哈Ha! 我向您介绍Elvis Saravia撰写的文章“
用深度卷积神经网络检测讽刺 ”的翻译。
自然语言处理中的关键问题之一是讽刺检测。 在其他领域,例如情绪计算和情绪分析,检测讽刺很重要,因为这可能反映出句子的极性。
本文介绍了如何检测讽刺,并提供了到
神经网络讽刺检测器的链接。
讽刺可以看作是刺痛的嘲讽或讽刺的表达。 讽刺的例子:“我每周工作40个小时以保持贫困”,或“如果患者真的想生存,医生将无能为力。”
要了解和发现讽刺,重要的是要了解与事件有关的事实。 这揭示了客观极性(通常为负)和作者传达的讽刺特征(通常为正)之间的矛盾。
考虑一个例子:“我喜欢分开的痛苦。”
如果这句话有讽刺意味,那很难理解。 在此示例中,“我喜欢痛苦”使作者了解了表达的感觉(在这种情况下为肯定),“分开”描述了矛盾的感觉(否定)。
在理解讽刺性陈述中存在的其他问题是对多个事件的引用以及对提取大量事实,常识和逻辑推理的需求。
型号
出现讽刺的沟通中经常会出现“情绪转变”。 因此,建议首先准备一种情绪模型(基于CNN)以提取情绪信号。 该模型在第一层中选择局部特征,然后将其转换为更高级别的全局特征。 讽刺表达是针对特定用户的-一些用户比其他用户使用更多的讽刺。
在提出的嘲讽检测模型中,使用了人格特质,情绪迹象和基于情绪的迹象。 一组检测器是旨在检测讽刺的框架。 通过单独的预训练模型研究每组属性。
CNN框架
CNN可以有效地建模局部要素的层次结构以突出显示全局要素,这对于检查上下文是必不可少的。 输入数据显示为单词向量。 对于输入数据的初始处理,使用了Google的word2vec。 向量的参数是在训练阶段获得的。 然后将最大并集应用于函数映射以创建函数。 在完全粘合的层之后,有一个softmax层以获得最终预测。
下图显示了该体系结构。
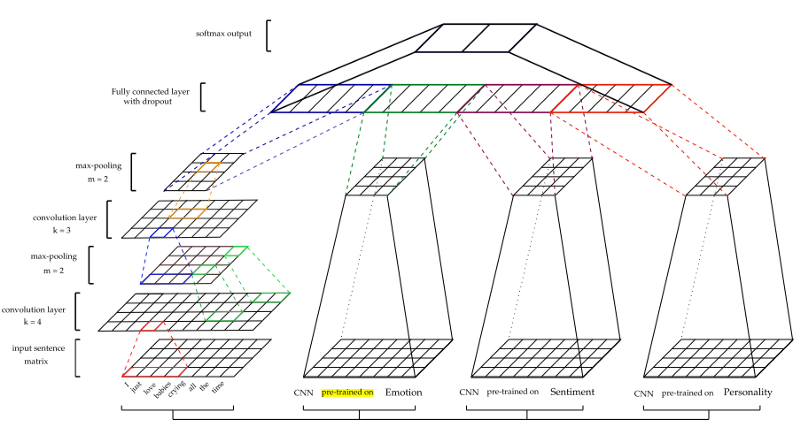
为了获得其他特征-情绪(S),情绪(E)和个性(P)-CNN模型经过初步训练,并用于从讽刺数据集中提取特征。 为了训练每个模型,使用了不同的训练数据集。 (有关更多详细信息,请参阅文档)
测试了两个分类器-纯CNN分类器(CNN)和传递到SVM分类器(CNN-SVM)的CNN提取特征。
还训练了一个单独的基本分类器(B),该分类器仅包含CNN模型,不包含其他模型(例如,情绪和情绪)。
实验
资料。 平衡和不平衡的数据集来自(Ptacek et al。,2014)和
讽刺探测器 。 删除用户名,URL和哈希标记,然后应用NLTK Twitter标记程序。
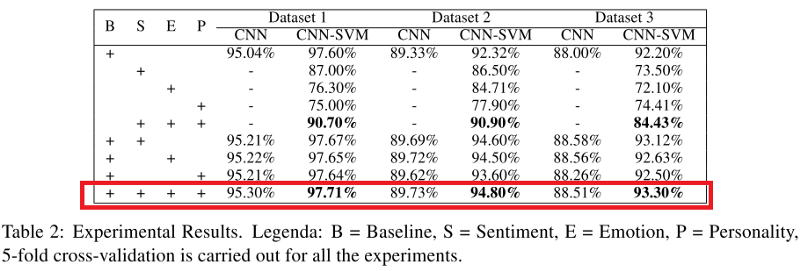
下表显示了应用于所有数据集的CNN和CNN-SVM分类器的指标。 您可能会注意到,当一个模型(尤其是CNN-SVM)结合了讽刺,情感,感觉和性格特征的标志时,除了基本模型(B)之外,它超越了所有其他模型。
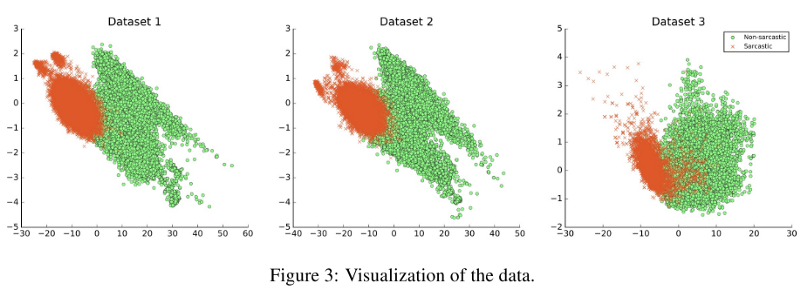
测试了模型的通用性的可能性,主要结论是,如果数据集本质上不同,则这会严重影响结果,如下图所示。 例如,对数据集1进行了训练,对数据集2进行了测试; 该模型的F1得分是33.05%。