在应用程序的微服务组织的情况下,大量工作取决于微服务的集成连接机制。 而且,这种集成应该是容错的,并且具有高度的可用性。
在我们的解决方案中,我们使用与Kafka,gRPC和RabbitMQ的集成。
在本文中,我们将分享我们的RabbitMQ集群经验,该集群的节点托管在Kubernetes上。

在RabbitMQ版本3.7之前,将其群集在K8S中并不是一件容易的事,因为它有很多技巧,而且解决方案也不是很好。 在版本3.6中,使用了RabbitMQ社区的自动集群插件。 并在3.7版中出现了Kubernetes Peer Discovery Backend。 它是由RabbitMQ的基本交付中的插件内置的,不需要单独的组装和安装。
在评论正在发生的事情时,我们将描述最终配置的整体。
理论上
该插件
在github上有一个
存储库 ,其中有
一个基本用法示例 。
此示例不适用于生产,其说明中已明确指出,此外,其中的某些设置与产品中使用的逻辑相反。 另外,在该示例中,根本没有提到存储的持久性,因此在任何紧急情况下,我们的集群都会变得毫无生气。
在实践中
现在,我们将告诉您您自己面临的挑战以及如何安装和配置RabbitMQ。
让我们描述在K8中作为服务的RabbitMQ各个部分的配置。 我们将立即说明,我们在K8s中将RabbitMQ安装为StatefulSet。 在K8s群集的每个节点上,RabbitMQ的一个实例将始终起作用(传统群集配置中的一个节点)。 我们还将在K8s中安装RabbitMQ控制面板,并允许在集群外部访问该面板。
权利和角色:
rabbitmq_rbac.yaml--- apiVersion: v1 kind: ServiceAccount metadata: name: rabbitmq --- kind: Role apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: endpoint-reader rules: - apiGroups: [""] resources: ["endpoints"] verbs: ["get"] --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: endpoint-reader subjects: - kind: ServiceAccount name: rabbitmq roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: endpoint-reader
RabbitMQ的访问权限完全来自示例,而无需进行任何更改。 我们为群集创建一个ServiceAccount,并将其授予Endpoints K8s的读取权限。
永久存储:
rabbitmq_pv.yaml kind: PersistentVolume apiVersion: v1 metadata: name: rabbitmq-data-sigma labels: type: local annotations: volume.alpha.kubernetes.io/storage-class: rabbitmq-data-sigma spec: storageClassName: rabbitmq-data-sigma capacity: storage: 10Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Recycle hostPath: path: "/opt/rabbitmq-data-sigma"
在这里,我们将最简单的情况作为持久性存储-hostPath(每个K8s节点上的常规文件夹),但是您可以使用K8s支持的多种持久卷中的任何一种。
rabbitmq_pvc.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: rabbitmq-data spec: storageClassName: rabbitmq-data-sigma accessModes: - ReadWriteMany resources: requests: storage: 10Gi
在上一步中创建的卷上创建卷声明。 然后,此Claim将在StatefulSet中用作持久数据存储。
服务项目:
rabbitmq_service.yaml kind: Service apiVersion: v1 metadata: name: rabbitmq-internal labels: app: rabbitmq spec: clusterIP: None ports: - name: http protocol: TCP port: 15672 - name: amqp protocol: TCP port: 5672 selector: app: rabbitmq
我们创建了一个内部的headless服务,Peer Discovery插件将通过该服务运行。
rabbitmq_service_ext.yaml kind: Service apiVersion: v1 metadata: name: rabbitmq labels: app: rabbitmq type: LoadBalancer spec: type: NodePort ports: - name: http protocol: TCP port: 15672 targetPort: 15672 nodePort: 31673 - name: amqp protocol: TCP port: 5672 targetPort: 5672 nodePort: 30673 selector: app: rabbitmq
为了使K8s中的应用程序能够与我们的集群一起使用,我们创建了平衡器服务。
由于我们需要访问K8之外的RabbitMQ集群,因此我们将遍历NodePort。 当访问端口31673和30673上的K8s集群的任何节点时,RabbitMQ将可用。在实际工作中,对此没有太大需求。 RabbitMQ管理面板的可用性问题。
在K8s中使用NodePort类型创建服务时,也会隐式创建ClusterIP类型的服务来为其提供服务。 因此,需要与RabbitMQ一起使用的K8中的应用程序将能够通过
amqp访问群集
:// Rabbitmq:5672配置:
rabbitmq_configmap.yaml apiVersion: v1 kind: ConfigMap metadata: name: rabbitmq-config data: enabled_plugins: | [rabbitmq_management,rabbitmq_peer_discovery_k8s]. rabbitmq.conf: | cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s cluster_formation.k8s.host = kubernetes.default.svc.cluster.local cluster_formation.k8s.port = 443 ### cluster_formation.k8s.address_type = ip cluster_formation.k8s.address_type = hostname cluster_formation.node_cleanup.interval = 10 cluster_formation.node_cleanup.only_log_warning = true cluster_partition_handling = autoheal queue_master_locator=min-masters cluster_formation.randomized_startup_delay_range.min = 0 cluster_formation.randomized_startup_delay_range.max = 2 cluster_formation.k8s.service_name = rabbitmq-internal cluster_formation.k8s.hostname_suffix = .rabbitmq-internal.our-namespace.svc.cluster.local
我们创建RabbitMQ配置文件。 主要魔术。
enabled_plugins: | [rabbitmq_management,rabbitmq_peer_discovery_k8s].
