
我叫Yuri Nevinitsin,我从事OK内部统计系统的工作。 我想谈一谈我们如何将一个50 TB的实时分析系统从Microsoft SQL转移到一个名为Druid的列基础上,该系统每天记录数十亿个事件。 同时,您将学习一些使用
Druid的食谱。
为什么我们需要统计?
我们想了解有关我们站点的所有信息,因此我们不仅记录磁盘,处理器等的行为,而且记录每个用户操作,子系统之间的每个交互以及几乎我们所有系统的所有内部进程。 统计系统紧密集成到开发过程中。
基于统计系统中的数据,我们的经理为团队设定目标,跟踪其成就和关键指标。 管理员和开发人员监视所有系统的运行,调查事件和异常情况。 自动监视会不断监视,并在早期发现问题,并做出超出限制的预测。 而且,功能和实验会不断启动,进行更新和更改。 并且我们通过统计系统监视所有这些动作的效果。 如果她拒绝,我们将无法对该站点进行更改。
我们的统计数据主要以图表的形式呈现。 通常,该图表一次显示几天,因此动态情况清晰明了。 这是我对德鲁伊进行实验的示例。 这是数据加载的图表(行/ 5分钟)。
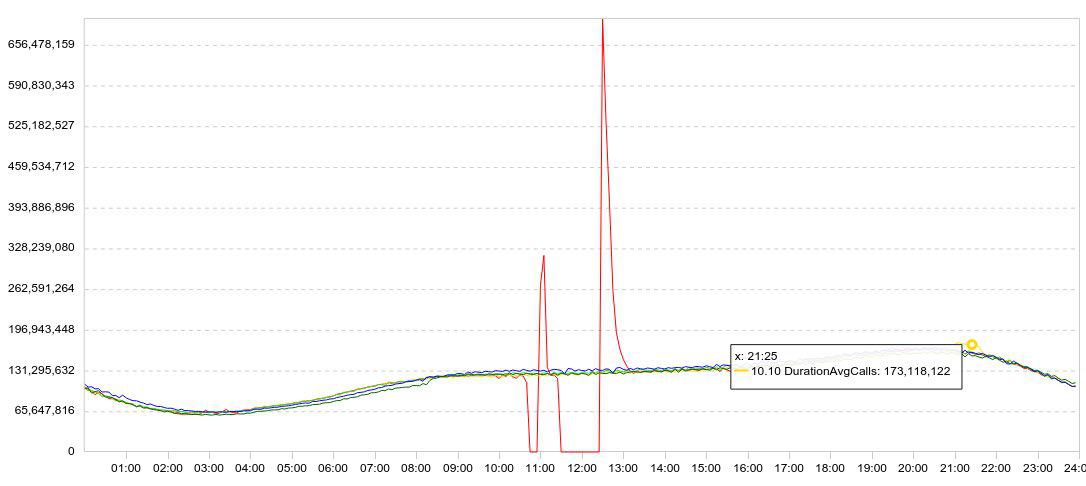
我放慢了下载速度(红色图表崩溃为零),等待了一会儿,重新开始下载,并观察了德鲁伊能够以多快的速度加载累积的数据(失败后达到峰值)。
可以使用任何参数扩展任何计划,例如,主机,表,操作等。 我们还有具有年度动态的长期图表。 例如,下面是德鲁伊中条目数量每日增加的图表。
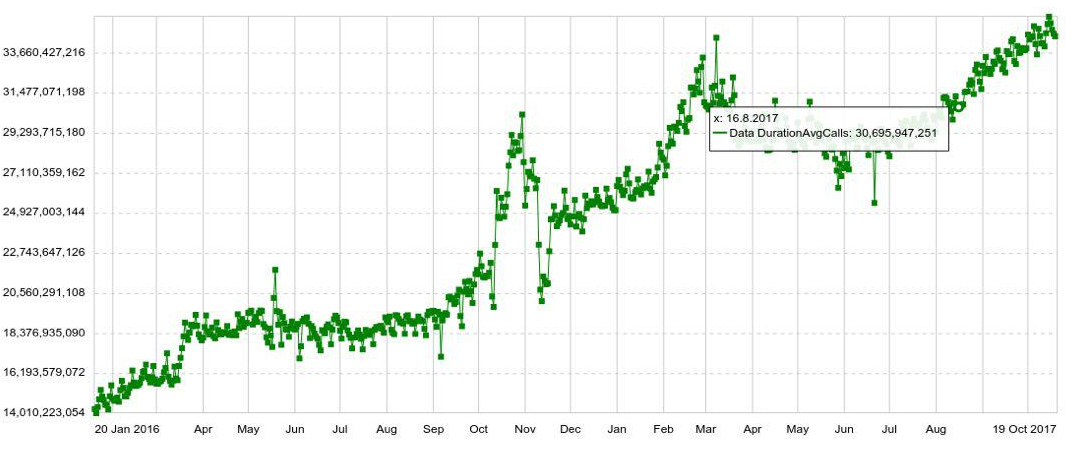
我们还可以在单独的面板(仪表盘)上组合多个图表,这非常方便。 即使用户只需要查看几百个图形,他仍然不能单独打开它们,而是在面板中打开它们,这增加了系统的负担。
问题
尽管数据量很小,但我们很好地处理了SQL。 但是,随着数据量的增长,图表输出会变慢。 最终,高峰时段的统计数据开始滞后半个小时,一张图表的平均响应时间达到了6秒。 也就是说,某人在2秒内收到了时间表,某人在10-20分钟内收到了时间表,而一分钟又收到了时间表。 (您可以在
