我如何通过将天气数据添加到其作者居住的地方,并用几行代码来打印来自Twitter的连续消息流? 以及如何限制对天气提供者的请求速度,以使它们不会将我们列入黑名单?
今天,我们将告诉您如何做,但是首先,我们将了解Akka Streams技术,该技术使处理实时数据流的过程与使用LINQ表达式的程序员一样容易,而无需实现单个actor或Reactive Streams接口。
本文基于我们12月的DotNext 2017莫斯科会议
上Vagif Abilov的
报告的笔录 。
我叫Vagif,我在挪威Miles公司工作。 今天我们将讨论Akka Streams库。
Akka和Reactive Streams是相当狭窄的集合的交集,人们可能会觉得这是一个利基市场,您需要具备一些丰富的知识才能进入,但恰恰相反。 本文旨在说明通过使用Akka Streams,您可以避免使用Reactive Streams和Akka.NET时所需的低级编程。 展望未来,我可以立即说:如果在我们使用Akka的项目的开始阶段,我们知道Akka Streams的存在,我们会写很多不同的东西,这样可以节省时间和代码。
“也许您能做的最糟糕的事情就是让没有痛苦的人服用阿司匹林。”
马克斯·克雷明斯基
“关门,头痛和智力需求”
在我们探讨技术细节之前,请先了解一下您通往Akka Streams的道路可能是什么,以及如何带领您到达那里。 有一天,我遇到了麦克斯·克雷敏斯基(Max Kreminski)的博客,他在博客中向程序员提出了这样一个哲学问题:程序员不可能或为什么无法解释什么是单子。 他是这样解释的:人们经常会立即去了解技术细节,解释函数式编程的精美程度以及monad的含义,而不必费神去问程序员为什么根本需要它。 打个比方,这就像试图出售阿司匹林而不必费心去寻找患者是否疼痛。
使用这个比喻,我想问一个问题:如果Akka Streams是阿司匹林,那将导致您的痛苦是什么?
数据流
首先,让我们谈谈数据流。 流可以非常简单,线性。
这里我们有一个特定的数据使用者(视频中的兔子)。 它以适合的速度消耗数据。 这是使用者与流的理想交互:它建立了带宽,而数据却悄悄地流向了它。 这个简单的数据流可以是无限的,也可以结束。
但是流程可能更复杂。 如果您并排种植多只兔子,我们将已经实现流程并行化。 Reactive Streams试图解决的问题恰恰是我们如何在更概念性的水平上与流进行通信,即不管我们是否只是在谈论某种温度传感器测量,线性测量都在其中进行。 ,或者我们对通过RabbitMQ队列进入系统并存储在系统日志中的数千个温度传感器进行连续测量。 以上所有内容都可以视为一个复合流。 如果走得更远,那么自动化的生产管理(例如,通过一些在线商店)也可以简化为数据流,并且无论如何复杂,我们都可以谈论计划这样的流,这将是很棒的。

对于现代项目,线程支持不是很好。 如果我没记错的话,您在图片中看到的推文Aaron Stannard想要获取一个包含CSV的数千兆字节文件的流,即 文字,事实证明,如果没有大量其他操作,您将无法立即采取和使用任何内容。 但是他根本无法获得CSV值流,这让他感到难过。 解决方案很少(除了一些特殊区域),许多方法都是通过旧方法实现的,当我们打开所有这些,开始读取,缓冲时,在最坏的情况下,我们会得到记事本之类的东西,它表示文件太大。
从概念上讲,我们都致力于处理数据流,并且Akka Streams将在以下情况下为您提供帮助:
- 您熟悉Akka,但想保留与编写actor代码及其协调相关的详细信息;
- 您对反应式流很熟悉,并希望使用其规范的现成实现。
- 阶段的Akka Streams块元素适合于对过程进行建模;
- 您想利用Akka Streams的反压(backpressure)来管理和动态优化工作流程的吞吐量阶段。
从演员到Akka Streams

第一种方法是从演员到Akka Streams,这是我的方法。
图片显示了为什么我们开始使用actor模型。 流程的手动控制,共享状态让我们筋疲力尽,仅此而已。 每个使用大型系统,使用多线程的人都知道需要花费多少时间,并且犯错很容易,这对于整个过程可能是致命的。 这导致我们成为演员的榜样。 我们不后悔做出的选择,但是,当然,当您开始更多的工作和编程时,并不是最初的热情让位于其他地方,而是您开始意识到可以更有效地完成某些事情。
“默认情况下,他们的消息的接收者以参与者代码输入。 如果我创建一个将消息发送给演员B的演员A,并且您想用演员C替换接收者,那么在一般情况下,这对您不起作用”
诺埃尔·韦尔奇(underscore.io)
演员批评没有作曲。 Underscore的开发人员之一Noel Welch就是第一个在他的博客上写此内容的人。 他注意到演员系统看起来像这样:

如果您不使用其他任何东西(例如依赖项注入),则将其接收者的地址缝到actor中。

当他们开始相互发送消息时,您需要事先设置好所有这些,以便对参与者进行编程。 无需任何其他技巧,就可以获得这样的刚性系统。
Akka的一位开发人员Roland Kuhn
解释了布局不佳通常是什么意思。 actor方法基于tell方法,即单向消息:它是void类型,即不返回任何内容(或单位,具体取决于语言)。 因此,不可能从一连串的参与者构建对过程的描述。 所以您发送告诉,然后呢? 停下 我们变得空虚。 您可以将其与LINQ表达式进行比较,例如LINQ表达式,其中表达式的每个元素都返回IQueryable,IEnumerable,所有这些都可以轻松编译。 演员们不给这样的机会。 同时,罗兰·库恩(Roland Kuhn)反对这样一个事实,他们说,它们原则上不构成,说实际上,它们是以其他方式进行编译的,与人类社会适合布局的意义相同。 这听起来像是一个哲学论点,但是如果您考虑一下,这个类比是有道理的-是的,参与者之间互相发送单向消息,但我们也互相交流,发出单向消息,但同时我们进行了非常有效的交互,即创建了复杂的系统。 但是,仍然存在对演员的这种批评。
public class SampleActor : ReceiveActor { public SampleActor() { Idle(); } protected override void PreStart() { } private void Idle() { Receive<Job>(job => ); } private void Working() { Receive<Cancel>(job => ); } }
另外,如果您使用C#工作,则actor的实现至少需要编写一个类,如果您使用F#工作,则至少需要编写一个函数。 在上面的示例中-样板代码,无论如何都必须编写。 尽管它不是很大,但是您总是必须在此较低级别上写入一定数量的行。 这里几乎所有的代码都是一种仪式。 当演员直接收到一条消息时,这里完全没有显示。 所有这些都需要编写。 当然,这不是很多,但这证明我们与参与者在低水平上合作,从而创造了这种无效的方法。
如果我们可以进入另一个更高的层次,问我们自己对流程建模的问题,该流程包括处理来自混合,转换和转移的各种来源的数据?
