Python很棒。 我们说“ pip install”,很可能将提供必要的库。 但是有时答案是:“编译失败”,因为存在二进制模块。 在几乎所有现代语言中,它们都遭受某种痛苦,因为存在许多体系结构,某些东西需要为特定的机器组装,某些东西需要与其他库链接。 总的来说,这是一个有趣但很少研究的问题:如何解决这些问题以及存在哪些问题? 去年,Dmitry Zhiltsov(
zaabjuda )试图在MoscowPython Conf上回答这个问题。
剪下的是德米特里报告的文字版本。 让我们简要地讨论何时需要二进制模块,以及何时最好放弃它们。 让我们讨论编写规则时应遵循的规则。 考虑五个可能的实现选项:
关于演讲者 :Dmitry Zhiltsov已经发展了10多年。 他在CIAN担任系统架构师,即负责技术解决方案和时序控制。 在我的一生中,我设法尝试了汇编程序Haskell,C,并且在过去的五年中,我一直在积极地使用Python进行编程。
关于公司
许多住在莫斯科并租房的人可能都知道CIAN。 CYAN每月有700万买家和租户。 每个月所有这些用户都可以使用我们的服务找到居住的地方。
大约75%的莫斯科人了解我们公司,这很酷。 在圣彼得堡和莫斯科,我们实际上被视为垄断者。 目前,我们正试图进入该地区,因此在过去三年中发展已增长了8倍。 这意味着团队增加了8倍,向用户交付价值的速度提高了8倍,即 从产品创意到工程师的手如何将产品推向生产。 我们在庞大的团队中学会了快速发展,并很快了解了目前的情况,但今天我们将讨论一些其他内容。
我将讨论二进制模块。 现在,几乎50%的Python库都具有某种二进制模块。 事实证明,许多人并不熟悉它们,并认为这是先验的,是黑暗的和不必要的。 其他人建议更好地编写单独的微服务,而不要使用二进制模块。
本文将包括两个部分。
- 我的经验:为什么需要它们,何时最好用,什么时候不用。
- 可以为Python实现二进制模块的工具和技术。
为什么需要二进制模块?
我们都非常清楚Python是一种解释语言。 它几乎是所有解释语言中最快的,但是不幸的是,它的
速度并不总是足够进行繁重的数学计算。 立即想到C会更快。
但是Python还有一个痛苦-它是
GIL 。 关于他的文章很多,关于如何与他相处的报道也很多。
我们还需要二进制扩展来
重用逻辑 。 例如,我们找到了一个库,其中包含我们需要的所有功能,以及为什么不使用它。 也就是说,您无需重新编写代码,我们只需要提取完成的代码并重复使用即可。
许多人认为,使用二进制扩展名可以
隐藏源代码 。 这个问题是非常非常有争议的,当然,在一些疯狂的变态的帮助下,这是可以实现的,但是并不能100%保证。 您可以得到的最大结果就是不让客户端反编译并查看所传递的代码中发生了什么。
何时真正需要二进制扩展?
关于速度和Python,这很清楚-当某些函数的运行速度非常慢,并且占用了所有代码的80%的执行时间时,我们开始考虑编写二进制扩展。 但是,要做出这样的决定,就必须像一位著名演讲者所说的那样,开始思考。
为了编写扩展扩展,首先必须考虑到它会很长。 首先,您需要“舔”您的算法,即 看看是否有门框。
在90%的情况下,对算法进行彻底检查后,写一些扩展的需求就消失了。
确实需要二进制扩展的第二种情况是
使用多线程进行简单操作 。 现在,它已不再那么重要了,但是它仍然存在于血腥的企业中,仍然存在于某些仍在编写Python 2.6的系统集成商中。 没有异步,甚至对于简单的事情,例如,上传一堆图片,多线程也会增加。 最初似乎并不会产生任何网络开销,但是当我们将图像上传到缓冲区时,命运不明的GIL来了,并且开始了某种制动。 如实践所示,最好使用Python一无所知的库来解决这些问题。
如果您需要实现一些特定的协议,则制作简单的C / C ++代码可能会很方便,并且省去了很多麻烦。 由于没有现成的库,我当时是在一家电信运营商那里完成的,所以我必须自己编写。 但是我再说一遍,现在这不是很相关,因为存在异步,对于大多数任务来说这就足够了。
关于明显的
困难操作,我已经事先说过。 当您遇到崩溃,大型矩阵之类的问题时,就需要对C / C ++进行扩展。 我想指出的是,有些人认为我们这里不需要二进制扩展,最好用某种“
超快速语言 ”制作微服务,并通过网络传输大量矩阵。 不,最好不要这样做。
当可以并且甚至应该采用它们时,另一个很好的例子是当您具有
模块的
既定逻辑时 。 如果您公司中有某种Python模块或一个库已经存在3年,则每年对其进行一次更改,然后进行2行更改,那么如果有空闲的资源和时间,为什么不将其转换为普通的C库。 至少可以提高生产率。 而且还会有一种理解,即如果需要在库中进行一些基本的更改,那么这并不是那么简单,也许值得重新思考一下,并以不同的方式使用该库。