此处阅读有关SQL系统开发的
信息 )
在调查异常或事件时,通常需要打开并查看十几个图形,每个图形都遵循前一个图形,因此无法同时打开它们。 我不得不等待10次10-20秒。 真烦人。
迁移
您仍然可以从系统中挤出一些东西,添加服务器...但是大约与此同时,Microsoft更改了其许可政策。 如果我们继续使用SQL Server,我们将不得不捐出数百万美元。 因此,他们决定迁移。
要求如下:
- 统计信息不应滞后(超过2分钟)。
- 该图表应在不超过2秒的时间内打开。
- 整个面板的打开时间不得超过10秒。
- 该系统必须具有容错能力,能够承受数据中心丢失的影响。
- 该系统必须易于扩展。
- 该系统应该易于修改,因此我们希望它使用Java。
所有这些仅由德鲁伊提供给我们。 它还具有初步聚合,可以使您节省更多的空间,并在数据插入期间建立索引。 Druid支持我们的统计信息所需的所有类型的查询。 因此,似乎我们可以轻松地用Druid代替SQL Server。
当然,我们不仅考虑德鲁伊作为此举候选人的角色。 我的第一个想法是用PostgreSQL取代Microsoft SQL Server。 但是,这只能解决财务成本问题,而无助于可访问性和扩展性。
我们还分析了Influx,但事实证明负责高可用性和可伸缩性的部分已关闭。 普罗米修斯在充分考虑到其性能的情况下,对其监控进行了更好的调整,因此无法吹嘘高可用性或简单的可伸缩性。 OpenTSDB也更适合于监视,它没有所有字段的索引。 我们之所以不考虑Click House,是因为那时它还不存在。
放德鲁伊。 迁移了TB的数据。 从SQL Server切换到Druid之后,图形视图的数量立即增加了5倍。 然后他们开始运行“大量”统计信息,他们担心这些统计信息会更早运行,因为 SQL几乎不会处理它。
现在,来自12个节点(40个内核,196 GB RAM)的Druid每高峰时间每秒要处理500,000个事件,同时还有很大的安全余量(MAX列:CPU余量的几乎五倍)。
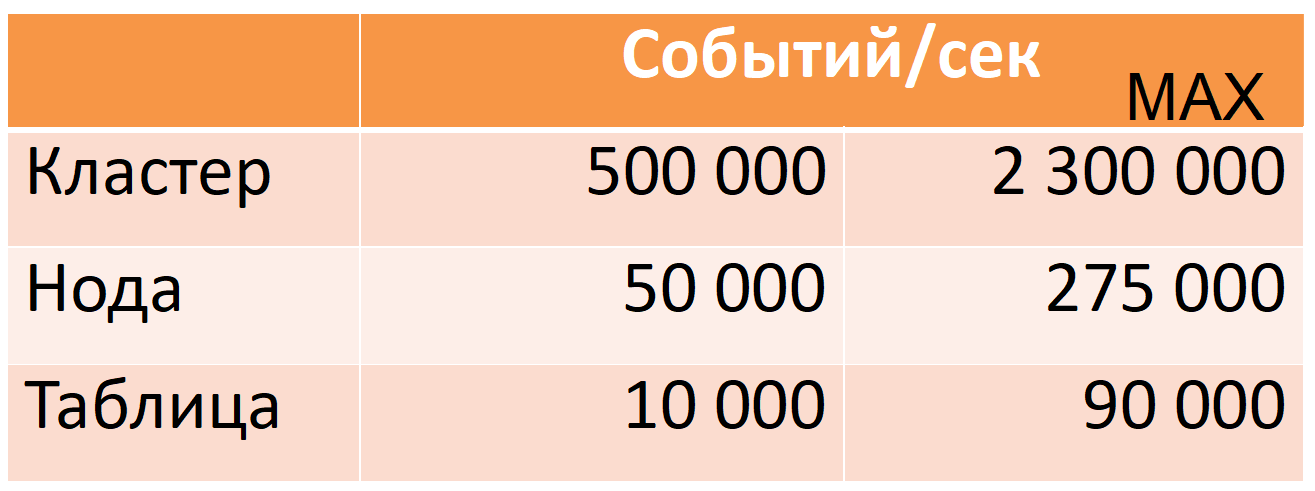
