这是一个有关将JavaScript移植到UniPro的国内Elbrus平台的故事。 本文提供了对平台,流程细节和陷阱的简要比较分析。

本文基于Dmitry(
dbezheckov )Bezhetskov和Vladimir(
volodyabo )Anufrienko与HolyJS 2018 Piter的报告。 在剪切下,您将找到报告的视频和文本成绩单。
第1部分。Elbrus,最初来自俄罗斯
首先,我们将了解Elbrus是什么。 与x86相比,以下是该平台的一些关键功能。
VLIW架构
与超标量体系结构完全不同的体系结构解决方案,现在在市场上更普遍。 由于Elbrus具有对所有独立算术逻辑设备(ALU)的明确控制,VLIW允许您在代码中更精细地表达意图,顺便说一下,Elbrus具有4。这不排除某些ALU停机的可能性,但仍将理论性能提高了一个时钟周期处理器。
团队捆绑
就绪的处理器命令组合在捆绑包中(捆绑包)。 一束是每条条件时钟执行的一条大指令。 它具有许多原子指令,这些指令在Elbrus架构中立即独立执行。

在右侧的图像中,灰色矩形表示通过处理左侧的JS代码获得的包。 如果使用ldd,fmuld,faddd,fsqrts指令几乎一切都清晰了,那么对于不熟悉Elbrus汇编器的人来说,第一个软件包开始时的return语句会令人惊讶。 该指令可将当前floatMath函数的返回地址提前加载到ctpr3寄存器中,以便处理器可以设法下载必要的指令。 然后,在最后一个包中,我们已经转换到ctpr3中的预加载地址。
还值得注意的是,Elbrus具有更多的寄存器192 + 32 + 32,而x86为16 + 16 +8。
显式推测与隐式
Elbrus在命令级别支持明确的推测性。 因此,如右图所示,我们甚至可以在检查a.bar不为null之前从内存中调用并加载它。 如果最后逻辑上的读取结果无效,则b中的值将被简单地标记为硬件错误,并且将无法访问它。

有条件的执行支持
Elbrus还支持条件执行。 在下面的示例中考虑这一点。

正如我们所看到的,由于使用了将条件表达式卷积为依赖关系,而不是通过控制,而是通过数据,从而减少了前面示例中有关投机性的代码。 Elbrus硬件支持谓词寄存器,在其中只能存储两个true或false值。 它们的主要特征是您可以使用这样的谓词标记指令,并且根据执行时其值的不同,指令是否执行。 在此示例中,cmpeq指令执行比较并将其逻辑结果放入谓词P1中,然后将其用作标记,以将b中的值加载到结果中。 因此,如果谓词等于true,则值0保留在结果中。
这种方法使您可以将相当复杂的程序控制图转换为谓词执行,并因此增加捆绑包的完整性。 现在我们可以根据不同的谓词组建更多独立的团队,并用捆绑包填充它们。 Elbrus支持32个谓词寄存器,允许您对65个控制流进行编码(如果命令中没有谓词,则添加一个)。
三种硬件堆栈与英特尔中的一种相比
其中两个受到程序员的保护,不得修改。 一个-链栈-负责存储函数返回的地址,另一个-寄存器栈-包含传递它们的参数。 第三个-用户堆栈-存储用户变量和数据。 在intel中,所有内容都存储在一个堆栈中,这会引起漏洞,因为所有转换地址,参数都位于一个不受用户修改保护的位置。
没有动态分支预测器
而是使用具有if-conversion和transition准备的方案,以使执行管道不会停止。
那么,为什么我们需要Elbrus上的JS?
- 进口替代。
- Elbrus向家用计算机市场的介绍,其中同一浏览器已经需要Javascript。
- 例如,Node.js在行业中已经需要Elbrus。 因此,您需要将Node移植到该体系结构。
- Elbrus体系结构的开发以及该领域的专家。
如果没有解释器,则有两个编译器
Google以前的v8实施作为基础。 它的工作方式是这样的:从源代码创建一个抽象语法树,然后根据是否执行该代码,分别使用两个编译器(Crankshaft或FullCodegen)之一来创建优化或未优化的二进制代码。 没有翻译。

