“ @Cloudflare团队刚刚进行了更改,这些更改显着改善了我们的网络性能,尤其是对于最慢的请求。 快多少? 我们估计,我们每天可以节省大约54年的Internet时间,否则这些时间将花费在等待网站加载上 。
” -Matthew Prince
tweet ,2018年6月28日
1000万个站点,应用程序和API使用Cloudflare来加快用户的内容下载。 高峰时,我们每秒在151个数据中心处理超过1000万个请求。 多年来,为了应对增长,我们对Nginx版本进行了许多更改。 本文介绍的是这些更改之一。
Nginx如何运作
Nginx是使用事件处理循环解决
C10K问题的程序之一 。 每次网络事件到达时(新的连接,发送大量数据的请求或通知等),Nginx都会唤醒,处理该事件,然后返回到另一个作业(可能正在处理其他事件)。 当事件到达时,它的数据就准备好了,这使您可以有效地处理许多同时发生的请求,而无需停机。
num_events = epoll_wait(epfd, events, events_len, -1); // events is list of active events // handle event[0]: incoming request GET http://example.com/ // handle event[1]: send out response to GET http://cloudflare.com/
例如,这是一段代码从文件描述符读取数据的样子:
// we got a read event on fd while (buf_len > 0) { ssize_t n = read(fd, buf, buf_len); if (n < 0) { if (errno == EWOULDBLOCK || errno == EAGAIN) { // try later when we get a read event again } if (errno == EINTR) { continue; } return total; } buf_len -= n; buf += n; total += n; }
如果fd是网络套接字,则将返回已经接收的字节。 最后一次调用将返回
EWOULDBLOCK 。 这意味着本地读取缓冲区已结束,在出现数据之前,您不再应该从此套接字读取数据。
磁盘I / O与网络不同
如果fd在Linux上是常规文件,则
EWOULDBLOCK和
EAGAIN永远不会出现,并且即使使用
O_NONBLOCK打开了文件,读操作也始终等待读取整个缓冲区。 如
公开(2)手册中所述:
请注意,该标志对于常规文件和块设备无效。
换句话说,上面的代码实质上简化为:
if (read(fd, buf, buf_len) > 0) { return buf_len; }
如果处理程序需要从磁盘读取,则它将阻塞事件循环,直到读取完成,随后的事件处理程序将等待。
对于大多数任务来说,这是正常的,因为从磁盘读取通常比等待网络中的数据包快得多,并且可预测性强。 特别是现在每个人都有一个SSD,而我们所有的缓存都在SSD上。 在现代SSD中,延迟非常小,通常为数十微秒。 此外,您可以在多个工作流程中运行Nginx,以便慢速事件处理程序不会阻止其他进程中的请求。 大多数时候,您可以依靠Nginx快速有效地处理请求。
