
我们开始在服务中更新对PgBouncer的监视,并决定对所有内容进行梳理。 为了使所有内容都适合,我们采用了最著名的性能监视方法:Brendan Gregg的USE(利用率,饱和度,错误)和Tom Wilkie的RED(请求,错误,持续时间)。
过场动画下面是一个故事,其中包含有关pgbouncer的工作原理,配置的处理方式以及如何使用USE / RED选择用于监控它的正确指标的图表。
首先关于方法本身
尽管这些方法是众所周知的(关于它们的详细信息尚未在Habré上发布,但已经很详细了 ),但这并不是说它们在实践中得到了广泛的应用。
使用方法
对于每种资源,请跟踪处置,饱和度和错误。
布伦丹·格雷格
在这里, 资源是任何单独的物理组件-CPU,磁盘,总线等。 但是,不仅-此方法还可以考虑某些软件资源的性能,特别是虚拟资源,例如具有限制的容器/ cgroup,考虑这一点也很方便。
U-处置 :资源忙于有用工作的时间的百分比(从观察间隔开始)。 例如,加载90%的CPU或磁盘利用率意味着90%的时间被有用的东西占用),或者对于诸如内存之类的资源,这就是所使用的内存百分比。
无论如何,100%的回收意味着资源不能再使用了。 并且要么工作会陷入等待发布/进入队列的状态,要么会出错。 其余两个相应的USE指标涵盖了这两种情况:
S-饱和度 ,它也是饱和度:“延迟” /排队工作量的度量。
E-错误 :我们只计算失败的次数。 错误/故障会影响性能,但由于检索翻转操作或使用备用设备的容错机制等,可能不会立即引起注意。
红色的
Tom Wilkie(现在在Grafana Labs工作)对USE方法感到沮丧,或者说,它在某些情况下的适用性很差并且与实践不符。 例如,如何测量内存饱和度? 还是在实践中如何测量系统总线错误?
事实证明,Linux确实报告了错误计数。
威尔基
简而言之,为了监视微服务的性能和行为,他提出了另一种合适的方法:再次测量三个指标:
R-速率 :每秒的请求数。
E-错误 :有多少个请求返回了错误。
D-持续时间 :处理请求所花费的时间。 它是等待时间,“等待时间”(©Sveta Smirnova :),响应时间等。
通常,USE更适合于监视资源,而RED更适合于服务及其工作负载/有效负载。
弹跳器
作为一项服务,它同时具有各种内部限制和资源。 关于Postgres,客户也可以通过此PgBouncer访问。 因此,要在这种情况下进行全面监视,则需要两种方法。
要了解如何将这些方法应用于保镖,您需要了解其设备的详细信息。 仅将其监视为黑盒子是不够的-“是pgbouncer进程还在运行”还是“端口是打开的”,因为 在出现问题的情况下,这将不会使您了解到底是什么,它如何破裂以及该怎么做。
从客户端的角度来看,PgBouncer通常是什么样的:
- 客户端连接
- [客户提出要求-收到回复] x他需要多少次
在这里,我从PgBoucer的角度绘制了相应的客户端状态图:

在登录过程中,授权可以在本地(文件,证书,甚至是新版本的PAM和hba)都可以进行,也可以在远程进行。 尝试连接到的数据库本身中。 因此,登录状态具有附加的子状态。 让我们称其为Executing以表示auth_query数据库中auth_query :
