
最近,网络钓鱼已成为网络犯罪分子窃取金钱或信息的最简单,最流行的方式。 例如,您无需走太远。 去年,领先的俄罗斯企业面临前所未有的大规模攻击-攻击者大量注册了虚假资源,化肥和石化产品制造商的确切副本,以代表他们签订合同。 此类攻击造成的平均损失为150万卢布,更不用说公司遭受的声誉损失。 在本文中,我们将讨论如何使用资源分析(CSS,JS图像等)而非HTML有效地检测网络钓鱼站点,以及数据科学专家如何解决这些问题。
Pavel Slipenchuk,IB组机器学习系统架构师
网络钓鱼流行
根据IB集团的统计,仅在俄罗斯,每天就有900多家银行的客户成为金融网络钓鱼的受害者-这一数字是每日恶意软件受害者人数的3倍。 对用户的一次网络钓鱼攻击造成的损害从2,000到50,000卢布不等。 欺诈者不仅会复制公司或银行的网站,其徽标和公司的颜色,内容,联系方式,注册类似的域名,而且还在社交网络和搜索引擎中积极宣传其资源。 例如,他们尝试将指向钓鱼网站的链接带到搜索结果的顶部,以请求“将钱转入卡”。 多数情况下,伪造站点的创建是为了在从卡到卡转移或为移动运营商的服务即时付款时偷钱。
网络钓鱼(英语:钓鱼,即钓鱼)是一种互联网欺诈行为,其目的是诱骗受害者向欺诈者提供机密信息。 大多数情况下,他们窃取银行帐户访问密码以窃取金钱,社交媒体帐户(代表受害者勒索金钱或发送垃圾邮件),注册付费服务,发送邮件或感染计算机,从而使其成为僵尸网络中的链接。
通过攻击方法,有两种针对用户和公司的网络钓鱼:
- 复制受害者原始资源(银行,航空公司,在线商店,企业,政府机构等)的网络钓鱼站点。
- 网络钓鱼邮件,电子邮件,短信,社交网络中的消息等。
个人经常受到用户的攻击,进入这一犯罪业务领域的门槛太低,以至于只需最少的“投资”和基本知识就可以实施。 网络钓鱼工具包,网络钓鱼网站建设者程序也可以促进这种欺诈行为的传播,这些程序可以在Darknet的黑客论坛上免费购买。
对公司或银行的攻击是不同的。 它们是由技术上更精明的攻击者执行的。 通常,大型工业企业,在线商店,航空公司以及大多数情况下的银行被选为受害者。 在大多数情况下,网络钓鱼归结为发送带有受感染文件的电子邮件。 为了使这种攻击获得成功,该小组的“工作人员”必须拥有编写恶意代码的专家,并且程序员必须使他们的活动自动化,并且可以对受害者进行初步侦查并发现受害者的弱点。
