大家好,我叫Semyon Levenson,我是Rambler Group的Stream项目的团队负责人,我想谈谈我们在Apollo的经历。
我将解释什么是“流”。 这是一项针对企业家的自动化服务,可让您在不参与广告的情况下将客户从Internet吸引到您的企业,并快速创建简单的网站而无需成为布局专家。
屏幕截图显示了创建登录页面的步骤之一。
是什么开始的?
最初有MVP,很多Twig,jQuery和非常紧迫的截止日期。 但是我们采用了非标准的方式,并决定进行重新设计。 重新设计不是“修补样式”的意思,而是决定完全审查该系统。 对于组装完美的前端,这对我们来说是一个很好的阶段。 毕竟,我们的开发团队应继续为此提供支持,并在此基础上执行其他任务,以实现产品团队设定的新目标。
我们的部门已经在使用React方面积累了足够的专业知识。 我不想花两个星期来设置webpack,所以我决定使用CRA (创建React应用)。 对于样式,使用了样式化的组件 ,而在没有键入的地方使用了Flow 。 他们选择Redux进行状态管理,但结果证明我们根本不需要它,但稍后再介绍。
我们汇集了完美的前端,并意识到我们忘记了一些东西。 事实证明,我们忘记了后端,或者忘记了与后端的交互。 当您考虑到我们可以用来组织这种互动的内容时,首先想到的是-Rest。 不,我们没有休息(微笑),而是开始谈论RESTful API。 从原则上讲,这个故事很熟悉,可以延续很长时间,但是我们也知道它存在的问题。 我们将讨论它们。
第一个问题是文档。 RESTful当然没有说明如何组织文档。 这里可以选择使用相同的选项,但实际上这是引入了一个额外的实体,并使过程变得复杂。
第二个问题是如何组织对API版本的支持。
第三个重要问题是我们可以奖励的大量查询或自定义端点。 假设我们需要为这些帖子请求帖子-评论以及这些评论的更多作者。 在经典的Rest中,我们必须至少进行3个查询。 是的,我们可以奖励自定义端点,并且所有这些都可以减少到1个请求,但这已经很复杂了。
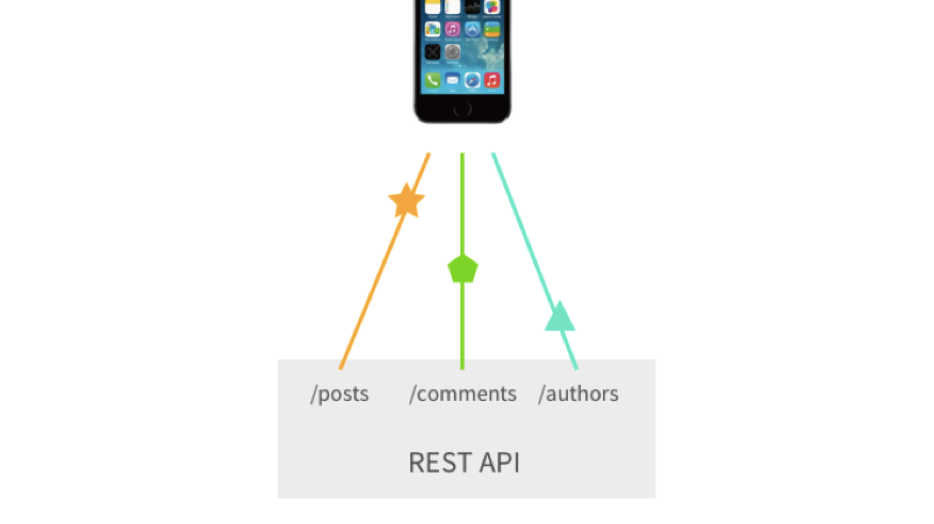
谢谢Sashko Stubailo的插图。
解决方案
目前,Facebook通过GraphQL帮助我们。 什么是GraphQL? 这是一个平台,但是今天我们将看一下其中的一部分-这是用于您的API的查询语言,只是一种语言,并且是一种非常原始的语言。 它的工作尽可能简单-当我们请求某种实体时,我们也会得到它。
要求:
{ me { id isAcceptedFreeOffer balance } }
答案是:
{ "me": { "id": 1, "isAcceptedFreeOffer": false, "balance": 100000 } }
但是GraphQL不仅与读取有关,还与更改数据有关。 为此,GraphQL中存在突变。 突变是值得注意的,因为我们可以通过成功的更改从后端声明所需的响应。 但是,有一些细微差别。 例如,如果我们的突变影响了图范围之外的数据。
我们使用免费优惠的一个变异示例:
mutation { acceptOffer (_type: FREE) { id isAcceptedFreeOffer } }
作为回应,我们得到了与请求相同的结构
{ "acceptOffer": { "id": 1, "isAcceptedFreeOffer": true } }
可以使用常规提取与GraphQL后端进行交互。
fetch('/graphql', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ query: '{me { id balance } }' }) });
GraphQL有哪些优势?