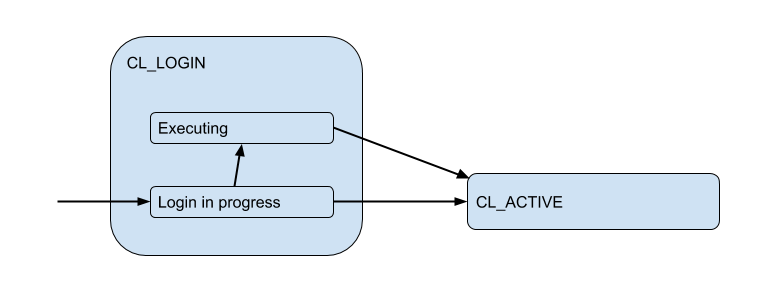
但是这些客户端连接实际上与PgBouncer在池中打开的后端/上游连接相匹配,并且保持有限数量。 而且,它们仅在一段时间内(在会话,事务或请求的持续时间内)才与客户端建立这种连接,具体取决于池的类型(由pool_mode设置确定)。 大多数情况下,使用事务池(稍后将主要讨论事务池)-当为一个事务向客户端发出连接时,实际上其余时间客户端未连接到服务器。 因此,客户的“活动”状态几乎没有告诉我们,我们将其划分为以下内容:
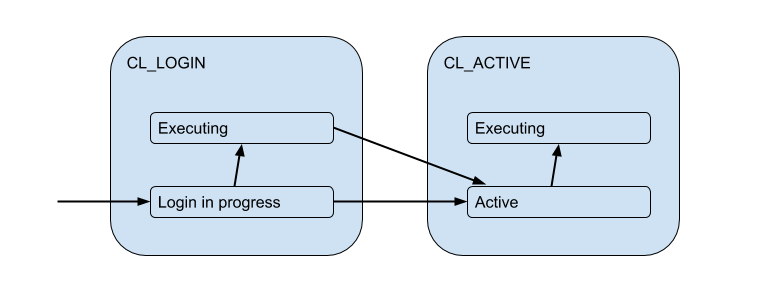
每个这样的客户端都属于自己的连接池,该连接池将被发布以供与Postgres的实际连接使用。 这是PgBouncer的主要任务-限制与Postgres的连接数。
由于服务器连接的限制,当客户端需要直接满足请求但现在没有免费连接时,可能会出现这种情况。 然后客户端排队,并且他的连接进入CL_WAITING状态。 因此,必须补充状态图:
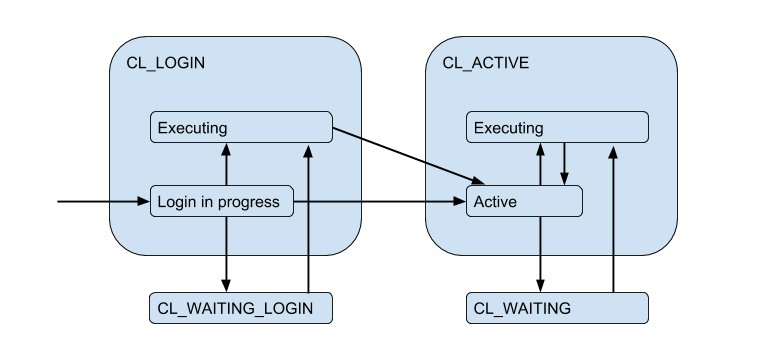
由于这可能发生在客户端仅登录并且他需要执行授权请求的情况下,因此CL_WAITING_LOGIN状态也会CL_WAITING_LOGIN 。
如果现在从背面看-从服务器连接的侧面看,则它们处于以下状态:当授权在连接后立即发生SV_LOGIN ,由客户端发布和(可能)使用SV_ACTIVE或自由使用SV_IDLE 。
用于PgBouncer
因此,我们来谈谈(原始版本)特定池的利用:
Pool utiliz = /
PgBouncer有一个特殊的pgbouncer实用程序数据库,其中有一个SHOW POOLS ,该SHOW POOLS显示每个池的连接的当前状态:

有4个客户端连接处于打开状态,并且所有客户端连接均为cl_active 。 在5个服务器连接中-4个sv_active和一个处于新状态sv_used 。
sv_used是关于pgbouncer与监控无关的不同设置的真正含义因此, sv_used并不像您可能想的那样意味着“正在使用连接”,而是“曾经使用过连接并且很长时间没有使用过”。 事实是,PgBouncer默认情况下在LIFO模式下使用服务器连接-即 首先,使用新发布的连接,然后使用最近使用的连接,等等。 逐渐转向长期使用的化合物。 因此,来自此类堆栈底部的服务器连接可能“变坏”。 并且应该在使用前检查它们的活泼性,这是使用server_check_query完成的,在检查它们时,状态将为sv_tested 。
该文档说,LIFO默认情况下处于启用状态,因为 那么“少量的连接将获得最大的工作量。当在pgbouncer后面有一台服务器为数据库服务时,这将提供最佳性能”,即 好像在最典型的情况下一样。 我相信潜在的性能提升是由于节省了多个后端进程之间的切换性能。 但是它不能可靠地解决,因为 这个实现细节已经存在超过12年了,并且超出了github上的提交历史和我感兴趣的深度=)