将必要的插件添加到允许下载的插件中。 现在,我们可以在K8S中使用自动对等发现。
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s
我们公开了必要的插件作为对等发现的后端。
cluster_formation.k8s.host = kubernetes.default.svc.cluster.local cluster_formation.k8s.port = 443
指定可以访问kubernetes apiserver的地址和端口。 在这里,您可以直接指定ip地址,但是这样做会更漂亮。
在名称空间默认情况下,通常会使用名称kubernetes创建服务,该服务将导致k8-apiserver。 在不同的K8S安装选项中,名称空间,服务名称和端口可能不同。 如果特定安装中的某些内容不同,则需要相应地对其进行修复。
例如,我们面临这样一个事实,在某些群集中,该服务位于端口443上,而在某些群集中,该服务位于6443上。可以理解,RabbitMQ启动日志中出现了问题,此处的到此地址的连接时间清楚地突出显示了。
### cluster_formation.k8s.address_type = ip cluster_formation.k8s.address_type = hostname
默认情况下,该示例通过IP地址指定RabbitMQ集群节点的地址类型。 但是,当您重新启动Pod时,它每次都会获得一个新IP。 惊喜! 集群快要死了。
将地址更改为主机名。 StatefulSet保证了主机名在整个StatefulSet生命周期内的不变性,这完全适合我们。
cluster_formation.node_cleanup.interval = 10 cluster_formation.node_cleanup.only_log_warning = true
由于当我们丢失一个节点时,我们假设它早晚会恢复,因此我们通过一群无法访问的节点禁用自删除。 在这种情况下,节点一旦返回联机状态,它将立即进入群集而不会丢失其先前状态。
cluster_partition_handling = autoheal
此参数确定在仲裁丢失的情况下群集的操作。 在这里,您只需要阅读
有关此主题的
文档,并自己了解更接近特定用例的内容。
queue_master_locator=min-masters
确定新队列的向导选择。 使用此设置,向导将选择队列数量最少的节点,因此队列将在群集节点之间平均分配。
cluster_formation.k8s.service_name = rabbitmq-internal
我们命名无头K8s服务(由我们之前创建),RabbitMQ节点将通过该服务彼此通信。
cluster_formation.k8s.hostname_suffix = .rabbitmq-internal.our-namespace.svc.cluster.local
在群集中寻址的重要事项是主机名。 K8炉膛的FQDN由短名称(rabbitmq-0,rabbitmq-1)+后缀(域部分)组成。 在这里,我们指出这个后缀。 在K8S中,它看起来像
。<服务名称>。<名称空间名称> .svc.cluster.localkube-dns可以将格式RabbitMq-0.rabbitmq-internal.our-namespace.svc.cluster.local解析为特定容器的IP地址,而无需任何其他配置,这使通过主机名进行群集的所有魔术成为可能。
