你好 我叫Denis Kiryanov,我在Sberbank工作,负责处理自然语言处理(NLP)的问题。 一次,我们需要选择一种语法解析器来使用俄语。 为此,我们深入研究了形态和标记化的原理,测试了不同的选项并评估了它们的应用。 我们在这篇文章中分享我们的经验。

准备选拔
让我们从基础开始:如何运作? 我们接受文本,进行标记化,并获得一些伪标记。 进一步分析的阶段适合金字塔:
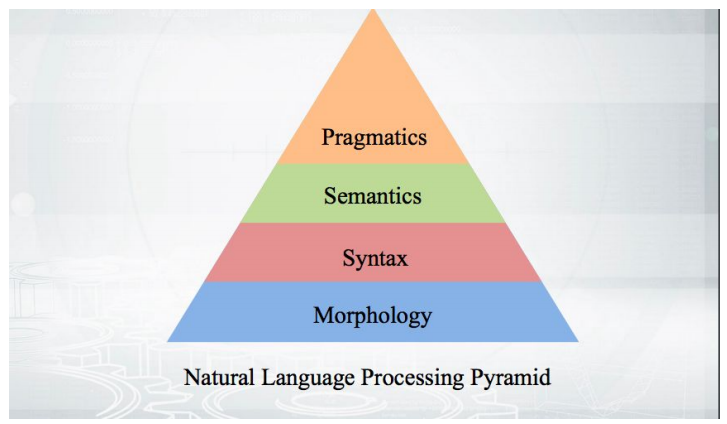
一切都从形态开始-分析单词的形式及其语法类别(性别,大小写等)。 形态学基于语法-单词之间的关系超出一个单词的边界。 将要讨论的语法解析器,分析文本并给出彼此依赖的单词的结构。
依存关系语法和直接组成部分的语法
解析有两种主要方法,它们在语言学理论中是平等存在的。

在第一行中,句子被解析为依赖语法的一部分。 这种方法是在学校教授的。 句子中的每个单词都以某种方式彼此关联。 “肥皂”-主题“母亲”所依赖的谓词(此处依赖项的语法不同于学校,谓词取决于主题)。 受试者对“我的”有从属定义。 谓词具有从属直接补语“框架”。 并直接添加到“框架”-“脏”的定义。
在第二行中,分析是根据组件本身的语法进行的。
根据她的说法,句子分为单词(短语)组。 一组内的单词关系更紧密。 “我的”和“母亲”这两个词,“框架”和“肮脏的”也联系得更紧密。 而且仍然有一个单独的“肥皂”。
自动分析俄语的第二种方法不太适用,因为在其中紧密相关的单词(同一组的成员)通常不会连续出现。 我们将它们与奇怪的括号结合在一起-用一两个词。 因此,在俄语的自动分析中,习惯上是基于依赖项的语法来工作的。 这也很方便,因为每个人都在学校熟悉这种“框架”。
依赖树
我们可以将一组依赖关系转换为树结构。 顶部是“肥皂”一词,有些词直接依赖于它,有些词依赖于其上瘾者。 这是Martin和Zhurafsky教科书中的依赖关系树的
定义 :
依赖关系树是满足以下约束的有向图:- 有一个没有传入弧的指定根节点。
- 除根节点外,每个顶点都只有一个传入弧。
- 从根节点到V中的每个顶点都有唯一的路径。
有一个顶级节点-谓词。 从它您可以到达任何单词。 每个词都依赖于另一个,但仅取决于一个。 依赖关系树如下所示:

在这棵树中,边以某种特殊类型的句法关系进行签名。 在依存关系的语法中,不仅分析单词之间的联系的事实,而且分析这种联系的性质。 例如,“被采取”几乎是一种动词形式,“清单”是“被采取”的主题。 因此,我们在一个方向和另一个方向上都有一个“ is”边缘。 这些不是相同的连接;它们具有不同的性质,因此必须加以区别。
在下文中,我们考虑不存在暗示成员的简单情况。 有处理通行证的结构和标记。 在树中出现的东西没有表面表达-一个单词。 但这是另一项研究的主题,但我们仍然需要专注于自己的研究。
普遍依赖项目
为了方便选择解析器,我们将注意力转向了
通用依赖项目和
CoNLL共享任务竞赛,该竞赛最近在其框架内进行。
普遍依赖关系是一个在依赖关系语法框架内统一句法语料库(tribank)标记的项目。 俄语中,语法链接的类型数量有限-主语,谓语等。 英文相同,但设定已经不同。 例如,在那里出现的文章也需要以某种方式标记。 如果我们想编写一个可以处理所有语言的魔术解析器,那么我们将很快遇到比较不同语法的问题。 普遍依赖的英雄创造者设法达成共识,并以单一格式标出了可供使用的所有建筑物。 他们如何达成一致并不是很重要,主要的是,在输出时,我们可以采用某种统一的格式来呈现整个故事-
超过100种的Tribanks支持60种语言 。
