今天的主题-坦克世界服务器的可靠性-相当滑。 游戏的可靠性需要权衡取舍,因此在游戏开发中需要快速完成所有工作。 服务器上的负载很大,用户往往会出于兴趣而破坏某些东西。 RIT ++的Levon Avakyan表示Wargaming正在采取什么措施来确保可靠性。
通常,当他们谈论可靠性时,总是会提到监视,压力测试等。 这没有什么超自然的,报告专门针对Tanks。

关于演讲者: Levon Avakyan在Wargaming担任WoT游戏服务和可靠性负责人,处理坦克服务器可靠性问题。
今天,我将讨论我们如何做到这一点,包括“坦克世界”服务器的用途,它的组成,所基于的内容,以便您了解对话的主题。 此外,我们将考虑服务器内部及其周围可能出问题的地方,因为游戏已不仅仅是服务器。 而且,我们还会讨论一些流程,因为许多人忘记了,在生产中建立完善的流程不仅会节省资源(许多实践都来自实际生产),而且是成功的一部分,但也会影响解决方案的质量和可靠性。

通常,当他们谈论可靠性时,总是会提及监视,压力测试等。 我没有在这里包括它,因为我觉得很无聊。 我们还没有发现任何超自然的东西。 是的,我们也有一个监控系统,我们通过压力测试进行压力测试,以提高系统的可靠性并知道它可能在哪里脱落。 但是今天,我将谈谈更具体的战车
大世界科技
这是一个后端引擎,也是用于创建MMO的工具包。
这个相当古老的BigWorld Server引擎(起源于90年代末-2000年代初)是一组支持游戏的不同进程。 流程在群集中启动,并在计算机网络中互连。 彼此交互,这些过程向用户展示了某种游戏机制。
该引擎之所以被称为BigWorld,是因为它非常适合在上面进行游戏,在该游戏中有很大的场地(空间),可以在上面进行军事行动(战斗)。 对于坦克,这非常适合。