当您开始使用它时,首先要意识到的一点就是它是强类型化的并且具有自记录功能。 通过在服务器上设计GraphQL模式,我们可以直接在代码中立即描述类型和属性。

如上所述,RESTful存在版本控制问题。 GraphQL为此实现了一个非常优雅的解决方案-已弃用。
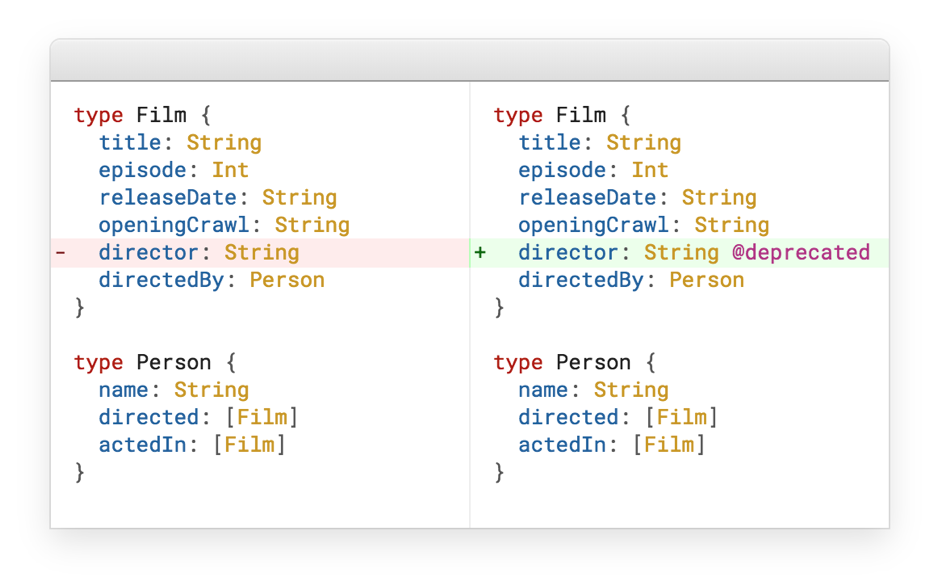
假设我们有一部电影,我们扩大了它,所以我们有一个导演。 在某些时候,我们只是将导演设为单独的类型。 问题是,如何处理最后一个导演字段? 对此有两个答案:要么删除此字段,要么将其标记为已弃用,然后它自动从文档中消失。
我们独立决定需要什么。
我们回想起上一张图片,其中所有内容都与REST一起使用,但是在这里,所有内容都组合到一个请求中,不需要后端开发进行任何自定义。 一旦他们都描述了它,我们就扭曲,扭曲,变戏法。
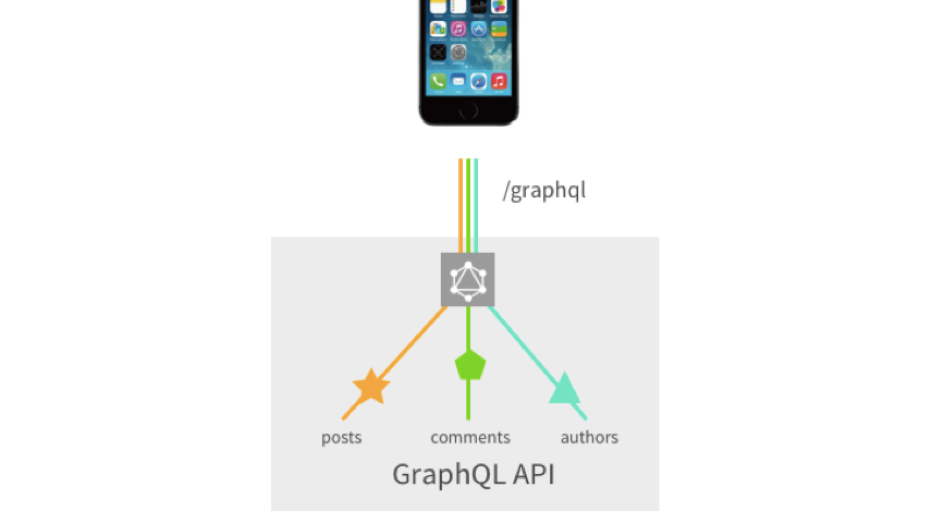
但不是没有美中不足的地方。 原则上,GraphQL在前端没有太多缺点,因为它最初是为解决前端问题而开发的。 但是后端运行得不太顺利...它们有类似N + 1的问题。 以查询为例:
{ landings(_page: 0, limit: 20) { nodes { id title } totalCount } }
一个简单的请求,我们请求20个站点以及我们拥有的站点数。 在后端,这可以变成21个数据库查询。 这个问题是已知的,已经解决。 对于Node JS,有来自Facebook的dataloader软件包。 对于其他语言,您可以找到自己的解决方案。
还存在深度嵌套的问题。 例如,我们有专辑,这些专辑有歌曲,通过歌曲我们也可以获取专辑。 为此,请进行以下查询:
{ album(id: 42) { songs { title artists } } }
{ song(id: 1337) { title album { title } } }
因此,我们得到了一个递归查询,这也为我们奠定了基础。
query evil { album(id: 42) { songs { album { songs { album {
这个问题也是众所周知的,Node JS的解决方案是GraphQL深度限制,对于其他语言也有解决方案。
因此,我们决定使用GraphQL。 现在是时候选择适用于GraphQL API的库了。 上面显示的几行带有访存的示例只是一个传输。 但是,由于该方案和声明性,我们还可以在前端缓存查询,并通过GraphQL后端以更高的性能工作。
因此,我们有两个主要参与者-Relay和Apollo。
接力赛
Relay是Facebook开发的,他们自己使用。 像Oculus,Circle CI,Arsti和Friday。
Relay的优点是什么?
直接的好处是开发人员是Facebook。 React,Flow和GraphQL是Facebook的发展,所有这些都是彼此量身定制的拼图游戏。 我们在Github上没有星星的地方,Relay有将近11,000,Apollo有7600可以比较。 。 我们可以假设这仅适用于GraphQL:
# Relay-compiler foo { # type FooType id ... on FooType { # matches the parent type, so this is extraneous id } } # foo { id }
中继的缺点是什么?
