收集的数据的屏幕截图:
 现代安全系统非常依赖资源。
现代安全系统非常依赖资源。 怎么了 因为它们比许多生产服务器和商业智能系统重要。
他们怎么看? 我现在解释。 让我们从一个简单的例子开始:按照惯例,第一代保护设备非常简单-在“启动”和“不启动”级别。 例如,防火墙允许根据某些规则的流量,而不允许根据其他规则的流量。 自然,为此不需要特殊的计算能力。
下一代已经获得了更复杂的规则。 因此,有些信誉系统会根据用户的奇怪行为和业务流程的变化,根据预定义的模板为它们分配可靠性等级,并手动设置运行阈值。
现在,UBA(用户行为分析)系统可以分析用户行为,将其与其他公司员工进行比较,并评估每个员工行为的一致性和正确性。 这样做是由于采用了Data Lake方法和相当耗费资源的机器学习算法而进行的自动处理-主要是因为用手书写所有可能的场景需要花费数千个工作日。
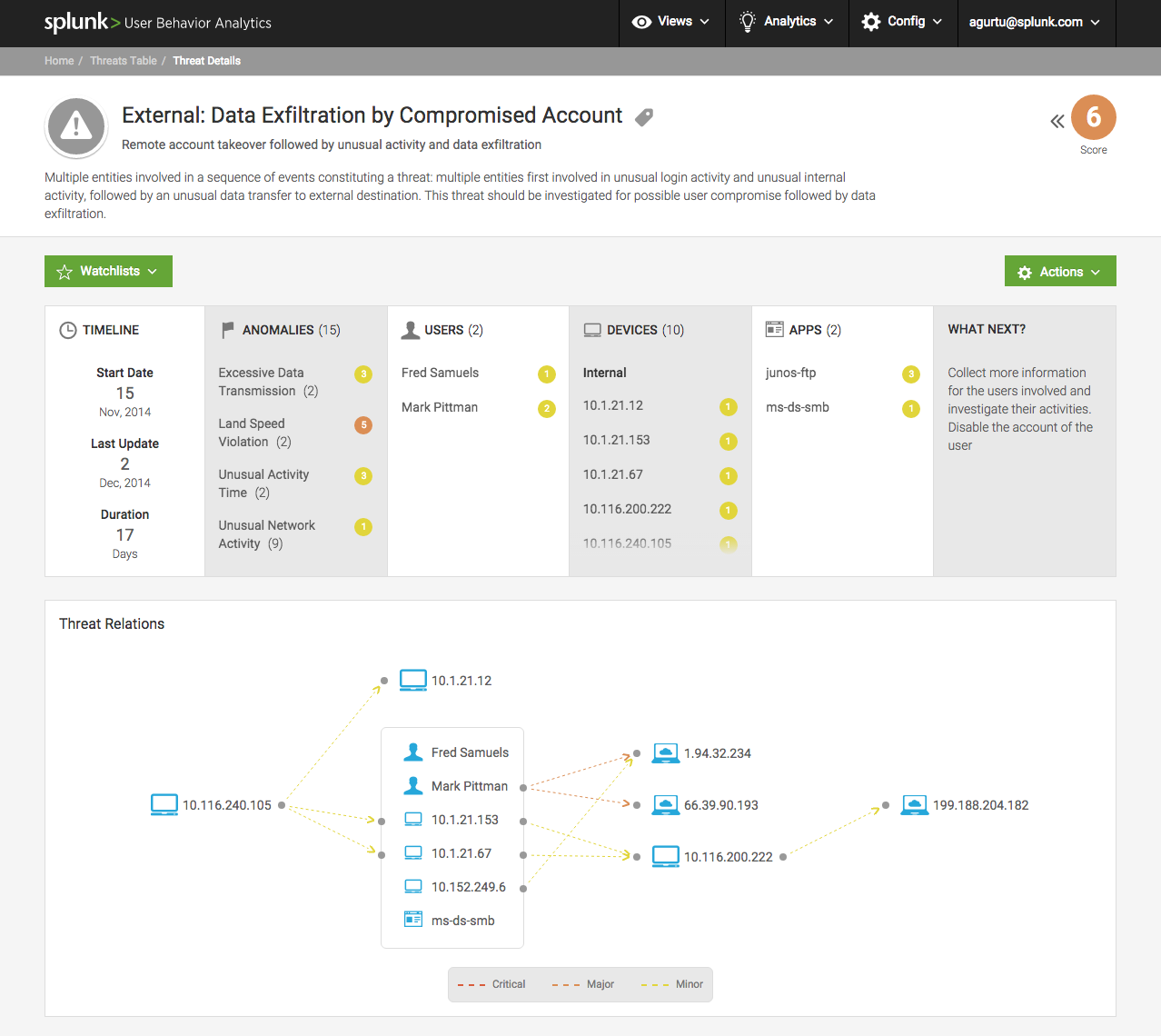
经典SIEM
直到2016年左右,当所有网络节点的所有事件都收集在分析服务器所在的位置时,该方法才被认为是渐进式的。 分析服务器可以收集,过滤事件并将其映射到关联规则。 例如,如果在某个工作站上开始录制大量文件,则可能是加密病毒的迹象,也可能不是。 但以防万一,系统将向管理员发送通知。 如果存在多个站点,则部署恶意软件的可能性会增加。 我们必须提起警报。
如果用户敲几个星期前注册的某个陌生域,并且几分钟后所有这些彩色音乐都消失了,那么这几乎肯定是一种加密病毒。 有必要熄灭工作站并隔离网段,同时通知管理员。
SIEM对来自DLP,防火墙,反垃圾邮件等的数据进行了比较,从而可以很好地应对各种威胁。 弱点是这些模式和触发器-考虑什么是危险情况,什么不考虑。 此外,就像病毒和各种棘手的DDoS一样,SOC中心专家开始形成其攻击信号的基础。 对于每种攻击类型,都考虑了一种情况,突出了症状,并为其分配了其他操作。 所有这些都需要在24 x 7模式下不断完善和调整系统。
有效-请勿触摸,但一切正常!
这就是为什么没有UBA是不可能的吗? 第一个问题是无法用手开处方。 因为不同的服务行为不同-以及不同的用户。 如果您为公司内的普通用户注册事件,则支持,会计,招标部门和管理员将非常有区别。 从这种系统的角度来看,管理员显然是恶意用户,因为他做了很多事并积极地爬进其中。 支持是恶意的,因为它与每个人都有联系。 簿记通过加密隧道传输数据。 招标部门在发布文件时会不断合并公司数据。