根据我们的估计,在俄罗斯,有15个犯罪集团针对金融机构从事网络钓鱼。 损害的金额始终很小(比银行木马的损害少十倍),但估计每天诱使他们到其站点的受害者人数为数千。 金融网络钓鱼网站的访问者中约有10-15%会自己输入数据。
当出现网页仿冒页面时,该账单要花费数小时甚至数分钟的费用,因为用户会遭受严重的财务损失,对于公司而言,这也将损害声誉。 例如,一些成功的网页仿冒页面可用的时间不到一天,但能够造成1,000,000卢布以上的损失。
在本文中,我们将讨论第一种网络钓鱼:网络钓鱼站点。 可以使用各种技术手段(如蜜罐,爬虫等)轻松检测“怀疑”网络钓鱼的资源,但是,要确保它们确实是网络钓鱼并确定受攻击的品牌是有问题的。 让我们弄清楚如何解决这个问题。
垂钓
如果一个品牌不监督其声誉,那么它就很容易成为目标。 在注册假站点后,有必要立即抓住犯罪分子的主动权。 实际上,对网络钓鱼页面的搜索分为四个阶段:
- 形成许多用于网络钓鱼扫描的可疑地址(URL)(爬网程序,蜜罐等)。
- 形成许多网络钓鱼地址。
- 按活动领域和受攻击技术对已经检测到的网络钓鱼地址进行分类,例如“ RBS :: Sberbank Online”或“ RBS :: Alfa-Bank”。
- 搜索捐助者页面。
第2和第3款的实施由数据科学专家承担。
之后,您已经可以采取主动步骤来阻止网络钓鱼页面。 特别是:
- 将Group-IB产品和我们合作伙伴的产品列入黑名单;
- 自动或手动将信件发送给域区域的所有者,并要求删除网络钓鱼网址;
- 向受攻击品牌的安全部门发送信件;
- 等

HTML分析方法
解决可疑网络钓鱼地址并自动检测受影响品牌的任务的经典解决方案是解析HTML源页面的多种方法。 最简单的事情是编写正则表达式。 这很有趣,但是这个技巧仍然有效。 如今,大多数新手钓鱼者都只是从原始站点复制内容。
同样,网络钓鱼套件研究人员可以开发出非常有效的反网络钓鱼系统。 但是在这种情况下,您需要检查HTML页面。 另外,这些解决方案不是通用的-它们的开发需要“鲸鱼”本身的基础。 研究人员可能不知道某些网络钓鱼工具包。 而且,当然,对每个新“鲸鱼”的分析都是相当费力且昂贵的过程。
