在该公司,我们用于抵抗DDoS攻击的团队称为“数据包丢弃程序”。 当其他所有团队都在通过我们的网络进行流量时,正在做一些很酷的事情,但是我们很高兴找到摆脱它的新方法。
 照片: Brian Evans , CC BY-SA 2.0
照片: Brian Evans , CC BY-SA 2.0快速丢弃数据包的能力对于抵抗DDoS攻击非常重要。
到达我们服务器的丢弃数据包可以在多个级别上执行。 每种方法都有其优缺点。 在削减下,我们将查看我们测试的所有内容。
译者注:在某些所示命令的输出中,删除了多余的空格以保持可读性。
测试地点
为了方便比较方法,我们将为您提供一些数字,但是由于测试的人为因素,请不要从字面上看。 我们将使用我们的Intel 10Gb / s网卡之一。 剩下的服务器特性并不是那么重要,因为我们要关注的是操作系统的限制,而不是硬件的限制。
我们的测试如下所示:
- 我们创建了大量的小型UDP数据包,达到每秒1400万个数据包的负载;
- 所有这些流量都定向到所选服务器的一个处理器核心。
- 我们测量单个处理器内核上内核处理的数据包数量。
人工流量的生成方式会产生最大负载:使用随机IP地址和发送方端口。 这是tcpdump中的样子:
$ tcpdump -ni vlan100 -c 10 -t udp and dst port 1234 IP 198.18.40.55.32059 > 198.18.0.12.1234: UDP, length 16 IP 198.18.51.16.30852 > 198.18.0.12.1234: UDP, length 16 IP 198.18.35.51.61823 > 198.18.0.12.1234: UDP, length 16 IP 198.18.44.42.30344 > 198.18.0.12.1234: UDP, length 16 IP 198.18.106.227.38592 > 198.18.0.12.1234: UDP, length 16 IP 198.18.48.67.19533 > 198.18.0.12.1234: UDP, length 16 IP 198.18.49.38.40566 > 198.18.0.12.1234: UDP, length 16 IP 198.18.50.73.22989 > 198.18.0.12.1234: UDP, length 16 IP 198.18.43.204.37895 > 198.18.0.12.1234: UDP, length 16 IP 198.18.104.128.1543 > 198.18.0.12.1234: UDP, length 16
在选定的服务器上,所有数据包都将进入一个RX队列,因此将由一个内核处理。 我们通过硬件流控制来实现:
ethtool -N ext0 flow-type udp4 dst-ip 198.18.0.12 dst-port 1234 action 2
性能测试是一个复杂的过程。 在准备测试时,我们注意到活动的原始套接字的存在会对性能产生负面影响,因此在运行测试之前,您需要确保没有
tcpdump正在运行。 有一种简单的方法来检查不良过程:
$ ss -A raw,packet_raw -l -p|cat Netid State Recv-Q Send-Q Local Address:Port p_raw UNCONN 525157 0 *:vlan100 users:(("tcpdump",pid=23683,fd=3))
最后,我们在服务器上关闭Intel Turbo Boost:
echo 1 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo
尽管Turbo Boost是一件了不起的事,并且将吞吐量提高了至少20%,但它大大破坏了我们测试中的标准偏差。 涡轮增压时,偏差达到±1.5%,而没有涡轮偏差时仅为0.25%。
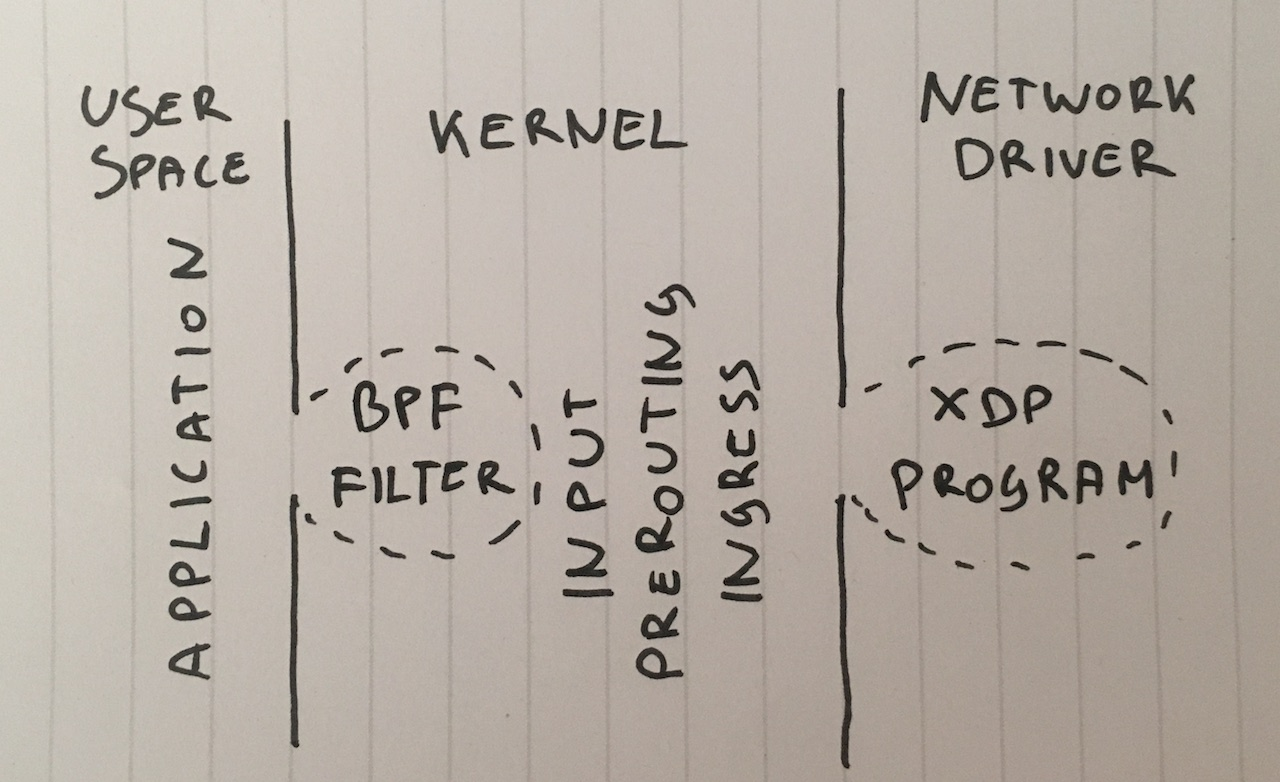
步骤1.在应用程序中丢弃数据包
让我们从将所有软件包交付给应用程序并在此处忽略它们的想法开始。 出于实验的诚实,请确保iptables不会以任何方式影响性能:
iptables -I PREROUTING -t mangle -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT iptables -I INPUT -t filter -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