这些数字基于生产数据。 我将告诉您我们是如何实现这一目标的,但首先,我将更详细地介绍Druid。
德鲁伊
这是一个分布式列时间序列OLAP系统。 它的文档没有包含表(数据源)或字符串(事件)的SQL世界的常用概念,但是为了便于描述,我将使用它们。
德鲁伊基于几种数据假设(局限性):
- 每条数据线都有一个单调增长的时间戳(默认在10分钟的窗口内)。
- 数据不变,仅插入(不更新操作)。
这使您可以将数据分割为所谓的时间段。 段是在一定时间段内一个表的最小不可分割且不变的“分区”。 所有数据操作,所有查询均逐段执行。
每个段都是自给自足的:除了以柱状形式编写的主表外,它还包含执行查询所需的目录和索引。 我们可以说一个段是一个小的列只读数据库(下面将对段设备进行更详细的描述)。
反过来,这导致“分布式”:将大量数据划分为小段以便并行执行计算的能力(在一台机器上同时在许多机器上)。
如果您需要“升级”至少一行,则必须重新加载整个段。 这是可能的,一切都为此做好了准备。 每个段都有一个版本,而具有较新版本的段将自动用旧版本取代该段(但是,如果需要定期进行更新,则值得重新评估Druid是否适合此用例)。
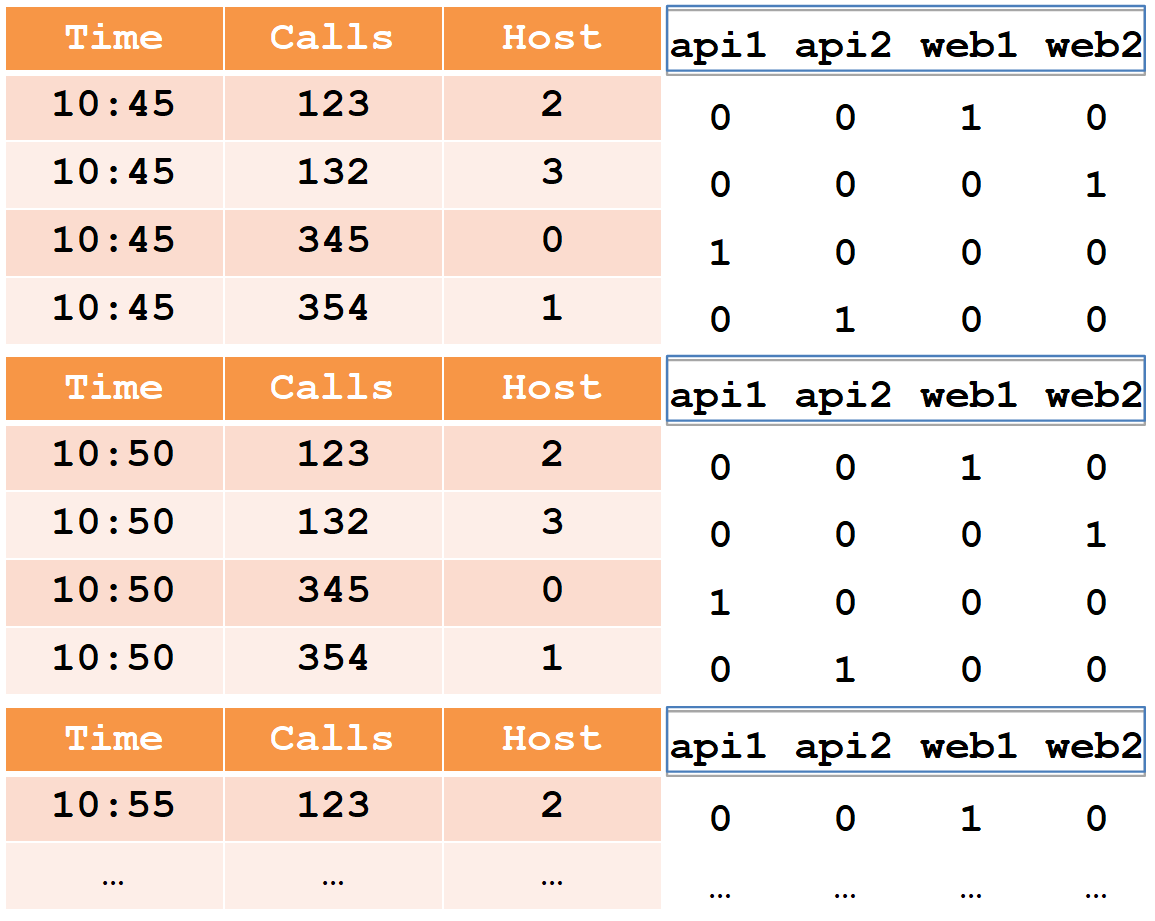
为了描述设备部分,我们考虑一个常用表格形式的简单示例:
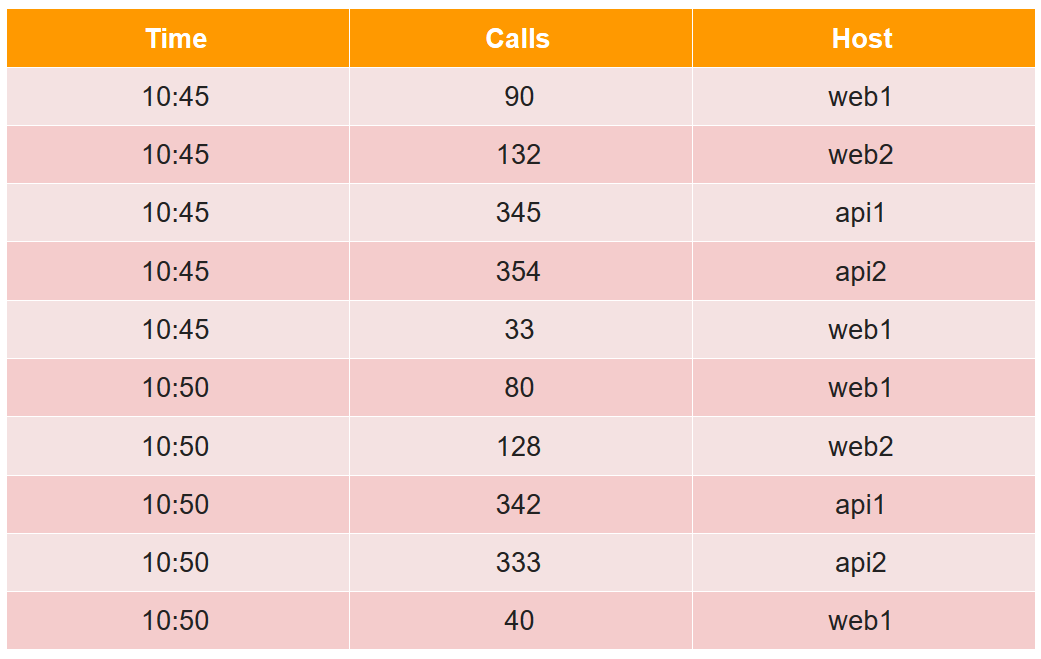
在此表中,四个主机之间在两个五分钟内的呼叫数(请注意,对于web1主机,每个五分钟内有两条线路)。
从德鲁伊的角度来看,所有数据单元都分为三种类型:
- timestamp-UTC时间戳(以毫秒为单位)(在示例中为Time)。
- 指标是您需要计算的值(总和,最小值,最大值,计数等),并且您需要提前了解每个表格的信息(在示例中,这是“通话次数”,我们将计算总和)。
- 尺寸-这是您可以分组和过滤的内容(您无需事先知道它们,可以随时更改)(在示例中,这是主机)。
插入时,所有行都按完整的维度集+时间戳进行分组,如果它们与每个指标匹配,则将应用“其”聚合功能(因此,没有行具有相同的维度集+时间戳)。 因此,插入德鲁伊后的示例如下所示:

时间戳记和所有指标(在我们的示例中为“时间和通话次数”)将被写入为long型数字数组(也支持float和double)。 对于每个维度(在我们的示例中为Host),将创建一个词典-一组排序的字符串(带有主机名)。 主机列本身将被写为一个int数组,指示字典中的数字。
请注意,在插入到德鲁伊后,将对具有相同时间戳的web1主机的多行进行汇总,并且总行数记录在调用中(无法从德鲁伊中提取初始数据)。
快速数据过滤需要索引,因为可以有数百万行和数千个主机。 索引是位图,字典中的每一行一个。

单位表示此主机参与的行号。 要过滤两个主机,您需要获取两个位图,通过“或”对其进行组合,然后以结果位图为单位选择行号。
德鲁伊由许多组成部分组成。
首先,它具有几个外部依赖性。

- 贮藏 在那里,Druid只是以压缩形式存储这些段。 它可以是本地目录,HDFS,Amazon S3。 此处仅使用空间,不执行任何计算。
- Meta:用于Meta信息的数据库。 该数据库存储完整的数据图:哪些段是相关的,哪些段已过期,哪些路径在存储中。
- 该系统使用ZooKeeper进行发现,并宣布可在哪些德鲁伊节点上查询哪些段。
- 已执行请求的缓存,可以是memcached或Java堆中的本地缓存。
其次,德鲁伊本身包含几种类型的组件。
- 实时节点按接收顺序加载新数据流,并为其请求服务。
- 历史节点包含全部数据并为其提供服务。 当我们说我们有一个300 TB的集群时,我们指的是历史节点。
- 经纪人负责在历史节点和实时节点之间分配计算。
- 协调器负责在历史节点之间分配段并进行复制。
- 索引服务,使您可以批量(重新)加载数据,例如,“升级”部分数据。
数据流
 粗体箭头指示数据流,细箭头指示元数据流。
粗体箭头指示数据流,细箭头指示元数据流。实时节点按时间(例如,按天)获取数据,索引并切成段。
实时节点的每个新段都将写入存储,并保留一个副本来满足对其的请求。 然后,它记录这样的元数据,即新段已沿着这样的路径出现在存储库中。