CoNLL共享任务是解析算法开发人员之间的竞争,这是“通用依赖项”项目的一部分。 组织者采取一定数量的三岸银行,并将其分为三个部分-培训,验证和测试。 第一部分提供给比赛的参与者,以便他们在上面训练他们的模型。 参与者还使用第二部分来评估训练后算法的操作。 参与者可以反复地重复训练和评估。 然后,他们将最佳算法提供给组织者,组织者在测试部分运行该算法,并且对参与者不开放。 Tribank的测试部分上的模型结果是竞争的结果。
质量指标
单词及其类型之间存在联系。 我们可以评估是否正确找到了top一词-UAS(未标记的附件得分)指标。 或评估是否正确找到了顶点和依存关系类型-LAS(标签附着分数)度量。

准确性评估似乎是在乞求自己-我们考虑从案件总数中获得了多少次。 如果我们有5个单词,而对于4个单词,我们正确地确定了首位,则得到80%。
但是实际上以纯形式评估解析器是有问题的。 解决自动解析问题的开发人员经常将原始文本作为输入,根据分析金字塔,原始文本会经历标记化和形态分析的阶段。 这些早期步骤中的错误可能会影响解析器的质量。 特别是,这适用于标记化过程-单词分配。 如果我们识别出错误的单位词,那么我们将不再能够正确评估它们之间的句法关系-毕竟,在我们最初标记的军中,单位是不同的。
因此,这种情况下的评估公式为f量度,其中准确度是准确命中相对于预测总数的份额,完整性是准确命中相对于标记数据中链接数的份额。
在将来进行估计时,我们必须记住,所使用的度量不仅影响语法,还影响标记化的质量。
普遍依赖性下的俄语
为了使解析器能够在语法上标记出尚未看到的句子,它需要提供标记出的语料库进行训练。 对于俄语,有几种这样的情况:

第二列表示令牌的数量-单词。 令牌越多,训练队伍越多,最终算法就越好(如果这是好的数据)。 显然,所有实验都是在SynTagRus(由IPPI RAS开发)上进行的,其中有超过一百万个令牌。 将对所有算法进行训练,稍后将进行讨论。
CoNLL共享任务中的俄语解析器
根据去年的
比赛结果,在同一SynTagRus上训练的模型实现了以下LAS指标:

俄语的解析器的结果令人印象深刻-比英语,法语和其他更罕见的语言的解析器的结果要好。 我们很幸运,有两个原因。 首先,算法在俄语方面做得很好。 其次,我们有SynTagRus-大而有标记的外壳。
顺便说一句,2018年的竞赛已经过去了,但是我们在今年春天进行了研究,因此我们依赖于去年赛道的结果。 展望未来,我们注意到
UDPipe (未来)的
新版本今年甚至更高。
Google解析器Syntaxnet不在列表中。 他怎么了 答案很简单:Syntaxnet仅从形态分析阶段开始。 他采用了现成的理想标记,并已经在其之上构建了处理。 因此,将其与其余部分相提并论是不公平的-其余部分使用自己的算法将其拆分为令牌,这可能会使语法的下一阶段的结果恶化。 Syntaxnet的2017年样本比上面的整个列表具有更好的结果,但是直接比较并不公平。
该表在12位和15位获得了UDPipe的两个版本。 积极参与Universal Dependencies项目的人们正在开发此解析器。
UDPipe更新会定期出现(顺便说一下,案例的布局也会更新)。 因此,在去年的竞赛之后,UDPipe进行了更新(这些是尚未发布的版本2.0的提交;在未来,为简单起见,我们将粗略地引用我们采取的UDPipe 2.0提交,尽管严格来讲不是这样); 当然,比赛表中没有此类更新。 “我们的”提交的结果大约在第七位。
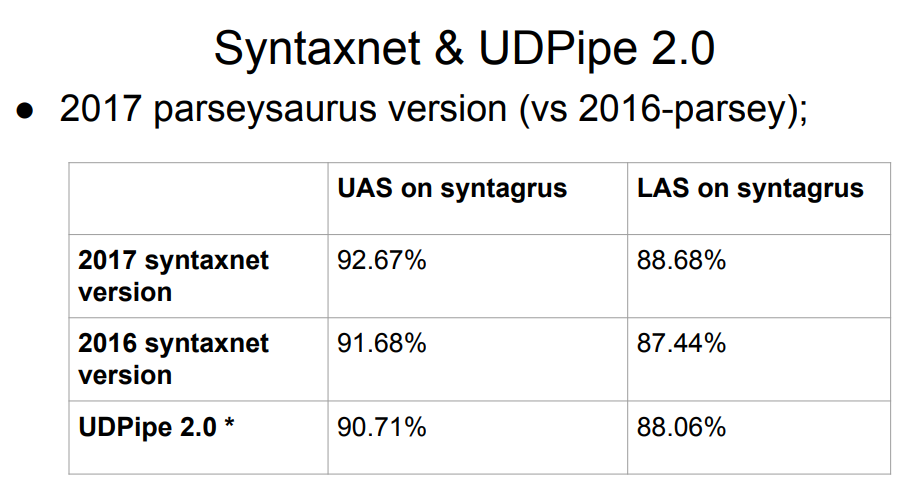