该应用程序是一个简单的周期,其中接收到的数据将立即被丢弃:
s = socket.socket(AF_INET, SOCK_DGRAM) s.bind(("0.0.0.0", 1234)) while True: s.recvmmsg([...])
我们已经准备好
代码 ,运行:
$ ./dropping-packets/recvmmsg-loop packets=171261 bytes=1940176
根据
ethtool和
我们的 mmwatch测量,该解决方案允许内核仅从硬件队列中获取17.5万个数据包:
$ mmwatch 'ethtool -S ext0|grep rx_2' rx2_packets: 174.0k/s
从技术上讲,每秒有1400万个数据包到达服务器,但是,一个处理器内核无法应付这样的容量。
mpstat确认了这一点:
$ watch 'mpstat -u -I SUM -P ALL 1 1|egrep -v Aver' 01:32:05 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 01:32:06 PM 0 0.00 0.00 0.00 2.94 0.00 3.92 0.00 0.00 0.00 93.14 01:32:06 PM 1 2.17 0.00 27.17 0.00 0.00 0.00 0.00 0.00 0.00 70.65 01:32:06 PM 2 0.00 0.00 0.00 0.00 0.00 100.00 0.00 0.00 0.00 0.00 01:32:06 PM 3 0.95 0.00 1.90 0.95 0.00 3.81 0.00 0.00 0.00 92.38
如我们所见,应用程序不是瓶颈:CPU#1的使用率为27.17%+ 2.17%,而中断处理在CPU#2上的占用率为100%。
使用
recvmessagge(2)扮演着重要的角色。 发现Spectre漏洞后,由于内核中使用了
KPTI和
retpoline ,系统调用变得更加昂贵
$ tail -n +1 /sys/devices/system/cpu/vulnerabilities/* ==> /sys/devices/system/cpu/vulnerabilities/meltdown <== Mitigation: PTI ==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <== Mitigation: __user pointer sanitization ==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <== Mitigation: Full generic retpoline, IBPB, IBRS_FW
步骤2.杀死conntrack
我们专门用不同的IP和发送方端口进行了这种加载,以便尽可能多地加载conntrack。 测试期间conntrack中的条目数趋于最大可能,我们可以验证这一点:
$ conntrack -C 2095202 $ sysctl net.netfilter.nf_conntrack_max net.netfilter.nf_conntrack_max = 2097152
此外,在
dmesg您还可以看到conntrack的尖叫声:
[4029612.456673] nf_conntrack: nf_conntrack: table full, dropping packet [4029612.465787] nf_conntrack: nf_conntrack: table full, dropping packet [4029617.175957] net_ratelimit: 5731 callbacks suppressed
因此,我们将其关闭:
iptables -t raw -I PREROUTING -d 198.18.0.12 -p udp -m udp --dport 1234 -j NOTRACK
并重新启动测试:
$ ./dropping-packets/recvmmsg-loop packets=331008 bytes=5296128
这使我们能够达到每秒33.3万个数据包的标记。 万岁!