StatefulSet RabbitMQ配置:
rabbitmq_statefulset.yaml apiVersion: apps/v1beta1 kind: StatefulSet metadata: name: rabbitmq spec: serviceName: rabbitmq-internal replicas: 3 template: metadata: labels: app: rabbitmq annotations: scheduler.alpha.kubernetes.io/affinity: > { "podAntiAffinity": { "requiredDuringSchedulingIgnoredDuringExecution": [{ "labelSelector": { "matchExpressions": [{ "key": "app", "operator": "In", "values": ["rabbitmq"] }] }, "topologyKey": "kubernetes.io/hostname" }] } } spec: serviceAccountName: rabbitmq terminationGracePeriodSeconds: 10 containers: - name: rabbitmq-k8s image: rabbitmq:3.7 volumeMounts: - name: config-volume mountPath: /etc/rabbitmq - name: rabbitmq-data mountPath: /var/lib/rabbitmq/mnesia ports: - name: http protocol: TCP containerPort: 15672 - name: amqp protocol: TCP containerPort: 5672 livenessProbe: exec: command: ["rabbitmqctl", "status"] initialDelaySeconds: 60 periodSeconds: 10 timeoutSeconds: 10 readinessProbe: exec: command: ["rabbitmqctl", "status"] initialDelaySeconds: 10 periodSeconds: 10 timeoutSeconds: 10 imagePullPolicy: Always env: - name: MY_POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: HOSTNAME valueFrom: fieldRef: fieldPath: metadata.name - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: RABBITMQ_USE_LONGNAME value: "true" - name: RABBITMQ_NODENAME value: "rabbit@$(HOSTNAME).rabbitmq-internal.