因此, server_check_delay设置的默认值为30秒,该默认值确定服务器未使用太长时间,应在将其提供给客户端之前进行检查,这似乎与当前现实server_check_delay 。 尽管事实上默认情况下同时使用默认设置同时启用了tcp_keepalive-闲置2小时后开始通过示例检查保持活动的连接。
事实证明,在想要在服务器上执行某些操作的客户端连接突发/激增的情况下,在server_check_query上引入了一个额外的延迟,尽管“ SELECT 1;可能仍需server_check_query = ';' 100微秒,并且如果使用server_check_query = ';' 那么您可以节省〜30微秒=)
但是,仅在几个连接中进行工作=在几个“主要”后端postgres流程上工作的假设将更加有效,这对我来说似乎令人怀疑。 postgres工作进程对有关此连接中访问的每个表的信息进行缓存(元)。 如果您有大量的表,则此relcache会增长很多,并占用大量内存,直到交换0_o进程的页面为止。 要解决此问题,请使用server_lifetime设置(默认为1小时),通过该设置将关闭服务器连接以进行旋转。 但另一方面,有一个server_round_robin设置,它将使用LIFO的连接模式切换为FIFO的使用模式,从而更均匀地分布服务器连接上的客户端请求。
SHOW POOLS从SHOW POOLS (由一些Prometheus出口商)获取度量,我们可以绘制以下状态:
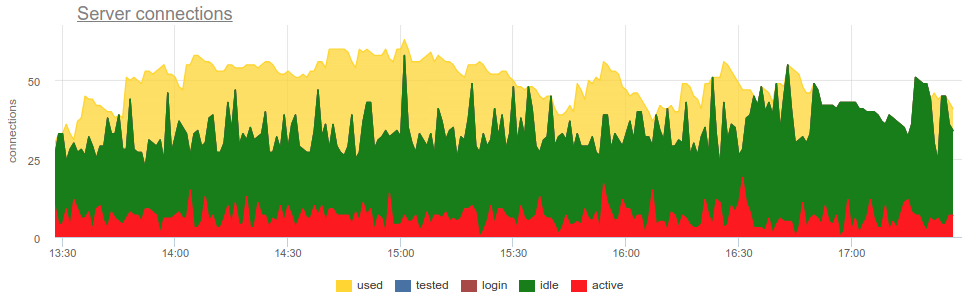
但是要处理,您需要回答几个问题:
- 游泳池的大小是多少?
- 如何计算使用了多少种化合物? 是开玩笑还是按时,平均还是高峰?
泳池大小
这里的一切都像生活一样复杂。 总共,pbbouncer中已经有五个设置限制!
- 可以为每个数据库设置
pool_size 。 为每个数据库/用户对创建一个单独的池,即 从任何其他用户,您可以创建另一个pool_size后端/ Postgres工作者。 因为 如果未设置pool_size ,则它属于default_pool_size ,默认值为20,那么事实证明,每个有权连接到数据库(并通过pgbouncer进行工作)的用户都可以创建20个Postgres进程,这似乎并不多。 但是,如果您有许多不同的数据库用户或数据库本身用户,并且池未向固定用户注册,即 将动态创建(然后由autodb_idle_timeout删除),这可能很危险=)
可能值得将default_pool_size保留为较小,仅适用于每个消防员。
max_db_connections只需限制一个数据库的连接总数,因为 否则,表现不佳的客户端可能会创建许多后端/ postgres进程。 默认情况下-无限__(ツ)_ /¯
也许您应该更改默认的max_db_connections ,例如,您可以专注于Postgres的max_connections (默认为100)。 但是如果您有很多PgBouncers ...
