
在过去的几年中,人工智能和机器学习的主题已不再是虚构领域的人们所关注的话题,并已牢固地融入日常生活。 社交网络提供了我们感兴趣的事件,在没有驾驶员的情况下学会了在路上行驶的汽车以及电话上的语音助手告诉您什么时候最好出门以避免交通堵塞以及是否带雨伞。
在本文中,我们将考虑Apple开发人员提供的机器学习工具,分析该公司在WWDC18上在该领域展示的新功能,并尝试了解如何将所有这些方法付诸实践。
机器学习
因此,机器学习是一个过程,在此过程中,系统使用某些数据分析算法并处理大量示例,以识别模式并将其用于预测新数据的特征。
机器学习源于计算机可以自行学习的理论,而尚未进行编程以执行某些动作。 换句话说,与具有用于解决特定问题的预定义指令的常规程序不同,机器学习允许系统学习如何独立识别模式并进行预测。
BNNS和CNN
苹果已经在其设备上使用机器学习技术已有一段时间了:邮件可识别垃圾邮件,Siri可帮助您快速找到问题的答案,照片可识别图像中的面孔。
在WWDC16上,该公司推出了两个基于神经网络的API-基本神经网络子例程(BNNS)和卷积神经网络(CNN)。 BNNS是Accelerate系统的一部分,该系统是在CPU上执行快速计算的基础,而CNN是使用GPU的Metal Performance Shaders库。 例如,您可以在此处了解有关这些技术的更多信息。
核心ML和Turi创建
去年,苹果公司宣布了一个框架,该框架极大地促进了机器学习技术Core ML的使用。 它基于采取预先训练的数据模型并将其仅用几行代码集成到您的应用程序中的想法。
使用Core ML,您可以实现许多功能:
- 定义照片和视频中的对象;
- 预测文字输入;
- 面部跟踪和识别;
- 运动分析;
- 条码定义;
- 对文本的理解和认可;
- 实时图像识别
- 图像样式化;
- 还有更多。
反过来,Core ML使用低级的Metal,Accelerate和BNNS,因此计算结果非常快。
内核支持神经网络,广义线性模型,特征工程,基于树的决策算法(树集成),支持向量机方法,管线模型。