var results = db.Companies .Join(db.People, c => c.CompanyID, p => p.PersonID, (c, p) => new { c, p }) .Where(z => zcCreated >= fromDate) .OrderByDescending(z => zcCreated) .Select(z => zp) .ToList();
这种方法的类似物可以是我们十年来一直习惯使用LINQ的方法。 我们并不奇怪联接是如何工作的。 我们知道有这样一个LINQ提供程序将为我们完成所有这些工作,并且我们对实现请求有更高的兴趣。 我们通常可以在这里混合数据库,我们可以发送分布式请求。 如果您可以用这种方式描述流程怎么办?
HttpGet pageUrl |> fun s -> Regex.Replace(s, "[^A-Za-z']", " ") |> fun s -> Regex.Split(s, " +") |> Set.ofArray |> Set.filter (fun word -> not (Spellcheck word)) |> Set.iter (fun word -> printfn " %s" word)
(来源)或者,例如,功能转换。 许多人喜欢函数式编程的地方是,您可以通过一系列转换来传递数据,并且无论使用哪种语言编写代码,都可以获得相当清晰的紧凑代码。 它很容易阅读。 图片中的代码是用F#专门编写的,但一般来说,大概每个人都可以理解这里发生的事情。
val in = Source(1 to 10) val out = Sink.ignore val bcast = builder.add(Broadcast[Int](2)) val merge = builder.add(Merge[Int](2)) val f1,f2,f3,f4 = Flow[Int].map(_ + 10) source ~> f1 ~> bcast ~> f2 ~> merge ~> f3 ~> sink bcast ~> f4 ~> merge ~>
(来源)那呢? 在上面的示例中,我们有一个源数据源,它由1到10的整数组成。这就是所谓的图形DSL(特定于域的语言)。 上例中的领域语言元素是单向箭头符号-这些是语言工具定义的其他运算符,这些工具以图形方式显示流的方向。 我们对Source进行了一系列转换-为了便于演示,它们都只增加了10。 接下来是广播:我们将频道相乘,即每个数字进入两个频道。 然后,我们再次添加10,混合我们的数据流,获得一个新的流,再添加10,所有这些都进入我们的数据流,在此过程中什么也没有发生。 这是用Scala编写的真实代码,Scala是Akka Streams的一部分,并以此语言实现。 也就是说,您可以指定数据转换的阶段,指示如何处理它们,指定源,库存,一些检查点,然后使用图形DSL形成这样的图形。 这是单个程序的所有代码。 几行代码显示了过程中发生的事情。
让我们忘记如何为单个角色编写定义代码,而学习如何在自己内部创建和连接所需角色的高级布局原语。 当我们运行这样的图时,提供Akka Streams的系统将自己创建所需的actor,将所有这些数据发送到那里,按需要进行处理,最后将其提供给最终收件人。
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString));
上面的示例显示了在C#中的外观。 最简单的方法:我们有一个数据源-这些是1到1000之间的数字(如您所见,在Akka流中,任何IEnumerable都可以成为数据流的源,这非常方便)。 我们进行一些简单的计算,例如,乘以2,然后在数据流上将所有这些都显示在屏幕上。