PS使用SO_BUSY_POLL,我们可以达到每秒47万的速度,但是,这是另一篇文章的主题。
步骤3.伯克利批次过滤器
让我们继续前进。 为什么我们需要将软件包交付给应用程序? 尽管这不是一个常见的解决方案,但是我们可以通过调用
setsockopt(SO_ATTACH_FILTER)将经典的Berkeley数据包筛选器绑定到套接字,并配置该筛选器以将数据包丢回到内核中。
准备
代码 ,运行:
$ ./bpf-drop packets=0 bytes=0
使用数据包过滤器(经典和高级伯克利过滤器可提供大致相似的性能),我们每秒可得到约512,000个数据包。 此外,在中断期间丢弃数据包使处理器不必唤醒应用程序。
步骤4.路由后的iptables DROP
现在,我们可以通过向INPUT链中的iptables添加以下规则来丢弃数据包:
iptables -I INPUT -d 198.18.0.12 -p udp --dport 1234 -j DROP
让我提醒您,我们已经使用
-j NOTRACK规则禁用了conntrack。 这两个规则使我们每秒获得608,000个数据包。
让我们看一下iptables中的数字:
$ mmwatch 'iptables -L -v -n -x | head' Chain INPUT (policy DROP 0 packets, 0 bytes) pkts bytes target prot opt in out source destination 605.9k/s 26.7m/s DROP udp -- * * 0.0.0.0/0 198.18.0.12 udp dpt:1234
好吧,还不错,但是我们可以做得更好。
步骤5.在PREROUTING中iptabes DROP
一种更快的技术是使用此规则在路由之前丢弃数据包:
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j DROP
这使我们每秒可以丢弃大量的168.80万个数据包。
实际上,这是性能上的令人惊讶的飞跃。 我仍然不明白原因,也许我们的路由很复杂,或者仅仅是服务器配置中的错误。
无论如何,原始iptables都快得多。
步骤6. nftables DROP
iptables实用程序现在有点旧了。 她被nftables取代。
观看这段视频,了解为什么nftables排名第一。 由于多种原因,Nftables承诺比使iptables变灰更快,其中包括谣言说repolines会大大降低iptables的速度。
但是我们的文章仍然不是关于比较iptables和nftables的,所以让我们尝试最快的方法:
nft add table netdev filter nft -- add chain netdev filter input { type filter hook ingress device vlan100 priority -500 \; policy accept \; } nft add rule netdev filter input ip daddr 198.18.0.0/24 udp dport 1234 counter drop nft add rule netdev filter input ip6 daddr fd00::/64 udp dport 1234 counter drop
计数器可以这样看:
$ mmwatch 'nft --handle list chain netdev filter input' table netdev filter { chain input { type filter hook ingress device vlan100 priority -500; policy accept; ip daddr 198.18.0.0/24 udp dport 1234 counter packets 1.6m/s bytes 69.6m/s drop
nftables输入挂钩显示的值约为153万包。 这比iptables中的PREROUTING链少一点。 但这是一个谜:从理论上讲,nftables挂钩比PREROUTING iptables更早,因此应更快地处理。
在我们的测试中,nftables比iptables慢一点,但是无论如何,nftables都更凉爽。 :P
步骤7. tc DROP
出乎意料的是,tc(流量控制)挂钩比iptables PREROUTING更早发生。 tc允许我们根据简单的标准选择数据包,当然也可以丢弃它们。 语法有点不寻常,因此我们建议使用
此脚本进行配置。 我们需要一个相当复杂的规则,如下所示:
tc qdisc add dev vlan100 ingress tc filter add dev vlan100 parent ffff: prio 4 protocol ip u32 match ip protocol 17 0xff match ip dport 1234 0xffff match ip dst 198.18.0.0/24 flowid 1:1 action drop tc filter add dev vlan100 parent ffff: protocol ipv6 u32 match ip6 dport 1234 0xffff match ip6 dst fd00::/64 flowid 1:1 action drop
我们可以对其进行检查:
$ mmwatch 'tc -s filter show dev vlan100 ingress' filter parent ffff: protocol ip pref 4 u32 filter parent ffff: protocol ip pref 4 u32 fh 800: ht divisor 1 filter parent ffff: protocol ip pref 4 u32 fh 800::800 order 2048 key ht 800 bkt 0 flowid 1:1 (rule hit 1.8m/s success 1.8m/s) match 00110000/00ff0000 at 8 (success 1.8m/s ) match 000004d2/0000ffff at 20 (success 1.8m/s ) match c612000c/ffffffff at 16 (success 1.8m/s ) action order 1: gact action drop random type none pass val 0 index 1 ref 1 bind 1 installed 1.0/s sec Action statistics: Sent 79.7m/s bytes 1.8m/s pkt (dropped 1.8m/s, overlimits 0 requeues 0)
tc挂钩使我们可以在单个内核上每秒丢弃多达180万个数据包。 太好了!
但是我们可以更快地做到这一点...
步骤8. XDP_DROP
最后,我们最强大的武器:XDP-
eXpress数据路径 。 使用XDP,我们可以直接在网络驱动程序的上下文中运行扩展的Berkley数据包筛选器(eBPF)代码,最重要的是,甚至可以在为
skbuff分配内存之前
skbuff ,这有望提高速度。
通常,XDP项目由两部分组成:
- 可下载的eBPF代码
- 引导加载程序将代码放入正确的网络接口
编写引导加载程序是一项艰巨的任务,因此只需使用
新的iproute2芯片并使用简单的命令加载代码即可:
ip link set dev ext0 xdp obj xdp-drop-ebpf.o
塔坝!
可在此处下载可下载的eBPF程序的源代码。 该程序查看IP数据包的特征,例如UDP协议,发送者子网和目标端口:
if (h_proto == htons(ETH_P_IP)) { if (iph->protocol == IPPROTO_UDP && (htonl(iph->daddr) & 0xFFFFFF00) == 0xC6120000 // 198.18.0.0/24 && udph->dest == htons(1234)) { return XDP_DROP; } }
XDP程序必须使用现代的clang生成,它可以生成BPF字节码。 之后,我们可以下载并测试BFP程序的功能:
$ ip link show dev ext0 4: ext0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdp qdisc fq state UP mode DEFAULT group default qlen 1000 link/ether 24:8a:07:8a:59:8e brd ff:ff:ff:ff:ff:ff prog/xdp id 5 tag aedc195cc0471f51 jited
然后在
ethtool查看统计信息:
$ mmwatch 'ethtool -S ext0|egrep "rx"|egrep -v ": 0"|egrep -v "cache|csum"' rx_out_of_buffer: 4.4m/s rx_xdp_drop: 10.1m/s rx2_xdp_drop: 10.1m/s
! 使用XDP,我们每秒可以丢弃多达1000万个数据包!
