几个月前,Kepler.gl的第一个版本已发布-一种新的开源工具,用于可视化和分析大量地理数据。
在本文中,我建议您熟悉该应用程序的主要功能,并使用该应用程序创建两个制图可视化图表,以使我们能够找到有关莫斯科有偿停车的一些有趣事实。
但是首先,关于创建Kepler.gl的人和原因的几句话
最初,Kepler.Gl是由Uber工程团队为公司分析师创建的,他们希望更好地了解“城市的运行方式”,为此使用世界各地成千上万的“超级”每天收集的大量地理信息交通数据。
但是,今年5月,该公司宣布开放访问此应用程序,并将Kepler.gl的所有源代码发布在GitHub上
Kepler.gl的主要功能
无论地图服务或框架使用的数据分析工具是什么,以及用于创建各种可视化效果的库,都将其处理过程简化为4个主要步骤:
- 信息收集
- 资料处理
- 研究和分析准备好的数据(以识别依赖关系,搜索异常等)
- 可视化创作
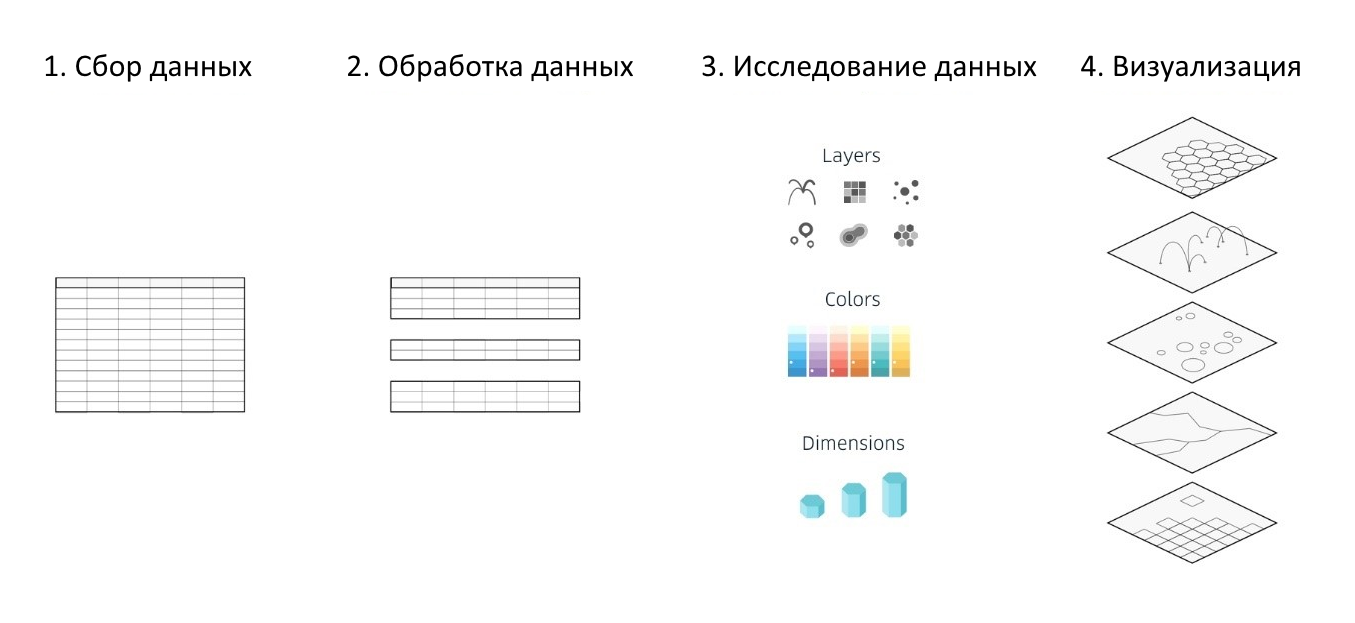 图1.创建可视化的基本阶段
图1.创建可视化的基本阶段Kepler.gl部分自动化并简化了列出的4个步骤中的3个,这大大简化了大型数据集的分析和可视化的整个过程,并帮助您在短短半小时内根据自己的地理数据集创建内容丰富,最重要的彩色交互式地图。
同时,绝对不需要编程或设计经验,因为过滤和数据聚合,根据要研究的对象的各种参数选择显示数据的方式,叠加来自各种来源的信息,在2D和3D模式之间进行切换以及使用UI面板进行的配置更多。
如何使用Kepler.gl进行数据分析
最简单的方法是使用kepler.gl上的在线版本开始与Kepler.gl相识,或者,如果您不信任第三方服务器,则可以按照
GitHub上的说明为自己部署本地版本。
