SDSM-15。 关于QoS。 现在有了
拉取请求的可能性。
因此,我们进入了QoS的主题。
您知道为什么现在才为什么,为什么它将成为整个SDSM课程的结尾文章? 因为QoS非常复杂。 周期中最难的事情。
这不是一种神奇的存档器,它可以巧妙地动态压缩流量并将您的千兆位推入一百兆位的上行链路。 QoS是关于如何牺牲不必要的东西,将不可食用的东西推入允许的框架中。
QoS与萨满主义和不可访问性的光环交织在一起,以至于所有年轻的工程师(不仅是工程师)都试图谨慎地忽略它的存在,认为这足以引发金钱问题,并不断扩大联系。 没错,直到他们意识到采用这种方法之前,失败将不可避免地等待着他们。 企业要么开始问一些不舒服的问题,要么会出现很多与通道宽度几乎不相关的问题,而直接取决于其使用效率。 是的,VoIP积极地在幕后挥舞着笔,组播流量恶意地抚摸着您。
因此,让我们意识到QoS是强制性的,您将不得不以某种方式知道它,并且由于某种原因,现在不要在轻松的氛围中开始。

目录内容
1.
决定QoS的因素是什么?2.
三种QoS模型3.
DiffServ机制4.
分类和标签5.
队列6.
避免拥塞7.
拥塞管理8.
速度限制9.
QoS的硬件实现
在读者深入研究这个漏洞之前,我将在其中进行三个设置:
- 扩展频段并不能解决所有问题。
- QoS不会扩展带宽。
- 有关管理有限资源的QoS。
1.决定QoS的因素是什么?
企业希望网络堆栈能够很好地执行其简单功能-将比特流从一台主机传输到另一台主机:无损且在可预测的时间内。
从这个简短的句子中,可以得出所有网络质量指标:
这三个特征决定了
网络的
质量,而与网络的性质无关:数据包,信道,IP,MPLS,无线电,
鸽子 。
损失
此度量标准告诉您源发送的数据包中有多少到达目的地。
丢失的原因可能是接口/电缆出现问题,网络拥塞,阻止ACL规则的位错误。
如果丢失,该怎么办由应用程序决定。 它可以忽略它们,就像在电话交谈中那样,不再需要延迟的数据包,或者重新发送它-TCP这样做是为了确保源数据的准确传递。

如果不可避免,如何在拥塞管理一章中管理损失。
如何利用拥塞预防一章中的损失。
延误
这是数据需要从源到目标的时间。

累积延迟由以下部分组成。
- 序列化延迟 -节点将数据包分解为比特并放入到下一个节点的链接所花费的时间。 它由接口的速度决定。 因此,例如,通过100 Mb / s的接口传输大小为1500字节的数据包将花费0.0001 s,而花费56 Kb / s-0.2 s。
- 传播延迟是臭名昭著的电磁波传播速度限制的结果。 物理学不允许您以30毫秒(实际上是70毫秒)的速度从纽约到达托木斯克。
- QoS引入的延迟是队列中数据包的减弱( 排队延迟 )和整形的后果( 整形延迟 )。 今天,我们将在“速度控制”一章中对此进行大量讨论。
- 处理数据包的 延迟 ( Processing Delay )-决定处理数据包的时间:查找,ACL,NAT,DPI-并将其从输入接口传递到输出。 但是在瞻博网络在其M40中将控制和数据平面分开的那天,可以忽略处理延迟。
对于不需要匆忙的应用程序,延迟并不是那么严重:文件共享,浏览,VoD,Internet广播电台等。 相反,它们对于交互操作非常重要:在电话交谈过程中,200毫秒的耳朵已经令人不快。
与
RTT (
往返时间 )不同义的与延迟相关的术语是往返。 在ping和跟踪时,您可以看到完全是RTT,而不是单向延迟,尽管这些值具有相关性。
抖动
连续数据包的传送之间的延迟差异称为抖动。
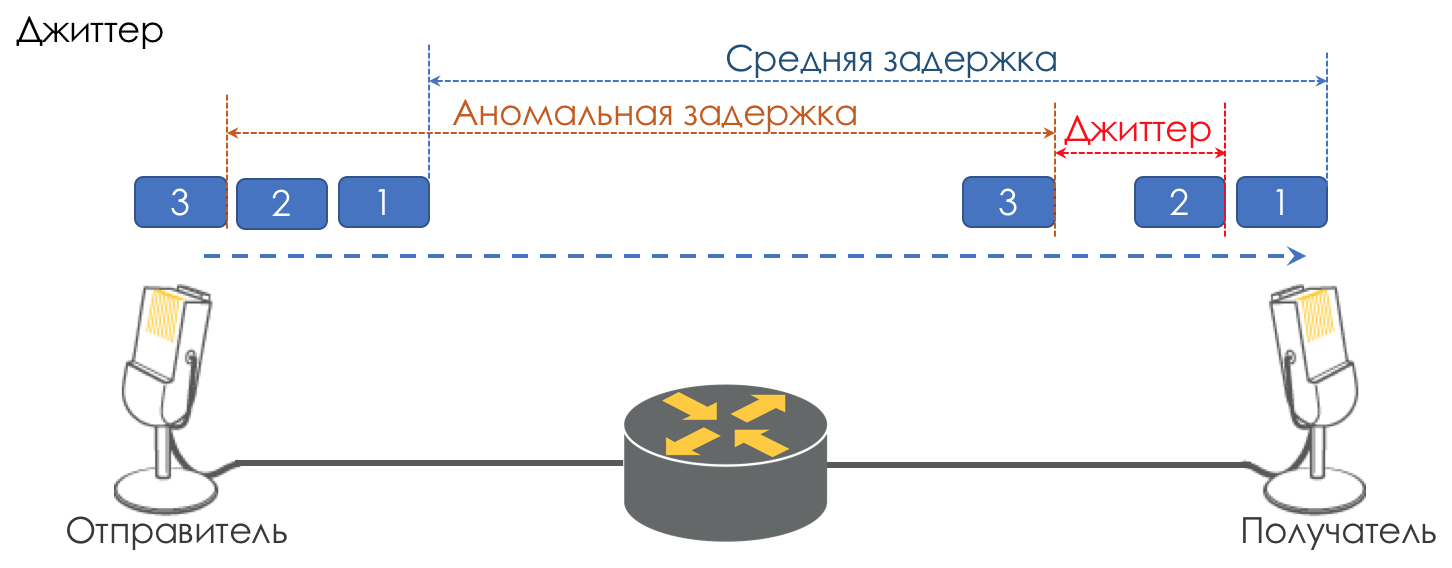
像延迟一样,抖动对许多应用程序都无关紧要。 甚至看起来,有什么区别-包装已经交付,还有什么呢?
但是,对于交互式服务而言,这一点很重要。
以相同的电话为例。 实际上,它是模拟信号的数字化,分为多个单独的数据块。 输出是相当统一的数据包流。 在接收侧,有一个固定大小的小缓冲区,顺序到达的数据包可放入其中。 为了恢复模拟信号,需要一定数量的模拟信号。 在浮动延迟的情况下,下一个数据块可能无法按时到达,这相当于丢失,并且信号无法恢复。
延迟可变性的最大贡献就是QoS。 在“速度限制”一章中,这也很繁琐。
这是网络质量的三个主要特征,但还有两个也起着重要作用。
随机发货
当数据包以错误的发送顺序到达接收方时,诸如电话,
NAS ,
CES等许多应用程序对数据包的随机传送极为敏感。 这可能导致连接断开,错误,文件系统损坏。
尽管随机传送不是正式的QoS功能,但它绝对是指网络质量。
即使TCP可以容忍此类问题,也会出现重复的ACK和重传。

频宽
不能将其区分为网络质量的度量标准,因为实际上它的缺点导致了上述三个方面。 但是,在我们的现实中,当应保证对某些应用程序使用它,或者相反,应按合同对其进行限制时,例如,MPLS TE在整个LSP中保留它,至少值得一提,至少作为一个弱指标。
速度控制机制将在“速度限制”一章中进行讨论。
为什么规格会变坏?
因此,我们从一个非常原始的想法开始,即网络设备(无论是交换机,路由器,防火墙还是其他设备)只是一条称为通信通道的管道,与铜线或光缆相同。

然后,所有数据包都以它们到达的相同顺序飞过,并且没有任何额外的延迟-无处可去。
但是实际上,每个路由器都会从信号中还原位和数据包,对它们进行一些处理(我们尚未考虑),然后将数据包转换回信号。
出现序列化延迟。 但是总的来说,这并不可怕,因为它是恒定的。 只要输出接口的宽度大于输入的宽度就不会令人恐惧。
例如,在设备的入口处是一个千兆端口,在输出处是一个620 Mb / s的无线电中继线连接到同一个千兆端口?
没有人会通过正式的千兆链路千兆流量禁止子弹。
无需执行任何操作-380 Mb / s会溅到地板上。
他们在这里-损失。
但与此同时,我非常希望摆脱最糟糕的部分-来自youtube的视频,并且执行董事与工厂董事之间的电话交谈不会被打断,甚至不会崩溃。
我希望声音有专线。
或者有五个输入接口,但有一个输出,并且同时有五个节点开始尝试向一个接收者注入流量。
添加少量VoIP理论(一篇没人写过的文章)-它对延迟及其变化非常敏感。
如果对于来自youtube的TCP视频流(在撰写
QUIC文章时-仍在进行实验),由于缓冲而造成的延迟(即使是几秒钟)完全不值钱,那么在与堪察加进行首次此类对话后,导演将致电技术部门主管。
在较早的时期,当自行车的作者仍在晚上做作业时,问题特别严重。 调制解调器连接的
速度为56k 。
当1.5K数据包进入这种连接时,它将占用整个线路200毫秒。 此刻没有人可以通过。 有声音吗 不,我没有听到。
因此,MTU问题非常重要-程序包不应占用接口太长时间。 速度越慢,所需的MTU越低。
他们在这里-延迟。
现在,该频道是免费的,并且延迟很短,一秒钟后有人开始下载大文件,延迟增加了。 他在这里-紧张不安。
因此,有必要使语音数据包以最小的延迟通过管道,而youtube将等待。
可用620 Mb / s用于语音,视频以及购买VPN的B2B客户。 我希望一种流量不会压制另一种流量,因此我们需要一个频带保证。
关于网络的性质,所有上述特征都是通用的。 但是,提供它们有三种不同的方法。
2.三种QoS模型
- 尽力而为-不保证质量。 所有人都是平等的。
- IntServ是每个流的质量保证。 从源到目标保留资源。
- DiffServ-没有保留。 每个节点本身确定如何确保正确的质量。
尽力而为(BE)
没有保证。实施QoS的最简单方法,从IP网络开始并一直沿用至今,有时是因为这样就足够了,但更多时候是因为没人考虑QoS。
顺便说一句,当您将流量发送到Internet时,它将作为BestEffort进行处理。 因此,通过在Internet上滚动的VPN(与提供商所提供的VPN相对),重要的通信量(例如电话对话)可能不会很自信。
在BE的情况下,所有流量类别都是相同的;任何优先级均不优先。 因此,不能保证任何延迟/抖动或频带。
这种方法的名称有点误会,即“尽力而为”(Best Effort),新来者用“ best”一词误导了它。
但是,“我将尽我所能”一词意味着演讲者将尽一切可能但不保证任何事情。
实施BE不需要任何操作-这是默认行为。 它制造便宜,员工不需要深入的专业知识,在这种情况下,QoS无法定制。
但是,这种简单性和静态性不会导致“尽力而为”方法未在任何地方使用的事实。 它可用于具有高带宽且不存在拥塞和突发的网络中。
例如,在跨大陆线路或某些没有超额预订的数据中心的网络中。
换句话说,在没有拥塞且不需要以任何特殊方式关联任何流量(例如电话)的网络中,BE是非常合适的。
互动
预先为从源到目的地的整个流程预留资源。MIT,Xerox和ISI网络之父决定将可预测性元素添加到不断增长的随机互联网中,同时保持其可操作性和灵活性。
因此,在1994年,IntServ的想法应运而生,以响应实时流量的快速增长和组播的发展。 然后将其简化为IS。
该名称反映了在同一网络中希望同时为实时和非实时流量类型提供服务的愿望,并通过预留频段来提供使用资源的第一优先权。 能够重用每个人都能赚钱的频段,并保留了IP拍摄的能力。
备份任务已分配给RSVP协议,该协议为
每个流在
每个网络设备上保留一个频段。
粗略地讲,在设置单速率三色MarkerP会话或开始数据交换之前,最终主机会以所需的带宽发送RSVP路径。 如果两个人都返回了RSVP Resv,则他们可以开始交流。 同时,如果没有可用资源,则RSVP将返回错误,并且主机将无法通信或无法使用BE。
现在让最勇敢的读者想象一下,将为当今Internet上的
任何流预先发送一个频道信号。 考虑到这要求
每个传输节点的CPU和内存成本不为零,并将实际交互延迟一段时间,因此很清楚为什么IntServ变成了一个几乎死命的想法-零可伸缩性。
从某种意义上讲,IntServ的现代化身是带有TEVP标记版本的MPLS TE-RSVP TE。 尽管这里当然不是端到端的,也不是按流的。
RFC 1633中描述了IntServ。
从原则上讲,该文档很好地评估了您在预测中的天真性。
区分服务
DiffServ很复杂。90年代末期,当端到端IntServ IP方法失败时,IETF召集了差异化服务工作组,该工作组对新QoS模型提出了以下要求:
- 没有信号(Adjos,RSVP!)。
- 基于总流量分类,而不是关注流量,客户等。
- 它具有一组有限的确定性操作,用于处理类的数据流量。
结果,标志性的
RFC 2474 (
IPv4和IPv6标头中的“区分服务字段”(DS字段)的定义 )和
RFC 2475 (
“区分服务的体系结构” )诞生了。
进一步,我们将仅讨论DiffServ。
值得注意的是,名称DiffServ并不是IntServ的对立面。 它反映出我们区分了各种应用程序提供的服务,或者说它们的流量,换句话说,我们共享/区分了这些类型的流量。
IntServ的作用相同-区分在同一网络上传输的流量BE和实时流量的类型。 和:IntServ和DiffServ都-区分服务的方式。
3. DiffServ机制
什么是DiffServ?为什么它击败了IntServ?
如果非常简单,则将流量分为几类。 对每个节点入口处的软件包进行分类,并对其应用一组工具,该工具以不同的方式处理不同类别的软件包,从而为它们提供不同的服务级别。
但这
不会 。
DiffServ的核心是经验丰富的IP IP
PHB概念
-每跳行为 。 业务路径上的每个节点都根据其报头独立地决定如何相对于传入数据包进行操作。
分组路由器的动作称为行为模型。 这样的模型的数量是确定性的并且是有限的。 在不同的设备上,针对相同流量的行为模型
可能会有所不同,因此它们是逐跳的。
我将在本文中将Behavior和PHB的概念用作同义词。有点混乱。 PHB一方面是每个节点的独立行为的一般概念,另一方面是特定节点上的特定模型。 有了这个,我们会解决的。

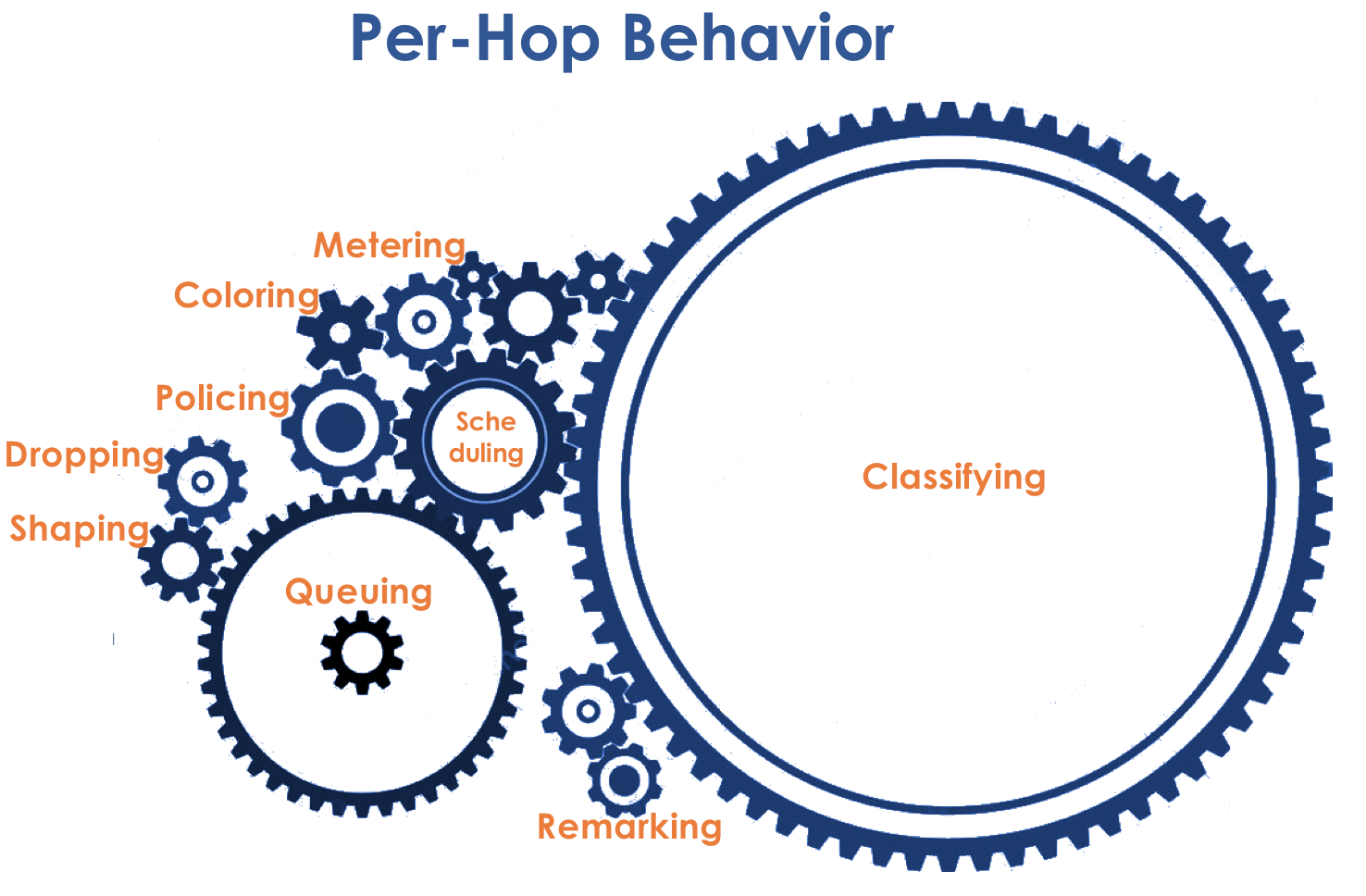
行为模型由一组工具及其参数确定:警务,丢弃,排队,调度,整形。
使用可用的行为模型,网络可以提供各种服务
类别(Service Class )。
也就是说,通过将不同的PHB应用于流量,不同类别的流量可以在网络上接收不同级别的服务。
因此,首先,您需要确定服务流量指的是-
分类 。
每个节点独立地对输入的数据包进行分类。