在可靠性方面,BigWorld投资了以下关键功能:
- 负载均衡。 引擎分配资源,试图实现两个目标:
- 使用尽可能少的机器;
- 同时,请勿加载您的应用程序,以使其加载量超过一定限制。
- 可扩展性。 我们将汽车添加到集群中,并在其上启动了流程-这意味着您可以计算更多的战斗并接受玩家。
- 高可用性。 例如,如果一辆汽车跌倒了,或者服务于游戏本身的其中一个游戏过程出了问题,则无需担心-游戏不会注意到,可以在其他地方恢复运行。
- 保持数据完整性和一致性。 这是容错的第二级。 如果有多个集群(例如在Tanks中),并且在数据中心或主渠道中发生了某种灾难,这并不意味着我们将完全失去该人玩过的游戏数据。 我们将恢复,保持一致。
我们系统中的流程及其功能- CellApp是负责处理游戏空间或其一部分的过程。
就像我说的,BigWorld在某些划分为单元的空间中工作。 我们游戏空间的每个特定单元都是由特定应用计算得出的。
- CellAppMgr-协调CellApp工作,负载平衡的过程。
CellApp可以有很多,因此,必须有一个控制它们的过程。
- BaseApp管理实体,将客户端与CellApp隔离。
在BigWorld中,基本概念之一是实体的概念-例如玩家的帐户。 我们在战场上所做的一切,都是与这个实体一起进行的。 CellApps计算物理和游戏机制,例如射击。 BaseApp适用于实体。 它为帐户,坦克等服务。
- ServiceApp是专用的BaseApp,可实现某种服务。
这是BaseApp的简化版本,该过程可处理各种服务。 例如,某人应该能够阅读RabbitMQ。 这不是关于游戏实体,而是需要的。