在下文中,我将使用莫斯科政府“开放数据门户”提供的“ 莫斯科有偿停车 ”数据 。 该集合包含有关位于街道网络上的9000多个对象的信息,包括有关停车位的成本和数量的信息。
阶段1.数据加载
迄今为止,Kepler.gl支持3种源数据格式:geojson,json和csv。 将数据保存为指定格式之一(在此示例中,我使用.csv),我们只需将它们加载到应用程序中即可。 顺便说一下,在这里,在下载对话框中,您可以使用数十种预定义的测试数据集之一来熟悉应用程序。
注意事项 对于Chrome,最大上传文件大小不应超过250Mb。 如果您需要下载较大的文件,Kepler.gl的创建者建议使用Safari。 但是,无论如何,您都需要记住,应用程序的性能取决于运行它的设备。 毕竟,所有与聚合,过滤和显示数据相关的操作都在客户端上进行。
第2阶段。在地图上显示数据
该应用程序支持9种类型的可视化层(数据可视化层),它们在一组可自定义的参数方面彼此不同:
- 点层
- 弧层(Arc)
- 线层(线)
- 网格(网格)
- 六角格(Hexbin)
- 图层多边形(Poligon)
- 群集层(群集)
- 图标层(图标)
- 热图(Heatmap)
此外,即使显示相同数据集的相同类型的层,也可能因所选配置而有很大差异。

图2.使用各种类型的图层在kepler.gl中创建的地图
Kepler.gl在显示测试数据集时不限制使用的层数。 图层以在侧面板的图层列表中的排列顺序绘制在地图上。 只需在“图层”选项卡上相对于彼此拖动相应的图层,即可轻松更改此顺序。
使用多个图层时,请注意“图层混合”参数,该参数负责图层的重叠方式。 在整个可视化中它是统一的,因此不可能对不同的图层使用不同类型的混合。
