如今,在企业中引入机器学习的主要障碍之一是高层管理人员所使用的ML指标和指标不兼容。 分析师预测利润增加? 但是您需要了解在哪些情况下机器学习将成为增长的原因,以及在哪些其他因素下。 遗憾的是,机器学习指标的改善通常不会导致利润增长。 另外,有时数据的复杂性使得即使是经验丰富的开发人员也可以选择无法定向的错误指标。
让我们看看什么是ML指标以及何时适合使用。 我们将分析常见的错误,并讨论设置问题的哪些选项可能适合机器学习和业务。
ML指标:为什么会有那么多?
机器学习指标是非常具体的,并且经常会引起误解,
在糟糕的游戏中表现出
良好的面孔,在糟糕的模型中表现良好。 要测试模型并进行改进,您需要选择一个足以反映模型质量以及度量方式的指标。 通常,使用单独的测试数据集来评估模型的质量。 如您所知,选择正确的指标是一项艰巨的任务。
借助机器学习最常解决哪些任务? 首先,这是回归,分类和聚类。 前两个是与老师的所谓训练:有一组标记数据,根据一些经验,您需要预测设置值。 回归是对某些价值的预测:例如,客户将购买多少,材料的耐磨性是多少,在第一次发生故障之前汽车将行驶多少公里。
聚类是通过突出显示聚类(例如,客户类别)来定义数据结构的方法,我们没有关于这些聚类的假设。 我们不会考虑这种类型的问题。
机器学习算法(通过计算损失函数)优化数学指标-模型预测与真实值之间的差异。 但是,如果度量标准是偏差的总和,则在两个方向上偏差的数量相同,则该总和将为零,并且我们根本不知道是否存在错误。 因此,它们通常使用平均绝对值(偏差的绝对值之和)或均方误差(偏差与真实值的平方之和)。 有时公式很复杂:取对数或提取这些和的平方根。 借助这些指标,您可以评估模型计算质量的动态,但是为此,您需要将结果与某些事物进行比较。
如果已经存在一个可以与结果进行比较的模型,这将不会很困难。 但是,如果您是第一次创建模型怎么办? 在这种情况下,通常使用确定系数R2。 确定系数表示为:
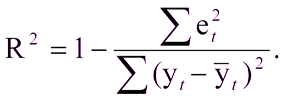
其中:
R ^ 2-确定系数,
e
t ^ 2是均方误差,
y
t是正确的值
带盖的y
t是平均值。
单位减去模型的均方误差与测试样品平均值的均方误差之比。也就是说,确定系数使我们能够评估模型对预测的改进。
有时,一个方向的错误并不等同于另一个方向的错误。 例如,如果模型预测了仓库中的货物订单,那么很可能会犯错并多订购一些,货物将在仓库中等待他们的时间。 而且,如果模型以其他方式犯了错误并减少了订单,那么您可能会失去客户。 在这种情况下,将使用分位数误差:使用不同的权重考虑与真实值的正偏差和负偏差。
在分类问题中,机器学习模型将对象分为两类:用户离开站点或不离开站点,零件是否有缺陷等等。 预测准确性通常被估计为正确定义的类数与预测总数之比。 但是,该特性很少被视为适当的参数。
 图 1.客户退货预测问题的误差矩阵示例
图 1.客户退货预测问题的误差矩阵示例 :如果每100名被保险人中有7人申请赔偿,那么预测没有被保险事件的模型将具有93%的准确度,而没有任何预测力。
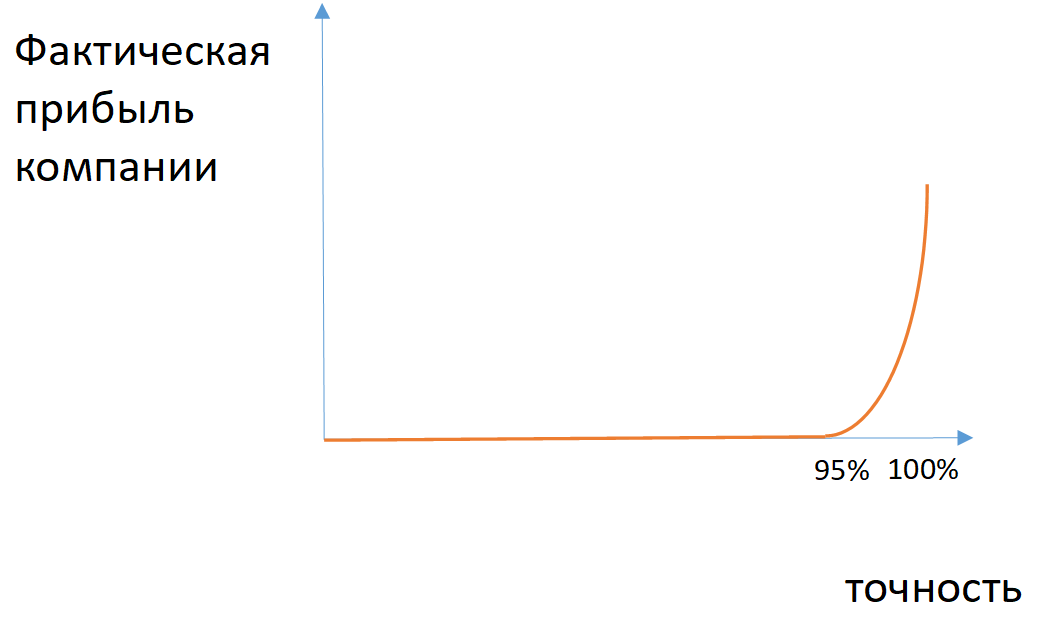 图 2.在类别不平衡的情况下,公司实际利润对模型准确性的依赖关系的示例
图 2.在类别不平衡的情况下,公司实际利润对模型准确性的依赖关系的示例对于某些任务,您可以应用完整性(在该类的所有对象中该类的正确定义的对象的数量)和准确性(在该模型分配给该类的所有对象中的该类的正确定义的对象的数量)的度量。 如果有必要同时考虑完整性和准确性,则在这些值之间应用谐波均值(F1度量)。