reserve_pool_size实际上,如果全部使用了pool_size,则PgBouncer可以再打开几个与该基座的连接。 据我了解,这样做是为了应对负载激增。 我们将回到这一点。max_user_connections相反,这是从一个用户到所有数据库的连接限制,即 如果您有多个数据库并且它们属于同一用户,则相关。max_client_conn -PgBouncer总共接受多少个客户端连接。 像往常一样,默认值有一个非常奇怪的含义-100。也就是说, 假设如果有超过100个客户端突然崩溃,那么它们只需要在TCP级别进行静默reset并reset (好吧,在日志中,我必须承认,这将是“不允许更多连接(max_client_conn)”)。
例如,可能值得将max_client_conn >> SUM ( pool_size' )十倍。
除了SHOW POOLS服务伪基pgbouncer还提供了SHOW DATABASES ,该SHOW DATABASES显示了实际应用于特定池的限制:

服务器连接
再次-如何测量使用了多少种化合物?
在平均/高峰/时间开玩笑吗?
在实践中,使用广泛的工具监视保镖的池使用情况非常困难,因为 pgbouncer本身仅提供瞬时图像,并且由于通常不进行调查,因此仍然存在由于采样而产生错误图像的可能性。 这是一个真实的示例,根据出口商的工作时间(在分钟的开始或结束时),已打开和已使用的化合物的外观都发生根本变化:
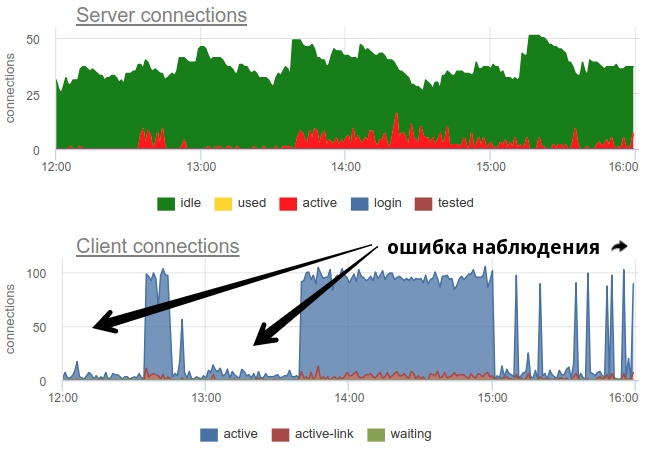
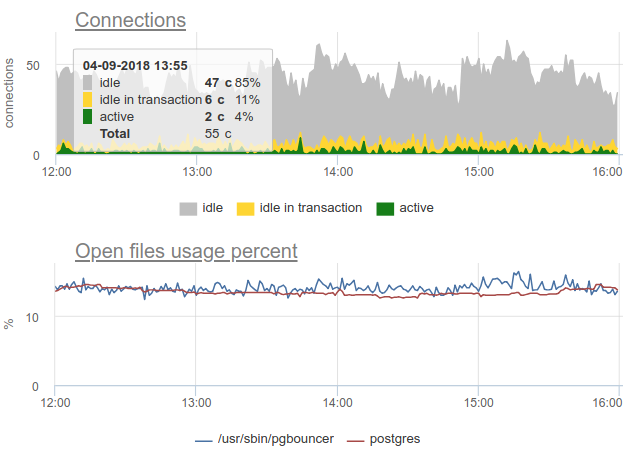
在这里,连接的负载/使用中的所有更改都只是一个虚构,是重新启动统计信息收集器的产物。 在这里,您可以在此期间查看Postgres中的连接图以及保镖和PG的文件描述符-不变:
回到处置问题。 我们决定在服务中使用一种组合方法-我们每秒对SHOW POOLS一次采样,每分钟一次,我们分别渲染每个类中的平均和最大连接数:
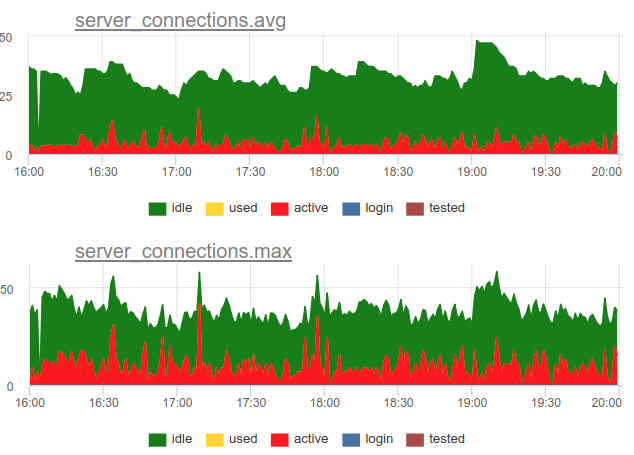
并且,如果将这些活动状态连接的数量除以池的大小,我们将获得该池的平均利用率和峰值利用率,并可以警告它是否接近100%。
另外,PgBouncer有一个SHOW STATS命令,它将显示每个代理数据库的使用情况统计信息:

我们最感兴趣的是total_query_time列-在postgres中执行查询的过程中所有连接所花费的时间。 从版本1.8开始,还有指标total_xact_time交易花费的时间。 基于这些指标,我们可以建立服务器连接时间的利用率;与根据连接状态计算得出的指标相比,该指标不受抽样问题的影响,因为 这些total_..._time计数器是累积的,不传递任何内容:

比较一下
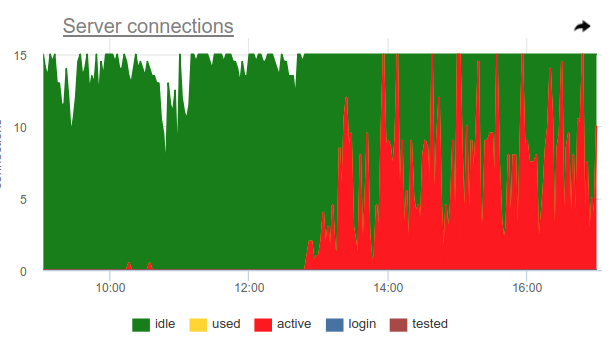
可以看出,采样并未显示出利用率高至100%的所有时刻,而query_time显示了。
饱和度和PgBouncer
为什么要监视饱和度,因为利用率很高,所以很显然一切都不好了?
问题是,无论如何衡量利用率,即使累积的计数器仅在很短的时间间隔内发生,也无法显示本地100%的资源利用率。 例如,您拥有任何王冠或其他同步进程,可以同时从该命令开始对数据库进行查询。 如果这些请求很短,那么以分钟甚至几秒为单位的利用率可能会很低,但是与此同时,在某些时候,这些请求被迫排队等待执行。 这与CPU使用率不是100%且平均负载很高的情况类似-就像处理器时间仍然存在,但是许多进程正在排队等待执行。
如何监视这种情况-很好,再次,我们可以根据SHOW POOLS简单地计数处于cl_waiting状态的客户端数量。 在正常情况下,为零,大于零意味着此池溢出:
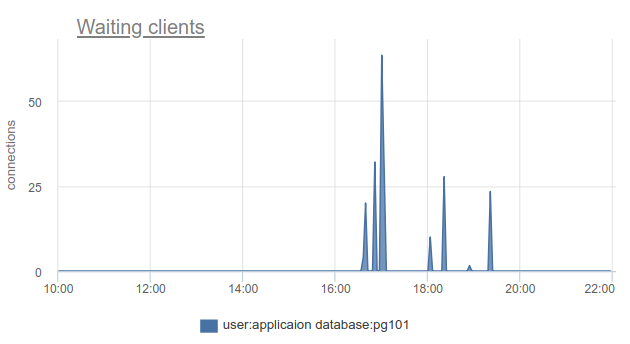
仍然存在只能对SHOW POOLS进行采样的问题,并且在具有同步表冠或类似情况的情况下,我们可以简单地跳过而不看到这样的等待客户端。
您可以使用此技巧,pgbouncer本身可以检测到100%使用该池并打开备份池。 这有两个设置负责: reserve_pool_size (如我所说的大小)和reserve_pool_timeout一些客户端在使用备份池之前应waiting多少秒。 因此,如果我们在服务器连接图上看到打开给Postgres的连接数大于pool_size,则表明池已饱和,如下所示:

显然,每小时收费一次之类的请求很多,并且完全占用了池中的资源。 即使我们看不到active连接超过pool_size限制的那一刻,仍然pgbouncer被迫打开其他连接。
同样在此图上, server_idle_timeout设置的工作情况清晰可见-在停止保持并关闭未使用的连接量之后。 默认情况下,这是10分钟,我们在图表上看到-在5:00、6:00等处的active峰值之后。 (根据cron 0 * * * * ),连接将idle + idle 10分钟并关闭。
如果您生活在进步的最前沿,并且在过去9个月中更新了PgBouncer,则可以在SHOW STATS列中找到total_wait_time ,它最能显示饱和度,因为 累积考虑客户在waiting状态下花费的时间。 例如,在这里- waiting出现在16:30:
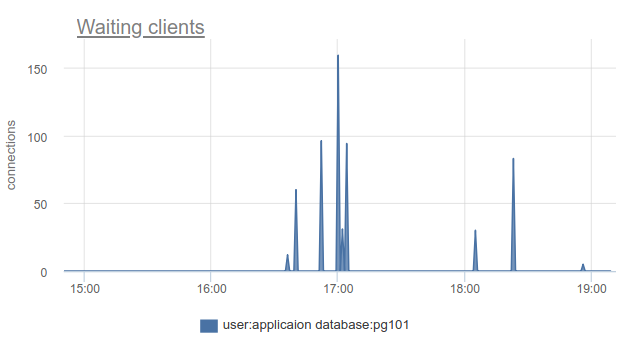