var graph = GraphDsl.Create(builder => { var bcast = builder.Add(new Broadcast<int>(2)); var merge = builder.Add(new Merge<int, int>(2)); var count = Flow.FromFunction(new Func<int, int>(x => 1)); var sum = Flow.Create<int>().Sum((x, y) => x + y); builder.From(bcast.Out(0)).To(merge.In(0)); builder.From(bcast.Out(1)).Via(count).Via(sum).To(merge.In(1)); return new FlowShape<int, int>(bcast.In, merge.Out); });
上面示例中显示的内容称为“ C#中的图形DSL”。 实际上,这里没有图形,它是Scala的移植端口,但是在C#中,无法以这种方式定义运算符,因此看起来有些麻烦,但仍然足够紧凑,可以理解这里发生的事情。 因此,我们正在从不同的组件创建一个特定的图(有不同类型的图,在这里称为FlowShape),那里有一个数据源并且有一些转换。 我们将数据发送到一个通道,在该通道中我们生成计数(即要传输的数据元素的数量),在另一个通道中,我们生成总和,然后将其全部混合。 接下来,我们将看到更多有趣的示例,而不仅仅是处理整数。
如果您有使用actor模型的经验,并且已经考虑过是否要手动编写每个角色,甚至是最简单的actor,这也是通向Akka Streams的第一条路径。 Akka流进入的第二种方式是通过反应流。
从反应流到Akka流
什么是
反应流 ? 这是一项联合倡议,旨在开发用于数据流异步处理的标准。 它定义了最小的接口,方法和协议集,这些接口,方法和协议描述了实现目标所必需的操作和实体-具有无阻塞背压(back pressure)的实时实时异步处理数据。 它允许使用不同的编程语言进行各种实现。
反应性流使您可以处理序列中可能不受限制的元素,并在不阻塞背压的情况下在组件之间异步传输元素。
创建Reactive Streams的发起者列表非常令人印象深刻:这是Netflix,Oracle和Twitter。
该规范非常简单,可以使使用不同语言和平台的实现尽可能地易于访问。 Reactive Streams API的主要组件:
- 发行人
- 订户
- 订阅方式
- 处理器
本质上,此规范并不意味着您将手动开始实现这些接口。 据了解,有一些图书馆开发人员会为您做这件事。 Akka Streams是此规范的实现之一。
public interface IPublisher<out T> { void Subscribe(ISubscriber<T> subscriber); } public interface ISubscriber<in T> { void OnSubscribe(ISubscription subscription); void OnNext(T element); void OnError(Exception cause); void OnComplete(); }
从示例中可以看到,这些接口实际上非常简单:例如,Publisher仅包含一种方法-“订阅”。 订户,订户,仅包含对该事件的一些反应。
public interface ISubscription { void Request(long n); void Cancel(); } public interface IProcessor<in T1, out T2> : ISubscriber<T1>, IPublisher<T2> { }
最后,订阅包含两种方法-“开始”和“拒绝”。 处理器根本不定义任何新方法;它结合了发布者和订阅者。
是什么使反应式流与其他流实现不同? 反应性流结合了推和拉模型。 对于支持,这是最有效的性能方案。 假设您的数据订阅者速度较慢。 在这种情况下,对他的推送可能是致命的:如果您向他发送大量数据,他将无法处理它们。 最好使用pull,以便订阅者自己从发布者中提取数据。 但是,如果发布者的速度很慢,事实证明订阅者一直被阻止,一直等待。 中间的解决方案可能是配置:我们有一个配置文件,可以在其中确定哪个更快。 如果他们的速度改变了?
因此,最优雅的实现是我们可以动态更改推拉模型的实现。