$(NAMESPACE).svc.cluster.local" - name: K8S_SERVICE_NAME value: "rabbitmq-internal" - name: RABBITMQ_ERLANG_COOKIE value: "mycookie" volumes: - name: config-volume configMap: name: rabbitmq-config items: - key: rabbitmq.conf path: rabbitmq.conf - key: enabled_plugins path: enabled_plugins - name: rabbitmq-data persistentVolumeClaim: claimName: rabbitmq-data
实际上,StatefulSet本身。 我们注意到有趣的观点。
serviceName: rabbitmq-internal
我们在StatefulSet中写下Pod通过其进行通信的无头服务的名称。
replicas: 3
设置集群中的副本数。 在我们国家,它等于K8个工作节点的数量。
annotations: scheduler.alpha.kubernetes.io/affinity: > { "podAntiAffinity": { "requiredDuringSchedulingIgnoredDuringExecution": [{ "labelSelector": { "matchExpressions": [{ "key": "app", "operator": "In", "values": ["rabbitmq"] }] }, "topologyKey": "kubernetes.io/hostname" }] } }
当K8s节点之一掉落时,有状态集试图保留集合中实例的数量,因此,它在同一K8s节点上创建了多个炉床。 这种行为是完全不希望的,并且原则上是毫无意义的。 因此,我们为来自有状态集的炉床集制定了反亲和性规则。 我们将规则设置为严格(必需),以便在计划吊舱时kube-scheduler不会破坏该规则。
本质上很简单:调度程序禁止在
应用程序内(名称空间内)放置多个Pod
:每个节点上有
Rabbitmq标记 。 我们通过
kubernetes.io/hostname标签的值来区分
节点 。 现在,如果由于某些原因,工作中的K8S节点的数量少于StatefulSet中所需的副本数,则只有在空闲节点再次出现之前,才会创建新副本。
serviceAccountName: rabbitmq
我们注册ServiceAccount,我们的Pod在该帐户下工作。
image: rabbitmq:3.7
RabbitMQ的图像是完全标准的,并且是从docker hub获得的;它不需要任何重建和文件修订。
- name: rabbitmq-data mountPath: /var/lib/rabbitmq/mnesia
来自RabbitMQ的持久数据存储在/ var / lib / rabbitmq / mnesia中。 在这里,我们将持久卷声明安装在此文件夹中,以便在重新启动炉床/节点或什至整个StatefulSet时,数据(包括有关已组装群集的所有服务和用户数据)都是安全无害的。 有一些示例使整个/ var / lib / rabbitmq /文件夹具有持久性。 我们得出的结论是,这不是最好的主意,因为与此同时,Rabbit配置所设置的所有信息都将被记住。 也就是说,为了更改配置文件中的某些内容,您需要清除持久性存储,这在操作中非常不方便。