但是苹果公司最初并没有展示自己的用于创建和训练模型的技术,而只是为其他流行的框架提供了转换器:Caffe,Keras,scikit-learn,XGBoost,LIBSVM。
使用第三方工具通常不是最容易的任务,受过训练的模型非常庞大,并且训练本身花费了大量时间。
在年底,该公司引入了Turi Create-一种训练模型的框架,其主要思想是易于使用并支持大量场景-图像分类,对象定义,推荐系统等。 但是,尽管Turi Create相对易于使用,但仅支持Python。
创建ML
今年,除了Core ML 2,Apple最终展示了自己的模型训练工具-使用Apple的本机技术-Xcode和Swift创建Create ML框架。
它运行迅速,使用Create ML创建模型模型真的很容易。
在WWDC上,以Memrise应用程序为例宣布了Create ML和Core ML 2令人印象深刻的性能。 如果之前使用24个图像训练一个模型花了24个小时,那么Create ML在MacBook Pro上将这个时间减少到48分钟,在iMac Pro上减少到18分钟。 训练模型的大小从90MB减少到3MB。
Create ML允许您将图像,文本和结构化对象用作表,例如用作源数据。
图片分类
首先,让我们看一下图像分类的工作原理。 为了训练模型,我们需要一个初始数据集:我们拍摄三组动物照片:狗,猫和鸟,并将它们分配到具有相应名称的文件夹中,这将成为模型类别的名称。 每组包含100张图像,分辨率最高为1920×1080像素,最大尺寸为1Mb。 照片应尽可能不同,以使训练后的模型不依赖于图像中的颜色或周围空间等符号。
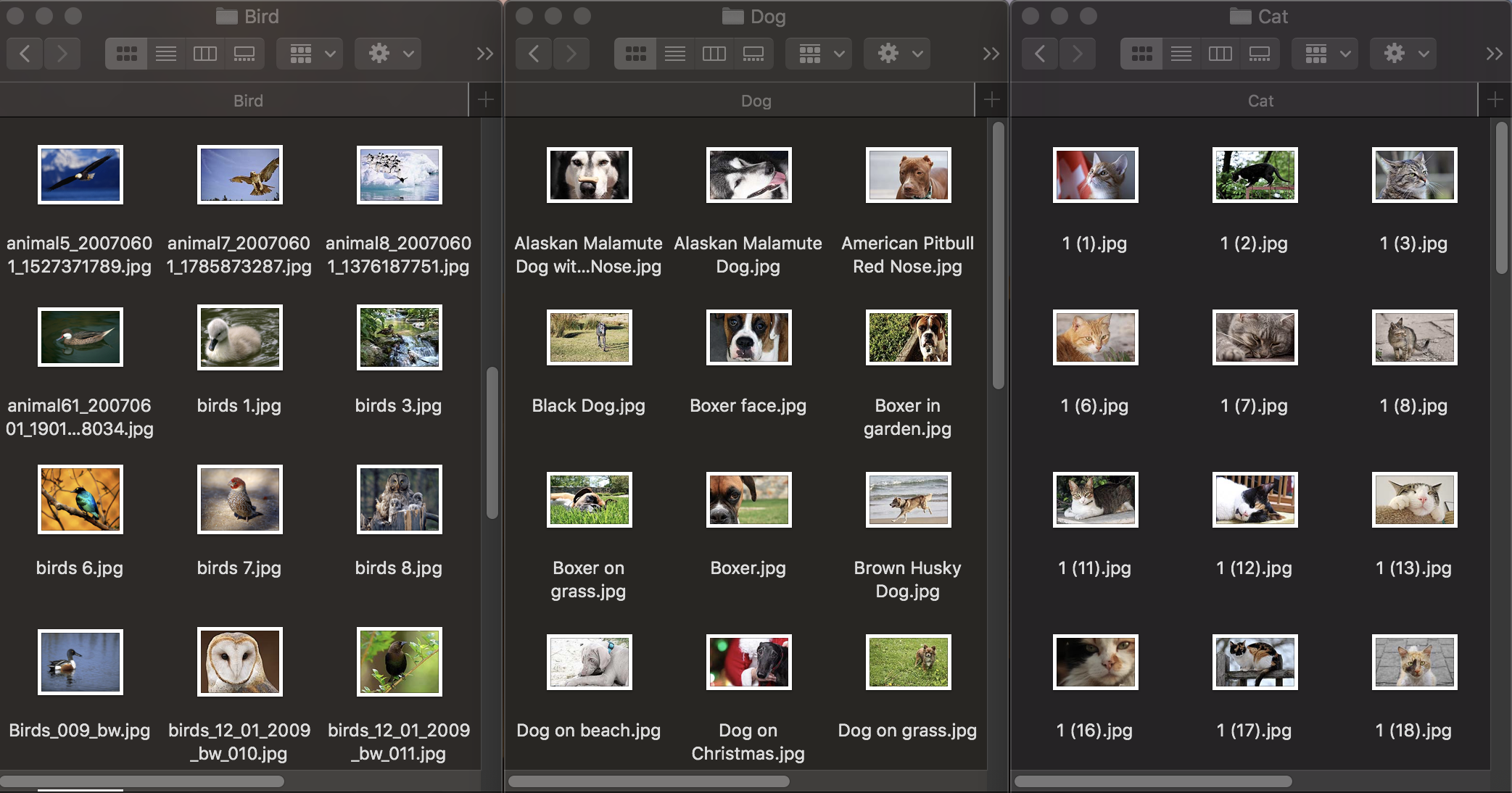
另外,要检查训练好的模型对对象识别的处理程度,您需要一个测试数据集-原始数据集中没有的图像。
Apple提供了两种与Create ML交互的方法:使用MacOS Playground Xcode上的UI,以及以编程方式使用CreateMLUI.framework和CreateML.framework。 使用第一种方法,编写几行代码,将所选图像传输到指定区域并等待模型学习就足够了。

在最高配置的Macbook Pro 2017上,训练花费29秒进行10次迭代,训练模型的大小为33Kb。 看起来不错。