当前,此参数的三个值可用:
- 正常的
在这种情况下,下层不影响上层的点(或其他元素)的颜色。
- 添加剂
使用这种类型的叠加层,可以将匹配元素的颜色值相加。 方便识别高密度区域,在这种情况下将变亮。 - 减法
与加性不同,它不相加,而是减去相交区域中颜色的含义。 当使用暗卡而不是暗卡时,这很方便。
因此,为了在地图上查看我们的数据,有必要使用它们创建至少一层。 值得注意的是,下载文件后,Kepler.gl将尝试识别包含地理位置信息的字段并立即显示它们,从而自动创建相应类型(通常是点或多边形)的图层。
但是,在我们的情况下,由于预期和使用的数据格式不同,您将必须自行指定坐标源。 为此,首先删除由Kepler.gl创建的多边形图层,然后手动添加一个新的Point类型图层。 作为坐标源,我们使用Latitude_WGS84和Longitude_WGS84字段,而不是应用程序自动选择的用于在地图上呈现数据的“坐标”字段。
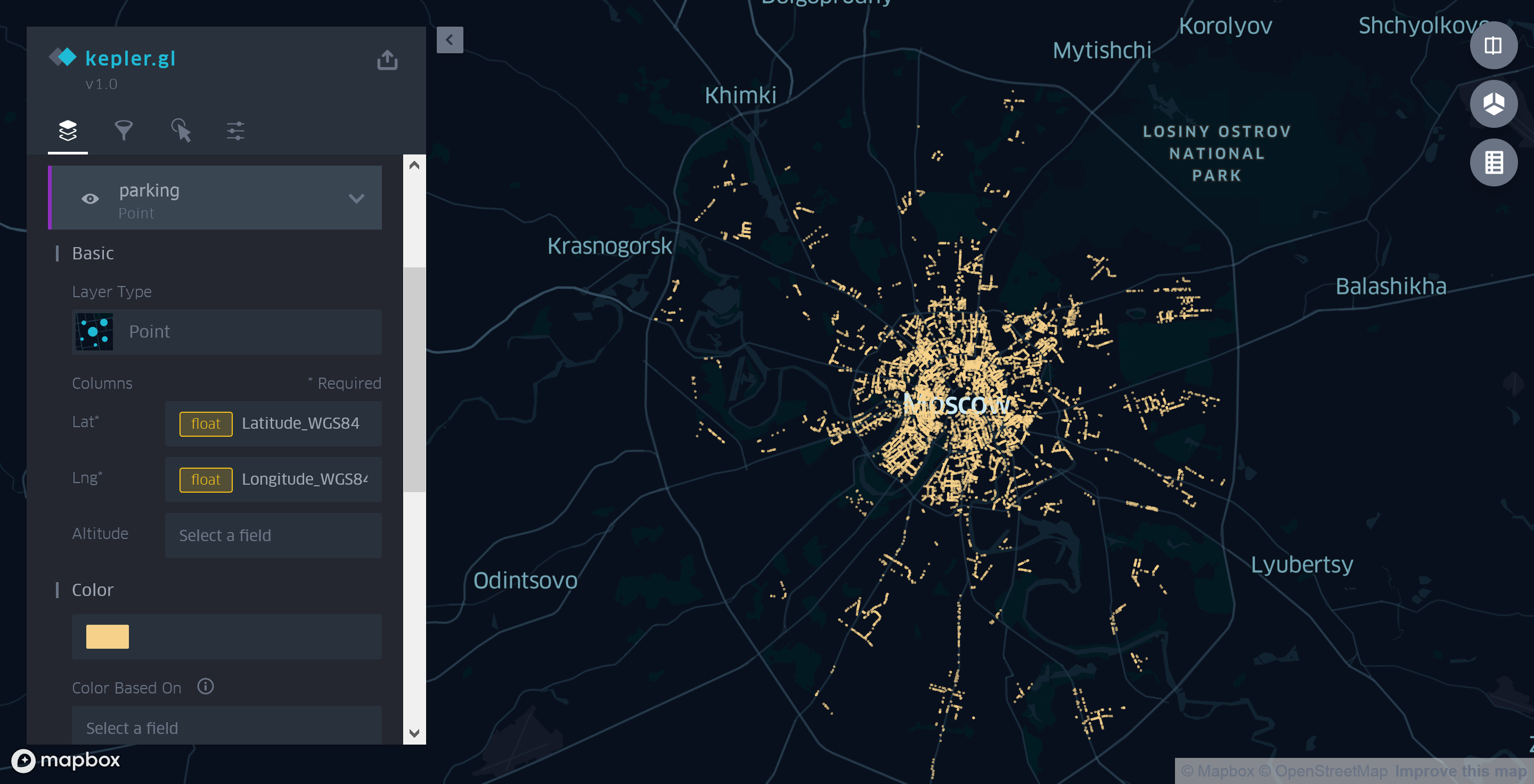
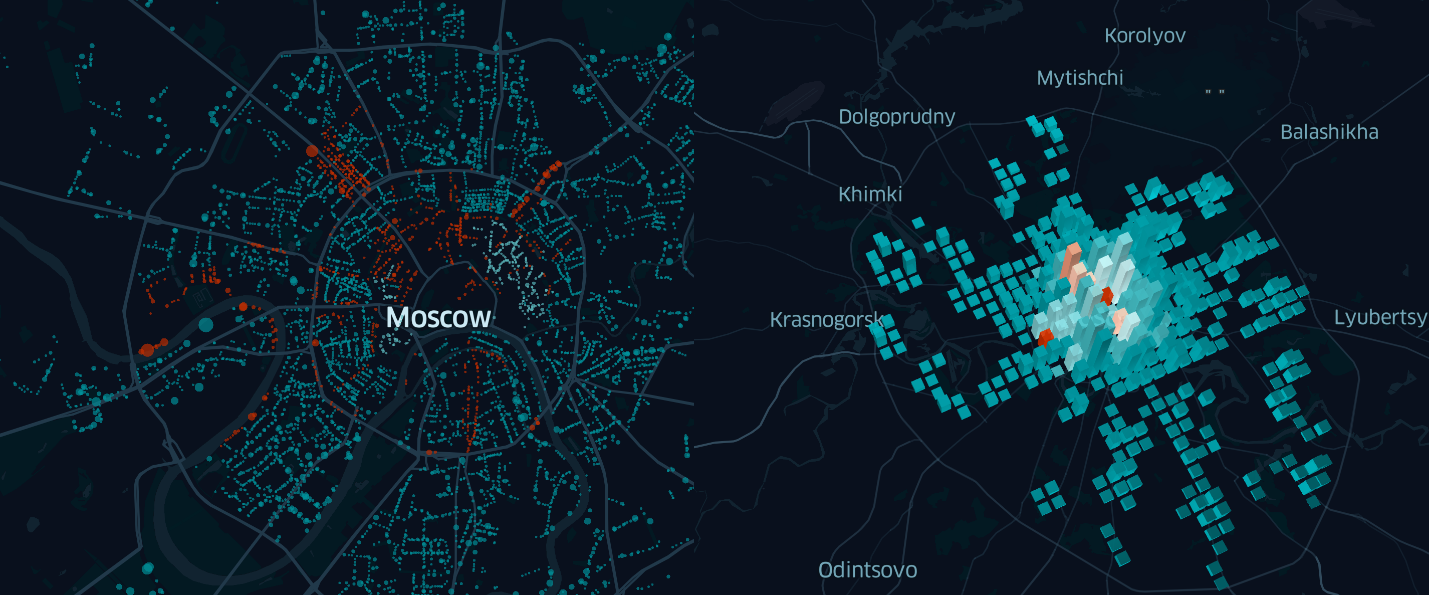
图3.使用Kepler.gl点图层显示莫斯科停车场
在该实施例中,卡不是非常有用。 看着她,唯一可以说的是,市中心的停车位比郊区多。
因此,是时候使用有关被研究对象的其他信息进行更详细的分析并搜索有趣的事实和/或模式了。
第3阶段。根据显示对象上的相关数据修改地图外观
从开放数据门户网站下载的数据集包含有关每个停车场的大量信息,但是,在我看来,两个参数最有趣:一个小时的停车费用和可用空间的数量。
莫斯科最昂贵的停车场在哪里? 停车场的大小与其距离之间的距离是否相关? 在花园环内外停车一小时的费用有多少不同? 要回答这些问题,我们只需稍微更改先前创建的点图层的显示设置,然后再次查看地图即可。