5条黄金法则
我在实践中得出了这些规则。 它们不仅涉及Python,还涉及可以使用二进制扩展名的其他语言。 您可以与他们争论,但也可以考虑并带自己的想法。
- 仅导出功能 。 在二进制库中用Python构建类非常耗时:您需要描述很多接口,需要查看模块本身中的许多参考完整性。 为该功能编写一个小的界面会更容易。
- 使用包装器类 。 有些人非常喜欢OOP,并且确实想要上课。 无论如何,即使这些不是类,也最好编写一个Python包装器:创建一个类,定义一个类方法或常规方法,调用本机C / C ++函数。 至少,这有助于维护数据体系结构的完整性。 如果您使用某种无法修复的C / C ++第三方扩展,则可以在包装程序中对其进行破解,以使其全部正常运行。
- 您不能将参数从Python传递到扩展-这甚至不是规则,而是要求。 在某些情况下,这可能会起作用,但这通常是一个坏主意。 因此,在您的代码中,您必须首先创建一个将Python类型转换为C类型的处理程序。并且只有在此之后,调用已经可以与类型s一起使用的任何本机函数。 同一处理程序从可执行函数接收响应,并将其转换为Python数据类型,然后将其放入Python代码。
- 考虑到垃圾回收 。 Python有一个众所周知的GC,您不要忘记它。 例如,我们通过引用传递了大量文本,并尝试在库中找到一些单词。 我们要对此进行并行化处理,我们将链接传递到该内存区域并启动多个线程。 此时,GC只是简单地获取并确定没有其他对象引用此对象,并将其从内存区域中删除。 在同一代码中,我们只是得到一个空引用,这通常是分段错误。 我们一定不要忘记垃圾收集器的这种功能,并将最简单的数据类型传递给char库:char,integer等。
另一方面,编写扩展的语言可能具有自己的垃圾收集器。 从这个意义上说,Python和C#库的组合是一件痛苦的事情。
- 明确定义导出函数的参数 。 这样,我想说这些功能将需要定性地注释。 如果我们接受PyObject函数,并且无论如何都将在我们的库中接受它,那么我们将需要明确指出哪些参数属于哪些类型。 这很有用,因为如果传递错误的数据类型,则库中将出现错误。 也就是说,您需要它是为了您的方便。
二进制扩展架构

实际上,二进制扩展的体系结构并不复杂。 有Python,有一个调用函数,该函数位于本地调用代码的包装器上。 该调用依次依赖于导出到Python的函数,并且可以直接调用该函数。 您需要在此功能中将数据类型转换为语言的数据类型。 并且只有在此函数将所有内容翻译给我们之后,我们才调用本机函数,该函数执行主要逻辑,然后以相反的方向返回结果并将其扔到Python中,从而将数据类型转换回去。
技术与工具
编写二进制扩展的最著名方法是本机C / C ++扩展。 仅仅是因为它是标准的Python技术。
本机C / C ++扩展
Python本身是用C实现的,并且python.h中的方法和结构用于编写扩展。 顺便说一句,这个东西也很好,因为在现有项目中很容易实现它。 在setup.py中指定xt_modules并说要构建项目,您需要使用此类编译标志来编译此类源代码就足够了。 下面是一个例子。
name = 'DateTime.mxDateTime.mxDateTime' src = 'mxDateTime/mxDateTime.c' extra_compile_args=['-g3', '-o0', '-DDEBUG=2', '-UNDEBUG', '-std=c++11', '-Wall', '-Wextra'] setup ( ... ext_modules = [(name, { 'sources': [src], 'include_dirs': ['mxDateTime'] , extra_compile_args: extra_compile_args } )] )
本机C / C ++扩展的优点
- 本机技术。
- 它很容易集成到项目程序集中。
- 最大数量的文档。
- 允许您创建自己的数据类型。
本机C / C ++扩展的缺点
- 高入门门槛。
- 必须具备C.的知识。
- Boost.Python。
- 细分错误。
- 调试困难。
根据这项技术,无论是标准文章还是博客文章,都会编写大量文档。 一个巨大的优点是我们可以创建自己的Python数据类型并构造我们的类。
这种方法有很大的缺点。 首先,这是入门门槛-并不是每个人都了解C足以进行生产编码。 您需要了解,为此,仅阅读本书并运行本机扩展是不够的。 如果要这样做,那么:首先,学习C; 然后开始编写命令实用程序; 只有在那之后才能编写扩展。
Boost.Python非常适合C ++,它使您几乎可以完全从我们在Python中使用的所有包装中抽象出来。 但是,我认为要减去的是,您需要花很多精力才能将其一部分吸收并导入到项目中,而无需下载整个Boost。