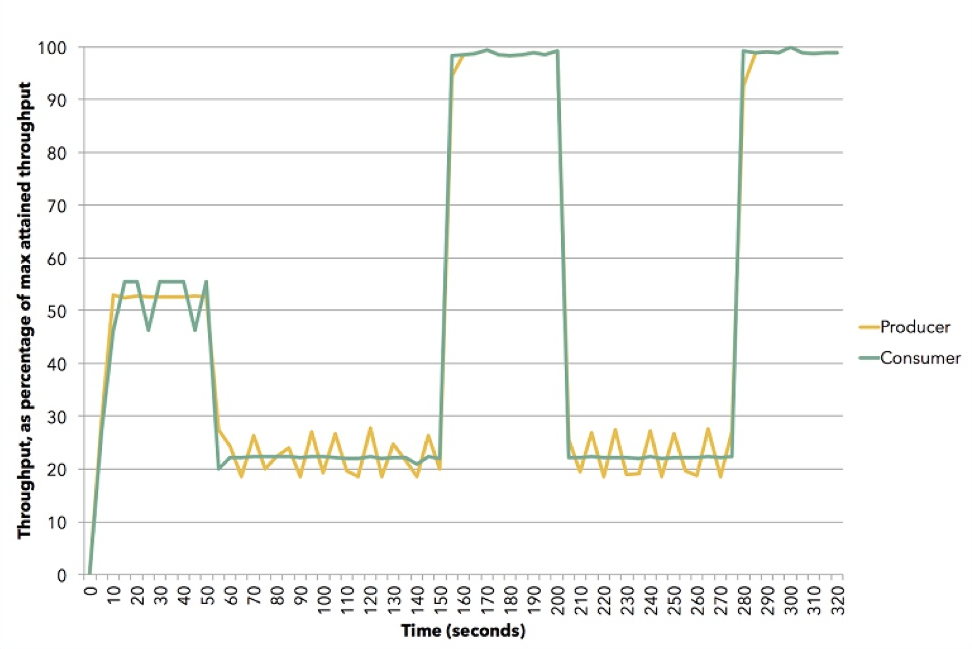 (来源(Apache Flink))
(来源(Apache Flink))该图显示了这种情况如何发生。 本演示使用Apache Flink。 Yellow是出版商,数据生产者,他的能力大约是他的50%。 订户尝试选择最佳策略-事实证明它是推式的。 然后,我们将订户重置为大约20%的速度,然后他切换为拉动。 然后我们进行100%处理,再返回20%进行处理,以此类推。所有这些都是动态发生的,您无需停止服务,无需在配置中输入任何内容。 这说明了反压在Akka Streams中如何工作。
Akka流原则
当然,如果没有易于使用的内置块,Akka Streams将不会受到欢迎。 有很多。 它们分为三个主要组:
- 数据源(源)-具有一个输出的处理阶段。
- 接收器是一个单项处理步骤。
- 检查点(流程)-具有一个输入和一个输出的处理阶段。 功能转换在此处进行,而不一定在内存中进行:例如,它可以是对Web服务,并行性的某些要素,多线程的调用。
在这三种类型中,可以形成图。 这些已经是更复杂的处理阶段,它们是根据源,排放点和检查点构建的。 但是,并非每个图形都可以执行:如果其中有孔,即打开输入和输出,则该图形不会运行。
图是可运行图,如果它是闭合的,即每个输入都有一个输出:如果输入了数据,则它肯定已经到了某个地方。

Akka Streams具有内置源:在图片中,您可以看到其中的多少。 它们的名称是一对一的,除了一些特定于.NET的有用资源之外,它们都反映了Scala或JVM的功能。 前两个(FromEnumerator和From)是最重要的一些:任何编号,任何可枚举都可以变成流源。

有内置的排水口:其中一些类似于LINQ方法,例如First,Last,FirstOrDefault。 当然,获得的所有内容都可以转储到文件,流中,而不是Akka Streams中,而是.NET流中。 同样,如果您的系统中有任何参与者,则可以在系统的输入和输出处使用它们,也就是说,如果您愿意,可以将其嵌入到最终系统中。

并且有大量的内置检查点,也许更让人联想到LINQ,因为这里有Select,SelectMany和GroupBy,也就是我们在LINQ中经常使用的所有检查点。
例如,Scala中的Select称为SelectAsync:它足够强大,因为它将并行化级别作为参数之一。 也就是说,例如,您可以指示Select将数据并行发送到十个线程中的某个Web服务,然后将它们全部收集并传递。 实际上,您可以使用一行代码来确定检查点的缩放程度。
流声明是它的执行计划,也就是说,图,甚至是运行图,都不能像这样执行-它需要实现。 必须有一个实例化的系统,一个参与者系统,您必须给它一个流,这个执行计划,然后它将被执行。 此外,它在运行时经过了高度优化,就像将LINQ表达式发送到数据库时一样:提供程序可以优化SQL以获得更有效的数据输出,本质上是用另一个查询命令来代替。 与Akka Streams相同:从2.0版开始,您可以设置一定数量的检查点,系统会理解其中的一些检查点可以组合在一起,以便由一个参与者执行(操作员融合)。 通常,检查点保持处理元素的顺序。
var results = db.Companies .Join(db.People, c => c.CompanyID, p => p.PersonID, (c, p) => new { c, p }) .Where(z => zcCreated >= fromDate) .OrderByDescending(z => zcCreated) .Select(z => zp) .ToList();
在上面的示例中,可以将流实现与LINQ表达式中的最后一个ToList元素进行比较。 如果我们不编写ToList,则将得到一个未实现的LINQ表达式,该表达式不会导致将数据传输到SQL Server或Oracle,因为大多数LINQ提供程序都支持所谓的延迟查询执行(延迟查询执行),t即,仅在给出命令以给出某些结果时才执行该请求。 根据要求的内容(列表或第一个结果),将组建最有效的团队。 当我们说ToList时,我们因此要求LINQ提供者给我们完成的结果。