首先,根据在此地方停车一个小时的费用,更改点的颜色。 为此,在“基于颜色”下拉列表中,作为选择颜色的基础,我们指示原始数据集的“价格”参数。

图4.使用颜色显示停车时间成本信息
在这个阶段已经可以进行一些有趣的观察。 例如,并不是整个中心对于驾车者来说同样昂贵,但是在特维尔大街上,最好是成为行人
现在让我们看看停车场的容量。 为此,我们将“ CarCapacity”字段用作确定点半径的基本参数(点层的“ Radius Based On”属性)。 将半径范围设置为0到30像素。

图5.根据停车位数量定制点的大小
因此,在短短几分钟内,我们的停车地图就变得更加翔实。 现在,即使只是粗略地浏览一下,它不仅可以比较城市不同地区的定价政策,而且可以粗略地评估您找到可用空间的机会,这不仅取决于附近的停车场数量,还取决于它们的宽敞程度。
第4阶段。使用Kepler.gl汇总数据
使用点层显示9000多个停车位中的每一个,已经使我们能够进行一些有趣的观察,但是该地图不允许我们轻松回答诸如“每单位面积上最大的停车位在哪里?”之类的问题。 要解决这个问题,我们需要使用聚合层之一。
目前,Kepler.Gl支持4种类型的图层:网格(Grid),六角形网格(Hexbin),热图(Heatmap)和簇(Cluster)。 当您只需要通过一个参数聚合数据时,后两种类型(集群和热图)很方便。 网格和六角形网格允许同时通过多个参数分析聚合值。
为了回答之前提出的问题,我们将先前创建的点层的类型更改为“网格”(网格),这不仅会评估单位面积的停车位总数,而且还会保存有关该位置一小时平均停车成本的信息。