- BaseAppMgr管理BaseApp和ServiceApp,因为它们也很多。
- LoginApp从客户端创建新连接,并在BaseApp上代理用户。
- DBApp实现了一个存储访问接口(数据库)。 我们使用Percona,但它可能是另一个数据库。
- DBAppMgr协调DBApp的工作。
- InterClusterMgr管理集群间通信。
- Reviewer是可以重新启动流程的流程检查器。
- 机加工 -在群集中的每台计算机上运行以协调其工作的守护程序。 它允许所有BaseApp管理员相互通信。
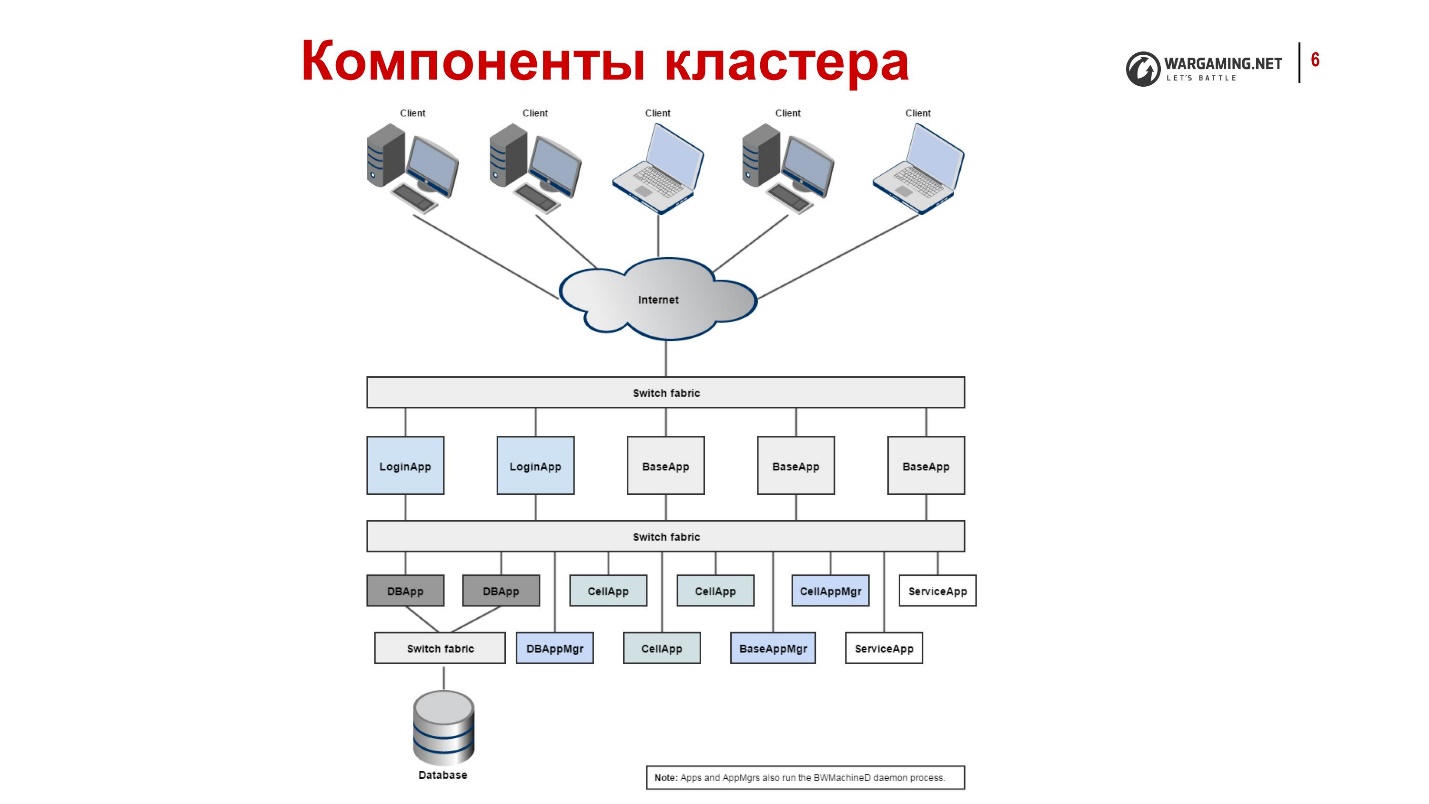
如果很简短,这就是Tanks从内部看的样子:
- 客户端通过Internet连接,进入LoginApp。
- LoginApp使用DBApp授权他们,并从BaseApp发出地址。
- 更多的顾客在玩他们。
所有这些都分散在许多机器上,每台机器都有一个BWMachineD,可以管理所有这些东西,协调等等。
坦克生态系统世界
周围是什么? 似乎有一个游戏服务器和玩家-选择一辆坦克,去玩。 但是,不幸的是(或快乐地),游戏正在发展,而“仅射击”的游戏机制已不再足够。 因此,游戏服务器开始充满了各种服务,其中某些服务通常在服务器内部是不可能完成的,而我们开始专门取出其他服务以提高向玩家提供内容的速度。 也就是说,用Python编写执行某种游戏机制的小型服务要比在所有BaseAPP,支持集群等服务器上进行的服务更快。
有些东西,例如支付系统最初是发行的。 我们忍受其他人,因为Wargaming毕竟开发了多个游戏。 这是三部曲:坦克,飞机,轮船,还有闪电战和新游戏计划。 如果它们在BigWorld内部,则无法方便地在其他产品中使用。