分类后,将进行测量(
计数 )-此类流量的多少位/字节已到达路由器。
根据结果,可以对包裹进行涂漆(
着色 ):绿色(在确定的限制范围内),黄色(在限制范围之外),红色(完全被海岸包围)。
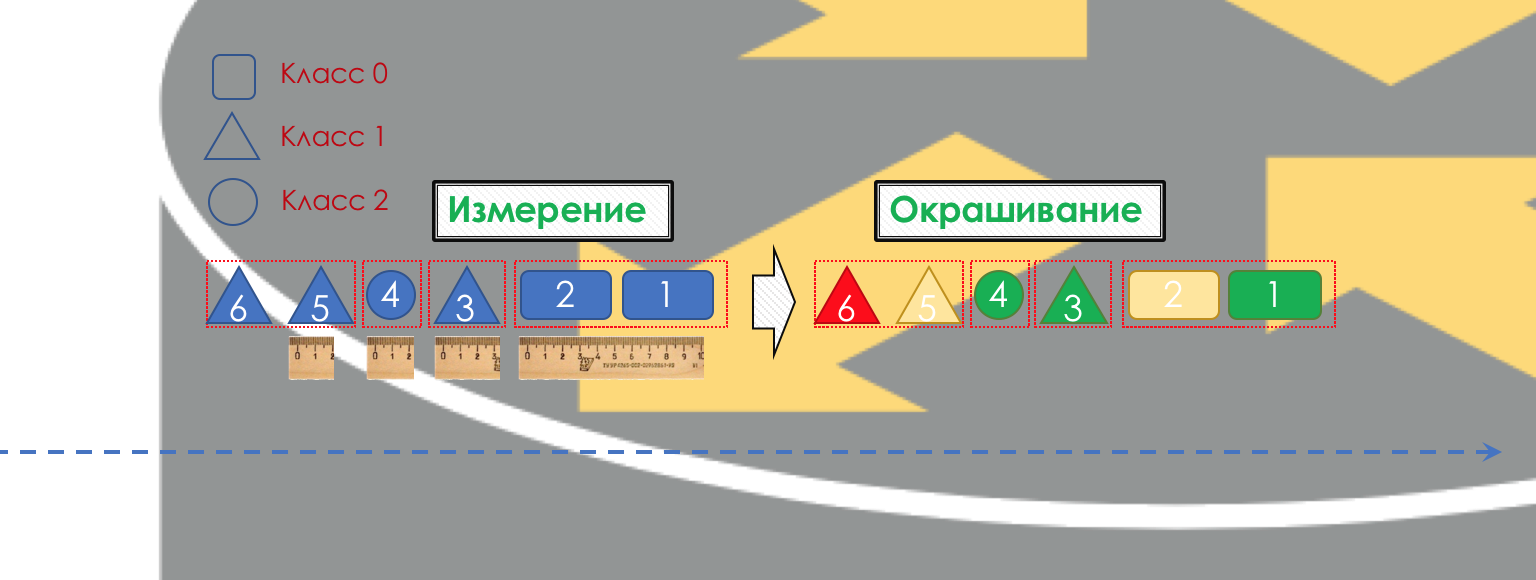
如有必要,则进行
警务处理(对这样的描图纸很抱歉,有一个更好的选择-写,我会改变)。 基于数据包颜色的抛光器为数据包分配一个操作-传输,丢弃或重新标记。
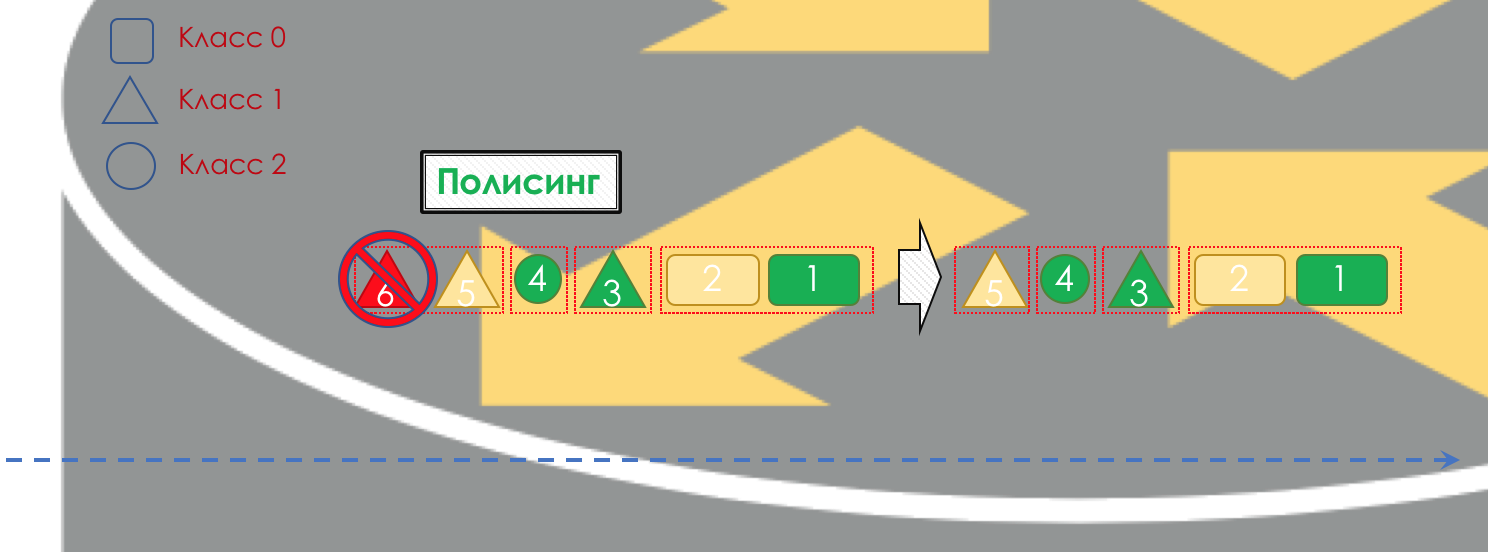
之后,数据包应落入队列之一(
Quueing )。 为每个服务类分配一个单独的队列,这使它们可以使用不同的PHB进行区分。
但是即使在数据包进入队列之前,如果队列已满,也可以将其丢弃(
Dropper )。
如果为绿色,则它将通过;如果为黄色,则如果行已满,并且如果红色肯定是自杀炸弹袭击者,则很可能将其丢弃。 有条件地,丢弃的可能性取决于数据包的颜色和将要到达的队列的满度。
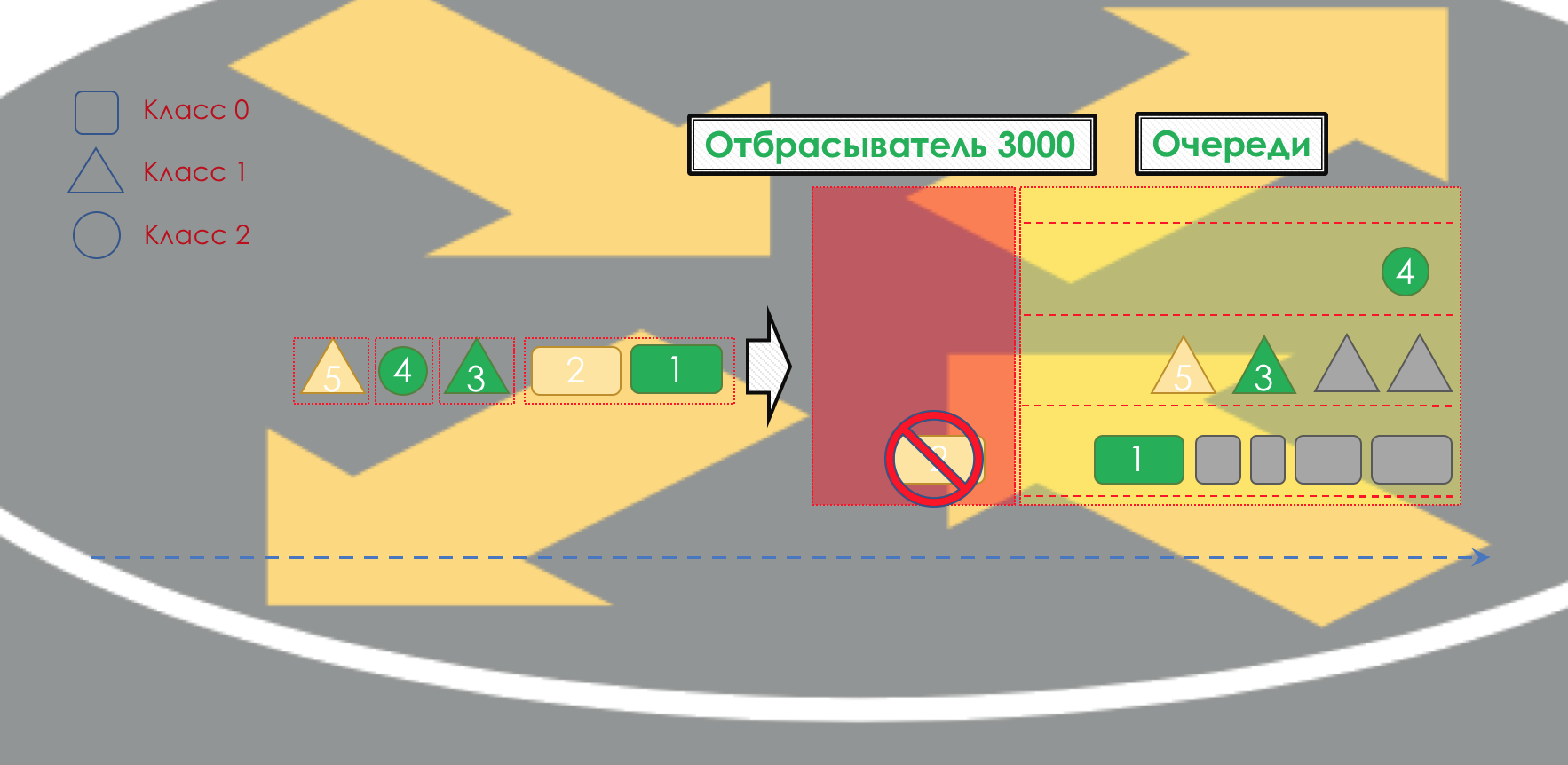
在队列出口处,
Shaper起作用,其任务与polyser的任务非常相似-将流量限制为给定值。
您可以为单个队列甚至在队列内配置任意成形器。
关于“速度限制”一章中的成形器和聚合器之间的区别。
所有队列最终都应合并为一个输出接口。
记住在路上8条车道合并为3条车的情况。如果没有交通管制员,这将变成混乱。 如果我们具有与输入相同的输出,则依次分隔将没有意义。
因此,有一个特殊的调度程序(
Scheduler ),该调度
程序周期性地从不同队列中取出数据包,并将其发送到接口(
Scheduling )。
实际上,一组队列和一个调度程序的组合是最重要的QoS机制,它允许您将不同的规则应用于不同的流量类别,一个提供较宽的带宽,另一个提供较低的延迟,第三种是没有丢弃。
然后,数据包已经到达接口,在该接口处,数据包被转换为比特流-序列化(
Serialization ),然后转换为环境信号。
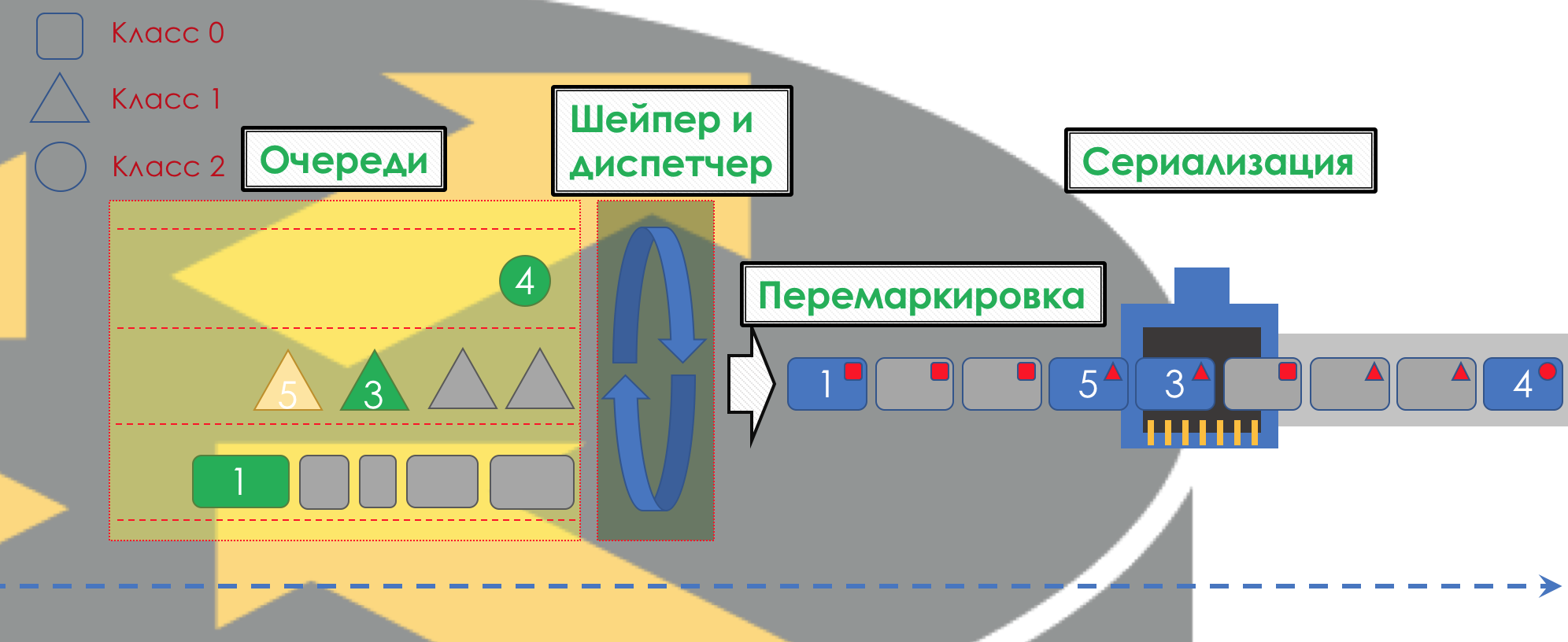
在DiffServ中,每个节点的行为都独立于其他节点;没有信令协议可以指示网络上哪个QoS策略。 同时,我希望在网络内部以相同的方式处理流量。 如果只有一个节点的行为有所不同,则整个QoS策略将不堪重负。
为此,首先,在所有路由器上为其配置相同的类别和PHB,其次,使用数据包的
标记 -属于特定类别
的数据包记录在报头(IP,MPLS,802.1q)中。
DiffServ的优点在于,下一个节点可以依靠此标签进行分类。
在这种信任区域中,将应用相同的流量分类规则和相同的行为,称为DiffServ域(
DiffServ-Domain )。

因此,在DiffServ域的入口处,我们可以基于5元组或接口对包进行分类,并根据域的规则对其进行标记(
Remark / Rewrite ),其他节点将信任该标记,而无需进行复杂的分类。
也就是说,DiffServ中没有显式的信令,但是节点可以告诉以下所有对象,该包需要提供哪个类,以等待其被信任。
在DiffServ域之间的交界处,您需要协商QoS策略(或不协商)。
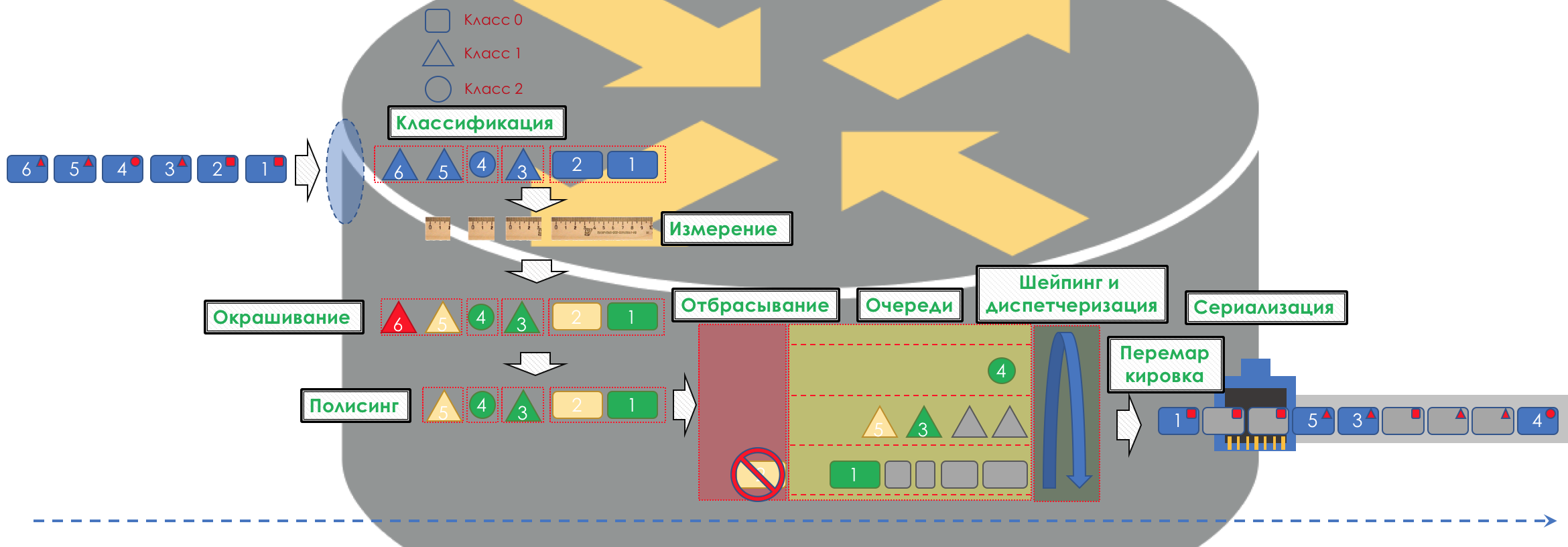
整个图片如下所示:
为了清楚起见,我将给出一个现实生活中的类似物。
乘飞机飞行(不是胜利)。
服务分为三类(CoS):经济,业务,第一。
购买机票时,会进行分类-乘客会根据价格获得某种服务等级。
在机场上有一个标记(备注)-发出表明等级的机票。
有两种行为(PHB):尽力而为和高级。
有一些机制可以实现这种行为:普通的候诊室或VIP休息室,小巴或共用公共汽车,舒适的大座位或紧排的座位,每位乘务员的乘客人数,点酒的能力。
根据班级,将行为模型分配给-尽力而为型经济,给企业-高级基础,再分配给第一-高级SUPER-POWER-NINJA-TURBO-NEO-ULTRA-HYPER-MEGA-MULTI-ALPHA-META-EXTRA-UBER-PREFIX!
同时,两种溢价有所不同,一种溢价是半甜的,另一种溢价是无限的百加得。
然后,到达机场后,每个人都穿过一扇门。 那些试图携带武器或没有票的人是不允许的(丢弃)。 商业和经济进入不同的候诊室和不同的交通方式(排队)。 首先,他们让头等舱登机,然后是商务,然后是经济舱(计划),但随后他们都乘坐一架飞机(界面)飞往目的地。
在同一示例中,飞机上的飞行是传播延迟,着陆是序列化延迟,在大厅中等待飞机的队列是排队,而护照控制是处理中。 请注意,此处的处理延迟通常在总时间方面可以忽略不计。
下一个机场可以用完全不同的方式来应对旅客-它的PHB是不同的。 但是同时,如果乘客不更换航空公司,那么对他的态度很可能不会改变,因为一家公司是一个DiffServ域。
您可能已经注意到,DiffServ非常(或无限)复杂。 但是,我们将分析上述所有内容。 同时,在本文中,我将不涉及物理实现的细微差别(即使在同一路由器的两个板上,它们也可能有所不同),也不会谈论HQoS和MPLS DS-TE。
进入了解QoS技术的工程师圈子的门槛比路由协议,MPLS或Radya,STP宽恕得多。
尽管如此,DiffServ已获得全球网络的认可和实施,因为正如他们所说的那样,它具有高度的可扩展性。
在本文的其余部分中,我将仅分析DiffServ。
下面我们将分析图中所示的所有工具和过程。
在扩展主题的过程中,我将在实践中展示一些东西。
我们将与这样的网络合作:
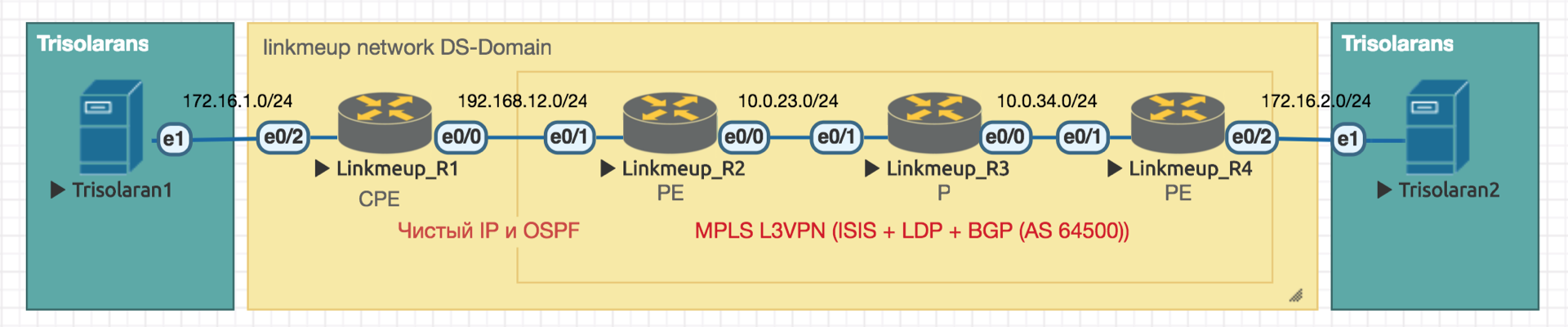
Trisolarans是具有两个连接点的linkmeup提供程序客户端。
黄色区域是Linkmeup网络的DiffServ域,其中有效的是单个QoS策略。
Linkmeup_R1是由提供商管理的CPE设备,因此位于受信任的区域中。 随之而来的是OSPF,并且通过干净的IP进行交互。
网络的核心是带有L3VPN的MPLS + LDP + MP-BGP,从Linkmeup_R2延伸到Linkmeup_R4。
我将在必要时提供所有其他评论。
初始配置文件 。
4.分类和标签
在他的网络中,管理员定义了他可以提供流量的服务类别。
因此,每个节点在接收到数据包时要做的第一件事就是对其进行分类。
有三种方法:
- 行为汇总 ( BA )
只需信任其标头中的现有包装标签即可。 例如,IP DSCP字段。
之所以这样称呼,是因为在DSCP字段中的同一标签下,汇总了各种流量类别,这些流量类别期望针对自己的行为相同。 例如,所有SIP会话都将汇总到一个类中。
可能的服务类别的数量以及行为方式均受到限制。 因此,不可能为每个类别(甚至对于流而言,甚至更多)都分配一个单独的类-必须进行汇总。 - 基于接口
特定接口上的所有内容都应放在一个流量类别中。 例如,我们确定数据库服务器已连接到该端口,仅此而已。 并在另一个员工工作站中。 - 多场 ( MF )
分析数据包头字段-IP地址,端口,MAC地址。 一般来说,任意字段。
例如,所有到达端口5000上的10.127.721.0/24子网的流量都需要标记为流量,这有条件地要求使用第5类服务。
管理员确定网络可以提供的服务类别集,并为它们映射一些数字值。
在DS域的入口处,我们不信任任何人,因此以第二种或第三种方式进行分类:根据地址,协议或接口,确定服务等级和相应的数字值。
在第一个节点的出口处,此数字被编码在IP头的DSCP字段(或流量类别的另一个字段:MPLS流量类别,IPv6流量类别,以太网802.1p)中-发生注释。
通常在DS域中信任此标签,因此,传输节点使用第一种分类方法(BA)-最简单的方法。 无需复杂的标题分析,只需查看记录的数字即可。
如上所述,在两个域的交界处,您可以基于接口或MF进行分类,也可以信任带有保留的BA标记。
例如,信任除6和7以外的所有值,然后将6和7重新分配给5。
当提供者连接具有其自己的标签策略的法人实体时,这种情况是可能的。 提供者不介意保存它,但不希望流量属于接收网络协议数据包的类别。
行为汇总
BA使用非常简单的分类-我看到一个数字-我了解该类。
那么数字是多少? 并记录在哪个领域?
- IPv6流量类别
- MPLS流量类别
- 以太网802.1p
分类主要基于换向标题。
我称呼一个通勤报头,设备根据此报文确定将数据包发送到哪里,以便它更接近接收者。也就是说,如果IP数据包到达路由器,则会分析IP头和DSCP字段。 如果MPLS到达,则将其解析-MPLS流量类。
如果以太网+ VLAN + MPLS + IP数据包到达常规的L2交换机,则将分析802.1p(尽管可以更改)。
IPv4服务条款
QoS字段与IP一样精确地伴随着我们。 八位TOS字段-服务类型-应该带有数据包的优先级。
甚至在DiffServ出现之前,
RFC 791 (
INTERNET PROTOCOL )就描述了如下字段:
IP优先级(IPP)+ DTR + 00。
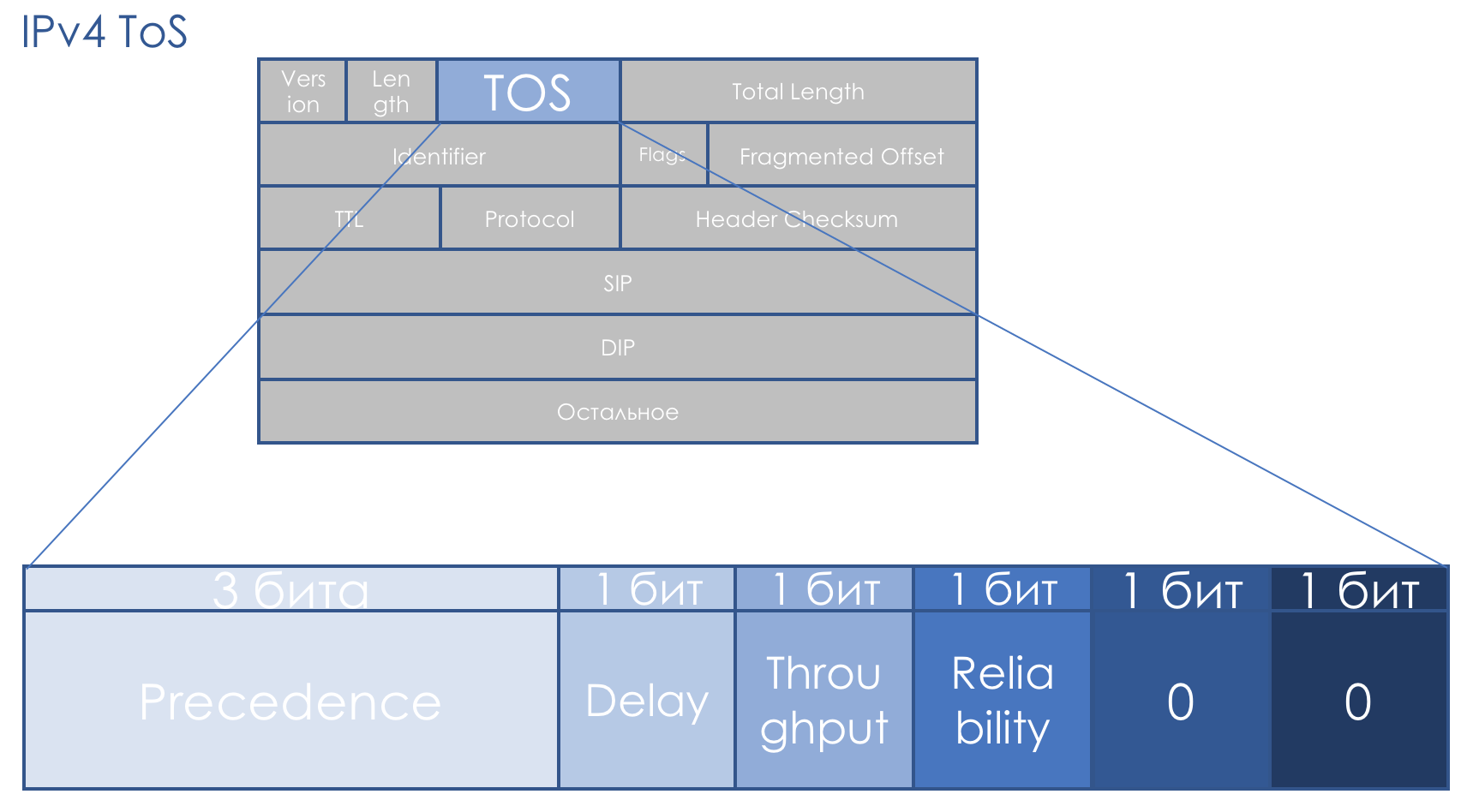
也就是说,数据包的优先级依次提高,然后是延迟,吞吐量,可靠性的精确度位(0-不要求,1-要求)。
最后两位必须为零。
优先级确定以下值...111-网络控制
110-互联网控制
101-评论/ ECP
100-闪存覆盖
011-闪光灯
010-立即发货
001-优先
000-例行
稍后在
RFC 1349 (
Internet协议套件中的服务类型 )中,对TOS字段进行了稍微的重新定义:
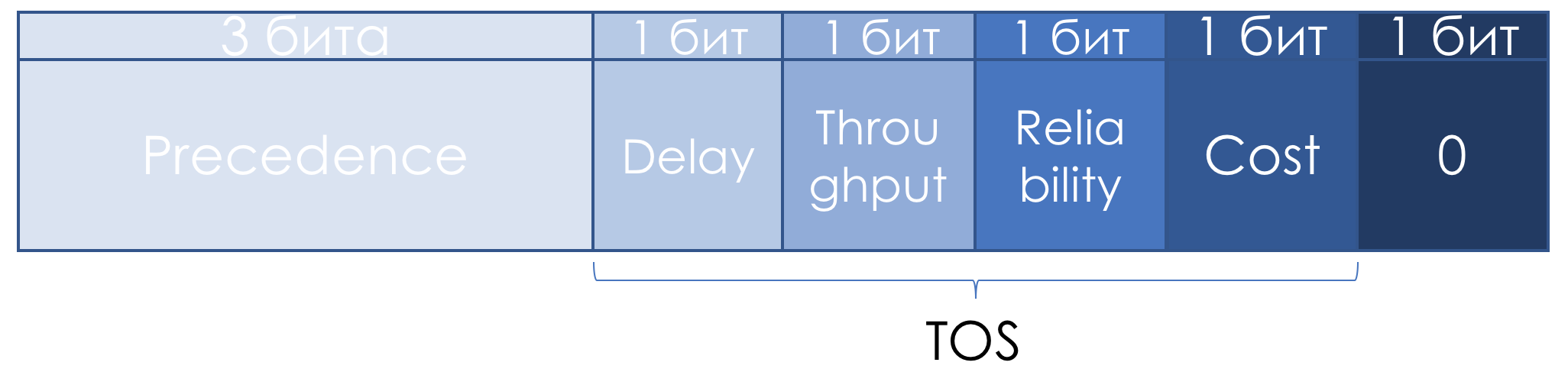
剩下的三位保留IP优先级,在添加Cost位后,剩下的四位变为TOS。
以下是读取这些TOS位中单位的方法:
- D-“最小化延迟”,
- T-“最大化t通量”,
- R-“最大化可靠性”,
- C-“最小化成本”。
朦胧的描述并没有促进这种方法的普及。
整个路径上没有系统的QoS方法,也没有关于如何使用优先级字段的明确建议,对延迟,吞吐量和可靠性位的描述非常模糊。
因此,在DiffServ的上下文中,在
RFC 2474 (
IPv4和IPv6标头中的区分服务字段(DS字段)的定义)中再次重新定义了TOS字段:

代替了IPP和DTRC位,引入了六位字段DSCP-
区分服务代码点 ,未使用两个正确的位。
从那时起,应该是DSCP字段成为DiffServ的主要标记:在其中写入了某个值(代码),该值在DS域中表征了程序包所需的特定服务类别及其丢弃优先级。 这是同一个人。
管理员可以视需要使用DSCP的所有6位,最多共享64个服务类。
但是,为了与IP优先级兼容,他们保留了前三位的类选择器的作用。
也就是说,与IPP一样,Class Selector的3位允许您定义8个类别。

但是,这仅是一种安排,即在其DS域的限制内,管理员可以根据自己的判断轻松地忽略并使用所有6位。
此外,我还注意到,根据IETF的建议,CS中记录的值越高,对该服务的流量要求越高。
但这不应被视为不可否认的真理。
如果前三位定义了流量类别,则后三位用于指示数据包丢弃优先级(
丢弃优先级或
数据包丢失优先级-PLP )。
八堂课-是很多还是一点? 乍看之下,这还远远不够-毕竟,网络上存在许多不同的流量,因此人们希望按类别区分每种协议。 但是,事实证明,对于所有可能的情况,八个就足够了。
对于每个类,您都需要定义一个将以不同于其他类的方式处理它的PHB。
随着除数的增加,股息(资源)不会增加。
我没有在谈论它们描述的流量类别的确切值,因为没有标准,您可以自行决定正式使用它们。 下面我将告诉您推荐哪些类及其对应的值。
ECN位...两位ECN字段仅出现在
RFC 3168 (
显式拥塞通知 )中。 定义该字段的目的是明确通知最终主机此过程中有人正在发生拥塞。
例如,当数据包在路由器队列中长时间延迟并填充(例如,由85%填充)时,它将更改ECN值,告知最终主机需要降低的速度-类似于以太网上的暂停帧。
在这种情况下,发送方必须降低传输速率并减少受灾节点的负载。
同时,从理论上讲,不需要所有传输节点对该字段的支持。 也就是说,使用ECN不会破坏不支持它的网络。
目标是好的,但是在生命周期中未特别发现ECN。 如今,超大型和超大型机对这两个比特产生了
新的兴趣 。
ECN是下面描述的拥塞避免机制之一。
DSCP分类实践
一点练习也没有什么坏处。
该方案是相同的。
要开始使用,只需发送一个ICMP请求:
Linkmeup_R1#ping ip 172.16.2.2 source 172.16.1.1 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds: Packet sent with a source address of 172.16.1.1 !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
Linkmeup_R1。 E0 / 0。 pcapng
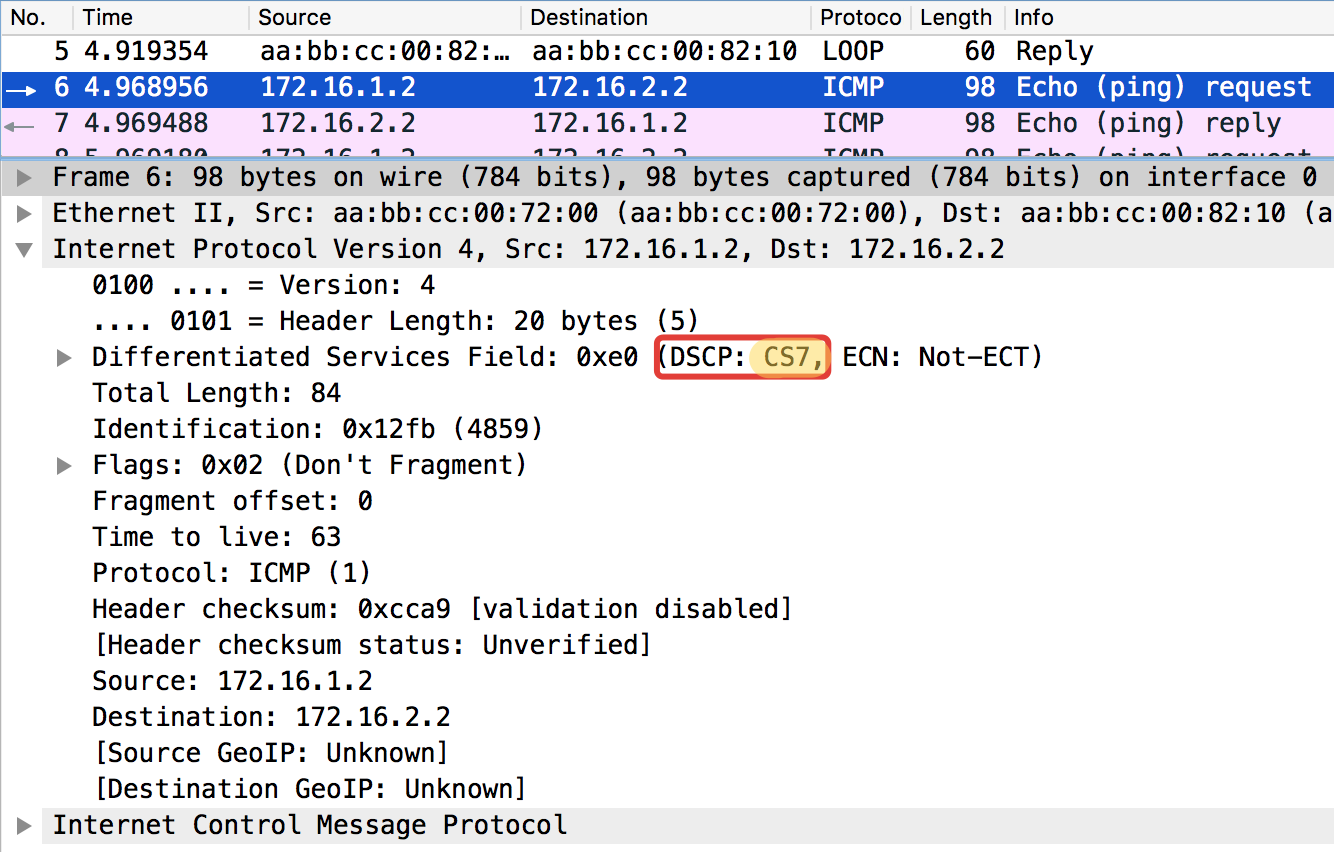
pcapng现在设置了DSCP值。
Linkmeup_R1#ping ip 172.16.2.2 source 172.16.1.1 tos 184 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds: Packet sent with a source address of 172.16.1.1 !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
值184是二进制10111000的十进制表示形式。其中,前6位是101110,即十进制46,这是EF类。
方便popingushki的标准TOS值表...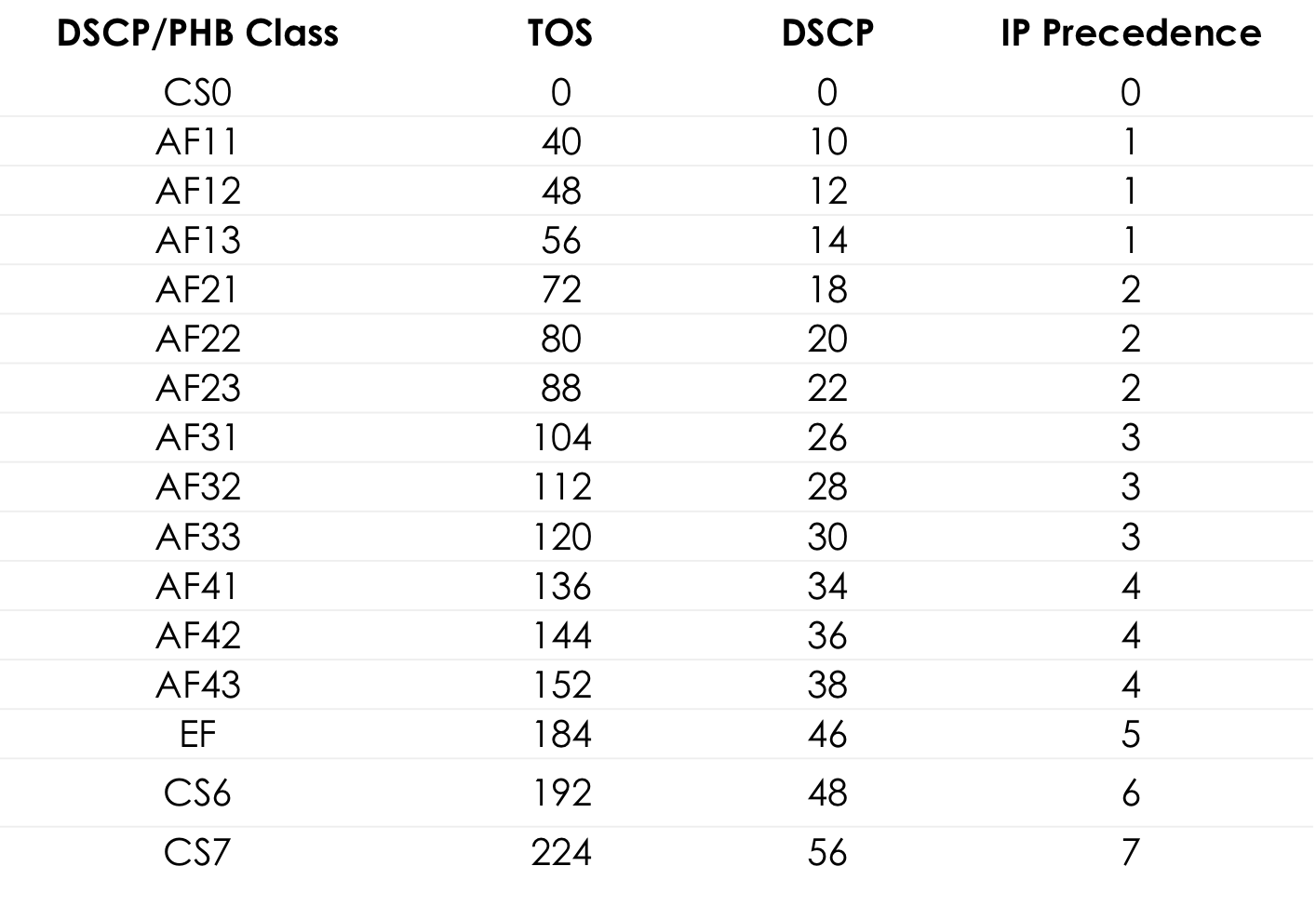 更多细节
更多细节在
IETF建议书一章的文字下面
,我将告诉您这些数字和名称的来源。
Linkmeup_R2。 E0 / 0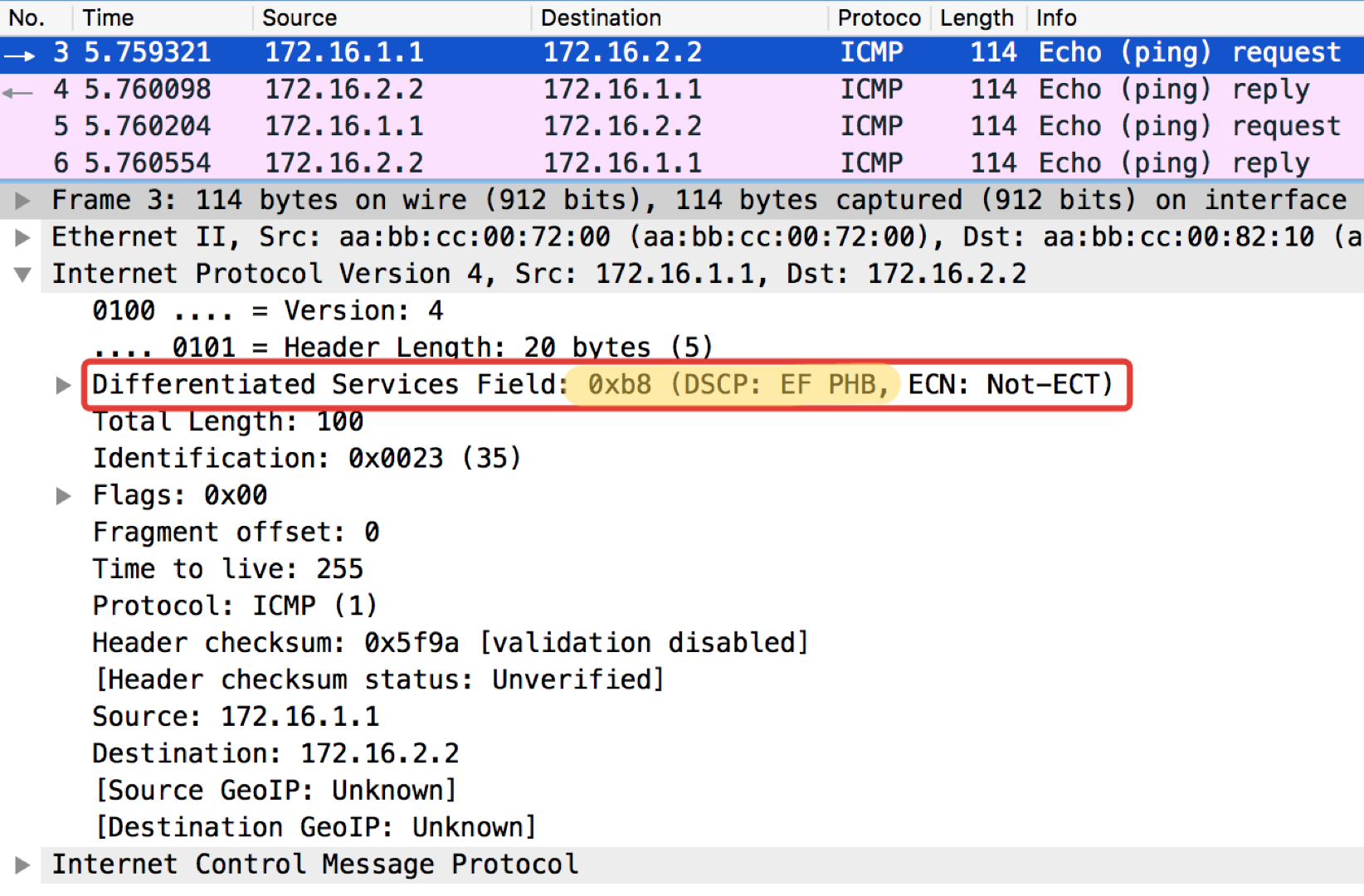 pcapng
pcapng一个奇怪的提示:ICMP Echo回复中pingushka的目的地设置了与Echo Request中相同的类值。 这是合乎逻辑的-如果发件人发送了具有特定重要性级别的数据包,那么显然他希望收到保证回送的数据包。
Linkmeup_R2。 E0 / 0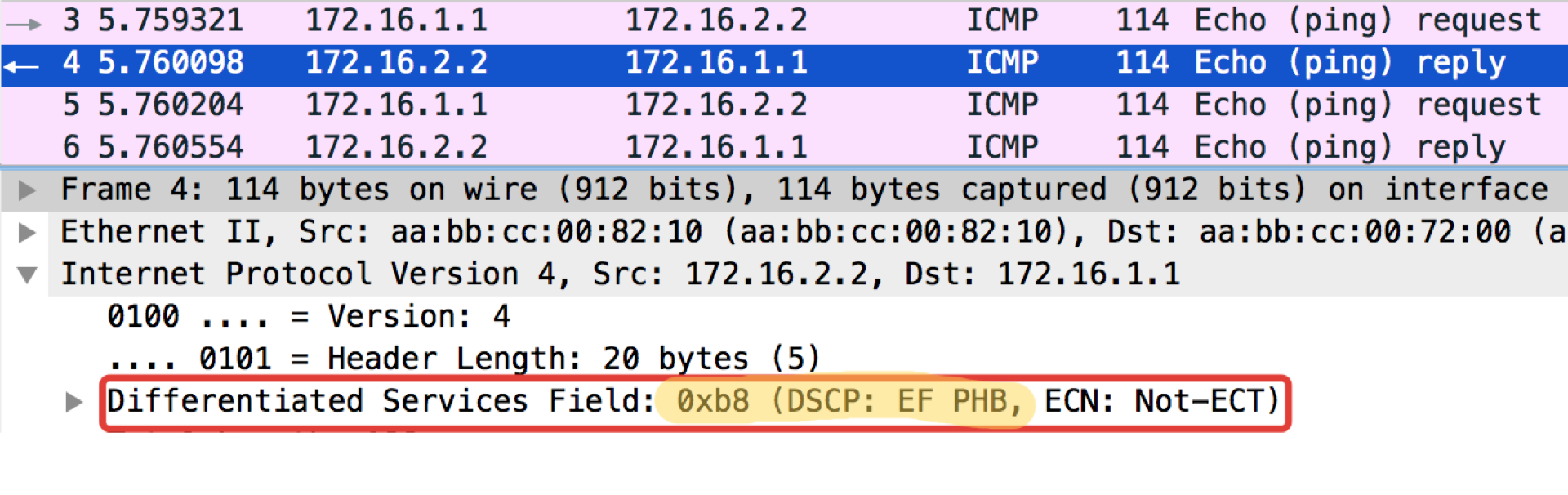 DSCP分类配置文件。
DSCP分类配置文件。IPv6流量类别
IPv6在QoS方面与IPv4并无太大不同。 八位字段称为流量类别,也分为两部分。 前6位(DSCP)的作用完全相同。

是的,流标签已经出现。 他们说,它可以用于类别的其他区分。 但是这个想法尚未在生活中应用。
MPLS流量类别
DiffServ的概念集中在具有IP标头路由的IP网络上。 真是倒霉-3年后,他们发布了
RFC 3031 (
多协议标签交换体系结构 )。 MPLS开始接管网络提供商。
DiffServ无法扩展到他。
碰巧的是,对于任何实验情况,都将三位EXP字段放入MPLS。 尽管事实上很久以前在
RFC 5462 (
“ EXP”字段重命名为“ Traffic Class”字段 )中正式成为Traffic Class字段,但由于惯性,它被称为IExPi。
它有一个问题-它的长度为3位,这将可能的值的数量限制为9。它不仅很小,而且比DSCP少3个二进制数。

