
如今,如果不使用
静态代码分析方法,就很难想象要开发高质量的软件。 程序代码的静态分析可以内置到开发环境中(通过标准方法或使用插件),可以在代码投入商业运行之前由专门的软件执行,或者由常规或外部专家“手动”执行。
经常有人争辩说,
动态代码分析或
渗透测试可以代替静态分析,因为这些验证方法将揭示实际问题,并且不会出现误报。 但是,这是有争议的,因为与静态分析不同,动态分析不会检查所有代码,而只会检查软件对模拟攻击者行为的一系列攻击的抵抗力。 攻击者可能比验证者更有创造力,而与执行验证的人员(人或机器)无关。
只有在完整的测试范围内进行动态分析,动态分析才能完成,而将其应用于实际应用程序时,这是一项艰巨的任务。 测试覆盖范围完整性的证明是算法上无法解决的问题。
在调试对信息安全性有更高要求的软件时,对程序代码进行强制性静态分析是必要的步骤之一。
目前,市场上有许多不同的静态代码分析器,并且越来越多的新静态分析器不断出现。 实际上,由于不同的分析仪寻找不同的缺陷,因此有时会同时使用多个静态分析仪以提高验证质量。
为什么没有通用的静态分析器可以完全检查任何代码并发现其中的所有缺陷而没有误报,并且同时可以快速工作并且不需要大量资源(CPU时间和内存)?
关于静态分析仪的架构
这个问题的答案在于静态分析仪的体系结构。 几乎所有静态分析器都以某种方式基于编译器原理构建,也就是说,在它们的工作中,存在源代码转换的阶段-与编译器执行的阶段相同。
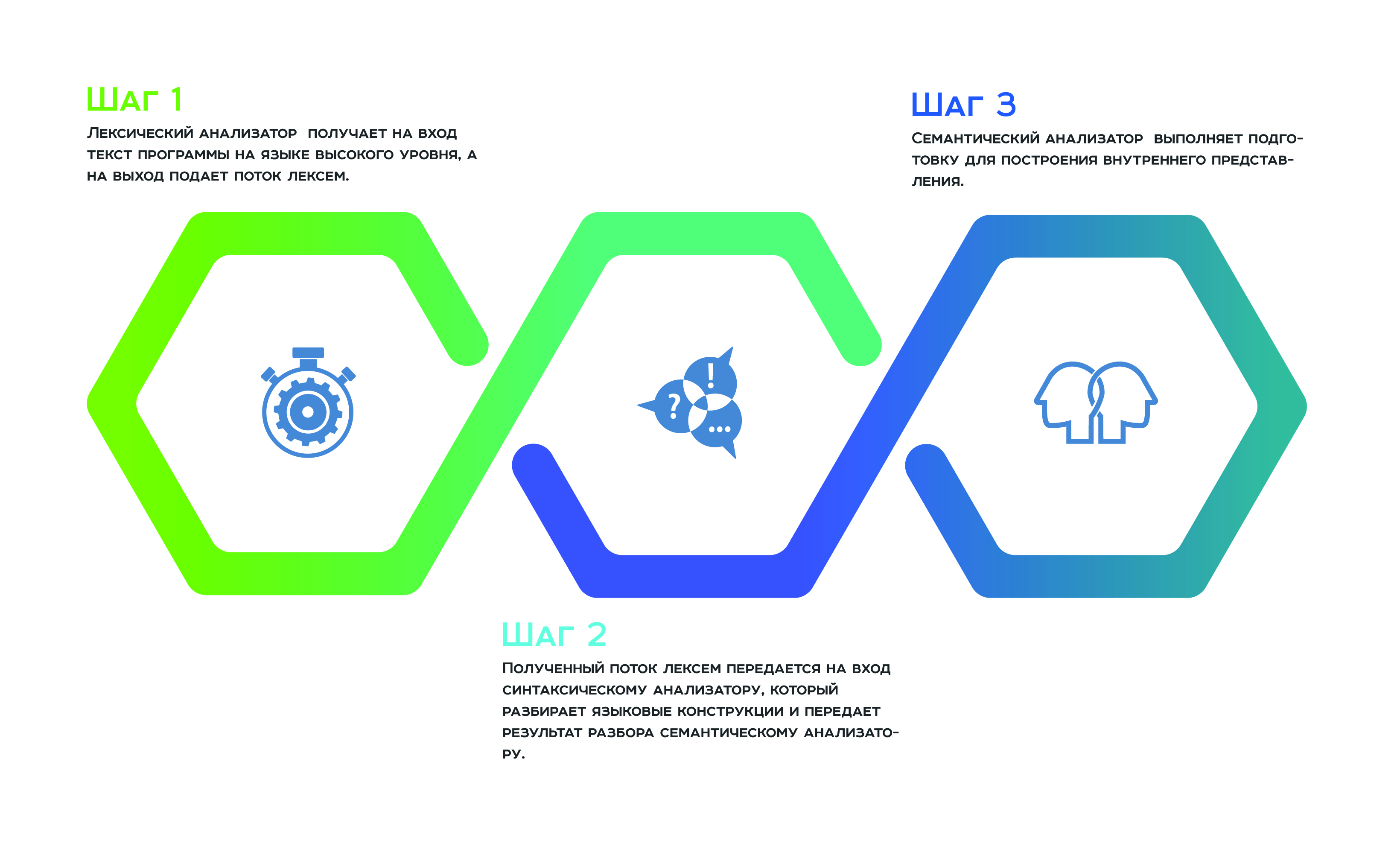
一切都从
词法分析开始,该
分析以高级语言接收程序文本作为输入,并输出标记流。 接下来,将接收到的令牌流传输到
解析器的输入
,解析器对语言结构进行解析,并将解析结果传递给
语义分析器 ,
语义分析器根据其工作结果准备构建内部表示。 这种内部表示是每个静态分析器的功能。 分析仪的效率取决于它的成功程度。
许多静态分析仪制造商声称对分析仪支持的所有编程语言使用通用的内部表示形式。 因此,他们可以整体分析以多种语言开发的程序代码,而不是将其作为单独的组件进行分析。 分析的“整体方法”可以避免遗漏在软件产品的各个组件之间的界面处出现的缺陷。
从理论上讲,这是正确的,但是在实践中,所有编程语言的通用内部表示都是困难且效率低下的。 每种编程语言都是特殊的。 内部视图通常是一棵树,其顶点存储属性。 通过遍历这样的树,分析器收集并转换信息。 因此,树的每个顶点必须包含一组统一的属性。 由于每种语言都是唯一的,因此属性的统一性只能由组件冗余来支持。 编程语言越多样化,每个顶点的特征中的组成成分就越多样化,因此内部表示对内存的效率不高。 大量的异构特性也影响了树行者的复杂性,这意味着它会导致性能低下。
静态分析仪的优化转换
为了使静态分析器在内存和时间上高效工作,您需要有一个紧凑的通用内部表示形式,这可以通过以下方式实现:将内部表示形式分为几棵树,每棵树都是为相关的编程语言设计的。
优化工作不仅限于将内部表示形式划分为相关的编程语言。 此外,制造商使用各种优化转换-与编译器技术相同,尤其
是循环的优化转换 。 事实是,静态分析的目标理想地是在程序中进行数据升级,以便评估程序执行期间的数据转换。 因此,在循环的每个回合中都必须“高级”数据。 因此,如果您节省了这些时间并使它们变小得多,那么我们将在内存和性能上获得巨大的好处。 为此目的,积极地使用这样的变换,以一定的概率以最小的通过次数将数据变换外推到周期的所有匝数。
您还可以通过计算程序在一个或另一个分支上运行的可能性来节省分支。 如果沿着分支通过的概率低于此概率,则不考虑该程序分支。