结论-必须为每种方法规定资源使用方案。 然后更深。 然后更深。 然后,过程中会发生某些变化(并且每天都会发生),并且必须再次进行规定。
当自动确定用户的标准时,使用“移动平均值”之类的方法是合乎逻辑的。 我们将回到这一点。
第二个问题是攻击者变得更加准确。 以前,即使您错过了黑客攻击的时间,数据流失也很容易捕获-例如,黑客可以通过邮件或文件托管将自己感兴趣的文件上传到自己,并且最好将其加密在存档中以避免被DLP系统检测到。
现在,一切都变得更加有趣。 这就是我们过去一年在SOC中心看到的情况。
- 通过将照片发送到Facebook进行隐写术。 该恶意软件已在FB注册并订阅了该组。 小组中发布的每张照片都配有内置的数据块,其中包含有关恶意软件的说明。 考虑到JPEG压缩期间的损失,事实证明,每张图片传输约100个字节。 此外,该恶意软件本身每天在社交网络上发布2-3张照片,足以传输通过mimikatz合并的登录名/密码。
- 在网站上填写表格。 该恶意软件运行了一个用户操作模拟器,转到了某些站点,在那里找到了“反馈”形式并通过它们发送数据,并在BASE64中对二进制数据进行了编码。 这是我们已经掌握的新一代系统。 在经典的SIEM上,最可能不知道这种发送方法的情况下,他们甚至都不会注意到。
- 以一种标准方式-a,以一种标准方式-他们将数据混合到DNS流量中。 DNS中有很多用于隐秘术的技术,通常通过DNS构建隧道,此处的重点不是轮询某些域,而是请求类型。 系统向用户发出有关DNS流量增长的轻微警报。 数据发送缓慢且间隔不同,因此很难使用安全功能进行分析。
为了渗透,他们通常使用由目标公司的用户直接制作的严格定制的病毒。 此外,攻击通常通过中间链接。 例如,起初承包商受到破坏,然后通过它,恶意软件被输入到主公司。
近年来,病毒几乎总是严格地位于RAM中,并且从一开始就被删除-强调没有痕迹。 在这种情况下进行取证非常困难。
总体结果-SIEM做得不好。 许多事情是看不见的。 像这样的事情,市场上出现了一个空位:这样就不必将系统调整为攻击类型,但是她自己知道什么地方出了问题。
她是如何“理解”自己的?