一切进行得非常迅速且混乱,这导致了我们的坦克生态系统中使用了一些动物园技术。
关键技术和协议:
1. Python 2.7、3.5;
2. Erlang;
3. Scala;
4. JavaScript;
构架
5. Django;
6.猎鹰;
7.异步
储存方式:
8. Postgres;
9. Percona。
10. Memcached和Redis用于缓存。
对于玩家来说,这就是坦克服务器:
- 单点授权;
- 聊天室
- 氏族;
- 付款系统;
- 比赛系统;
- 元游戏(全球地图,防御区);
- 坦克门户,战队门户;
- 内容管理等
但是,如果您看,这些是在不同技术上编写的稍有不同的东西。 这会导致一些可靠性问题。
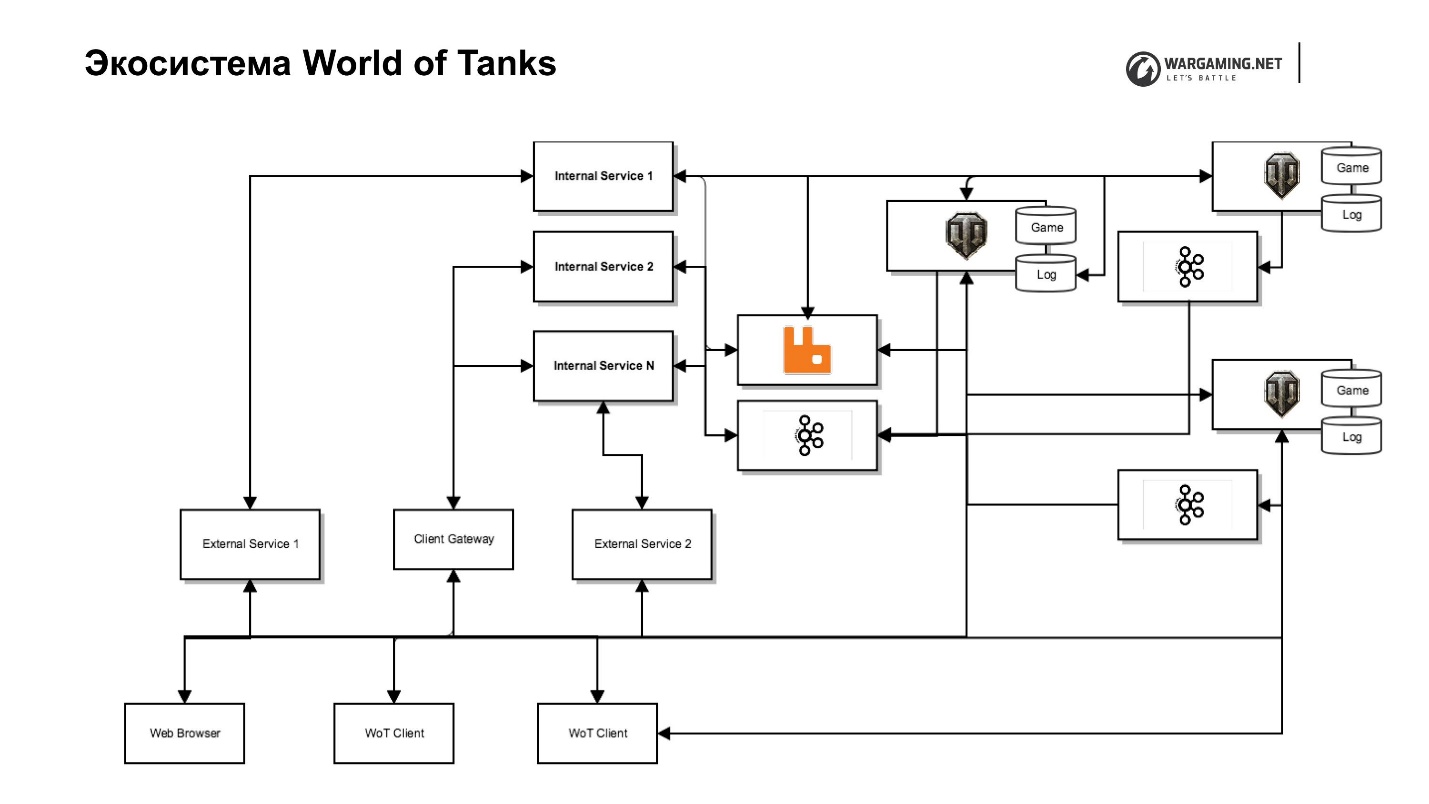
该图显示了我们的储罐服务器及其生态系统。 有一个游戏服务器,Web服务(内部和外部),包括完全特殊的服务,这些服务位于后端网络中并执行服务功能,并为其提供服务,这些服务实际上实现了接口。 例如,有一个带有自己的氏族门户的氏族服务,它允许您管理这个氏族,还有游戏本身的入口,等等。
这种分离使我们不必担心安全性,因为没有人可以访问内部网络-问题更少。 但是,这需要付出更多的努力,因为我们需要代理,如果需要将代理推向外部,它们将提供访问权限。
我已经说过,我们决定从服务器中删除一些游戏逻辑和其他内容。 有一项任务要以某种方式将所有内容包含在客户端中。 我们有一个很棒的客户端网关,它允许坦克客户端从这些内部服务的某些API(与我们的元游戏相同的氏族或API)直接访问服务器。
