长期以来,众所周知的快速傅里叶变换不仅用于解决数字信号处理,图像中对象识别的问题,而且还用于计算机图形学。 杰里·特森多夫(Jerry Tessendorf)描述了一种
数学模型 ,可让您合成海浪并对其进行实时动画处理。 该模型基于二维FFT。
当我负责开发可视化FFT操作的DSP处理器应用程序时,我意识到波形建模非常适合此目的。

波浪的数学模型
波浪数学模型的基本思想可以用以下表达式描述:
mathbfH = FFT2D(
mathbf widetildeH ),FFT2D表示为二维FFT的运算符。
mathbfH 是水面高度的字段(矩阵大小)
n1xn2 在哪里
n1 和
n2 可以取2的幂)。 该矩阵的元素是波高。
mathbf widetildeH -信号(矩阵大小
n1xn2 ),是根据特定法律并根据时间生成的。
mathbf widetildeH= mathbf widetildeH0。∗ mathbfA+ overline mathbf widetildeH0。∗ overline mathbfA 矩阵的元素在哪里
mathbfA 是的
$ inline $ e ^ {iω_{ij} t} =cos(ω_{ij} t)+ isin(ω_{ij} t)$ inline $ 和矩阵
\上线 mathbfA -复合共轭物
mathbfA 矩阵
i=0,1,...n1,j=0,1,...n2ωij 是矩阵元素
\大 mathbfω 。
。∗ -逐元素矩阵乘法。
mathbf widetildeH0 -初始时间
t = 0时的高度场。
\上线 mathbf widetildeH0 -复合共轭物
mathbf widetildeH0 矩阵(大小
n1xn2 )
要实时创建波浪运动的动画,必须重新计算矩阵
mathbf widetildeH 和
mathbfH 改变
t 。 矩阵
mathbf widetildeH0 ,
\上线 mathbf widetildeH0 和
\大 mathbfω 计算一次并重新使用。
现在,让我们继续对DSP处理器的描述,基于上面的公式,它必须能够:
- 计算FFT。
- 逐元素相乘矩阵。
- 添加矩阵。
- 计算正弦和余弦的向量。