HTML混淆后,所有基于HTML页面分析的网络钓鱼检测系统都将停止工作。 在许多情况下,仅更改HTML页面的框架就足够了。
根据IB集团的说法,目前此类钓鱼网站的数量不超过10%,但是即使丢失一个钓鱼网站也可能使受害者付出高昂的代价。
因此,对于钓鱼者来说,绕过锁,只需简单地更改HTML框架就足够了,而无需混淆频率-混淆HTML页面(混淆标记和/或通过JS加载内容)。
问题陈述。 基于资源的方法
基于所用资源分析的方法对于检测网络钓鱼页面更为有效和通用。 资源是呈现网页时上载的任何文件(所有图像,级联样式表(CSS),JS文件,字体等)。
在这种情况下,您可以构建一个二部图,其中一些顶点将成为可疑网络钓鱼的地址,而另一些顶点将是与它们相关的资源。
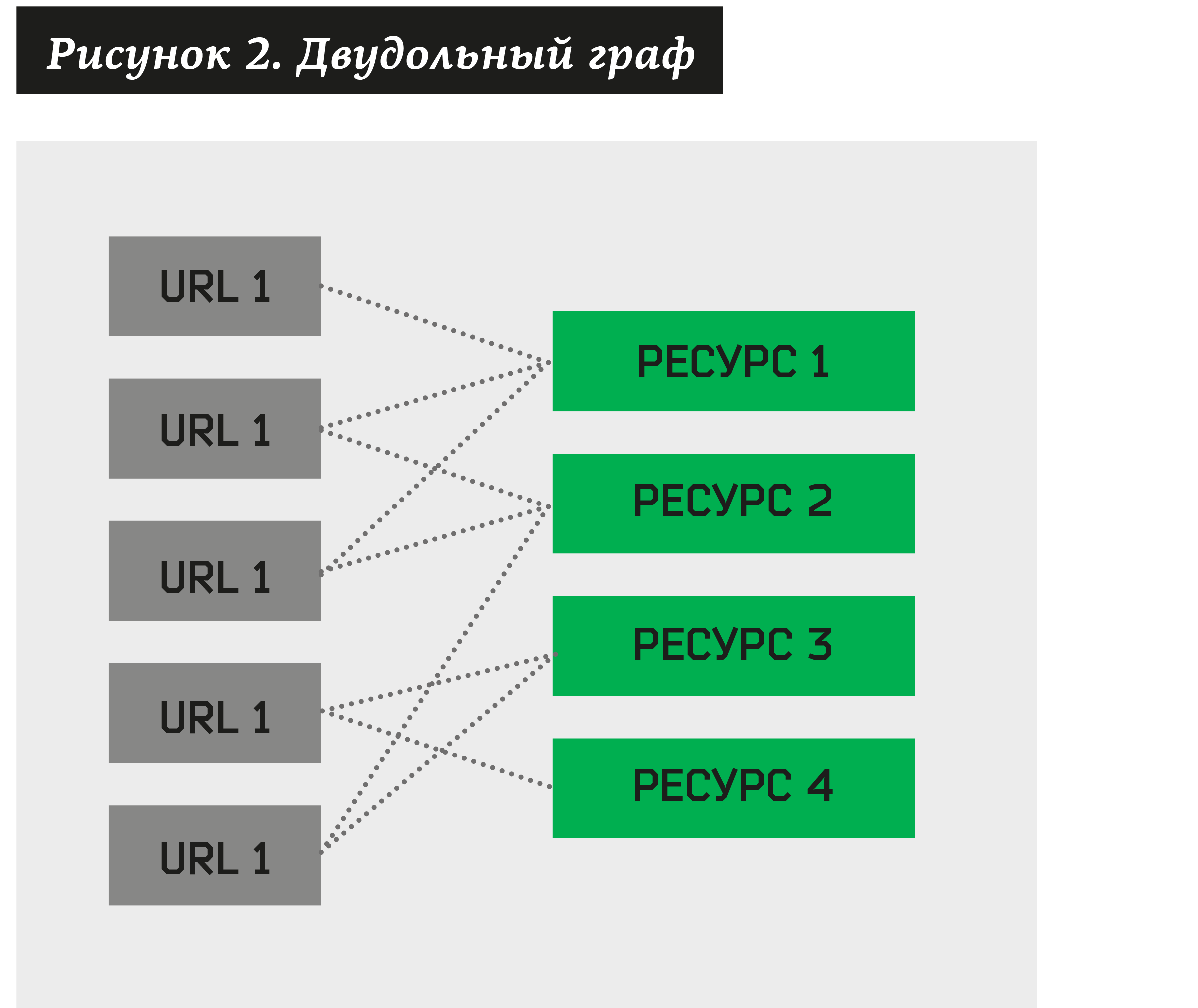
群集的任务由此产生-查找拥有相当大量不同URL的此类资源的集合。 通过构造这样的算法,我们可以将任何二分图分解为簇。
假设是,基于真实数据,可以说该群集包含一个URL的集合,这些URL属于同一品牌,并且是由一个网络钓鱼工具生成的,具有相当高的概率。 然后,为了检验该假设,可以将每个这样的群集发送到CERT(信息安全事件响应中心)进行手动验证。 反过来,分析人员将给出群集状态:+1(“已批准”)或–1(已拒绝)。 分析师还可以将受攻击的品牌分配给所有批准的集群。 此“手动工作”结束-其余过程是自动化的。 平均而言,一个获批的小组占了152个网络钓鱼地址(截至2018年6月的数据),有时甚至会遇到500-1000个地址的集群! 分析人员花费大约1分钟来批准或驳斥该群集。
然后,将所有拒绝的群集从系统中删除,过一会儿,它们的所有地址和资源都再次馈送到群集算法的输入中。 结果,我们得到了新的集群。 再一次,我们将它们发送给进行验证,等等。
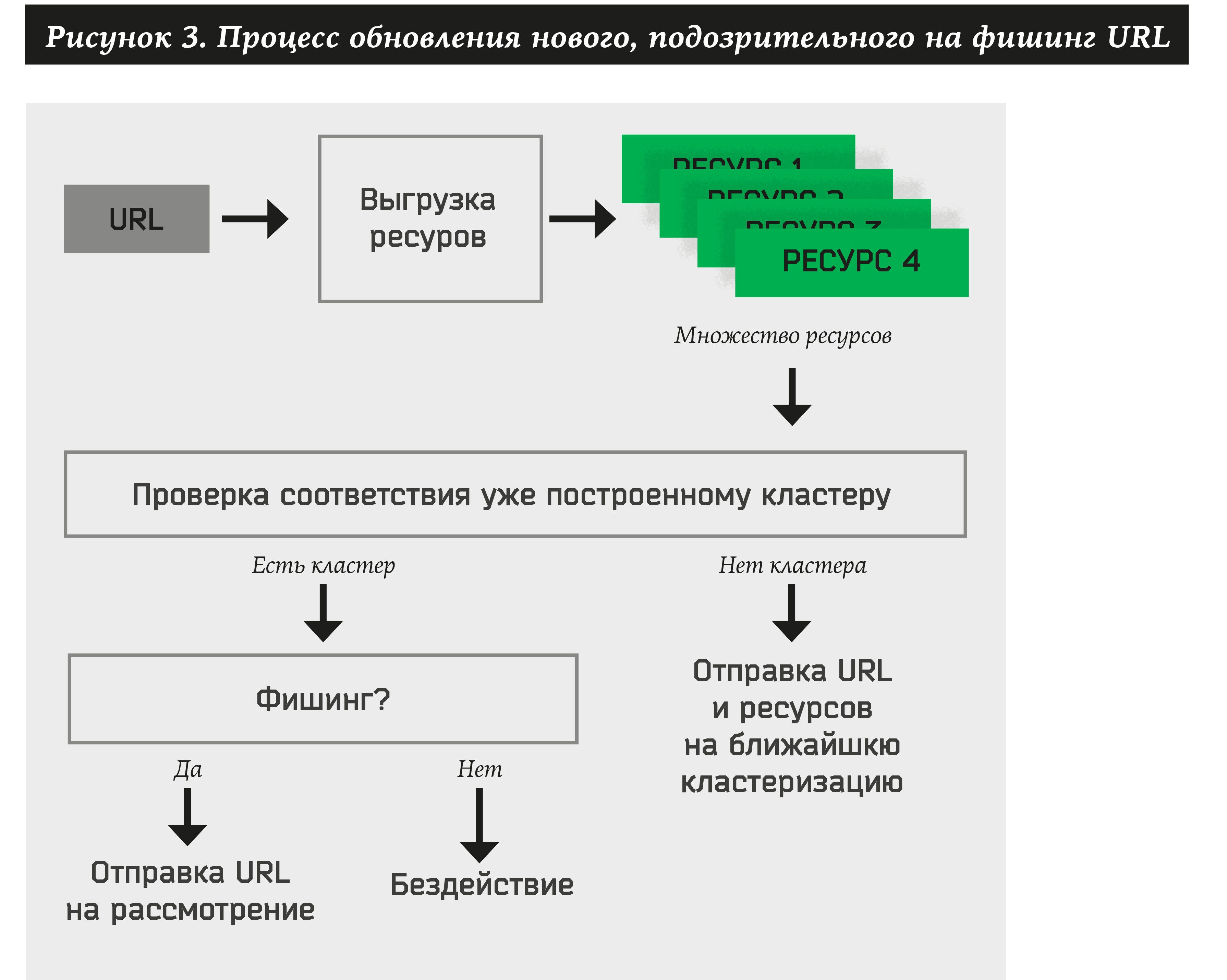
因此,对于每个新收到的地址,系统必须执行以下操作:
- 提取站点的许多资源。