首先要减去的*是缺少SSR。 Github尚有一个未解决的问题 。 为什么在星号下-因为已经有解决方案,但是它们是第三方的,而且还很模棱两可。
同样,中继是一个规范。 事实是GraphQL已经是一个规范,而Relay是一个规范之上的规范。
例如,中继分页的实现方式有所不同,光标出现在此处。
{ friends(first: 10, after: "opaqueCursor") { edges { cursor node { id name } } pageInfo { hasNextPage } } }
我们不再使用通常的偏移量和限制。 对于提要中的提要,这是一个很棒的话题,但是当我们开始做各种网格时,就会感到痛苦。
Facebook通过为React编写一个库解决了这个问题。 还有针对vue.js的其他库的解决方案,例如-vue -relay 。 但是,如果我们注意恒星和commit-s的数量,那么在这里也不是所有事物都那么平滑且不稳定。 例如,在CRA框外创建Create React App会阻止您使用中继编译器。 但是您可以使用react-app-rewired来解决此限制。
阿波罗
我们的第二个候选人是阿波罗 。 由他的团队Meteor开发。 Apollo使用诸如AirBnB,ticketmaster,Opentable等著名命令。
阿波罗有什么优势?
第一个重要的优点是Apollo被开发为框架不可知的库。 例如,如果我们现在想在Angular上重写所有内容,那么这将不是问题,Apollo可以解决此问题。 您甚至可以用Vanilla编写所有内容。
阿波罗(Apollo)有很不错的文档,有针对常见问题的现成解决方案。

另一个优点是Apollo-功能强大的API。 原则上,与Redux一起工作的人会在这里找到常用的方法:有ApolloProvider(例如Provux for Redux),而不是Apollo的商店,它称为客户端:
import { ApolloProvider } from 'react-apollo'; import { ApolloClient } from './ApolloClient'; const App = () => ( <ApolloProvider client={ApolloClient}> ... </ApolloProvider> );
在组件本身的级别,我们提供了graphql HOC作为连接。 并且我们已经在其中编写了GraphQL查询,例如Redux中的MapStateToProps。
import { graphql } from 'react-apollo'; import gql from 'graphql-tag'; import { Landing } from './Landing'; graphql(gql` { landing(id: 1) { id title } } `)(Landing);
但是,当我们在Redux中执行MapStateToProps时,我们会拾取本地数据。 如果没有本地数据,则Apollo本身会向服务器发送数据。 非常方便道具属于组件本身。
function Landing({ data, loading, error, refetch, ...other }) { ... }
这是:
•数据;
•下载状态;
•错误(如果发生);
辅助功能,例如refetch重新加载数据或fetchMore进行分页。 Apollo和Relay都有一个巨大的优势,那就是Optimistic UI。 它允许您在请求级别提交撤消/重做:
this.props.setNotificationStatusMutation({ variables: { … }, optimisticResponse: { … } });
例如,用户单击“喜欢”按钮,“喜欢”立即计数。 在这种情况下,对服务器的请求将在后台发送。 如果在发送过程中发生一些错误,则可变数据将自行返回其原始状态。
服务器端渲染实现良好,我们在客户端上设置了一个标志,一切就绪。
new ApolloClient({ ssrMode: true, ... });
但是在这里我想谈谈初始状态。 当阿波罗自己烹饪时,一切都很好。
<script> window.__APOLLO_STATE__ = client.extract(); </script> const client = new ApolloClient({ cache: new InMemoryCache().restore(window.__APOLLO_STATE__), link });
但是我们没有服务器端渲染,后端将特定的GraphQL查询推送到全局变量中。 在这里,您需要一个小拐杖,您需要编写一个Transform函数,后端的GraphQL响应已经变成了Apollo所需的格式。
<script> window.__APOLLO_STATE__ = transform({…}); </script> const client = new ApolloClient({ cache: new InMemoryCache().restore(window.__APOLLO_STATE__), link });
Apollo的另一个优点是可以很好地自定义。 我们都记得Redux的中间件,这里的一切都是一样的,仅此称为链接。

我想分别说明两个链接: apollo-link-state和apollo-link-rest ,如果我们想将GraphQL查询写入Rest API,则需要在不存在Redux的情况下存储本地状态。 但是,对于后者,您需要非常小心,因为 可能会出现某些问题。
阿波罗也有缺点
让我们来看一个例子。 出现了意外的性能问题:在前端(这是一个目录)上请求了2,000个项目,并且开始出现性能问题。 在调试器中查看它之后,原来是Apollo在读取时吞噬了很多资源,该问题基本上已经解决,现在一切都很好,但是有这样的缺点。
而且,结果却非常明显。
function Landing({ loading, refetch, ...other }) { ... }
此外,似乎在执行数据重新请求时,如果先前的请求以错误结束,则加载应该变为true。 但是不!