列出调试的缺点,我的意思是,现在每个人都习惯了使用图形调试器,而对于二进制模块,这样的事情将不起作用。 您最有可能需要使用Python插件安装GDB。
让我们看一个如何创建它的例子。
#include <Python.h> static PyObject*addList_add(Pyobject* self, Pyobject* args){ PyObject * listObj; if (! PyARg_Parsetuple( args, "", &listObj)) return NULL; long length = PyList_Size(listObj) int i, sum =0; // return Py_BuildValue("i", sum); }
首先,我们包括Python头文件。 之后,我们描述Python将使用的addList_add函数。 最重要的是正确命名函数,在这种情况下,addList是模块的名称,_add是将在Python中使用的函数的名称。 我们传递PyObject模块本身,并使用PyObject传递参数。 之后,我们执行标准检查。 在这种情况下,我们试图解析元组参数,并说它是一个对象-必须显式指定文字“ O”。 之后,我们知道我们将listObj作为对象进行传递,并尝试使用标准Python方法PyList_Size找出其长度。 注意,这里我们仍然不能使用调用来找出此向量的长度,而是使用Python功能。 我们省略了实现,之后有必要将所有值返回给Python。 为此,调用Py_BuildValue,指定我们要返回的数据类型(在这种情况下,“ i”是整数),以及sum变量本身。
在这种情况下,每个人都可以理解-我们找到列表中所有元素的总和。 让我们更进一步。
for(i = 0; i< length; i++){
这是同一件事;目前,listObj是一个Python对象。 在这种情况下,我们尝试获取列表项。 Python.h具有为此所需的一切。
达到温度后,我们尝试将其转换为较长时间。 而且只有在那之后,您才能在C语言中执行某些操作。
在实现整个功能之后,有必要编写文档。
文档始终是好的 ,并且该工具包包含了便于维护的所有内容。 按照命名约定,我们将其命名为addList_docs模块,并将描述保存在那里。 现在您需要注册该模块,为此有一个特殊的PyMethodDef结构。 在描述属性时,我们说该函数以“ add”的名称导出到Python,该函数称为PyCFunction。 METH_VARARGS意味着一个函数可以潜在地使用任意数量的变量。 我们还写下了其他几行内容,并描述了标准检查,以防万一我们刚刚导入了模块,但未使用任何方法以免脱落。
在宣布所有这些信息之后,我们尝试制作一个模块。 我们创建一个moduledef,并将我们所做的一切都放在这里。
static struct PyModuleDef moduledef = { PyModuleDef_HEAD_INIT, "addList example module", -1, adList_funcs, NULL, NULL, NULL, NULL };
PyModuleDef_HEAD_INIT是您应该始终使用的标准Python常量。 -1表示在导入阶段不需要分配其他内存。
创建模块本身时,需要对其进行初始化。 Python一直在寻找init,因此请为addList创建一个PyInit_addList。 现在,从组装的结构中,您可以调用PyModule_Create并最终创建模块本身。 接下来,添加元信息并返回模块本身。
PyInit_addList(void){ PyObject *module = PyModule_Create(&mdef); If (module == NULL) return NULL; PyModule_AddStringConstant(module, "__author__", "Bruse Lee<brus@kf.ch>:"); PyModule_addStringConstant (Module, "__version__", "1.0.0"); return module; }
正如您已经注意到的,有很多事情需要改变。 当我们用C / C ++编写代码时,您应该永远记住Python。
因此,大约15年前,为了促进普通的普通程序员的生活,出现了SWIG技术。
威格
该工具允许您从Python绑定中抽象并编写本机代码。 它具有与Native C / C ++相同的优缺点,但也有例外。
SWIG优点:
- 技术稳定。
- 大量的文档。
- 从绑定到Python的摘要。
SWIG的缺点:
- 长安装。
- 知识C.