另外,我们在储罐客户端中推出了Chromium嵌入式框架(CEF)。 现在,我们使用相同的浏览器。 玩家没有将他与游戏窗口区分开。 这使您可以使用整个基础结构,而无需使用游戏服务器。
我们有很多集群-就是这样-我告诉你原因。 这就是独联体地区的样子。
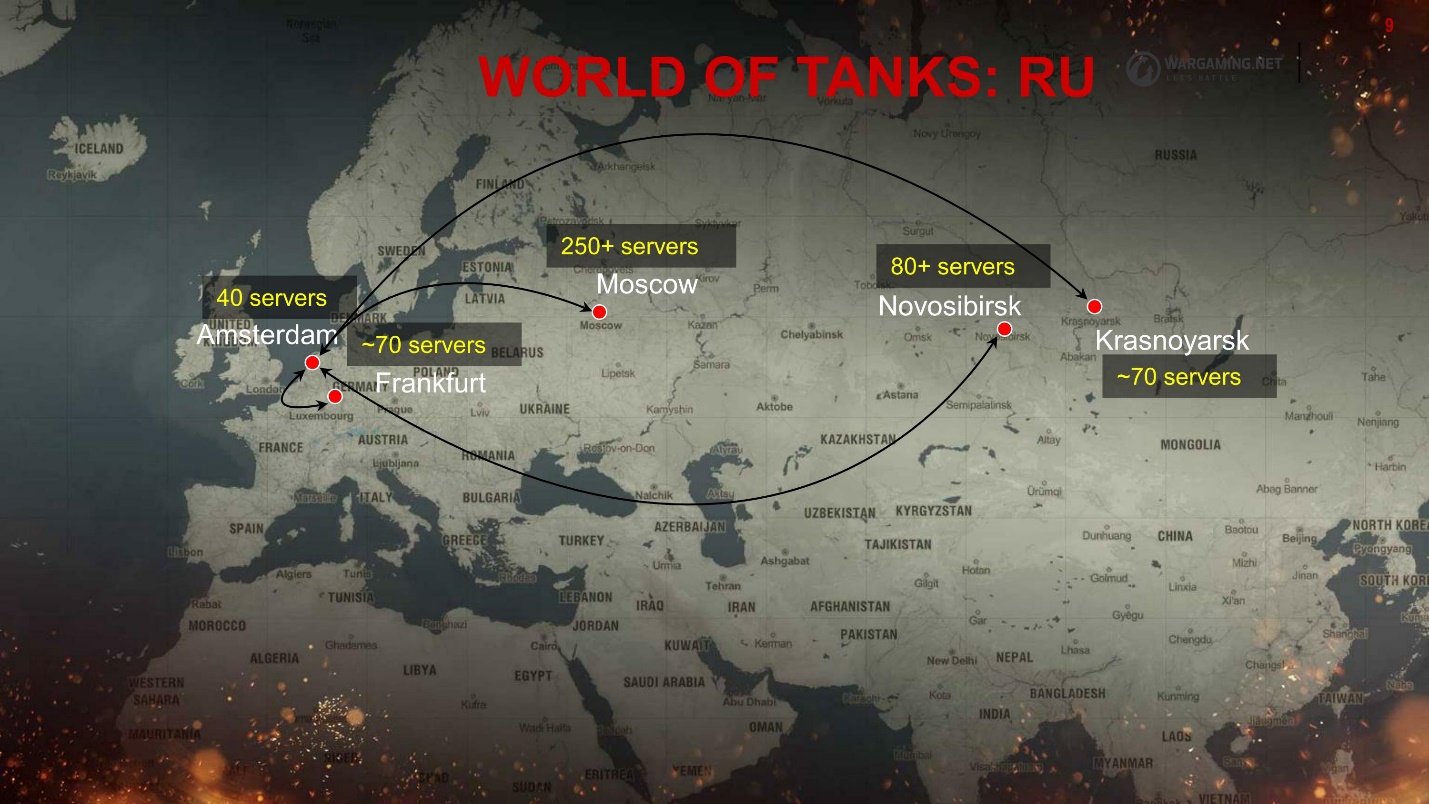
一切都分散在数据中心周围。 根据ping更好的位置,玩家可以连接到该位置。 但是整个生态系统并不能以这种方式扩展,主要是在欧洲和莫斯科,这也给我们增加了一些可靠性问题-额外的延迟和转发。
这就是《坦克世界》生态系统的外观。
所有这些经济状况可能出什么问题? 任何你想要的! 然后去J。但是让我们拆开它。
集群中的关键故障点
单个机器或过程失败
我们可以预测的最简单的选择是集群中一台机器或进程的故障。 我们拥有10到100辆汽车的集群-有些东西会飞出来。 正如我所说,BigWorld本身提供了开箱即用的机制,使我们更加可靠。
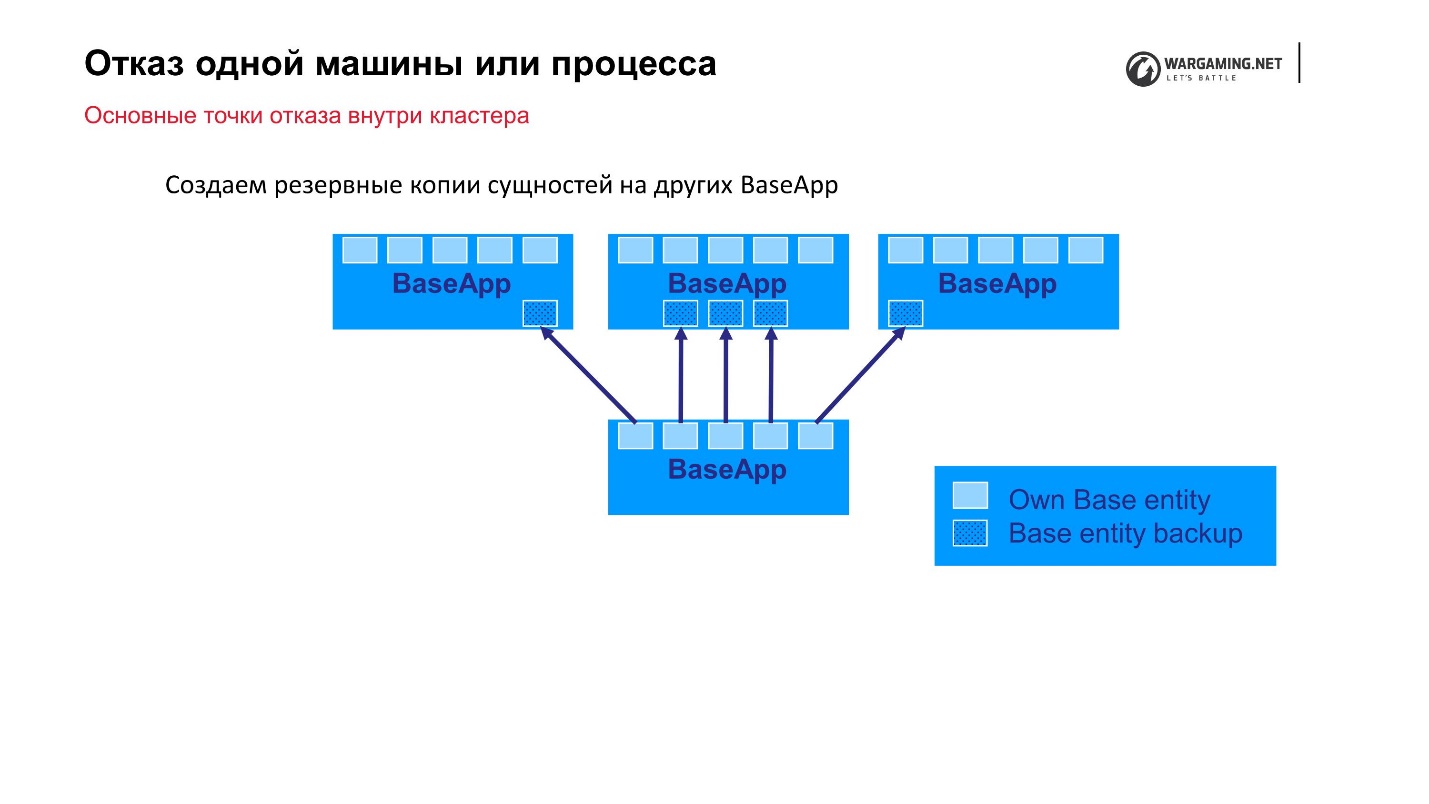
标准方案:有些BaseApps分布在不同的计算机上。 在这些BaseApp上,存在包含状态实体的实体。 每个BaseApp都使用Round Robin来备份自己。
假设我们有一个文件,一些BaseApp死了,或者整个机器都死了-没关系! 剩余的BaseApp离开了这些实体,它们将被恢复,并且玩家的游戏玩法不会受到影响。
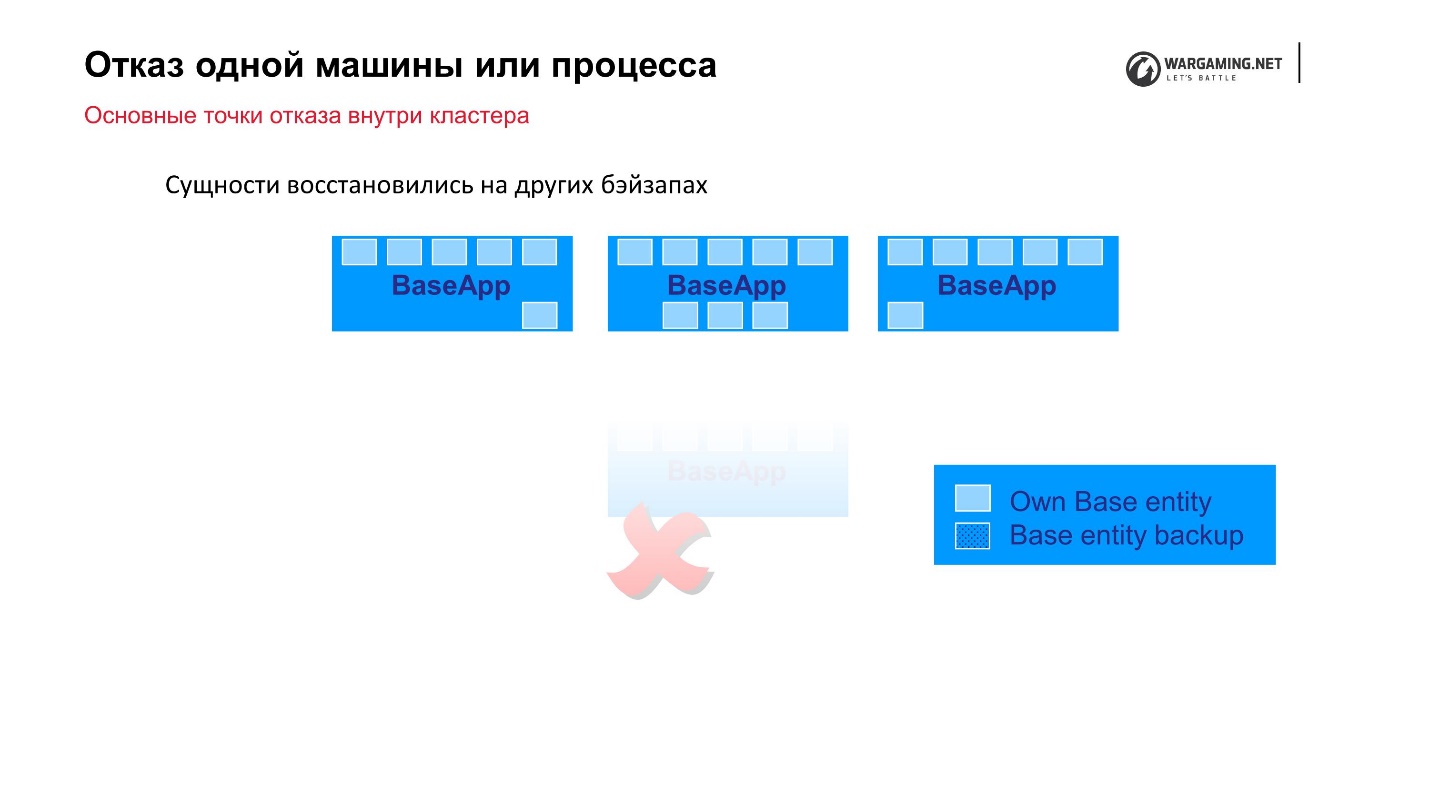
CellAPP执行完全相同的操作,唯一的是它们也将状态存储在BaseApp上,而不是在其他CellAPP上。
这似乎是一个可靠的机制,但是...
