哈Ha 我想谈谈解决说话人歧视问题的一种方法,并说明如何在python中实现该方法。 为了不吓the读者,我不会给出复杂的数学公式(部分原因是我本人“不是真正的焊工”),但我将尝试用简单的语言解释所有内容,并以一种从未接触过机器学习的开发人员理解它的方式告诉一切。
在准备撰写本文时,我选择了两个选项:一个是对数据科学已经熟悉的人,另一个是那些编程简单的人。 最后,我选择了第二个选项,认为这将很好地证明DS的功能。
问题陈述
正如Wikipedia
告诉我们的那样,差异化是根据音频流属于一个或另一个扬声器将输入音频流划分为同质片段的过程。 换句话说,记录必须分成几部分并编号:一个人在这些地方讲话,而另一个人在这些地方讲话。 从机器学习的角度来看,这类任务属于没有老师的学习类别,称为聚类。 例如,您可以
在此处或
此处阅读有关存在哪些聚类方法的信息,但是我仅讨论对我们有用的那些方法-这是一种高斯混合模型和频谱聚类。 但是稍后再谈。
让我们从头开始。
环境准备
扰流板我不确定是否要离开本节-我不想将本文变成非常教程。 但是最后我离开了。 不需要它的人会跳过,对于那些从头开始做所有事情的人,此步骤将有助于开始。
一般而言,除了R之外,python是解决数据科学问题的主要语言,如果您尚未尝试对它进行编程,那么我强烈建议您这样做,因为python允许您优雅地在很多行中完成许多事情(顺便说一句,甚至一个模因)。
有两个单独开发的python分支-版本2和版本3。在我的示例中,我使用版本3.6,但如果需要,它们可以轻松移植到版本2.7。 通过安装
Anaconda安装程序可以很方便地部署这些分支中的任何一个,通过安装,您将立即收到一个用于开发的交互式外壳程序-IPython。
除了开发环境本身之外,还需要其他库:librosa(用于处理音频和提取属性),webrtcvad(用于分段)和pickle(用于将经过训练的模型写入文件)。 所有这些都可以通过Anaconda Prompt中的简单命令安装。
pip install [library]
特征提取
让我们从特征的提取开始-机器学习模型将使用的数据。 原则上,声音信号本身已经是数据,即声音振幅值的有序数组,在其中添加了包含通道数量,采样频率和其他信息的标题。 但是我们将无法直接分析这些数据,因为其中不包含此类数据,因此我们的模型可以说出这些数据-是的,这些数据属于同一个人。
在语音处理任务中,有几种提取特征的方法。 其中之一是获得梅尔频率倒谱系数。 他们
已经在这里
写过 ,所以我只会提醒您一下。
原始信号被切成16-40毫秒长的帧。 然后,将
汉明窗应用于帧,他们进行快速傅立叶变换并获得功率谱密度。 然后,通过将特殊的“梳”过滤器“梳”均匀地排列在粉笔刻度上,制作了粉笔频谱图,并对其应用了离散余弦变换(DCT)-一种广泛使用的数据压缩算法。 这样获得的系数是帧的一种压缩特性,并且由于我们使用的过滤器位于
粉笔刻度中,因此这些系数在人耳感知范围内携带更多信息。 通常,每帧使用13至25 MFCC。 由于除了频谱本身之外,语音的个性还由速度和加速度形成,因此MFCC与一阶和二阶导数结合在一起。
通常,MFCC是处理语音的最常见选项,但是除了它们之外,还有其他符号-LPC(线性预测编码)和PLP(感知线性预测),有时您还可以找到LFCC,其中使用粉笔刻度代替线性刻度。
让我们看看如何在python中提取MFCC。
import numpy as np import librosa mfcc=librosa.feature.mfcc(y=y, sr=sr, hop_length=int(hop_seconds*sr), n_fft=int(window_seconds*sr), n_mfcc=n_mfcc) mfcc_delta=librosa.feature.delta(mfcc) mfcc_delta2=librosa.feature.delta(mfcc, order=2) stacked=np.vstack((mfcc, mfcc_delta, mfcc_delta2)) features=stacked.T
如您所见,实际上只需要几行就可以完成。 现在,让我们继续第一个聚类算法。
高斯混合模型
高斯分布混合模型表明,我们的数据是具有特定参数的多维高斯分布的混合。
如果愿意,您可以轻松找到模型的详细说明以及训练该模型的
EM算法的工作原理,但是我保证不会因复杂的公式而烦恼,因此,我将展示本文中的精美示例。
我们将生成四个群集并将其绘制。
from sklearn.datasets.samples_generator import make_blobs X, y_true=make_blobs(n_samples=400, centers=4, cluster_std=0.60, random_state=0) plt.scatter(X[:, 0], X[:, 1]);