第一个声誉安全系统是用于防止银行洗钱的反欺诈模块。 对于银行而言,最主要的是识别所有欺诈交易。 也就是说,不愿再花一点时间,主要是操作人员首先要了解什么。 他并没有被很小的警报所淹没。
系统的工作方式如下:
- 他们基于许多参数构建用户配置文件。 例如,他通常如何花钱:他购买了什么,他如何购买,他输入确认码的速度有多快,他从哪台设备进行交易等等。
- 逻辑层检查在交易之间的时间段内是否有可能从付款时间到传输的另一个时间。 如果购买是在另一个城市,则检查用户是否经常去其他城市,如果在另一个国家-用户是否经常去其他国家,并且最近购买的机票增加了不需要报警的机会。
- 信誉模块-如果用户在其正常行为的框架内进行所有操作,则将为他的行为(非常缓慢地)给予积极的评分,而在非典型的框架内则给予否定的评分。
让我们更详细地讨论后者。
示例1.您一生都在星期五在麦当劳买了一块馅饼和可乐,然后在星期二早上突然买了500卢布。 非标准时间减2点,非标准时间减3点。 您的警报阈值设置为–20。 没事
对于大约5到6次这样的购买,您会将这些积分撤回零,因为系统会记住您在星期二早上去麦当劳是正常的。 当然,我极大地简化了工作,但是工作逻辑大致相同。
示例2。您一生都以普通用户的身份购买了各种小东西。 您将在杂货店付款(系统已经“知道”您通常吃多少食物,以及您最常购买的位置,或者确切地说,它不知道,只需在个人资料中写上),然后购买一个月的地铁票或订购一些小东西通过在线商店。 现在,您在香港以八千美元的价格购买了钢琴。 可以吗 可以。 让我们看一下要点:–15代表标准欺诈,–10代表非标准金额,–5代表非标准地点和时间,–5代表没有购票的另一个国家,–7代表以前没有使用过任何物品他们带去了国外,他们的标准设备+5,银行其他用户在那儿购买的+5。
您的警报阈值设置为–20。 交易被“暂停”,银行IB的一名员工开始了解情况。 这是一个非常简单的情况。 5分钟后,他很可能会打电话给您说:“您真的决定在凌晨4点在香港的一家音乐商店以8千美元的价格买东西吗?” 如果您回答“是”,他们将跳过交易。 一旦完成一项操作,数据就会落入配置文件中,然后对于类似的操作,将给出较少的负值,直到它们完全成为标准。
正如我说的,我真的非常简化。 多年来,银行一直在对信誉系统进行投资,并且已经对其进行了完善。 否则,一堆mu子会很快提款。
这如何转移到企业信息安全中?
基于反欺诈和反洗钱算法,出现了行为分析系统。 收集了完整的用户配置文件:打印速度,访问的资源,与之交互的对象,启动的软件-通常,用户每天执行的所有操作。
一个例子。 用户经常与1C进行交互并经常在其中输入数据,然后突然开始以数十个小报告的形式卸载整个数据库。 他的行为超出了此类用户的标准行为,但是可以按类型将他与相似配置文件的行为进行比较(很可能是其他会计师)-很明显,他们在特定时间会有一个星期的报告,并且他们都这样做。 数字相同,没有其他差异,警报不会发出。
另一个例子。 一个用户一生都在使用文件球工作,每天记录几十个文件,然后突然他开始从中取出成千上万个文件。 另一个DLP表示它发出了一些重要信息。 也许招标部门已经开始为比赛做准备,也许“老鼠”正在向竞争对手泄漏数据。 该系统当然不知道这一点,而只是描述其行为并向安全卫士发出警报。 从根本上讲,新员工,技术支持人员或CEO的行为可能与“哥萨克行动不当”的行为几乎没有什么不同,安全人员的任务是告诉系统这是正常行为。 无论如何,配置文件都将遵循,如果总经理的帐户受到损害并且声誉下降,就会响起警报。
用户配置文件引起了UBA系统的规则。 更准确地说,成千上万的启发式规则会定期更改。 每个用户组都有自己的原则。 例如,这种类型的用户每天发送100 MB,其他用户每天发送1 GB(如果不是周末)。 依此类推。 如果第一个发送5 GB,则表示可疑。 如果是第二个-则将有负点,但它们不会超过警报阈值。 但是,如果他在附近将DNS设置为可疑的新域,那么将会有更多负面影响,并且警报已经发生。
