如果您很长时间以来一直喜欢神经网络技术,那么您可能会碰到一个在修辞问题中简短总结的观点:“当神经网络认为自己患有癌症时,您如何向人解释?” 而且,如果在最好的情况下,这种想法使您怀疑在足够
负责的领域中使用神经网络,那么在最坏的情况下,您可能会失去全部兴趣。
我遇到了最好的选择-我从容地接受了这一限制,并且不加思索,就继续在计算机视觉领域使用神经网络技术。
挑战赛
最近,一项任务落在我身上-快速创建可行的情绪检测器。 条件设置得很清楚-正面位于100x100分辨率的人。 在寻找一个完整的数据集时,我花了几个小时才意识到几乎没有什么适合我的。 甚至出于“研究目的”,都很难访问数据集。 很快就找到了出路-拍摄十几部长片,然后简单地通过它们运行Haar级联以卸载所有面孔。 在夜间,收到了超过(!)30k图像。 此外,接收到的图像按5种主要情绪进行分类(快乐,悲伤,中立,愤怒,惊讶)。 当然,远非所有图像都适合,因此,每个类别中有400-500张面部图像。
然后,一切都从解释神经网络的结果开始。 即使使用了足够高质量的自定义数据扩充,这种数据集也显然不足。 在训练基于Resnet块的网络时,获得了以下数字作为度量标准:
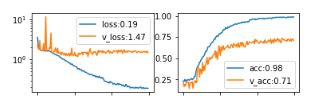
再培训是在示例数量不足的背景下进行的,但是由于缺乏时间,因此迫切需要确保网络至少在某种程度上令人满意地工作并且不依赖于情绪的确定。
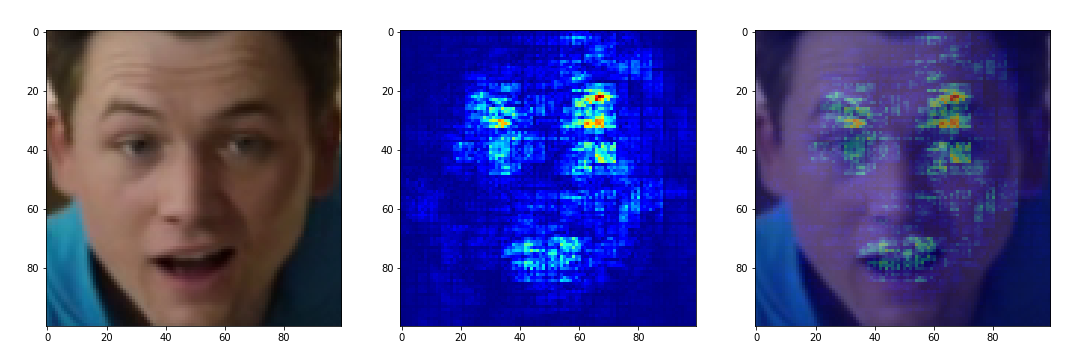
我曾经不得不使用Lime和Keras-Vis之类的工具,但是在这里,它们可能成为使黑盒子变成更透明的东西的哲学石。 两种工具的本质大致相同-确定对最终网络解决方案贡献最大的源图像区域。 为了测试,我拍摄了一个模仿各种情绪的视频。 卸载了与各种情感相对应的面部表情后,我在上面运行了上述工具