该信息由协调器接收,定期重新读取元数据库。 当他找到一个新的段时,(通过ZooKeeper)命令几个历史节点下载该段。 他们下载并(通过ZooKeeper)宣布拥有一个新细分。 当实时节点(通过ZooKeeper)接收到此消息时,它将删除其副本以为新数据腾出空间。
要求处理

三种类型的节点参与请求处理:代理,实时和历史。 请求到达代理,该代理知道哪些段位于哪个节点上。 它通过存储所需段的历史(实时)节点分发请求。 历史节点还尽可能并行化计算,将结果发送给代理,然后代理将结果提供给客户端。 通过将该方案与列数据存储相结合,Druid可以非常快速地处理大量信息。
高可用性
您还记得,依赖项列表中的Druid具有元数据基础,元数据可以是MySQL或PostgreSQL。 还提到了Apache Derby,但该产品不能用于生产,只能用于开发(据我了解,derby以嵌入式形式使用,以免在处女环境中引发mysql / pgsql)。
如果此基础失败(和/或存储和/或协调器),将会发生什么? 实时节点无法写入元数据(和/或段)。 这样,协调器将无法重新读取它们,也将找不到新的段。 历史节点将不会下载它,实时节点不会删除其副本,但会继续下载最新数据。 结果,数据将开始在实时节点中累积。 这不能无限期地进行下去。 但是,已知实时节点上有哪些资源可用,以及我们拥有什么样的数据流。 因此,我们有可预测的时间来修复故障的基础(和/或存储和/或协调器)。
由于受支持的mysql / pgsql不能保证开箱即用的高可用性,因此我们决定安全使用它并使用基于Cassandra的我们自己的(现成的)解决方案,因为开箱即用的解决方案提供了高可用性(您可以
在此处阅读更多内容)。
此外,我们最终确定了实时节点,以免累积过多的数据,删除最旧的数据,从而为新数据腾出空间。 这对我们来说非常重要,因为这种情况导致我们无法长时间提高失败的基准(和/或存储和/或协调器)并且积累大量数据,这很可能是大事故的结果。 目前,最新数据至关重要。
德鲁伊与动物园管理员
有了ZooKeeper,一切都会变得越来越糟。 更好,因为ZooKeeper本身是容错的,它具有开箱即用的复制功能。 看来可能会发生?