让我们尝试弄清楚我们如何实现这些指标以及什么是“内幕”。
图像分类是卷积神经网络最流行的用途之一。 首先,值得解释一下它们是什么。
一个人看到了动物的图像后,便可以根据任何明显的特征将其迅速归为某一类。 神经网络通过搜索基本特征以类似的方式起作用。 以像素的初始数组为输入,它顺序地将信息传递给卷积层组,并建立越来越复杂的抽象。 在随后的每一层中,她都学习突出显示某些特征-首先是线,然后是线集,几何形状,身体部位等。 在最后一层,我们得出一个类或一组可能类的结论。
在创建ML的情况下,不会从头开始执行神经网络训练。 该框架使用以前在庞大的数据集上训练过的神经网络,该数据集已经包括大量的层并且具有很高的准确性。
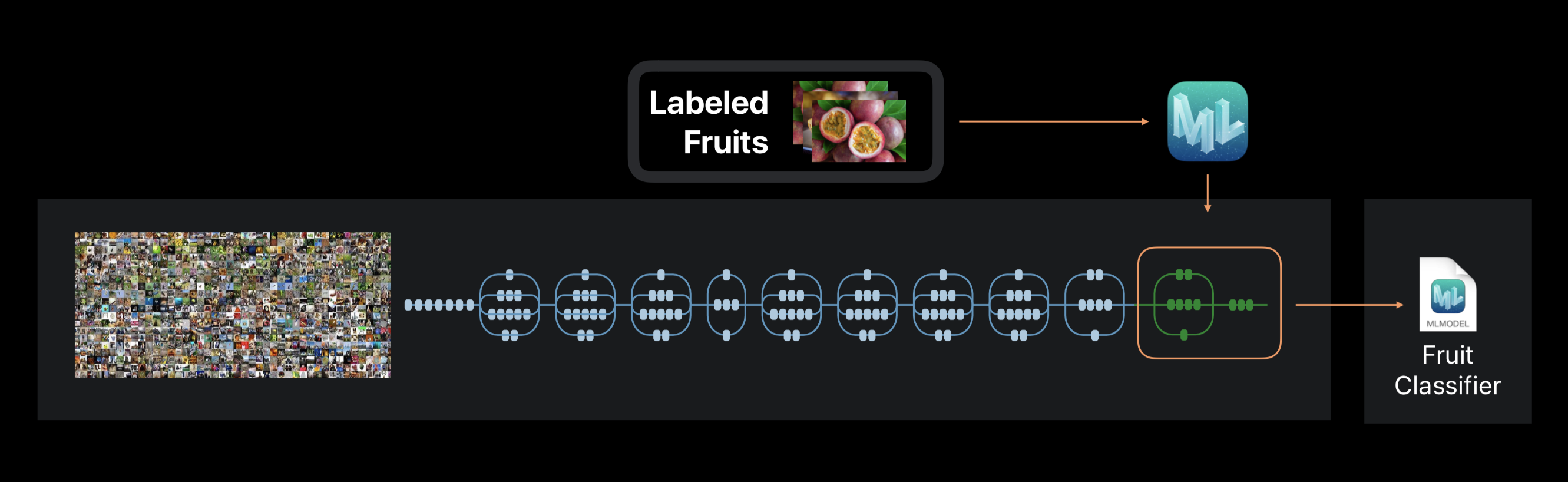
这项技术称为转移学习。 有了它,您可以更改经过预先训练的网络的体系结构,使其适合解决新问题。 然后在新的数据集上训练更改后的网络。
在训练过程中创建ML,从照片中提取约1000个独特功能。 这可以是对象的形状,纹理的颜色,眼睛的位置,大小以及许多其他内容。
应该注意的是,像我们一样,使用过的神经网络进行训练的初始数据集可能包含猫,狗和鸟的照片,但这些类别并未明确分配。 所有类别形成一个层次结构。 因此,完全不可能以纯形式应用此网络-有必要在我们的数据上对其进行重新训练。
在该过程的最后,我们看到经过几次迭代后,模型的训练和测试的准确性如何。 为了改善结果,我们可以增加原始数据集中的图像数量或更改迭代数量。
接下来,我们可以在测试数据集上自己测试模型。 其中的图片必须是唯一的,即 不要输入源集。
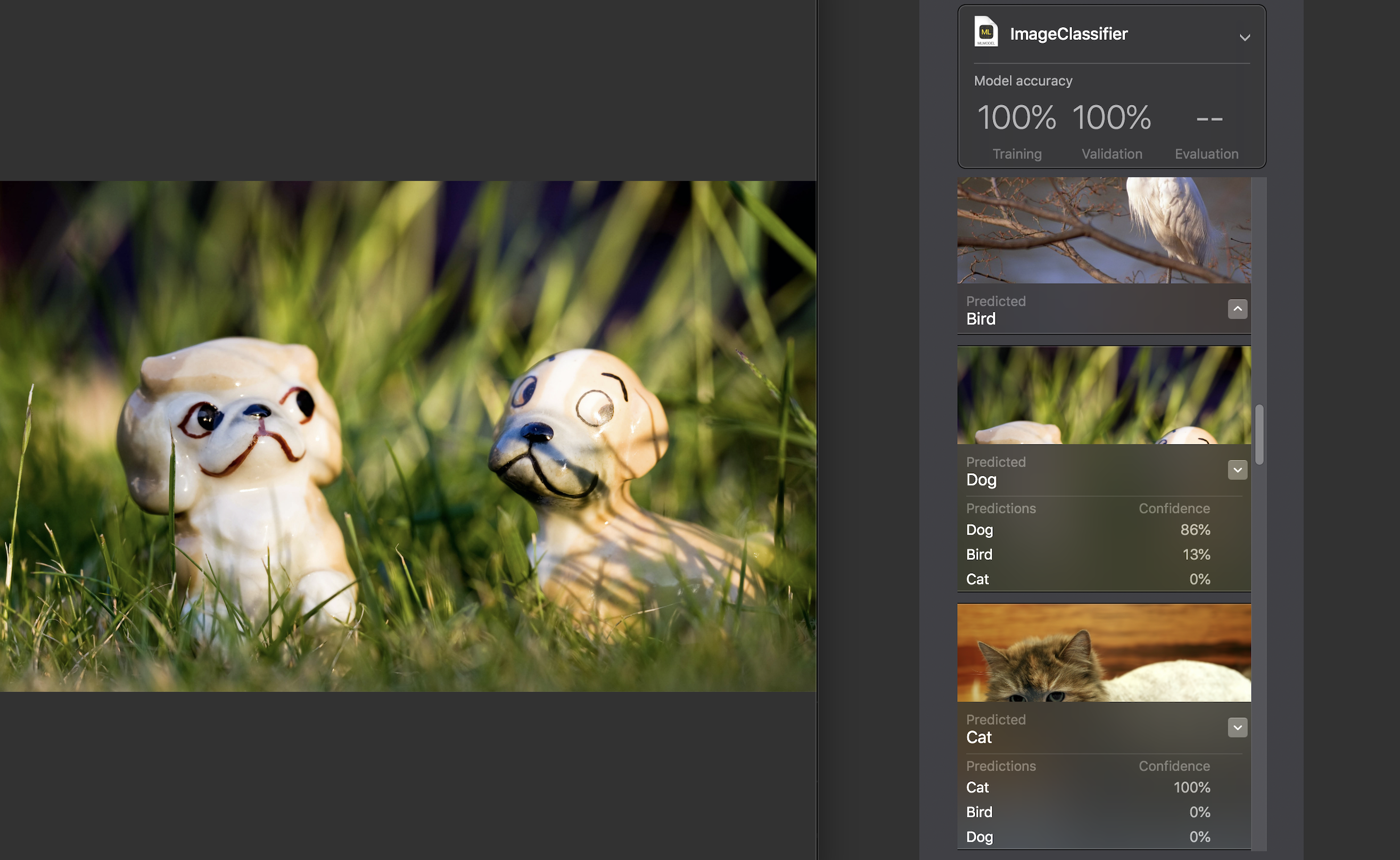
对于每个图像,都会显示一个置信度指示器-在我们的模型的帮助下,该类别的识别准确度。
对于几乎所有照片,除了极少数例外,这个数字都是100%。 我专门将您在上方看到的图像添加到了测试数据集中,并且可以看到,Create ML在其中识别了86%的狗和13%的鸟。
模型训练已经完成,剩下的就是保存* .mlmodel文件并将其添加到您的项目中。