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString));
Akka Streams的工作方式相同。 图中是我们启动的图形,它由检查点和径流的源组成,现在我们要运行它。
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString)); var system = ActorSystem.Create("MyActorSystem"); using (var materializer = ActorMaterializer.Create(system)) { await runnable.Run(materializer); }
为了做到这一点,我们需要创建一个参与者系统,其中有一个实体化器,将我们的图形传递给他,然后他将执行它。 如果我们重新创建它,它将再次执行它,并且可以获得其他结果。
除了流程的实体化之外,在谈论Akka Streams的实质部分时,值得一提的是实体化值。
var output = new List<int>(); var source1 = Source.From(Enumerable.Range(1, 1000)); var sink1 = Sink.ForEach<int>(output.Add); IRunnableGraph<NotUsed> runnable1 = source1.To(sink1); var source2 = Source.From(Enumerable.Range(1, 1000)); var sink2 = Sink.Sum<int>((x,y) => x + y); IRunnableGraph<Task<int>> runnable2 = source2.ToMaterialized(sink2, Keep.Right);
当我们有一个从源头经过检查点到流失点的流时,如果我们不请求任何中间值,则它们对我们不可用,因为它将以最有效的方式执行。 就像一个黑匣子。 但是,对于我们来说,提取一些中间值可能是有趣的,因为在左侧的每个点上都有一些值输入,在右侧有其他值出现,并且您可以指定一个图表来表示您感兴趣的内容。 在上面的示例中,在其中显示了NotUsed的磨合图,即没有实现的值引起我们的兴趣。 下面,我们在径流的右侧(即,在完成所有转换之后)需要给出物化值的指示来创建它。 我们得到图Task-一个任务,完成后我们得到一个整数,即该图末尾发生的情况。 您可以在每个段落中指出您需要某种具体化的值,所有这些都将逐步收集。
为了将数据传输到Akka Streams流中或将其移出那里,当然,需要与外界进行某种交互。 嵌入式源阶段包含各种反应性数据流:
- Source.FromEnumerator和Source.From允许您从实现IEnumerable的任何源传输数据;
- 只要Unfold和UnfoldAsync返回非零值,它就会生成函数计算的结果。
- FromInputStream转换一个Stream;
- FromFile将文件的内容解析为响应流;
- ActorPublisher转换actor消息。
就像我已经说过的那样,对于.NET开发人员来说,使用Enumerator或IEnumerable效率很高,但是有时访问数据太原始,效率太低。 包含大量数据的更复杂的源需要特殊的连接器。 这样的连接器被写入。 有一个开源项目Alpakka,最初出现在Scala中,现在在.NET中。 此外,Akka具有所谓的持久性参与者,并且它们具有自己的可用流(例如,Akka Persistence Query构成了Akka Event Journal的内容流)。

如果您使用Scala,那么最简单的方法对您而言:连接器数量众多,您一定会找到自己喜欢的东西。 作为信息,Kafka是所谓的反应式Kafka,而不是Kafka Streams。 据我所知,Kafka Streams不支持背压。 Reactive Kafka是Kafka的流实现,支持Reactive Streams。