SSD性能:并非始终如愿
您可能已经猜到过,这些乐观的假设并不总是正确的。 如果每次读取始终花费50μs,则以4 KB的块读取0.19 MB(我们读取的块甚至更大)将仅花费2 ms。 但是测试表明,到第一个字节的时间有时会更糟,尤其是在第99和999个百分位数中。 换句话说,每100个(或1000个)读数中最慢的读数通常需要更长的时间。
固态驱动器非常快,但以其复杂性而闻名。 他们在该队列中拥有计算机并对I / O进行重新排序,还执行各种后台任务,例如垃圾收集和碎片整理。 有时,请求会明显减慢。 我的同事
Ivan Bobrov启动了多个I / O基准,并记录了长达1秒的读取延迟。 此外,我们的某些SSD比其他SSD具有更高的性能峰值。 将来,在购买SSD时,我们将考虑这一指标,但是现在,我们需要为现有设备开发解决方案。
使用SO_REUSEPORT均匀的负载分配
很难避免每1000个请求有一个缓慢的响应,但是我们真正不希望的是将剩余的1000个请求阻塞一整秒。 从概念上讲,Nginx可以并行处理许多请求,但一次只能启动1个事件处理程序。 因此,我添加了一个特殊的指标:
gettimeofday(&start, NULL); num_events = epoll_wait(epfd, events, events_len, -1); // events is list of active events // handle event[0]: incoming request GET http://example.com/ gettimeofday(&event_start_handle, NULL); // handle event[1]: send out response to GET http://cloudflare.com/ timersub(&event_start_handle, &start, &event_loop_blocked);
第99个百分点(p99)
event_loop_blocked超过了TTFB的50%。 换句话说,服务请求的一半时间是其他请求阻塞事件处理周期的结果。
event_loop_blocked仅测量一半的锁定(因为未测量对
epoll_wait()未决调用),因此实际的阻塞时间比率要高得多。
我们的每台机器都通过15个工作流程运行Nginx,即一个缓慢的I / O将阻止不超过6%的请求。 但是事件并不是平均分配的:主要工作人员收到11%的请求。
SO_REUSEPORT可以解决分布不均的问题。 Marek Maikovsky先前曾在其他Nginx实例的上下文中
描述过此方法的
缺点 ,但是在这里您几乎可以忽略它:上游缓存连接是持久的,因此您可以忽略打开连接时延迟的轻微增加。 仅通过激活
SO_REUSEPORT更改此配置,从而将p99峰值提高了33%。
将read()移到线程池:不是灵丹妙药
解决方案是使read()无阻塞。 实际上,此功能是
在普通Nginx中实现的 ! 使用以下配置,在线程池中执行read()和write(),并且不会阻塞事件循环:
aio threads; aio_write on;
但是我们测试了这种配置,并没有将响应时间提高33倍,而是注意到p99仅有很小的变化,差异在误差范围之内。 结果非常令人沮丧,因此我们暂时推迟了此选项。
Nginx开发人员之类的原因使我们没有取得重大改进的原因有很多。 在测试中,他们使用200个并发连接来向HDD请求4 MB的文件。 温彻斯特具有更多的I / O延迟,因此优化效果更大。
此外,我们主要关注p99(和p999)的性能。 优化平均延迟不一定解决峰值发射问题。
最后,在我们的环境中,典型的文件大小要小得多。 90%的缓存命中小于60KB。 文件越小,阻塞的情况就越少(通常我们通过两次读取来读取整个文件)。
让我们看一下在缓存中命中时的磁盘I / O:
// https://example.com 0xCAFEBEEF fd = open("/cache/prefix/dir/EF/BE/CAFEBEEF", O_RDONLY); // 32 // , "aio threads" read(fd, buf, 32*1024);
并非总是读取32K。 如果标头很小,则只需要读取4 KB(我们不直接使用I / O,因此内核舍入为4 KB)。
open()似乎无害,但实际上占用了资源。 内核至少应检查文件是否存在以及调用进程是否具有打开文件的权限。 他需要找到
/cache/prefix/dir/EF/BE/CAFEBEEF ,为此,他必须在
/cache/prefix/dir/EF/BE/寻找
CAFEBEEF 。 简而言之,在最坏的情况下,内核执行以下搜索:
/cache /cache/prefix /cache/prefix/dir /cache/prefix/dir/EF /cache/prefix/dir/EF/BE /cache/prefix/dir/EF/BE/CAFEBEEF
这些是
open()产生的6个独立读取,而1个
read() ! 幸运的是,在大多数情况下,搜索属于
Dentry缓存,而没有到达SSD。 但是很明显,在线程池中处理
read()只是图片的一半。
最后的和弦:线程池中的非阻塞open()
因此,我们对Nginx进行了更改,以便
open()主要在线程池内部执行,并且不会阻塞事件循环。 这是来自非阻塞open()和read()同时的结果:
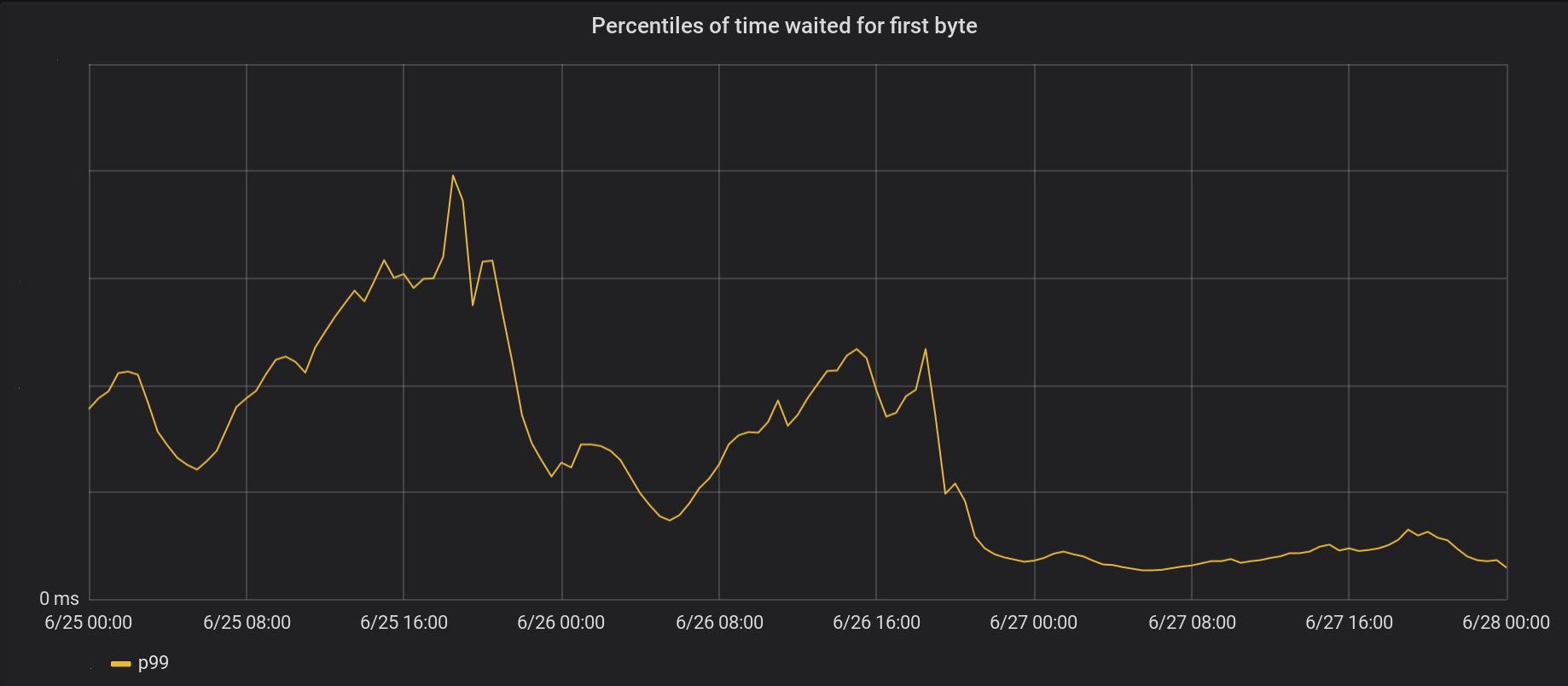
6月26日,我们将更改范围扩展到了5个最繁忙的数据中心,并于第二天将更改扩展到了全球所有其他146个数据中心。 总峰p99 TTFB降低了6倍。 实际上,如果我们始终总结每秒处理800万个请求的时间,则每天可以节省54年的Internet等待时间。
我们的一系列活动尚未完全摆脱困境。 特别是在第一次缓存文件(
open(O_CREAT)和
rename() )或更新重新验证时,仍然会发生阻塞。 但是与高速缓存访问相比,这种情况很少见。 将来,我们将考虑将这些元素移至事件处理循环之外以进一步改善延迟因子p99的可能性。
结论
Nginx是一个功能强大的平台,但是扩展极高的Linux I / O负载可能是一项艰巨的任务。 标准Nginx可以分流读取单独线程中的数据,但是就我们而言,我们经常需要更进一步。