方法是,这不是以下规则:“如果存在奇怪的DNS查询,然后流量跳开,则……”,而不是“如果信誉达到–20,则...”规则-用户或进程的信誉点的每个单独来源都是独立且确定的完全是他的行为规范。 自动地。
同时,首先,信息安全部门帮助培训系统并确定什么是规范,什么不是规范,然后系统根据实际流量和用户活动日志进行适应,重新培训。
我们放什么
作为系统集成商,我们为客户提供信息安全运营管理服务(托管
SOC CROC服务)。 可从我们的云基础架构中获得的关键组件以及资产管理,漏洞管理,安全测试和威胁情报等系统,是经典SIEM与主动型UBA之间的链接。 同时,根据客户的意愿,对于UBA,我们可以使用大型供应商的工业解决方案,也可以使用我们自己的基于Hadoop + Hive + Redis + Splunk Analytics for Hadoop(Hunk)捆绑包的分析系统。
以下解决方案可从我们的云SOC CROC或根据内部模型进行行为分析:
- Exabeam:也许是最用户友好的UBA系统,它使您可以通过User Tracking技术快速调查事件,该技术将IT基础架构中的活动(例如,使用SA帐户登录的本地数据库)与真实用户联系起来。 包括约400个风险评分模型,这些模型为每个奇怪或可疑的行为增加了用户罚款点;
- Securonix:一个非常耗资源但非常有效的行为分析系统。 该系统位于大数据平台之上,几乎有1000款可用。 他们中的大多数使用专有的群集技术来进行用户活动。 该引擎非常灵活,您可以跟踪和聚类CEF格式的任何字段,从Web服务器日志与每天平均请求数的偏差开始,到识别用户流量的新网络交互为止。
- Splunk UBA:Splunk ES的一个很好的补充。 开箱即用的规则很小,但是参考了“杀伤链”(Kill Chain),它使您不会被较小的事件分散注意力,并专注于真正的黑客。 当然,我们可以使用Splunk机器学习工具包上的所有统计数据处理功能以及对累积数据总量的回顾性分析。
对于关键部分,无论是自动化过程控制系统还是关键业务应用程序,我们都放置了其他传感器来收集高级取证和hanitopes,以将黑客的注意力从生产系统转移出去。
为什么资源丰富?
因为所有事件都被写入。 就像Google Analytics(分析)一样,仅在本地工作站上。 在本地网络上,所有事件均通过有关统计信息和关键事件的Internet元数据发送到Data Lake,但是,如果SOC运营商想要调查该事件,也将记录完整的日志。 一切都已收集:临时文件,注册表项,所有正在运行的进程及其校验和,这些都写在启动,操作,截屏中-随便什么。 以下是收集的数据的示例。
工作站的参数列表:
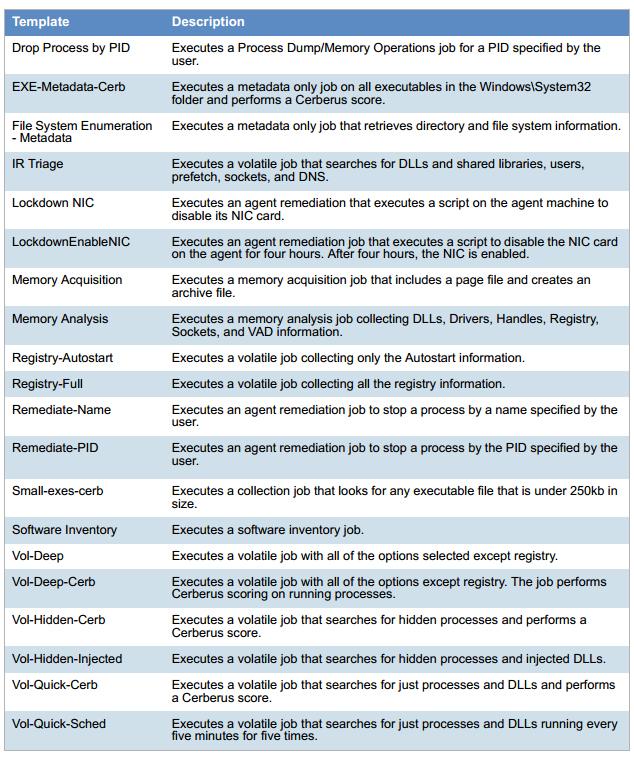


就存储和RAM而言,系统变得更加复杂。 经典的SIEM以64 GB的RAM,两个处理器和半TB的存储空间开始。 UBA来自TB级的RAM和更高。 例如,我们的上一个实现是在33台物理服务器(28个计算节点用于数据处理+ 5个控制节点用于负载平衡),150 TB的湖(硬件为600 TB,包括实例上的快速缓存)和384 GB的RAM上。
谁需要这个?
首先,那些处于“风险区”并不断受到攻击的人是银行,金融机构,石油和天然气部门,大型零售商店以及许多其他国家。
对于这样的公司,数据泄漏或丢失的成本可能高达数千万甚至数亿美元。 但是安装UBA系统的成本要低得多。 当然,还有国有公司和电信公司,因为没有人希望在某个时候以公开访问的方式来传递数以百万计的患者或数以千万计的人的信件。
参考文献