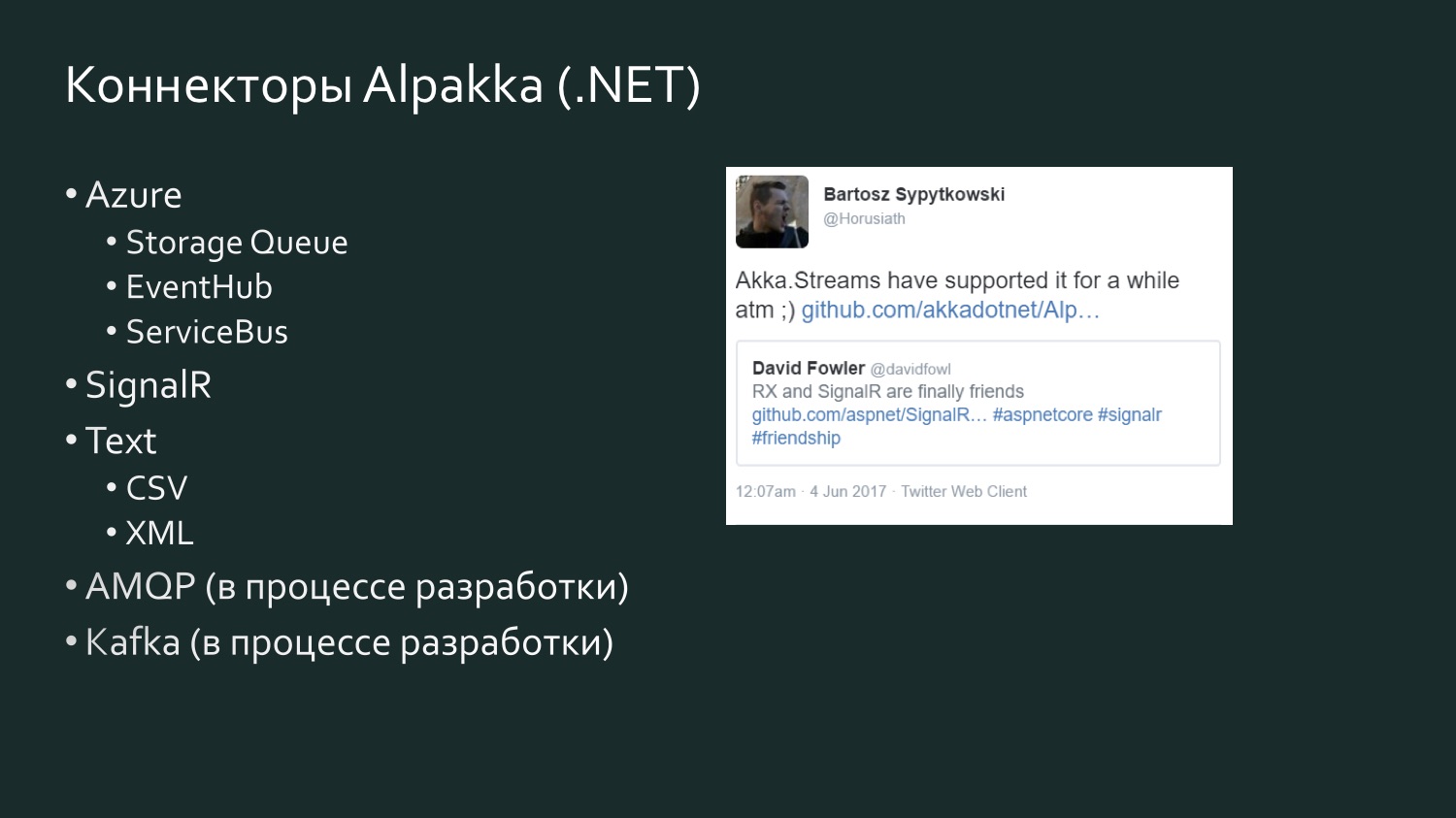
Alpakka .NET连接器的列表较为适中,但已得到补充,并且存在竞争元素。 微软的大卫·福勒(David Fowler)发表了半年的推文,他说SignalR现在可以与Reactive Extensions交换数据了,一位Akka开发人员回答说,它实际上已经存在于Akka Streams中一段时间了。 Akka支持Microsoft Azure提供的各种服务。 CSV是Aaron Stannard沮丧的结果,因为他发现CSV没有好的流:现在Akka拥有自己的CSV XML流。 有AMQP(实际上是RabbitMQ),正在开发中,但是可以使用,并且可以使用。 Kafka也正在开发中。 此列表将继续扩大。
关于替代方案的一些话,因为如果您使用数据流,那么Akka Streams当然不是处理这些流的唯一方法。 在您的项目中,最有可能选择如何实现线程将取决于可能成为关键的许多其他因素。 例如,如果您与Microsoft Azure一起工作很多,并且Orleans通过对虚拟角色(或称其为Grain)的支持而有机地融入到项目的需求中,那么他们将拥有自己的不符合Reactive Streams规范的实现-Orleans Streams,它对您来说是最接近的,因此您应该注意它。 如果您经常使用TPL,则有TPL DataFlow-这可能是最类似于Akka Streams的类比:它还具有用于构成数据流的原语,以及缓冲和带宽限制工具(BoundedCapacity,MaxMessagePerTask)。 如果演员模型的想法很接近您,那么Akka Streams可以解决此问题并节省大量时间,而无需手动编写每个演员。
实施示例:事件日志流
让我们看几个实现示例。
第一个示例不是直接实现流,而是如何使用流。这是我们对Akka Streams的首次体验,当时我们发现实际上我们可以订阅一些可以简化很多工作的流。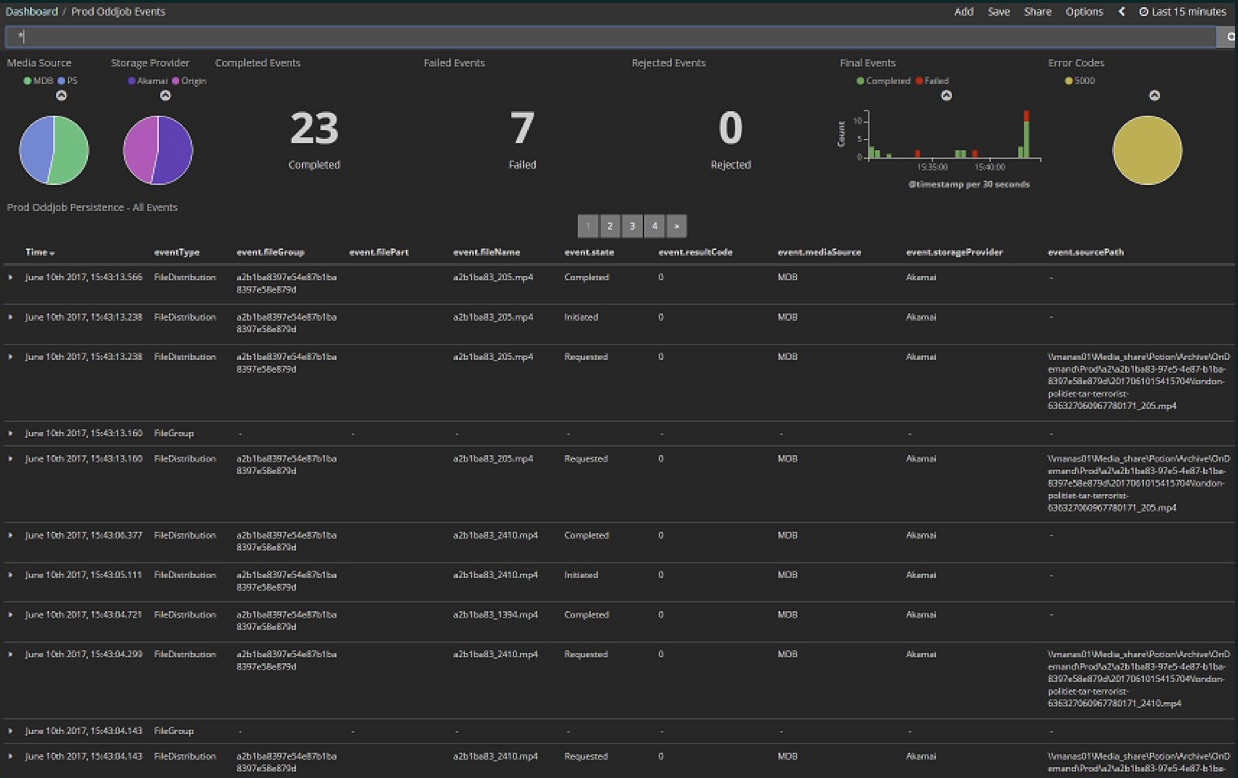 我们将各种媒体文件上传到云中。这是该项目的早期阶段:在过去15分钟内,这里有23个文件,其中有7个错误。现在实际上几乎没有错误,文件数量也大得多-每隔几分钟就会有数百个文件通过。所有这些都包含在Kibana仪表板中。
我们将各种媒体文件上传到云中。这是该项目的早期阶段:在过去15分钟内,这里有23个文件,其中有7个错误。现在实际上几乎没有错误,文件数量也大得多-每隔几分钟就会有数百个文件通过。所有这些都包含在Kibana仪表板中。Kibana Elasticsearch , Elasticsearch , , , , . , , , . . . (event journal) Akka, Microsoft SQL Server. , .
CREATE TABLE EventJournal ( Ordering BIGINT IDENTITY(1,1) PRIMARY KEY NOT NULL, PersistenceID NVARCHAR(255) NOT NULL, SequenceNr BIGINT NOT NULL, Timestamp BIGINT NOT NULL, IsDeleted BIT NOT NULL, Manifest NVARCHAR(500) NOT NULL, Payload VARBINARY(MAX) NOT NULL, Tags NVARCHAR(100) NULL CONSTRAINT QU_EventJournal UNIQUE (PersistenceID, SequenceNr) )
, , , , SQL Server, eventstore Akka, eventJournal. eventstore.
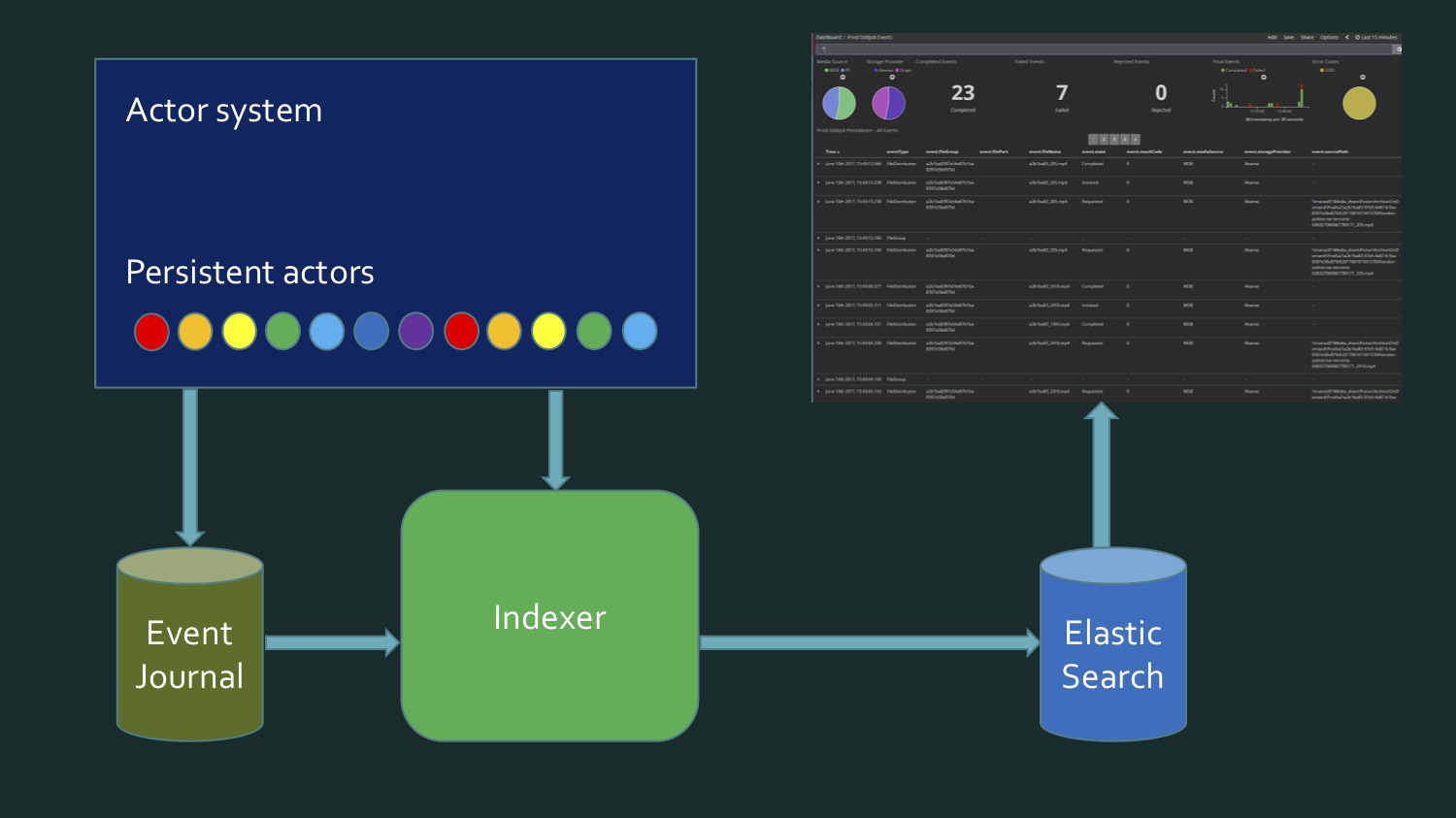
, . , , , , - : , . , . . . - . , . , . , Akka persistence query.