将网格大小设置为1km2(Kepler.gl中的最小值)。 Coverage参数的值从1减小到0.7,以便在单元格之间出现很小的空间,从而提高了最终地图的可读性。
注意事项 可用于自定义的选项列表取决于所选的图层类型。 您可以在Kepler.gl的官方文档中找到有关每个属性所支持的属性的更多详细信息。
与以前一样,新可视化中每个单元的颜色将取决于一个小时的停车费用。 但是,现在,除了使用的数据集中的字段名称外,我们还需要指出Kepler.gl将如何聚合此信息。 汇总方法取决于所选字段的类型。 在我们的示例中, “价格”是数字类型(int),应用程序提供5个选项之一:
- 最高值(最小值)
- 最小值(最大值)
- 金额(总和)
- 平均值(平均值)
- 中位数
网格的每一列的高度将反映该区域中停车位的总数。 为此,请转到查看地图的3D模式。 然后,在侧面板的“ Layers”选项卡上,为我们的聚合层选择“ Enable height” ,然后选择“ CarCapacity”字段作为基本参数。
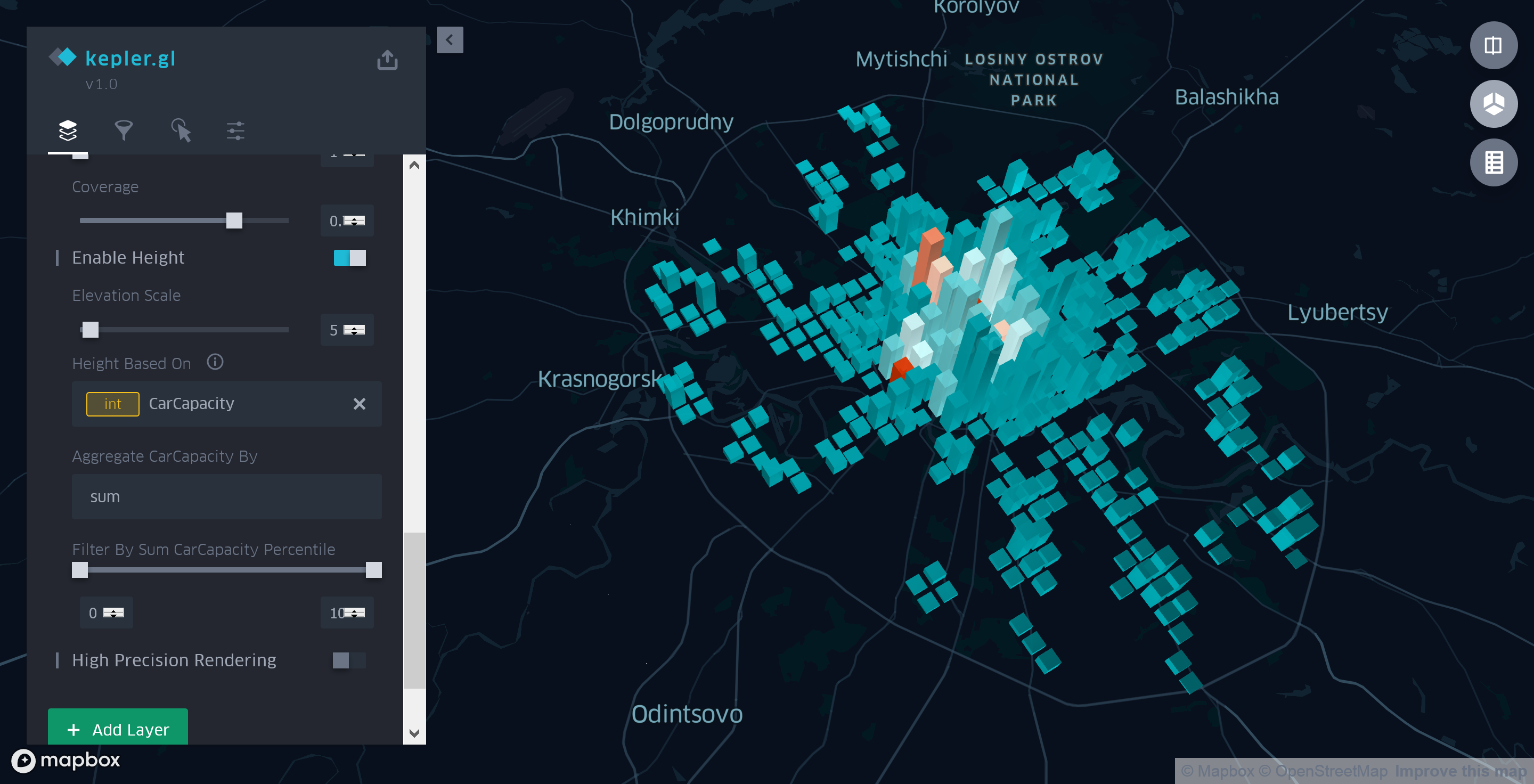
图6.有关停车成本和容量的一般信息
因此,在花了几分钟的时间设置聚集层之后,我们可以自信地说,在花园环内不仅停车位数量很多,而且实际停车位数量也比外面大得多。
结论
在本文中,使用一个特定示例,仅将Kepler.gl的部分功能视为用于可视化和对各种地理数据进行基本分析的现代工具。 如果您对此应用程序感兴趣,建议您也熟悉下面的文章和教程,并尝试进行数据过滤,设置工具提示和地图样式以及此应用程序的其他功能。
在下一篇文章中,我将向您介绍共享创建的可视化效果和地图的方法,以及将Kepler.gl用作Web应用程序的React组件。
有用的链接