在
上一篇文章中,我们已经熟悉了神经形态系统领域的一项研究。 今天,我们将再次讨论该主题,但它与创建人造神经细胞无关,而与如何将这些细胞组合成一个有效的网络有关。 毕竟,人脑就像世界上最复杂的网络一样,由数十亿个神经元的交叉点和连接点组成。 研究人员建议,用光代替电将大大简化创建人工神经网络的过程,其复杂程度可与人脑媲美。 除了大胆的话,复杂的计算和无经验之外,科学家还提供了该设备的有效演示版。 它是如何工作的,它的功能是什么?它对神经形态技术的未来具有什么意义? 所有问题的答案都隐藏在研究人员的报告中。 仍然找不到他们。 走吧
美国国家标准技术研究所(NIST)的科学家已经创建了一种可以使用光信号的芯片,因为它具有两个“层”的光子波导。 后者将光流转换成窄带以传输光信号。 根据科学家的说法,这种发展将允许实施复杂的信号路由系统,也可以通过添加其他芯片来对其进行扩展。
设备结构值得注意的是,研究中实验描述的光子收集器无论波长或
时分多路复用*都可以工作 。
临时多路复用* -在一个通道上同时传输多个信号。
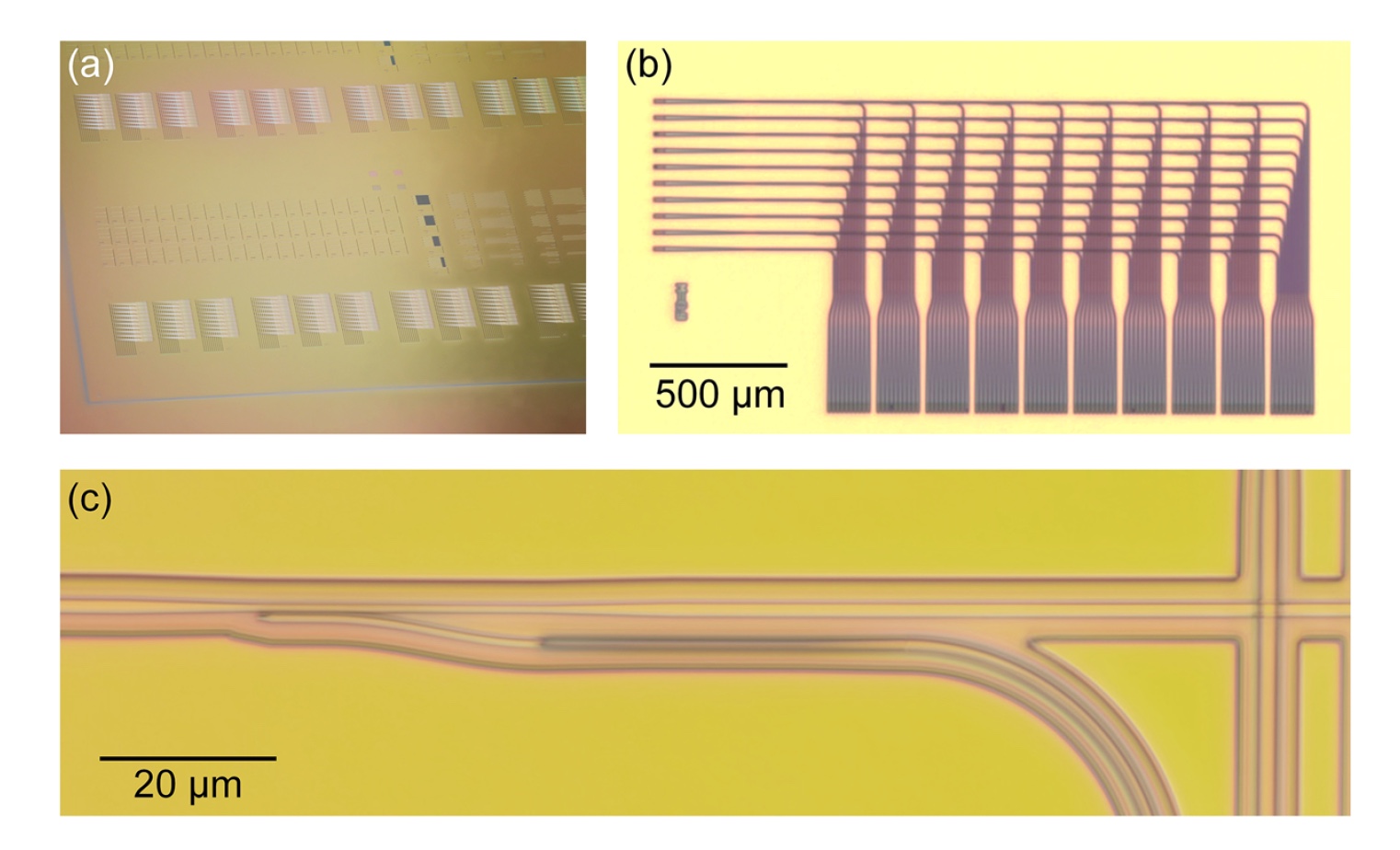
 图片编号1
图片编号1集电极结构基于2个垂直集成的波导平面。 下平面(P
1 )朝东,而第二平面(P
2 )朝南,这避免了相交。
从每个输入节点收集的来自P
1的光在开始向东移动时会被导向P
2 。 这种布线减少了所涉及的波导的数量,因为每个输入信号都是使用
星形连接器*布线的。
星形连接器* -接收传入信号并将其分配到多个传出信号的设备。
收集器由具有反馈的神经网络的两层实现,相互连接:
- 10个上升神经元;
- 具有100个突触的10个下降神经元。
图
1c示出了系统的独立部分的图,其描述了储层的结构。
备注:该报告使用与图像
1b和
1c相关的缩写,即T
x (第一层神经元的递质)和S
x,y (第二层神经元的突触/受体)。 因此,例如,S
8.3是第三接收机从第八发射机(T
8 )接收信号的突触。
这种网络结构允许每个输入节点形成一组10个输出流,它们一起代表整个输入阵列。 每个组的作用类似于特定下降神经元的突触(接收器)。 该结构特征如图
1b所示。
收集器的目标是按照给定的功率分配模式将每个输入定向到每个输出的一个突触。
研究人员创建了该系统的两个版本:
- 统一 -每个传出的突触都具有相同的功能;
- 高斯 -来自上升层中层神经元的突触获得大部分能量,并且沿着神经元外围的突触要小得多。
为了自动生成这两个选项的模板,编写了一个脚本,该脚本的变量负责神经元的数量和强度分布图。
系统中最重要的元素是图像
1e中所示的所谓的回缩和传输装置。 该设备由束出口和平面间耦合器(以下称为
IPC )组成,它们之间的位置应尽可能靠近。 该设备的任务是将总线电源的一部分转移到上平面的垂直波导中。
波导P
1和P
2绝热地变窄并扩展到1.5μm的距离(连接图像
1e中的红线和蓝线),以最小化沿其整个长度的散射损耗。
为了清楚起见,波导P
1在12μm的距离处变窄至400nm的宽度,然后在18μm之后返回其原始宽度。 此外,P
1在12μm处逐渐减小到200 nm的最小宽度。 反过来,P
2仅以相反的顺序重复此模式。 结果,IPC的总长度为42微米。
当网络具有这样的尺寸时,为它提供令人印象深刻的功率去除系数动态范围非常重要,这将允许实现均匀或高斯分布。
为了满足此要求,收集器使用三个连接间隙和可变的连接长度,从而可以成功扩展网络的配电范围。
通过脚本从搜索表中选择连接间隙,其中收集抽头系数的先前计算数据。
三个间隙的值如下:300nm,400nm和500nm。 化合物的长度从2.7微米到19微米不等。
集热器制造光子收集器是
在美国国家标准技术研究院的
Boulder微加工设施的壁内制造的。
 在实验室内部:“无尘室”策展人约翰·尼巴格(John Nibarger)检查了一个板的支架,该板设计为用于喷涂材料以喷涂贵金属的沉积工具。
在实验室内部:“无尘室”策展人约翰·尼巴格(John Nibarger)检查了一个板的支架,该板设计为用于喷涂材料以喷涂贵金属的沉积工具。硅晶片的直径为77mm。
 影像2:制成的样品的光学影像
影像2:制成的样品的光学影像样品中的两个波导的平面由厚度为400 nm的
SiN膜(氮化硅)组成,晶面间距为1.2μm,标称宽度为800 nm。 SiN膜的材料是在非常低的温度(24、25和40℃)下沉积的,以最大程度地降低机械应力和热膨胀失配。
该SiN膜的折射率为1.96,并且在λ= 1310nm的波长下,波传播损耗指数为〜5dB / cm。
在所有侧面,波导都衬有等离子体沉积的
SiO 2 (二氧化硅)。
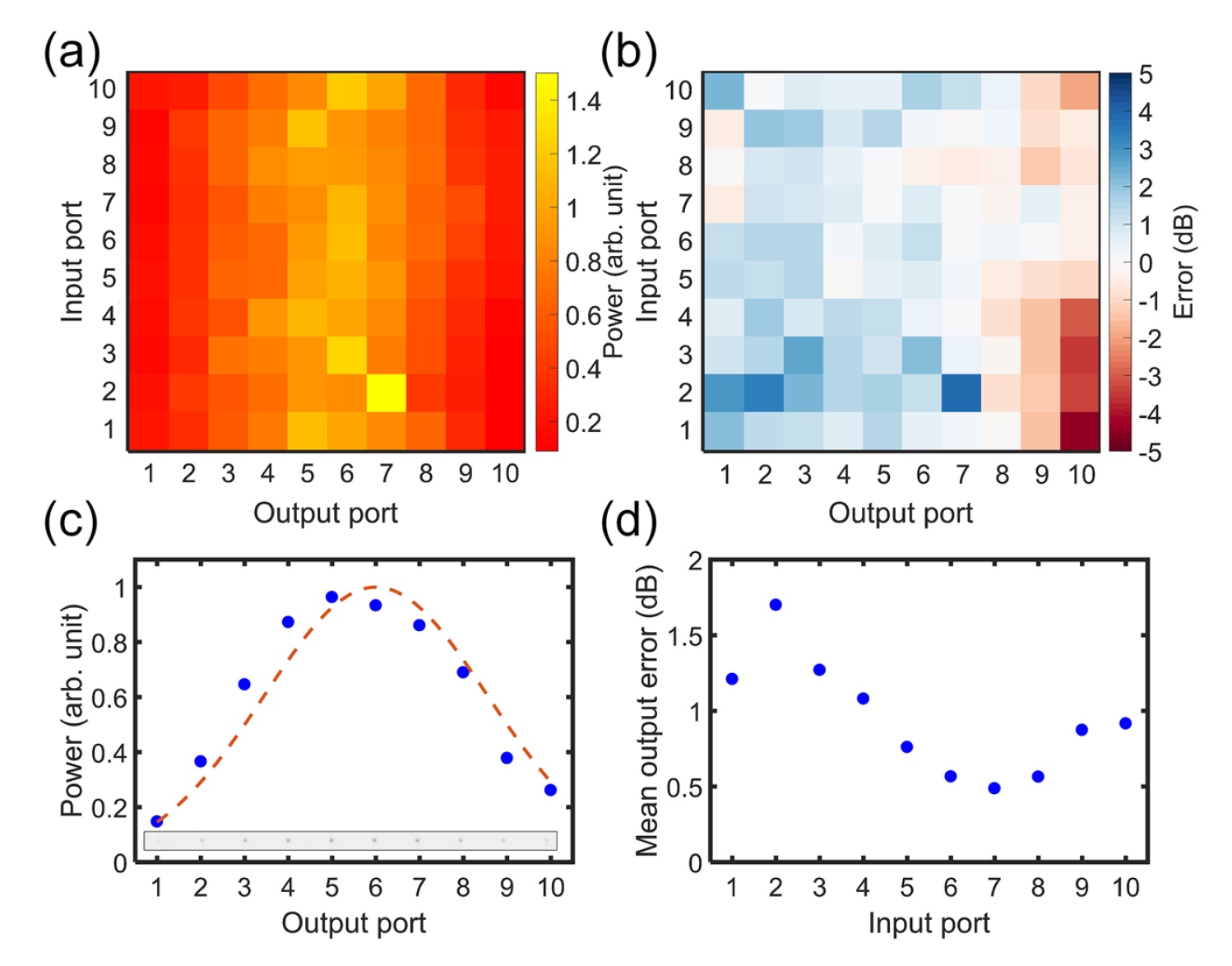
均匀分布的歧管众所周知,无论输入功率如何,都必须向每个连接的输出突触提供相同部分的功率。 例如,将光引导到输入节点Tx,我们应该看到以下功率分布:S
x,1 = S
x,2 = S
x,3 ··= S
x,10 。
 3b号图像:收集器的红外图像,显示出光如何从传出节点出现
3b号图像:收集器的红外图像,显示出光如何从传出节点出现为了满足该要求,分配系数为0.1至0.5。
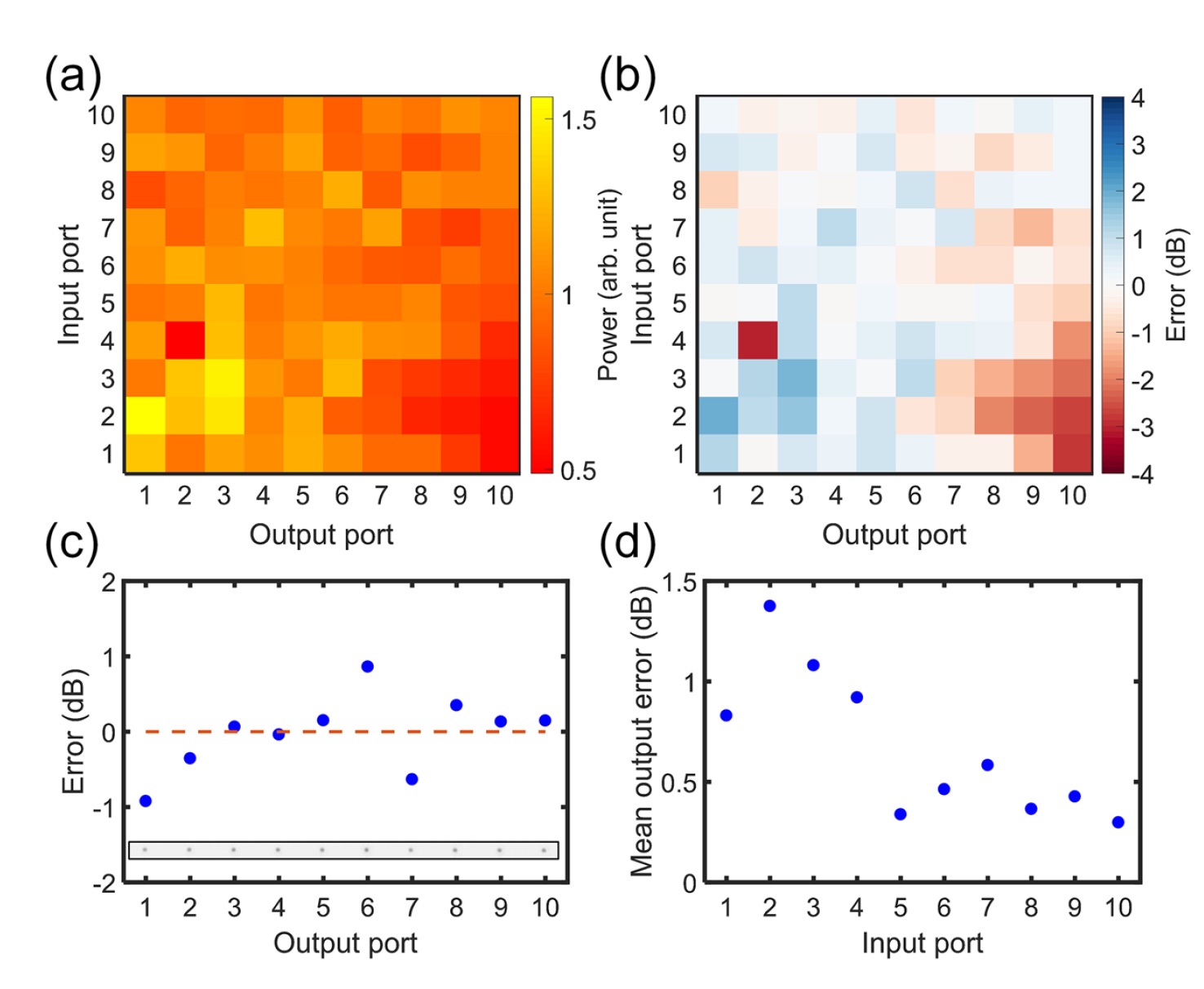 图片编号4
图片编号4在图像
4a中 ,收集了测得的强度指标,在图
4b中 ,收集了所有误差。 在这里,我们看到尽管有一些错误,但大多数突触仍显示出良好的一致性。
作为示例,显示了针对T
8 (输入)(
4s )的传出节点的功率均匀性级别。
依次将误差计算为每个点与平均值的偏差。 在图像
4d中,从图像
4b中的每行中的误差的绝对值测量平均值。 结合所有计算数据,研究人员获得了0.7 dB的平均误差值。
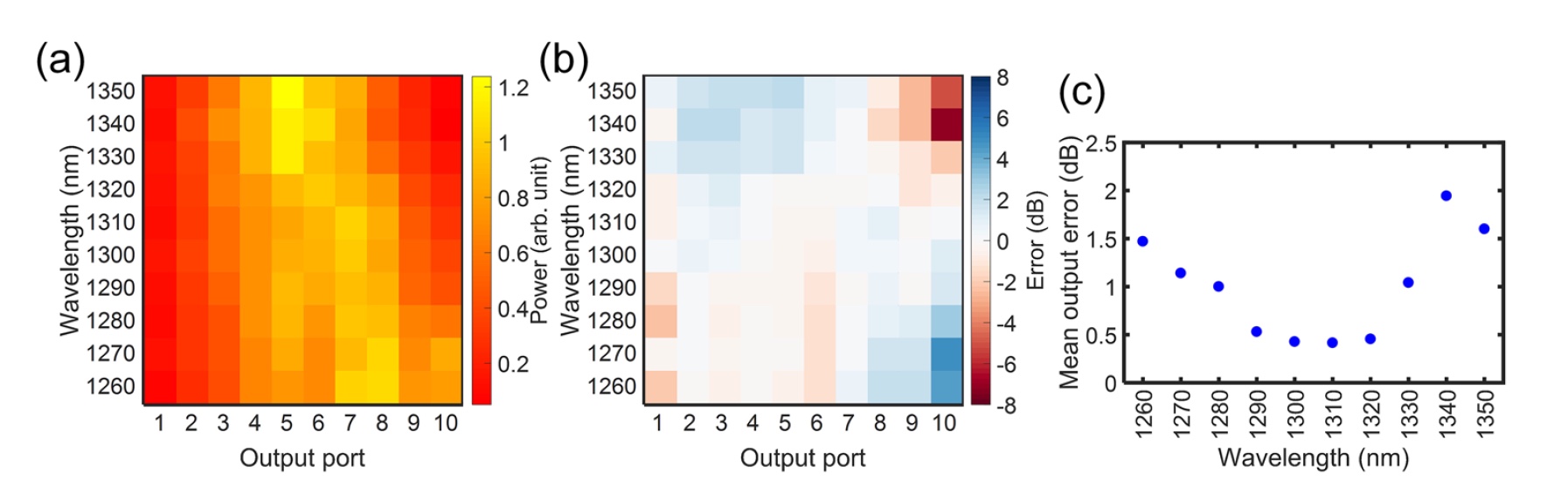
该研究的另一个重要参数是具有均匀分布的收集器的光谱依赖性。 为此,仅建立了一个输入节点T
8的连接 ,此后,观察了输出随扫描波长的均匀性变化。
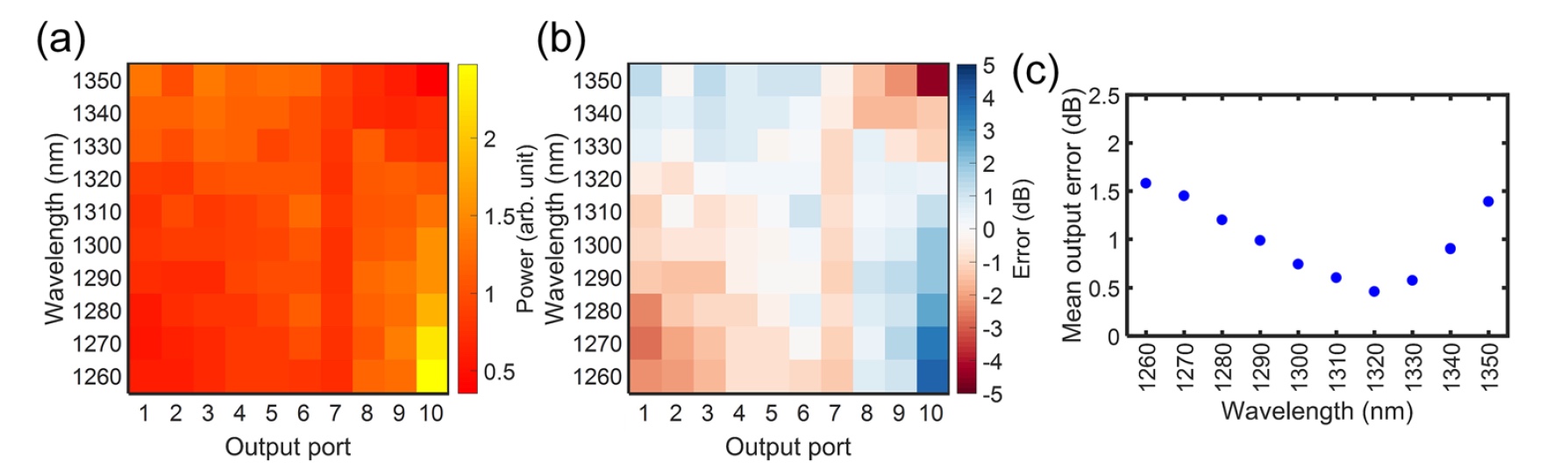 图片编号5
图片编号5图
5a示出了功率对波长的依赖性。
5b显示所有错误。
图5c显示,在1320 nm波长处观察到的最小误差平均值为0.46 dB。 即使通带为50 nm,此参数也不会超过1 dB。
高斯分布收集器该收集器以使得突触根据高斯包络原理接收功率的方式制成。
 图片编号6
图片编号6在实验确定的输入节点T
8的突触功率分布上,包络线的叠加显示出极好的一致性(
6c )。
否则,根据与先前的收集器相同的方案进行测量。
图像
6a是功率对波长的依赖性的一组指示符。
6b-错误。
曲线图
6d是考虑到来自
6b的所有序列而计算出的误差的绝对值的平均值。 这个数字是0.9 dB。
然后测量光谱依赖性。 与以前的收集器一样,只有T
8节点参与了测量。
 图片编号7
图片编号7功率对波长的依赖性在图像
7a中显示 ,误差在
7b中显示 。
同样,从图像
7a ,随着波长的增加,可以看到包络的
重心*向具有最低数量的突触的移动。
重心* -图中所有点的算术平均位置。
如图
13c所示,在1310nm的波长处观察到最小的误差值
0.42dB 。
考虑到两个版本的收集器在大约相同的波长下具有最小的误差值,因此可以认为,在1310–1320 nm的波长下可以很好地校准抽头系数。
总结通过测量两个收集器变量中的错误数量及其平均值,可以清楚地看出,数量较大的输出节点缺少电源,尤其是当它们连接到数量较小的节点时。 科学家得出的结论是,这是由于这些波导路径的交叉点很多,与其他路径相比,这增加了损耗。 此外,最长的路线的配电损耗累积高达1 dB,这会影响配电的均匀性。
观察到的错误的另一种类型是在上面的图像中清晰可见的暗突触和亮突触(例如,图像
6b中的突触S
2.7 )。 类似的缺陷很可能与
平面化过程中的机械损坏(从板表面去除不规则处)有关。
值得注意的是,此类错误可以修复。 为此,您需要调整抽头系数,以使突触接收更多的光。 这样的解决方案可以显着改善整个集电极的功率分配。
换句话说,该实验中最常见的错误是在样品制造过程中或在实验研究过程中由偶然缺陷引起的那些错误。
强度误差会影响系统的能效,而不会影响数据处理。 但这也取决于系统本身的类型。
在神经形态系统中,每个突触都需要一定数量的最小光子才能引发反应。 如果神经元和突触之间的光功率分配网络中有节点无意间接收到异常少量的光子,那么您只需要增加神经元产生的光的供应即可。 这将确保光信号到达最弱的连接。
对具有高斯分布的集电极的实验测量再次表明,由于对功率分配过程的高度控制,可以针对不同的系统架构实现这种设备。
重要的是要注意,使用此类收集器的系统可通过添加更多输入和源节点来进行扩展。 遮盖这种积极结果的唯一一件事就是与波导相交相关的损耗。 发现一条路线上的最大交叉点数目与节点数目的平方成正比。

一次穿越的损耗为6 mdB。 如果收集器具有22个输入节点和22个源节点,则总损耗率将为3 dB。 可以非常简单地避免这种情况-通过增加平面间距。 因此,尽管芯片尺寸将增加,但是损耗将最小。
要更详尽地了解研究材料,强烈建议您单击链接。结语有人会说从事这种研究的科学家正在浪费时间。 我不会那么激进。 在任何实践经验或理论反思过程中获得的任何知识,对于科学的共同利益,以及对社会生活的共同利益,都是重要的。 这就像一个难题的一小部分,没有它,难题的图片的总体概念不会改变,但是将是不完整的。
正如格奥尔格·利希滕贝格(Georg Lichtenberg)所说:
世界上最伟大的事物是由我们认为无关紧要的其他事物造成的。 (“世界上最伟大的事物是由我们认为没有的其他事物带来的。”)
感谢您与我们在一起。 你喜欢我们的文章吗? 想看更多有趣的资料吗? 通过下订单或将其推荐给您的朋友来支持我们,
为我们为您发明的入门级服务器的独特模拟,为Habr用户提供
30%的折扣: 关于VPS(KVM)E5-2650 v4(6核)的全部真相10GB DDR4 240GB SSD 1Gbps从$ 20还是如何划分服务器? (RAID1和RAID10提供选件,最多24个内核和最大40GB DDR4)。
戴尔R730xd便宜2倍? 仅
在荷兰和美国,我们有
2台Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100电视(249美元起) ! 阅读有关
如何构建基础架构大厦的信息。 使用价格为9000欧元的Dell R730xd E5-2650 v4服务器的上等课程?