如果您熟悉C#,则很可能知道必须始终重写
Equals以及
GetHashCode以避免性能
GetHashCode 。 但是如果不这样做会怎样? 今天,我们将性能与两个调整选项进行比较,并考虑使用有助于避免错误的工具。

这个问题有多严重?
并非每个潜在的性能问题都会影响应用程序的运行时间。
Enum.HasFlag方法的效率不是很高(*),但是如果您不将其用于资源密集的代码段,则项目中不会出现严重的问题。 对于由只读上下文中的非只读结构类型创建的
受保护副本 ,情况也是如此。 存在该问题,但在普通应用程序中不太可能引起注意。
(*)已在.NET Core 2.1中修复,并且正如我在先前的出版物中提到的那样 ,现在可以使用针对较早版本的自配置HasFlag减轻后果。但是,我们今天要谈论的问题是特殊的。 如果未在结构中创建
Equals和
GetHashCode方法,则
System.ValueType的标准版本。 而且它们会大大降低最终应用程序的性能。
为什么标准版本比较慢?
CLR作者竭尽全力使Equals和GetHashCode的标准版本对值类型尽可能有效。 但是,有几种原因会导致这些方法失去用户版本的有效性,这些版本是手动为某种类型编写的(或由编译器生成的)。
1.配送包装转换。 CLR的设计方式是,每次对
System.ValueType或
System.Enum类型中定义的元素的调用都会触发包装转换(**)。
(**)如果该方法不支持JIT编译。 例如,在Core CLR 2.1中,JIT编译器识别Enum.HasFlag方法并生成不会开始包装的合适代码。2.标准版本的
GetHashCode方法中可能存在冲突。 在实现哈希函数时,我们面临一个难题:使哈希函数的分布良好或快速。 在某些情况下,您可以同时执行两种操作,但是在
ValueType.GetHashCode类型中,这通常很困难。
类型为struct的传统哈希函数“组合”所有字段的哈希码。 但是,在
ValueType方法中获取字段哈希码的唯一方法是使用反射。 这就是CLR作者决定为分发而牺牲速度的原因,而标准版本的
GetHashCode仅返回第一个非零字段的哈希码,并
使用类型标识符 (***)“
RegularGetValueTypeHashCode ”它 (有关更多详细信息,请参阅github上
RegularGetValueTypeHashCode中的RegularGetValueTypeHashCode)。
(***)根据CoreCLR存储库中的注释判断,将来情况可能会有所变化。 public readonly struct Location { public string Path { get; } public int Position { get; } public Location(string path, int position) => (Path, Position) = (path, position); } var hash1 = new Location(path: "", position: 42).GetHashCode(); var hash2 = new Location(path: "", position: 1).GetHashCode(); var hash3 = new Location(path: "1", position: 42).GetHashCode();
这是一个合理的算法,直到出现问题为止。 但是,如果您不走运,并且在大多数情况下struct类型的第一个字段的值相同,那么hash函数将始终产生相同的结果。 您可能已经猜到了,如果将这些实例保存在哈希集或哈希表中,则性能会下降。
3.基于反射的实现速度较低。 很低 如果正确使用,反射是一个强大的工具。 但是,如果您在占用大量资源的代码上运行它,后果将是可怕的。
让我们看看失败的哈希函数(可能由(2)和基于反射的实现导致)如何影响性能:
public readonly struct Location1 { public string Path { get; } public int Position { get; } public Location1(string path, int position) => (Path, Position) = (path, position); } public readonly struct Location2 {
Method | NumOfElements | Mean | Gen 0 | Allocated | -------------------------------- |------ |--------------:|--------:|----------:| Path_Position_DefaultEquality | 1 | 885.63 ns | 0.0286 | 92 B | Position_Path_DefaultEquality | 1 | 127.80 ns | 0.0050 | 16 B | Path_Position_OverridenEquality | 1 | 47.99 ns | - | 0 B | Path_Position_DefaultEquality | 10 | 6,214.02 ns | 0.2441 | 776 B | Position_Path_DefaultEquality | 10 | 130.04 ns | 0.0050 | 16 B | Path_Position_OverridenEquality | 10 | 47.67 ns | - | 0 B | Path_Position_DefaultEquality | 1000 | 589,014.52 ns | 23.4375 | 76025 B | Position_Path_DefaultEquality | 1000 | 133.74 ns | 0.0050 | 16 B | Path_Position_OverridenEquality | 1000 | 48.51 ns | - | 0 B |
如果第一个字段的值始终相同,则默认情况下,哈希函数对所有元素返回相等的值,并且哈希集通过O(N)插入和搜索操作有效地转换为链接列表。 填充集合的操作数变为O(N ^ 2)(其中N是每个插入的复杂度为O(N)的插入数)。 这意味着将其插入到1000个元素集中将产生对
ValueType.Equals近500,000次调用。 这是使用反射方法的后果!