为此,您需要在graphql HOC中指定notifyOnNetworkStatusChange:true,或在本地存储重新获取状态。
阿波罗vs. 接力赛
因此,我们得到了这样一张桌子,我们都进行了称重,计数,并且落后阿波罗76%。
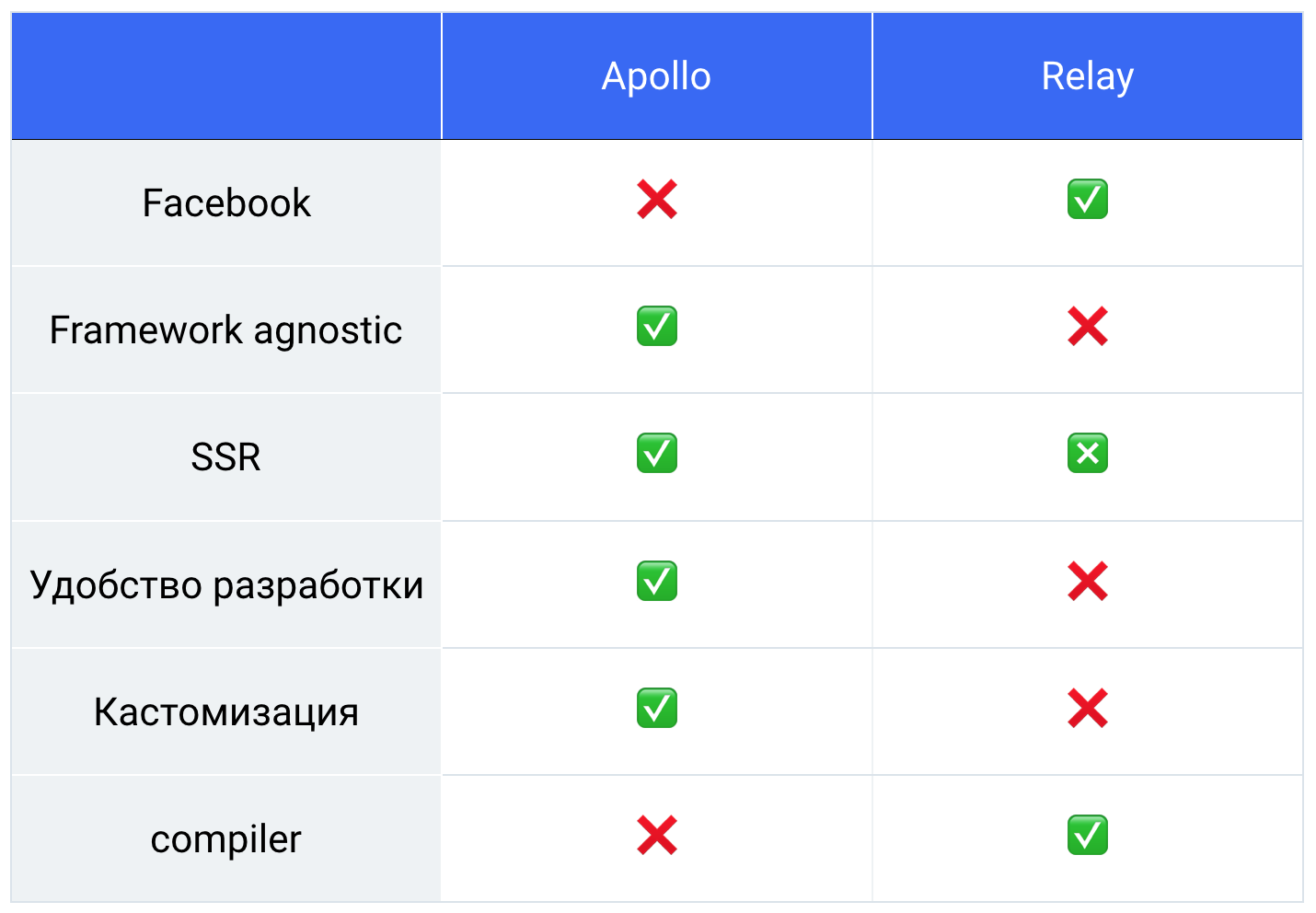
因此,我们选择了图书馆并开始工作。
但是我想对工具链说更多。
这里的一切都非常好,有一些供编辑者使用的插件,无论是更好的地方还是坏的地方。 还有一个apollo-codegen,它生成有用的文件,例如流类型,并基本上从GraphQL API中提取模式。
标题为“疯狂的手”或我们在家做的事情
我们遇到的第一件事是,我们基本上需要以某种方式请求数据。
graphql(BalanceQuery)(BalanceItem)
我们有共同的条件:加载,错误处理。 我们编写了自己的鹰(asyncCard),该鹰通过graqhql和asyncCard组成。
compose( graphql(BalanceQuery), AsyncCard )(BalanceItem)
我也想谈谈片段。 有一个LandingItem组件,它从GraphQL API知道需要什么数据。 我们设置fragment属性,在该属性中,我们指定了Landing实体的字段。
const LandingItem = ({ content }: Props) => ( <LandingItemStyle> … </LandingItemStyle> ); LandingItem.fragment = gql` fragment LandingItem on Landing { ... } `;
现在,在组件使用级别,我们在最终请求中使用其片段。
query LandingsDashboard { landings(...) { nodes { ...LandingItem } totalCount } ${LandingItem.Fragment} }
假设有一项任务可以完成,以向此目标网页添加状态-这不是问题。 我们向渲染器和片段添加一个属性。 一切准备就绪。 单一责任原则的所有荣耀。