使用这些指标,您可以评估执行的分类。 但是,许多模型预测模型与特定类的关系的可能性。 从这个角度来看,可以更改将元素分配给一个或另一类的概率阈值(例如,如果客户离开的概率为60%,则可以认为是剩余的)。 如果未设置特定阈值,则可以使用所选曲线下的面积作为度量标准,构建度量对不同阈值(
ROC曲线或PR曲线 )的依赖关系图以评估模型的有效性。
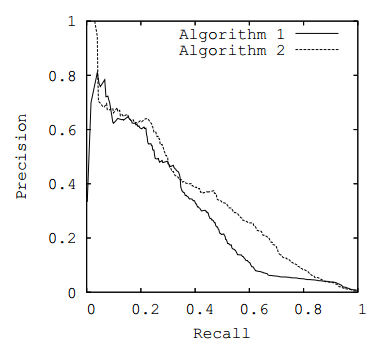 图 3. PR曲线
图 3. PR曲线业务指标
寓言地讲,业务指标是一头大象:它们不能被忽视,在一个这样的“象素”中,可以容纳大量机器学习的“鹦鹉”。 哪个机器学习指标将增加利润的问题的答案取决于改进。 实际上,业务指标在某种程度上与利润的增长有关,但是我们几乎从来没有设法直接将利润与利润相关联。 通常使用中间指标,例如:
- 库存货物的存续时间以及无法获得的货物请求数量;
- 客户将要离开的金额;
- 在制造过程中节省的材料量。
在使用机器学习优化业务时,总是隐含创建两个模型:预测模型和优化模型。
第一个比较复杂,第二个使用其结果。 预测模型中的错误迫使我们在优化模型中放置较大的余量,因此减少了优化量。
示例 :预测客户行为的准确性或工业缺陷的可能性越低,保留的客户越少,节省的材料量越少。
设置ML任务时,很少获得公认的业务成功指标(EBITDA等)。 通常,您必须深入研究细节并应用我们引入机器学习的领域(平均检查,出勤等)中接受的指标。
翻译困难
具有讽刺意味的是,使用业务代表难以理解的指标来优化模型是最方便的。 评论语调模型中ROC曲线下的面积与特定收入规模有何关系? 从这个角度来看,企业面临两项任务:如何衡量以及如何最大程度地引入机器学习?
如果您具有回顾性数据,并且同时可以均衡或衡量其他因素,则第一个任务更容易解决。 然后,没有什么可以阻止您将获得的值与类似的回顾性数据进行比较。 但是有一个复杂之处:样本必须具有代表性,并且必须与我们用来测试模型的样本相似。
示例 :您需要找到最相似的客户,以查看他们的平均支票是否增加了。 但同时,客户样本应足够大,以避免由于异常行为而激增。 通过首先创建足够多的相似客户选择并将其用于检查其努力的结果,可以解决此问题。
但是,您可能会问:如何将所选度量转换为损失函数(模型将其最小化)以进行机器学习。 这个任务不能立即解决:模型的开发人员将不得不深入研究业务流程。 但是,如果在训练模型时使用取决于业务的度量标准,则模型的质量会立即提高。 假设,如果模型预测了哪些客户将离开,那么在业务指标的作用下,您可以使用一个图表,其中根据模型将离开的客户数量绘制在一个轴上,并将这些客户的资金总额绘制在另一个轴上。 在这样的时间表的帮助下,业务客户可以选择一个对自己方便的点并使用它。 如果使用线性变换将图缩小为PR曲线(一个轴上的精度,第二个完整性),那么我们可以与业务指标同时优化该曲线下的面积。
 图 4.货币效应曲线
图 4.货币效应曲线结论
在设置用于机器学习的任务和创建模型之前,您需要选择一个合理的指标。 如果要优化模型,则可以将标准度量之一用作误差函数。 确保与客户协调选定的指标,其权重和其他参数,将业务指标转换为ML模型。 就持续时间而言,这可以与模型本身的开发进行比较,但是如果没有持续时间,则开始工作是没有意义的。 如果让数学家参与业务流程的研究,则可以大大减少指标出错的可能性。 如果不了解主题领域以及在业务和统计层面对问题进行联合陈述,就不可能有效地优化模型。 在所有计算之后,您将能够根据模型的每次改进来评估利润(或储蓄)。
Jet Infosystems机器学习小组负责人Nikolay Knyazev( iRumata )