从15:15到将近19:

尽管如此,监视客户端连接的状态仍然非常有用,因为 它不仅使您能够发现与该数据库的所有连接都已用光并且客户端必须等待的事实,而且还因为用户将SHOW POOLS划分为单独的池,而SHOW STATS却没有,还可以找出使用了所有连接的客户端到指定的基数-根据相应池的sv_active列。 或按公制
sum_by(user, database, metric(name="pgbouncer.clients.count", state="active-link")):
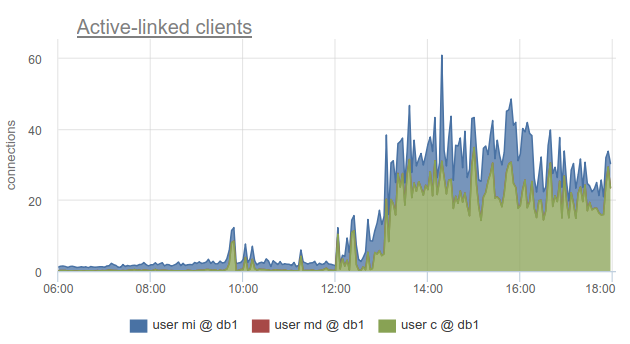
我们在okmeter上走得更远,并添加了打开和使用它们的客户端IP地址所使用的连接的细目分类。 这使您可以准确了解哪些应用程序实例的行为有所不同:

在这里,我们看到了需要处理的特定炉膛kubernetes的IP。
失误
这里没有什么特别棘手的问题:pgbouncer写入日志,如果达到客户端连接的限制,连接到服务器的超时等,它会报告错误。 我们尚未到达pgbouncer日志:(
RED for PgBouncer
尽管USE更侧重于性能,但在瓶颈的意义上,RED在我看来主要是关于传入和传出流量的特征,而不是瓶颈。 就是说,RED回答了这个问题-一切正常吗,如果没有,那么USE将有助于理解问题所在。
要求条件
对于SQL数据库以及此类数据库中的代理/连接拉程序,一切似乎都很简单-客户端执行SQL语句(即请求)。 从SHOW STATS我们获取total_requests并绘制其时间导数
rate(metric(name="pgbouncer.total_requests", database: "*"))

但是实际上,拉动有不同的方式,最常见的是交易。 此模式的工作单位是事务,而不是查询。 因此,从版本1.8开始,Pgbouner已经提供了另外两个统计信息total_query_count ,而不是total_requests和total_xact_count已完成的事务数。
现在,不仅可以根据已完成的请求/事务的数量来表征工作负载,而且例如,您可以查看不同数据库中每个事务的平均请求数量,一分为二
rate(metric(name="total_requests", database="*")) / rate(metric(name="total_xact", database="*"))

在这里,我们看到了负载配置文件中的明显变化,这可能是性能变化的原因。 而且,如果仅查看事务或请求的速率,则可能看不到这一点。
RED错误