从Lime获得以下结果:

不幸的是,即使更改各种功能参数,Lime也无法获得足够的人类可读显示。 由于某些原因,脸的右半部分会影响“愤怒”阶层的归属。 “开心”的唯一一件事就是嘴巴的逻辑区域和典型的微笑酒窝。
此外,所有相同的图像都通过Keras-Vis和bingo运行:
快乐正在寻找眼睛的位置和嘴巴的形状。 悲伤专注于下垂的眉毛和眼皮。 “中性”会尝试查看整个脸部以及图像的纯正下角。 从逻辑上讲,“生气”着眼于眉毛移动,但忘记了嘴巴的形状,并出于某种原因寻找右下角的特征。 而“惊讶”则指的是嘴巴的形状和左眼(!)抬起的眼睑-现在也该开始识别右眼了。
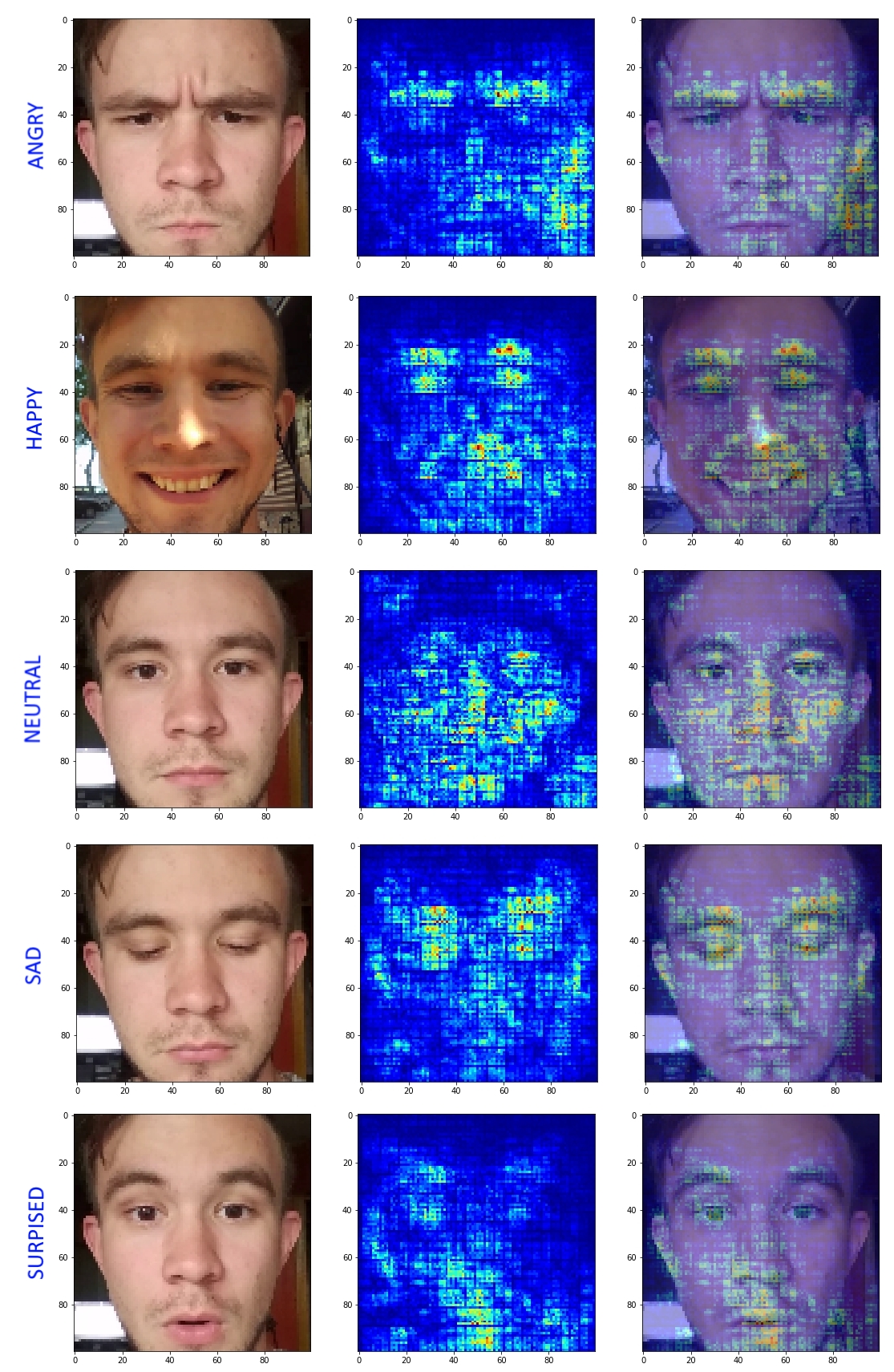
结果令人欣喜,并有可能看到最终网络的优势和劣势。 在感觉到“惊讶”和“愤怒”类的分类中存在弱点之后,我发现可以稍微增加样本并增加更多的辍学。 在下一次迭代中,获得了以下结果:

可以看出,激活区域更局限。 在“愤怒”的情况下,网络对背景的关注已经消失。 当然,网络仍然有其缺点,忘记了一侧的眉毛等等。 但是这种方法可以更好地了解结果模型的作用和原因。 在我们对网络的正确收敛性有疑问的情况下,这种方法是理想的。
结论
神经网络仍然只是复杂优化问题的解决方案。 但是,即使是最简单的网络注意卡也可以为该丛林带来一些透明度。 这种方法可以与损失函数的通常方向一起使用,这将允许获得更自觉的网络。
如果我们从文章开头回顾一下有关修辞的问题,那么我们可以说注意卡的使用以及网络的最终响应已经进行了某种明确的解释,而这是非常缺乏的。
再次可视化,可视化和可视化!