 照片: CC BY-SA 2.0 , Andrew Filer
照片: CC BY-SA 2.0 , Andrew Filer结论
我们重复了针对IPv4和IPv6的实验,并准备了以下图表:
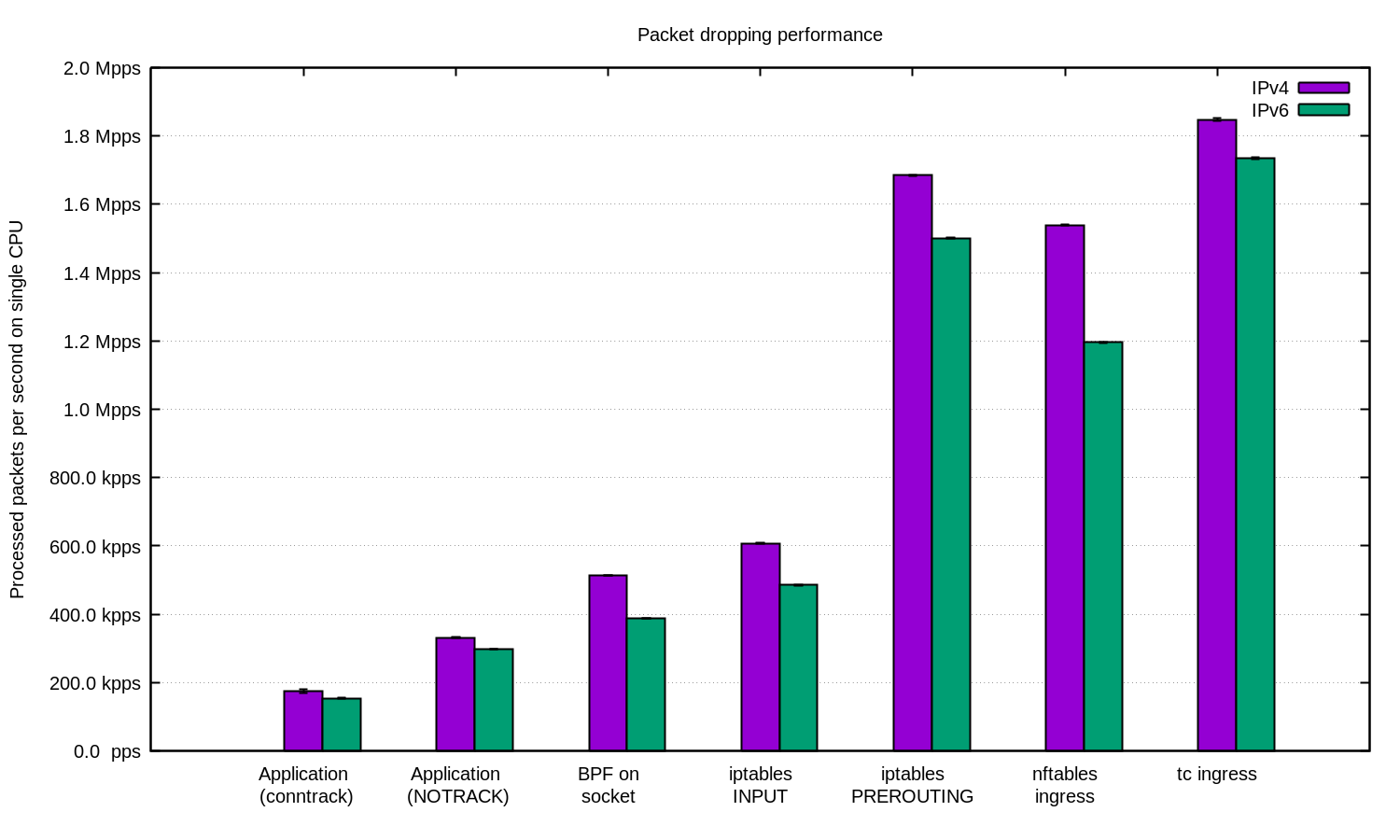
通常,可以说我们为IPv6设置的速度稍慢。 但是,由于IPv6数据包有些大,因此可以预期速度上的差异。
Linux有很多方法可以过滤软件包,每种方法都有自己的速度和复杂性。
为了防止DDoS,将数据包提供给应用程序并在其中进行处理是非常合理的。 调整良好的应用程序可以显示出良好的效果。
对于具有随机IP或欺骗性IP的DDoS攻击,禁用conntrack可能会有所帮助,以使速度有所提高,但请注意:在某些攻击中conntrack非常有用。