const LandingItem = ({ content }: Props) => ( <LandingItemStyle> … <LandingItemStatus … /> </LandingItemStyle> ); LandingItem.fragment = gql` fragment LandingItem on Landing { ... status } `;
我们还有什么其他问题?
我们网站上有许多小部件,它们发出了各自的请求。
在测试过程中,事实证明所有这些都会变慢。 我们的安全检查时间很长,每个请求的费用都很高。 原来也没问题,有Apollo-link-batch-http
new BatchHttpLink({ batchMax: 10, batchInterval: 10 });
它的配置如下:我们传递可以合并的请求数,以及第一个请求出现后此链接将等待多长时间。
结果是这样的:同时加载所有内容,同时同时加载所有内容。 值得注意的是,如果在此合并过程中任何子查询返回错误,则该错误将仅与他有关,而不与整个请求有关。
我想分别告诉大家,去年秋天,从第一个阿波罗到第二个
一开始是阿波罗和雷德克斯
'react-apollo' 'redux'
然后,Apollo变得更加模块化和可扩展,这些模块可以独立开发。 相同的阿波罗缓存内存。
'react-apollo' 'apollo-client' 'apollo-link-batch-http' 'apollo-cache-inmemory' 'graphql-tag'
值得注意的是,不需要Redux,事实证明,原则上不需要Redux。
结论:
- 功能交付时间减少了,我们不会浪费时间描述操作,减少了Redux,并减少了后端的接触
- 出现抗脆弱性是因为 通过API的静态分析,您可以在前端需要一件事而后端返回完全不同的问题时消除问题。
- 如果您开始使用GraphQL-试试Apollo,请不要失望。
附注:您也可以在Rambler Front&Meet up#4上观看我的演讲中的视频