- 检查至少一个先前批准的集群。
- 如果URL属于任何群集,则自动提取品牌名称并对其执行操作(通知客户,删除资源等)。
- 如果没有群集可以分配给资源,则将地址和资源添加到二部图中。 将来,此URL和资源将参与新集群的形成。
简单资源聚类算法
信息安全方面的数据科学专家应考虑的最重要的细微差别之一是,一个人就是他的对手。 因此,分析条件和数据变化非常快! 2-3个月后,现在可以解决此问题的解决方案原则上可能会停止工作。 因此,重要的是创建通用的(笨拙的)机制(如果可能)或可以快速开发的最灵活的系统。 信息安全方面的数据科学专家不能一劳永逸地解决问题。
由于功能众多,标准的聚类方法不起作用。 每个资源都可以表示为布尔属性。 但是,实际上,我们每天从5,000个网站地址获取数据,每个网站平均包含17.2个资源(2018年6月的数据)。 维度的诅咒甚至不允许将数据加载到内存中,更不用说构建任何聚类算法了。
另一个想法是尝试使用各种协作过滤算法将其集群化。 在这种情况下,有必要创建另一个功能-属于特定品牌。 该任务将简化为系统应针对其余URL预测此符号的存在或不存在的事实。 该方法给出了积极的结果,但是有两个缺点:
- 对于每个品牌,有必要创建自己的特征以进行协作过滤;
- 需要训练样本。
最近,越来越多的公司希望在互联网上保护自己的品牌,并要求自动检测网络钓鱼站点。 受保护的每个新品牌都会增加一个新属性。 为每个新品牌创建培训样本需要额外的人工工作和时间。
我们开始寻找解决此问题的方法。 他们找到了一种非常简单有效的方法。
首先,我们将使用以下算法构建资源对:
- 取所有至少有N1个地址的资源(我们用a表示),将这种关系表示为#(a)≥N1。
- 我们构造所有类型的资源对(a1,a2),并仅选择至少有N2个地址的资源对,即 #(a1,a2)≥N2。
然后,我们类似地考虑由上一段中获得的对组成的对。 结果,我们得到四个:(a1,a2)+(a3,a4)→(a1,a2,a3,a4)。 此外,如果在一对中至少有一个元素,则不是三元组,而是三元组:(a1,a2)+(a2,a3)→(a1,a2,a3)。 在结果集中,我们只留下至少与N3个地址相对应的那些四和三元组。 依此类推...
