我们的公司SberTech(Sberbank Technologies)当前使用HDFS 2.8.4,因为它具有许多优势,例如Hadoop生态系统,快速处理大量数据,擅长分析以及更多其他功能。 但是在2017年12月,Apache软件基金会发布了用于开发和执行分布式程序的开源框架的新版本-Hadoop 3.0.0,其中包括对先前主要发行版本(hadoop-2.x)的许多重大改进。 对我们来说,最重要,最有趣的更新之一就是对冗余代码(擦除编码)的支持。 因此,任务设置为将这些版本相互比较。
SberTech公司为此研究工作分配了10个虚拟机,每个虚拟机40 GB。 由于RS(10.4)编码策略至少需要14台机器,因此无法对其进行测试。
除了DataNode之外,还将在其中一台计算机上放置NameNode。 将使用以下编码策略进行测试:
而且,使用复制因子为3的复制。
选择的数据块大小等于32 MB。
研究成果
数据速率测试
进行数据传输速率测试。 数据已从本地文件系统传输到分布式文件系统。 此测试中使用的文件大小为292.2 MB。
得到以下结果:
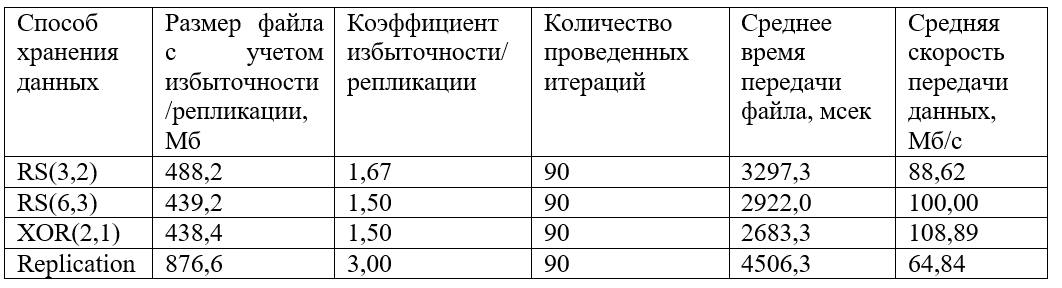
还构造了文件传输时间的分组接收值的图形:

此外,还提供了分组接收数据速率的图表:
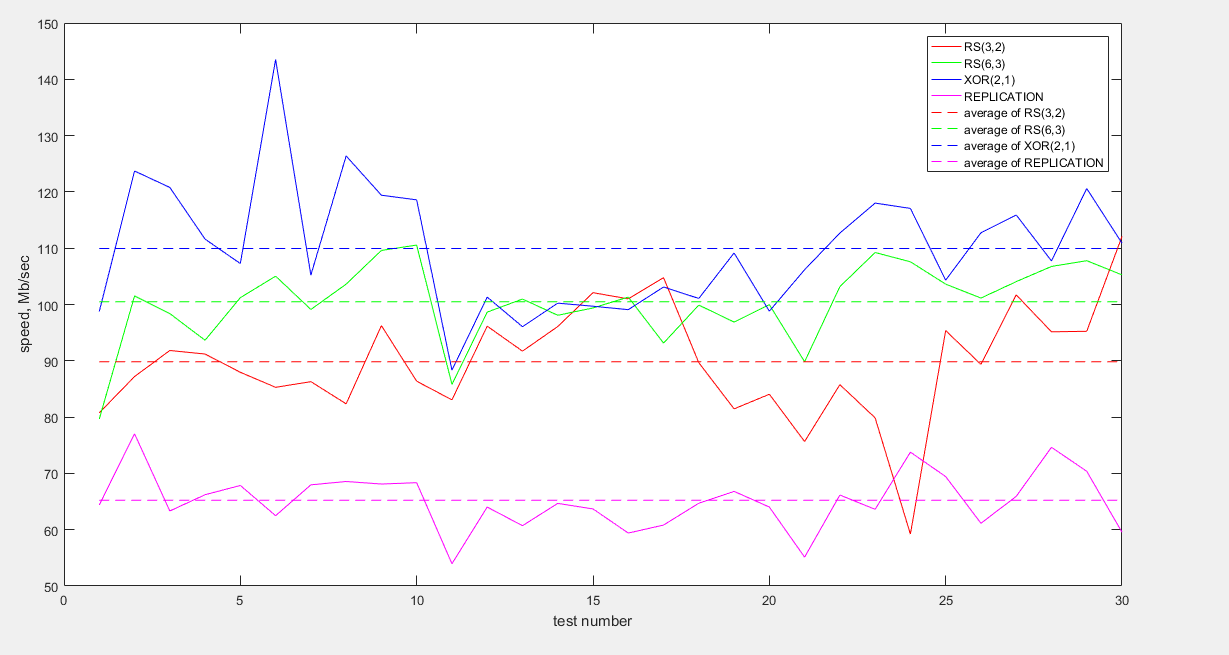
从图中可以看出,最快的数据是用XOR(2,1)编码传输的。 编码RS(6.3)和RS(3.2)表现出相似的行为,尽管RS(6.3)的平均速度值略高。 复制会损失很多速度(大约比XOR低1.5倍,比RS低1.5倍)。
至于存储效率,XOR(2.1)和RS(6.3)是最有利可图的存储方法,冗余数据仅为50%。 复制比率为3的复制再次丢失,存储了200%的冗余数据。
性能测试
在先前的测试中,使用Grafana监视工具监视了服务器的状态。
下图显示了数据传输测试期间的CPU负载:
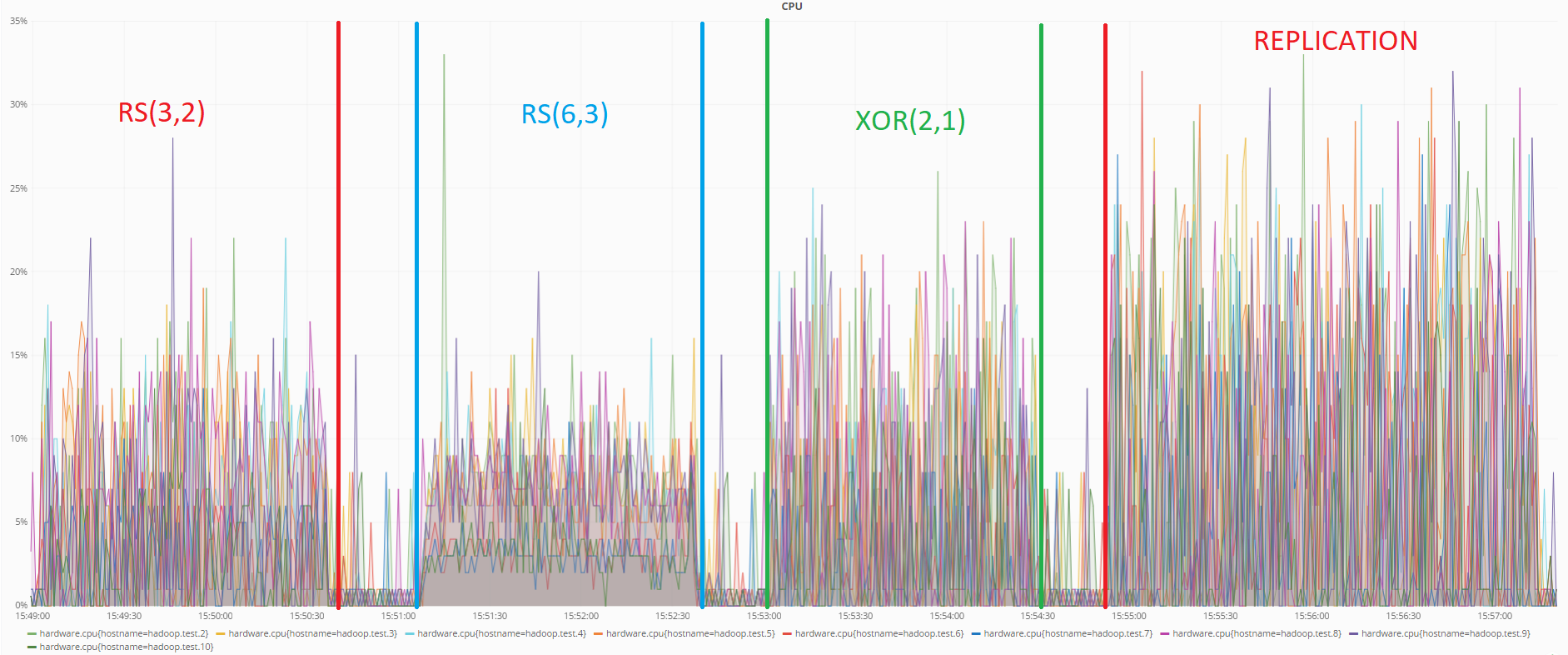
从图中可以看出,在此测试中,RS(6.3)编码也消耗最少的资源。 复制再次显示最差的结果。
数据恢复中的资源消耗
为了进行此测试,需要将一定数量的数据上载到Hadoop分布式文件系统。 然后,省略了具有DataNode的两台计算机。
以下是使用RS(6.3)编码进行数据恢复时以及使用复制时的计算机状态图:
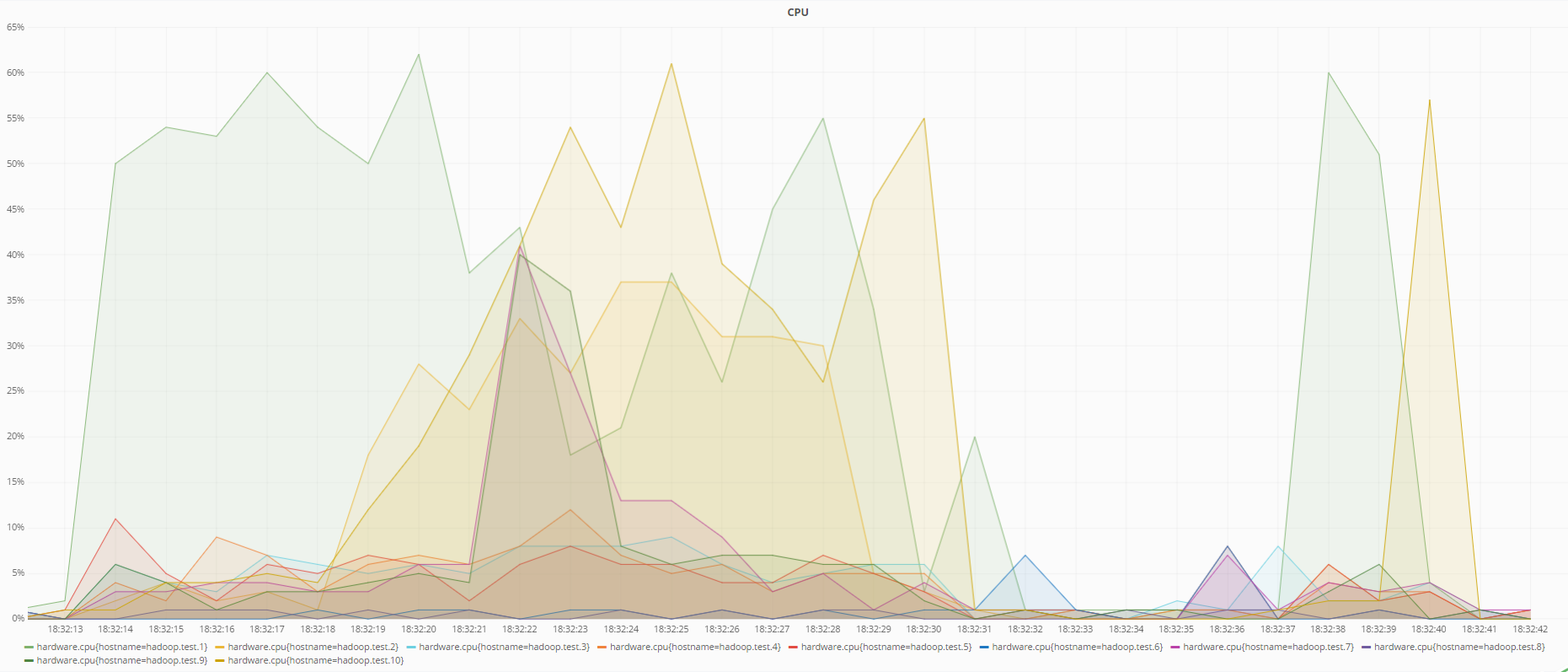
使用RS编码(6.3)进行数据恢复期间处理器的状态

使用复制进行数据恢复期间的CPU状态