鉴于MPLS流量类通常是从DSCP IP数据包继承的,因此存档时会丢失。 或者...不,您不想知道...
L-LSP 。 结合使用“流量类别+标签”值。
通常,情况很奇怪-MPLS被设计为用于快速决策的IP辅助-MPLS标签是通过Full Match在CAM中立即检测到的,而不是传统的Longest Prefix Match。 也就是说,他们了解IP,并参与了交换,但是没有提供正常的优先级字段。
实际上,我们在上面已经看到,只有DSCP的前三位用于确定流量类别,其他三位是丢弃优先级(或PLP-丢包优先级)。
因此,就服务类别而言,我们仍然具有1:1的对应关系,仅丢失有关丢弃优先级的信息。
在MPLS的情况下,IP分类可以基于接口MF,IP DSCP或流量类别MPLS。
标记意味着将值写入MPLS标头的“业务类别”字段。
一个数据包可能包含多个MPLS标头。 出于DiffServ的目的,仅使用顶部。
通过MPLS域将数据包从一个纯IP段移动到另一个纯IP段时,存在三种不同的重标记场景:(这只是
本文的摘录)。
- 统一模式
- 管道模式
- 短管模式
操作模式...统一模式
这是一个扁平的端到端模型。
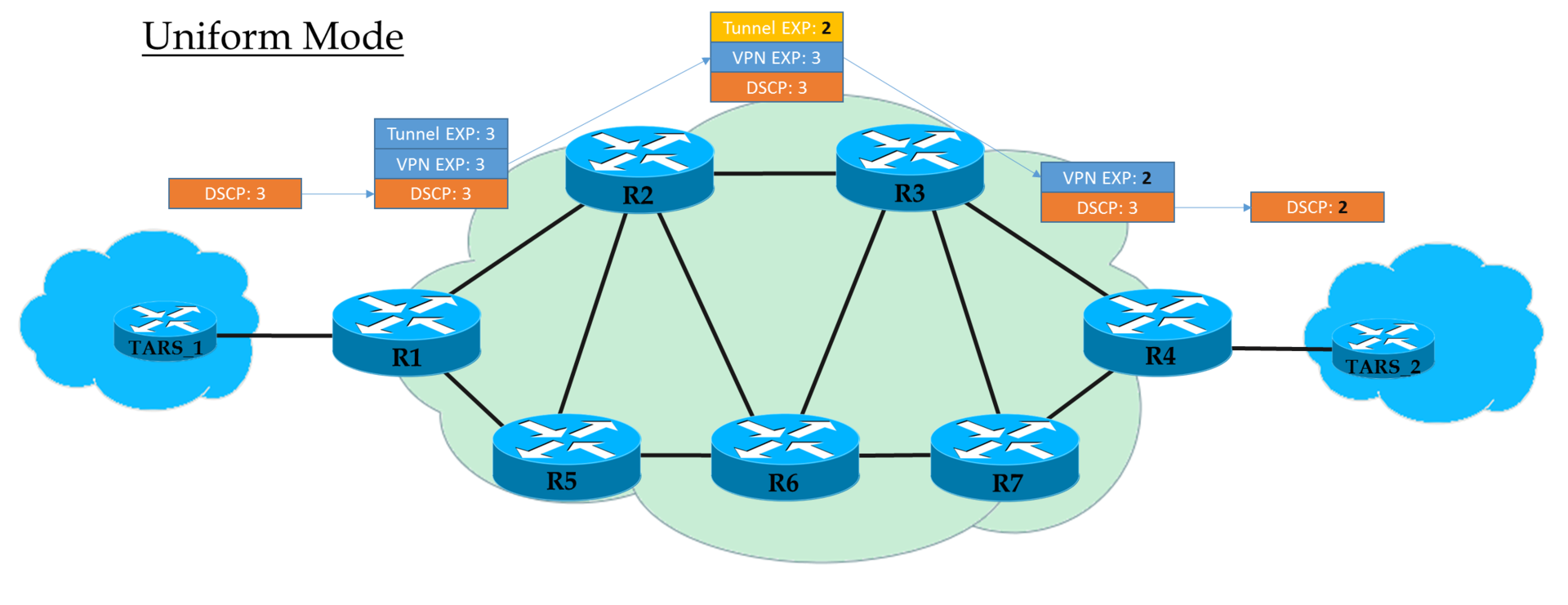
在Ingress PE,我们信任IP DSCP并在MPLS EXP(隧道和VPN标头)中复制(
严格地说是显示,但为简单起见,我们称其为
“复制” )。 在Ingress PE的输出处,已经根据上层MPLS标头的EXP字段的值处理了数据包。
每个中转站P也根据最高EXP处理数据包。 但是同时,如果操作员需要,他可以更改它。
倒数第二个节点删除传输标签(PHP),并将EXP值复制到VPN标头。 站在那里并没关系-在统一模式下,会进行复制。
出口PE删除了VPN标签,也将EXP值复制到IP DSCP,即使在其中写入了其他内容也是如此。
也就是说,如果在中间某处隧道头中的EXP标签的值已更改,则此更改将被IP数据包继承。
管道模式
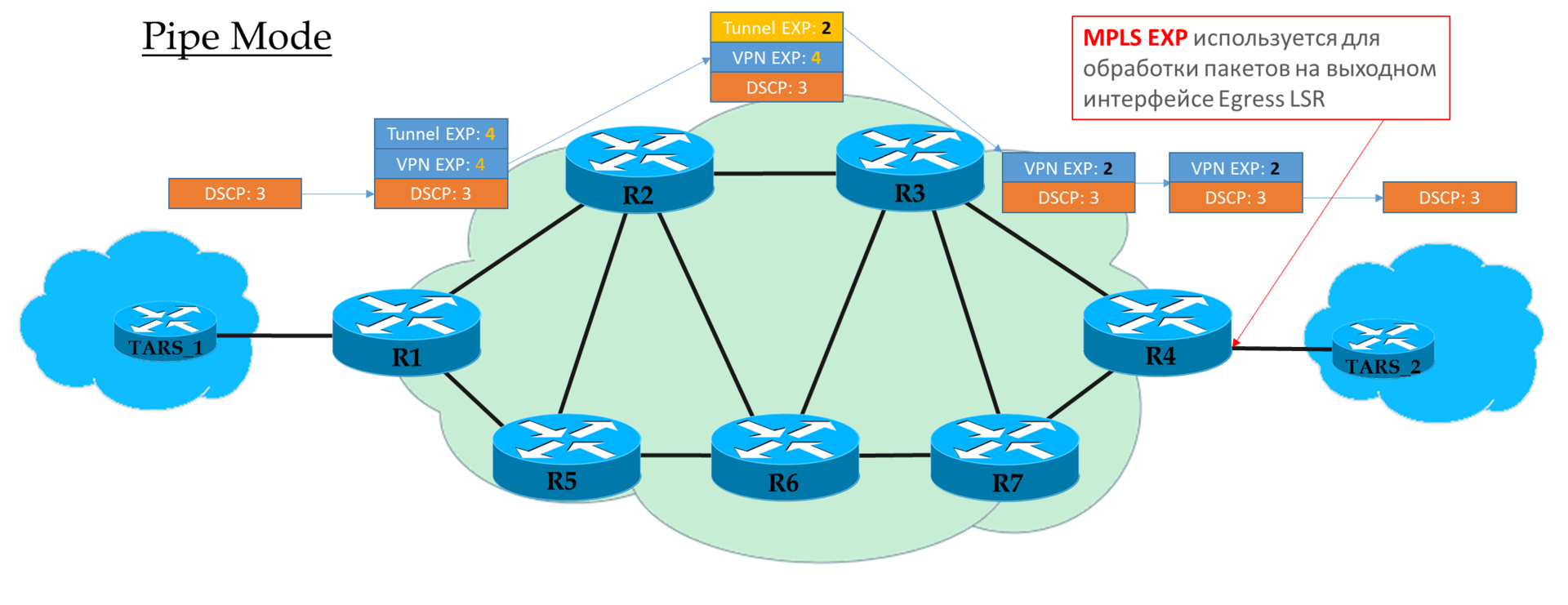
如果在Ingress PE上我们决定不信任DSCP值,则将运营商想要的EXP值插入到MPLS标头中。
但是可以复制DSCP中的内容。 例如,您可以重新定义值-将所有内容复制到EF,然后将CS6和CS7映射到EF。
每个转接P仅查看上层MPLS标头的EXP。
倒数第二个节点删除传输标签(PHP),并将EXP值
复制到VPN标头。
出口PE首先根据MPLS标头中的EXP字段处理数据包,然后才将其删除,
而不将值
复制到DSCP。
也就是说,不管MPLS标头中的EXP字段发生了什么,IP DSCP都保持不变。
当运营商拥有自己的Diff-Serv域并且不希望客户端流量以某种方式影响它时,可以使用这种方案。
短管模式
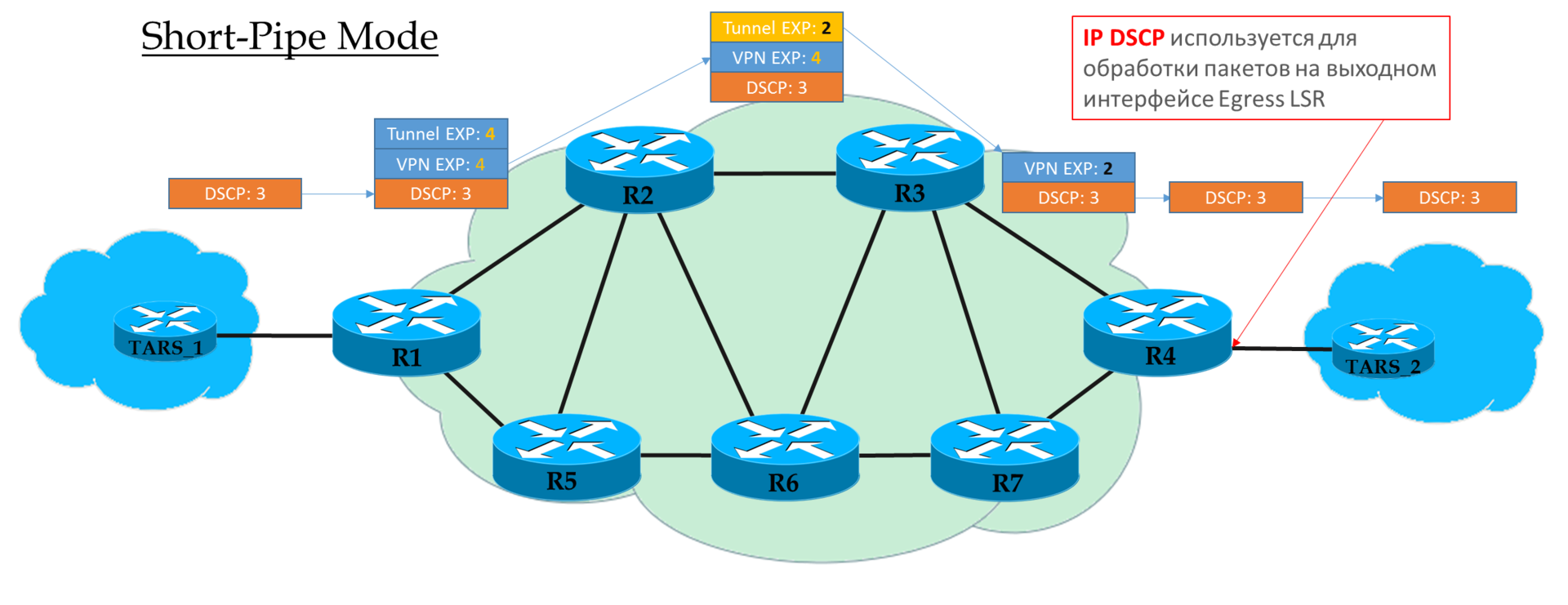
您可以将此模式视为管道模式的变体。 唯一的区别是,在MPLS网络的出口处,将根据数据包的IP DSCP字段而不是MPLS EXP来处理数据包。
这意味着输出端的数据包优先级是由客户端而不是运营商确定的。
入口PE不信任IP DSCP入站数据包
Transit Ps在顶部标题的EXP字段中查找。
倒数第二个P删除传输标签,并将值复制到VPN标签。
出口PE首先删除MPLS标签,然后处理队列中的数据包。
思科的解释。
分类实践MPLS Traffic Class
该方案是相同的:
配置文件是相同的。在linkmeup网络图中,存在从IP到MPLS到Linkmeup_R2的过渡。
让我们看看在
ping ip 172.16.2.2源172.16.1.1 tos 184时标记发生了什么。
Linkmeup_R2。 E0 / 0。 pcapng
pcapng因此,我们看到IP DSCP中的原始EF标签被转换为VPN标头和传输标头的EXP MPLS字段的值5(也是流量类,记住这一点)。
在这里,我们目睹了统一操作模式。
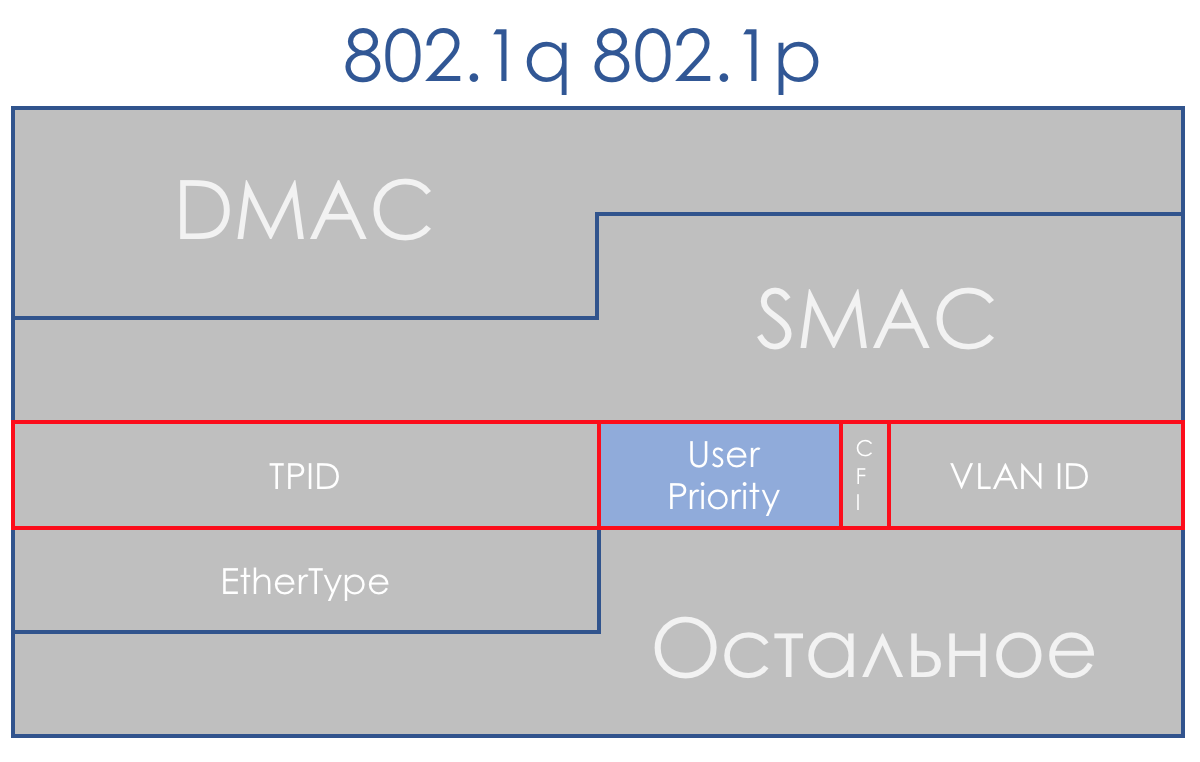
以太网802.1p
802.3(Ethernet)中缺少优先级字段的原因是,以太网最初专门作为LAN网段的解决方案而设计。 如果花很少的钱,您可能会获得过多的带宽,并且上行链路始终是瓶颈-无需担心优先级。
但是,很快就清楚地认识到,以太网+ IP的经济吸引力将这一捆绑带到了骨干网和WAN层。 而且,需要解决洪流和电话的一个局域网段中的同居问题。
幸运的是,802.1q(VLAN)为此及时到来,其中为优先级分配了一个3位(再次)字段。
在DiffServ计划中,此字段允许您定义相同的8个流量类别。
接收数据包时,DS域的网络设备在大多数情况下会考虑其用于交换的报头:
- 以太网交换机-802.1p
- MPLS节点-MPLS流量类别
- IP路由器-IP DSCP
尽管可以更改此行为:基于接口和多字段分类。 有时您甚至可以在CoS字段中明确地说出要查看的标头。
基于接口
这是对额头上的包裹进行分类的最简单方法。 注入到指定接口中的所有内容均使用特定类进行标记。
在某些情况下,这种粒度就足够了,因此可以在生活中使用基于接口的方法。
基于界面的分类实践
该方案是相同的:
在大多数供应商的设备中设置QoS策略分为多个阶段。
- 首先,定义分类器:
class-map match-all TRISOLARANS_INTERFACE_CM
match input-interface Ethernet0/2
以太网0/2接口的所有内容。
- 接下来,创建一个策略,其中将分类器和必要的操作相关联。
policy-map TRISOLARANS_REMARK class TRISOLARANS_INTERFACE_CM set ip dscp cs7
如果数据包符合TRISOLARANS_INTERFACE_CM分类器,则在DSCP字段中写入CS7。
在这里,我先使用晦涩的CS7,然后再使用EF,AF。 您可以在下面阅读有关这些缩写和已接受协议的信息。 同时,只需知道这些是具有不同服务级别的不同类别即可。
- 最后一步是将策略应用于接口:
interface Ethernet0/2 service-policy input TRISOLARANS_REMARK
在这里,分类器有点多余,它将检查数据包是否到达e0 / 2接口,然后在其中应用策略。 任何人都可以写匹配:
class-map match-all TRISOLARANS_INTERFACE_CM match any
但是,该策略实际上可以应用在vlanif或输出接口上,因此是可行的。
使用Trisolaran1在172.16.2.2(Trisolaran2)上执行常规ping:
在Linkmeup_R1和Linkmeup_R2之间的转储中,我们将看到以下内容:
 pcapng基于配置文件界面的分类。
pcapng基于配置文件界面的分类。多领域
DS域入口处最常见的分类类型。 我们不信任现有的标签,并且根据包头分配一个类。
在发件人未标记的情况下,通常这是完全“启用” QoS的方法。
一个相当灵活的工具,但同时又很麻烦-您需要为每个类创建困难的规则。 因此,在DS域中,BA更重要。
MF分类实践
该方案是相同的:
从上面的实际示例中可以看出,网络设备默认情况下信任传入数据包的标签。
这在DS域中很好,但在入口点是不可接受的。
现在让我们不要盲目相信吗? 在
Linkmeup_R2上, ICMP将标记为EF(仅作为示例),TCP标记为AF12,其他所有标记为CS0。
这将是MF(多字段)分类。
- 步骤是相同的,但是现在我们将根据ACL进行匹配,以取消必要的流量类别,因此首先创建它们。
在Linkmeup_R2上:
ip access-list extended TRISOLARANS_ICMP_ACL permit icmp any any ip access-list extended TRISOLARANS_TCP_ACL permit tcp any any ip access-list extended TRISOLARANS_OTHER_ACL permit ip any any
- 接下来,我们定义分类器:
class-map match-all TRISOLARANS_TCP_CM match access-group name TRISOLARANS_TCP_ACL class-map match-all TRISOLARANS_OTHER_CM match access-group name TRISOLARANS_OTHER_ACL class-map match-all TRISOLARANS_ICMP_CM match access-group name TRISOLARANS_ICMP_ACL
- 现在,我们定义了政治评论的规则:
policy-map TRISOLARANS_ADMISSION_CONTROL class TRISOLARANS_ICMP_CM set ip dscp ef class TRISOLARANS_TCP_CM set ip dscp af11 class TRISOLARANS_OTHER_CM set ip dscp default
- 并且我们在接口上挂起了策略。 分别在输入时,因为必须在网络的入口处做出决定。
interface Ethernet0/1 service-policy input TRISOLARANS_ADMISSION_CONTROL
来自最终主机Trisolaran1的ICMP测试。 我们没有明确指定类别-默认值为0。
我已经用Linkmeup_R1删除了该策略,因此流量带有标记CS0,而不是CS7。
这是附近的两个转储,分别是Linkmeup_R1和Linkmeup_R2:
Linkmeup_R1。 E0 / 0。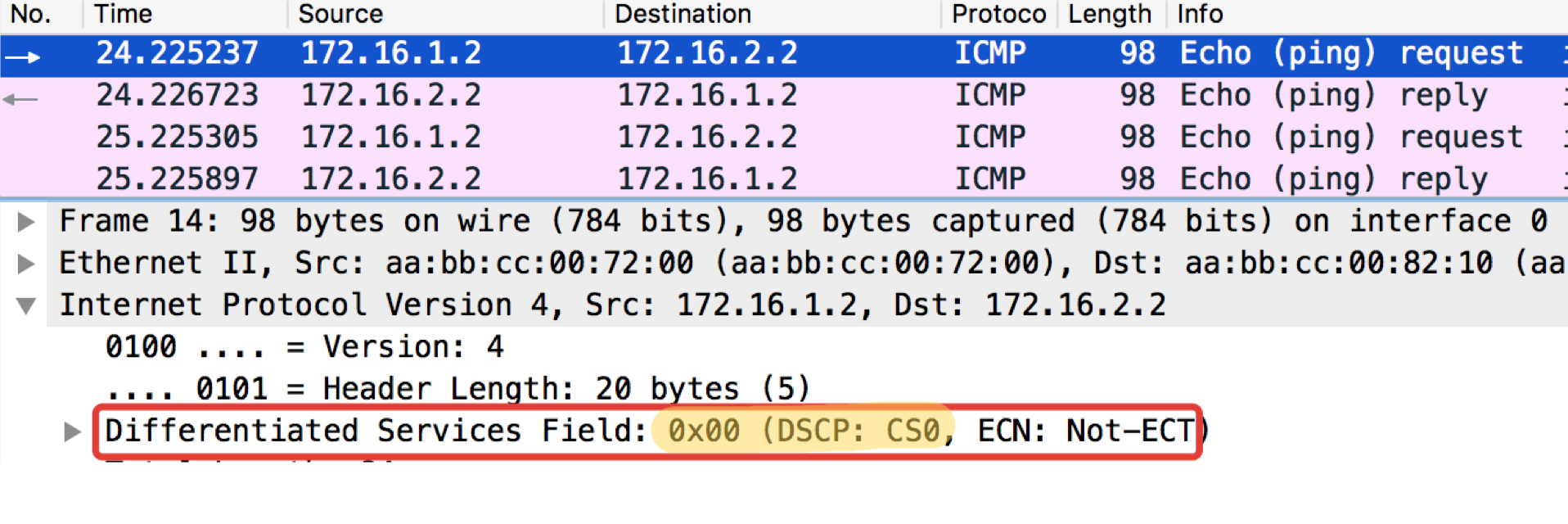 pcapngLinkmeup_R2。 E0 / 0。
pcapngLinkmeup_R2。 E0 / 0。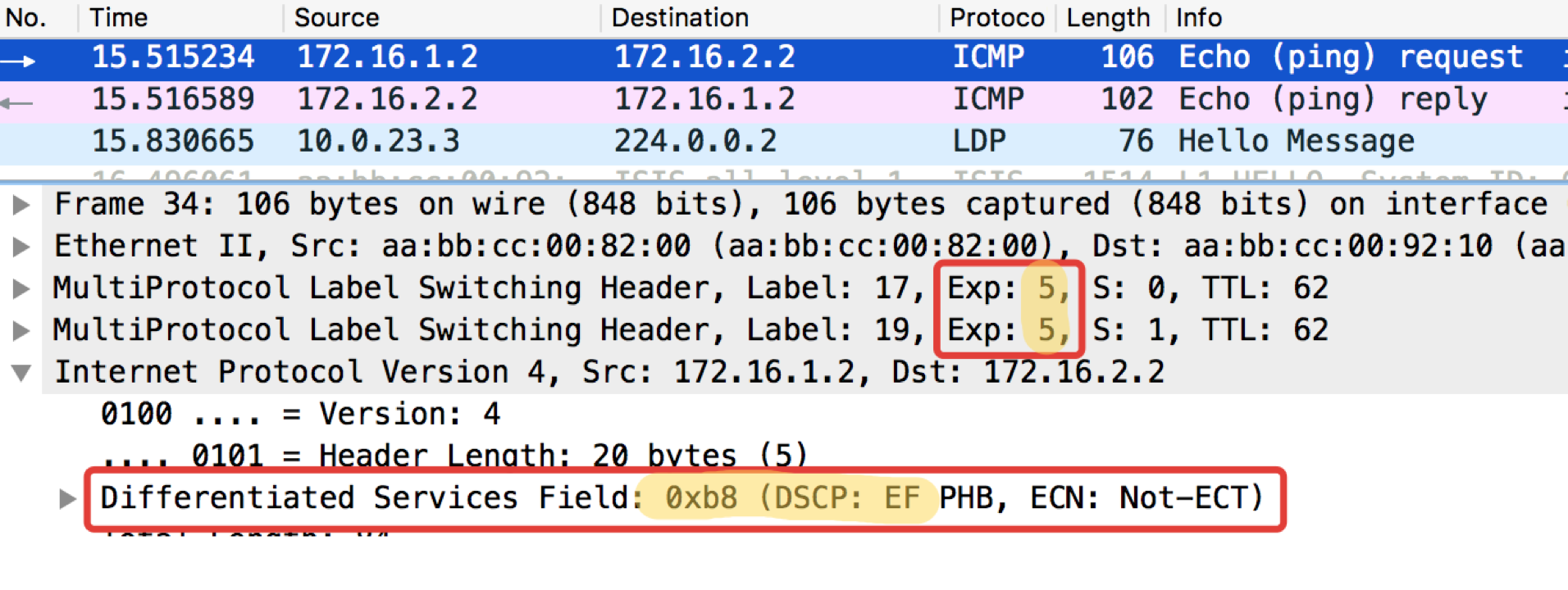 pcapng
pcapng可以看出,在对ICMP数据包的Linkmeup_R2进行分类并重新标记后,不仅DSCP更改为EF,而且MPLS Traffic Class等于5。
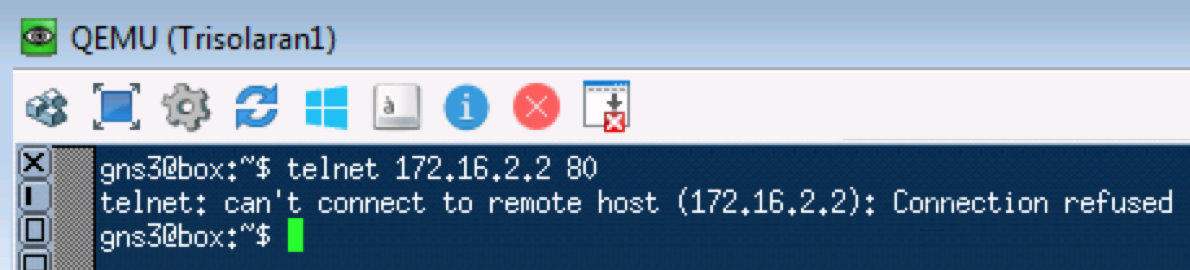
使用telnet 172.16.2.2。进行类似的测试。 80-因此请检查TCP:
 Linkmeup_R1。 E0 / 0。
Linkmeup_R1。 E0 / 0。 pcapngLinkmeup_R2。 E0 / 0。
pcapngLinkmeup_R2。 E0 / 0。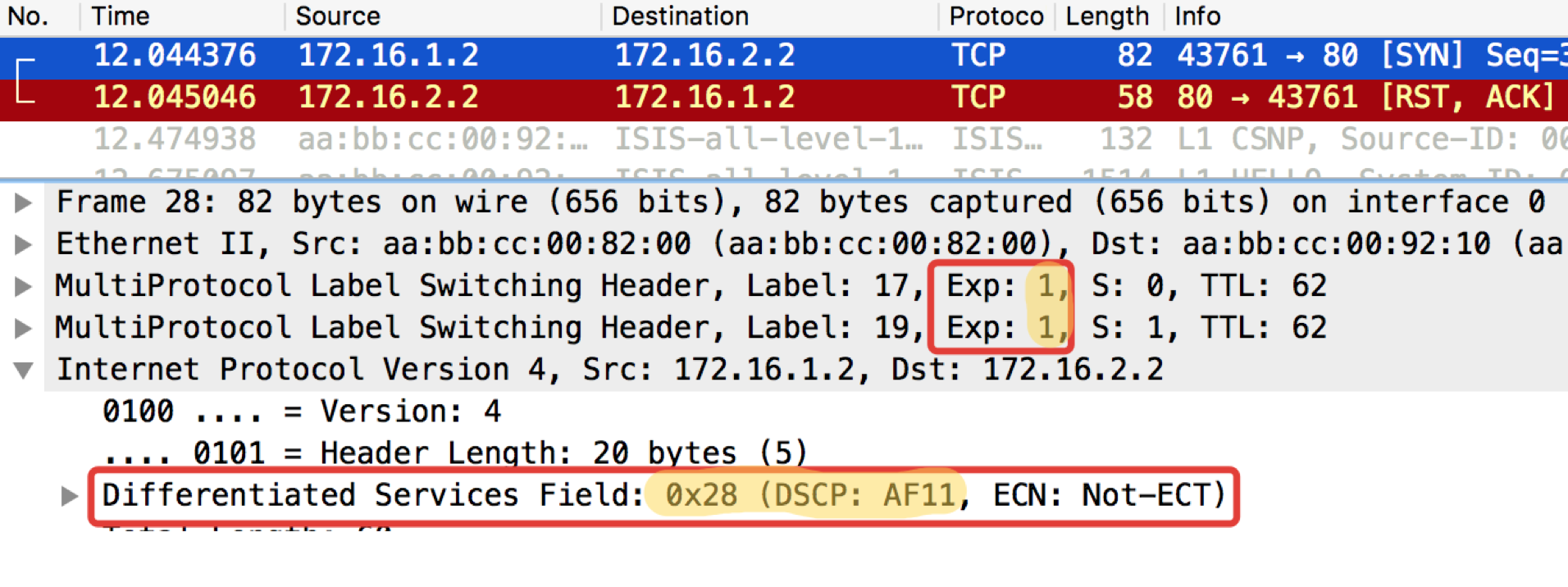 pcapng
pcapng阅读-什么和要求期望。 TCP作为AF11传输。
下一个测试将测试UDP,根据我们的分类器,它应该转到CS0。 我们将为此使用iperf(通过Apps将其引入Linux Tiny Core)。 在远程端
iperf3 -s-启动服务器,在本地
iperf3 -c -u -t1-客户端(
-c ),UDP协议(
-u )上,测试1秒钟(
-t1 )。
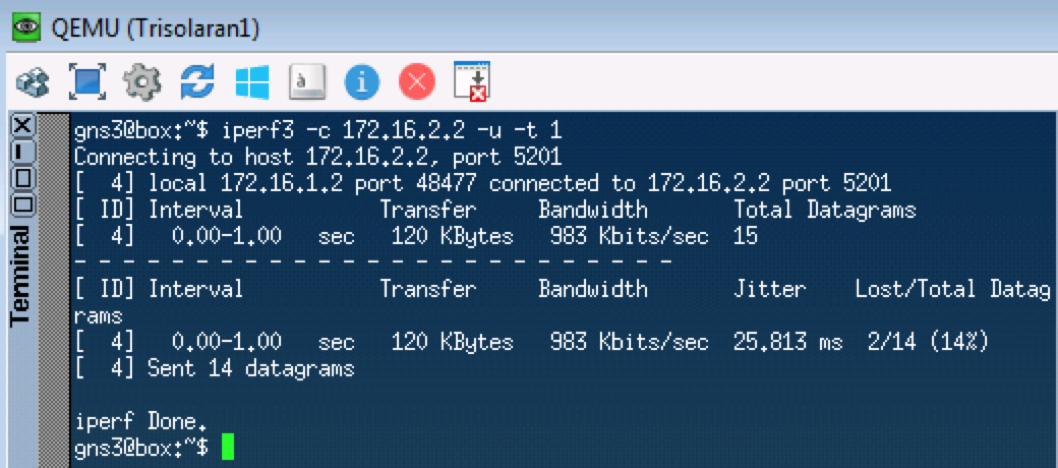 Linkmeup_R1。 E0 / 0。
Linkmeup_R1。 E0 / 0。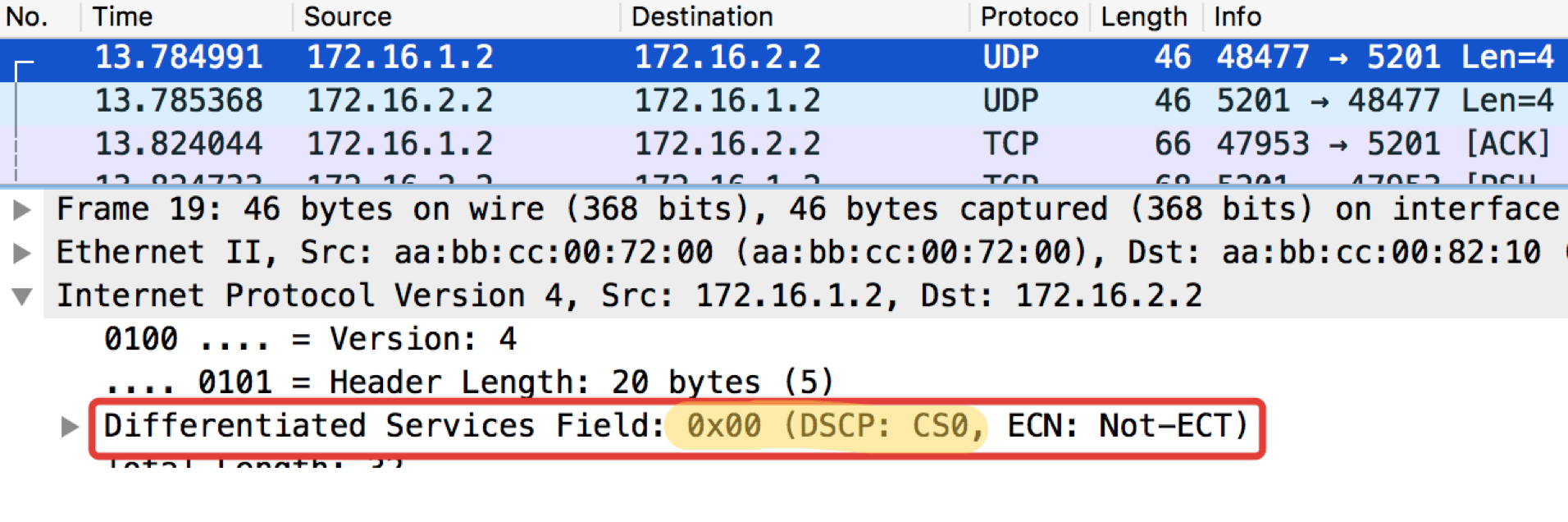 pcapngLinkmeup_R2。 E0 / 0
pcapngLinkmeup_R2。 E0 / 0 pcapng
pcapng从现在开始,将根据配置的规则对进入此界面的所有内容进行分类。
在设备内部标记
再次:在DS域分类的入口处可以发生MF,基于接口或BA。
在DS域的节点之间,标头中的数据包带有有关所需服务等级的标志,并由BA分类。
无论采用哪种分类方法,在包装之后,都将在设备内为包装分配内部类,并根据该内部类对其进行处理。 标头被删除,裸包(否)到达出口。
在输出处,内部类将转换为新标头的CoS字段。
也就是说,标题1⇒分类⇒内部服务等级⇒标题2。
在某些情况下,您需要在另一个协议的标头字段中显示一个协议的标头字段,例如,“流量类别”中的DSCP。
这仅通过中间内部标记发生。
例如,DSCP标题⇒分类⇒内部服务等级⇒交通等级标题。
形式上,内部类可以随意调用,也可以简单地编号,并且它们仅分配有一定的队列。
在本文深入探讨时,无论它们叫什么都无所谓,重要的是将特定的行为模型与QoS字段的特定值相关联。
如果我们正在谈论特定的QoS实现,则设备可以提供的服务类别的数量不超过可用队列的数量。 通常有八种(在国际植检门户网站的影响下,有时甚至是未经书面同意)。 但是,取决于供应商,设备,板,它们可以更多或更少。
也就是说,如果有4个队列,那么服务类根本就没有意义要做四个以上的队列。
让我们在硬件一章中更详细地讨论这一点。
如果您仍然真的想要一点特殊性...乍看起来,下表似乎对QoS字段和内部类之间的关系似乎很方便,但是在调用类PHB名称时,它们有些误导。 尽管如此,PHB是将哪种行为模型分配给特定类别的流量,大致来说,其名称是任意的。
因此,请持怀疑态度参阅下表(因此,在扰流板之下)。
以华为为例 。 在这里,Service-Class是包的非常内部的类。
也就是说,如果在输入中将BA分类,则DSCP值将转换为相应的Service-Class和Color值。