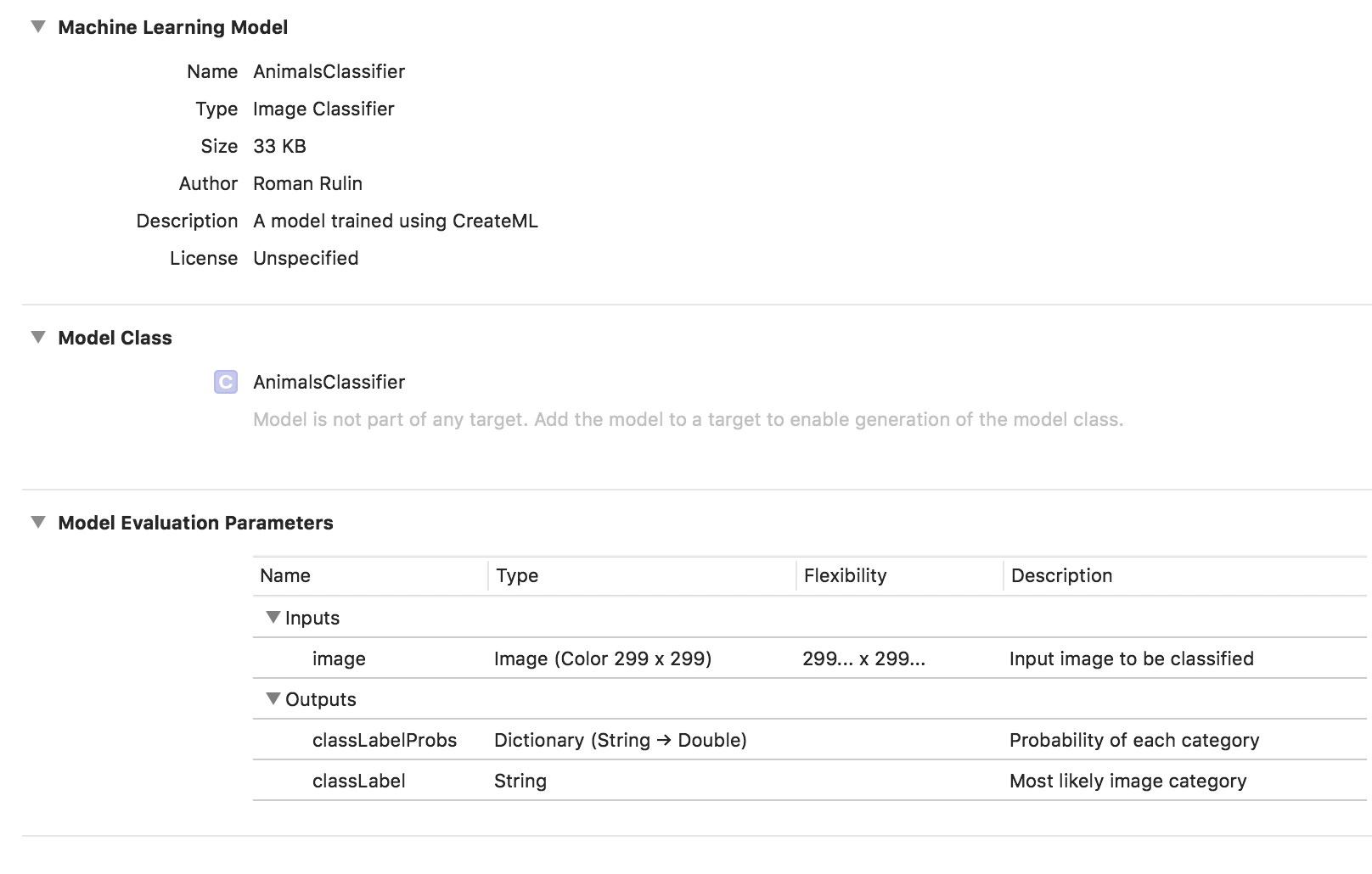
为了测试模型,我使用Vision框架编写了一个简单的应用程序。 它使您可以使用Core ML模型并解决使用它们的问题,例如图像分类或对象检测。
我们的应用程序将识别设备摄像头中的图像,并显示分类的类别和可信度百分比。
我们初始化Core ML模型以使用Vision并配置查询:
func setupVision() { guard let visionModel = try? VNCoreMLModel(for: AnimalsClassifier().model) else { fatalError("Can't load VisionML model") } let request = VNCoreMLRequest(model: visionModel) { (request, error) in guard let results = request.results else { return } self.handleRequestResults(results) } requests = [request] }
添加将处理VNCoreMLRequest的结果的方法。 我们只显示置信度超过70%的那些:
func handleRequestResults(_ results: [Any]) { let categoryText: String? defer { DispatchQueue.main.async { self.categoryLabel.text = categoryText } } guard let foundObject = results .compactMap({ $0 as? VNClassificationObservation }) .first(where: { $0.confidence > 0.7 }) else { categoryText = nil return } let category = categoryTitle(identifier: foundObject.identifier) let confidence = "\(round(foundObject.confidence * 100 * 100) / 100)%" categoryText = "\(category) \(confidence)" }