- 细分错误。
- 调试困难。
- 集成到项目组装中的复杂性。
第一个缺点是,
在进行设置时,您会失去理智 。 首次设置时,我花了一天半的时间甚至将其启动。 然后,当然更容易了。 SWIG 3.x变得更加容易。
为了不再使用代码,请考虑SWIG的通用方案。
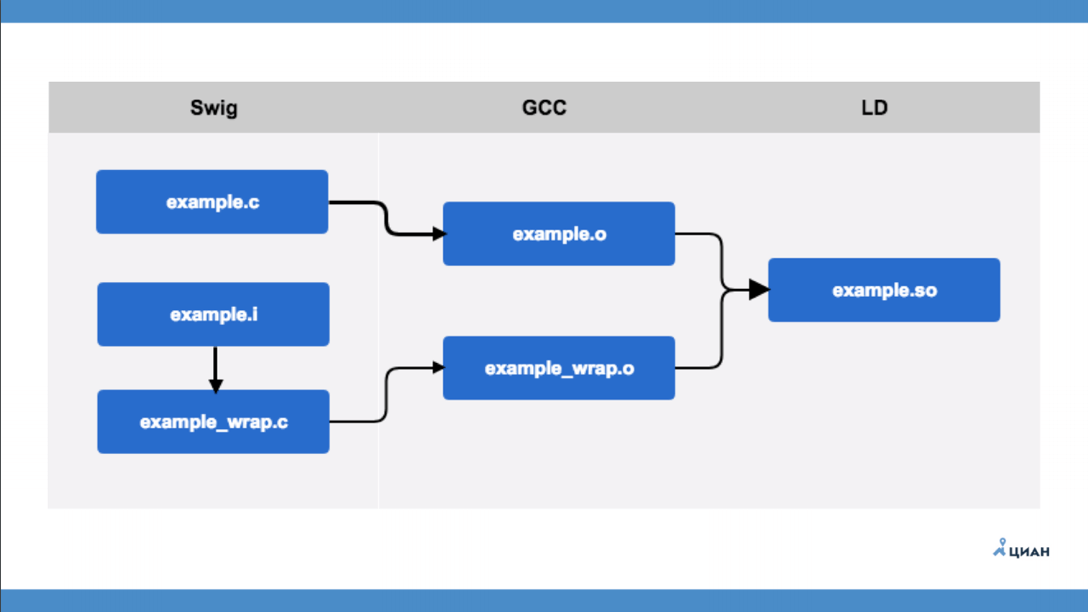
example.c是一个C模块,对Python一无所知。 有一个接口文件example.i,以SWIG格式描述。 之后,运行SWIG实用程序,该实用程序从接口文件中创建example_wrap.c-这与我们以前用手工进行的包装相同。 也就是说,SWIG只是为我们创建了一个文件包装器,即所谓的桥。 之后,使用GCC,我们编译了两个文件并获得了两个目标文件(example.o和example_wrap.o),然后才创建我们的库。 一切都简单明了。
赛顿
Andrey Svetlov在MoscowPython Conf上作了出色的
报告 ,所以我只想说这是一种流行的技术,它提供了很好的文档。
Cython优点:
- 流行技术。
- 相当稳定。
- 它很容易集成到项目程序集中。
- 好的文档。
Cython的缺点:
缺点一如既往。 最主要的是它自己的语法,该语法类似于C / C ++,并且非常类似于Python。
但我想指出的是,可以使用Cython通过编写本机代码来加速Python代码。

如您所见,装饰器很多,这不是很好。 如果要使用Cython,请参阅Andrei Svetlov的报告。
C类型
CTypes是与外来功能接口一起使用的标准Python库。 FFI是一个低级库。 这是一项本机技术,在代码中经常使用,它的帮助很容易实现跨平台。
但是FFI会带来很多开销,因为所有桥,运行时中的所有处理程序都是动态创建的。 也就是说,我们加载了动态库,而Python此时此刻不知道该库是什么。 只有在内存中调用库时,才会动态构建这些桥。
CType的优点:
- 本机技术。
- 易于在代码中使用。
- 易于实现跨平台。
- 您几乎可以使用任何语言。
缺点CType:
from ctypes import *
他们使用adder.so并在运行时调用它。 我们甚至可以传递本机Python类型。
毕竟,问题是:“它在某种程度上很复杂,到处都是C,怎么办?”。
铁锈
有一次,我没有适当地注意该语言,但是现在我几乎转向了它。
Rust的优点:
- 安全的语言。
- 强大的静态保证行为正确。
- 轻松集成到项目构建( PyO3 )中。
锈的缺点:
- 高入门门槛。
- 长安装。
- 调试困难。
- 几乎没有文档。
- 在某些情况下,开销很大。
Rust是一种具有自动工作证明的安全语言。 语法本身和语言预处理器本身不允许出现显式错误。 同时,它着重于可变性,也就是说,它必须处理代码分支执行的任何结果。
感谢PyO3团队,Rust有很好的Python绑定程序,以及用于集成到项目中的工具。
不利的一面是,对于一个没有准备的程序员来说,配置它会花费很长时间。 很少有文档,但是没有缺点,我们没有细分错误。 在Rust中,以一种很好的方式,在99%的情况下,程序员只有在明确指出未包装并对其打分的情况下,才能获得分段错误。
一个小代码示例,与我们之前检查过的模块相同。
#![feature(proc_macro)] #[macro_use] extern crate pyo3; Use pyo3::prelude::*;