值得注意的是,没有使用许多DSCP值,而带有此类标记的数据包实际上被视为BE。
这是一个向后匹配表,显示重新标记输出时将为通信设置哪些DSCP值。

请注意,只有AF具有颜色渐变。 BE,EF,CS6,CS7-全部为绿色。
该表用于将IPP,MPLS流量类别和802.1p以太网字段转换为内部服务类别。

再回来

注意,关于丢弃优先级的任何信息通常都会在此处丢失。
应该重复进行-这只是
随机选择的供应商提供的默认匹配的一个具体示例。 对于其他人,这可能有所不同。 管理员可以在其网络上配置完全不同的服务和PHB类。
就PHB而言,用于分类的DSCP,流量类别,802.1p绝对没有区别。
在设备内部,它们变成了网络管理员定义的流量类别。
也就是说,所有这些标记都是一种告诉邻居应将其分配给此服务包的服务等级的方法。 就像BGP社区一样,它本身并不意味着任何东西,除非在网络上定义了解释它们的策略。
IETF建议(流量类别,服务等级和行为)
标准并没有完全标准化应该存在哪些特定服务类别,如何对它们进行分类和标记以及将哪些PHB应用于它们。
这受供应商和网络管理员的控制。
我们只有3位-我们可以根据需要使用。
这很好:
- 每块铁(供应商)独立选择用于PHB的机制-无信号,无兼容性问题。
- 每个网络的管理员可以灵活地在不同类别之间分配流量,选择类别本身和相应的PHB。
这很不好:
- 在DS域的边界,出现转换问题。
- 在完全行动自由的条件下-有些在森林里,有些是恶魔。
因此,IETF在2006年发布了有关如何实现服务差异化的培训手册:
RFC 4594 (
DiffServ服务类别的配置指南 )。
以下是此RFC的简要摘要。
行为模型(PHB)
DF-默认转发标准出货。如果未专门为流量模型分配行为模型,则将使用默认转发对其进行处理。
这是尽力而为-该设备将尽一切可能,但不能保证任何事情。 可能会出现掉落,混乱,不可预测的延迟和浮动抖动,但这并不准确。
该模型适用于要求不高的应用程序,例如邮件或文件下载。
顺便说一句,有PHB甚至更不确定
-A努力 。
AF-保证转发保证发货。这是一种改进的BE。 一些保证出现在这里,例如带。 下降和浮动延迟仍然可能,但程度要小得多。
该模型适用于多媒体:流媒体,视频会议,在线游戏。
RFC 2597 (
保证转发PHB组 )。
EF-快速转发紧急运送。所有资源和优先事项都涌向这里。 该模型适用于不需要损耗,短延迟,稳定抖动但对带宽不贪婪的应用。 例如,电话或有线仿真服务(CES-电路仿真服务)。
EF的损失,混乱和浮动延迟极不可能。
RFC 3246 (
快速转发PHB )。
CS-类选择器这些行为旨在维护具有DS功能的网络中与IP优先级的向后兼容性。
IPP中存在以下类别:CS0,CS1,CS2,CS3,CS4,CS5,CS6,CS7。
并非所有人都总是有一个单独的PHB,通常有两个或三个,然后将其余的简单地转换为最近的DSCP类并获得相应的PHB。
因此,例如,标记为CS 011000的数据包可以分类为011010。
当然,在CS中,仅将推荐用于NCP(网络控制协议)且需要单独PHB的CS6,CS7保留在设备中。
像EF一样,PHB CS6.7设计用于具有很高的延迟和损耗要求,但在一定程度上可以容忍频带歧视的类。
用于CS6.7的PHB的任务是提供一种服务级别,即使在接口,芯片和队列极度过载的情况下,也可以消除丢弃和延迟。
重要的是要了解PHB是一个抽象概念-实际上,它们是通过实际设备上可用的机制来实现的。
因此,在DS域中定义的相同PHB在Juniper和华为上可能有所不同。
此外,单个PHB并不是一组静态的操作;例如,PHB AF可能包含几个选项,这些选项的保证级别(带宽,可接受的延迟)不同。
服务等级
IETF照顾了管理员,并确定了应用程序的主要类别及其服务类别。
我在这里不会太冗长,仅插入本准则RFC中的几版。应用类别: 对网络特性的要求:
对网络特性的要求: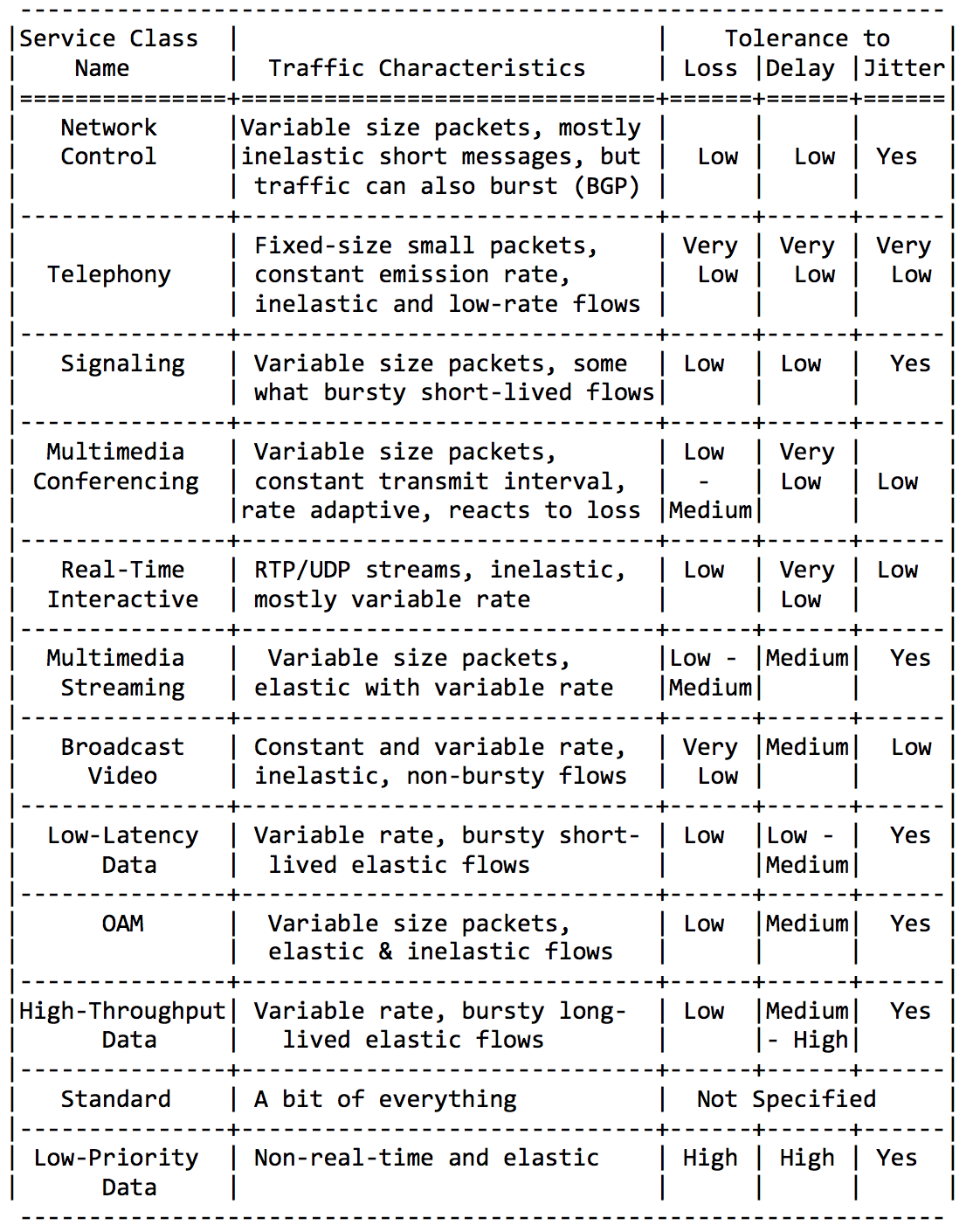 最后,推荐类名称和相应的DSCP值:
最后,推荐类名称和相应的DSCP值: 通过以不同方式组合上述类(以适应8种可用的类型),您可以获得适用于不同网络的QoS解决方案。也许最常见的是:
通过以不同方式组合上述类(以适应8种可用的类型),您可以获得适用于不同网络的QoS解决方案。也许最常见的是: DF(或BE)类标记的流量绝对不高-它在剩余的基础上受到关注。PHB AF服务于AF1,AF2,AF3,AF4类。他们都需要提供一条通道,以免造成延误和损失。丢失由丢弃优先级位控制,这就是为什么将它们称为AFxy的原因,其中x是服务级别,y是丢弃优先级。EF需要某种最小频带保证,但更重要的是-保证延迟,抖动和无损失。CS6,CS7甚至需要更少的带宽,因为这是服务包的细流,其中仍然可能发生突发(例如BGP Update),但是其中的损失和延迟是不可接受的-如果Hello崩溃,BFD使用10 ms的定时器是什么100毫秒队列?也就是说,在AF下提供了8个可用课程中的4个。尽管事实上它们通常只是这样做,但我再说一遍,这些只是建议,没有什么可以阻止DS域中的三个类分配EF,而只有两个分配AF。
DF(或BE)类标记的流量绝对不高-它在剩余的基础上受到关注。PHB AF服务于AF1,AF2,AF3,AF4类。他们都需要提供一条通道,以免造成延误和损失。丢失由丢弃优先级位控制,这就是为什么将它们称为AFxy的原因,其中x是服务级别,y是丢弃优先级。EF需要某种最小频带保证,但更重要的是-保证延迟,抖动和无损失。CS6,CS7甚至需要更少的带宽,因为这是服务包的细流,其中仍然可能发生突发(例如BGP Update),但是其中的损失和延迟是不可接受的-如果Hello崩溃,BFD使用10 ms的定时器是什么100毫秒队列?也就是说,在AF下提供了8个可用课程中的4个。尽管事实上它们通常只是这样做,但我再说一遍,这些只是建议,没有什么可以阻止DS域中的三个类分配EF,而只有两个分配AF。
分类汇总
在节点的入口处,根据接口,MF或其标签(BA)对包装进行分类。标签是IPv4中DSCP字段的值,IPv6中通信类的值以及802.1q中MPLS或802.1p的值。有8种服务类别,可汇总各种流量。每个班级都有自己的PHB,可以满足班级的要求。根据IETF的建议,区分以下服务类别:CS1,CS0,AF11,AF12,AF13,AF21,CS2,AF22,AF23,CS3,AF31,AF32,AF33,CS4,AF41,AF42,AF43,CS5,EF,CS6, CS7在交通中的重要性越来越高。从中可以选择8的组合,这些组合实际上可以编码为CoS字段。最常见的组合:CS0,AF1,AF2,AF3,AF4,EF,CS6,CS7,具有3种用于AF的颜色等级。每个类别都分配有一个PHB,其中PHB的严重性从高到低依次为3-默认转发,保证转发,快速转发。除了PHB类选择器。每个PHB可能因工具参数而异,但稍后会更多。
他们说,在无负载的网络上,不需要QoS。他们说,通过扩展链接可以解决任何QoS问题。他们说,有了以太网和DWDM,我们将永远不会遇到线路拥塞的情况。他们是那些不了解什么是QoS的人。但是现实打击了ILV上的VPN。- 并非到处都有光学器件。RRL是我们的现实。有时,在事故发生时(不仅如此),在狭窄的无线电链路中,希望抓取所有网络流量。
- 交通突发是我们的现实。短期流量突发很容易排队,从而迫使丢弃非常必要的数据包。
- 电话,视频会议,在线游戏是我们的现实。如果队列至少有点忙,延迟就会开始。
在我的实践中,有一些示例在网络负载不超过40%的情况下将电话转换为摩尔斯电码。只需在EF中重新标记即可立即解决该问题。
是时候使用允许您为不同的类提供不同的服务的工具了。
PHB工具
实际上,只有三组QoS工具可以有效地操作程序包:- 避免拥塞-要做的事还不错。
- 拥塞管理-已经很糟糕时该怎么办。
- 速率限制-如何在网络上不增加过多的内容,如何释放不可接受的内容。
但是,如果不是要排队的话,所有这些都将毫无用处。5.队列
在游乐园中,如果您不为付更多钱的人安排单独的队列,就不能给予某人优先权。网络中的情况相同。如果所有流量都在一个队列中,则您将无法从其中间拉出重要数据包以使其具有优先级。这就是为什么在分类之后将数据包放置在与此类别相对应的队列中。然后,一个队列(带有语音数据)将快速移动,但带宽有限,另一队列变慢(流),但带宽较大,并且某些资源将根据剩余原理移动。但是在每个单独队列的限制内,应用相同的规则-您不能从中间提取数据包-只能从其头部提取数据包。每个队列都有一定的限制长度。一方面,这是由硬件限制决定的,另一方面,将数据包保留在队列中的时间过长是没有意义的。如果VoIP数据包延迟了200毫秒,则不需要此数据包。 RTT到期(在sysctl中配置)后,TCP将有条件地请求转发。因此,丢弃并不总是坏的。网络设备的开发人员和设计人员必须在尝试尽可能长时间保存程序包与试图避免浪费带宽,尝试提供不再需要的程序包之间寻求折衷。在正常情况下,当接口/芯片未过载时,缓冲区利用率接近零。它们吸收短期爆发,但这不会导致其长时间充盈。如果流量超出交换芯片或输出接口的处理能力,则队列开始占满。超过20-30%的长期利用率已经是需要解决的情况。
6.避免拥塞
在任何路由器的生命周期中,都会出现队列已满的情况。将包裹放在哪里,如果绝对没有地方可放-就是这样,缓冲区已经过去了,即使看起来不错,即使您支付了额外的费用,缓冲区也不会在那里。有两种方法:要么丢弃此数据包,要么丢弃已经转弯的数据包。如果这些已经在队列中,请考虑缺少什么。如果是这样,那就认为他没有来。这两种方法称为“ 尾巴掉落”和“ 头部掉落”。尾巴和头部掉落
尾部丢弃 -最简单的队列管理机制-丢弃所有不适合缓冲区的新到达数据包。 Head Drop丢弃已排队很长时间的数据包。最好将它们丢弃而不是保存,因为它们很可能毫无用处。但是,到达队列末尾的相关性更高的软件包将有更多机会按时到达。另外,Head Drop允许您不使用不必要的程序包加载网络。自然,最早的软件包是那些位于队列开头的软件包,因此是方法的名称。
Head Drop丢弃已排队很长时间的数据包。最好将它们丢弃而不是保存,因为它们很可能毫无用处。但是,到达队列末尾的相关性更高的软件包将有更多机会按时到达。另外,Head Drop允许您不使用不必要的程序包加载网络。自然,最早的软件包是那些位于队列开头的软件包,因此是方法的名称。 丢头还有另一个明显的优点-如果您在队列开始处丢弃数据包,接收者将迅速发现网络上的拥塞并通知发送者。对于“尾巴丢弃”,有关丢弃的数据包的信息可能会在数百毫秒后到达-直到从行尾到她的头部为止。两种机制依次与差异化协同工作。也就是说,实际上,不必整个缓冲区都已满。如果第二个队列为空,而零队列为零,则仅丢弃从零开始的数据包。
丢头还有另一个明显的优点-如果您在队列开始处丢弃数据包,接收者将迅速发现网络上的拥塞并通知发送者。对于“尾巴丢弃”,有关丢弃的数据包的信息可能会在数百毫秒后到达-直到从行尾到她的头部为止。两种机制依次与差异化协同工作。也就是说,实际上,不必整个缓冲区都已满。如果第二个队列为空,而零队列为零,则仅丢弃从零开始的数据包。 尾部下降和头部下降可以同时工作。
尾部下降和头部下降可以同时工作。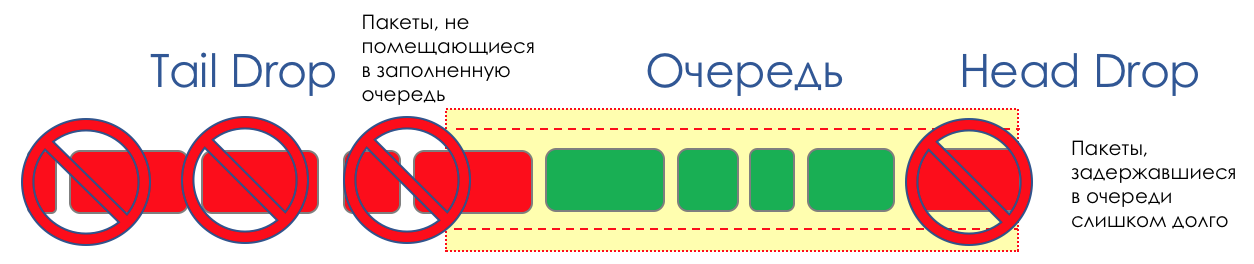