最后一个-我们将添加委托方法AVCaptureVideoDataOutputSampleBufferDelegate,该方法将在摄像机的每个新帧中调用并执行请求:
func captureOutput( _ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) { guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else { return } var requestOptions: [VNImageOption: Any] = [:] if let cameraIntrinsicData = CMGetAttachment( sampleBuffer, key: kCMSampleBufferAttachmentKey_CameraIntrinsicMatrix, attachmentModeOut: nil) { requestOptions = [.cameraIntrinsics:cameraIntrinsicData] } let imageRequestHandler = VNImageRequestHandler( cvPixelBuffer: pixelBuffer, options: requestOptions) do { try imageRequestHandler.perform(requests) } catch { print(error) } }
让我们检查一下模型如何完成其任务:

确定类别的准确性很高,当您考虑训练进行的速度以及原始数据集的大小时,这尤其令人惊讶。 该模型会定期在黑暗的背景下显示鸟类,但我认为可以通过增加原始数据集中的图像数量或提高最低可接受置信度来轻松解决。
如果我们要重新训练模型以对其他类别进行分类,只需添加一组新图像并重复该过程-这将需要几分钟。
作为实验,我制作了另一个数据集,其中从同一角度和相同环境,从不同角度更改了一只猫的照片中的所有猫照片。 在这种情况下,模型几乎总是在空房间中犯错误并识别类别,显然是依靠颜色作为关键特征。
仅在今年Vision中引入的另一个有趣的功能是能够实时识别图像中的对象。 它由VNRecognizedObjectObservation类表示,该类允许您获取对象的类别及其位置-boundingBox。

现在,Create ML不允许创建用于实现此功能的模型。 苹果建议在这种情况下使用Turi Create。 这个过程并不比上面复杂得多:您需要准备带有照片的类别文件夹和一个文件,其中将为每个图像指示对象所在矩形的坐标。
自然语言处理
下一个Create ML功能是训练模型以自然语言对文本进行分类-例如,确定句子的情感色彩或检测垃圾邮件。
要创建模型,我们必须收集一个具有原始数据集的表-分配给特定类别的句子或全文,并使用MLTextClassifier对象使用该模型训练模型:
let data = try MLDataTable(contentsOf: URL(fileURLWithPath: "/Users/CreateMLTest/texts.json")) let (trainingData, testingData) = data.randomSplit(by: 0.8, seed: 5) let textClassifier = try MLTextClassifier(trainingData: trainingData, textColumn: "text", labelColumn: "label") try textClassifier.write(to: URL(fileURLWithPath: "/Users/CreateMLTest/TextClassifier.mlmodel"))
在这种情况下,训练后的模型的类型为文本分类器:
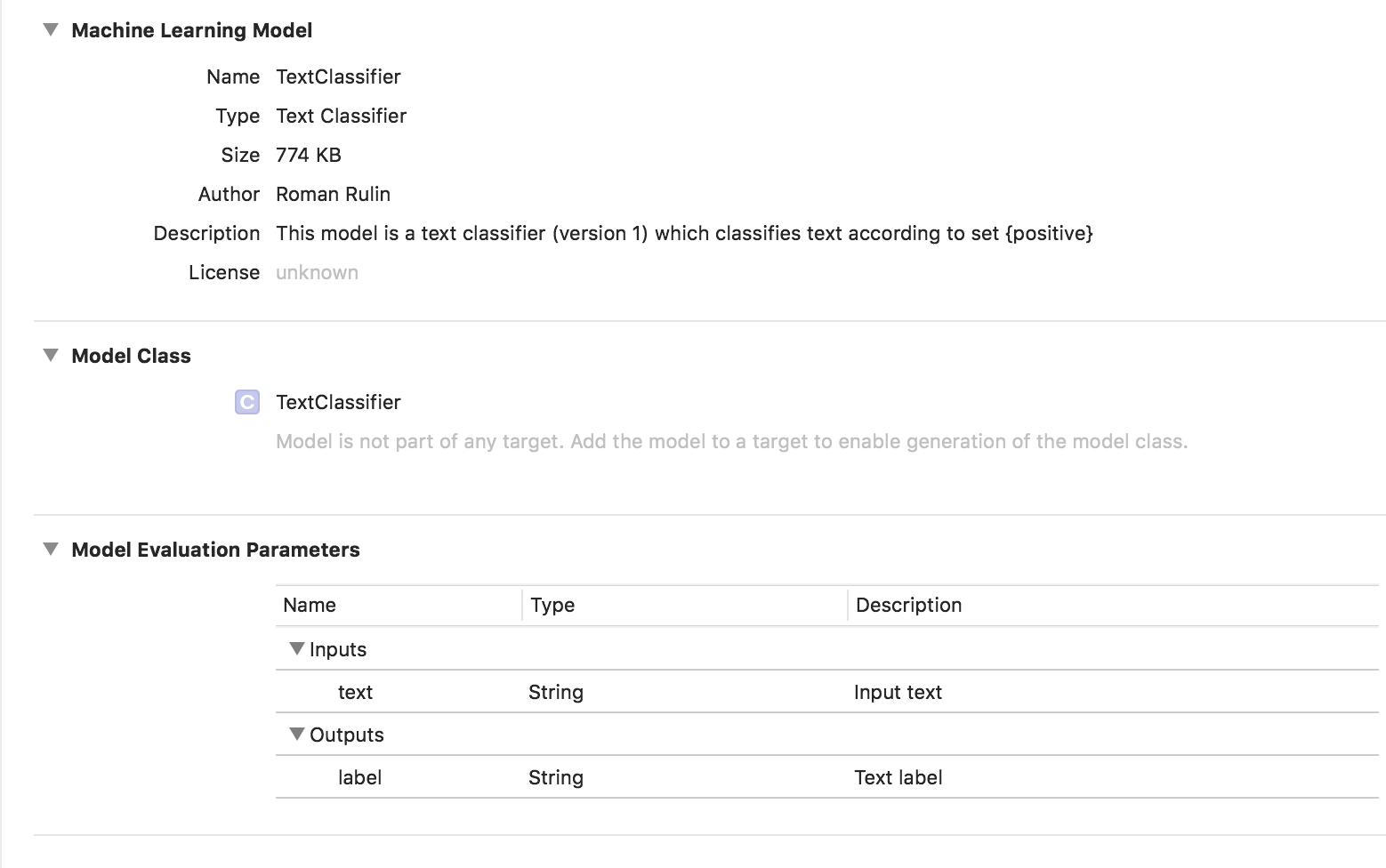
表格数据
让我们仔细看看Create ML的另一个功能-使用结构化数据(表)训练模型。