我们将创建一个模型,对数据进行训练,然后再次得出要点,但要考虑到群集成员的预测模型。
from sklearn.mixture import GaussianMixture gmm = GaussianMixture(n_components=4) gmm.fit(X) labels=gmm.predict(X) plt.scatter(X[:, 0], X[:, 1], c=labels, s=40, cmap='viridis');
该模型很好地处理了人工数据。 原则上,通过调节混合分量的数量和协方差矩阵的类型(高斯自由度的数量),可以描述相当复杂的数据。

因此,我们知道如何进行数据参数化,并能够训练高斯分布混合模型。 现在可以尝试在额头上进行聚类-在从对话中提取的MFCC上训练GMM。 而且,也许在一些理想的球形-真空对话中,每个讲话者都将适合他的高斯,我们将获得一个很好的结果。 显然,实际上这将永远不会发生。 实际上,在GMM的帮助下,他们没有对对话进行建模,而是对对话中的每个人进行建模-也就是说,他们想象提取出的符号中每个说话人的声音都由其自己的一组高斯描述。
总而言之,我们正在慢慢进入主题。
细分
传统上,区分过程由三个连续的块组成-语音检测(语音活动检测),分段和聚类(有些模型将最后两个步骤组合在一起,请参阅
LIA E-HMM )。
第一步,将语音与各种噪声分开。 VAD算法确定提交给它的音频文件是语音,还是听起来像是警笛声或打喷嚏。 显然,为了使这种算法具有较高的质量,有必要对教师进行培训。 这又意味着您需要标记数据-换句话说,创建一个包含语音和各种噪声记录的数据库。 我们会偷懒地做-用现成的
VAD不能完美运行,但是对于初学者来说我们已经足够了。
第二个块用一个活动的扬声器将语音数据切成段。 在这方面,经典方法是基于贝叶斯信息准则
-BIC的说话人变更确定算法。 这种方法的本质如下:在音频记录中滑动窗口,然后在段落的每个点回答问题:“如何更好地描述此位置的数据-一个或两个分布?” 为了回答这个问题,计算参数
,根据该符号决定更换扬声器。 问题在于,这种方法在说话者频繁更换的情况下,甚至在有噪声的情况下(录制电话对话的特征),都无法很好地发挥作用。
一点解释最初,我处理的是呼叫中心的电话录音,平均录音时间约为4分钟。 由于明显的原因,我无法发布这些笔记,因此,为了进行演示,我从一个广播电台接受
了采访。 在长时间的采访中,此方法可能会得出可接受的结果,但对我的数据无效。
在播音员不互相打扰且声音不重叠的情况下,我们将使用VAD或多或少地应对分段任务,因此前两个步骤将如下所示。
实际上,人们肯定会同时讲话。 此外,由于记录不是实时的,但在某些地方,VAD出现了错误,但是这是减少了暂停的胶合。 您可以尝试重复切成段,将VAD的攻击力从2提高到3。
GMM-UBM
现在我们有单独的细分,我们决定使用GMM为每个说话者建模。 我们从线段中提取符号,并根据此数据训练模型。 让我们在每个细分上进行比较,并将生成的模型彼此进行比较。 有理由期望在属于同一个人的网段上训练的模型会有些相似。 但是,这里我们面临以下问题,从一个1秒长的音频文件中提取符号(采样频率为8000 Hz,窗口大小为10 ms),我们得到了800个MFCC向量集。 我们的模型将无法学习,因为它可以忽略不计。 即使不是一秒,而是十秒,数据仍然不够用。 通用背景模型(UBM)可以解决这个问题,也称为独立于说话者。 这个想法如下。 我们将在大量数据样本上训练GMM(在我们的情况下,这是完整的采访记录),我们将获得广义说话者的声学模型(这将是我们的UBM)。 然后,使用特殊的自适应算法(如下所述),我们可以将该模型“拟合”到从每个片段中提取的特征中。 这种方法不仅广泛用于数字化,而且还广泛用于语音识别系统。 要通过语音识别一个人,您首先需要在其上训练模型,而没有UBM,则您必须有几个小时的时间来记录该人的语音。
从每个适应的GMM中,我们提取剪切系数的向量
(如果愿意,也可以是中间值或期望值),并基于所有细分中这些向量的数据,我们将进行聚类(下面将清楚为什么是移动向量)。
地图适应
我们将为每个段自定义UBM的方法称为最大A后验适应。 通常,算法如下。 首先,根据适应性数据和每个高斯的权重,中位数和方差的
足够统计量计算后验概率。 然后将获得的统计数据与UBM参数组合在一起,并获得适应模型的参数。 在我们的情况下,我们将仅调整中位数,而不会影响其余参数。 尽管我承诺不会更深入地研究数学,但毕竟我会引用三个公式,因为MAP自适应是本文的重点。
在这里
-后验概率,
-足够的统计数据
,
