多年来,Mail.ru一直举办机器学习锦标赛,每次任务以其自己的方式有趣且以其自己的方式复杂。 这是我第四次参加比赛,我真的很喜欢这个平台和组织,而正是通过训练营,我进入了竞争性机器学习的道路,但是我还是第一次获得了第一名。 在文章中,我将告诉您,如果测试部分与数据的训练部分明显不同,那么如何在不对公共排行榜或延迟样本进行重新训练的情况下显示稳定的结果。
挑战赛
可在→
链接中找到任务的全文。 简而言之:有10 GB的数据,其中每行包含三种json类型的“密钥:计数器”,特定类别,特定时间戳和用户ID。 多个条目可以对应一个用户。 需要确定用户属于哪个类别,第一或第二。 该模型的质量度量是ROC-AUC,在Alexander Dyakonov
[1]的博客中对此进行了很好的描述。
示例文件输入
00000d2994b6df9239901389031acaac 5 {"809001":2,"848545":2,"565828":1,"490363":1} {"85789":1,"238490":1,"32285":1,"103987":1,"16507":2,"6477":1,"92797":2} {} 39
解决方案
成功下载数据集的数据科学家提出的第一个想法是将json列转换为稀疏矩阵。 此时,许多参与者遇到了缺少RAM的问题。 在python中甚至部署一列时,内存消耗都比普通笔记本电脑高。
一些干统计。 每列中的唯一键数为2053602、20275、1057788。此外,在火车部分和测试部分中,只有493866、20268、141931。火车中的427994个唯一用户和测试部分中的181024。 培训部分中约1%的4%。
如您所见,我们有很多标志,使用它们都是在火车上过度拟合的一种明显方法,因为例如决策树使用标志的组合,并且甚至还有如此众多标志的独特组合,并且几乎所有这些标志仅存在于训练部分数据或正在测试中。 但是,我拥有的基本模型之一是lightgbm,colsample〜0.1,非常严格的正则化。 但是,尽管正规化的参数很大,但在比赛结束后,结果却显示出公共和私人场合的不稳定结果。
决定参加此比赛的人的第二个想法可能是收集火车并进行测试,并通过标识符汇总信息。 例如金额。 或最大。 在这里,事实证明Mail.ru为我们想到了两个非常有趣的事情。 首先,可以以非常高的准确性对测试进行分类。 即使根据有关cuid条目数和json中唯一键数的统计数据,测试也大大超出了训练范围。 基本分类器的测试识别率为0.9+ roc-auc。 其次,计数器没有任何意义,几乎所有模型都从从计数器转换为二进制形式的符号变得更好:没有/没有密钥。 甚至连树木(从理论上也不会因为一个单位有一定数量而不是一个单位而变得更糟)似乎也经过了重新训练。
公共排行榜上的结果大大超过了交叉验证的结果。 显然,这是由于这样的事实,即模型在测试中建立两个记录的排名比在火车中更容易,因为更多的符号给出了更多的排名条件。