显然,RED和USE在错误监视上相交,但是在我看来,USE中的错误主要是由于100%的利用率导致的请求处理错误,即 当服务拒绝接受更多工作时。 RED的错误会更好地从客户端,客户端请求的角度精确地测量错误。 也就是说,不仅在PgBouncer中的池已满或其他限制已起作用的情况下,而且在请求超时(例如“由于语句超时而取消语句”),客户端的取消和回滚已起作用等情况下,也是如此。 e。 更高级别,更接近业务逻辑类型的错误。
持续时间
再次使用累积计数器total_xact_time , total_query_time和total_wait_time SHOW STATS将对我们有帮助,将它们分别除以请求和事务的数量,可以得到平均请求时间,平均事务时间,平均每个事务的平均等待时间。 我已经显示了关于第一个和第三个的图形:
你还能得到什么? 与数据库和Postgres一起使用的众所周知的反模式,特别是当应用程序打开事务,发出请求,然后启动(长时间)以处理其结果时,甚至更糟-转到其他服务/数据库并在那里发出请求。 一直以来,事务在“ postgres”打开中“挂起”,然后服务返回并发出更多请求,在数据库中进行更新,然后才关闭事务。 对于postgres来说,这尤其令人不快,因为 pg工人很昂贵。 因此,我们可以在pg_stat_activity的state列中监视此类应用程序何时在postgres自身的idle in transaction中idle in transaction state ,但是在采样方面仍然存在上述相同的问题,因为 pg_stat_activity只给出当前图片。 在PgBouncer中,我们可以从事务处理中所花费的时间total_query_time减去客户端在total_query_time请求中所花费的时间-这就是这种空闲时间。 如果结果仍然除以total_xact_time ,则将其标准化:值1对应于这样的情况,即客户100%的时间idle in transaction中idle in transaction 。 通过这种归一化,可以很容易地理解所有内容的严重程度:
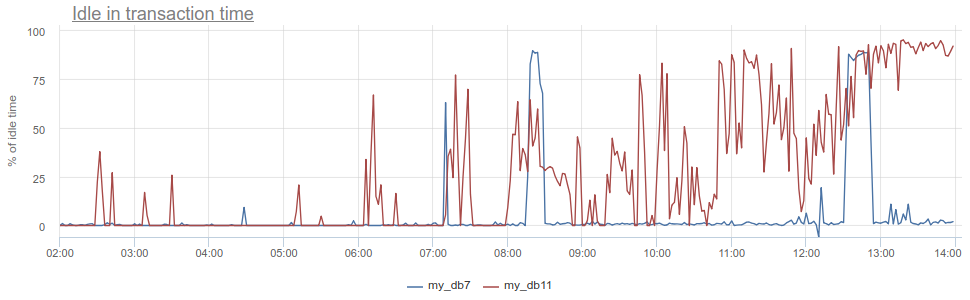
此外,返回到“持续时间”,可以将指标total_xact_time - total_query_time除以事务数量,以查看每个事务平均空闲应用程序有多少。
我认为,USE / RED方法对于结构化您拍摄的指标和原因最有用。 由于我们从事全职监控,因此我们必须对各种基础架构组件进行监控,因此这些方法可帮助我们采用正确的指标,为客户制定正确的时间表和触发器。
不能立即进行良好的监视;这是一个反复的过程。 在okmeter.io中,我们仅进行连续监视(有很多东西,但是明天它将更好,更详细:)