因此,我们需要为俄语选择一个解析器。 作为初始数据,我们在上方的板块中拥有领先的Syntaxnet和UDPipe 2.0,位于第七位。
选择型号
我们使之简单:我们从具有最高速率的解析器开始。 如果他有什么问题,请继续。 根据以下条件,某些事情可能不正确-也许它们不是完美的,但它们还是取决于我们:
- 工作速度 。 我们的解析器应该足够快地工作。 当然,该语法与实时系统中唯一的“幕后”模块相距甚远,因此您在该模块上的花费不应超过十几毫秒。
- 工作质量 。 解析器本身至少基于俄语数据。 要求是显而易见的。 对于俄语,我们有相当不错的形态分析仪,可以将其集成到我们的金字塔中。 如果我们可以确保解析器本身在没有形态的情况下运行很酷,那么这将适合我们-我们稍后将忽略形态。
- 在公共领域中提供培训代码的最好是模型 。 如果我们有培训代码,我们将能够重复模型作者的结果。 为此,它们必须是开放的。 而且,此外,我们需要仔细监视案例和模型分布的条件-如果将它们用作算法的一部分,是否需要购买许可证才能使用它们?
- 无需费力即可发射 。 该项目非常主观,但很重要。 这是什么意思? 这意味着如果我们坐了三天开始一些事情,但是没有开始,那么即使它具有完美的质量,我们也将无法选择该解析器。
解析器图表上所有高于UDPipe 2.0的内容都不适合我们。 我们有一个Python项目,列表中的某些解析器不是用Python编写的。 为了在Python项目中实现它们,有必要付出非常大的努力。 在其他情况下,我们面临着封闭的源代码,学术,工业发展–一般来说,您不会陷入困境。
Star Syntaxnet值得一个关于工作质量的故事。 在这里,他不适合我们的工作速度。 他对聊天中一些常见短语的响应时间为100毫秒。 如果我们在语法上花了很多钱,那么我们没有足够的时间来做别的事情。 同时,UDPipe 2.0会解析大约3ms。 结果,选择落在UDPipe 2.0上。
UDPipe 2.0
UDPipe是一个学习令牌化,词条化,形态标记和依赖性语法解析的管道。 我们可以单独教他所有这一切。 例如,用它制作另一种用于俄语的形态分析仪。 或训练并使用UDPipe作为标记器。
详细记录了UDPipe 2.0。 有一个
体系结构的
描述 ,一个
带有培训代码的
仓库 ,一个
手册 。 最有趣的是
现成的模型 ,包括用于俄语的
模型 。 下载并运行。 同样在该资源上,已经发布了为每个语言语料库选择的训练参数。 对于每个这样的模型,大约需要60个训练参数,在它们的帮助下,您可以独立实现与表中相同的质量指标。 它们可能不是最佳的,但至少我们可以确定管道会正确运行。 此外,此类参考的存在使我们能够自行冷静地尝试该模型。
UDPipe 2.0如何工作
首先,文本分为句子,句子分为单词。 UDPipe在联合模块(神经网络(单层双面GRU))的帮助下一次完成所有这些操作,该模块为每个字符预测是句子中还是单词中的最后一个字符。
然后,标记器开始工作-预测令牌的形态特性的事物:在这种情况下,单词是多少。 根据每个单词的最后四个字符,标记器会生成关于该单词的词性和词性标记的假设,然后借助感知器选择最佳选项。
UDPipe还具有一个词形匹配器,可以选择单词的初始形式。 他学习了非母语者尝试确定不熟悉单词的引理的相同原理。 我们剪掉单词的前缀和结尾,添加一些“ t”(以动词的初始形式出现),等等。 这样就产生了候选者,最佳感知器从中选择。
形态标记方案(确定数量,大小写以及其他所有内容)和引理的预测非常相似。 可以一起预测它们,但最好分开预测-俄语的形态太丰富了。 您还可以连接引理列表。