作为DSP处理器,使用了基于NeuroMatrix架构的1879VM6Ya,该架构由科学技术中心“模块” CJSC开发。 该电路如图1所示。
该处理器包含2个并行工作核NMPU0和NMPU1(以500 MHz的频率工作),每个核都有一个RISC处理器和一个矢量协处理器(NMCore FPU用于浮点运算,而NMCore INT用于整数运算)。 NMPU0内核用于浮点数据处理,而NMPU1则用于整数数据。 NMPU0具有8个内部SRAM库(每个128 kB),而NMPU1具有4个库(128 kB)的同一存储器。 在1879VM6Ya上,安装了DMA控制器和DDR2接口。
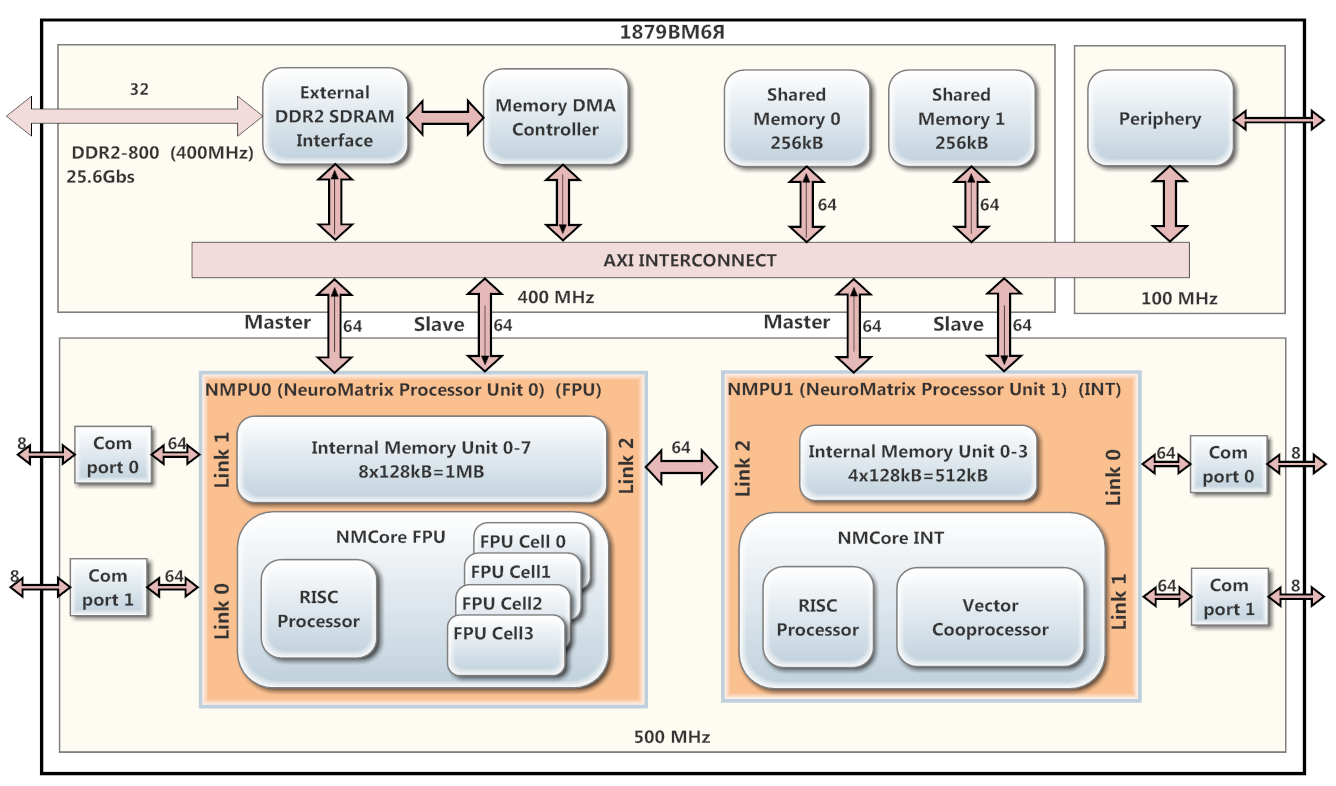 图 1.处理器框图1879VM6YA
图 1.处理器框图1879VM6YA处理器位于仪器模块MC121.01(请参见图2)上。 此模块还具有512 MB的DDR2内存。
 图2。 MS121.01
图2。 MS121.01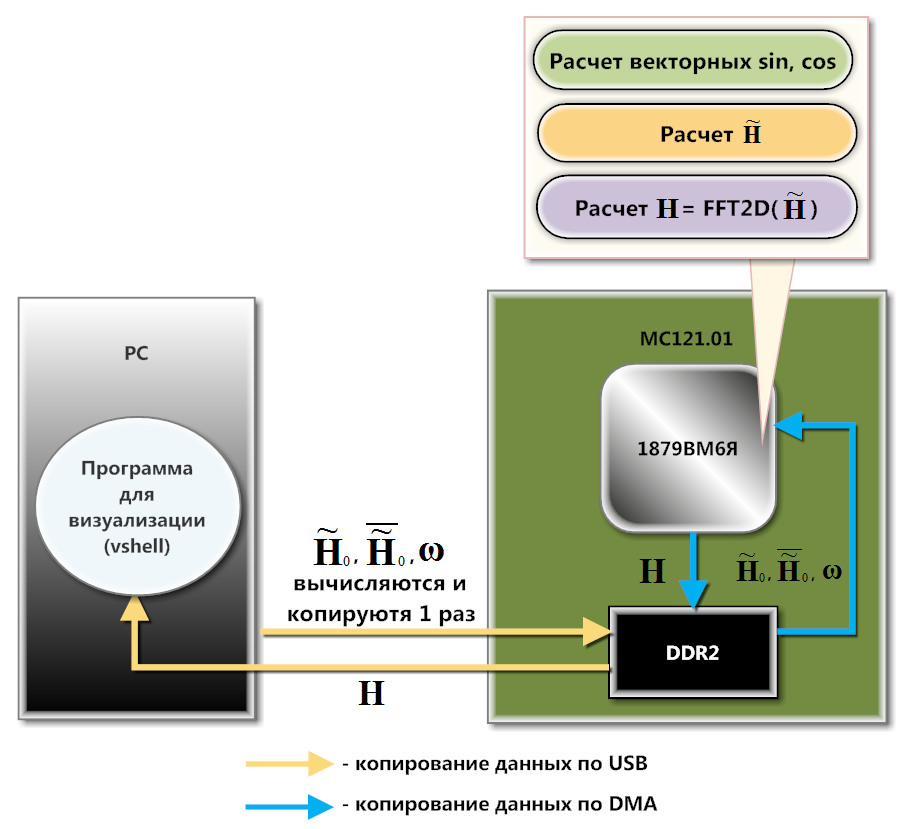 图 3. MC121.01与PC的交互方案
图 3. MC121.01与PC的交互方案MC121.01通过USB与PC交互(图3中的图表)。 在软件级别,使用下载和数据交换库来组织这种交互,该库是本开发板SDK的一部分。 预先计算的矩阵
mathbf widetildeH0 ,
\上线 mathbf widetildeH0 和
\大 mathbfω 通过下载和交换库的功能将它们加载到DDR2存储器中。 DMA控制器副本
mathbf widetildeH0 ,
\上线 mathbf widetildeH0 和
\大 mathbfω 逐行进入处理器的内部存储器(SRAM)。 下载到DDR2的原因是这些矩阵都不完全适合SRAM。 在这里进行逐行复制,因为1879BM6Ya从SRAM计算的速度比从DDR2计算的速度更快。 此外,可以在DMA的背景下完成大部分计算。
使用NMPP库的向量函数计算向量的正弦,余弦,乘法和加法,处理器可计算矩阵行
mathbf widetildeH 并从中获取一维FFT。 结果通过DMA发送回DDR2。 因此,在DDR2中形成一个中间矩阵,处理器从该矩阵的列中计算一维FFT(在通过DMA将中间矩阵的列加载到SRAM之后)。 因此,在DDR2中形成矩阵