如测试所示,如果您幸运并且结构的第一个元素是唯一的(对于
Position_Path_DefaultEquality ),则性能可以接受。 但是,如果不是这样,那么生产率将非常低。
真正的问题
我想现在您可以猜到我最近遇到了什么问题。 几周前,我收到一条错误消息:我正在处理的应用程序的运行时间从10秒增加到60秒。 幸运的是,该报告非常详细,并且包含Windows事件的痕迹,因此很快发现了问题点
ValueType.Equals加载了50秒。
快速查看代码后,很清楚问题出在哪里:
private readonly HashSet<(ErrorLocation, int)> _locationsWithHitCount; readonly struct ErrorLocation {
我使用了一个包含自定义结构类型和标准版本
Equals的元组。 不幸的是,它有一个可选的第一字段,几乎总是等于
String.equals 。 生产率一直很高,直到集合中的元素数量显着增加。 在短短的几分钟内,就初始化了一个包含成千上万个元素的集合。
默认的ValueType.Equals/GetHashCode实现是否总是运行缓慢?
ValueType.Equals和
ValueType.GetHashCode都有特殊的优化方法。 如果类型没有“指针”并且已正确包装(我将在稍后显示示例),则使用优化版本:对实例块执行
GetHashCode迭代,使用4字节的XOR,
Equals方法使用
memcmp比较两个实例。
该检查本身在
ValueTypeHelper::CanCompareBits执行,从
ValueType.Equals的迭代和
ValueType.Equals的迭代中调用。
但是优化是一件非常隐蔽的事情。
首先,很难理解它何时打开。 即使对代码进行很小的更改也可以将其打开和关闭:
public struct Case1 {
有关内存结构的更多信息,请参见我的博客
“托管对象的内部元素,第4部分 。
字段结构” 。
其次,比较内存并不一定会得到正确的结果。 这是一个简单的示例:
public struct MyDouble { public double Value { get; } public MyDouble(double value) => Value = value; } double d1 = -0.0; double d2 = +0.0;