你必须付出一切
随着时间的流逝,我们开始观察以下内容。
•创建实体的备份副本开始占用越来越多的系统资源和网络流量。
实际上,当群集中的大多数网络都忙于将副本传输到Round Robins时,备份过程本身就开始影响系统的稳定性。
•随着新属性和游戏机制的添加,实体的大小会随着时间的推移而增长。
但是最不愉快的是这些实体的大小像雪崩般增长。 例如,玩家执行一些动作(购买游戏属性),并且此操作开始变慢。 我们尚未完成它,但已保存对这些属性的更改。 也就是说,系统非常糟糕,我们仍在开始增加需要完成的备份的大小。 有雪球效应。
•系统稳定性整体下降
由于我们正试图摆脱一台机器或一个进程的崩溃,因此我们降低了整个系统的稳定性。
我们做了什么处理呢? 我们决定让每个实体强调需要真正备份的内容。 我们将属性分为可变的和不可变的,并且不复制整个实体,但仅备份其可变的属性。 这样,我们仅减少了真正需要保留的信息量。 现在,在添加新属性时,执行此操作的人应该会更清楚地看到将属性归于何处。 但总的来说,这为我们节省了情况。
坦率地说,这种机制是在BigWorld中建立的,但是在Tanks中直到某个时候才不再支持该机制,并不是每个实体都可以从其备份中恢复。 例如,在《飞船》中,伙计们对此表示支持。 您可以在那里安全地关闭计算机-信息将仅在其他计算机上恢复,并且客户端不会注意到任何信息。 不幸的是,在Tanks中并非总是如此,但是我们将实现所有这些功能的返回,从而使其正常工作。
数据中心故障。 多集群
如果突然没有1-2辆赛车摔倒,而我们又开始失去整个数据中心,也就是整个集群,那么系统应该具有什么属性才能使游戏在这种情况下不会掉下去?
- 每个群集必须是独立的,即:
- 必须有自己的数据库;
- 集群仅处理其空间(战场)。
因此,如果某些领域受到打击,其他领域仍然有效。 - 集群必须彼此通信,以便一个可以对第二个说:“我摔倒了!” 上升时,将从保存的副本中还原数据。
- 还希望您可以将用户从一个群集转移到另一个群集。
目前,我们的多集群方案看起来像这样。
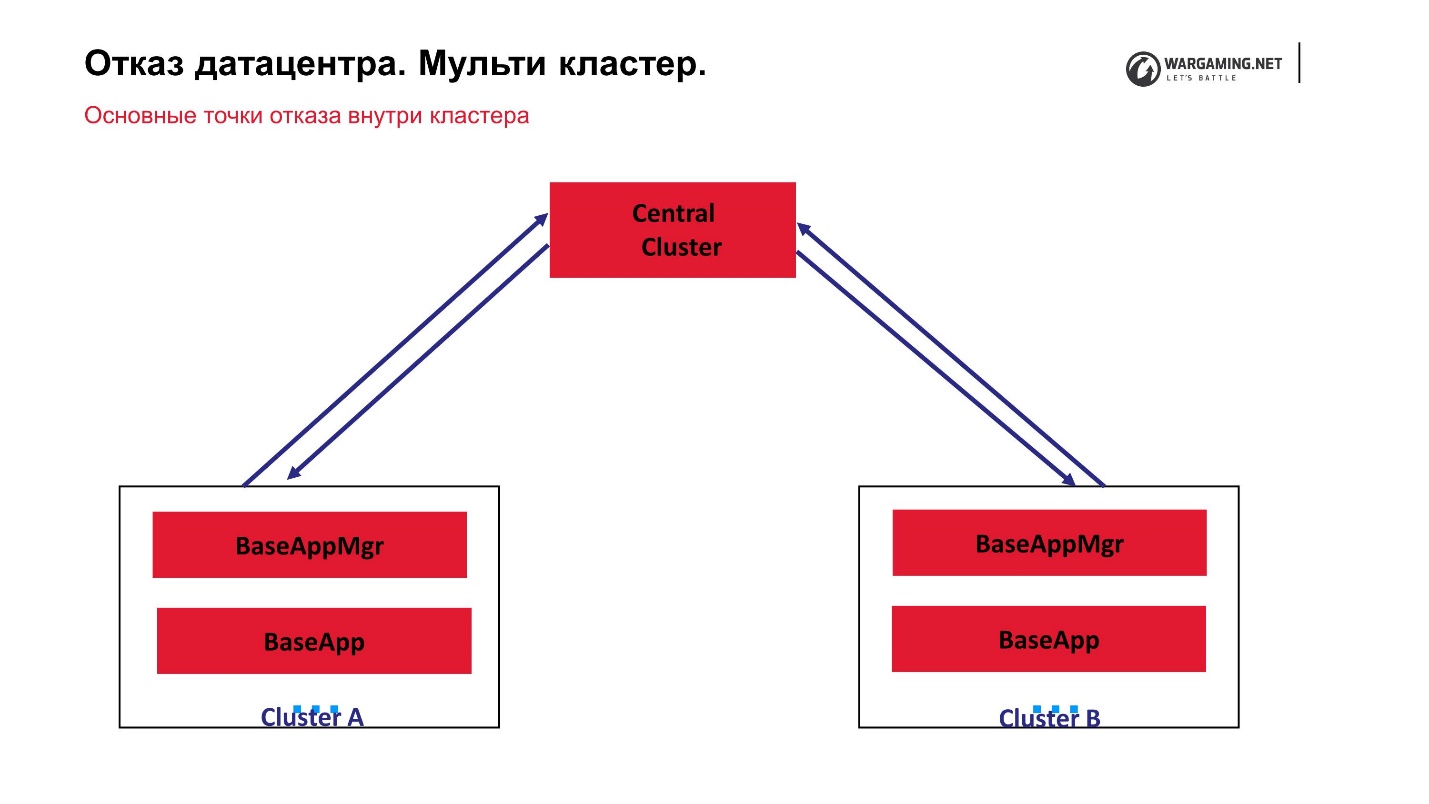
我们有一个中央集群和所谓的外围设备,在这些外围设备上进行了实际的战斗。 CellApp不在中央集群上运行,否则与其他所有人完全相同。 这是帐户处理的中心点:它们上升到那里,被发送到外围设备,并且在外围设备上已经有人在玩游戏。 也就是说,任何群集的故障都不会导致整个游戏的可操作性损失。 甚至中央集群的故障也根本不允许新玩家登录,但是已经在外围玩游戏的玩家可以继续游戏。
事实证明,所有事情都可以通过中央集群为我们工作,因为一般而言,BigWorld技术本身都假设有一个特殊的跨集群管理器管理流程。 实际上,这样的跨部门经理可以有所提高。
从历史上看,Tanks需要一个多集群,因为它开始在线上出现雪崩。 当我们达到20万名玩家的顶峰时,来自他们的传入流量就不再只是通过网络放置在数据中心中。 我们实际上必须屈服于某种解决方案,以便可以将播放器启动到多个数据中心。
实际上,我们只赢了,因为我们现在有了一个多集群。 它对玩家也很有用,因为ping(即通过网络的可访问性)会极大地影响游戏玩法。 如果延迟超过50-70 ms,则这已经开始影响游戏本身的质量,因为在Tanks中,绝对所有的事情都是在服务器上计算的。 客户端上没有任何计算。 因此,请记住,几乎没有任何事情可以做。 当然,在这里制作了一些mod,但是它们并不影响过程本身。 您可以尝试猜测会发生什么,但会影响游戏机制本身-不会。
由于这种方法,我们的