让我们继续进行最有趣的部分-解析器。 有几种依赖性解析器体系结构。 UDPipe是基于过渡的体系结构:它工作迅速,在线性时间内一次通过所有令牌。
在这种体系结构中,语法分析从堆栈(开始时只有根)和空配置开始。 有三种默认的更改方式:
- LeftArc-如果堆栈的第二个元素不是root,则适用。 它保持令牌在堆栈顶部和第二个令牌之间的关系,并且还将第二个令牌从堆栈中弹出。
- RightArc是相同的,但是依赖项是通过其他方式构建的,并且技巧被丢弃。
- Shift-将下一个单词从缓冲区传输到堆栈。
下面是解析器(
source )的示例。 我们有“为我预订早班航班”一词,我们正在重新连接它:

结果如下:

经典的基于过渡的解析器具有上面列出的三个操作:单向箭头,单向箭头和移位。 在基本的基于过渡的解析器体系结构中也没有交换操作,但它包含在UDPipe中。 交换将堆栈的第二个元素返回到缓冲区,以从缓冲区中获取下一个元素(如果它们之间有间隔)。 这有助于略过几句话并恢复正确的连接。
提出交换操作
的人的
链接上有一篇很好的文章。 我们指出了一点:尽管我们反复经历了初始令牌缓冲区(即我们的时间不再是线性的)的事实,但是可以优化这些操作,以便使时间返回非常接近线性的时间。 也就是说,从语言的角度来看,摆在我们面前的不仅仅是有意义的操作,而且是一种不会大大降低解析器工作速度的工具。
使用上面的示例,我们展示了这些操作,结果是我们进行了一些配置-令牌缓冲区及其之间的连接。 我们在当前步骤中将此配置提供给基于过渡的解析器,并使用它来在下一步中预测该配置。 比较每个步骤的输入向量和配置,即可对模型进行训练。
因此,我们选择了适合我们所有条件的解析器,甚至了解了它的工作原理。 我们进行实验。
UDPipe问题
让我们问一个小句子:“给妈妈一百卢布”。 结果使您抓紧了头。
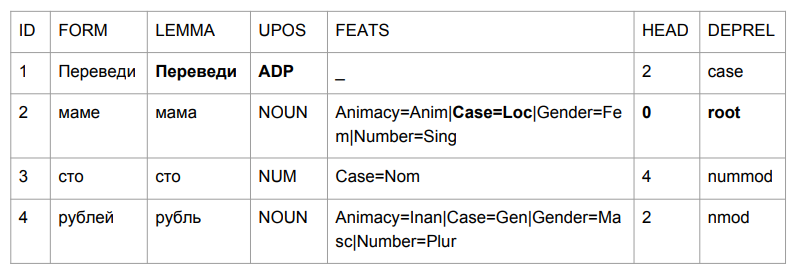
事实证明,“翻译”是一个借口,但这很合逻辑。 我们通过最后四个字符确定单词形式的语法。 “铅”类似于“中间”,因此选择相对合理。 “妈妈”更有趣:“妈妈”在介词中,并成为这句话的顶峰。
如果我们尝试根据解析结果来解释所有内容,那么我们将得到“在一个妈妈中间(谁妈妈?这个妈妈是谁?)几百卢布的信息”。 与其一开始的样子不太一样。 我们需要以某种方式处理这个问题。 我们想到了如何。
在分析金字塔中,语法基于形态标记建立在形态之上。 这是语言学家L.V.的教科书示例。 谢尔比在这方面:
“矮胖的矮胖的shuteko budlanula bokra和卷发的小男孩。”分析该建议不会引起问题。 怎么了 因为我们作为UDPipe标记器,要查看单词的结尾并理解它指的是语音的一部分以及它的形式。 以“翻译”为借口的故事完全与我们的直觉相矛盾,但是当我们试图用不熟悉的单词做同样的事情时,事实证明这是合乎逻辑的。 一个人可能会以同样的方式思考。
我们将分别评估UDPipe标记器。 如果不适合我们,我们将使用另一个标记器-然后在另一个形态标记的基础上进行解析。
从纯文本标记(CoNLL17 F1分数)- 金币形式:301639 ,
- upostag:98.15% ,
- xpostag:99.89% ,
- 壮举:93.97% ,
- alltags:93.44% ,
- 引理:96.68%
UDPipe 2.0的形态质量还不错。 但是对于俄语来说可以说是更好的语言。 Mystem分析器(
Yandex的
发展 )在确定语音部分方面比UDPipe取得了更好的结果。 另外,其他分析器在python项目中更难以实现,并且它们的工作速度与Mystem相当,质量也较慢。 ,
.