FullCodegen如何工作?
语法树的节点将转换为二进制代码,然后将所有内容“粘合”在一起。 一个节点在一个宏汇编器中大约包含300行代码。 首先,这提供了广泛的优化视野,其次,没有解释器中的字节码转换。 这很简单,但是同时存在一个问题-在移植期间,您将不得不在宏汇编器中重写很多代码。
尽管如此,所有这些都完成了,结果是Elbrus的FullCodegen 1.0编译器版本。 一切都是通过C ++运行时v8完成的,他们没有进行任何优化,只是将汇编代码从x86重写为Elbrus架构。
Codegen 1.1
结果,结果与预期的并不完全相同,因此决定发布FullCodegen 1.1:
- 用宏汇编器编写的代码减少了运行时间;
- 添加了手动if-conversions(在图中,例如,检查js变量为true或false);

请注意,一次检查NaN,undefined,null无需使用if,这在Intel体系结构中是必需的。
- 该代码不仅由Intel重写,而且在存根中实现了推测性,并且还通过MAsm(宏汇编器)实现了快速路径。
测试在Google Octane中进行。 测试机器:
- Elbrus:E2S 750 MHz,24 GB
- 英特尔:酷睿i7 3.4 GHz,16 GB
进一步的结果:

直方图上是结果的比率,即 Elbrus比Intel差多少倍? 在两个测试(Crypto和zlib)上,由于Elbrus尚无用于加密的硬件说明,因此结果明显较差。 通常,考虑到频率的差异,结果非常好。
下面是与firefox的js解释器进行比较的测试,它是标准Elbrus发行版的一部分。 多多益善。
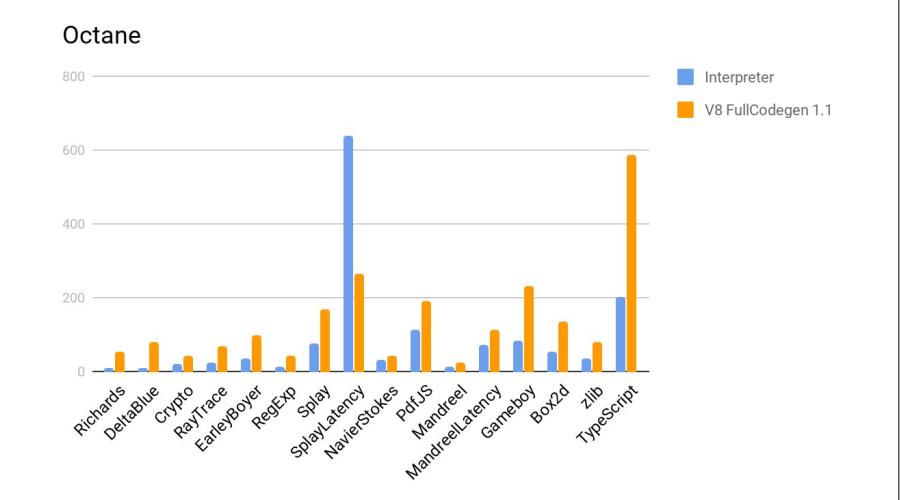
结论-编译器再次做得很好。
发展成果
- 新的JS引擎通过了test262测试。 这赋予了它被称为成熟的运行时环境ECMAScript 262的权利。
- 与以前的引擎-解释器相比,生产率平均提高了五倍。
- Node.js 6.10也被移植为使用V8的示例,因为这并不困难。
- 但是,它仍然比FullCodegen上的Core i7差七倍。
似乎没有什么预兆
一切都很好,但是Google在这里宣布不再支持FullCodegen和Crankshaft,它们将被删除。 之后,该团队收到了Firefox浏览器的开发订单,以后还会有更多开发订单。

第2部分。Firefox及其蜘蛛猴
关于Firefox浏览器引擎-SpiderMonkey。 在图中,该引擎与更新的V8之间的区别。
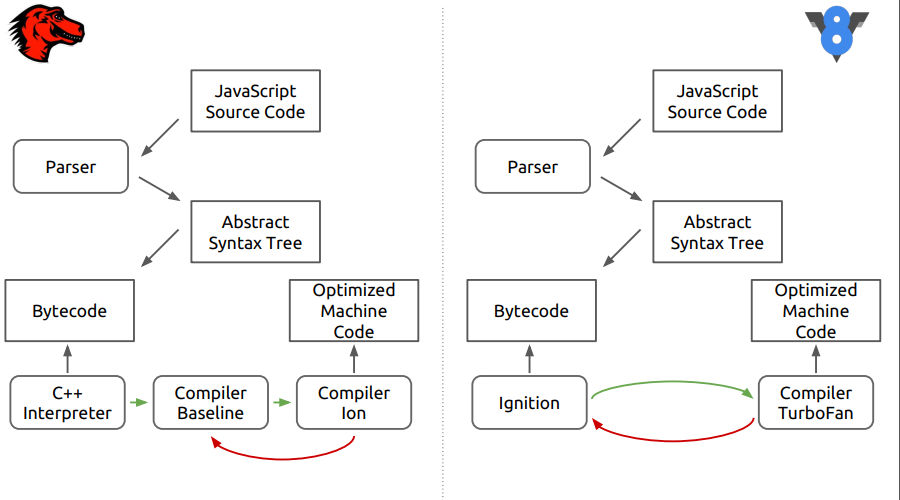
可以看出,在第一阶段,一切看上去都像将源代码解析为抽象语法树,然后解析为字节码,然后开始区别。
在SpiderMonkey中,字节码由C ++解释器解释,该解释器本质上类似于一个大型开关,在其中进行字节码跳转。 此外,解释后的代码进入了新的编译器基准。 然后,在最后阶段,将优化编译器Ion包含在该案例中。 在V8引擎中,字节码由Ingnition解释器处理,然后由TurboFan编译器处理。
基线,我选择你!
移植从Baseline编译器开始。 它本质上是一台堆叠式机器。 也就是说,有一个特定的堆栈,他从该堆栈中获取变量,记住它们并对其执行一些操作,然后他将变量和操作结果都返回到堆栈的单元中。 下面的几张图相对于简单函数foo逐步展示了这种机制:
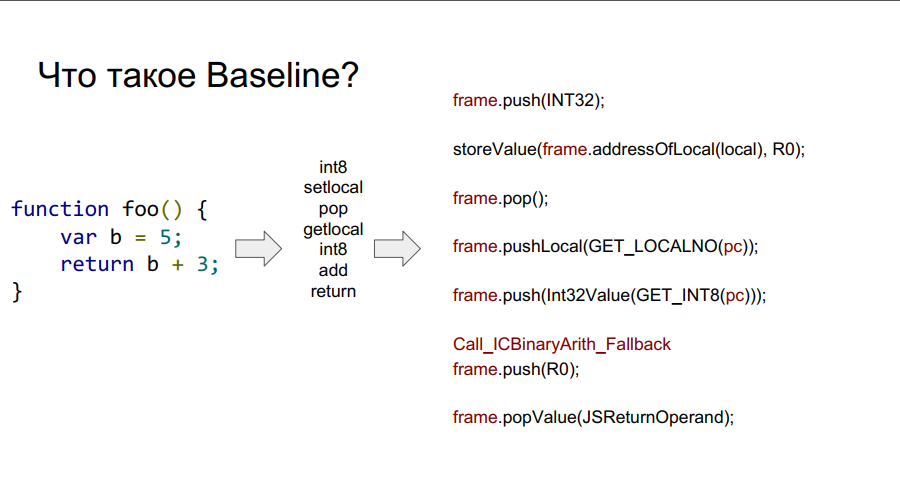


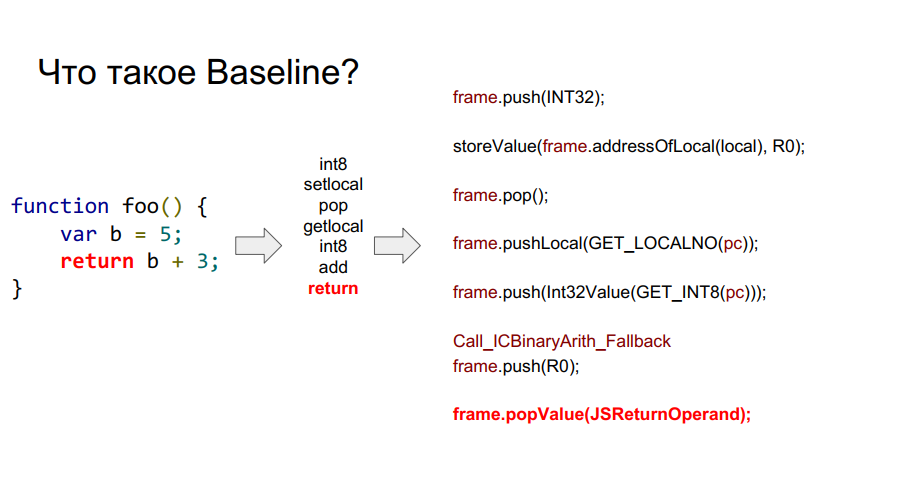
什么是镜框?
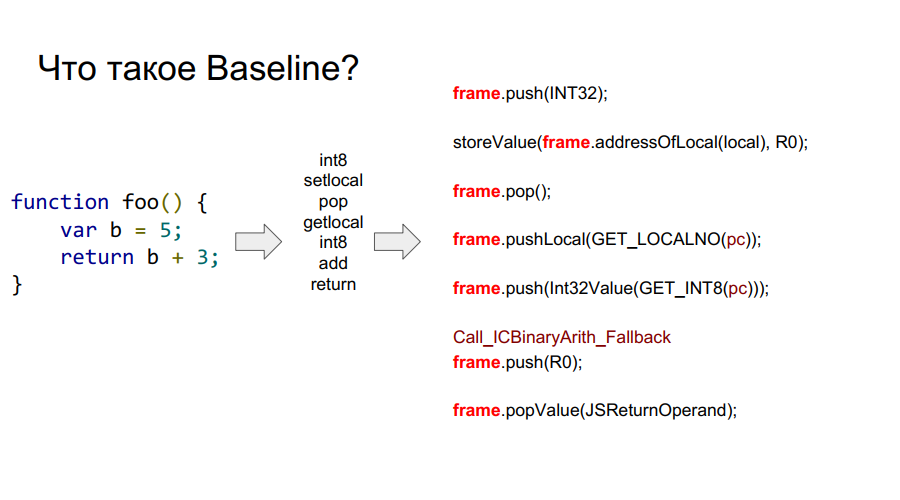
在上图中,您可以看到单词框架。 粗略地说,这是硬件上的Javascript上下文,即堆栈上描述任何功能的数据集。 在下图中,函数为foo,在其右侧为堆栈上的样子:参数,函数说明,返回地址,前一帧的指示,因为该函数是从某处调用的,并且为了正确返回到调用的位置,应将该信息存储在其中堆栈,然后局部变量本身使用函数和操作数进行计算。

因此,
基准的
优势 :
- 看起来像FullCodegen,所以他的移植经验派上了用场;
- 移植汇编器,得到一个可以工作的编译器;
- 调试方便;
- 任何存根都可以重写。
但是也有
缺点 :
- 线性代码,直到执行一个字节代码,您将无法执行以下代码,这对于具有并行计算的体系结构不是很好;
- 由于它可以与字节码一起使用,因此您实际上并没有进行优化。
只剩下实现宏汇编程序并获得现成的编译器了。 调试工作并不顺利,仅查看x86体系结构上的堆栈,然后再进行移植以查找问题时获得的堆栈就足够了。
结果,在使用新编译器进行的测试中,生产率提高了三倍:

但是,Octane不支持例外。 它们的实现非常重要。
出色的工作
首先,让我们看看异常如何在x86上工作。 程序运行时,函数的返回地址被写入堆栈。 在某些时候,会发生异常。 我们传递给运行时异常处理程序,该处理程序使用上面讨论的框架。 我们找到确切发生异常的位置,之后我们需要将堆栈倒回所需的状态,然后将返回地址更改为将要处理异常的地址。
问题在于,由于Elbrus体系结构上的另一个堆栈设备,此方法不起作用。 有必要通过系统调用来计算在链堆栈中需要倒带多少。 接下来,我们进行系统调用以获取调用堆栈。 接下来,在链堆栈中的地址中,我们替换返回地址的地址。
下面是这些步骤的顺序说明。

不是最快的方法,但是,可以处理异常。 但是,在Intel上,它看起来要简单一些:

使用Elbrus,处理程序将有更多跳转:

这就是为什么您不应该将程序逻辑基于异常,尤其是Elbrus。
优化它!
因此,实现了异常处理。 现在,我们将告诉您如何更快地完成所有操作:
- 手动(然后自动)安排延误;
- 他们为过渡做准备(代码越高):过渡越早准备越好;
- 支持的增量垃圾收集器
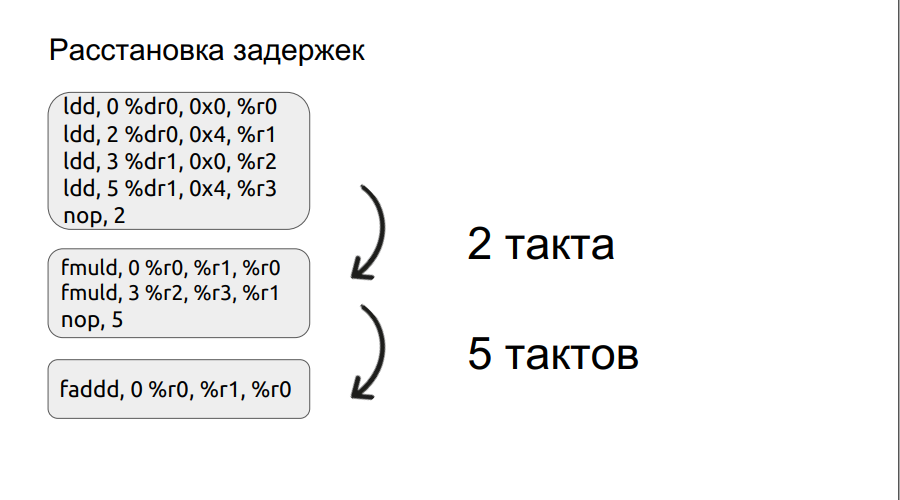
第二段将详细介绍。 我们已经研究了使用捆绑软件的一个小例子,我们将继续进行下去。

任何操作(例如加载)都不会在一个周期内完成,在这种情况下,它会在三个周期内完成。 因此,如果我们想将两个数字相乘,我们进入了乘法运算,但是操作数本身尚未加载,处理器只能等待它们加载。 他将等待一定数量的措施,是四项措施的倍数。 但是,如果您手动设置延迟,则可以减少等待时间,从而提高性能。 此外,安排延误的过程是自动化的。
优化结果BaseLine v1.0与Baseline v1.1。 当然,引擎变得更快了。

程序员如何不制造离子枪?
在实现Baseline v1.1的成功浪潮中,决定移植优化编译器Ion。

优化的编译器如何工作? 解释源代码,开始编译。 在执行字节码的过程中,Ion会收集有关程序中使用的类型的数据,并分析“热功能”-这些功能比其他功能执行得更多。 之后,将决定对它们进行更好的编译,优化。 接下来,构建编译器的高级表示,即操作图。 优化图形(选项1,选项2,选项...),创建一个低级表示,包括机器指令,保留寄存器,并生成直接优化的二进制代码。
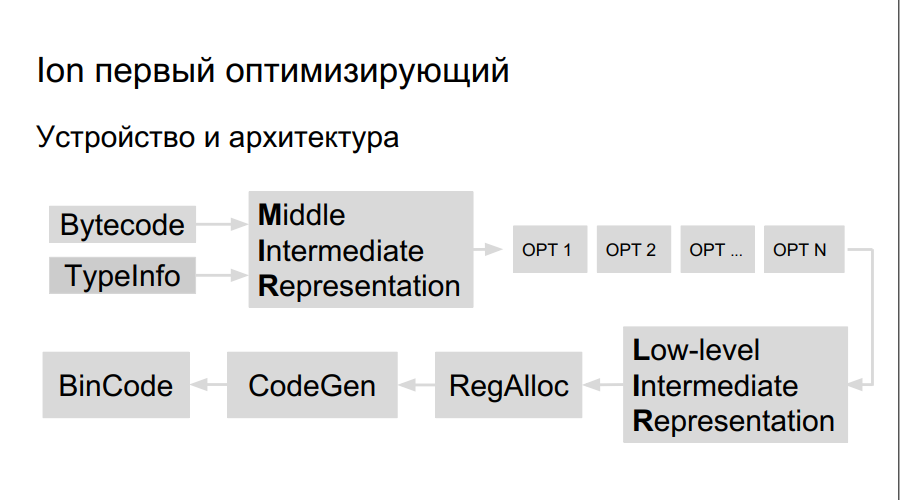
Elbrus上的寄存器更多,并且团队本身很大,因此我们需要:
- 团队策划人
- 自己的寄存器分配器;
- 自己的LIR(低级中间代表);
- 自己的代码生成器。
该团队已经有将Java移植到Elbrus的经验,他们决定使用相同的库来生成代码以移植Ion。 她叫TANGO。 它具有:
仍然需要在TANGO中引入高级表示,以使选择器成为可能。 问题在于,TANGO中的低级视图就像汇编器一样,难以维护和调试。 编译器内部应该是什么样? 为了更好地理解,Mozilla制作了自己的HolyJit编译器;还可以选择编写自己的迷你语言,以在高级和低级表示形式之间进行转换。
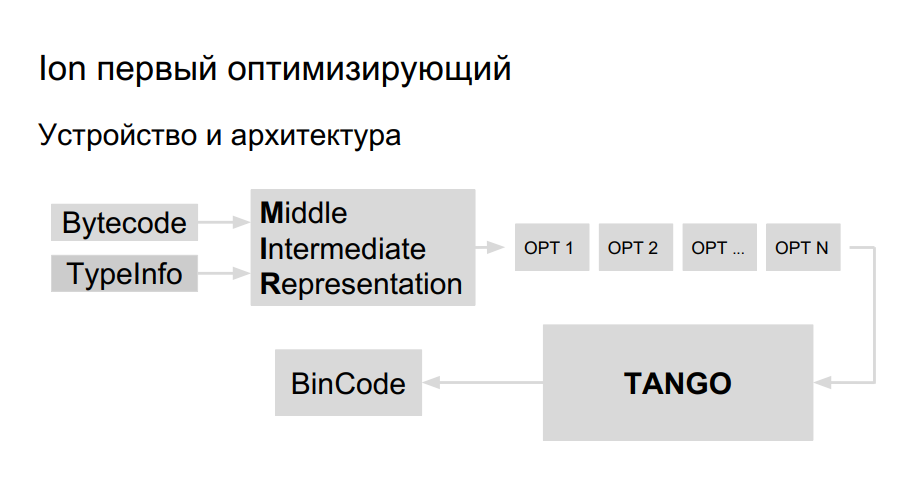
发展仍在进行中。 好吧,进一步探讨如何不通过优化来过度使用它。
第三部分。最好是善的敌人
原样编译
当代码变热然后进行编译和优化时,Ion中的优化过程非常贪婪,可以在下面的示例中看到。
function foo(a, b) {
return a + b;
}
function doSomeStuff(obj) {
for (let i = 0; i < 1100; ++i) {
print(foo(obj,obj));
}
}
doSomeStuff("HollyJS");
doSomeStuff({n:10});
JS Shell ( ), Mozilla, :

. , , - bailout (). , . foo object, , , . , :
function doSomeStuff(obj) {
for (let i=0; i < 1100; ++i) {
if (!(obj instanceof String))
print(foo_only_str(obj, obj));
}
}
, .
. , , DCE.
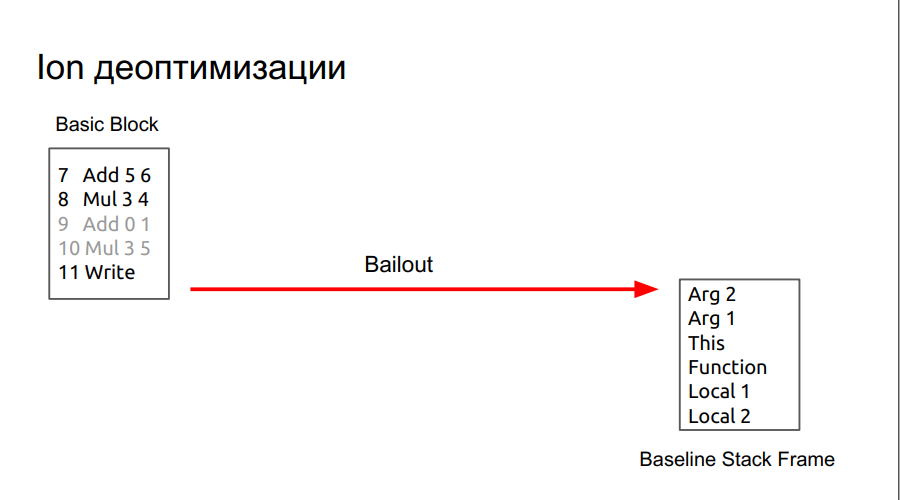
, , , .
, , , SpiderMonkey Resume Point. - , . , baseline . , runtime , . lowering, regAlloc, (snapshot), , . baseline .
:

runtime x86 : , . . , , , , , . , , Type . :
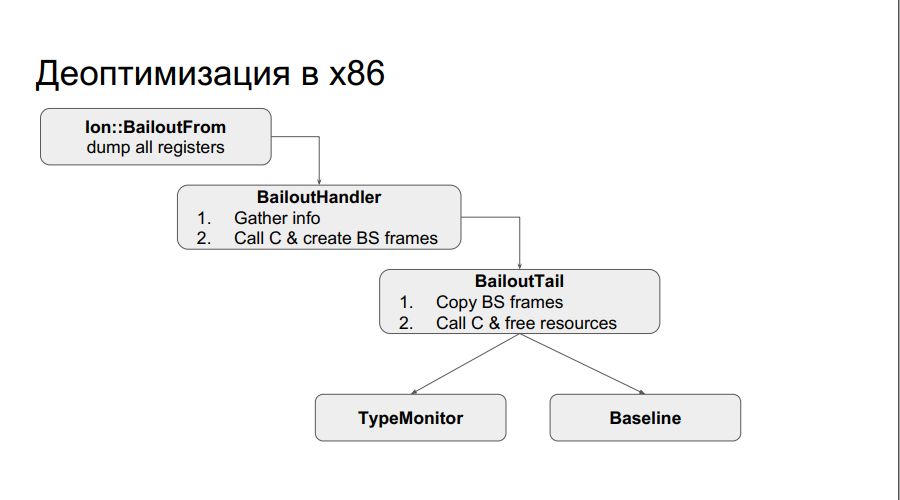
, , chain . , , .
: , chain-, N , , baseline, .
, .
:

Ion 4- baseline. :
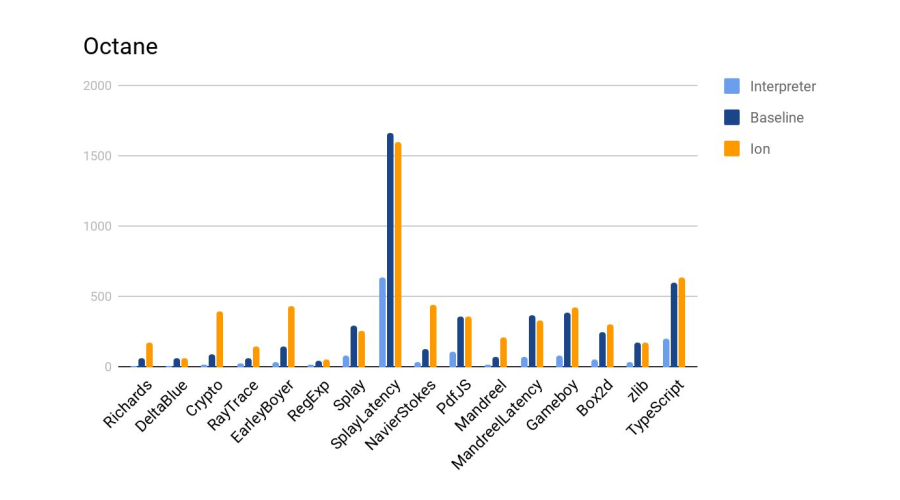
, , SpiderMonkey, V8 Node. — . .
. , , chain-.
, : 24-25 HolyJS, . — , .