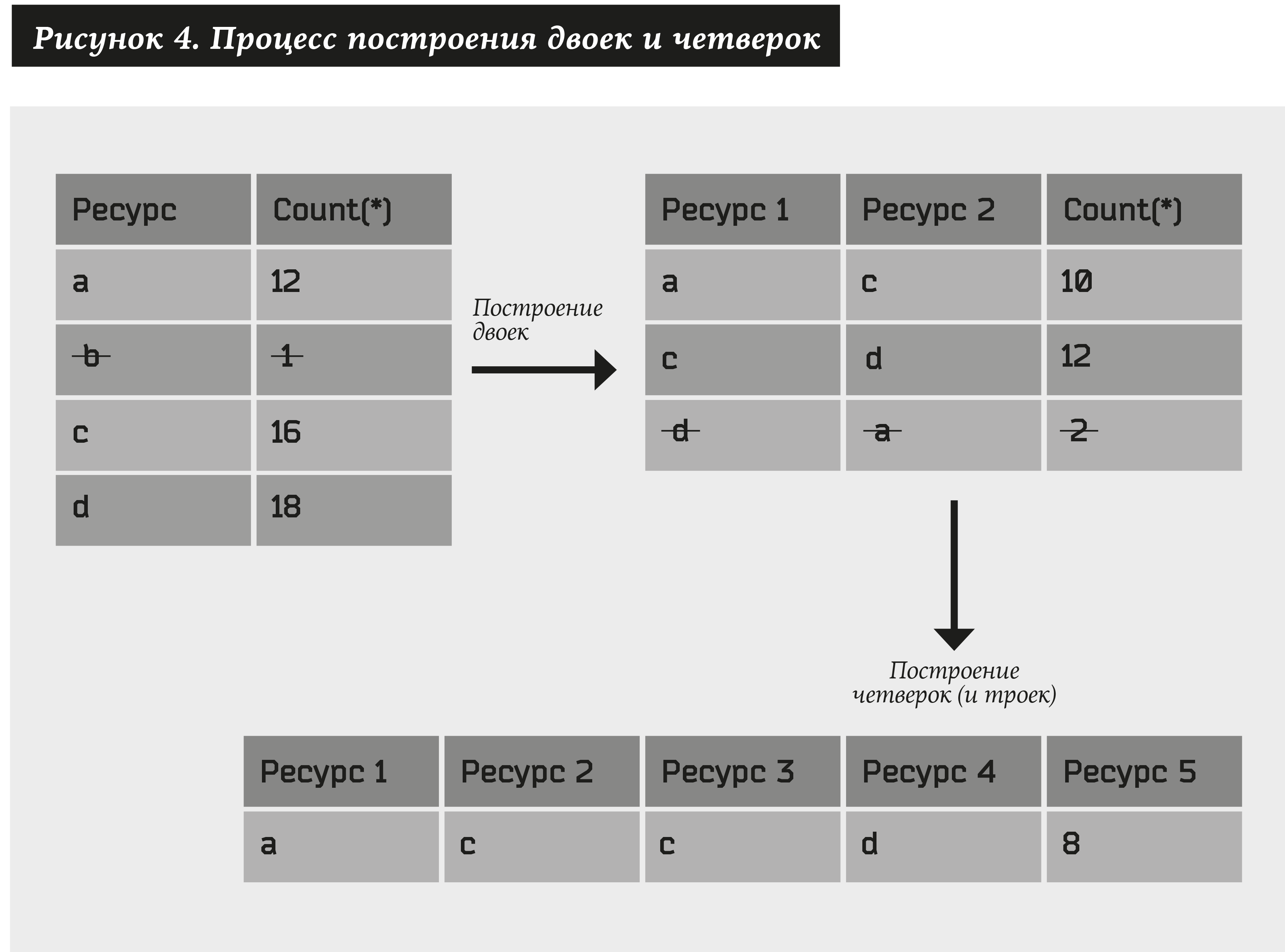
您可以获得多个任意长度的资源。 将步数限制为U。然后N1,N2 ... NU是系统参数。
值N1,N2 ... NU是算法的参数,它们是手动设置的。 在一般情况下,我们有CL2个不同的对,其中L是资源的数量,即 建立配对的难度为O(L2)。 然后从每对创建一个四边形。 从理论上讲,我们可能得到O(L4)。 但是,实际上,此类对要小得多,并且具有大量地址,因此可以凭经验获得O(L2log L)依赖性。 而且,随后的步骤(将二变成四,将四倍变成八,等等)可以忽略不计。
应该注意的是,L是非集群URL的数量。 可以归因于任何先前批准的群集的所有URL均不属于群集选择。
在输出中,您可以创建许多包含最大可能资源集的集群。 例如,如果存在满足Ni边界的(a1,a2,a3,a4,a5),则应从一组簇(a1,a2,a3)和(a4,a5)中删除。
然后,每个接收到的群集都将发送以进行手动验证,CERT分析人员将其分配为状态:+1(“已批准”)或–1(“已拒绝”),并指出落入该群集的URL是否是网络钓鱼或合法站点。