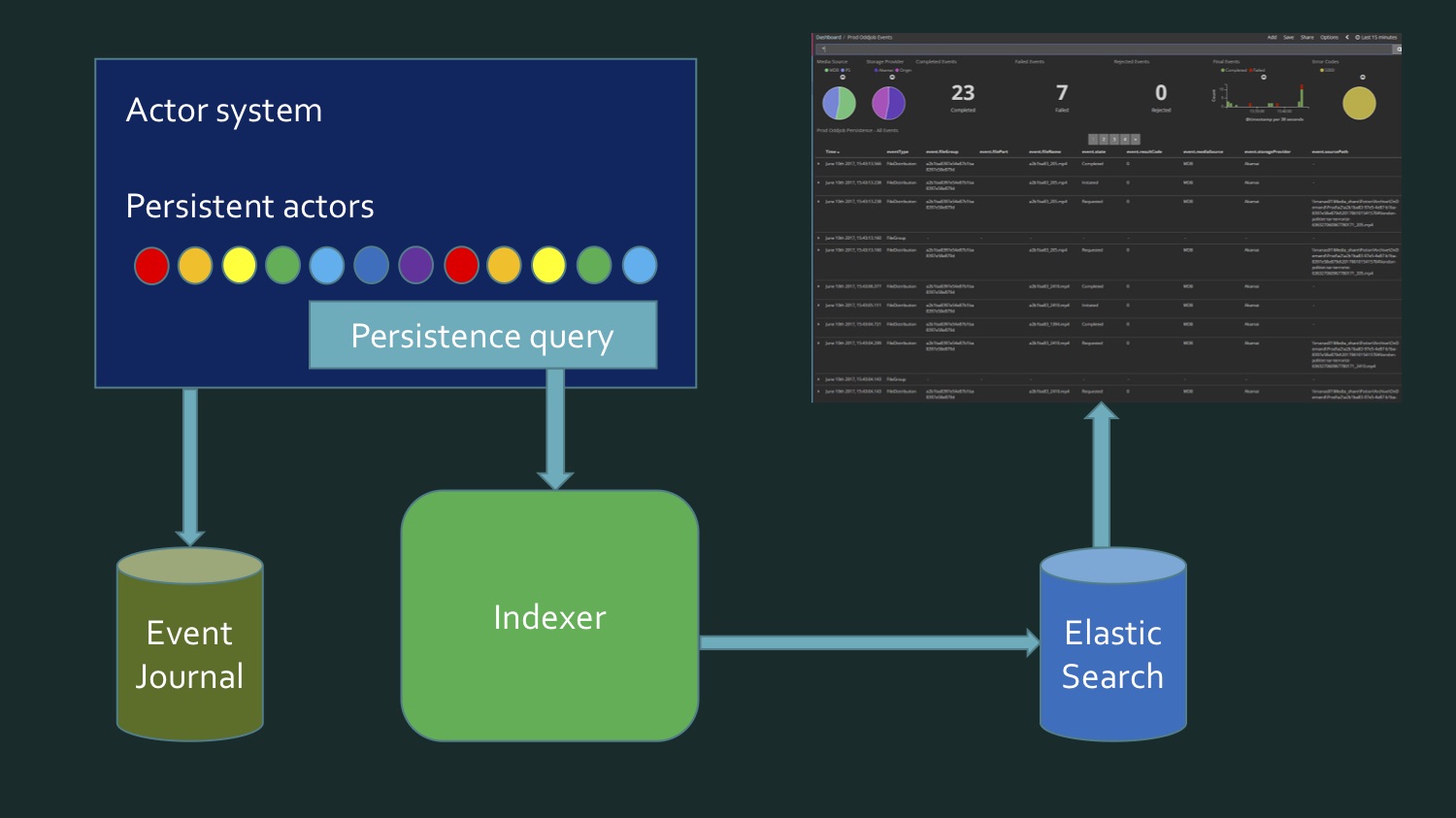
, , .
(persistence queries):
- AllPersistencelds
- CurrentPersistencelds
- EventsByPersistenceld
- CurrentEventsByPersistenceld
- EventsByTag
- CurrentEventsByTag
, , , Current — , . — . EventsByTag.
let system = mailbox.Context.System let queries = PersistenceQuery.Get(system) .ReadJournalFor<SqlReadJournal>(SqlReadJournal.Identifier) let mat = ActorMaterializer.Create(system) let offset = getCurrentOffset client config let ks = KillSwitches.Shared "persistence-elastic" let task = queries.EventsByTag(PersistenceUtils.anyEventTag, offset) .Select(fun e -> ElasticTypes.EventEnvelope.FromAkka e) .GroupedWithin(config.BatchSize, config.BatchTimeout) .Via(ks.Flow()) .RunForeach((fun batch -> processItems client batch), mat) .ContinueWith(handleStreamError mailbox, TaskContinuationOptions.OnlyOnFaulted) |> Async.AwaitTaskVoid
, . F#, C# . EventsByTag, Akka Streams, , Elasticsearch. . . - , , , — . .