我们将编写一个测试应用程序,该应用程序根据其在地图上的位置和其他指定参数来预测公寓的价格。
因此,我们有了一个表格,其中以csv文件的形式包含了莫斯科公寓的抽象数据:每个公寓的面积,楼层,房间数量和坐标(纬度和经度)是已知的。 另外,每间公寓的费用是已知的。 越靠近中心或面积越大,价格越高。
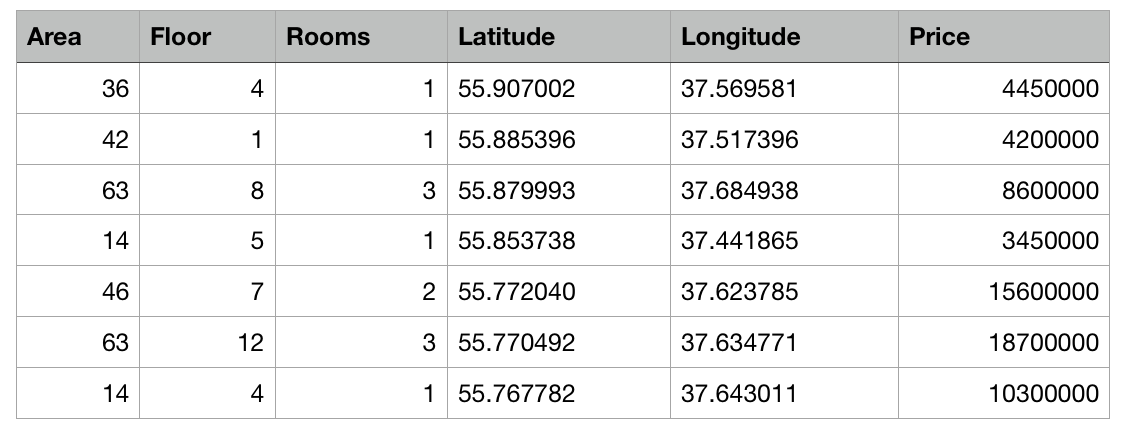
Create ML的任务是建立一个能够基于这些特征来预测公寓价格的模型。 机器学习中的此类任务称为回归任务,是与老师一起学习的经典示例。
Create ML支持许多模型-线性回归,决策树回归,树分类器,逻辑回归,随机森林分类器,Boosted Trees回归等。
我们将使用MLRegressor对象,该对象将根据输入数据选择最佳选项。
首先,使用csv文件的内容初始化MLDataTable对象:
let trainingFile = URL(fileURLWithPath: "/Users/CreateMLTest/Apartments.csv") let apartmentsData = try MLDataTable(contentsOf: trainingFile)
我们以80/20的百分比将初始数据集划分为用于模型训练和测试的数据:
let (trainingData, testData) = apartmentsData.randomSplit(by: 0.8, seed: 0)
我们创建MLRegressor模型,指示训练数据和要预测其值的列的名称。 根据输入数据的研究,将自动选择特定任务类型的回归变量(线性,决策树,增强树或随机森林)。 我们还可以指定特征列-用于分析的特定参数列,但是在此示例中这不是必需的,我们将使用所有参数。 最后,保存训练好的模型并添加到项目中:
let model = try MLRegressor(trainingData: apartmentsData, targetColumn: "Price") let modelPath = URL(fileURLWithPath: "/Users/CreateMLTest/ApartmentsPricer.mlmodel") try model.write(to: modelPath, metadata: nil)