中央集群已成为故障点 。 一切都在他身上关闭。 我们决定-由于这些机器和大型游戏巢穴基地就在那儿,让我们的外围设备专门应对战斗。 这样一来,实际上就不需要存储大量信息了-正在进行战斗,正在进行战斗-让我们将所有内容都锁定在那里。
要完全重写所有内容以摆脱中央集群的概念,现在没有时间,没有特别的愿望。 但是我们首先决定教外围集群相互通信。 然后,我们看到了它们中的一个漏洞,以便可以使用第三方服务来影响它们。
例如,为了更早进行战斗,有必要告知中央集群,有必要在一些外围地区进行战斗。 此外,通过内部机制,实体得以移动,竞技场的本质得以创建,等等。
现在可以绕过中央集群直接接触外围设备。 因此,我们从他身上删除了多余的工作。 但是到目前为止,还不希望完全切换到所有集群几乎都是对等的方案,而所有这些都是由某些进程而不是集群控制的。
我提醒您,除了带有BaseApps,CellApps等游戏集群之外,我们还有一个生态系统。
我们试图确保生态系统的性能不会影响游戏玩法。 例如,在最坏的情况下,锦标赛系统不起作用,但是您可以随机玩-无论如何,大多数人都是随机玩。 是的,我们降低了质量,但是总的来说,您可以在没有比赛的情况下存活几个小时。
这并非总是会发生。 首先,已经有这样的Web服务深深地嵌入了游戏中。 例如,单个授权点是一项服务,它使您可以登录Web或某个地方的某个地方,并实际上登录到整个Wargaming Universe。
第二个示例是为游戏购买和交易提供服务的服务。 也必须将它带入游戏,因为我们需要跟踪玩家的购买情况。 事实是,在某些地区,我们有义务向客户显示有关用真钱购买了哪些游戏财产以及用钱购买了哪些游戏财产的信息。 该系统最初没有假设这一点,5年前没有人提出这一点,但是
法律很严格:您需要这样做-做到这一点 。
坦克世界生态系统故障点
问题编号1.增加负荷
我们有一个多集群,其中有10个集群以及大量的计算机。 玩家玩它们,网络很小。 没有人在每个数据中心再购买五台机器。 但是同时,我们在客户端内部提供了所有相同的功能以及所有需要的功能。 这是主要问题。
界面交互性和反应性是生态系统负荷增加的主要来源。
我将提供来自氏族服务的两个示例:
- 您想邀请其他玩家加入氏族。 当然,我希望被邀请者立即收到通知,他将可以加入您的行列。 为了实现这一点,有必要使氏族服务以某种方式通知客户端,或者让客户端不时询问Web服务:“有什么变化吗? 我有新邀请吗?” 这是额外负载可能来自的第一个选项。
- 坦克有强化的制度。 假设不是由一个人演奏,而是由多个人演奏。 所有玩家都有一个带有强化区域的开着的窗户。 指挥官盖了建筑物。 建议对于打开此窗口的每个人,立即显示该建筑物。
调查前额的决定不是很好。 实际上,它是有效的,只是您需要为此分配许多容量,因此该功能不会给公司带来任何利润。 而且,如果该功能没有带来利润,那么您就不需要这样做。
我对如何处理此问题的个人建议:使系统在负载下更可靠的最佳方法通常是从逻辑上减少负载。
您不应该沉迷于铁,想出新颖的系统,优化某些东西-一样,负载越大,就会出现更多您无法摆脱的东西。 此外,甚至在越来越低的抽象级别上也会出现工件-首先是应用程序,然后是不同的Web服务,然后您将进入网络(cisco等)。 在某种程度上,您根本无法解决问题。
如果您仔细考虑,就可以避免它们。
我们要做的第一件事是
学习如何使用
游戏服务器的基础结构
通过游戏服务器通知客户端 。 例如,当一个邀请到达氏族时,我们告诉服务器:“我们邀请了这样的人”,然后群集集群本身会找到应该向其发送通知的人,特别是因为他们已经建立了联系。 就是说,我们确实从服务中推动,但没有人不断地倾倒我们。 , , . , , .