UDPipe. . , Mystem . , « » «» — «», «». . , «», (), , . 可能是:
- « » —
- « » — ..
- « - » — (- )
在这种情况下,Mystem会诚实地给出整个链:
m.analyze(" ")
[{'analysis': [{'lex': '', 'gr': 'PART='}], 'text': ''},
{'text': ' '},
{'analysis': [{'lex': '', 'gr': 'S,,=(,|,|,)'}],
'text': ''},
{'text': '\n'}]
但是我们无法将整个管道链发送到UDPipe,但是必须指定一些更好的标记。 如何选择呢? 如果您什么都没碰,我想先拿,也许可以用。 但是标签是按照英文名称的字母顺序排序的,因此我们的选择几乎是随机的,并且某些语法分析几乎失去了成为第一个的机会。
有一个可以提供最佳选择的分析器-Pymorphy2。 但是通过形态分析,他变得更糟。 另外,他在上下文之外给出了最好的词。 Pymorphy2将只对“无导演”,“见导演”和“导演”给出一种分析。 它不会是随机的,但实际上是概率最高的,它在pymorphy2中被认为是在单独的文本中。 但是,一定程度上可以保证对战斗文本进行不正确的分析,这仅仅是因为它们很可能包含具有不同实际形式的短语:“我看见导演”和“导演参加会议”以及“没有导演”。 无上下文解析的可能性不适合我们。
如何根据上下文获取最佳标签集? 使用
RNNMorph分析器。 很少有人听说过他,但去年,他赢得了在Dialogue会议上举行的形态分析仪竞赛。
RNNMorph有其自身的问题:它没有标记化。 如果Mystem可以标记原始文本,则RNNMorph要求在输入处提供标记列表。 要获取语法,您首先需要使用一些外部标记器,然后将结果提供给RNNMorph,然后才将结果形态提供给语法分析器。
这是我们的选择。 对于Mystem中有争议的案例,我们现在不会拒绝pymorphy2上下文无关的分析-突然,它不会远远落后于RNNMorph。 尽管如果仅在形态标记的质量水平上比较它们(来自
MorphoRuEval-2017的数据),则损失是巨大的-如果我们根据词语来计算准确性,则损失约为15%。
接下来,我们需要将Mystem的输出转换为UDPipe可以理解的格式-conllu。 再一次,这是一个问题,甚至多达两个。 纯技术性-线路不匹配。 从概念上讲-并不总是完全清楚如何比较它们。 面对两种不同的语言数据标记,您几乎肯定会遇到标签匹配的问题,请参见下面的示例。 “哪个标签在这里”这个问题的答案可能有所不同,正确的答案可能取决于任务。 由于这种不一致,匹配标记系统本身并不是一件容易的事。
如何转换? 有
Russian_tagsets _
包 -用于Python的包,可以转换不同的格式。 从发布Mystem到Conllu的格式没有翻译,这在普遍依赖关系中是接受的,但是例如从俄语国家语料库的标记格式到conllu都有翻译(反之亦然)。 程序包的作者(顺便说一句,他是pymorphy2的作者)直接在文档中写了一件很棒的事情:“如果您不能使用此程序包,请不要使用它。” 他这样做并不是因为krivorukov程序员(他是一位优秀的程序员!),而是因为如果您需要将一个人转换为另一个人,那么由于标记约定的语言不一致,您就有可能遇到问题。