一般而言,本章不再相关。 这不是一个成功的故事,(我们和新鲜的德鲁伊)决定从根本上从ZooKeeper删除几乎所有数据,现在德鲁伊节点直接通过HTTP相互请求,这是一个痛苦。
ZooKeeper有两种类型的超时。 连接超时是一个简单的网络超时,此后客户端重新连接到ZooKeeper并尝试恢复其会话。 并且会话超时,此后会话将被删除,并且在该会话中创建的所有
临时数据也将被删除(由ZooKeeper本人),这将通知所有其他ZooKeeper客户端。
基于此,在德鲁伊中的发现有效:在启动时,每个节点都会在ZooKeeper中创建一个新会话并记录有关其自身的
短暂数据:主机:端口,节点类型(代理/实时/历史/ ...),连接时间戳等。 ...其他德鲁伊节点从ZooKeeper接收通知并读取此数据,因此他们了解到新的德鲁伊节点已上升以及它是哪种节点。 如果任何druid节点在其会话超时后掉落,则ZooKeeper将删除有关其的数据,其他druid节点将知道该数据。 为了让他们更快地了解它,我们宁愿设置一个小的会话超时时间。
当实时或历史节点上升时,它除了关于自身的数据外,还向ZooKeeper写入其拥有的段列表(这也是
临时数据)。 在此过程中,实时节点和历史节点上的线段将被创建为新的,旧的段将被删除,并且每个节点都在ZooKeeper的列表中反映出这一点。 该列表可能很大,因此将其分为几部分,因此不会覆盖整个列表,而只会覆盖已修改的部分。
经纪人反过来,当他看到一个新的实时或历史节点时,也会从ZooKeeper中减去其分段列表,以便将请求分发到该节点。 实时节点读取此列表以删除其在历史节点上出现的段的副本。 由于列表分为几部分,并且被部分覆盖,因此ZooKeeper会告诉您哪个部分已更改,只有它会被重新读取。
正如我所说,此列表可能很长。 当ZooKeeper中有很多数据时,事实证明它不再那么稳定。 在我们的案例中,当段数达到约700万时,明显的问题开始了,ZooKeeper快照随后占用了6GB。
如果德鲁伊节点失去与ZooKeeper的联系会怎样?
Druid与ZooKeeper的合作方式是,在会话超时的情况下,每个节点都将创建一个新会话,并将其所有数据写入那里,然后重新读取其他节点的数据。 由于存在大量数据,因此ZooKeeper上的流量开始增加。 这可能导致druid的其他节点超时,然后它们也开始重写和重新读取。 因此,流量像雪崩般增长,直到ZooKeeper失去实例之间的同步并开始来回驱动快照。
用户此时会看到什么?
当代理与ZooKeeper失去联系(并且发生会话超时)时,它不再知道历史节点位于哪些段上。 并给出空答案。 也就是说,如果ZooKeeper处于关闭状态,则Druid无法正常工作。 完全不可能“治愈”它,但是有可能在某些地方散布秸秆。
首先,您可以从ZooKeeper中删除数据。 如果他们迷路了也没关系:德鲁伊只会覆盖它们。 如果ZooKeeper的问题已经开始,那么为了最快的解决方案,建议禁用ZooKeeper,删除数据并将其清空,而不要等待其自行解决。
现在,我们正在增加会话超时。 在这种情况下会发生什么?
假设历史节点未正确重启,并且没有从ZooKeeper中删除旧会话,而是在创建新会话并在其中写入大量数据时。 当旧的会话仍然存在并且超时没有过去时,两个数据副本存储在ZooKeeper中。 如果有许多这样的节点立即重新启动,那么将复制大量数据。 因此,您需要为ZooKeeper保留内存,以使其不会用完并且ZooKeeper不会停止工作。 为什么不能删除旧会话的数据?