显然,这些转换中的每一个都会“丢失”分析仪应检测到的缺陷,但这对存储器效率和性能来说是“费用”。
静态代码分析器在寻找什么?
有条件地,对入侵者(因此对于审核员)感兴趣的缺陷可以分为以下几类:
验证错误是由于未正确检查输入数据的正确性而导致的。 攻击者可以输入程序不希望的内容作为输入,从而获得对控件的未授权访问。 最常见的数据验证错误是注入和
XSS 。 攻击者没有提供有效数据,而是将携带小程序的经过特殊准备的数据提交给程序输入。 被处理的程序被执行。 其实施的结果可能是将控制权转移到另一个程序,数据损坏等等。 同样,由于验证错误,可以替换用户正在使用的站点。 验证错误可以通过静态代码分析方法定性检测。
信息泄漏错误是与以下事实有关的错误:来自用户的敏感信息(作为处理结果)被拦截并传输给攻击者。 反之亦然:存储在系统中的敏感信息在移至用户时会被拦截并传输给攻击者。
此类漏洞与验证错误一样难以检测。 要检测此类错误,需要在统计信息中跟踪整个程序代码中数据的进度和转换。 这需要实施诸如
污点分析和
过程间数据分析之类的方法 。 分析的准确性在很大程度上取决于这些方法的开发水平,即最大限度地减少误报和漏失。
用于检测缺陷的规则库,尤其是描述这些规则的格式,在静态分析仪的准确性中也起着重要作用。 所有这些都是每台分析仪的竞争优势,并且受到竞争对手的精心保护。
身份验证错误是攻击者最感兴趣的错误,因为它们难以识别,因为它们出现在组件的交汇处并且难以形式化。 攻击者利用这种错误来升级访问权限。 由于不清楚要查找的内容,因此不会自动检测到身份验证错误-这些是构建程序逻辑中的错误。
记忆体错误
它们很难检测,因为准确的识别需要解决麻烦的方程组,这在内存和性能上都是昂贵的。 因此,方程组减少了,这意味着精度下降。
典型的内存错误包括
free-after-free ,
double-free ,
null-pointer-dereference和它们的变体,例如,
越界读取和
越界写入 。
当下一个分析仪未能检测到内存泄漏时,您会发现很难利用此类缺陷。 攻击者必须具备很高的资格并运用大量技能,首先要找出代码中是否存在此类缺陷,其次要进行利用。 好吧,争论还在继续:“您确定您的软件产品对这样一个水平的专家来说很有趣吗?” ...但是,历史知道成功利用内存错误并造成相当大破坏的案例。 众所周知的情况,例如:
- CVE-2014-0160 -openssl库中的错误-私钥的潜在危害要求重新发行所有证书和密码。
- CVE-2015-2712 -Mozilla firefox中的js实现中的错误-边界检查。
- CVE-2010-1117-可在Internet Explorer中免费使用-可远程利用。
- CVE-2018-4913-在Acrobat Reader中免费使用-代码执行。
此外,攻击者喜欢利用与线程或进程的不正确同步相关的缺陷。 由于没有“时间”的概念来模拟机器的状态并不是一件容易的事,因此很难从静态中识别出此类缺陷。 这是指诸如
race-condition之类的错误。 如今,并发无处不在,即使在很小的应用程序中也是如此。
综上所述,应该注意的是,如果使用正确,静态分析器在开发过程中很有用。 在操作过程中,有必要了解它的期望值以及如何处理静态分析仪原则上无法识别的那些缺陷。 如果他们说在开发过程中不需要静态分析器,则意味着他们根本不知道如何操作它。
如何正确操作静态分析仪,以正确有效地使用其提供的信息,请在我们的博客中继续阅读。