该代码具有特定的语法,但是您很快就会习惯它。 实际上,这里的一切都是一样的。 使用宏,我们制作了modinit,它为我们完成了为Python生成各种绑定程序的所有其他工作。 记住我说过,您需要做一个处理程序包装,这是相同的。 run_py转换类型,然后我们调用本机代码。
如您所见,为了导出某些功能,有语法糖。 我们只是说我们需要add函数,并且不描述任何接口。 我们接受list,它就是py_list,而不是Object,因为Rust本身会在编译时设置必要的绑定器。 如果我们在扩展名扩展名中传递了错误的数据类型,则会发生TypeError。 得到列表后,我们开始处理它。
让我们更详细地了解他正在做什么。
#[pyfn(m, "add", py_list="*")] fn add(_py: Python, py_list: &PyList) -> PyResult<i32> { match py_list.len() { 0 =>Err(EmptyListError::new("List is empty")), _ => { let mut sum : i32 = 0; for item in py_list.iter() { let temp:i32 = match item.extract() { Ok(v) => v, Err(_) => { let err_msg: String = format!("List item {} is not int", item); return Err(ItemListError::new(err_msg)) } }; sum += temp; } Ok(sum) } } }
与C / C ++ / Ctypes中的代码相同,但仅在Rust中。 在那里,我尝试将PyObject强制转换为某种形式。 如果我们要列出,除了数字,会得到一个字符串怎么办? 是的,我们会收到SystemEerror。 在这种情况下,通过
let mut sum
:i32 = 0; 我们还试图从列表中获取一个值并将其转换为i32。 也就是说,如果没有item.extract(),我们将无法在不知不觉中将其强制转换为所需的类型。 当我们编写i32时,如果出现Rust错误,则在编译阶段会说:“处理非i32的情况”。 在这种情况下,如果我们有i32,则返回一个值,如果这是错误,则抛出异常。
选择什么
简短的导览结束后,我们会思考到底该选择什么?
答案确实取决于您的口味和肤色。
我不会推广任何特定技术。

只需总结一下:
- 对于SWIG和C / C ++,您需要非常了解C / C ++,并了解此模块的开发会带来一些额外的开销。 但是将使用最少的工具,并且我们将使用开发人员支持的原生Python技术。
- 就Cython而言,我们的输入阈值很小,开发速度很高,这也是一个普通的代码生成器。
- 我要警告您有关相对大的开销的CType。 当我们不知道动态库加载是哪种类型的库时,可能会导致很多麻烦。
- 我建议Rust选择一个不太了解C / C ++的人。 生产中的铁锈问题最少。
征集论文
我们将在9月7日之前接受莫斯科Python Conf ++的申请-以这种简单的形式编写您所了解的Python,您确实需要与社区共享。
对于那些对聆听更感兴趣的人,我可以谈论很酷的报道。
- 唐纳德·怀特(Donald Whyte)喜欢谈论用Python加速数学,并正在为我们准备一个新故事 :如何使用流行的库,技巧和阴险使数学速度提高10倍,并且代码清晰易懂并受支持。
- Artyom Malyshev收集了他在Django开发中多年的经验,并提出了有关该框架的报告指南 ! 在接收HTTP请求和发送完成的网页之间发生的一切:暴露魔术,框架内部机制的映射以及项目的许多有用技巧。