在其他情况下,添加Linux防火墙作为缓解DDoS攻击的方法之一是有意义的。 在某些情况下,最好使用“ -t raw PREROUTING”表,因为它比过滤器表快得多。
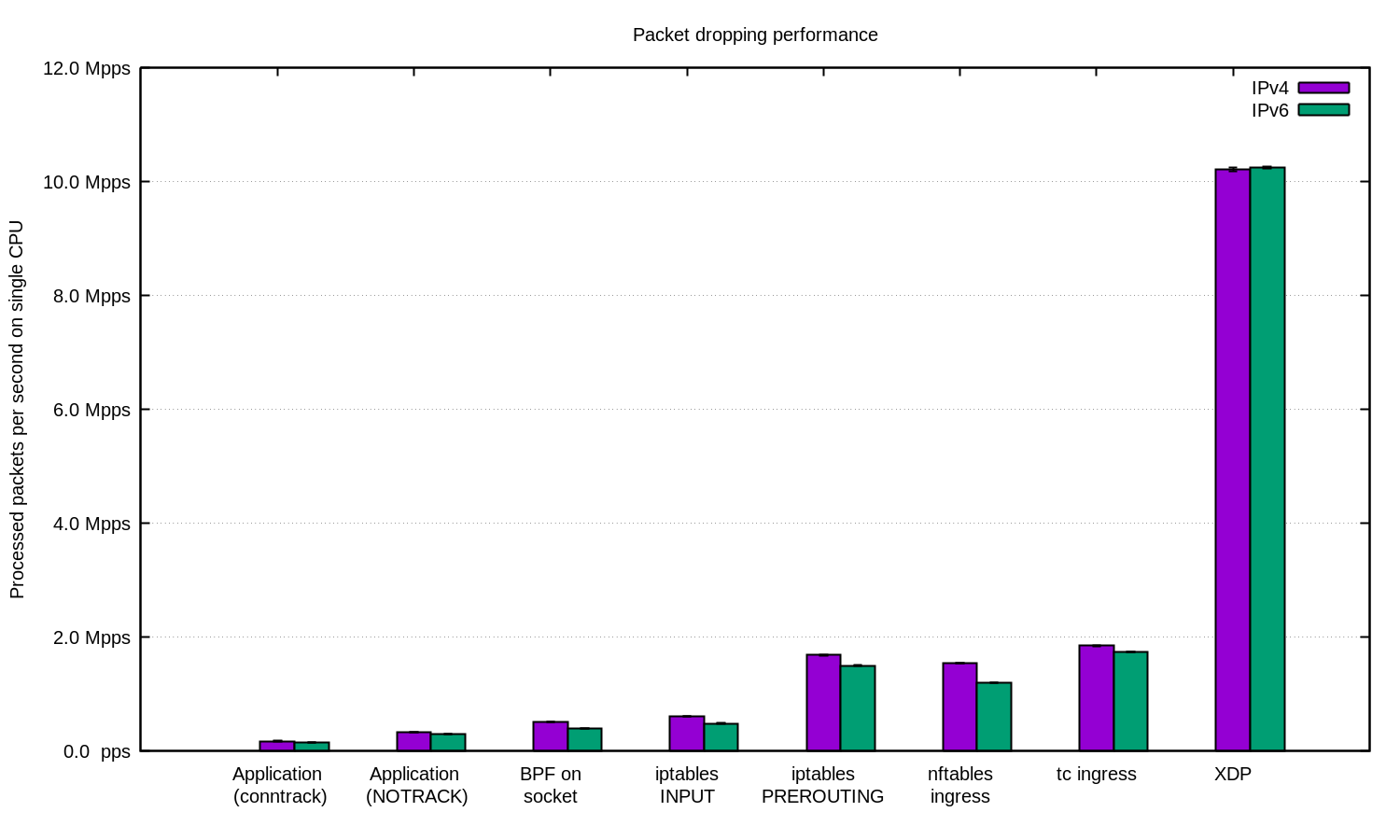
对于最高级的情况,我们始终使用XDP。 是的,这是非常强大的事情。 这是上面的图形,仅适用于XDP:
如果您想重复实验,请参阅
自述文件,其中记录了所有内容 。
我们在CloudFlare使用...几乎所有这些技术。 用户空间中的一些技巧已集成到我们的应用程序中。 iptables技术可以在
Gatebot中找到。 最后,我们将自己的核心解决方案替换为XDP。
非常感谢
Jesper Dangaard Brouer的帮助。