尾巴和头部掉落是避免拥塞的“前额”。您甚至可以说-这是他的缺席。在队列100%充满之前,我们什么也不做。之后,我们开始丢弃所有新到达(或延迟很长时间)的数据包。如果您不需要采取任何措施来实现目标,那么在某处会有细微差别。而这种细微差别就是TCP。回想一下(更深入,更深入)TCP如何工作-我们正在谈论现代实现。有一个滑动窗口(滑动窗口或rwnd-收件人的广告窗口),由接收者控制,告诉发送者可以发送多少。并且有一个过载窗口(CWND-拥塞窗口),它可以响应网络问题并由发送方控制。数据传输过程以CWND呈指数增长的慢启动(Slow Start)开始。对于每个确认的段,将1个MSS大小添加到CWND,实际上,它在等于RTT(数据在那里,ACK返回)的时间内加倍(有关Reno / NewReno的语音)。举个例子
 指数增长继续达到称为ssthreshold(慢启动阈值)的值,该值在主机的TCP配置中指定。接下来,对于每个已确认的分段,将开始线性增长1 / CWND,直到其抵御RWND或开始亏损(通过重新确认(重复ACK)或完全没有确认的损失)。一旦检测到段丢失,就会发生TCP Backoff -TCP大大减小了窗口,实际上降低了发送速度-并且快速恢复机制启动:
指数增长继续达到称为ssthreshold(慢启动阈值)的值,该值在主机的TCP配置中指定。接下来,对于每个已确认的分段,将开始线性增长1 / CWND,直到其抵御RWND或开始亏损(通过重新确认(重复ACK)或完全没有确认的损失)。一旦检测到段丢失,就会发生TCP Backoff -TCP大大减小了窗口,实际上降低了发送速度-并且快速恢复机制启动:- 发送丢失的段(快速重传),
- 窗户翻了一倍,
- ssthreshold值也等于所到达窗口的一半,
- 线性增长再次开始,直到第一次亏损,
- 再说一次
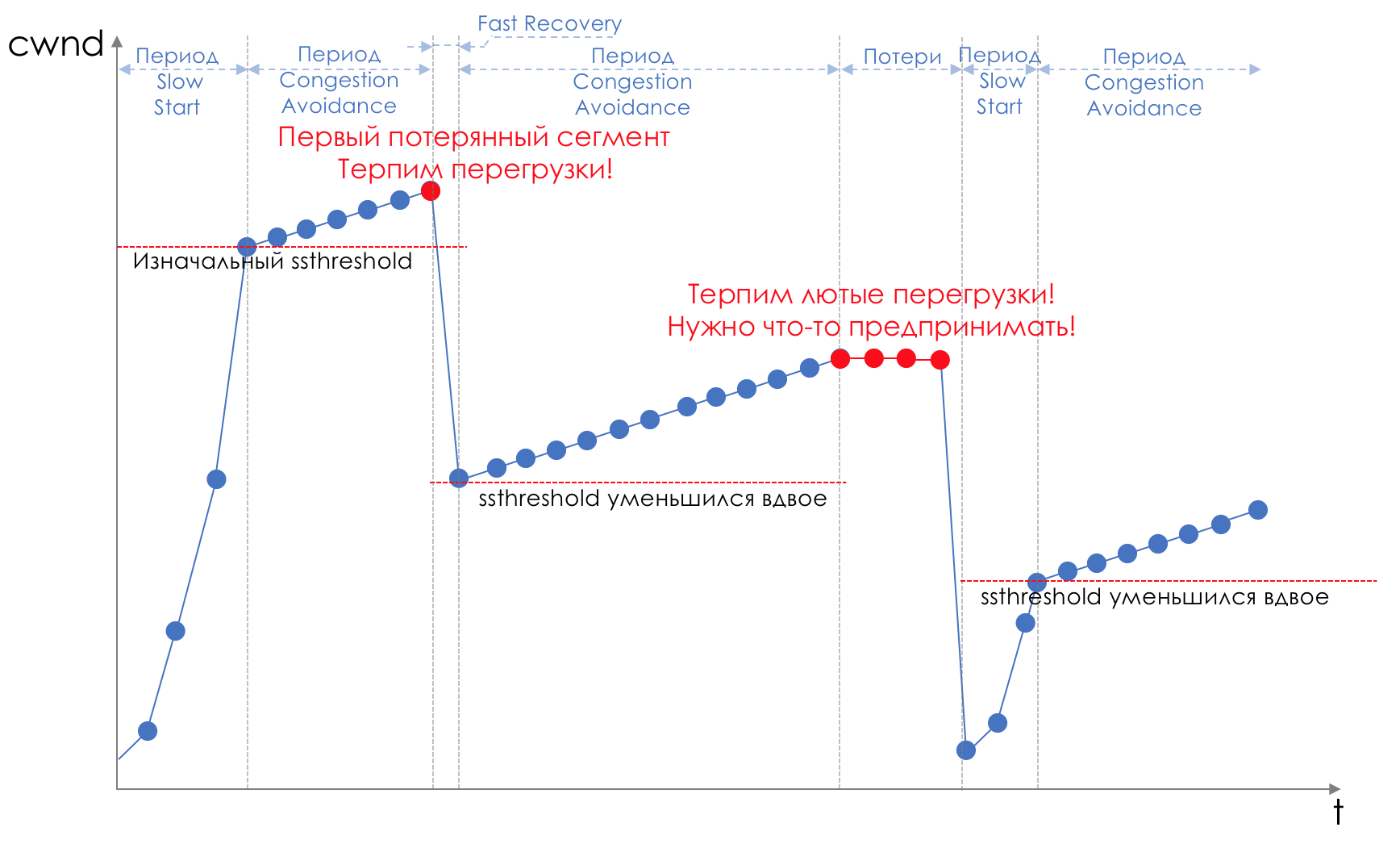 丢失可能意味着某个网络段完全崩溃,然后认为它已丢失,或者线路拥塞(读取缓冲区溢出并丢弃此会话的一部分)。这是TCP最大限度地利用可用带宽并处理拥塞的方法。而且非常有效。但是,拖尾会导致什么?
丢失可能意味着某个网络段完全崩溃,然后认为它已丢失,或者线路拥塞(读取缓冲区溢出并丢弃此会话的一部分)。这是TCP最大限度地利用可用带宽并处理拥塞的方法。而且非常有效。但是,拖尾会导致什么?- 假设通过路由器存在数千个TCP会话的路径。在某个时刻,会话流量达到1.1 Gb / s,输出接口速度-1 Gb / s。
- 交通自带快于叶,缓冲区已填满vsklyan。
- 启用尾部丢弃功能,直到调度员从队列中取出一些数据包为止。
- Fast Recovery ( Slow Start).
- , , Tail Drop .
- TCP- , .
- .
- Fast Recovery/Slow Start.
- .
了解有关RFC 2001中 TCP机制更改的更多信息(TCP慢启动,拥塞避免,快速重传和快速恢复算法)。这是一种称为“ 全局TCP同步: 全局 ”的情况的典型说明,因为通过此节点建立的许多会话都会受到影响。同步,因为它们同时受苦。情况将一直重复,直到出现过载为止。TCP-因为没有拥塞控制机制的UDP不受它的影响。在这种情况下,如果不引起条带的次优使用(锯齿之间的缝隙)和浪费的钱,就不会有任何不好的事情发生。第二个问题是TCP饥饿 -TCP耗尽。尽管TCP放慢了速度以减轻负载(首先不让我们拆开-首先,一定要传输数据),但UDP,数据报一般会带来的所有道德苦难-会发送尽可能多的内容。因此,减少了TCP流量,并且UDP不断增长(可能),下一个丢失周期-快速恢复发生在较低的阈值。 UDP占用空间。 TCP流量总量下降。如何解决问题,最好避免。让我们尝试使用快速恢复/缓慢启动来减少在队列填满之前的负载,这对我们不利。
全局 ”的情况的典型说明,因为通过此节点建立的许多会话都会受到影响。同步,因为它们同时受苦。情况将一直重复,直到出现过载为止。TCP-因为没有拥塞控制机制的UDP不受它的影响。在这种情况下,如果不引起条带的次优使用(锯齿之间的缝隙)和浪费的钱,就不会有任何不好的事情发生。第二个问题是TCP饥饿 -TCP耗尽。尽管TCP放慢了速度以减轻负载(首先不让我们拆开-首先,一定要传输数据),但UDP,数据报一般会带来的所有道德苦难-会发送尽可能多的内容。因此,减少了TCP流量,并且UDP不断增长(可能),下一个丢失周期-快速恢复发生在较低的阈值。 UDP占用空间。 TCP流量总量下降。如何解决问题,最好避免。让我们尝试使用快速恢复/缓慢启动来减少在队列填满之前的负载,这对我们不利。RED-随机早期检测
但是,如果我们在缓冲区的某些部分上拍摄并涂抹了液滴,该怎么办?相对而言,当队列已满80%时,开始丢弃随机数据包,从而迫使某些TCP会话减少窗口并相应地降低速度。如果队列已满90%,我们将开始随机丢弃50%的数据包。90%-概率增加到“尾巴丢弃”(100%的新数据包被丢弃)。实现这种队列管理的机制称为AQM-自适应(或活动)队列管理,这就是RED的工作方式。早期检测 -解决潜在的过载;随机 - 随机丢弃数据包。有时它们会像随机随机早期丢弃一样解码RED(在我看来,从语义上来说更正确)。从图形上看,它看起来像这样: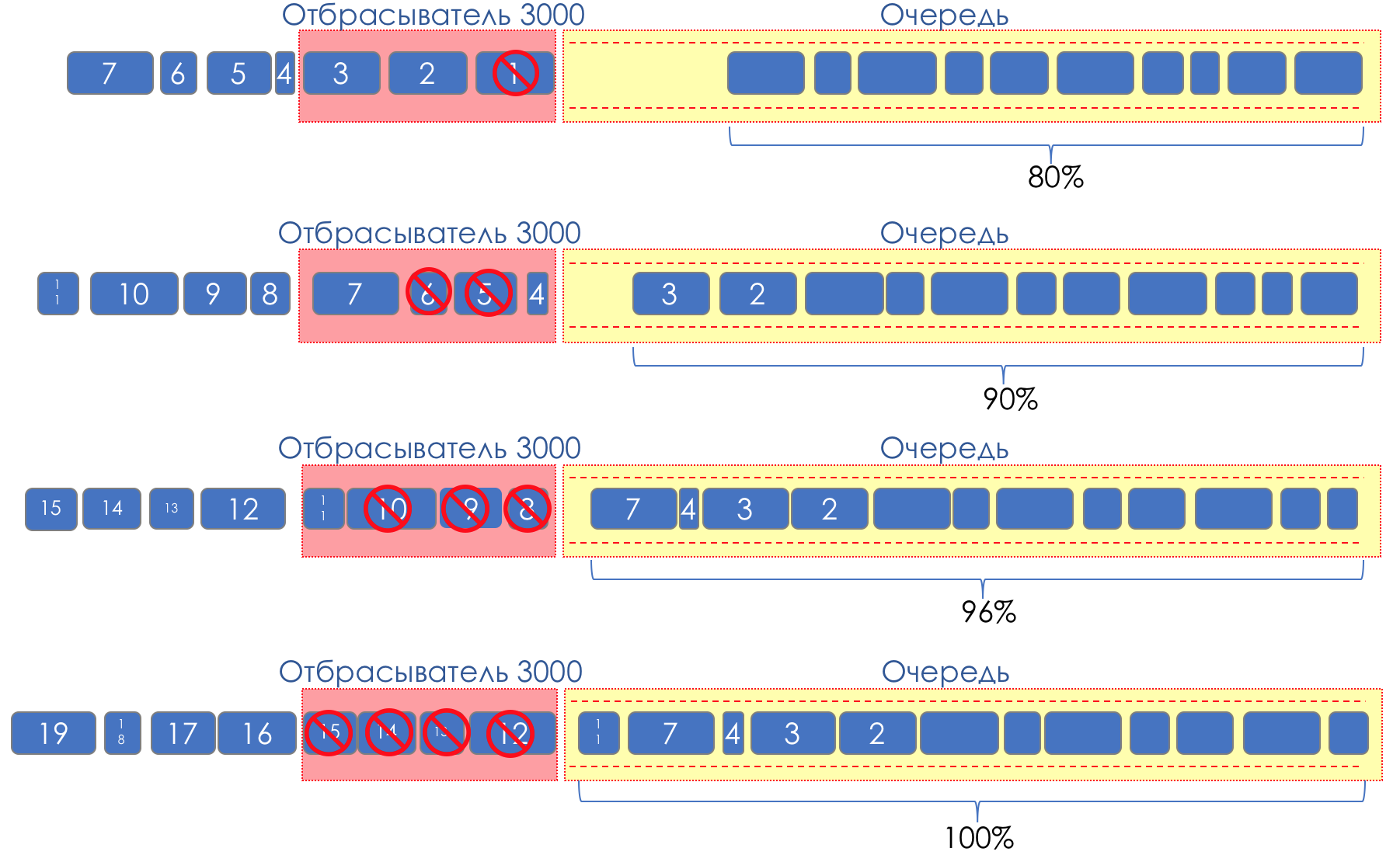
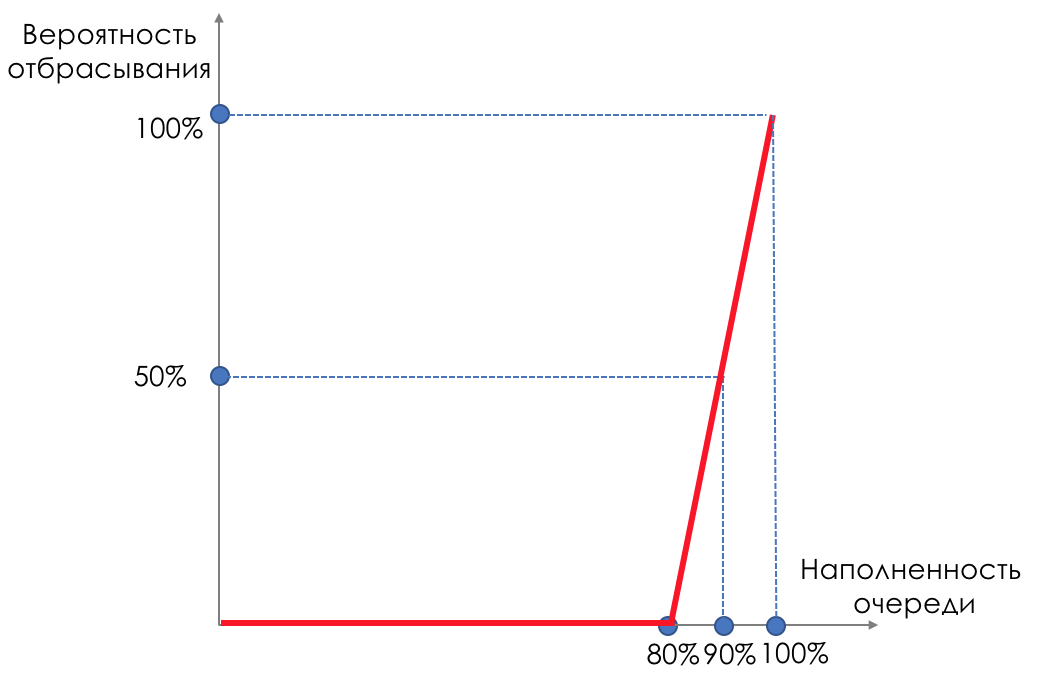 在缓冲区满80%之前,不会完全丢弃数据包-概率为0%。从80到100个数据包开始被丢弃,并且队列填充的次数越多,该数据包就越高。因此百分比从0增加到30。RED的副作用是,激进的TCP会话更有可能减慢速度,这仅仅是因为有很多数据包,而且它们很有可能被丢弃。使用RED胶条的效率低下,可通过钝化较小部分的牙齿,而不会引起牙齿之间的严重牵伸而解决。正是出于同样的原因,UDP无法占据所有内容。
在缓冲区满80%之前,不会完全丢弃数据包-概率为0%。从80到100个数据包开始被丢弃,并且队列填充的次数越多,该数据包就越高。因此百分比从0增加到30。RED的副作用是,激进的TCP会话更有可能减慢速度,这仅仅是因为有很多数据包,而且它们很有可能被丢弃。使用RED胶条的效率低下,可通过钝化较小部分的牙齿,而不会引起牙齿之间的严重牵伸而解决。正是出于同样的原因,UDP无法占据所有内容。WRED-加权随机早期检测
但是在所有人的听证中,可能仍然是WRED。敏锐的linkmeup读者已经建议这是相同的RED,但要依次加权。而且他不太正确。RED在同一队列中操作。如果BE已满,则回顾EF没有任何意义。因此,依次称重不会带来任何东西。在这里,丢弃优先权才有效。在同一队列中,具有不同丢弃优先级的数据包将具有不同的曲线。优先级越低,就越有可能遭到抨击。 这里有3条曲线:红色-优先级较低的流量(根据丢弃),黄色-优先级较高,绿色-最大。当缓冲区已满20%时,红色流量开始被丢弃,从20降低到40,然后下降到20%,然后是尾部丢弃。黄色从稍后开始-从30到50,最多丢弃10%,然后-拖尾。绿色是最不易受影响的:从50到100,它可以平滑增长到5%。接下来是尾巴掉落。对于DSCP,可能是AF11,AF12和AF13,分别是绿色,黄色和红色。
这里有3条曲线:红色-优先级较低的流量(根据丢弃),黄色-优先级较高,绿色-最大。当缓冲区已满20%时,红色流量开始被丢弃,从20降低到40,然后下降到20%,然后是尾部丢弃。黄色从稍后开始-从30到50,最多丢弃10%,然后-拖尾。绿色是最不易受影响的:从50到100,它可以平滑增长到5%。接下来是尾巴掉落。对于DSCP,可能是AF11,AF12和AF13,分别是绿色,黄色和红色。 在这里,它与TCP一起使用非常重要,并且绝对不适用于UDP。或者,使用UDP的应用程序会忽略损失,例如电话或视频流,这会对用户的观看体验产生负面影响。或者应用程序本身控制交付,并要求您重新发送相同的程序包。但是,不必要求信号源降低传输速率。而不是减少负载,而是由于重传而增加。这就是为什么只有尾巴落下用于EF的原因。对于CS6,CS7,还使用了“尾巴掉落”,因为没有假定高速,并且WRED无法解决任何问题。对于AF,将应用WRED。 AFxy,其中x是服务的类别,即服务所属的队列,而y是放置优先级-相同的颜色。对于BE,将基于此队列中的主要流量来做出决策。在单个路由器中,使用了特殊的内部数据包标签,与承载标头的标签不同。因此,无法在丢弃优先级进行编码的MPLS和802.1q可以在具有不同丢弃优先级的队列中进行处理。例如,一个MPLS数据包到达一个节点,它不带有Drop Precedence标签,但是根据抛光的结果,它变成黄色,可以在放入队列之前被丢弃(可以由Traffic Class字段确定)。值得记住的是,整个彩虹只存在于节点内部。邻居之间的线没有颜色的概念。当然,尽管可以在DSCP的“丢弃优先级”部分中编码颜色。
在这里,它与TCP一起使用非常重要,并且绝对不适用于UDP。或者,使用UDP的应用程序会忽略损失,例如电话或视频流,这会对用户的观看体验产生负面影响。或者应用程序本身控制交付,并要求您重新发送相同的程序包。但是,不必要求信号源降低传输速率。而不是减少负载,而是由于重传而增加。这就是为什么只有尾巴落下用于EF的原因。对于CS6,CS7,还使用了“尾巴掉落”,因为没有假定高速,并且WRED无法解决任何问题。对于AF,将应用WRED。 AFxy,其中x是服务的类别,即服务所属的队列,而y是放置优先级-相同的颜色。对于BE,将基于此队列中的主要流量来做出决策。在单个路由器中,使用了特殊的内部数据包标签,与承载标头的标签不同。因此,无法在丢弃优先级进行编码的MPLS和802.1q可以在具有不同丢弃优先级的队列中进行处理。例如,一个MPLS数据包到达一个节点,它不带有Drop Precedence标签,但是根据抛光的结果,它变成黄色,可以在放入队列之前被丢弃(可以由Traffic Class字段确定)。值得记住的是,整个彩虹只存在于节点内部。邻居之间的线没有颜色的概念。当然,尽管可以在DSCP的“丢弃优先级”部分中编码颜色。丢弃也可能出现在未加载的网络中,在该网络中似乎没有队列溢出。 怎么了
造成这种情况的原因可能是流量短暂爆发。最简单的示例-同时有5个应用程序决定将流量传输到一个终端主机。
一个例子更加复杂-发送器通过10 Gb / s接口连接,接收器为1 Gb / s。环境本身使您可以在发件人上更快地制作包裹。接收器的以太网流控制请求最近的主机减速,并且数据包开始在缓冲区中累积。
好吧,当情况变得更糟时该怎么办?7.拥塞管理
当一切都不好时,应将处理优先级分配给更重要的流量。每个包装的重要性在分类阶段确定。但是什么不好呢?并非所有缓冲区都需要阻塞才能使应用程序开始遇到问题。最简单的示例是语音数据包,该语音数据包挤满了正在下载文件的应用程序的大包大包。这将增加延迟,破坏抖动,并可能导致掉线。也就是说,在没有实际拥塞的情况下,我们在提供优质服务方面存在问题。此问题旨在解决拥塞管理机制。如上所述,不同应用程序的流量分为多个队列。但只有这样,所有内容都应再次合并为一个接口。序列化仍然依序进行。不同的队列如何管理以提供不同级别的服务?以不同的方式从不同的队列中删除数据包。调度员参与其中。从最简单的开始,我们将考虑当今的大多数调度员:- FIFO-仅一行,BE,C中的所有内容-不公正。
- PQ-通往寡头,走狗的道路让步。
- FQ-全部相等。