—
Web-sockets (nginx-pushstream) . , Web-sockets. , Chromium Embedded Framework — , , Web-sockets Nginx. pushstream, Web-sockets .
№ 2.
, , ,
— . , , — .
, , .
? : - , - , , . - , , . .
.

,
120 Game Play . . , , . , . .
3 , :
- HTTP API;
- RabbitMQ — ;
- Apache Kafka .
, , , , , . , - — , . , .
1. HTTP— HTTP. , , -, . :
, , . , , , Django, 100 200 , API, . , , - 30-40 , , . , — .
, , HTTP, — . . — — . ,
, , , .
. . - , - API — API, .
— , . , , . , 10 , - 100 500. , HTTP . nginx' , — .
, HTTP , .
2. RabbitMQRabbitMQ BigWord .
— - , , , .
: . , API: « N — ». , , , , — . , .
«», «», — .
RabbitMQ , , , , , , , .
— RabbitMQ .
3. Kafka, , — Kafka. , RabbitMQ - .
, , , . , , . . Kafka. , — , .
, . , , - — .
Kafka , , , - , . .
— .

:
- . , - , ..
- — , , , .
- — , . , , .
. , , , entity. . , , .
DLC
, DLC (Development Lifecycle) — , , .
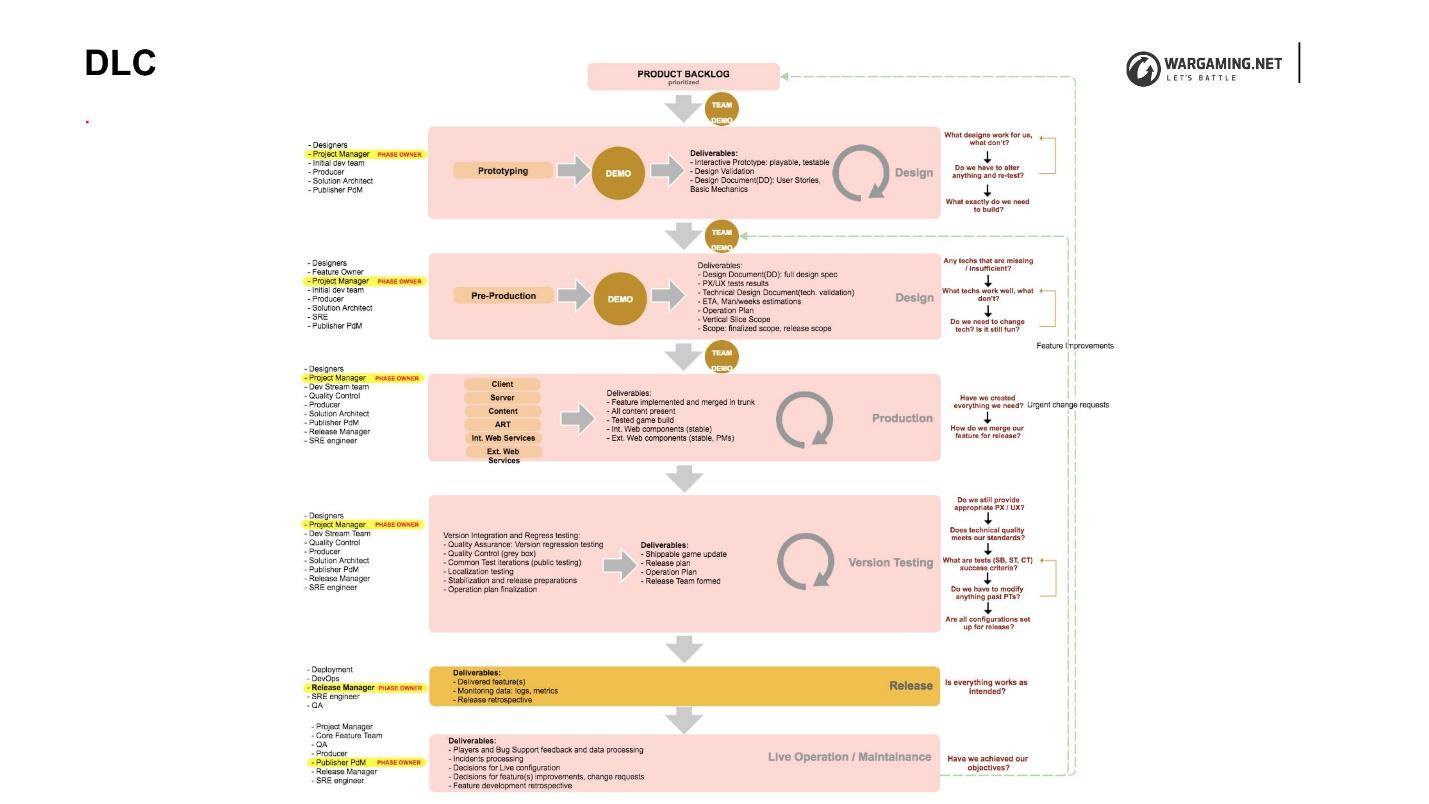
, , . DLC , , . , . , , , .
DLC, . , , , .
DLC, , :
•
( )., , «- , », . , , , , .
• : SRE.
, solution-, technical-owner, reability- — , - , game- . , , , . - , , , , . , .
•
SRE .— - . , . , SRE -. SRE , : « , , , — !» , .
QA , , - , , — .
BigWorld Technology «» . , . . « », .
« » , , . — «» (, ) — . , . , - .
: ++. , 40 , . , .RootConf — DevOpsConf Russia . DevOps 1 2 , . , . , — !