这是一个例子。 学校被告知“条件类别”(冷,必要)。 有人说这是副词,有人说这是形容词。 您需要对此进行转换,并添加一些规则,但是仍然不能在一种格式和另一种格式之间实现明确的对应关系。
另一个例子:承诺(某人做了某事或与某人做了某事)。 “ Petya杀死了某人”或“ Petya被杀死了”。 “ Vasya拍照”-“ Vasya拍照”(实际上是“ Vasya被拍照”)。 SynTagRus中还有一个中间保证-我们甚至不会深入研究它的含义和原因。 但是在Mystem中却不是。 如果您需要以某种方式将一种格式转换为另一种格式,那将是一个死胡同。
我们或多或少地诚实地接受了Russian_tagsets软件包作者的建议-没有使用它的开发,因为在对应格式列表中找不到所需的对。 结果,我们编写了从Mystem到Conllu的自定义转换器,然后继续。
我们连接了第三方标记器和UDPipe解析器
经过所有的冒险,我们采用了三种算法,如上所述:
- 基线UDPipe
- 从pymorphy2消除标签歧义的Mym
- 核蛋白
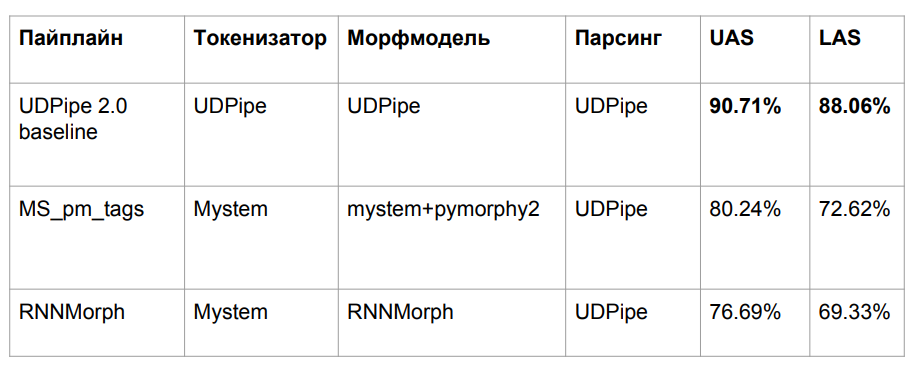
我们由于明显的原因而失去了质量。 我们采用了在一种形态上训练的UDPipe模型,但在输入上忽略了另一种形态。 训练和测试之间的数据不匹配的经典问题是质量下降的结果。
我们试图将自动形态标记工具与SynTagRus标记对齐,该标记是手动标记的。 我们没有成功,因此,在SynTagRus培训大楼中,我们将用一种情况下的Mystem和pymorphy2以及另一种情况下的RNNMorph代替那些手动形态标记。 在手动标记的经过验证的情况下,我们被迫将手动标记更改为自动标记,因为在“战斗中”,我们将永远不会获得手动标记。
结果,我们使用与基线相同的超参数训练了UDPipe解析器(仅解析器)。 造成语法的原因-连接类型所依赖的顶点ID-我们离开了,我们更改了其他所有内容。
结果
此外,我将我们与Syntaxnet和其他算法进行比较。 CoNLL共享任务组织者已经发布了SynTagRus分区(train / dev / test 80/10/10)。 我们最初进行了另一次培训(培训/测试70/30),因此尽管在同一案例中收到了数据,但数据并不总是与我们一致。 此外,我们从SynTagRus存储库中获取了最新的(截至2月至3月)发行版-此版本与竞争对手的版本略有不同。 拆分结果与比赛相同的文章提供了未取得成功的数据-此类算法在表格中标有星号。
这是最终结果:
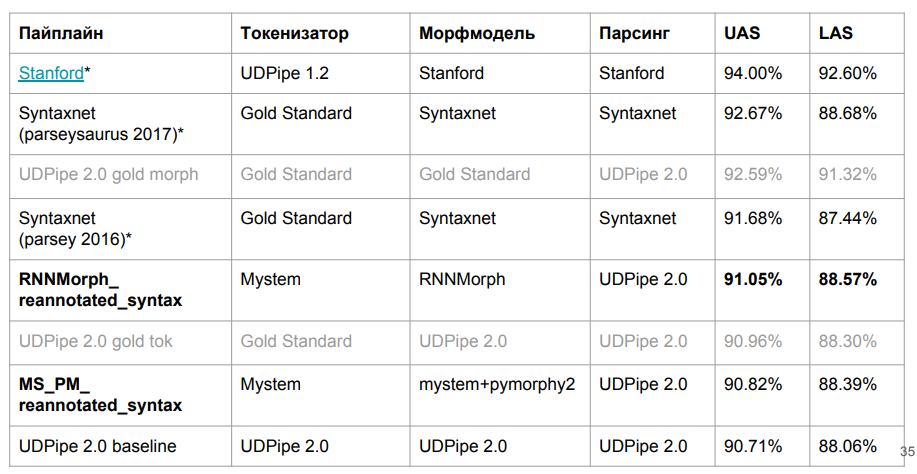
事实证明RNNMorph更好-不是绝对意义上的,而是根据解析结果(与Mystem + pymorphy2相比)的一种辅助工具的作用,该工具可用于获取通用度量。 即,形态越好,语法越好,但是“句法”分离远小于形态分离。 还要注意,我们离基线模型并没有太远,这意味着在形态学上确实没有我们期望的那么多。