从图中可以看出,RS(6.3)编码在数据恢复期间比复制负担更多的处理器负担,这是合乎逻辑的,因为为了使用冗余代码恢复丢失的数据,有必要计算逆冗余矩阵,该矩阵消耗的资源不仅仅是覆盖数据复制时来自其他DataNode的数据。
测试结果:
- 对于数据传输速率,最好使用XOR(2.1)或RS(6.3)编码
- 传输数据时,处理器最少加载编码RS(6.3)和RS(3.2)
- 还原数据时,使用复制对处理器的压力最小。
- 存储数据的最紧凑方式是RS(6.3)和XOR(2.1)编码
最可靠的存储方法是RS(6.3)编码,因为它允许您丢失多达三台计算机而不会丢失数据,并且复制系数为3的复制最多支持2台计算机的故障。 XOR(2,1)是存储数据的最不可靠的方法,因为它使您最多丢失一台计算机。
结论
在SberTech中使用分布式文件系统的主要目标是:
- 高可靠性
- 降低维护服务器以存储数据的成本
- 提供数据分析工具
根据分析结果,得出以下结论:
- HDFS 3优于HDFS 2的可靠性。
- HDFS 3通过最小化服务器维护成本而获胜,因为它可以更紧凑地存储数据。
- HDFS 3具有与HDFS 2相同的数据分析工具集。
在这方面,可以得出结论,HDFS 3是HDFS 2的合理替代。
二手货源: