与流行的看法相反,机器学习不是21世纪的发明。 在过去的二十年中,仅出现了生产率足够高的硬件平台,因此建议使用神经网络和其他机器学习模型来解决任何日常应用的问题。 算法和模型的软件实现也已加强。
使机器自己照顾我们的安全并保护人员(宁可懒,又精明)的诱惑变得太大了。 根据
CB Insights的数据,将近90家初创公司(其中2家估值超过10亿美元)正在尝试使至少部分例行和单调任务自动化。 获得不同的成功。

当前,
人工智能在安全性方面的主要问题是过度宣传和坦率的营销废话。 短语“人工智能”吸引了投资者。 来到这个行业的人们愿意将AI称为事件的最简单关联。 购买自有解决方案的买家无法实现他们的期望(即使这些期望最初过高)。

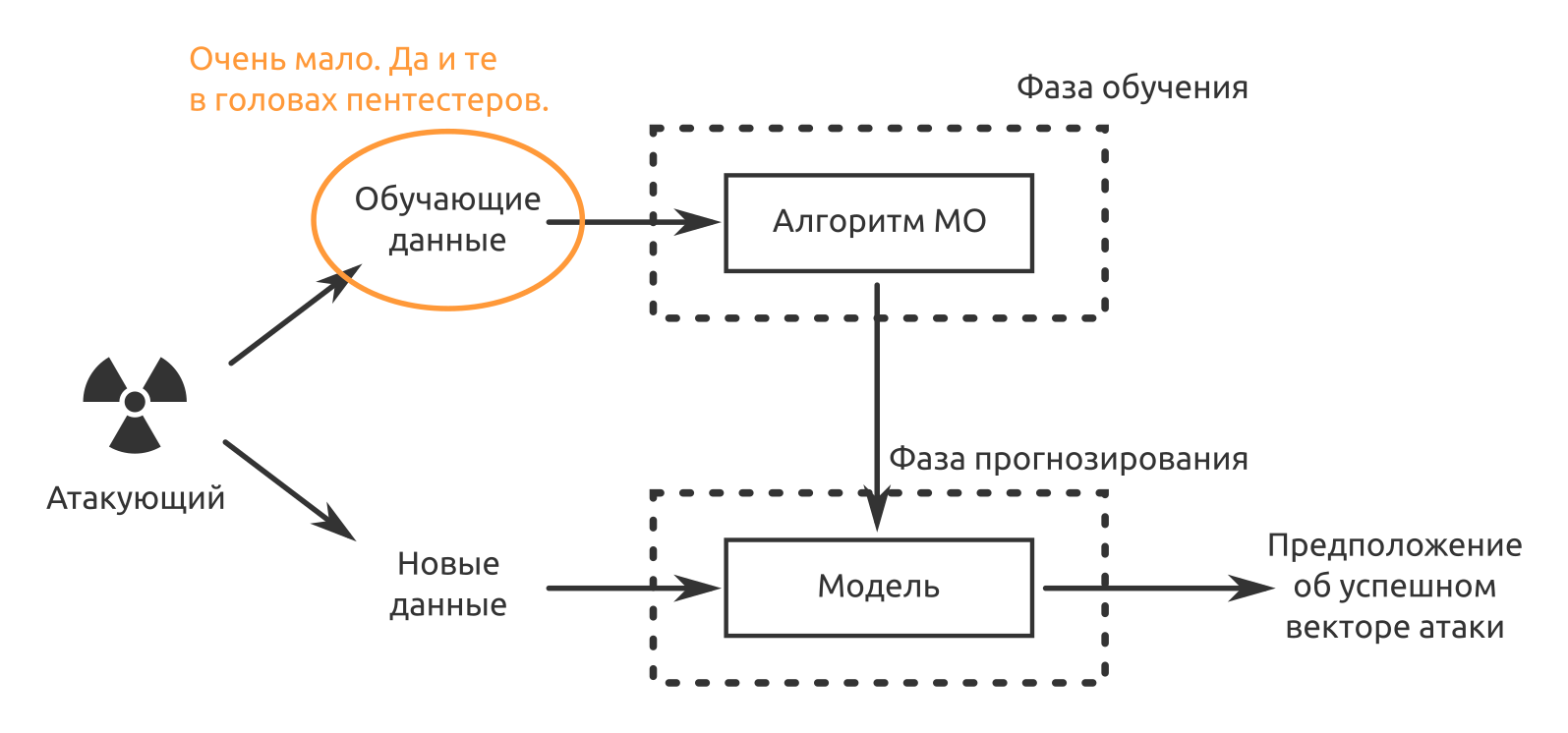
从CB Insights地图可以看出,有数十个使用MO的区域。 但是由于一些严重的局限性,机器学习尚未成为网络安全的“魔药”。
第一个限制是每个特定模型功能的狭窄适用性。 神经网络可以做一件事。 如果能够很好地识别图像,则同一网络将无法识别音频。 与信息安全性相同,例如,如果模型经过训练以对来自网络传感器的事件进行分类并检测对网络设备的计算机攻击,则它将无法与移动设备一起使用。 如果客户是AI粉丝,那么他将进行购买,购买和购买。
第二个限制是缺乏训练数据。 解决方案是经过预先培训的,但没有针对您的数据。 如果仍然可以接受“谁在操作的前两周内认为假阳性”的情况,那么将来“安全人员”会有些困惑,因为他们购买了一种解决方案,使机器可以执行常规操作,反之亦然。

到目前为止,第三个也是最重要的一点是,不能使MO产品对其决策负责。 甚至“人工智能的独特保护手段”的开发者也可以回答这样的说法:“那么,您想要什么? 神经网络是一个黑匣子! 她为什么要这样决定,除了她自己都不知道。” 因此,人们现在确认了信息安全事件。 机器有帮助,但人们仍然要负责。
信息保护存在问题。 他们将早晚解决。 但是攻击呢? MO和AI能否成为网络攻击的“银弹”?
使用机器学习来增加笔试成功或安全性分析的可能性的选项
现在,在以下情况下使用MO可能是最有利可图的:
- 您需要创建类似于神经网络已经遇到的东西;
- 有必要识别出人类不明显的模式。
MO在这些任务上已经做得很好。 但是除此之外,还可以加速某些任务。 例如,我的同事已经写过有关
使用python和metasploit进行攻击自动化的文章 。
试图愚弄
或检查员工对信息安全问题的意识。 正如我们的渗透测试实践所表明的那样,社会工程在几乎所有进行过此类攻击的项目中都取得了成功。
假设我们已经使用传统方法(公司网站,社交网络,工作站点,出版物等)恢复了:
- 组织结构;
- 主要员工名单;
- 电子邮件地址格式或真实地址
- 打了个电话,假装是潜在客户,找出了卖方,经理,秘书的名字。
接下来,我们需要获取数据以训练将模仿特定人的声音的神经网络。 在我们的案例中,来自测试公司管理层的人员。
本文指出,一分钟的声音足以真实地装扮。
我们正在寻找会议演讲的录音,我们自己去找他们录音,然后尝试与需要的人交谈。 如果我们设法模仿声音,那么我们可以为攻击的特定受害者自己造成压力。
你好
-卖方Preseylovich,您好。 这是Nachalnikovich主任。 您的手机没有响应。 现在您将收到Vector-Fake LLC的来信,请参阅。 紧急!
“是的,但是...”
-就是这样,我不能再讲话了。 我在开会 沟通之前。 回答他们!
谁不回答? 谁看不到附件? 每个人都会看到。 您可以将任何内容加载到这封信中。 同时,无需知道董事的电话号码或卖方的个人电话号码;无需在内部公司地址上伪造电子邮件地址,而恶意电子邮件将来自该公司内部地址。
顺便说一下,攻击准备(数据收集和分析)也可以部分自动化。 我们现在正在寻找可以解决此类问题并创建软件包的团队中的
开发人员 ,该软件包可以使分析人员在竞争情报和企业经济安全领域的工作变得更加轻松。
我们攻击密码系统的实现
假设我们可以监听受攻击组织的加密流量。 但是我们想知道在此流量中到底是什么。 思科员工的这项研究“
在加密的TLS流量中检测恶意代码(不解密) ”提出了这个想法。 的确,如果我们能够基于NetFlow,TLS和DNS服务数据中的数据确定恶意对象的存在,那么是什么阻止我们使用相同的数据来识别受攻击组织的员工之间以及员工与公司IT服务之间的通信?