我想知道形态到底有多少? 由于理想的形态,能否在语法分析器中实现根本的改进? 为了回答这个问题,我们使用了经过完美校准的标记化和形态的UDPipe 2.0(使用标准的手动标记标准)。 从我们所拥有的内容(包括从正确确定连接类型的角度来看)有一定的余量(请参阅表中有关“金形态”的行;从RNNMorph_reannotated_syntax得出的结果为+ 1.54%)。 如果有人曾经写过一个绝对完美的俄语形态分析仪,那么使用抽象句法分析器获得的结果也可能会增长。 而且,我们大致了解了上限(至少对于该体系结构以及用于UDPipe的参数组合的上限-如上表的第三行所示)。
有趣的是,我们几乎达到了LAS指标中的Syntaxnet版本。 显然,我们的数据略有不同,但原则上仍是可比较的。 语法网标记化是“黄金”,对我们而言-来自Mystem。 我们将上述包装器写入Mystem,但是解析仍会自动进行。 可能Mystem也误认为某个地方。 从“ UDPipe 2.0 gold tok”表的行中可以看出,如果采用默认的UDPipe和gold令牌化,则它仍然会稍微失去Syntaxnet-2017。 但是它的工作速度更快。
斯坦福解析器是没人能达到的。 它的设计与Syntaxnet相同,因此可以长期使用。 在UDPipe中,我们只是沿着堆栈前进。 Stanford解析器和Syntaxnet的体系结构具有不同的概念:首先,它们生成一个完整的面向图,然后该算法工作,以保留最有可能出现的骨架(最小生成树)。 为此,他进行了组合操作,并且此搜索不再是线性的,因为您将不止一次转向一个单词。 尽管长期以来,从纯科学的角度来看,至少对于俄语来说,它是一种效率更高的体系结构。 我们尝试了两天来提高这一学术发展水平-,,结果没有奏效。 但是基于其体系结构,很明显它无法快速运行。
至于我们的方法-尽管我们在形式上几乎没有上升,但现在“母亲”一切都很好。
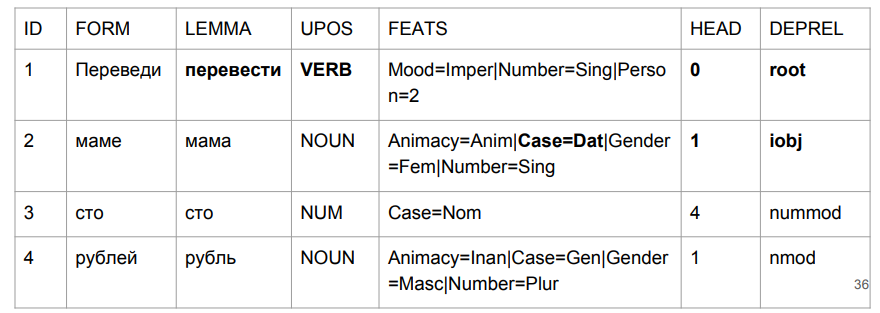
在“向妈妈翻译一百卢布”这句话中,“翻译”实际上是祈使语气中的动词。 “妈妈”得到了和解。 对我们来说,最重要的是我们的标签(iobj),这是一个间接对象(目标)。 尽管数量的增长可以忽略不计,但我们很好地解决了任务开始的问题。
奖金追踪:标点符号
如果我们返回真实数据,事实证明语法取决于标点符号。 用“你不能执行怜悯”这句话。 “执行”或“仁慈”究竟是不能完成的,取决于逗号所在的位置。 即使我们将语言学家标记为数据,他也需要标点符号作为某种辅助工具。 他不能没有她。
让我们使用短语“ Peter hello”和“ Peter hello”,并通过基线UDPipe模型查看它们的分析。 根据该模型,我们省去了以下问题:
1)“ Petya”是一个女性名词;
2)“ Petya”是(按标签集判断)初始形式,但同时,他的引理据称不是“ Petya”。
这就是结果由于逗号而变化的方式,借助它,我们得到了与真实情况类似的结果。
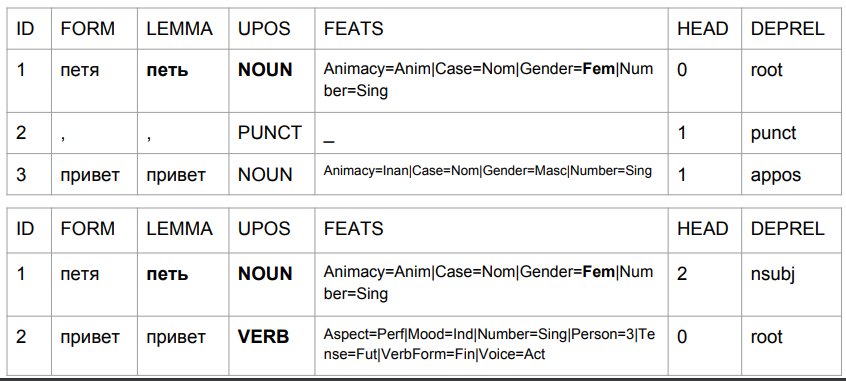
在第二种情况下,“ Petya”是主语,“ hello”是动词。 返回基于最后四个字符来预测单词的形状。 在算法解释中,这不是“ Petya问候”,而是“ Petya问候”。 输入“ Petya唱歌”或“ Petya会来”。 这种分析是可以理解的:在俄语中,主题和谓语之间不能有逗号。 因此,如果是逗号,则为“ hello”,如果没有逗号,则可能为“ Petya Privet”。
我们会在生产中经常遇到此问题,因为拼写检查器会纠正拼写,但不能纠正标点符号。 更糟的是,用户可能会错误地设置逗号,并且我们的算法会在理解自然语言时将它们考虑在内。 这里有什么可能的解决方案? 我们看到两个选择。
第一种选择是像将语音转换为文本时那样做。 最初,此类文本中没有标点符号,因此通过模型将其还原。 就俄语规则而言,输出是相对称职的材料,这有助于语法解析器正常工作。
第二个想法有些大胆,与俄语的学校课程相矛盾。 它涉及不带标点的工作:如果输入突然变成了标点,我们将从那里将其删除。 我们还将从培训团队中删除所有标点符号。 我们假设俄语不存在标点符号。 仅用于划分句子的要点。
从技术上讲,这很简单,因为我们不更改语法树中的末端节点。 标点符号不能放在最前面。 除%符号外,这始终是一些最终节点,由于某些原因,SynTagRus中的%符号是前一个数字的顶点(SynTagRus中的50%被标记为%-顶点,而50则取决于它)。
让我们使用Mystem(+ pymorphy 2)模型进行测试。

对于我们而言,至关重要的是,不要给出没有标点的标点文本模型。 但是,如果我们总是在不加标点的情况下给出文本,那么我们将排在第一位,并至少获得可接受的结果。 如果文本不带标点,并且模型不带标点,那么相对于理想标点和标点模型,降幅仅为3%左右。
怎么办呢? 我们可以详细讨论这些数字-使用无标点模型和标点的提纯获得。 或提出某种分类器以恢复标点符号。 我们无法获得理想的数字(在标点模型上带有标点的数字),因为标点恢复算法会出现一些错误,并且“理想”数字是在绝对纯的SynTagRus上计算得出的。 但是,如果我们要编写一个恢复标点符号的模型,那么进度会偿还我们的成本吗? 答案尚不明确。
我们可以对解析器的体系结构进行很长时间的思考,但是我们必须记住,实际上还没有一个语法标记明显的Web文本语料库。 它的存在将有助于更好地解决实际问题。 到目前为止,我们正在研究绝对有素的,经过编辑的文本,而由于在战斗中获取通常是不识字的自定义文本,我们正在失去质量。
结论
我们研究了基于依存语法的各种语法解析算法的用法,该算法应用于俄语。 事实证明,就速度,便利性和工作质量而言,UDPipe被证明是最好的工具。 如果将标记化和形态分析的阶段分配给其他第三方分析器,则可以改进其基线模型:此技巧使纠正标记器的不正确行为成为可能,从而可以纠正重要情况下的解析器进行分析。
我们还分析了标点符号与解析之间关系的问题,得出的结论是,在我们的案例中,句法解析之前的标点符号更易于删除。
我们希望本文中讨论的应用程序点将帮助您使用语法分析来尽可能有效地解决问题。
作者感谢Nikita Kuznetsova和Natalya Filippova在撰写本文时提供的帮助; 为研究提供帮助-安东·阿列克谢夫(Anton Alekseev),尼基塔·库兹涅佐夫(Nikita Kuznetsov),安德烈·库图佐夫(Andrei Kutuzov),鲍里斯·奥列霍夫(Boris Orekhov)和米哈伊尔·波波夫(Mikhail Popov)。