-0,0和
+0,0相等,但是具有不同的二进制表示形式。 这意味着
Double.Equals为true,而
MyDouble.Equals为false。 在大多数情况下,差异并不大,但请想象一下您将花费多少小时来解决由该差异引起的问题。
如何避免类似的问题?
您能问我在现实情况下上述情况如何发生吗? 在结构类型中运行
Equals和
GetHashCode方法的一种明显方法是使用FxCop
CA1815规则 。 但是有一个问题:这太严格了。
对于性能至关重要的应用程序可以具有数百个结构类型,这些结构类型不一定在哈希集或字典中使用。 因此,应用程序开发人员可以禁用该规则,如果结构类型使用修改后的功能,则将导致不愉快的后果。
一种更正确的方法是,如果将具有(在应用程序或第三方库中定义的)元素默认值相同的“不适当”类型结构存储在哈希集中,则警告开发人员。 当然,我谈论的是
ErrorProne.NET以及我遇到此问题后在其中添加的规则:

ErrorProne.NET版本并不完美,如果在构造函数中使用了自定义的相等解析器,则会“怪罪”正确的代码:
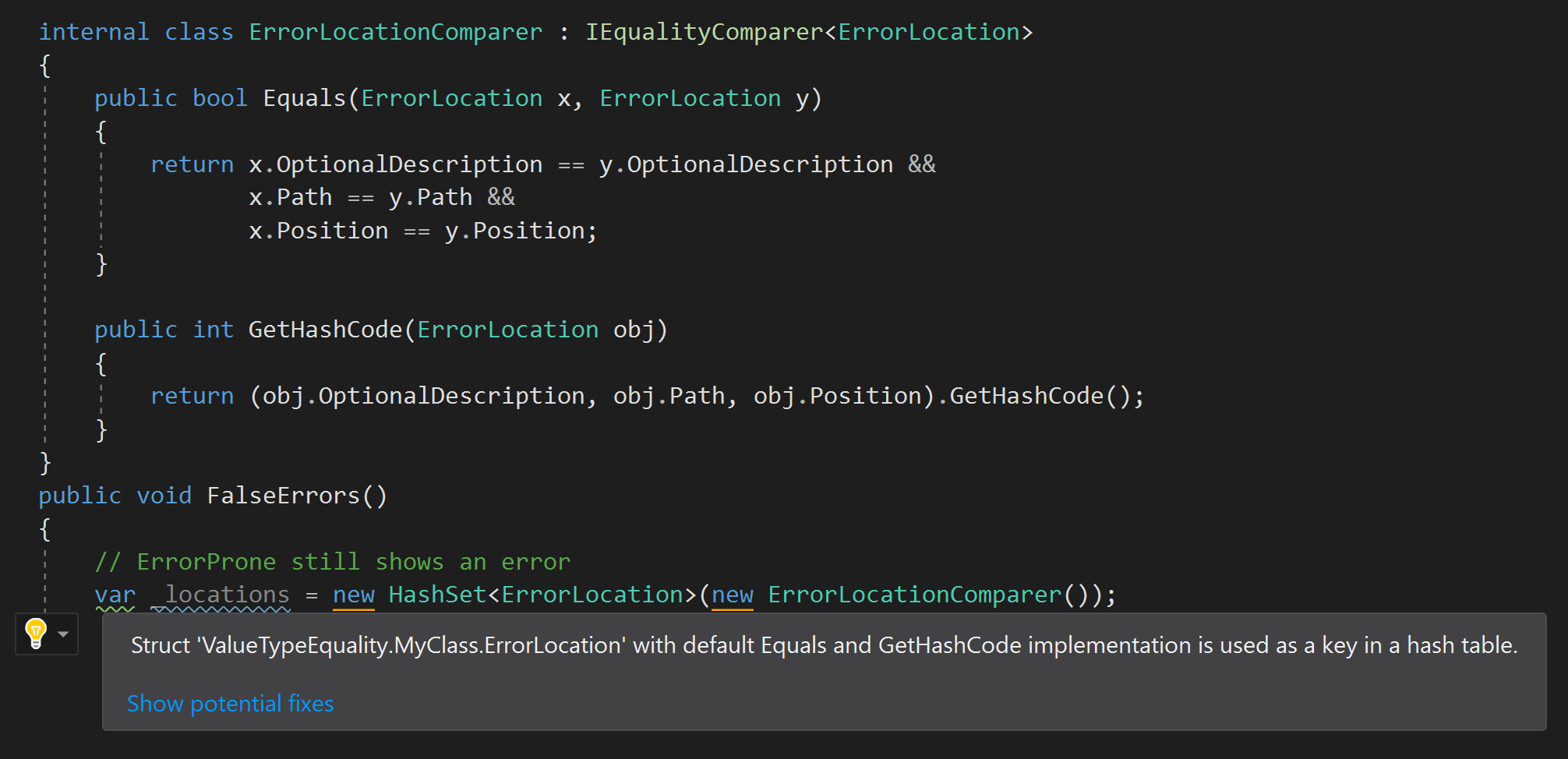
但我仍然认为,如果在生成时默认不使用具有相等元素的结构,则值得警告。 例如,当我检查规则时,我意识到mscorlib中定义的
System.Collections.Generic.KeyValuePair <TKey, TValue>结构不会覆盖
Equals和
GetHashCode 。 今天不太可能有人会定义像
HashSet <KeyValuePair<string, int>>这样的变量,但是我相信,即使BCL也会违反规则。 因此,在为时已晚之前发现它很有用。
结论
- 实现结构类型的默认相等性可能会对您的应用程序造成严重后果。 这是一个实际的问题,而不是理论问题。
- 值类型的默认相等元素基于反射。
- 如果许多实例的第一个字段具有相同的值,则由标准版本的
GetHashCode执行的分发将非常糟糕。 - 标准
Equals和GetHashCode方法有优化的版本,但您不应依赖它们,因为即使很小的代码更改也可以将其关闭。 - 使用FxCop规则确保每个结构类型都覆盖均等元素。 但是,如果将“不合适的”结构存储在哈希集或哈希表中,则最好防止分析器出现问题。
其他资源