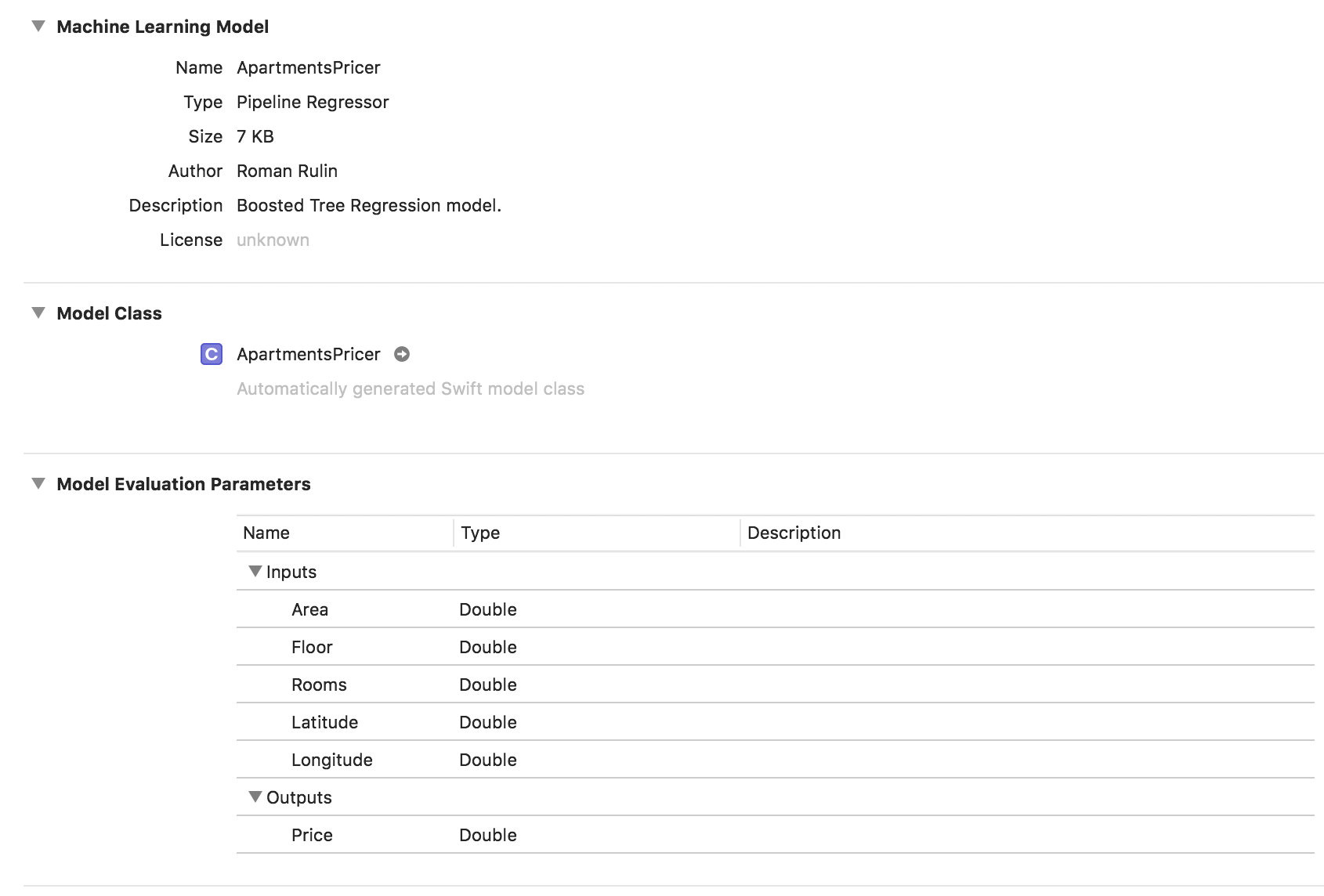
在此示例中,我们看到模型类型已经是管道回归器,并且“描述”字段包含自动选择的回归器类型-Boosted Tree Regression Model。 输入和输出参数对应于表的列,但它们的数据类型已变为Double。
现在检查结果。
初始化模型对象:
let model = ApartmentsPricer()
我们调用预测方法,将指定的参数传递给它:
let area = Double(areaSlider.value) let floor = Double(floorSlider.value) let rooms = Double(roomsSlider.value) let latitude = annotation.coordinate.latitude let longitude = annotation.coordinate.longitude let prediction = try? model.prediction( area: area, floor: floor, rooms: rooms, latitude: latitude, longitude: longitude)
我们显示成本的预测值:
let price = prediction?.price priceLabel.text = formattedPrice(price)
更改地图上的一个点或参数值,我们得出的公寓价格非常接近我们的测试数据:
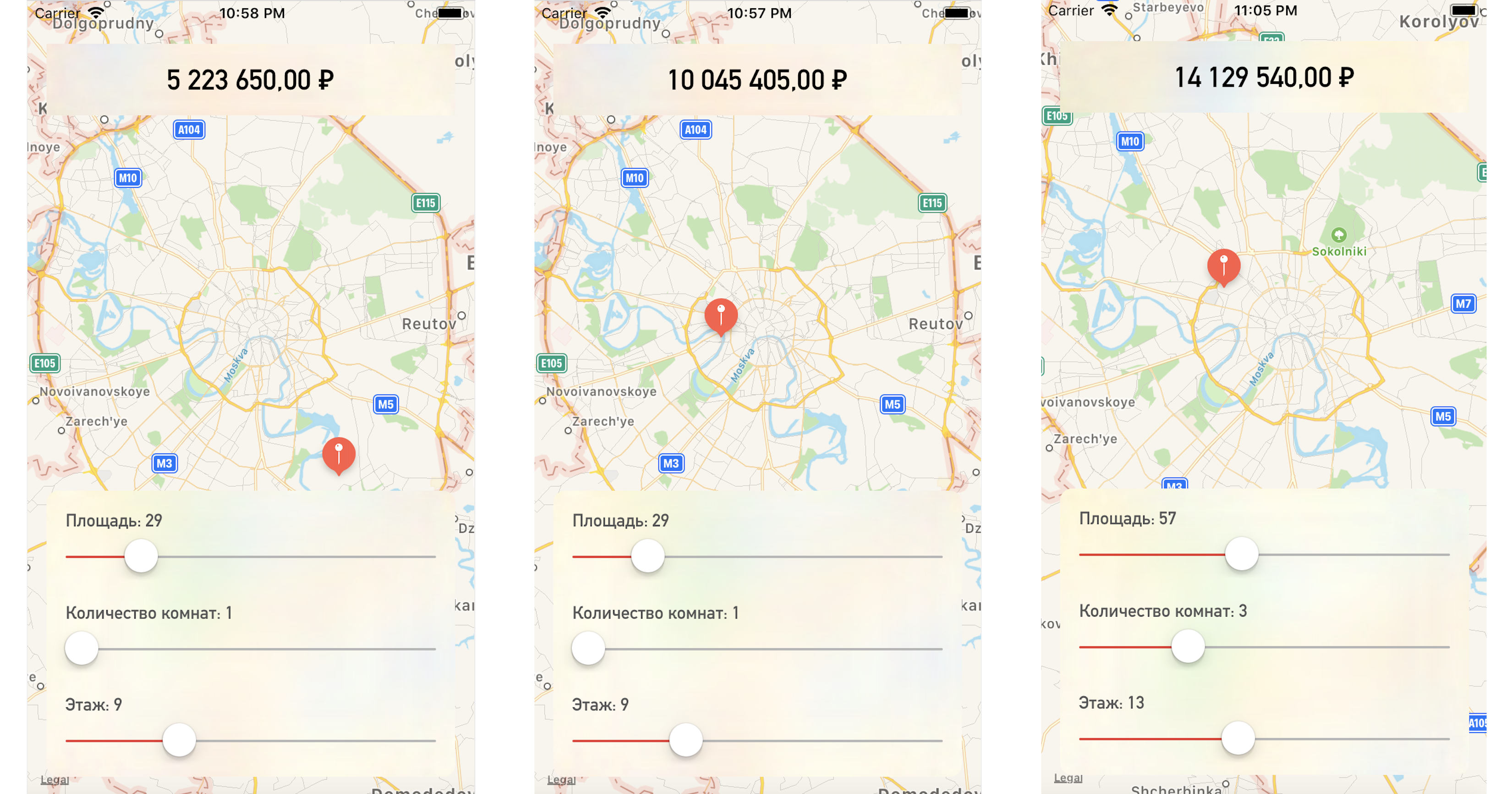
结论
现在,创建ML框架是使用机器学习技术的最简单方法之一。 它尚未允许创建用于解决某些问题的模型:识别图像中的对象,对照片进行样式化,确定类似图像,基于来自Turi创建的加速度计或陀螺仪的数据识别物理动作。
但是,值得注意的是,在过去的一年中,苹果在这一领域取得了相当大的进步,而且,可以肯定的是,我们很快就会看到上述技术的发展。