为了继续
讨论过度多样化的危险,我们将创建有用的股票选择工具。 之后,我们将进行简单的重新平衡,并添加技术指标的独特条件,而这些指标通常是受欢迎的服务所缺乏的。 然后比较单个资产和不同投资组合的收益。
在所有这些中,我们使用Pandas并最大程度地减少了循环次数。 对时间序列进行分组并绘制图表。 让我们熟悉多索引及其行为。 而这一切在Python 3.6的Jupyter中。
如果您想做点好事,请自己动手做。
费迪南德·保时捷
所描述的工具将使您能够为投资组合选择最佳资产,并排除顾问施加的工具。 但是,我们只会看到大局-没有考虑流动性,招聘职位的时间,经纪人佣金和一股的成本。 通常,通过每月或每年对大型经纪人进行再平衡,这将是微不足道的成本。 但是,在应用之前,仍应在事件驱动的回测器(例如,Quantopian(QP))中检查所选策略,以消除潜在的错误。
为什么不立即加入QP? 时间 在那里,最简单的测试大约持续5分钟。 当前的解决方案将使您能够在一分钟内检查数百种具有独特条件的不同策略。
原始数据加载
要加载数据,请采用
本文中介绍的方法。 我使用PostgreSQL来存储每日价格,但是现在它充满了免费的资源,您可以从中创建必要的DataFrame。
存储库中提供了用于从数据库下载价格历史记录的代码。 该链接将在文章的结尾。
数据框结构
使用价格历史记录时,为了方便分组和访问所有数据,最好的解决方案是使用带有日期和股票行情的多索引(MultiIndex)。
df = df.set_index(['dt', 'symbol'], drop=False).sort_index() df.tail(len(df.index.levels[1]) * 2)
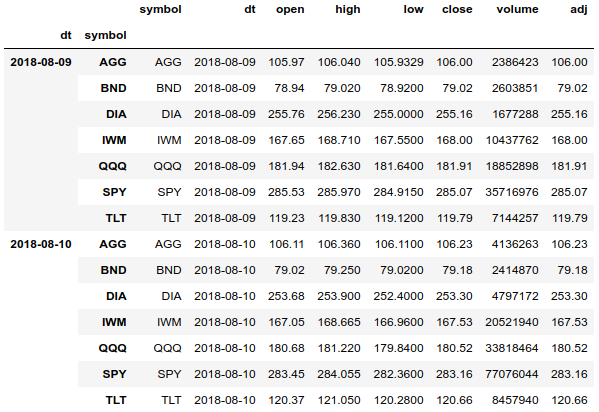
使用多索引,我们可以轻松访问所有资产的整个价格历史记录,并可以按日期和资产分别对数组进行分组。 我们还可以获取一项资产的价格历史记录。
这是一个示例,您可以轻松地按周,月和年对历史进行分组。 并在熊猫部队的图表上显示所有这些信息:
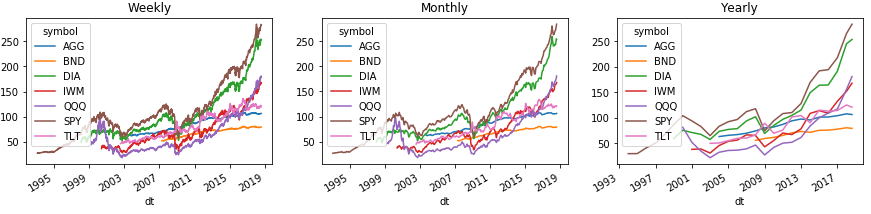
为了正确显示带有图表图例的区域,我们使用Series()。Unstack(1)命令将带有报价的索引级别转移到列上方的第二级别。 使用DataFrame(),这样的数字将不起作用,但是下面的解决方案。
按标准时间分组时,Pandas使用索引中该组的最新日历日期,该日期通常与实际日期不同。 为了解决此问题,请更新索引。
monthly = df.groupby([pd.Grouper(freq='M', level=0), level_values(1)]).agg(agg_rules) \ .set_index(['dt', 'symbol'], drop=False)
获取特定资产价格历史记录的示例(我们采用所有日期,QQQ代码和所有列):
monthly.loc[(slice(None), ['QQQ']), :]
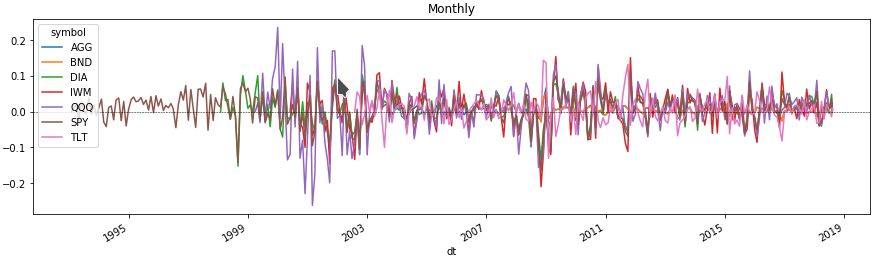
每月资产波动
现在,我们可以看一下图表上的几条线,即我们感兴趣期间每种资产的价格变化。 为此,我们通过将数据框与资产报价器按多索引级别分组来获得价格变化的百分比。
monthly = df.groupby([pd.Grouper(freq='M', level=0), level_values(1)]).agg( agg_rules).set_index(['dt', 'symbol'], drop=False)
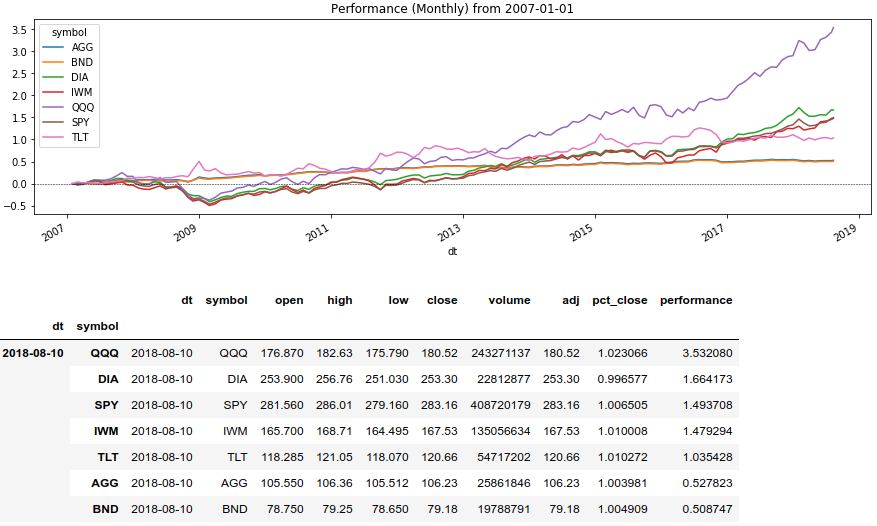
比较资产收益
现在,我们将使用Series()。Rolling()窗口方法并显示一定时期内的资产收益率:
Python代码 rolling_prod = lambda x: x.rolling(len(x), min_periods=1).apply(np.prod)
投资组合再平衡方法
所以我们去了最美味的。 在示例中,我们将查看投资组合在几种资产之间将资本分配给预定份额的结果。 并且还添加了独特的条件,在该条件下,我们将在分配资本时放弃某些资产。 如果没有合适的资产,那么我们假设经纪人在缓存中有资本。
为了使用Pandas方法进行重新平衡,我们需要将分配份额和重新平衡条件存储在具有分组数据的DataFrame中。 现在考虑我们将传递给DataFrame()。Apply()方法的重新平衡函数:
为了:
- rebalance_simple是最简单的函数,它将以股份形式分配每项资产的获利能力。
- rebalance_sma是一项功能,用于在移动平均比重新平衡时的200天高50天的资产之间分配资金。
- rebalance_rsi-用于在100天的RSI指标的值大于50的资产之间分配资本的函数。
- rebalance_custom是最慢和最通用的函数,我们将从平衡时的每日资产价格历史记录中计算指标值。 在这里您可以使用任何条件和数据。 甚至每次都从外部源下载。 但是你不能没有一个循环。
- 缩图-辅助功能,显示投资组合中的最大缩图。
在重新平衡功能中,我们需要按资产细分日期的所有数据组成的数组。 我们将用来计算投资组合结果的DataFrame()。Apply()方法会将一个数组传递给我们的函数,其中列将成为行索引。 如果我们建立一个多指标,其中报价为零,那么我们就会得到一个多指标。 我们可以将此多索引扩展为二维数组,并在每一行上获取相应资产的数据。

投资组合再平衡
现在就足以准备必要的条件并为周期中的每个投资组合进行计算。 首先,我们计算每日价格历史记录中的指标:
现在,我们将使用上述方法在所需的重新平衡期间对故事进行分组。 同时,我们将在期初采用指标值,以排除对未来的展望。
我们描述了投资组合的结构,并指出了所需的再平衡。 由于我们需要指定唯一的份额和条件,因此我们将按周期计算投资组合:
这次,我们需要对列和行索引进行一些技巧,以在重新平衡函数中获得所需的多索引。 我们将通过依次调用DataFrame()。Stack()。Unstack([1,2])方法来实现此目的。 此代码会将列转移到小写的多索引,然后以所需的顺序返回带有行情收录器和列的多索引。
现成的公文包
现在仍然可以绘制所有内容。 为此,请再次运行投资组合循环,这将在图表上显示数据。 最后,我们将以SPY作为比较基准。
Python代码 fig = plt.figure(figsize=(15, 4), facecolor='white') ax_perf = fig.add_subplot(121) ax_dd = fig.add_subplot(122) for p in portfolios: p['performance'].rename(p['name']).plot(ax=ax_perf, legend=True, title='Performance') p['drawdown'].rename(p['name']).plot(ax=ax_dd, legend=True, title='Max drawdown')
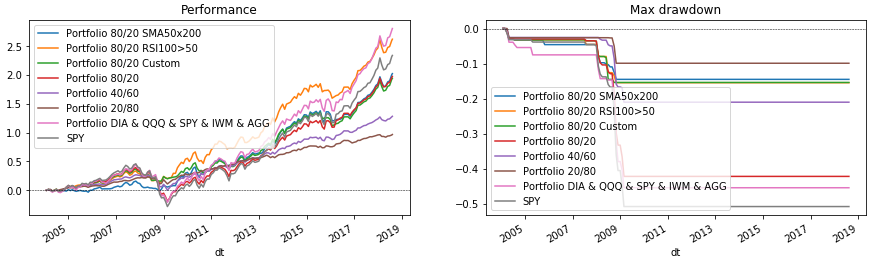
结论
所考虑的代码使您可以选择各种投资组合结构和再平衡条件。 借助它的帮助,您可以快速检查例如是否值得在投资组合中持有黄金(GLD)或新兴市场(EEM)。 自己尝试,添加指标的条件或选择已经描述的参数。 (但请记住,幸存者的错误以及对过去数据的拟合可能无法达到预期的将来。)然后决定对谁信任自己的投资组合-Python还是财务顾问?
仓库:
rebalance.portfolio