. , , , , Twitter , — , , , . , Akka Streams.
:
Akka Scala, Akka.NET, , , , , . . - .
Tweetinvi — , Twitter, . Reactive Streams, . . , , , , - Akka, , .

, , . . Broadcast-. , , . : , , , , .
GitHub-,
AkkaStreamsDemo . (
).
让我们从一个简单的开始。 Twitter: Program.cs
var useCachedTweets = false
万一我被Twitter禁止,我已经缓存了推文,它们的速度更快。首先,我们创建一些RunnableGraph。 public static IRunnableGraph<IActorRef> CreateRunnableGraph() { var tweetSource = Source.ActorRef<ITweet>(100, OverflowStrategy.DropHead); var formatFlow = Flow.Create<ITweet>().Select(Utils.FormatTweet); var writeSink = Sink.ForEach<string>(Console.WriteLine); return tweetSource.Via(formatFlow).To(writeSink); }
(来源)我们这里有来自演员的推文来源。我将向您展示如何将这些tweet拉到那里,对其进行格式化(tweet格式仅向作者发送tweet),然后将其写在屏幕上。StartTweetStream-在这里我们将使用Tweetinvi库。 public static void StartTweetStream(IActorRef actor) { var stream = Stream.CreateSampleStream(); stream.TweetReceived += (_, arg) => { arg.Tweet.Text = arg.Tweet.Text.Replace("\r", " ").Replace("\n", " "); var json = JsonConvert.SerializeObject(arg.Tweet); File.AppendAllText("tweets.txt", $"{json}\r\n"); actor.Tell(arg.Tweet); }; stream.StartStream(); }
(
)
CreateSampleStream , . , , , : « ». IEnumerable, .
TweetEnumerator : , Current, MoveNext, Reset, Dispose, . , . , . .
现在,我们将useCachedTweets的值更改为true,这里开始复杂化。 CashedTweets是同一件事,只有我那里已经选择,保存了50,000条推文的文件,我们将使用它们。我试图选择包含我们作者所需地理坐标数据的推文。下一步是我们要并行化推文。执行后,我们将首先在列表中包含推文的所有者,然后是坐标。TweetsWithBroadcast: var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates)) .Via(formatCoordinates) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); });
(
)
Scala, , DSL. Broadcast — out(0), out(1) — CreatedBy, , . .
— . .
var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy) .Throttle(10, TimeSpan.FromSeconds(1), 1, ThrottleMode.Shaping)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates) .Buffer(10, OverflowStrategy.DropNew) .Throttle(1, TimeSpan.FromSeconds(1), 10, ThrottleMode.Shaping)) .Via(formatCoordinates) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); });}
(
)
10 , 10. , , , . , , Akka Streams Reactive Streams: . , , , , - . , , , . , . , , . Buffer(10, OverFlowStrategy.DropHead). , . 10 , . , , - , — - , , , , . . . , .
var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy) .Throttle(10, TimeSpan.FromSeconds(1), 1, ThrottleMode.Shaping)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates) .Buffer(10, OverflowStrategy.DropNew) .Throttle(1, TimeSpan.FromSeconds(1), 10, ThrottleMode.Shaping)) .Via(Flow.Create<ICoordinates>().SelectAsync(5, Utils.GetWeatherAsync)) .Via(formatTemperature) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); });
(
)
, SelectAsync, . , , 5: , 5 , , . , , .
public static async Task<decimal> GetWeatherAsync(ICoordinates coordinates) { var httpClient = new HttpClient(); var requestUrl = $"http://api.met.no/weatherapi/locationforecast/1.9/?lat={coordinates.Latitude};lon={coordinates.Latitude}"; var result = await httpClient.GetStringAsync(requestUrl); var doc = XDocument.Parse(result); var temp = doc.Root.Descendants("temperature").First().Attribute("value").Value; return decimal.Parse(temp); }
(
)
. -, , - , HttpClient , XML, , .
,
, , . 10 10 , , .
, — , . , Akka Streams, , . , , .
, , , Akka Streams, . , , Akka Streams, C# , , , , .
 阅读本文后,我希望您对Akka Streams有什么想法?在2017年莫斯科DotNext会议上,我正在听Alex Thyssen的演讲
阅读本文后,我希望您对Akka Streams有什么想法?在2017年莫斯科DotNext会议上,我正在听Alex Thyssen的演讲 Azure Functions. - , deployment, , ( - , , ), . , , , . , , Akka Streams, .. , . .
Akka Streams , , , , , . , , , , , . Akka Streams — , , .
, Akka Streams, «Akka Stream Rap».
, .
This is the Akka Stream.
This is the Source that feeds the Akka Stream.
This is the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Streams.
This is the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Throttle that speeds down the TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Bidiflow that turns back the Throttle that speeds down the TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the source that feeds the Akka Streams.
这是从Bidiflow中填充的接收器,该接收器使节流阀回退,从而降低了从从Zip中删除的Drop中拉出的TakeWhile的速度,并从Balance中分离出来,该Balance分离了FilterNot,并从从广播中收集的合并中选择派生从提供Akka流的Source映射的MapAsync。
分钟的广告。如果您喜欢这份报告,并且想要其他类似的内容,下届DotNext 2018莫斯科将于11月22日至23日在莫斯科举行,那对您来说同样会很有趣。赶快以 7月的价格购买车票(从8月1日开始,车票的价格将增加)。