出于同样的原因,有必要正确完成历史节点的操作,因为这时历史节点会从ZooKeeper中删除其数据,并且可以长时间这样做。 历史节点的完成大约需要半小时。
历史节点还有一个功能。 当他们开始时,他们会查看存储在其上的段,然后将有关此段的信息写入ZooKeeper。 并且由于数据或多或少均匀地分布在历史节点上,因此,如果您同时运行它们,则它们将在大约同一时间开始写入ZooKeeper。 这再次增加了像波浪一样的流量增长和超时的可能性。 因此,您需要顺序运行历史节点,以便及时传播ZooKeeper中的记录会话。
我们还进行了另外两个优化:
- 我们对ZooKeeper进行了一些重新编程,以便仅从Druid中读取需要它们的那些节点。并且只有实时,代理和协调器才需要它们,而历史节点则不需要。他们不需要知道哪些其他历史节点具有段。同样,对于索引服务及其工作人员(可能很多)而言,所有这些都不是必需的。
- 他们从写入ZooKeeper的数据中删除了所有多余的内容,只保留了满足请求所需的内容。这将ZooKeeper中的数据量从6 GB减少到2 GB(这是快照的大小)。
结果,流量的急剧增长减少了大约8倍;因此,我们将风扇超时的可能性降到了最低。上传到德鲁伊
 在加载实时数据的过程中,节点通过将部分数据刷新到磁盘来定期释放内存。从技术上讲,这些部分是微型段(每个部分都有一个表,目录,索引)。为了基于此数据处理请求,将使用MMAP(以及完整段)将其上拉。到装入此类零件的一部分结束时,已经积累了很多东西。有两点与此有关。首先,实时节点不仅在JVM崩溃或服务器意外重启期间,甚至在正确的重启期间,都可能破坏数据。
在加载实时数据的过程中,节点通过将部分数据刷新到磁盘来定期释放内存。从技术上讲,这些部分是微型段(每个部分都有一个表,目录,索引)。为了基于此数据处理请求,将使用MMAP(以及完整段)将其上拉。到装入此类零件的一部分结束时,已经积累了很多东西。有两点与此有关。首先,实时节点不仅在JVM崩溃或服务器意外重启期间,甚至在正确的重启期间,都可能破坏数据。 这就是为什么发生这种情况。将数据刷新到磁盘的过程包括两个部分:1)直接刷新数据; 2)在重新启动后保持从其开始的位置。这两种类型的数据是完全独立记录的,它们彼此之间一无所知。而且,当然不是原子的。根据丢失的确切程度,我们可能会丢失数据或发生重复。 (目前,在原始的德鲁伊中,它正在积极修复,但尚未修复)。如果您不使用实时节点并使用索引服务加载数据或不成对使用它们,则可以解决此问题,因为索引服务根本不保存位置,它将加载整个段或丢弃其未能加载的内容(出于任何原因)。
这就是为什么发生这种情况。将数据刷新到磁盘的过程包括两个部分:1)直接刷新数据; 2)在重新启动后保持从其开始的位置。这两种类型的数据是完全独立记录的,它们彼此之间一无所知。而且,当然不是原子的。根据丢失的确切程度,我们可能会丢失数据或发生重复。 (目前,在原始的德鲁伊中,它正在积极修复,但尚未修复)。如果您不使用实时节点并使用索引服务加载数据或不成对使用它们,则可以解决此问题,因为索引服务根本不保存位置,它将加载整个段或丢弃其未能加载的内容(出于任何原因)。, . , , .
, Druid . , , , .
, . , (web%, api%).
- Druid — . .
- , .
- Druid , , : , , , .
- Druid , , calls.
, 5 % , 95 % — .
, , realtime- .
, ( 10:45) . - , -. , ( 10:50) , -. 依此类推。 , , «calls», «time» «host» .
-. , «» . , , . ( 95% ) , : , . 100 , 1000.
? , . , realtime , . (.. historical realtime-), .
, : . , , . 100 . , . .