mathbfH 。 该矩阵被下载到PC上以绘制波面图像的单个帧。 要对图片进行实时动画处理,您需要根据上述算法计算矩阵
mathbfH 通过增加参数
t 。
实际上,结果是18796计算矩阵
mathbfH 速度比PC放气快。 因此,处理器可能处于空闲状态,等待PC接收下一批数据。 使用环形缓冲区(包含多个矩阵)可以解决此问题。
mathbfH )组织在DDR2内存板上。
在软件级别,使用NeuroMatrix处理器的HAL(硬件抽象级别)库函数执行DMA控制器和环形缓冲区的工作。
波面可视化
当DEM
mathbfH 加载到PC内存中后,您可以可视化表面。 为了更清楚地显示它,您需要协调x,y,z,以描述表面上的点,再乘以
旋转矩阵 。 因此,我们获得了曲面x',y',z'的新坐标,将其旋转一定角度。
通过缩放新坐标并沿直线将其连接起来,您可以看到海浪的动画(请参见下面的视频)。 为了使表面可视化,该库用于在vshell屏幕上显示图像。
结论
最后,我想说的是,一个矩阵的计算和通过USB的传输
mathbfH 大小为256x256浮点数时,大约要花费470万个时钟周期(每个浮点72个时钟周期)。 帧速率为〜107。 如果您不考虑通过USB传输数据所花费的时间,那么计算将花费约250万个周期(每个浮点运算38个周期)。 这是18796处理器在元素的元素乘法和矩阵相加,FFT计算,正弦,余弦和使用DMA复制方面花费的总时间。 这些计算是在USB数据传输的背景下进行的。
相差220万个时钟周期(470万-250万= 220万)表明,在PC-MC121.01系统中,USB是“瓶颈”,并且1879VM6YA的计算量可以增加46%,而无需接收缩图FPS。
我还要指出,在USB数据传输和在浮点协处理器上进行计算的背景下,可以使用此任务中未使用的整数运算协处理器。
下表显示了nmpp库的某些矢量函数的性能。
| 功能介绍 | 吧台 |
|---|
| 一维FFT 256点 | 1770年 |
| 正弦,256点 | 1400 |
| 余弦256点 | 1400 |
参考文献:
NMPP-NeuroMatrix体系结构的原语库HAL-NeuroMatrix硬件相关的抽象库VSHELL-图像处理和显示库