攻击额头上的隐窝更昂贵。 因此,使用源和目标的地址和端口上的数据,传输的数据包的数量及其大小,时间参数,我们尝试确定加密的流量。
此外,在确定了p2p通信情况下的加密网关或终端节点之后,我们开始完成它们,迫使用户切换到安全性较低,更容易受到攻击的通信方法。
该方法的魅力包括两个优点:
- 该机器可以在Virtualochki上在家中进行培训。 有很多免费的甚至开源的产品可以创建安全的通信。 “机器,这样的协议,它具有这样的数据包大小,这样的熵。 你明白了吗? 还记得吗? 对不同类型的打开数据尽可能重复多次。
- 无需“驱动”并通过模型传递所有流量,仅元数据就足够了。
缺点-仍然需要接收MitM。
寻找软件错误和漏洞
自动搜索,利用和纠正漏洞的最著名尝试可能是DARPA网络大挑战。 在2016年,由不同团队设计的七个全自动系统一起参加了类似CTF的最后一场战斗。 当然,开发的目标被宣布为唯一的好–实时保护基础架构,物联网,应用程序,并且无需人员参与。 但是您可以从另一个角度看待结果。
MO在这方面发展的第一个方向是模糊自动化。 同样的CGC成员也广泛使用了美国的模糊垂度。 根据设置,模糊器在操作期间会产生或多或少的输出。 在存在大量结构化和弱结构化数据的地方,MO模型可以完美地寻找模式。 如果尝试“删除”应用程序时需要一些输入,则该方法可能会在其他地方使用。
当应用程序源代码不可用时,对可执行文件的静态代码分析和动态分析也是如此。 神经网络不仅可以查找具有漏洞的代码段,还可以查找看起来容易受到攻击的代码。 幸运的是,有许多具有已确认(和已修复)漏洞的代码。 研究人员将不得不证实这一怀疑。 随着发现每个新的错误,这样的NS将变得越来越“聪明”。 通过这种方法,您可以摆脱仅使用预写签名的麻烦。
在动态分析中,如果神经网络可以“理解”输入数据(包括用户数据),执行顺序,系统调用,内存分配和已确认的漏洞之间的关系,那么它最终可以寻找新的漏洞。
自动化操作
现在使用纯自动操作存在一个问题-
Isao Takaesu和开发Deep Exploit的其他贡献者,“使用机器学习的全自动渗透测试工具”,正试图解决这一问题。 关于他的细节写
在这里和
这里 。
此解决方案可以在两种模式下工作-数据收集模式和蛮力模式。
在第一种模式下,DE识别出受攻击主机上的所有开放端口,并启动以前用于这种组合的漏洞利用程序。
在第二种模式下,攻击者使用漏洞利用程序,有效负载和目标的所有可用组合来指示产品名称和端口号以及DE“按区域划分的命中数”。
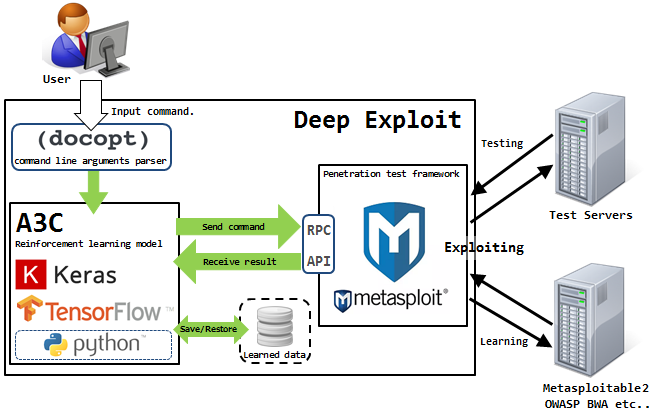
Deep Exploit可以使用强化培训来独立学习操作方法(由于DE从被攻击系统收到的反馈)。
AI可以立即取代Pentester团队吗?
可能
还没有。
机器在构建利用已发现漏洞的逻辑链方面存在问题。 但这恰恰常常直接影响渗透测试目标的实现。 机器可以发现漏洞,甚至可以自行创建漏洞,但是无法评估此漏洞对特定信息系统,信息资源或整个组织的业务流程的影响程度。
自动化系统的运行会在受攻击的系统上产生很多噪音,保护设备很容易注意到这些噪音。 汽车笨拙地工作。 在社会工程学的帮助下,可以减少这种噪音并获得系统的构想,并且机器也不是很好。
而且这些汽车没有独创性,也没有意义。 我们最近有一个项目,其中进行测试的最具成本效益的方法是使用无线电控制模型。 我无法想象没有人会想到这样的事情。
您可以提供哪些自动化想法?