还有一个重点。有时,花费在过滤上的时间中有80%花费字典来通过正则表达式而不是组合位图。我们对此一无所知,在迁移过程中,所有过滤器都被制成了正则表达式。这不是必需的。当我们按确切值过滤时,我们应该使用选择器类型的过滤器,因为它将通过二进制搜索找到所需的值并立即获得位图。这比正则表达式快一千倍。碳带优化
如您所知,在任何社交网络中都有一个事件提要,该事件提要收集所有开发团队创建的内容。当然,所有这些团队都希望观察和编写统计信息。我们将磁带统计信息写在一个板上,每天80亿行。她甚至在德鲁伊中都刹车了。最糟糕的是,当放慢速度时,它会使整个德鲁伊超载,也就是说,所有人的一切都放慢了速度。在这些统计数据中,存在一个组合字段,该字段由通过点连接的几个单词组成。这样的事情: 我们可以在主相册中,在相册中,在小组中欣赏照片。视频和音乐也是如此。我们还可以在主页,相册和群组中共享照片,视频和音乐。我们可以评论所有内容。总共27个事件组合。因此,该词典将具有27行,27个位图。我们要计算有多少个赞。该查询将在字典中通过27个值的正则表达式,选择其中9个,获得9个位图,合并并计数。现在,将其分为三个部分。
我们可以在主相册中,在相册中,在小组中欣赏照片。视频和音乐也是如此。我们还可以在主页,相册和群组中共享照片,视频和音乐。我们可以评论所有内容。总共27个事件组合。因此,该词典将具有27行,27个位图。我们要计算有多少个赞。该查询将在字典中通过27个值的正则表达式,选择其中9个,获得9个位图,合并并计数。现在,将其分为三个部分。 首先是行动:喜欢,分享,发表评论。第二部分是一个对象:照片,视频,音乐。第三部分是位置:在主要部分中,在专辑中,在组中。然后,查询将只进入一个字典-一个动作,其中只有三个值和三个位图。为了实验的纯度,假设这也是一个正则表达式。也就是说,在这种情况下,将有三个正则表达式,而在前一个中有27个。有9个位图,现在有1个。结果,我们将字典遍历和位图组合(花费了95%的时间)减少了9倍。我们只将27行的字典切成三行。实际上,我们有1.4万种组合。因此,我们的字典中有14000个值和14000个位图。结果,当我们根据单词将该字段切成小块时,磁带统计的速度提高了10倍,数据大小减半。现在一切正常。
首先是行动:喜欢,分享,发表评论。第二部分是一个对象:照片,视频,音乐。第三部分是位置:在主要部分中,在专辑中,在组中。然后,查询将只进入一个字典-一个动作,其中只有三个值和三个位图。为了实验的纯度,假设这也是一个正则表达式。也就是说,在这种情况下,将有三个正则表达式,而在前一个中有27个。有9个位图,现在有1个。结果,我们将字典遍历和位图组合(花费了95%的时间)减少了9倍。我们只将27行的字典切成三行。实际上,我们有1.4万种组合。因此,我们的字典中有14000个值和14000个位图。结果,当我们根据单词将该字段切成小块时,磁带统计的速度提高了10倍,数据大小减半。现在一切正常。请求优先级
但是用户来了,想查看一年的统计数据,这是2 TB。在我们的群集上,您需要从磁盘上增加11 GB,这将花费74秒。用户知道他正在请求大量数据并准备等待。但是其他用户将在这74秒内做什么?简单地说,他们会紧张,问为什么图形不起作用。德鲁伊使您可以优先处理请求。我们尝试降低大数据的优先级,这变得很容易,但是它仍然放慢了速度,因为优先级在队列级别上起作用。这意味着,如果繁重的请求的一部分已经处理完毕,那么每个人都必须等待。然后,轻量级的快速请求向前跳转,重度级的请求再次占用所有资源。感觉系统正在努力工作,达到了极限。我们利用了Druid具有有关请求和数据的所有信息这一事实。他们实现了一个简单的优先级划分,它为该请求将要传递的数据数(以兆字节为单位)设置了优先级。同时,我们制作了5个队列:一个用于最困难的请求,一个用于最轻的请求,三个用于中间。他们分散了对计算出的优先级的要求。每个队列在操作系统级别都有优先级(通过标准方式和java设置来设置),因此快速请求排挤了繁重的请求。现在,终于,德鲁伊获得了您所期望的收益。总结
, , SQL Server, Microsoft.
, / .
, , .
20 , , 18 .
one-cloud (
https://habr.com/company/odnoklassniki/blog/346868/ ), .