大家好!
我们在
Java Developer课程中进行的步骤实验仍在继续,很奇怪的是,甚至相当成功(某种程度上):事实证明,在任何方便的时间计划几个月的杠杆作用并在下一个过渡到新步骤的过程要比将近六个月的时间分配给如此困难的课程。 因此,有人怀疑正是我们很快将开始慢慢将其转移到这样一个系统的复杂课程。
抱歉,这是关于我们的,关于otusovsky的我。 与往常一样,我们将继续研究有趣的主题,尽管它们在我们的计划中没有得到解决,但已经与我们讨论过,因此我们针对老师提出的问题之一准备了我们认为最有趣的文章的译文。
走吧

JDK中的集合是列表和映射的标准库实现。 如果查看典型的大型Java应用程序的快照,则会看到数千甚至数百万个
java.util.ArrayList ,
java.util.HashMap等实例。集合对于存储和处理数据是必不可少的。 但是您是否曾经考虑过应用程序中的所有集合是否都可以最佳利用内存? 换句话说,如果您的应用程序因可耻的
OutOfMemoryError崩溃而崩溃,或者在垃圾回收器中导致长时间的停顿,则是否曾经检查过使用过的回收器是否泄漏。
首先,应该指出的是,JDK的内部集合并不是某种魔术。 它们是用Java编写的。 他们的源代码随JDK一起提供,因此您可以在IDE中打开它。 他们的代码也可以在Internet上轻松找到。 而且,事实证明,就优化消耗的内存量而言,大多数集合都不是很优雅。
例如,考虑最简单和最受欢迎的集合之一
java.util.ArrayList类。 在内部,每个
ArrayList使用
Object[] elementData的数组进行操作。 这是列表项的存储位置。 让我们看看如何处理该数组。
当使用默认构造函数创建
ArrayList时,即调用
new ArrayList() ,
elementData指向大小为零的通用数组(
elementData也可以设置为
null ,但是该数组提供了一些实现上的小好处)。 当您将第一个元素添加到列表时,将
elementData一个真正唯一的
elementData数组,并将所提供的对象插入其中。 为了避免每次更改数组的大小,在添加新元素时,将创建其长度等于10(“默认容量”)的元素。 事实证明:如果您不再向此
ArrayList添加元素,那么
elementData数组中10个插槽中的9个将保持为空。 即使清除列表,也不会减小内部阵列的大小。 以下是此生命周期的图表:
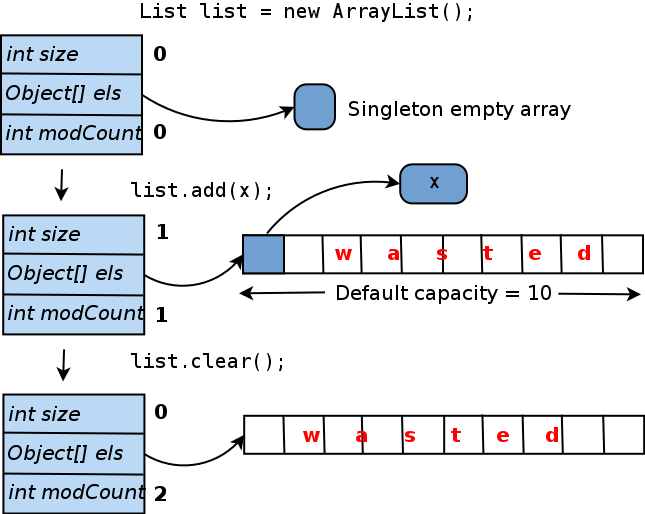
这里浪费了多少内存? 绝对而言,它的计算方式为(对象指针的大小)。 如果您使用JVM HotSpot(Oracle JDK随附),则指针的大小将取决于最大堆大小(有关更多详细信息,请参见
https://blog.codecentric.de/zh/2014/02/35gb-heap-less- 32gb-java-jvm-memory-oddities / )。 通常,如果指定的
-Xmx小于32 GB,则指针的大小为4个字节; 对于大堆-8个字节。 因此,由默认构造函数初始化的
ArrayList (仅添加一个元素)浪费了36或72个字节。
实际上,空的
ArrayList也不浪费内存,因为它不承担任何工作量,但是
ArrayList本身的大小不为零,并且比您想象的要大。 这是因为,一方面,由HotSpot JVM管理的每个对象都有一个12字节或16字节的标头,JVM将该标头用于内部目的。 此外,集合中的大多数对象都包含一个
size字段,一个指向内部数组或其他“工作负载媒体”对象的指针,一个用于跟踪内容变化的
modCount字段等。因此,即使是表示一个空集合的最小对象也可能至少需要32个字节的内存。 有些,例如
ConcurrentHashMap ,会占用更多空间。
考虑另一个常见的集合
java.util.HashMap类。 它的生命周期类似于
ArrayList生命周期:

如您所见,一个仅包含一个键值对的
HashMap花费了数组的15个内部单元,对应于60或120个字节。 这些数字很小,但是内存丢失的程度对于应用程序中的所有集合都很重要。 事实证明,某些应用程序可以通过这种方式花费大量内存。 例如,作者分析过的一些流行的开源Hadoop组件在某些情况下会损失大约20%的堆! 对于由缺乏经验的工程师开发的产品,如果他们没有进行定期的性能检查,则内存损失甚至可能更高。 在很多情况下,例如,一棵大树中90%的节点仅包含一个或两个后代(或根本不包含任何后代),而在其他情况下,堆被0、1、2元素集合阻塞。
如果在应用程序中发现未使用或未充分使用的集合,如何解决它们? 以下是一些常见的食谱。 在这里,假设我们有问题的集合是一个由数据字段
Foo.list引用的
ArrayList 。
如果列表的大多数实例从未使用过,请尝试将其延迟初始化。 所以以前看起来像的代码
void addToList(Object x) { list.add(x); }
...应重做为类似
void addToList(Object x) { getOrCreateList().add(x); } private list getOrCreateList() {
请记住,有时您将需要采取其他措施来应对潜在的竞争。 例如,如果您支持
ConcurrentHashMap ,它可以由多个线程同时更新,则初始化它的代码不应允许两个线程随机创建此映射的两个副本:
private Map getOrCreateMap() { if (map == null) {
例如,如果列表或地图的大多数实例仅包含少量项目,请尝试使用更合适的初始容量进行初始化。
list = new ArrayList(4);
如果您的集合为空或在大多数情况下仅包含一个元素(或键-值对),则可以考虑一种优化的极端形式。 仅当在当前类中对集合进行完全管理(即其他代码无法直接访问它)时,它才有效。 这个想法是,您可以将数据字段的类型(例如,从列表更改为更通用的对象),以便现在它可以指向真实列表或直接指向单个列表项。 这是一个简短的草图:
显然,经过这种优化的代码不太清晰,也很难维护。 但是,如果您确定这将节省大量内存或摆脱垃圾收集器的长时间停顿,则这将很有用。
您可能已经想知道:如何找出应用程序中的哪些集合用尽了内存以及多少?
简而言之:没有合适的工具很难找到。 试图猜测大型复杂应用程序中数据结构使用或消耗的内存量几乎永远不会导致任何问题。 而且,由于不知道确切的内存位置,您可能会花费大量时间追求错误的目标,而您的应用程序
OutOfMemoryError顽固地继续
OutOfMemoryError 。
因此,您应该使用特殊工具检查大量应用程序。 根据经验,分析JVM内存(以与该工具对应用程序性能的影响相比,可用信息量衡量)的最佳方法是获取堆转储,然后脱机查看它。 堆转储本质上是堆的完整快照。 您可以通过调用jmap实用程序随时获取它,也可以将JVM配置为在应用程序因
OutOfMemoryError崩溃而自动转储。 如果您搜索“ JVM堆转储”,您将立即看到大量文章,详细解释了如何进行转储。
堆转储是JVM堆大小的二进制文件,因此只能使用特殊工具读取和分析。 有几种工具,包括开源和商业工具。 最受欢迎的开源工具是Eclipse MAT。 还有VisualVM和一些功能较弱,知名度较低的工具。 商业工具包括通用Java探查器:JProfiler和YourKit,以及专门为堆转储分析设计的一种工具-JXRay(免责声明:最后由作者开发)。
与其他工具不同,JXRay立即分析堆转储中是否存在大量常见问题,例如重复行和其他对象以及效率不高的数据结构。 上述集合的问题属于后一类。 该工具将生成一个报告,其中包含所有收集的HTML格式的信息。 这种方法的优点是您可以随时随地查看分析结果,并轻松与他人共享。 您还可以在任何计算机上运行该工具,包括数据中心中大型而功能强大但“无头”的计算机。
JXRay以字节为单位,并以所用堆的百分比计算开销(如果消除特定问题,将节省多少内存)。 它合并了具有相同问题的同一类的集合...

...然后将可通过相同链接链从垃圾收集器的某些根访问的有问题的集合分组,如下例所示

知道哪些链接链和/或单个数据字段(例如,上面的
INodeDirectory.children )指示花费了大部分内存的集合,使您可以快速而准确地标识造成问题的代码,然后进行必要的更改。
因此,配置不充分的Java集合会浪费大量内存。 在许多情况下,此问题很容易解决,但有时您可能需要以不平凡的方式修改代码以取得重大改进。 很难猜测哪些集合需要优化才能产生最大的影响。 为了不浪费时间优化代码的错误部分,您需要获取JVM堆转储并使用适当的工具对其进行分析。
结束
一如既往,我们对您的意见和问题很感兴趣,您可以离开这里或
在公开课上提问并向我们的
老师提问。