-调整后模型的中位数,
-适应系数,
-合规因素。
如果所有这些看起来都是胡说八道并引起沮丧,请不要绝望。 实际上,要了解该算法的操作,不必深入研究这些公式;可以通过以下示例轻松演示其操作:
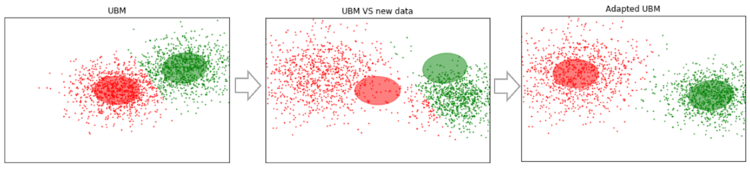
假设我们有足够大的数据,并且对它们进行了训练(左图,UBM是高斯分布的两部分混合)。 出现了不适合我们模型的新数据(中间的图)。 使用此算法,我们将移动高斯的中心,使它们位于新数据上(右图)。 将该算法应用于实验数据,我们将期望在具有相同说话者的片段上,高斯将向一个方向移动,从而形成聚类。 这就是为什么我们将使用剪切数据对片段进行聚类的原因
。
因此,让我们为每个段进行MAP适配。 (作为参考:除了MAP Adaptation外,还广泛使用MLLR方法-最大似然线性回归及其某些修改。它们还尝试将这两种方法结合起来。)
SV = []
现在,对于每个细分,我们都有关于
,我们终于进入最后一步。
光谱聚类
文章中简要介绍了光谱聚类,这是我一开始就提供的链接。 该算法构造了一个完整的图形,其中顶点是我们的数据,而顶点之间的边是相似度的度量。 在语音识别任务中,余弦度量用作这种度量,因为它考虑了向量之间的角度,而忽略了它们的大小(该幅度不携带有关说话者的信息)。 通过构造图,计算基尔霍夫矩阵的特征向量(本质上是结果图的表示),然后使用一些标准的聚类方法,例如k-means方法。 都适合两行代码
N_CLUSTERS = 2 sc = SpectralClustering(n_clusters=N_CLUSTERS, affinity='cosine') labels = sc.fit_predict(SV)
结论和未来计划
所描述的算法已通过各种参数进行了测试:
- MFCC号:7、13、20
- MFCC与LPC组合
- GMM中混合物的类型和数量:满[8、16、32],诊断[8、16、32、64、256]
- UBM适应方法:MAP(covariance_type ='full')和MLLR(covariance_type ='diag')
结果,参数在主观上保持最佳:MFCC 13,GMM covariance_type ='full'n_components = 16。
不幸的是,我没有耐心(一个多月前开始写这篇文章)来标记接收到的段并计算DER(数字化错误率)。 从主观上讲,我将算法的操作评估为“原则上不错,但远非理想状态”。 通过对从前一百个片段中获得的矢量进行聚类(一次MAP通过),然后选择访问员说的那些内容(女孩,她的讲话比那里的客人少很多),聚类给出一个列表
那是100%命中 同时,同时存在两个扬声器的段(例如14个)丢失,但这已经归咎于VAD错误。 此外,随着MAP通过次数的增加,开始考虑这些段。 重要的一点。 与我们合作的采访或多或少是“干净的”。 如果添加了各种音乐插入,噪音和其他非语言内容,则聚类开始变得li行。 因此,有计划尝试训练我们自己的VAD(例如,因为webrtcvad不会将音乐与语音分开)。
由于我最初是通过电话交谈进行工作的,因此无需估算发言人的数量。 但是,即使是接受采访,发言人的人数也不总是预先确定的。 例如,在中间的
这次采访中,有一个公告叠加在音乐上,并由另外两个人发声。 因此,尝试一种方法来估计参考文献列表部分中第一篇文章中指定的说话者人数(基于对规范化Laplace矩阵特征值的分析)。
参考文献
除了文本和Jupyter笔记本电脑中的链接上的资料外,还使用以下资源编写本文:
- 使用GMM超向量和高级归约算法对说话人进行二分法。 营养素
- 语音识别中的特征提取方法LPC,PLP和MFCC。 南拉达·戴夫
- 马尔可夫链的多变量高斯混合观测的MAP评估。 让·吕克·高文和李真慧
- 关于谱聚类分析和算法。 吴安德(Andrew Y. Ng),迈克尔·乔丹(Michael I.
- 在YOHO数据库上使用通用背景模型进行说话人识别。 亚历山大·马捷尼亚克(Alexandre Majetniak)
我还将添加一些diarization项目:
- Sidekit和s4d diarization扩展 。 用于语音处理的python库。 不幸的是,文档很差。
- Bob及其各个部分,例如bob.bio , bob.learn.em-一个用于信号处理和处理生物特征数据的python库。 不支持Windows。
- LIUM是用Java编写的交钥匙解决方案。
所有代码都发布在
github上 。 为了方便起见,我制作了几台Jupyter笔记本电脑,并演示了某些内容-MFCC,GMM,MAP适应和Diarization。 后者是主要过程。 存储库中还包含带有一些预先训练的模型的腌制文件以及访谈本身。