添加新资源时,URL的数量可能会减少,保持不变,但永远不会增加。 因此,对于任何资源a1 ... aN,该关系为真:
#(a1)≥#(a1,a2)≥#(a1,a2,a3)≥...≥#(a1,a2,...,aN)。
因此,明智的是设置参数:
N1≥N2≥N3≥...≥NU
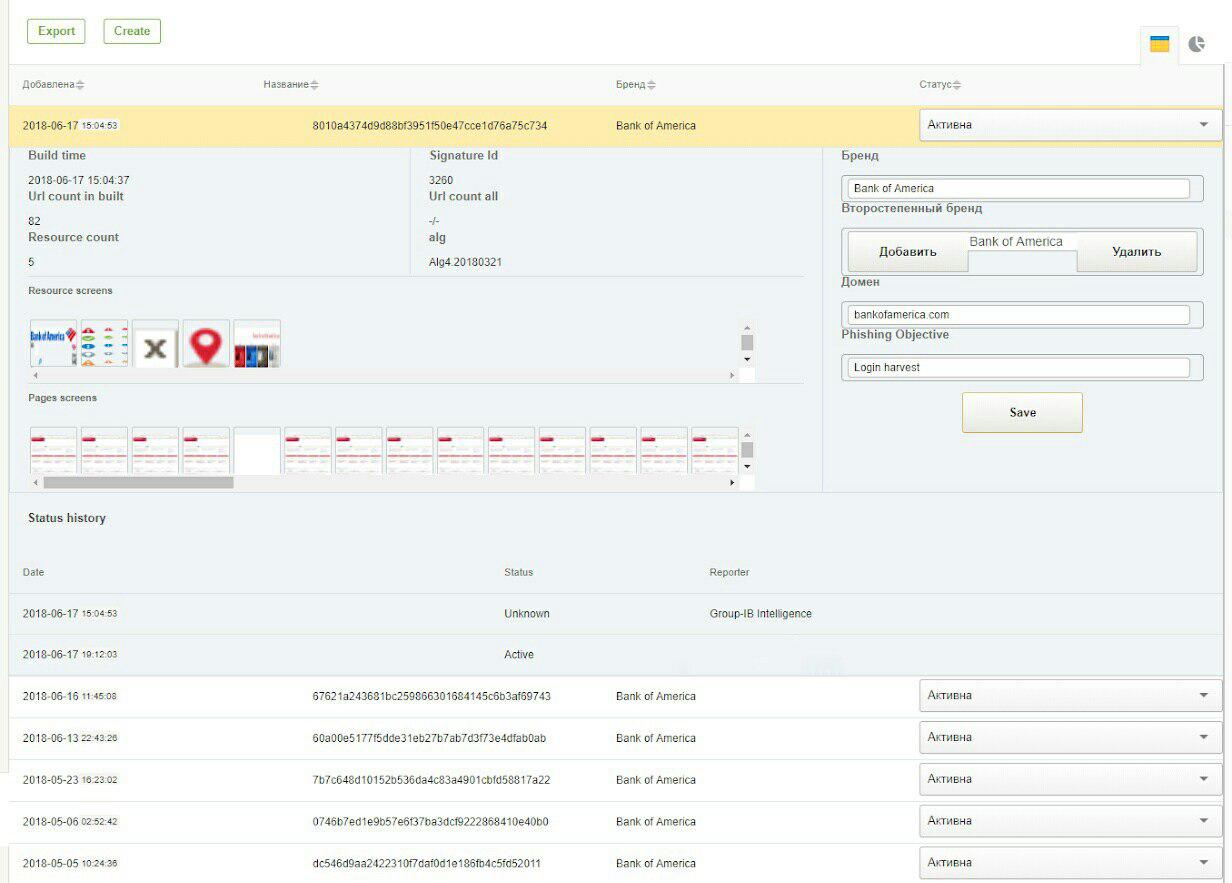
在输出中,我们给出各种组进行验证。 在图。 本文开头的图1展示了所有资源都是图像的真实群集。
在实践中使用该算法
请注意,现在您不再需要研究网络钓鱼工具! 系统会自动聚类并找到必要的网络钓鱼页面。
每天,该系统从5,000个网络钓鱼页面中接收信息,每天构造总共3至25个新集群。 对于每个群集,将上传资源列表,并创建许多屏幕截图。 将该群集发送到CERT分析以进行确认或拒绝。
在启动时,算法的准确性很低-只有5%。 但是,三个月后,系统将精度保持在50%到85%之间。 其实准确性没关系! 最主要的是分析师有时间查看集群。 因此,例如,如果系统每天生成约10,000个群集,而您只有一名分析人员,则必须更改系统参数。 