哈Ha 我叫Vitaliy Kotov,我在Badoo的测试部门工作。 我编写了许多UI自动测试,但是我与不久前一直在这样做并且还没有设法掌握所有功能的人进行了更多合作。
因此,在添加了我自己的经验和对其他人的观察之后,我决定为您准备一个“如何编写测试不值得”的集合。 我为每个示例提供了详细的描述,代码示例和屏幕截图。
对于UI测试的初学者来说,这篇文章会很有趣,但是该主题的老手们可能会学到一些新东西,或者只是微笑,就“在年轻时”记得自己。 :)
走吧

目录内容
没有属性的定位器
让我们从一个简单的例子开始。 由于我们在谈论UI测试,因此定位器在其中扮演着重要角色。 定位器是根据特定规则组成并描述一个或多个XML(特别是HTML)元素的线。
定位器有几种类型。 例如,
css定位器用于级联样式表。
XPath定位器用于处理XML文档。 依此类推。
Selenium使用的定位器类型的完整列表可以在
seleniumhq.imtqy.com中找到。
在UI测试中,定位符用于描述驱动程序应与之交互的元素。
在几乎所有浏览器检查器中,都可以选择我们感兴趣的元素并复制其XPath。 看起来像这样:
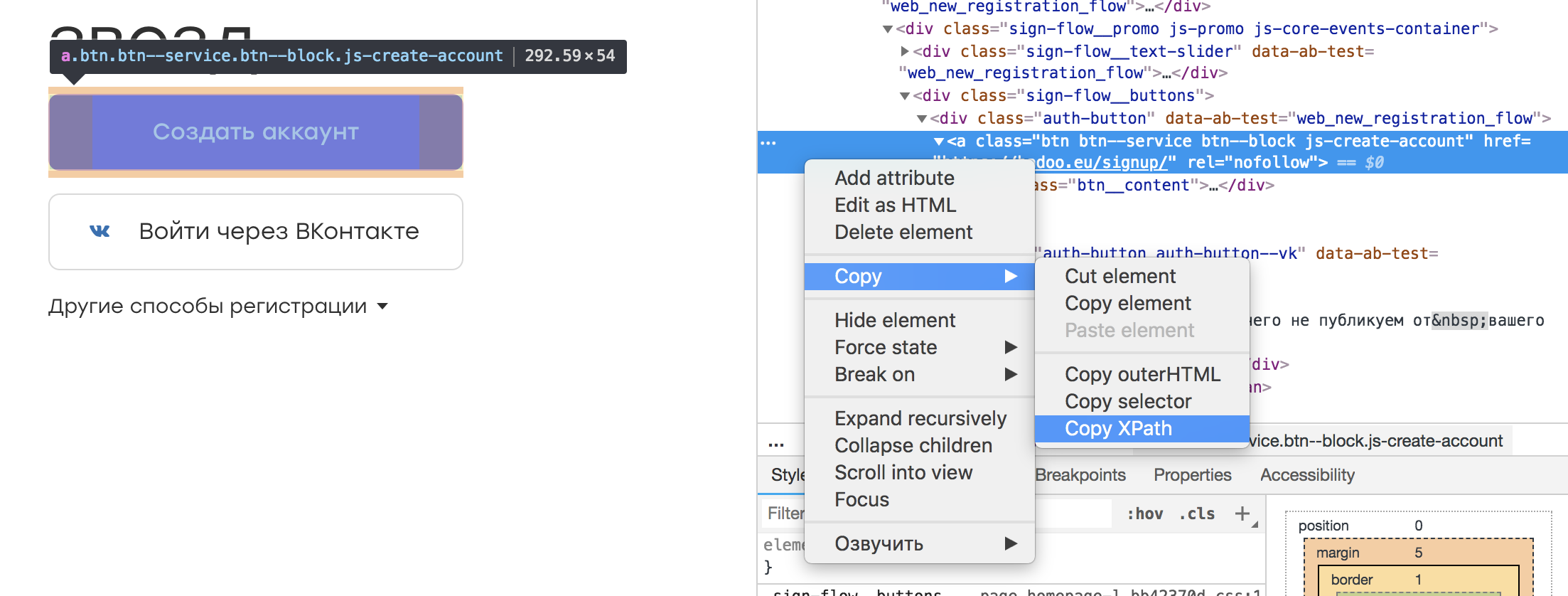
事实证明这样的定位器:
/html/body/div[3]/div[1]/div[2]/div/div/div[2]/div[1]/a
这样的定位器似乎没有错。 毕竟,我们可以将其保存在类的某些常量或字段中,其名称将传达元素的本质:
@FindBy(xpath = "/html/body/div[3]/div[1]/div[2]/div/div/div[2]/div[1]/a") public WebElement createAccountButton;
并包装相应的错误文本,以防找不到该元素:
public void waitForCreateAccountButton() { By by = By.xpath(this.createAccountButton); WebDriverWait wait = new WebDriverWait(driver, timeoutInSeconds); wait .withMessage(“Cannot find Create Account button.”) .until( ExpectedConditions.presenceOfElementLocated(by) ); }
这种方法有一个优点:无需学习XPath。
但是,有许多缺点。 首先,当更改布局时,不能保证此类定位器上的元素将保持不变。 可能会有其他人代替,这将导致无法预料的情况。 其次,自动测试的任务是寻找错误,而不是监视布局更改。 因此,在树中增加一些包装器或其他一些元素不会影响我们的测试。 否则,我们将花费大量时间来更新定位器。
结论:您应该使定位器能够正确描述元素,并且能够抵抗在我们应用程序的测试部分之外更改布局。 例如,您可以绑定到元素的一个或多个属性:
//a[@rel=”createAccount”]
这样的定位器在代码中更容易理解,并且只有在“ rel”消失时它才会中断。
这种定位器的另一个优点是能够在具有指定属性的模板存储库中进行搜索。 但是,如果定位器在原始示例中看起来像该怎么办? :)
如果最初在应用程序中元素没有任何属性或它们是自动设置的(例如,由于类的
混淆 ),则值得与开发人员讨论。 他们应该对自动化产品测试同样感兴趣,并且一定会满足您的需求并提供解决方案。
检查缺少的物品
每个Badoo用户都有自己的个人资料。 它包含有关用户的信息:(姓名,年龄,照片)以及有关用户希望与谁聊天的信息。 另外,可以表明您的兴趣。
假设我们曾经有一个错误(尽管当然不是这样)。 用户在他的个人资料中选择了兴趣。 在列表中找不到合适的兴趣,他决定单击“更多”以更新列表。
预期的行为:旧的兴趣应该消失,新的兴趣应该出现。 但是弹出的是“意外错误”:
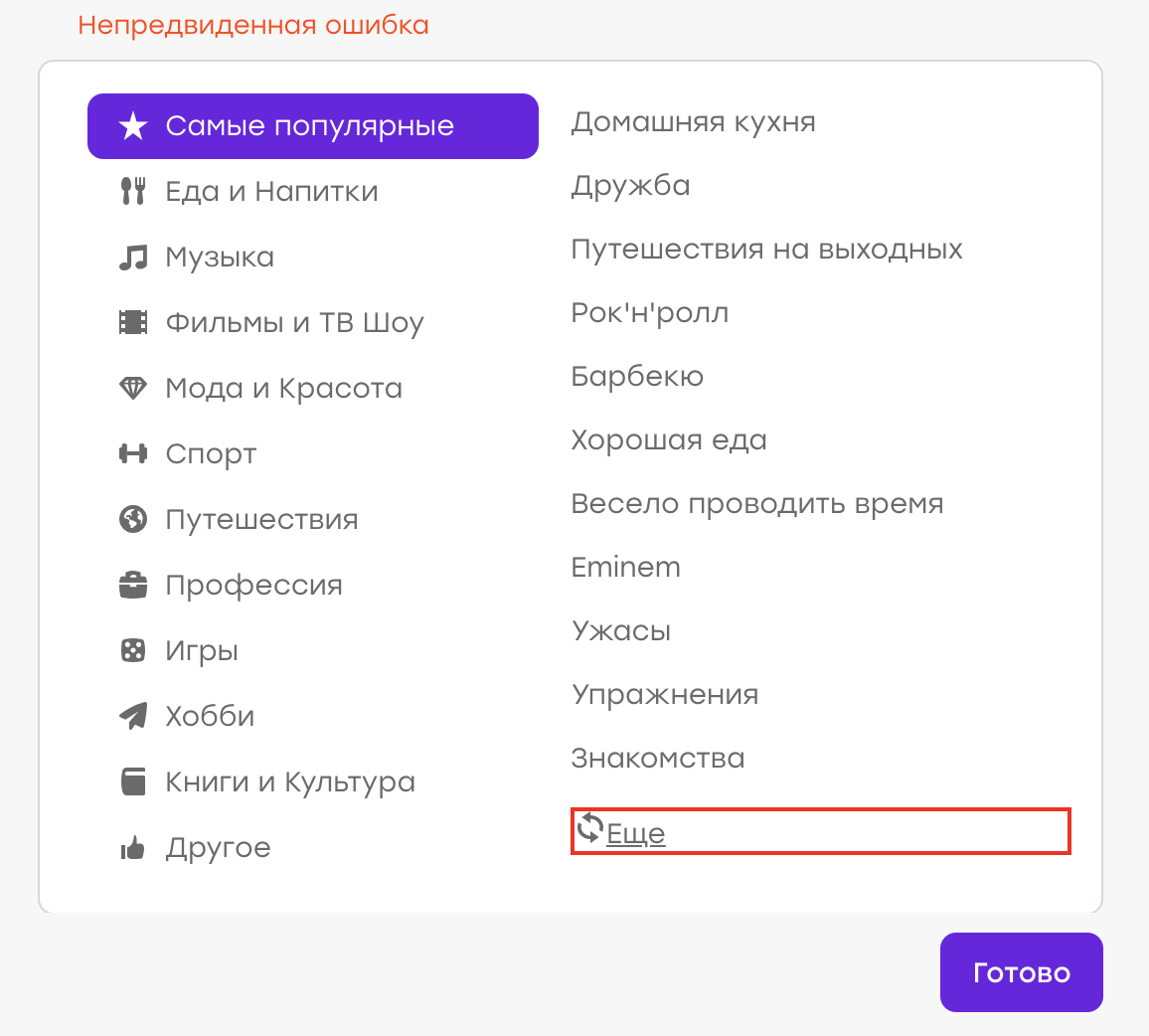
事实证明,服务器端存在问题,答案不尽相同,客户端通过显示通知来处理此问题。
我们的任务是编写一个自动测试来检查这种情况。
我们大致编写以下脚本:
- 开启个人资料
- 公开兴趣清单
- 点击“更多”按钮
- 确保没有出现错误(例如,没有div.error元素)
我们进行了这样的测试。 但是,会发生以下情况:在几天/几个月/几年之后,尽管测试没有发现任何问题,但还是重新出现了该错误。 怎么了
一切都非常简单:在成功通过测试的过程中,用于搜索错误文本的元素的定位器已更改。 对模板进行了重构,我们使用“ error_new”类代替了“ error”类。
在重构期间,测试继续按预期进行。 div.error元素没有出现;没有理由跌倒。 但是现在“ div.error”元素根本不存在-因此,无论应用程序发生什么情况,测试都不会失败。
结论:最好通过积极的检查来测试接口的可操作性。 在我们的示例中,我们应该期望兴趣列表已更改。
在某些情况下,阴性测试无法代替阳性测试。 例如,当与某个元素交互时,在“好”情况下什么也没有发生,而在“坏”情况下出现错误。 在这种情况下,您应该想出一种模拟“不良”情况并在其上进行自动测试的方法。 因此,我们验证了错误元素是否出现在否定情况下,从而我们监控了定位器的相关性。
检查项目
如何确保与界面的测试交互成功并且一切正常? 这在此界面中发生的更改中最常见。
考虑一个例子。 您需要确保在发送消息时消息出现在聊天室中:
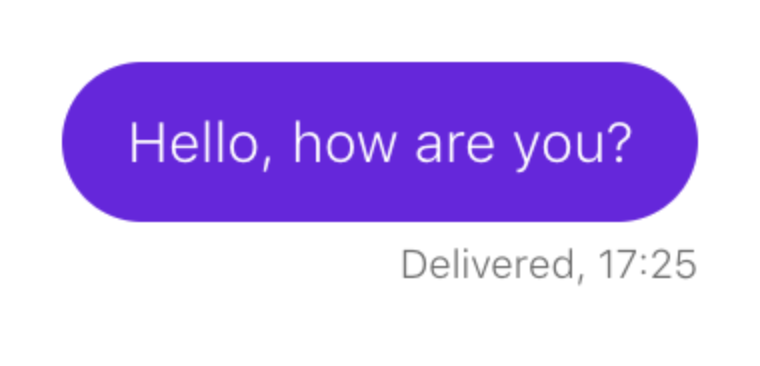
该脚本如下所示:
- 打开用户个人资料
- 与他公开聊天
- 写留言
- 提交
- 等待消息出现。
我们在测试中描述了这种情况。 假设聊天消息与定位符匹配:
p.message_text
这是我们验证元素出现的方式:
this.waitForPresence(By.css('p.message_text'), "Cannot find sent message.");
如果我们的等待有效,那么一切正常:绘制聊天消息。
您可能已经猜到,过一会儿,发送聊天消息会中断,但是我们的测试仍在继续进行,没有中断。 让我们做对。
事实证明,在聊天室中出现一个新元素的前一天:一些文本如果提示消息突然未被注意,则提示用户突出显示该消息:
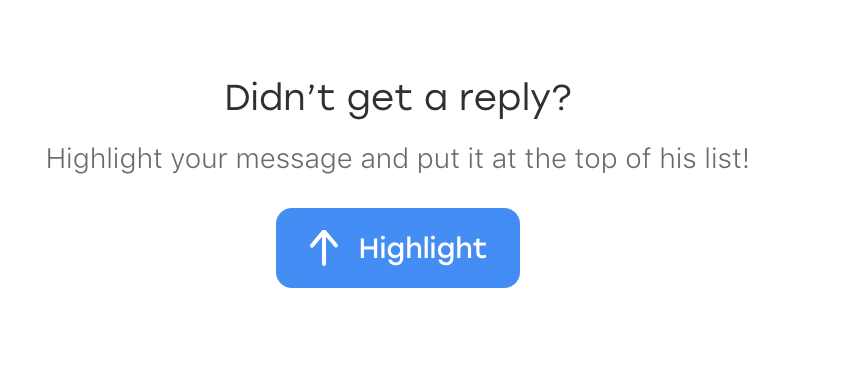
而且,最有趣的是,它也属于我们的定位器。 只有它有一个附加类,可将其与已发送消息区分开:
p.message_text.highlight
当出现此阻止时,我们的测试没有中断,但是“等待消息出现”的检查不再有意义。 指示成功事件的元素现在始终存在。
结论:如果测试的逻辑是基于检查某些元素的外观,则在与UI交互之前必须检查是否没有此类元素。
- 打开用户个人资料
- 与他公开聊天
- 确保没有发送的消息
- 写留言
- 提交
- 等待消息出现。
随机数据
UI测试经常与输入数据的表单一起使用。 例如,我们有一个注册表:
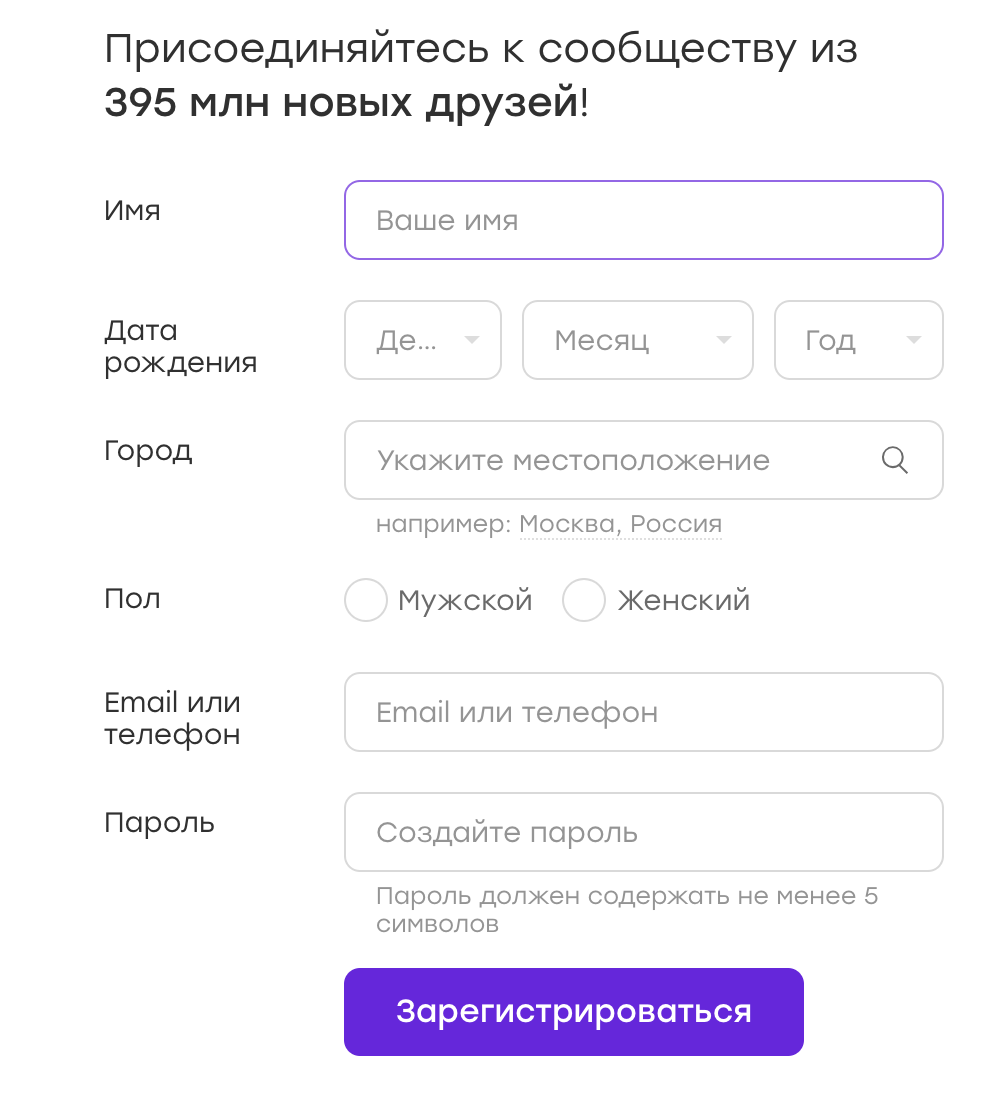
此类测试的数据可以存储在配置中或在测试中进行硬编码。 但是有时会想到这种想法:为什么不随机化数据? 很好,我们将涵盖更多案例!
我的建议:不要。 现在,我告诉你为什么。
假设我们的测试是在Badoo上注册的。 我们决定随机选择用户的性别。 在编写测试时,女孩和男孩的注册流程没有什么不同,因此我们的测试成功通过了。
现在想象一下,注册流程变得不同了。 例如,我们会在注册后立即为该女孩提供免费奖金,我们会通过特殊的叠加通知该女孩。
在测试中,没有用于关闭覆盖层的逻辑,但是反过来,它会干扰测试中规定的任何其他操作。 我们得到的测试涵盖了50%的情况。 任何自动化工具都将确认UI测试本质上不是固有稳定的。 这是正常现象,必须忍受它,不断在“在所有情况下”使用冗余逻辑(这明显破坏了代码的可读性,并使代码的支持变得复杂)和这种不稳定本身之间。
下次,当测试失败时,我们可能没有时间去处理它。 我们只是重新启动它,看它已经通过了。 我们决定在我们的应用程序中一切正常运行,并且事情是不稳定的测试。 冷静一下
现在继续前进。 如果该覆盖层破裂怎么办? 该测试将在50%的情况下继续通过,这将大大延迟发现问题的速度。
由于数据的随机性,我们创建了“ 50 x 50”的情况,这是很好的。 但这情况有所不同。 例如,在注册之前,密码被认为可接受,至少长度为三个字符。 我们编写的代码带有一个不小于三个字符(有时三个字符,有时更多)的随机密码。 然后规则更改-密码应该已经至少包含四个字符。 在这种情况下跌倒的可能性是多少? 而且,如果我们的测试发现了一个真正的错误,我们将如何迅速找出答案?
在输入大量随机数据的测试中特别困难:名称,性别,密码等...在这种情况下,还存在许多不同的组合,并且如果其中任何一个发生错误,通常都很难注意到。
结论 正如我上面所写,随机化数据是不好的。 当然,最好以牺牲数据提供者为代价来覆盖更多的情况,而不要忘记
等效类 。 通过测试将花费更长的时间,但是您可以与之抗衡。 但是,我们将确定如果出现问题,便可以将其检测到。
测试的原子性(第1部分)
让我们看下面的例子。 我们正在编写一个检查页脚中用户计数器的测试。

场景很简单:
我们将这样的测试称为testFooterCounter并运行它。 然后,有必要检查计数器是否不显示零。 我们将此测试添加到现有测试中,为什么不呢?
但是随后有必要验证页脚中是否有指向项目描述的链接(链接“关于我们”)。 编写新的测试或添加到现有测试? 如果是新测试,我们将不得不重新启动应用程序,准备用户(如果我们在授权页面上检查页脚),然后登录-通常,请花一些宝贵的时间。 在这种情况下,将测试重命名为testFooterCounterAndLinks似乎是个好主意。
一方面,这种方法具有以下优点:节省时间,将应用程序某些部分的所有检查(在本例中为页脚)存储在一个地方。
但是有一个明显的减号。 如果在第一次测试中测试失败,我们将不检查其余组件。 假设测试在某个分支中崩溃,不是因为不稳定,而是由于错误。 怎么办 返回仅描述此问题的任务? 然后,我们冒着获得仅修复此错误的任务的风险,进行测试并发现该组件在另一个地方也被进一步破坏。 并且可以有很多这样的迭代。 在这种情况下,来回踢票会花费很多时间,而且效果不佳。
结论:如果可能,将检查结果雾化。 在这种情况下,即使在一种情况下出现问题,我们也会对所有其他情况进行检查。 而且,如果您必须退票,我们可以立即描述所有问题区域。
测试的原子性(第2部分)
考虑另一个例子。 我们正在编写一个聊天测试,检查以下逻辑。 如果用户相互支持,则聊天窗口中将显示以下促销块:

场景如下:
- 用户A对用户B的投票
- 用户B对用户A的投票
- 用户A与用户B的公开聊天
- 确认装置就位
在一段时间内,该测试成功进行,但是随后发生了以下情况……不,这次,测试不会丢失任何错误。 :)
一段时间后,我们发现还有另一个与我们的测试无关的错误:如果您打开聊天,立即将其关闭并再次打开,该块将消失。 不是最明显的情况,在测试中我们当然没有预见到。 但是我们认为我们也需要涵盖它。
出现同样的问题:编写另一个测试或将测试插入现有测试中? 写一个新书似乎不合适,因为他有99%的时间会做与现有书相同的事。 我们决定将测试添加到已经存在的测试中:
- 用户A对用户B的投票
- 用户B对用户A的投票
- 用户A与用户B的公开聊天
- 确认装置就位
- 关闭聊天
- 开启即时通讯
- 确认装置就位
例如,当我们在很长一段时间后重构测试时,可能会出现问题。 例如,将在项目上进行重新设计-您将不得不重写许多测试。
我们将打开测试并尝试记住测试内容。 例如,测试称为testPromoAfterMutualAttraction。 我们是否理解为什么在结束时写聊天的开始和结束? 很有可能不会。 特别是如果该测试不是我们编写的。 我们会离开这块吗? 也许可以,但是如果他有任何问题,我们很可能会删除他。 仅仅因为其含义不明显,验证就会丢失。
我在这里看到两个解决方案。 第一:仍然进行第二项测试,并将其命名为testCheckBlockPresentAfterOpenAndCloseChat。 用这样的名字,很明显,我们不仅在做某些动作,而且还在做非常有意识的检查,因为那是一种消极的经历。 第二种解决方案是在代码中写一个详细的注释,说明为什么我们要在此特定测试中进行此测试。 还建议在注释中指出错误编号。
点击现有项目时出错
以下示例将
bbidox扔给了我,为此他在业力方面大加了!
当测试代码已经成为一个框架时,这是一个非常有趣的情况。 假设我们有一个这样的方法:
public void clickSomeButton() { WebElement button_element = this.waitForButtonToAppear(); button_element.click(); }
在某个时候,这种方法开始发生奇怪的事情:当您尝试单击一个按钮时,测试崩溃。 我们打开测试崩溃时拍摄的屏幕截图,我们看到屏幕截图中有一个按钮,并且waitForButtonToAppear方法成功运行。 问题:点击有什么问题?
这种情况下最难的部分是测试有时可以成功。 :)
让我们做对。 假设示例中考虑的按钮位于这样的覆盖层上:
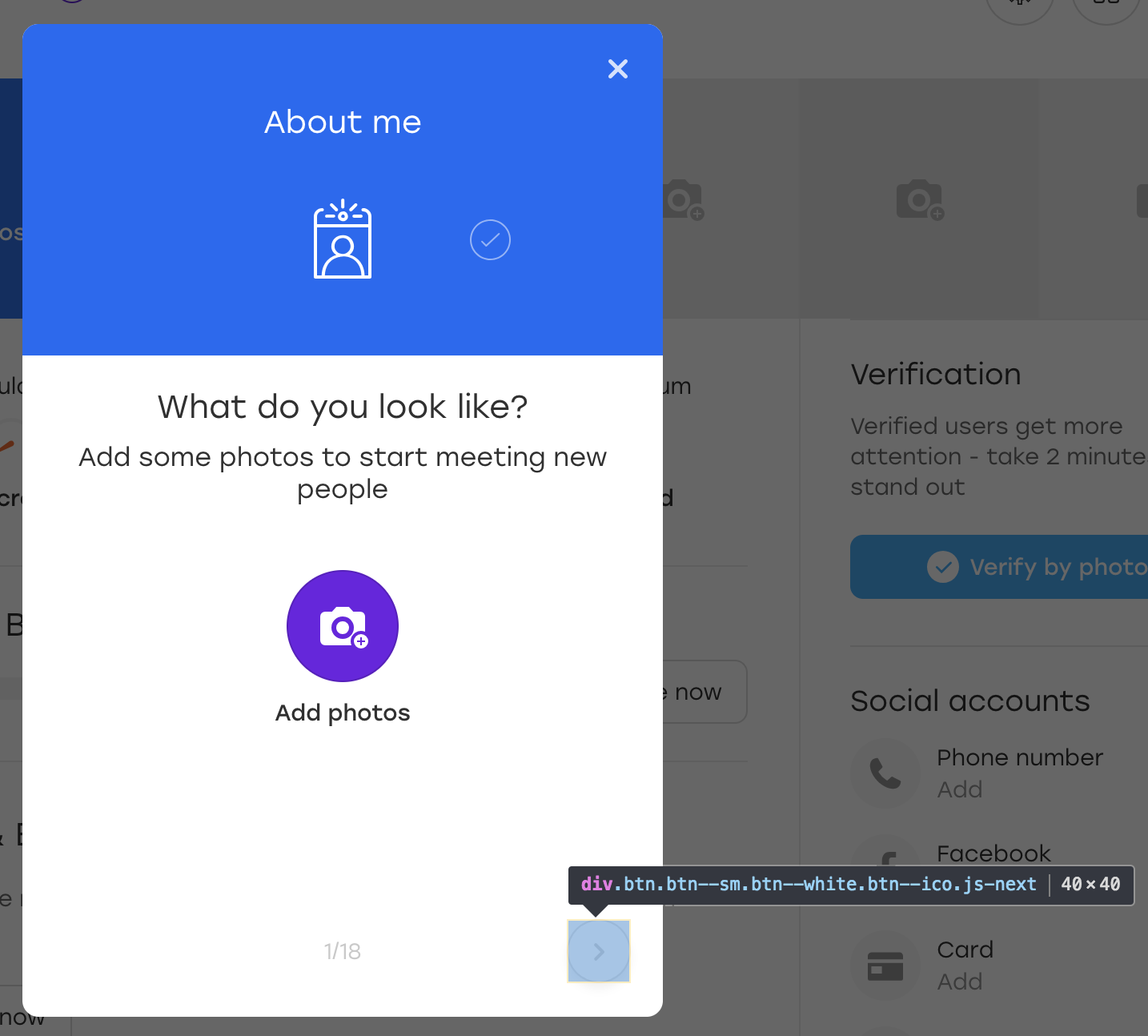
这是一个特殊的叠加层,通过它我们网站上的用户可以填写有关他自己的信息。 当您单击突出显示的覆盖按钮时,下一个块似乎会填充。
为了好玩,让我们为该按钮添加一个额外的OLOLO类:
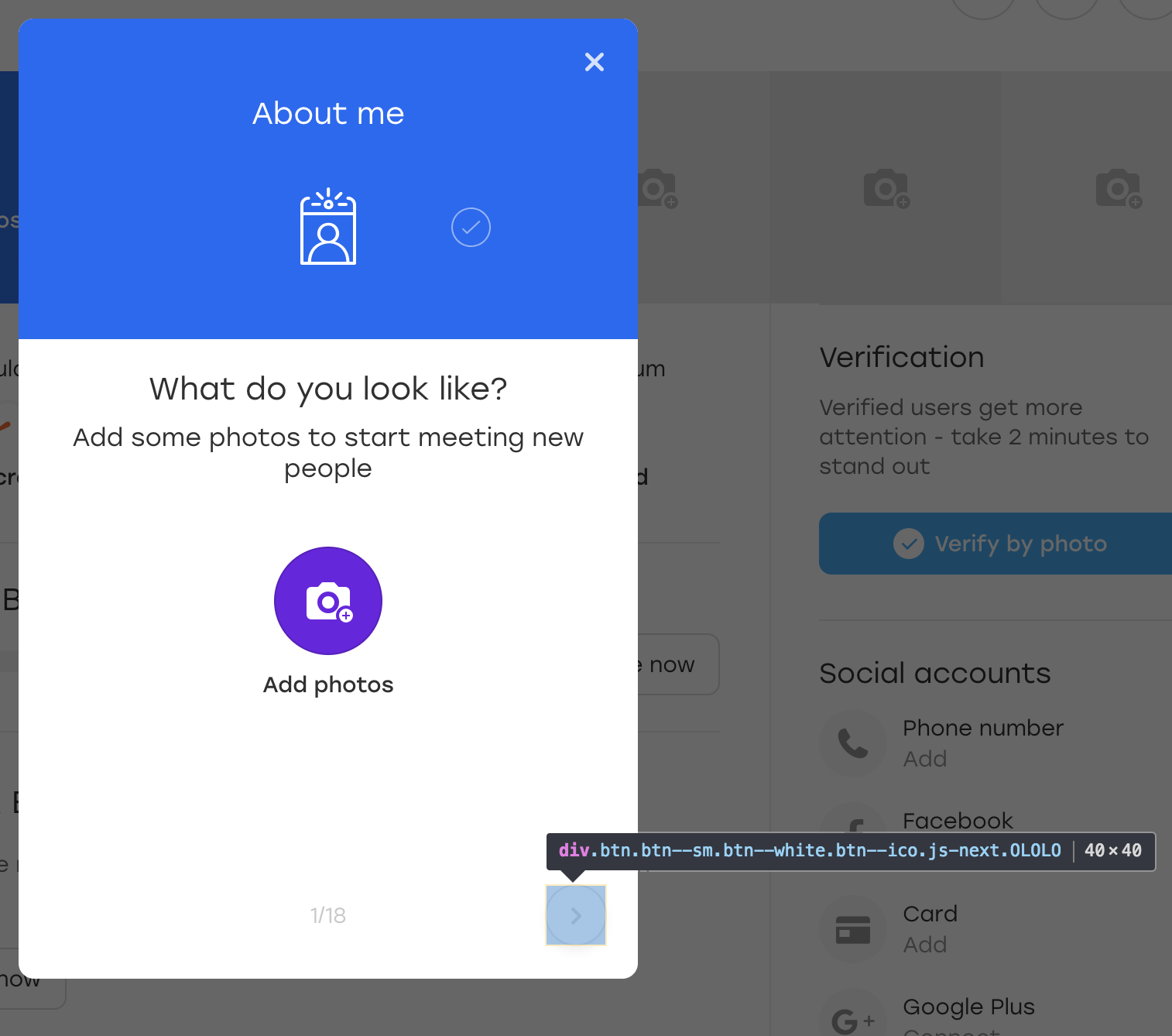
之后,我们单击此按钮。 在视觉上,什么都没有改变,但是按钮本身仍然留在原处:
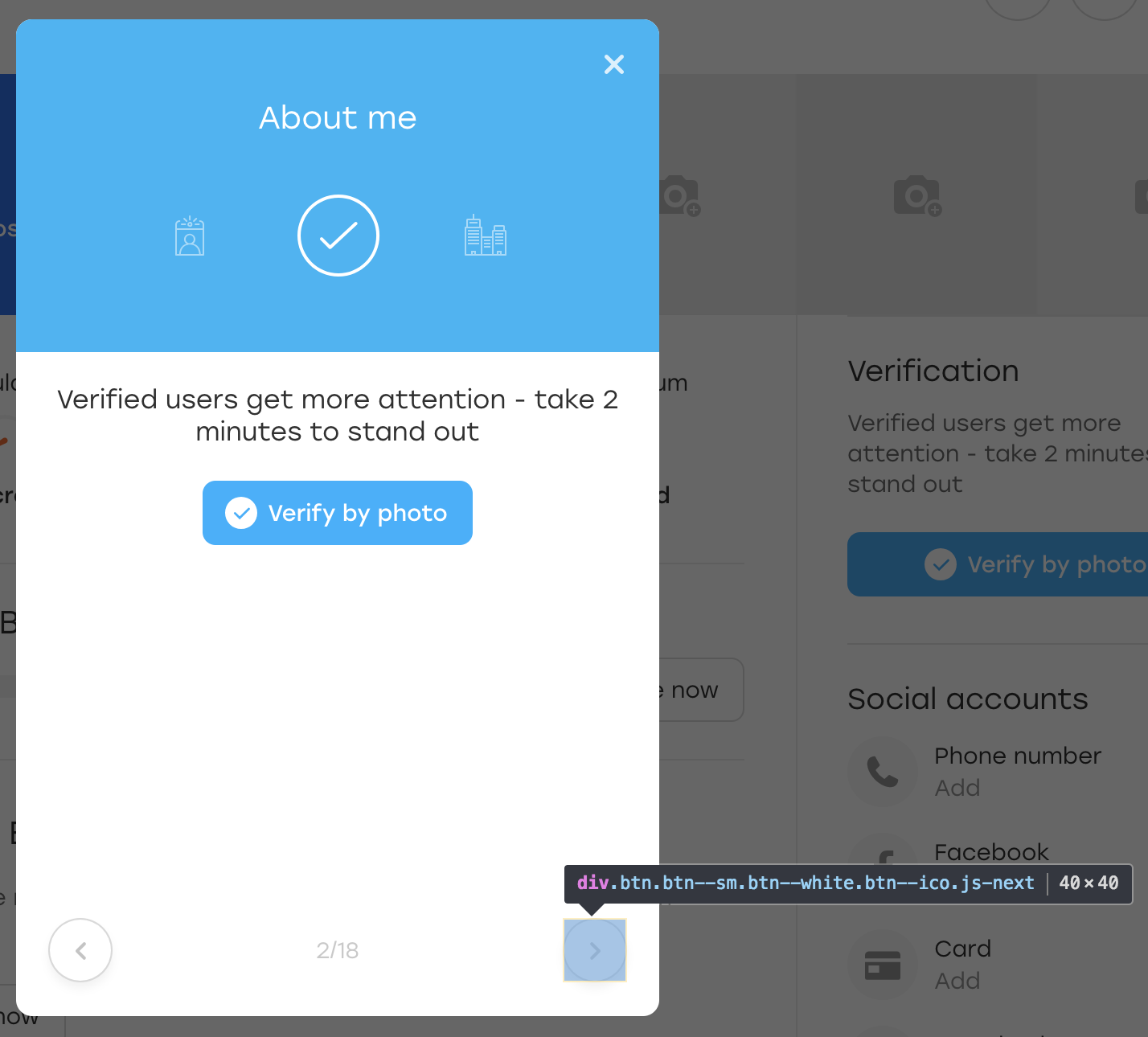
怎么了 实际上,当JS向我们重新绘制块时,他也重新绘制了按钮。 它在同一定位器上仍然可用,但这是另一个按钮。 我们缺少的OLOLO类证明了这一点。
在上面的代码中,我们将元素存储在$ element变量中。 如果在此期间重新生成了一个元素,则可能无法在视觉上看到它,但是您不能再单击它-click()方法将失败。
有几种解决方案:
- 在try块和catch rebuild元素中单击包装
- 向属性添加按钮以表明它已更改
错误文字
最后,简单但重要的一点。
此示例不仅适用于UI测试,而且还经常在其中进行。 通常,在编写测试时,您处于所发生情况的上下文中:在验证之后描述验证并理解其含义。 并且您在相同的上下文中编写错误文本:
WebElement element = this.waitForPresence(By.css("a.link"), "Cannot find button");
这段代码中可能有什么难以理解的? 测试期望按钮的外观,如果按钮不存在,则自然会掉落。
现在想象一下测试的作者正在休病假,而他的同事正在照顾测试。 然后,他删除了testQuestionsOnProfile测试并编写了以下消息:“找不到按钮”。 同事需要尽快了解正在发生的事情,因为该版本即将发布。
他将要做什么?
打开测试失败的页面并检查“ a.link”定位器是没有意义的-没有任何内容。 因此,您必须仔细研究测试并找出测试内容。
使用更详细的错误文本会更简单:“在问题叠加层上找不到提交按钮”。 遇到这样的错误,您可以立即打开覆盖并查看按钮的位置。
输出两个。 首先,将错误文本传递给测试框架的任何方法是值得的,并且它是必需的参数,因此不会产生遗忘的诱惑。 其次,应详细说明错误文本。 这并不总是意味着它应该很长,足以表明测试出了什么问题。
如何理解错误文本写得好? 很简单 想象一下,您的应用程序已损坏,您需要去开发人员并说明损坏的地方。 如果只告诉他们错误文本中写了什么,他们会理解吗?
总结
编写测试脚本通常是一个有趣的活动。 同时,我们追求许多目标。 我们的测试应:
- 涵盖尽可能多的情况
- 尽可能快地工作
- 被理解
- 只是扩大
- 易于维护
- 订购披萨
- 等等...
在不断变化和变化的项目中使用测试特别有趣,在该项目中,测试必须不断更新:添加一些内容并削减一些内容。 这就是为什么值得事先考虑一些问题,而不是总是急于做出决定的原因。 :)
希望我的技巧可以帮助您避免一些问题,并让您在案例研究中更加体贴。 如果读者喜欢这篇文章,我将尝试收集一些更无聊的示例。 同时-再见!