- DWRR-都相等,但有些甚至更均匀。
FIFO-先进先出
实际上,最简单的情况是没有QoS,即所有流量都以相同的方式处理-在一个队列中。数据包完全按照到达队列的顺序离开队列,因此名称为:第一次进入-首先并且离开。FIFO既不是真正意义上的调度程序,也不是DiffServ机制,因为它实际上并不分离类。如果队列开始填满,延迟和抖动开始增加,则您将无法对其进行管理,因为您无法从队列中间拉出重要的数据包。数据包大小为1,500字节的激进TCP会话可能会占用整个队列,从而导致较小的语音数据包受损。在FIFO中,所有类都合并到CS0中。 但是,尽管存在所有这些缺点,但现在这就是Internet的工作方式。现在,大多数FIFO供应商都是默认的调度程序,其中一个队列用于所有传输流量,而另一个队列用于本地生成的服务数据包。很简单,很便宜。如果渠道很宽而且流量很少,那么一切都很好。QoS(针对穷人)扩大了带宽范围,客户将得到满足,您的薪水将成倍增长,这是最典型的想法。只有这样,网络设备才能正常工作。但是很快世界就面临着一个事实,那就是根本无法解决问题。随着融合网络的发展趋势,很明显,不同类型的流量(服务,语音,多媒体,互联网冲浪,文件共享)具有根本不同的网络要求。FIFO不够,因此他们创建了多个队列并开始制定流量调度方案。但是,FIFO永远不会消失:在每个队列中,始终根据FIFO原则处理数据包。
但是,尽管存在所有这些缺点,但现在这就是Internet的工作方式。现在,大多数FIFO供应商都是默认的调度程序,其中一个队列用于所有传输流量,而另一个队列用于本地生成的服务数据包。很简单,很便宜。如果渠道很宽而且流量很少,那么一切都很好。QoS(针对穷人)扩大了带宽范围,客户将得到满足,您的薪水将成倍增长,这是最典型的想法。只有这样,网络设备才能正常工作。但是很快世界就面临着一个事实,那就是根本无法解决问题。随着融合网络的发展趋势,很明显,不同类型的流量(服务,语音,多媒体,互联网冲浪,文件共享)具有根本不同的网络要求。FIFO不够,因此他们创建了多个队列并开始制定流量调度方案。但是,FIFO永远不会消失:在每个队列中,始终根据FIFO原则处理数据包。PQ-优先排队
第二种最复杂的机制,是将服务划分为类的尝试是优先级队列。现在,根据类别-优先级(例如,尽管不一定,相同的BE,AF1-4,EF,CS6-7),将流量分配到几个队列中。调度程序经过另一个队列。首先,它会从优先级最高的队列中跳过所有数据包,然后从较少的队列中跳过,然后从较少的队列中跳过。以此类推。
在高优先级队列为空之前,调度程序不会开始检索低优先级数据包。 如果在处理低优先级数据包时,某个数据包到达了较高优先级队列,则调度程序将切换到该队列,并且只有在清空后,该调度程序才会返回到其他队列。
如果在处理低优先级数据包时,某个数据包到达了较高优先级队列,则调度程序将切换到该队列,并且只有在清空后,该调度程序才会返回到其他队列。 PQ的工作原理与FIFO差不多。对于协议包和语音之类的流量非常有用,在这些流量中,延迟至关重要,并且总流量不是很大。好吧,您必须承认,由于来自YouTube的几个大视频块,您不应该保持BFD Hello。但这就是缺少PQ的原因-如果优先级队列中加载了流量,调度程序将永远不会切换到其他队列。如果某个邪恶的医生在寻找征服世界的方法时,决定用最高的黑标来标记他的所有恶行,那么其他所有将尽职地等待然后被丢弃。也不必谈论每条线的保证车道。高优先级队列可以通过在其中处理的流量的速度来削减。这样别人就不会饿死了。但是,控制它并不容易。
PQ的工作原理与FIFO差不多。对于协议包和语音之类的流量非常有用,在这些流量中,延迟至关重要,并且总流量不是很大。好吧,您必须承认,由于来自YouTube的几个大视频块,您不应该保持BFD Hello。但这就是缺少PQ的原因-如果优先级队列中加载了流量,调度程序将永远不会切换到其他队列。如果某个邪恶的医生在寻找征服世界的方法时,决定用最高的黑标来标记他的所有恶行,那么其他所有将尽职地等待然后被丢弃。也不必谈论每条线的保证车道。高优先级队列可以通过在其中处理的流量的速度来削减。这样别人就不会饿死了。但是,控制它并不容易。
以下机制依次遍历所有队列,从它们中获取一定数量的数据,从而提供更为真实的条件。但他们的做法有所不同。公平排队
理想调度员的下一个竞争者是公平排队机制。FQ-公平排队
它的历史始于1985年,当时John Nagle建议为每个数据流创建一个队列。从本质上讲,这与IntServ方法很接近,并且很容易通过以下事实来解释:像DiffServ这样的服务类概念就不存在了。FQ从每个队列中依次提取相同数量的数据。诚实的事实在于,调度程序不是以数据包的数量进行操作,而是以每个队列可以传输的位数进行操作。因此,激进的TCP流无法淹没该接口,并且每个人都有平等的机会。从理论上讲。在实践中,FQ从未实现为在网络设备中分配队列的机制。有三个缺点:第一个-很明显-非常昂贵-为每个流启动一个队列,计算每个数据包的权重,并始终担心要跳过的位和数据包的大小。第二个-不那么明显-所有线程在带宽方面都有平等的机会。如果我想要不平等?第三点-不明显-FQ诚实是绝对的:每个人都有相同的延迟,但是有些线程比延迟更重要。例如,在256个流中有语音流,这意味着它们中的每个仅将到达256个线程中。不清楚如何处理它们。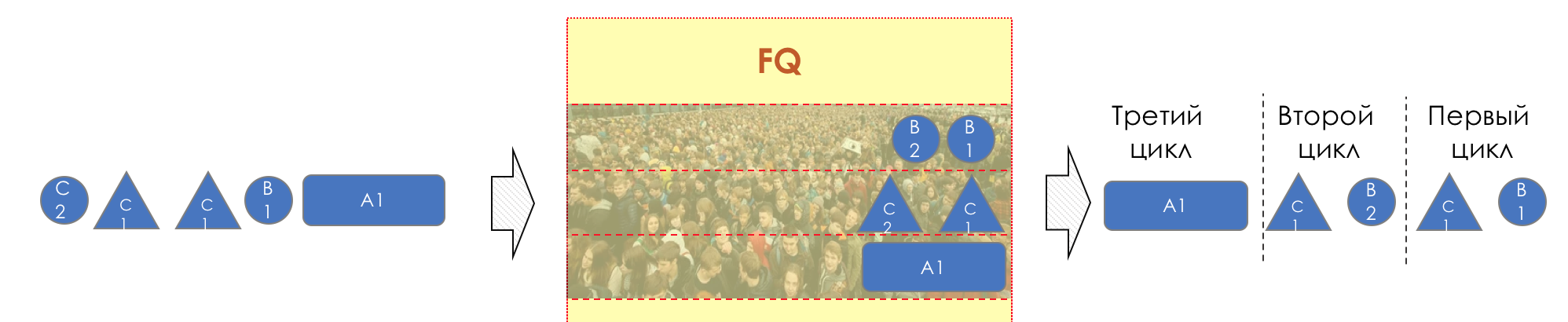 在这里您可以看到,由于第3阶段的数据包很大,在前两个周期中,我们处理了前两个数据包中的一个。对Round Robin和GPS的逐位机制的描述已经超出了本文的范围,我建议读者进行独立研究。
在这里您可以看到,由于第3阶段的数据包很大,在前两个周期中,我们处理了前两个数据包中的一个。对Round Robin和GPS的逐位机制的描述已经超出了本文的范围,我建议读者进行独立研究。WFQ-加权公平排队
FQ的第二个缺陷和第三个缺陷试图关闭1989年发布的WFQ。每个队列都被赋予权重,因此有权在一个周期内以权重的倍数分配流量。权重是根据两个参数计算得出的:仍然相关然后是IP优先级和数据包长度。在WFQ中,权重越大,效果越差。因此,IP优先级越高,数据包权重越低。包装尺寸越小,重量越轻。因此,高优先级的小数据包获得最多的资源,而低优先级的大数据包则在等待。在下面的图示中,数据包接收的权重如下:首先跳过来自第一个队列的一个数据包,然后跳过第二个队列的两个数据包,再次跳过第一个队列,然后才处理第三个队列。因此,例如,如果第二阶段中的数据包大小相对较小,则可能会发生这种情况。 关于WFQ的苛刻工程设计,其包完成时间,虚拟时间和假发定理,您可以阅读一个好奇的彩色文档。但是,这并没有解决第一个和第三个问题。基于流的方法也很不方便,需要短延迟和稳定抖动的流没有收到它们。但是,这并不能阻止WFQ在某些(大多数是旧的)Cisco设备中使用。最多有256个队列根据其标头的哈希值放置线程。基于流的范式和有限的资源之间的折衷。
关于WFQ的苛刻工程设计,其包完成时间,虚拟时间和假发定理,您可以阅读一个好奇的彩色文档。但是,这并没有解决第一个和第三个问题。基于流的方法也很不方便,需要短延迟和稳定抖动的流没有收到它们。但是,这并不能阻止WFQ在某些(大多数是旧的)Cisco设备中使用。最多有256个队列根据其标头的哈希值放置线程。基于流的范式和有限的资源之间的折衷。CBWFQ-基于类的WFQ
随着DiffServ的出现,CBWFQ提出了解决复杂性问题的方法。 “行为汇总”将所有流量类别分为8类,并因此将其分为队列。这给了他一个名字,大大简化了排队。CBWFQ中的权重具有不同的含义。应管理员的要求,在配置中将权重手动分配给类(不是线程),因为DSCP字段已经用于分类。也就是说,DSCP确定要放入哪个队列以及配置的权重-该队列可使用多少个通道。最重要的是,这间接地使生活变得更轻松和低延迟流,这些流现在聚集在一个(2-3个)队列中,并且更频繁地获得其高分。生活已经变得更好,但仍然不是很好-根本没有保证-总的来说,在WFQ中,就延误而言,一切仍然相等。并且,对包大小,包的碎片和碎片整理的持续监控的需求并没有消失。CBWFQ + LLQ-低延迟队列
最后的方法是逐位方法的最终结果,是CBWFQ与PQ的结合。队列之一成为所谓的LLQ(低延迟队列),而所有其他队列均由CBWFQ管理器处理,而PQ管理器则在LLQ与其余队列之间运行。也就是说,尽管LLQ中有数据包,但其余队列正在等待,但它们的延迟却在增加。LLQ中的数据包一经用完,我们便开始处理其余的数据包。数据包出现在LLQ中-他们忘记了剩下的,返回给它。FIFO也可以在LLQ内部使用,因此您不应该在没有到达那里就推销一切,同时增加缓冲区利用率和延迟。但是,为了使非优先级队列不会饿死,值得在LLQ中设置带宽限制。 因此,绵羊吃饱了,狼也很安全。
因此,绵羊吃饱了,狼也很安全。RR-轮循
与FQ同行和RR并驾齐驱。一个很诚实,但并不简单。另一个则相反。 RR经过队列,从队列中提取了相等数量的数据包。该方法比FQ更原始,因此在各种流程方面都不诚实。激进的资源很容易用1500字节大小的数据包淹没该条。但是,它实现起来非常简单-您无需知道队列中数据包的大小,对其进行分段然后将其收集回来。但是,他在地带分配上的不公正性阻碍了他通往世界的道路-在网络世界中,纯轮循并未得到实施。
RR经过队列,从队列中提取了相等数量的数据包。该方法比FQ更原始,因此在各种流程方面都不诚实。激进的资源很容易用1500字节大小的数据包淹没该条。但是,它实现起来非常简单-您无需知道队列中数据包的大小,对其进行分段然后将其收集回来。但是,他在地带分配上的不公正性阻碍了他通往世界的道路-在网络世界中,纯轮循并未得到实施。WRR-加权循环
WRR具有相同的命运,它基于IP优先级增加了队列的权重。在WRR中,不是取出相等数量的数据包,而是队列权重的倍数。可以为具有较小数据包的队列赋予更大的权重,但是动态地做到这一点是不可能的。
DWRR-赤字加权循环法
突然之间,M。Shreedhar和G. Varghese在1995年提出了一种非常奇怪的方法。每行都有一个单独的信用额度(以位为单位)。从队列中传递时,将发出尽可能多的信用包。从贷款额中减去队列开头的包裹大小。如果差异大于零,则删除此数据包并检查下一个数据包。因此直到差值小于零为止。如果即使第一个包裹也没有足够的信誉,well ,,,泥泞不堪,他仍然会排队。在下一次通过之前,每行的功劳会增加一定的量,称为量子。对于不同的队列,量子量是不同的-您需要赋予的频带越大,量子量就越大。因此,无论队列中数据包的大小如何,所有队列都将获得保证的带宽。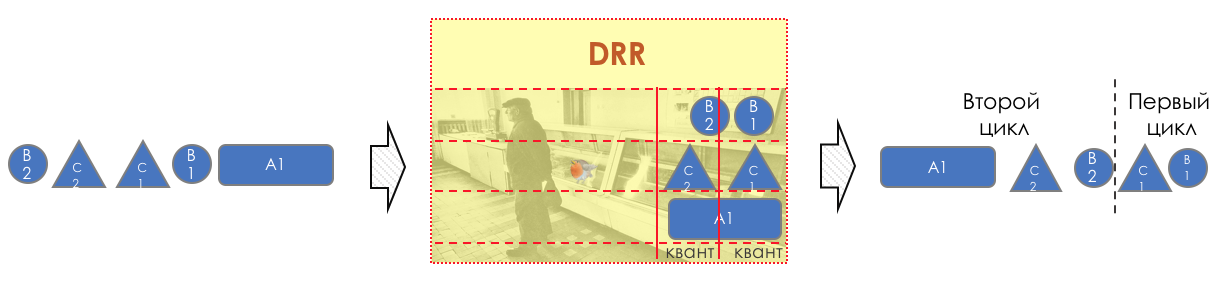 从上面的解释中,我不清楚这是如何工作的。
从上面的解释中,我不清楚这是如何工作的。让我们画出步骤...让我们分析一下球形情况:- DRR(无W),
- 4线
- 在第0位,所有数据包各为500个字节,
- 1日-每个1000
- 在2至1500年,
- 在第三个中放着一根4000欧元的香肠,
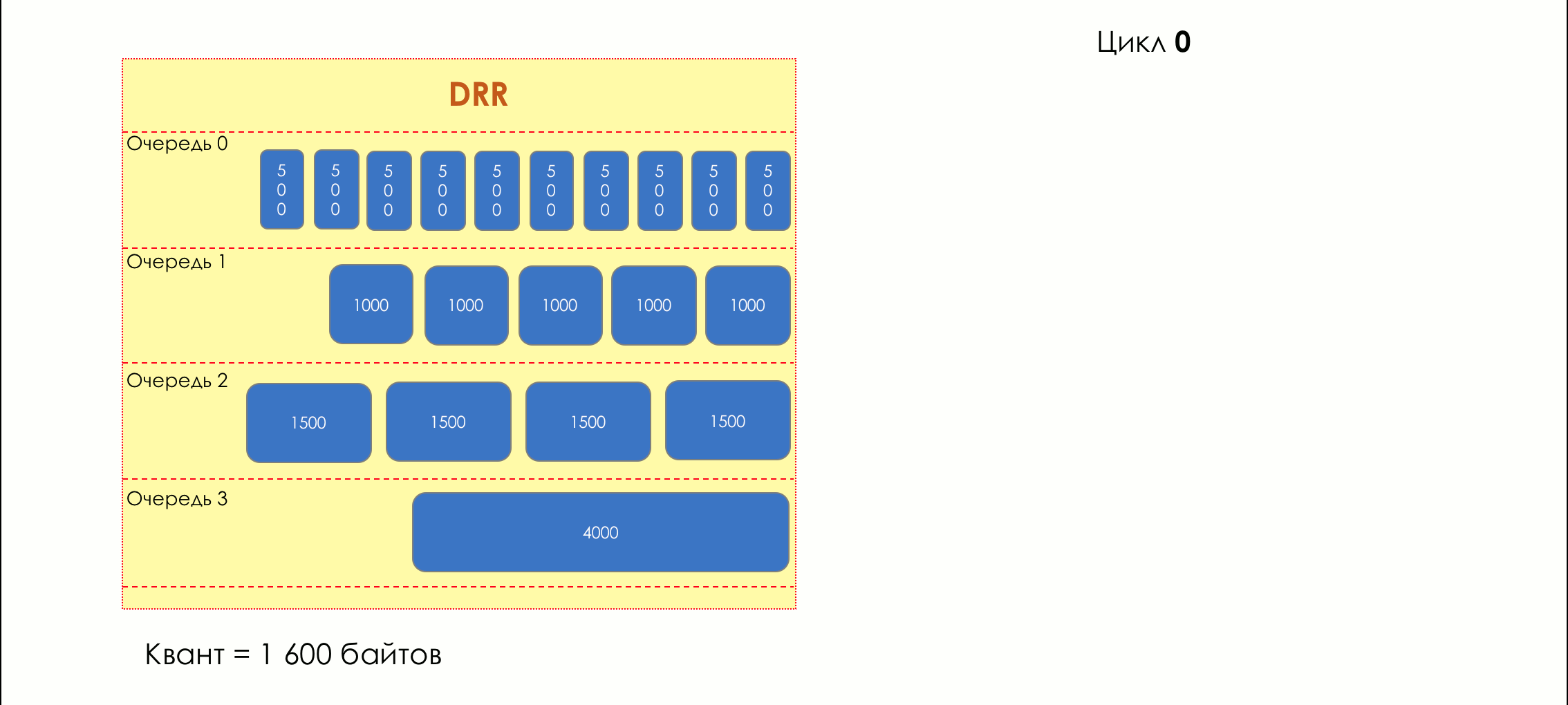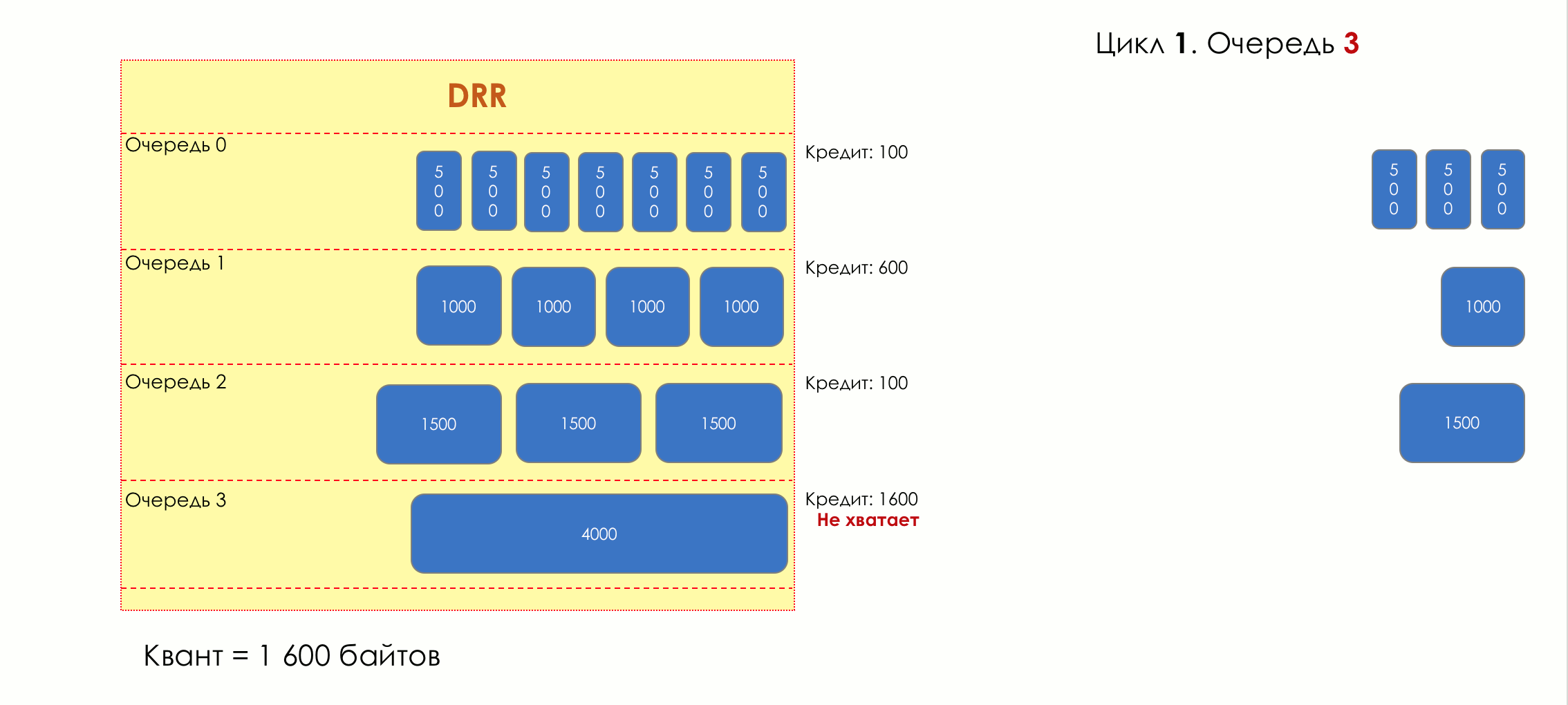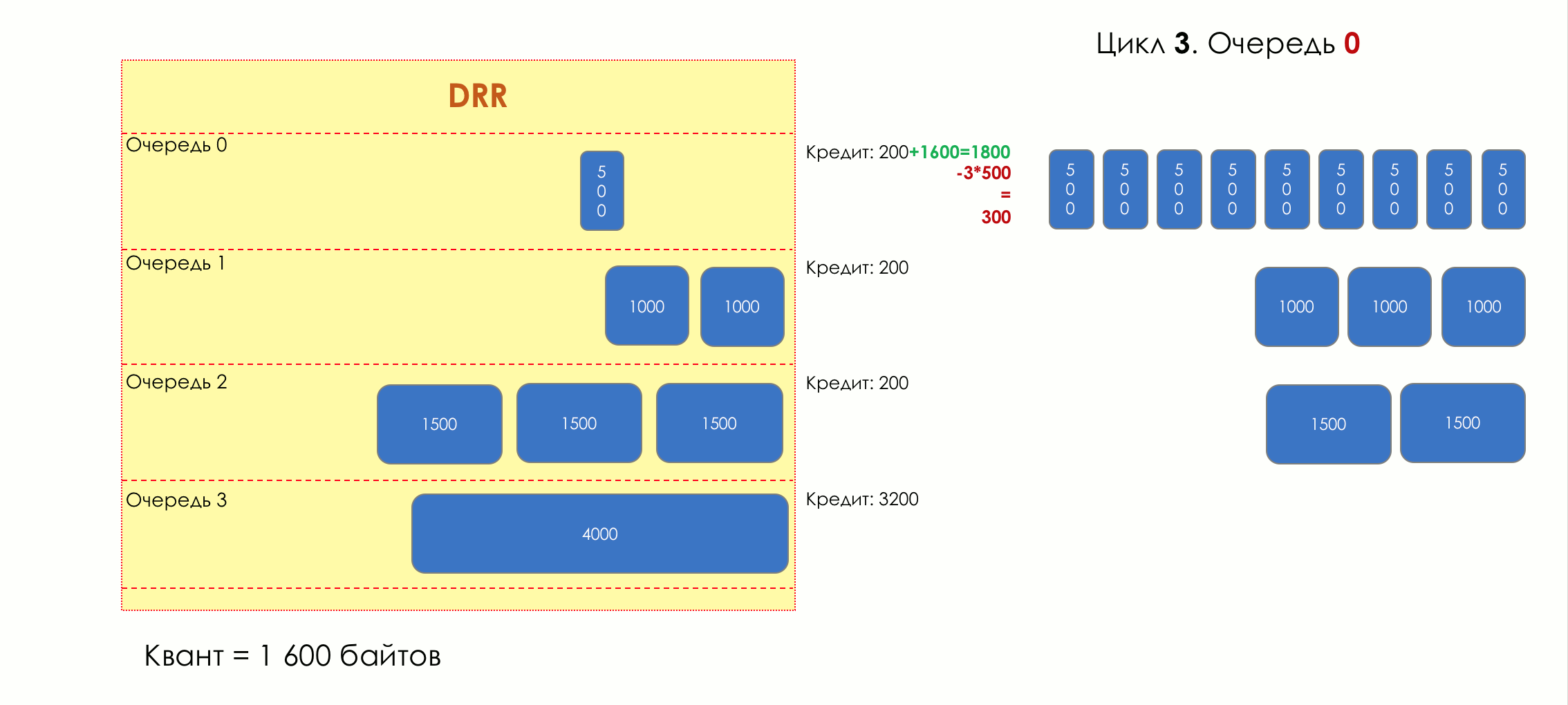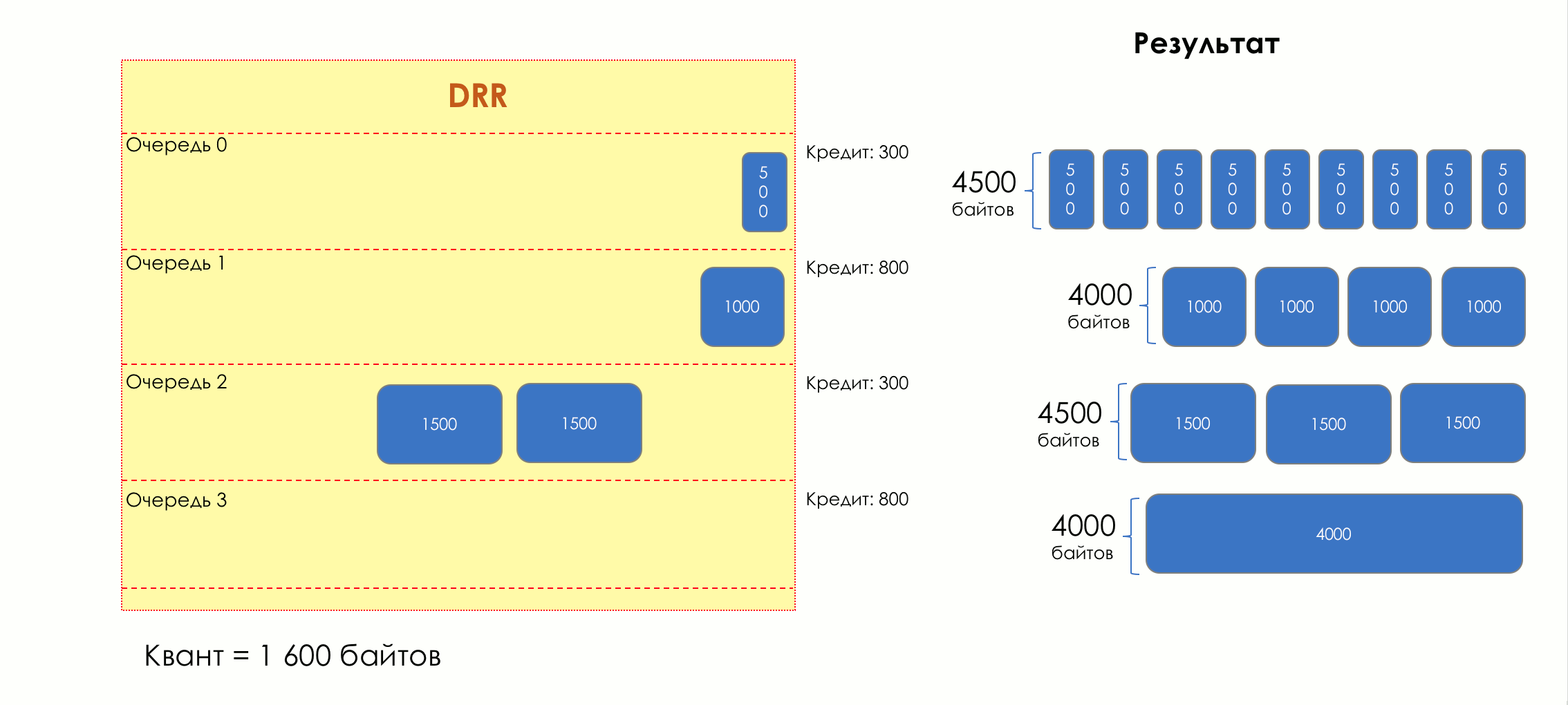
- 量子-1600字节。