如果每天不超过200,对于一个人来说,这是一项可行的任务。 如实践所示,视觉分析平均需要大约1分钟。
系统的完整性约为82%。 其余18%是网络钓鱼的特例(因此无法将其分组),或者是网络钓鱼资源少(没有任何分组依据)的网络钓鱼,或者是网络钓鱼页面超出了参数N1,N2 ... NU的范围。
重要要点:多久在未发送的新鲜URL上开始新的集群? 我们每15分钟执行一次。 此外,根据数据量,群集时间本身需要10到15分钟。 这意味着在出现仿冒网站URL之后,会有30分钟的时间滞后。
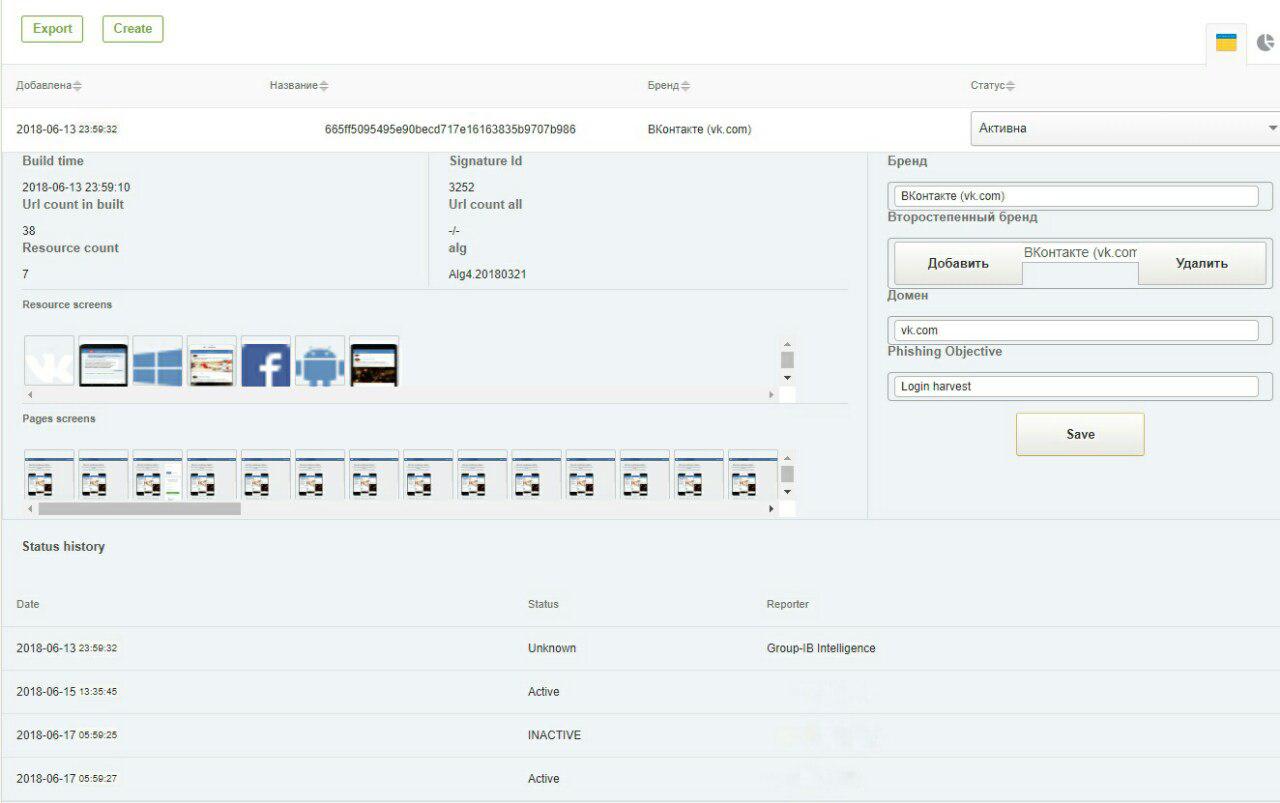
以下是来自GUI系统的2个屏幕截图:用于在VKontakte和Bank of America社交网络上检测网络钓鱼的签名。
当算法不起作用时
如上所述,如果没有达到由参数N1,N2,N3 ... NU指定的边界,或者如果资源的数量太小而无法形成必要的群集,则该算法在原理上将不起作用。
网络钓鱼者可以通过为每个网络钓鱼站点创建唯一的资源来绕过算法。 例如,在每个图像中,您可以更改一个像素,并且对于已加载的JS和CSS库,请使用模糊处理。 在这种情况下,有必要为每种类型的已加载文档开发可比较的哈希算法(感知哈希)。 但是,这些问题不在本文讨论范围之内。
全部放在一起
我们将模块与经典的HTML常规代码(从Threat Intelligence(网络智能系统)获得的数据)连接起来,填充度达到99.4%。 当然,这是对威胁情报先前已归类为网络钓鱼可疑的数据的完整性。
没有人知道所有可能数据的完整性,因为从原则上讲不可能覆盖整个Darknet,但是,根据Gartner,IDC和Forrester的报告,Group-IB在功能上是威胁情报解决方案的领先国际提供商之一。
那未分类的网络钓鱼页面又如何呢? 每天约有25-50个。 可以手动检查它们。 总的来说,在信息安全领域,对于Data Sciense而言,在任何一项非常困难的任务中总会有体力劳动,而且任何关于100%自动化的指控都是市场虚构的。 数据科学专家的任务是将体力劳动减少2-3个数量级,以使分析师的工作尽可能高效。
在
JETINFO上发表的
文章