建实例的配额。 默认情况下,所有区域的GPU配额均设置为零,因此使用GPU创建实例的所有尝试均将失败。 在这里可以找到有关如何增加配额的很好的解释。
确保区域中有足够的GPU可以满足您的要求 。 即使您选择了正确的区域,并且在该区域中拥有GPU的配额,这也不意味着您在该区域中有您感兴趣的GPU。 不幸的是,除了尝试创建实例并查看会发生什么,我不知道您还能如何检查GPU的可用性。
选择正确数量的GPU(取决于GPU的类型) 。 事实是我们团队中的“加速器”标志负责实例可使用的GPU的类型和数量: “-Accelerator ='type = nvidia-tesla-v100,count = 8'”将创建一个具有八个可用Nvidia Tesla V100(Volta)GPU的实例。 每种类型的GPU都有一个有效的计数值列表。 以下是每种类型的GPU的列表:
- nvidia-tesla-k80,可以包含:1,2,4,8
- nvidia-tesla-p100,可以包含:1,2,4
- nvidia-tesla-v100,可以包含:1,8
启动实例时,请授予Google Cloud权限代表您安装Nvidia驱动程序 。 Nvidia的驱动程序是必须的。 由于超出了本文范围的原因,这些映像没有预安装的Nvidia驱动程序。 但是,您可以授予Google Cloud首次启动实例时代表您安装它的权利。 这是通过添加“-元数据='install-nvidia-driver = True”标志来完成的。 如果未指定此标志,则首次通过SSH连接时,系统将提示您安装驱动程序。
不幸的是,驱动程序安装过程在第一次启动时会花费一些时间,因为它需要下载并安装该驱动程序(这也需要重新启动实例)。 总共不超过5分钟。 稍后我们将讨论如何减少首次启动时间。
通过SSH连接到实例
这比萝卜简单,可以使用一个命令来完成:
gcloud compute ssh $INSTANCE_NAME
gcloud将创建一个密钥对,并将其自动上传到新创建的实例,并在其上创建用户。 如果要使此过程更加简单,可以使用一个函数来简化此过程:
function gssh() { gcloud compute ssh $@ } gssh $INSTANCE_NAME
顺便说一下,您可以在这里找到我所有的gcloud bash函数。 好了,在我们开始讨论这些映像的速度或如何处理这些映像之前,让我先说明一下启动实例的速度问题。
如何减少首次启动的时间?
从技术上讲,首次启动的时间不算什么。 但是您可以:
- 用一个K80创建最便宜的n1-standard-1实例;
- 等到第一次下载完成;
- 验证是否已安装Nvidia驱动程序(可以通过运行“ nvidia-smi”来完成);
- 停止实例
- 从停止的实例创建自己的映像
- 获利-从您的派生图像创建的所有实例的传奇启动时间均为15秒。
因此,从该列表中,我们已经知道如何创建新实例并连接到该实例,并且还知道如何检查驱动程序的可操作性。 剩下的只是谈论如何停止实例并从中创建映像。
要停止实例,请运行以下命令:
function ginstance_stop() { gcloud compute instances stop - quiet $@ } ginstance_stop $INSTANCE_NAME
这是创建映像的命令:
export IMAGE_NAME="my-awesome-image" export IMAGE_FAMILY="family1" gcloud compute images create $IMAGE_NAME \ --source-disk $INSTANCE_NAME \ --source-disk-zone $ZONE \ --family $IMAGE_FAMILY
恭喜,现在您已经拥有安装了Nvidia驱动程序的映像。
Jupyter Lab怎么样?
一旦您的实例运行,下一步的逻辑就是启动Jupyter Lab以直接开展业务:)使用新映像,这非常简单。 自实例启动以来,Jupyter Lab已在运行。 您需要做的就是连接到实例,并转发Jupyter Lab正在侦听的端口。 这是端口8080。这是通过以下命令完成的:
gssh $INSTANCE_NAME -- -L 8080:localhost:8080
一切就绪,现在您只需打开自己喜欢的浏览器,然后转到http:// localhost:8080
TensorFlow来自图像的速度有多快?
一个非常重要的问题,因为训练模型的速度是真钱。 但是,此问题的完整答案将是本文中已写的最长的答案。 因此,您必须等待下一篇文章:)
同时,我将通过我的个人小实验为您提供一些帮助。 因此,在ImageNet上的训练速度为每秒6100张图像(ResNet-50网络)。 我的个人预算不允许我完全完成对模型的训练,但是,以这种速度,我认为可以在5小时内达到一点点的75%的准确性。
在哪里获得帮助?
如果您需要有关新图像的任何信息,则可以:
- 使用标签google-dl-platform询问关于stackoverflow的问题;
- 向公众Google组写信;
- 可以在邮件或Twitter上给我写信。
您的反馈意见非常重要,如果您对图片有什么意见,请随时以方便您的方式与我联系,或者在本文下发表评论。