在这一阶段,完全清楚的是,在这场比赛中进行验证不是一件容易的事,公共信息或其他参与者的简历也不会被诱骗,这可被诱骗到官方聊天室中
[2] 。 为什么会发生? 似乎火车和考试是按时间分开的,后来组织者证实了这一点。
任何有经验的kaggle成员都会立即建议进行对抗验证
[3] ,但这并不那么简单。 尽管通过度量roc-auc进行的火车和测试分类器的准确性接近于1,但火车中没有很多类似的条目。 我试图对具有相同目标的cuid聚合样本进行汇总,以增加json中具有大量唯一键的记录的数量,但是这在交叉验证和公共验证方面均造成了缺点,因此我害怕使用此类模型。
有两种方法:通过无监督的学习寻找永恒的价值,或尝试采用对测试更重要的功能。 我走了两种路,使用TruncatedSVD进行无监督,并在测试中按频率选择特征。
第一步,我做了一个深层的自动编码器,但是我被弄错了,两次取相同的矩阵,我无法修复错误并使用全套符号:在任何密集层大小下,输入张量都不适合GPU内存。 我发现了一个错误,后来我没有尝试对功能进行编码。
我以各种富有想象力的方式生成了SVD:在具有cat_feature的原始数据集上,然后通过cuid求和。 对于每列分别。 通过json上的tf-idf作为词袋
[4] (没有帮助)。
为了获得更多的品种,我尝试在火车中选择少量特征,对交叉验证的每一折火车部分使用A-NOVA。
型号
主要基本模型:lightgbm,vowpal wabbit,xgboost,SGD。 另外,我使用了几种神经网络架构。 在公共排行榜的第一名的德米特里·尼基特科(Dmitry Nikitko)建议使用
HashEmbeddings ,此模型经过一些参数选择后显示出良好的效果并改善了整体效果。
另一个神经网络模型,用于搜索3-4-5数据列(左三个输入),数字统计量(4个输入),SVD矩阵(5个输入)之间的交互作用(分解机器样式)。
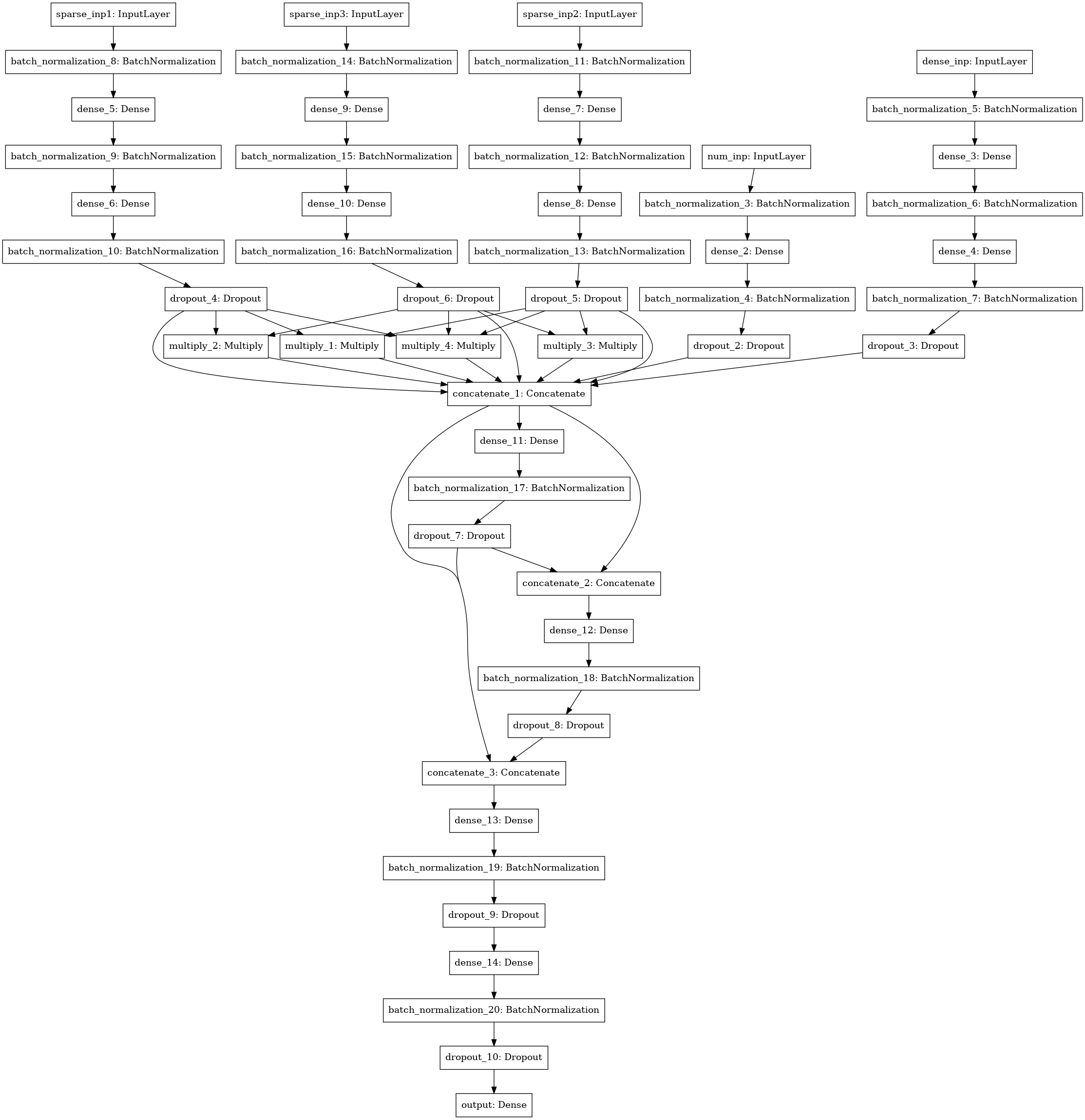
合奏
我对所有模型进行了褶皱计数,然后对经过各种褶皱训练的模型得出的测试预测结果进行平均。 火车预测用于堆叠。 使用xgboost在基础模型的预测上使用1级堆栈显示最佳结果,并从每个json列中选择250个属性,并根据测试中该属性满足的频率进行选择。
我在解决方案上花费了大约30个小时的时间,指望具有4个core-i7内核,64 GB RAM和一个GTX 1080的服务器。结果,我的解决方案非常稳定,我从公共排行榜上的第三名移到了第一个私有排行榜上。
该代码的很大一部分以笔记本电脑的形式在位桶中可用
[5] 。
我要感谢Mail.ru进行的有趣的竞赛,以及其他与小组中的有趣交流的参与者!
[1]
Aleksandrov Dyakonov博客上的ROC-AUC[2]
官方聊天ML BootCamp官方[3]
对抗性验证[4]
口碑[5]
大多数模型的源代码