- name: HOSTNAME valueFrom: fieldRef: fieldPath: metadata.name - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: RABBITMQ_USE_LONGNAME value: "true" - name: RABBITMQ_NODENAME value: "rabbit@$(HOSTNAME).rabbitmq-internal.$(NAMESPACE).svc.cluster.local"
有了这组环境变量,我们首先告诉RabbitMQ使用FQDN名称作为集群成员的标识符,其次,我们设置该名称的格式。 解析配置时,前面已经描述了格式。
- name: K8S_SERVICE_NAME value: "rabbitmq-internal"
集群成员之间进行通信的无头服务的名称。
- name: RABBITMQ_ERLANG_COOKIE value: "mycookie"
Erlang Cookie的内容在集群的所有节点上都应该相同,您需要注册自己的值。 具有其他Cookie的节点无法进入集群。
volumes: - name: rabbitmq-data persistentVolumeClaim: claimName: rabbitmq-data
从先前创建的“持久卷声明”中定义映射的卷。
这就是我们在K8s中完成设置的地方。 结果是RabbitMQ集群,该集群在节点之间平均分配队列,并且可以抵抗运行时环境中的问题。
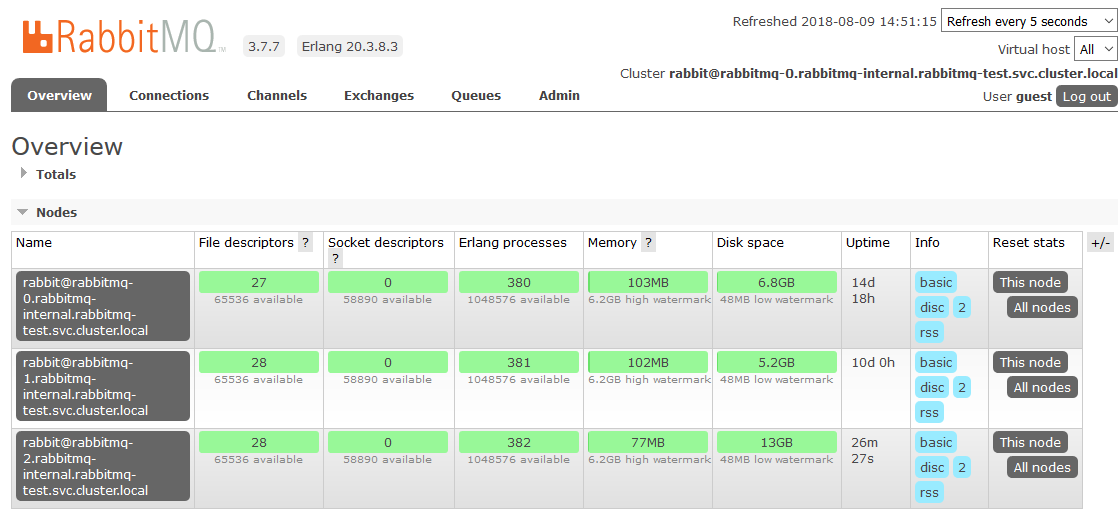
如果群集节点之一不可用,则包含在其中的队列将停止访问,其他所有节点将继续工作。 节点一旦恢复运行,它将返回集群,并且原来作为主节点的队列将再次运行,并保留其中包含的所有数据(当然,如果持久性存储未损坏)。 所有这些过程都是全自动的,不需要干预。
奖励:自定义HA
其中一个项目是细微差别。 这些要求完善了集群中所有数据的镜像。 这是必要的,以便在至少一个群集节点可运行的情况下,从应用程序的角度来看,一切都将继续工作。 此刻与K8s无关,我们仅将其描述为一个小型操作方法。
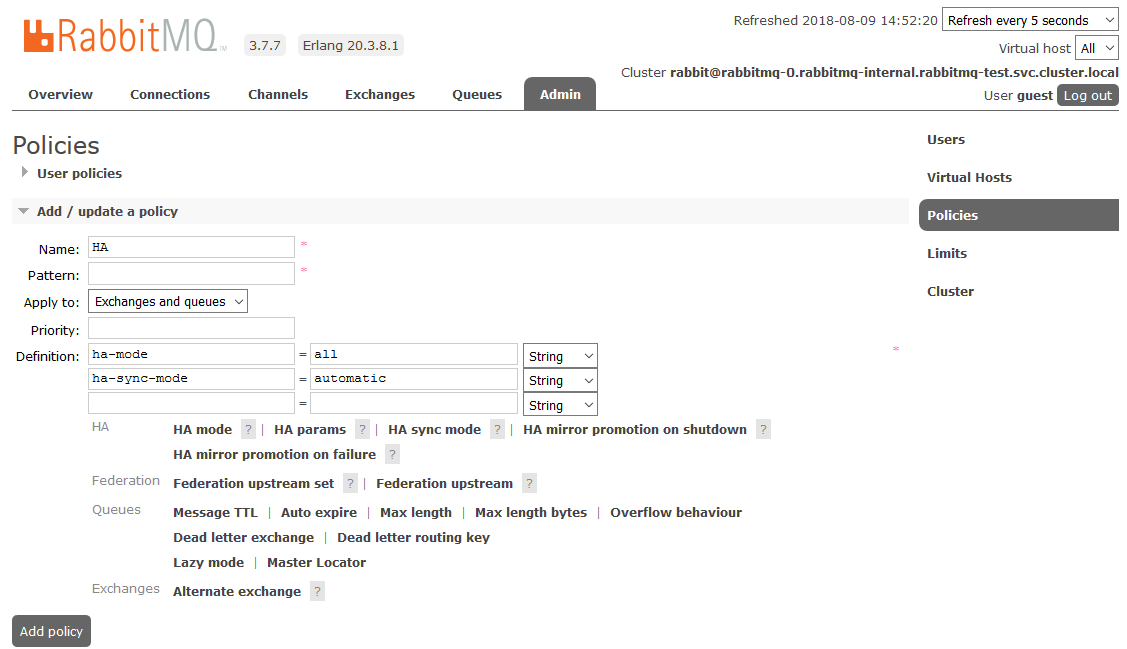
要启用完整的HA,您需要在Admin-
> Policies选项卡上的RabbitMQ仪表板中创建一个Policy。 名称是任意的,模式为空(所有队列),在“定义”中添加两个参数:
ha-mode:all ,
ha-sync-mode:automatic 。
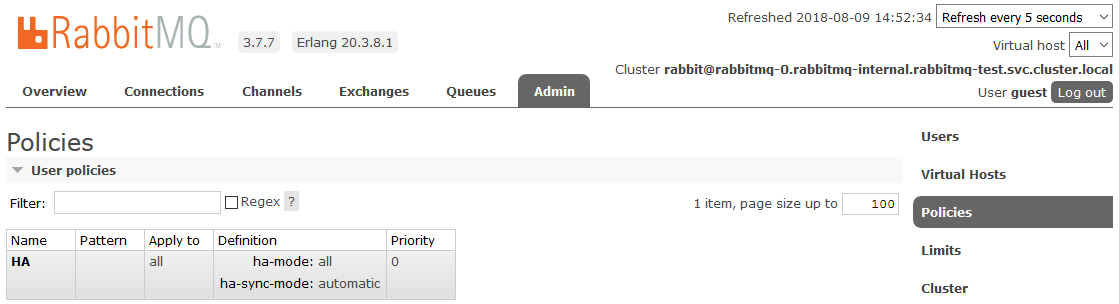
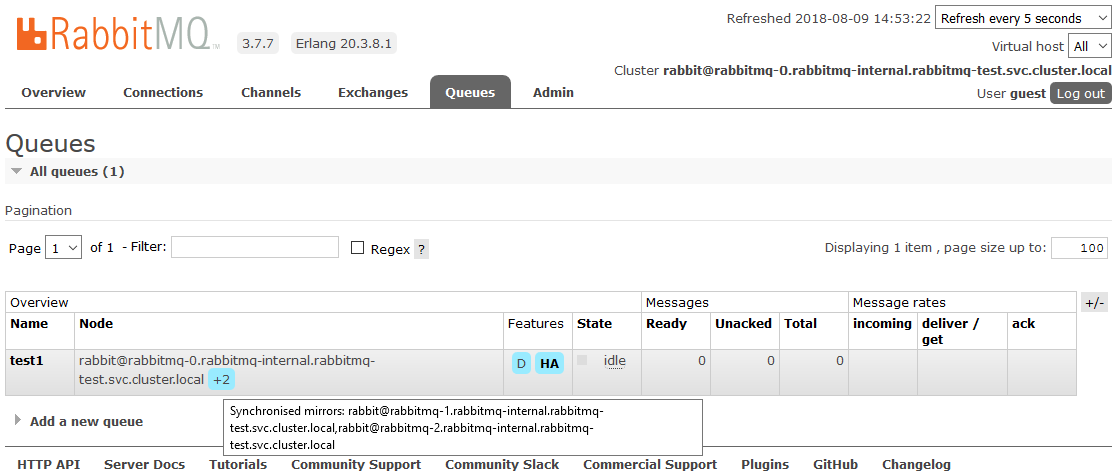
之后,集群中创建的所有队列将处于高可用性模式:如果主节点不可用,则新向导将自动选择其中一个从站。 并且进入队列的数据将被镜像到集群的所有节点。 实际上,这是必须接收的。
在
此处阅读有关RabbitMQ中的HA的更多信息
有用的文献:
祝你好运!