
如果您遵循Google I / O(或至少看过Keynotes),那么您可能已经注意到作为Firebase平台一部分称为ML Kit的新产品的发布。
ML Kit提供了一个API,无论您是经验丰富的机器学习开发人员还是该领域的初学者,都可以使用该API向应用程序(Android和iOS)添加强大的机器学习功能。
尽管该产品尚未成为会议关注的焦点(感谢Google Duplex),但肯定有很多有用的方法可以在Android开发中使用它。
因此,让我们与他一起玩并创建一个看起来像Google Lens的小应用程序(差不多)!
这是该应用程序的一些屏幕截图。 在它们上,您可以看到尝试识别图像中的对象的尝试。

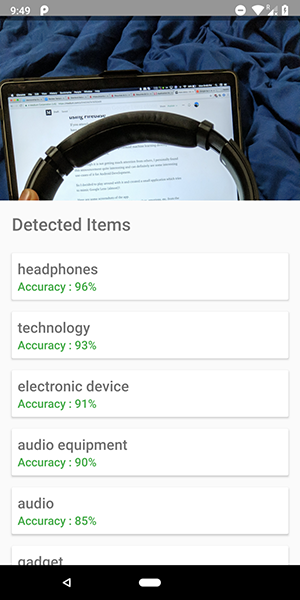
相当准确吧?
您还可以使用此API定义人类情感,例如幸福,悲伤,愤怒等,这甚至更酷。
别再说了,给我看看代码!
ML套件中有5个API:
- 文本识别(我们已经发布了有关使用此功能的应用程序的文章 )
- 人脸检测(此类文章在我们的博客上)
- 条码扫描
- 识别图像中的对象(我们将要使用的对象)
- 字符识别
在本文中,我们将在图像上使用对象标识API。 使用此API,我们可以获得图像中可识别的对象的列表:人物,事物,地点,活动等。
此外,此API有2种类型。 第一个是设备内置的API,该API在设备本身上可以正常工作。 它是免费的,可以识别图像中的400多个不同对象。
第二个是cloud API ,它运行在Google Cloud上,可以识别10,000多个不同的对象。 它是付费的,但是每月前1000个请求是免费的。
在本文中,我们将研究第一种API, 它是免费的(但是付费的原理类似于免费)。
让我们开始吧。
- 将Firebase连接到您的项目并添加
firebase-ml-vision 依赖项
如何连接Firebase,可以在Google的优秀教程中看到。 您还必须添加适当的依赖关系才能使用此API:
implementation 'com.google.firebase:firebase-ml-vision:15.0.0' implementation 'com.google.firebase:firebase-ml-vision-image-label-model:15.0.0'
fab_take_photo.setOnClickListener { // cameraView is a custom View which provides camera preview cameraView.captureImage { cameraKitImage -> // Get the Bitmap from the captured shot and use it to make the API call getLabelsFromDevice(cameraKitImage.bitmap) } } private fun getLabelsFromDevice(bitmap: Bitmap) { val image : FirebaseVisionImage = FirebaseVisionImage.fromBitmap(bitmap) val detector : FirebaseVisionLabelDetector = FirebaseVision.getInstance().visionLabelDetector detector.detectInImage(image) .addOnSuccessListener { // Task completed successfully for(firebaseVision : FirebaseVisionLabel in it){ // Logging through the list of labels returned from the API and Log them Log.d(TAG,"Item Name ${firebaseVision.confidence}") Log.d(TAG,"Confidence ${firebaseVision.confidence}") } } .addOnFailureListener { // Task failed with an exception Toast.makeText(baseContext,"Sorry, something went wrong!",Toast.LENGTH_SHORT).show() } }
在上面的代码片段中,我们首先从位图创建一个FirebaseVisionImage 。
然后,我们创建一个FirebaseVisionLabelDetector实例,该实例穿过FirebaseVisionImage并找到它在提供的图像中可以识别的特定FirebaseVisionLabels (对象)。
最后,我们将图像传递给detectInImage()方法,并让检测器分析图像。
我们可以将侦听器设置为处理成功的分析和不成功的处理。 在那里,我们将分别访问图像中标识的对象列表和已出现的异常。
对于每个识别的对象,您可以获取其名称,识别准确度和实体ID 。
如前所述,此API还可以用于定义图像中的人类情感,可以在下面的屏幕截图中看到:

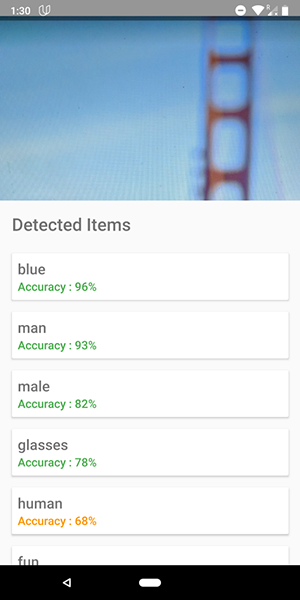
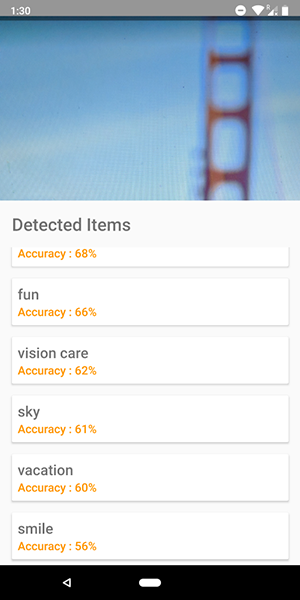
云API的代码与我们为设备API编写的代码非常相似。 只有检测器的类型 ( FirebaseVisionCloudLabelDetector与FirebaseVisionLabelDetector )和已识别对象的类型 ( FirebaseVisionCloudLabel与FirebaseVisionLabels ) FirebaseVisionLabels :
private fun getLabelsFromDevice(bitmap: Bitmap) { ... val detector : FirebaseVisionCloudLabelDetector = FirebaseVision.getInstance().visionCloudLabelDetector detector.detectInImage(image) .addOnSuccessListener { for(firebaseVision : FirebaseVisionCloudLabel in it){ ... } } .addOnFailureListener { ... } }
除了更改代码外,您还需要为您的项目配置结算(付款)并在Google Cloud Console中启用Google Vision API 。
请注意,该API每月仅允许您执行1000个免费查询 ,因此如果您只想使用它,则无需付费。
屏幕快照中显示的应用程序可以在GitHub存储库中找到。