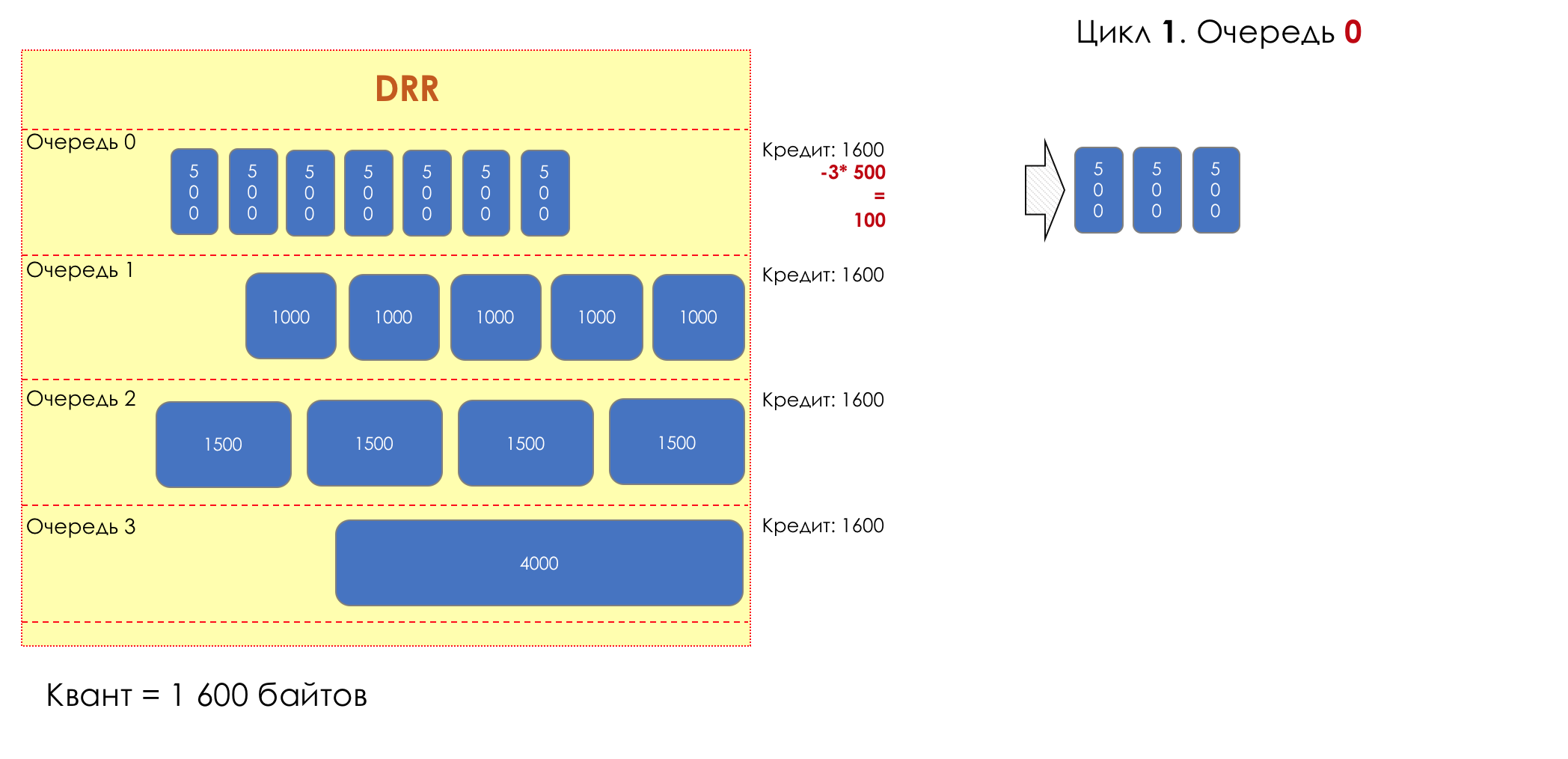
周期1
1. 0, 1600 ()
0- . :
— (1600 — 500 = 1100).
— — (1100 — 500 = 600).
— — (600 — 500 = 100).
— (100 — 500 = -400). .
— 100 .
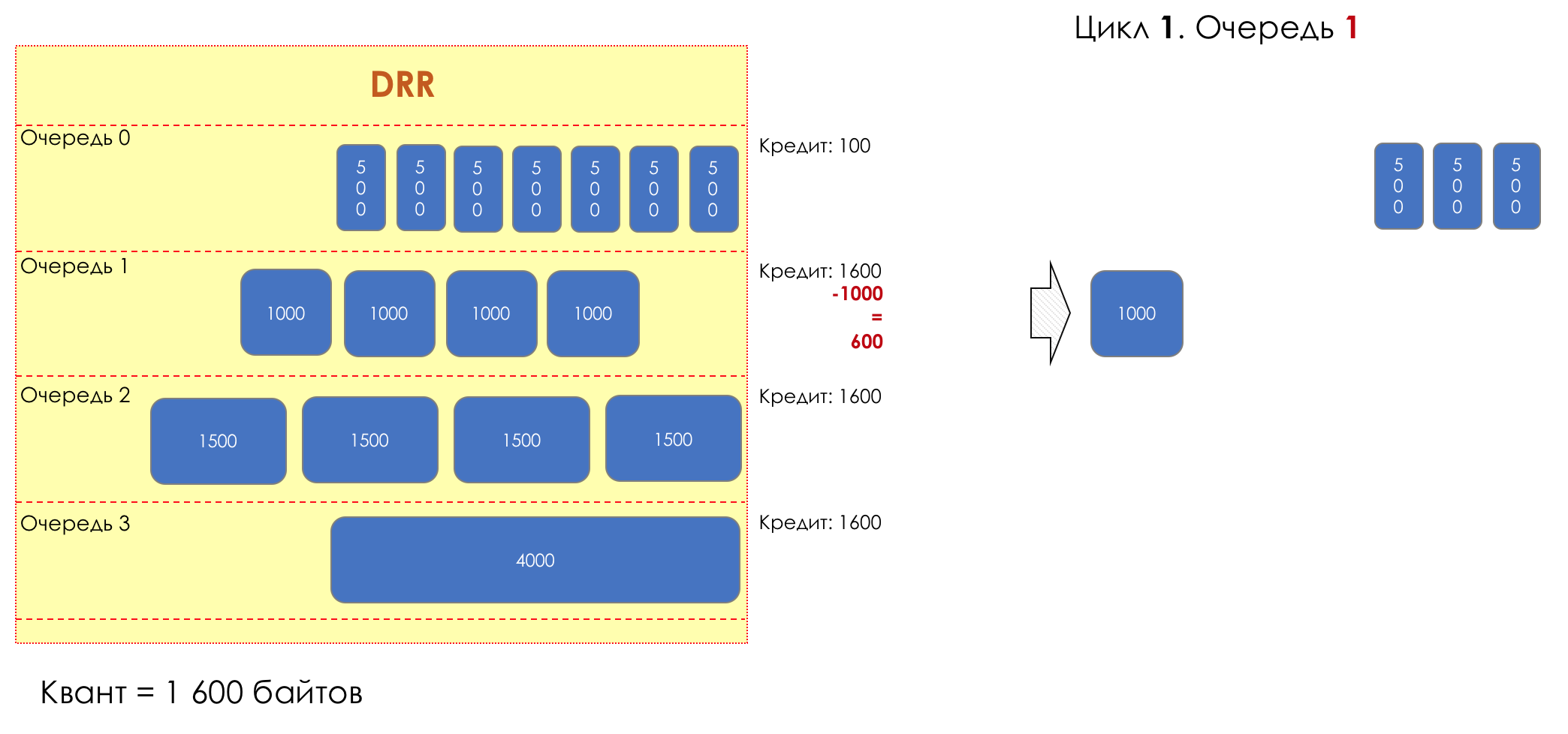
 1. 1
1. 1— (1600 — 1000 = 600).
(600 — 1000 = -400). .
— 600 .
 1. 2
1. 2— (1600 — 1500 = 100).
(100 — 1000 = -900). .
— 100 .
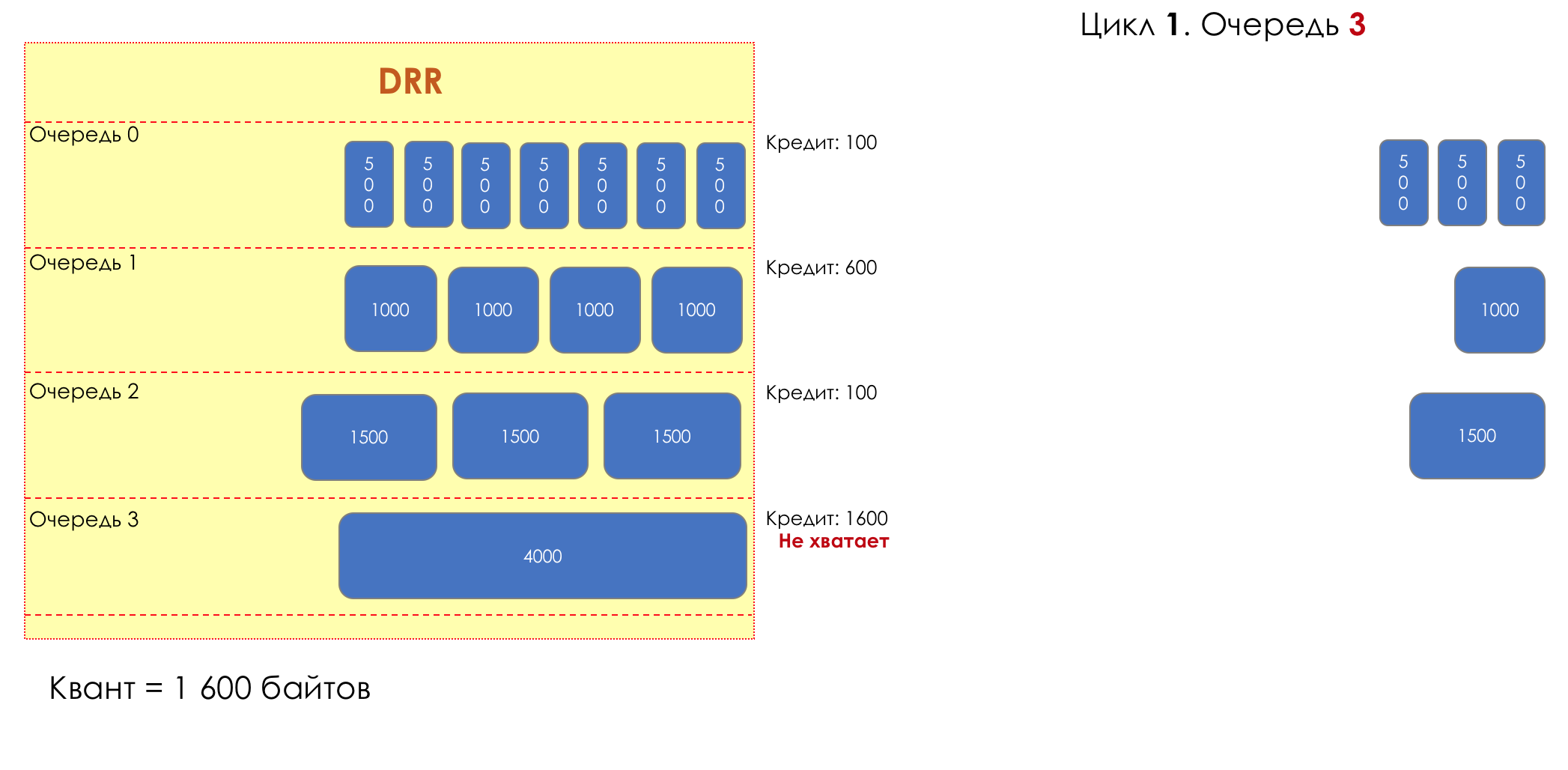
 1. 3
1. 3. (1600 — 4000 = -2400).
.
— 1600 .
, :
- 0 — 1500
- 1 — 1000
- 2 — 1500
- 3 — 0
:
- 0 — 100
- 1 — 600
- 2 — 100
- 3 — 1600
2
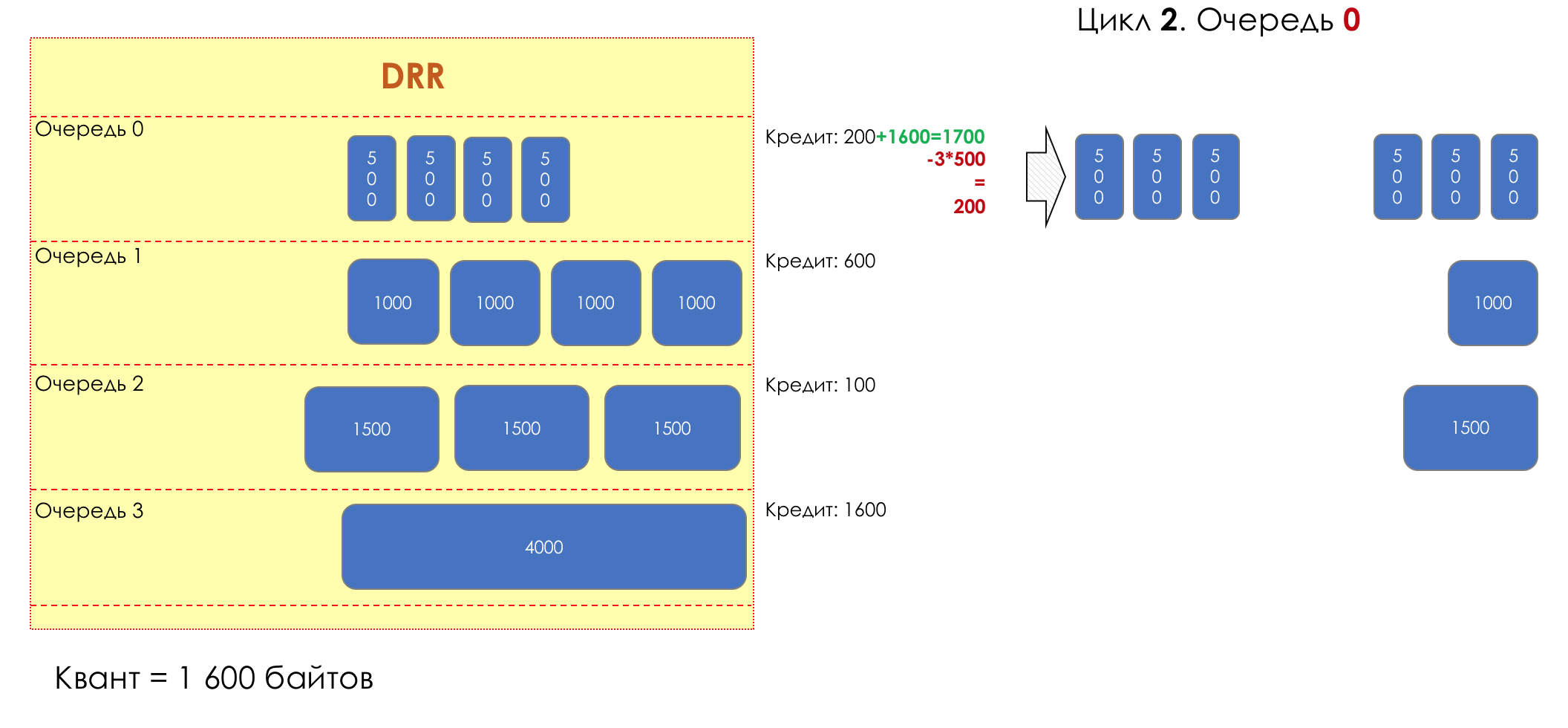
— 1600 .
2. 01700 (100 + 1600).
— (1700 — 3*500 = 200).
.
— 200 .
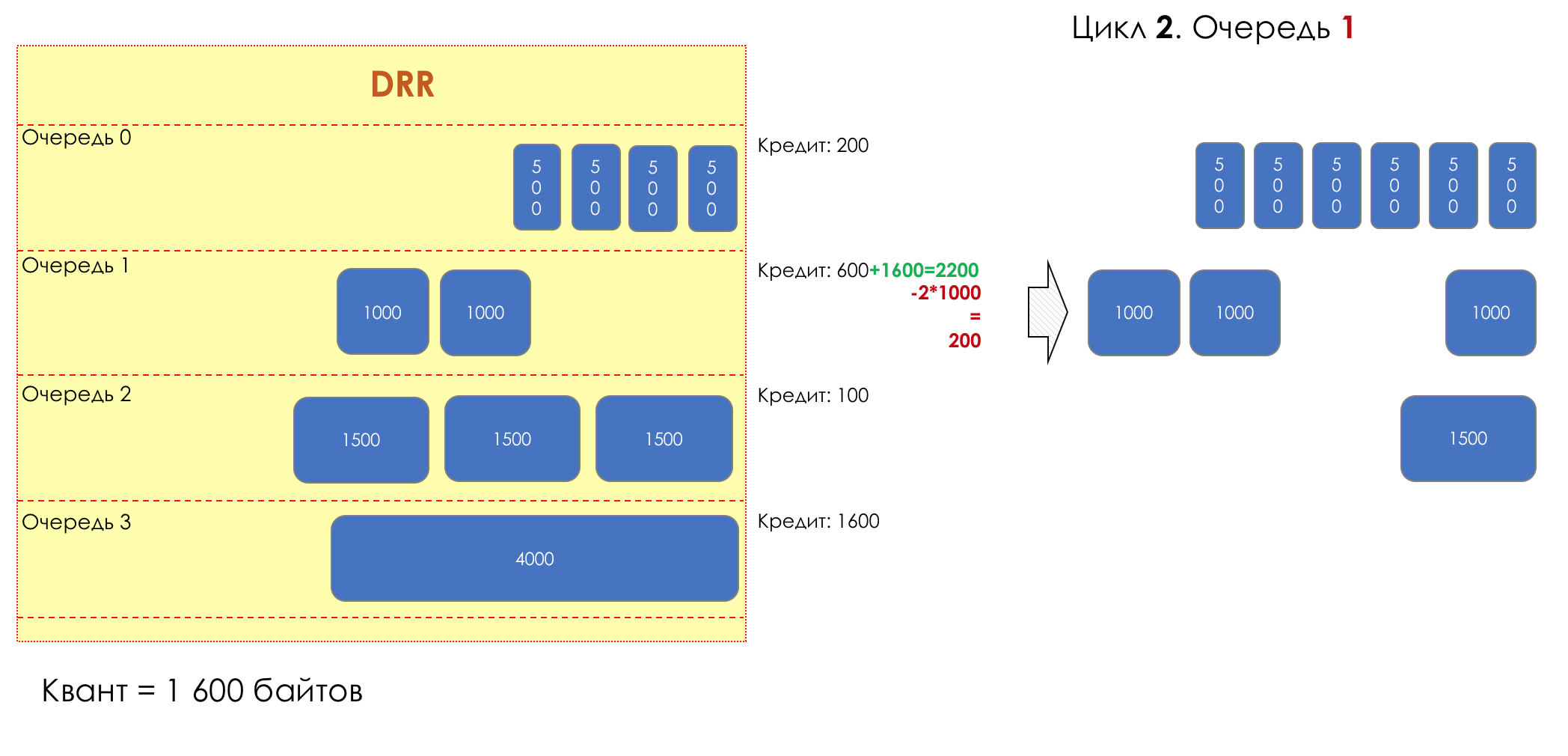
 2. 1
2. 12200 (600 + 1600).
— (2200 — 2*1000 = 200).
.
— 200 .
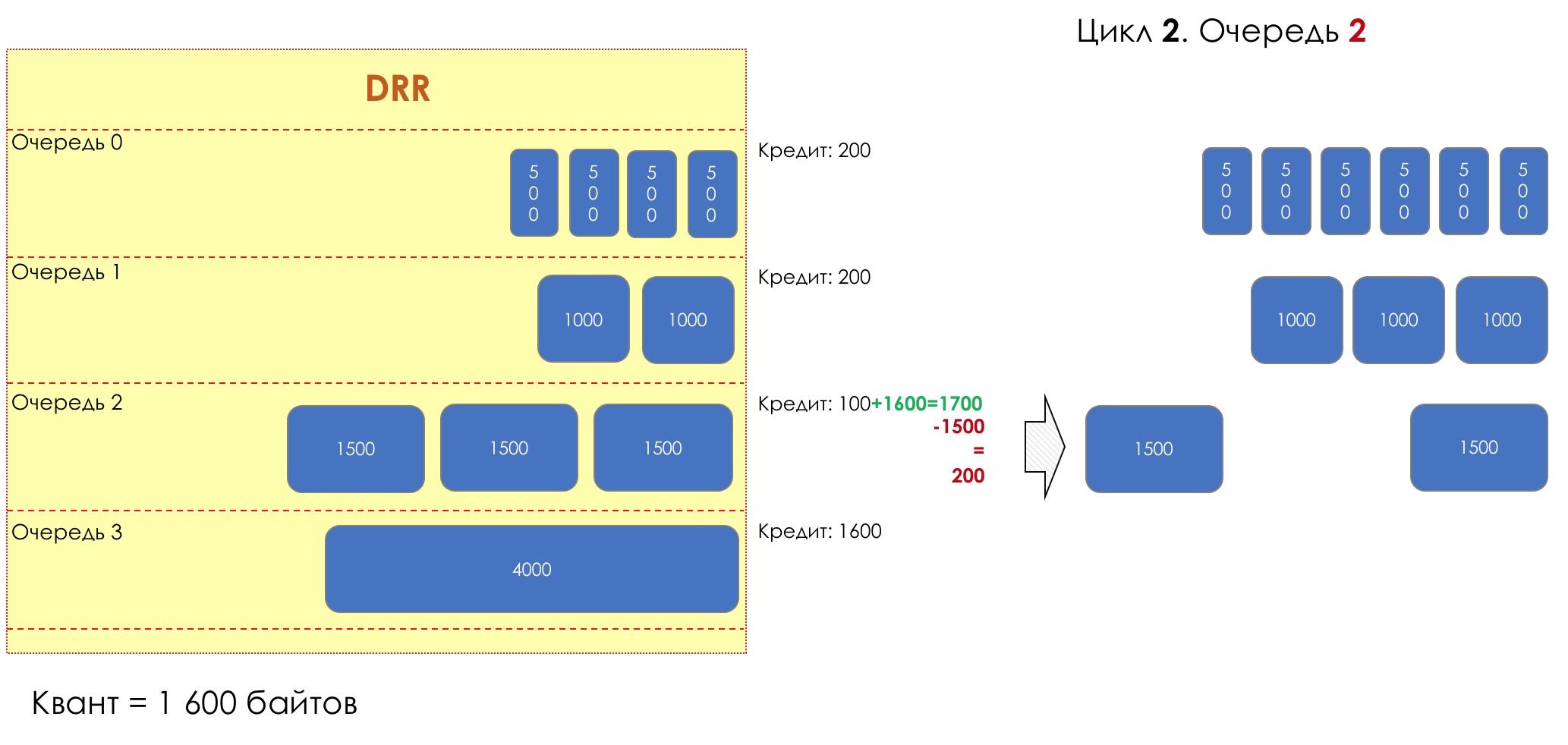
 2. 2
2. 21700 (100 + 1600).
— (2200 — 1500 = 200).
— .
— 200 .
 2. 3
2. 33200 (1600 + 1600).
(3200 — 4000 = -800)
— 3200 .
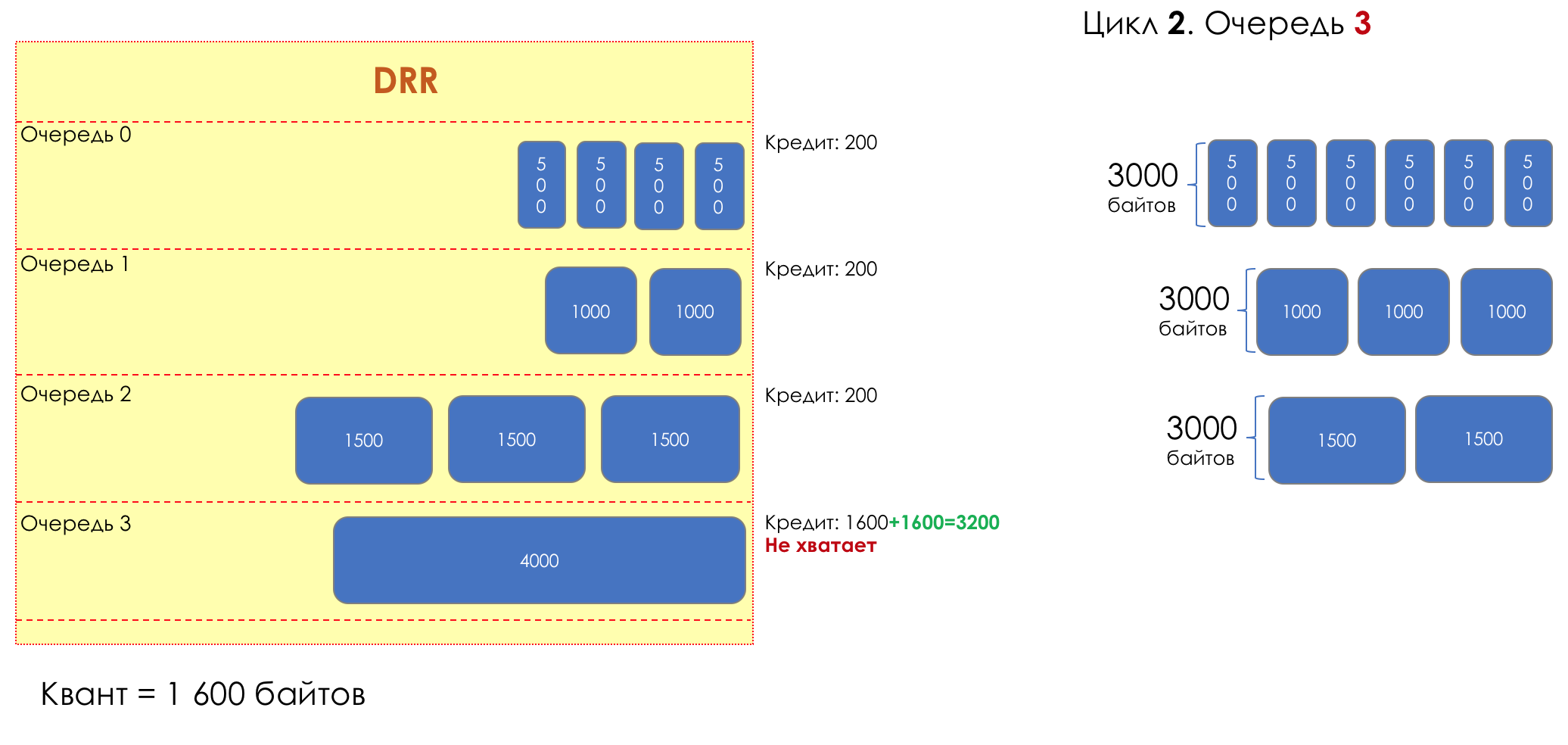
, :
- 0 — 3000
- 1 — 3000
- 2 — 3000
- 3 — 0
:
- 0 — 200
- 1 — 200
- 2 — 200
- 3 — 3200
3
— 1600 .
3. 01800 (200 + 1600).
— (1800 — 3*500 = 300).
.
— 300 .
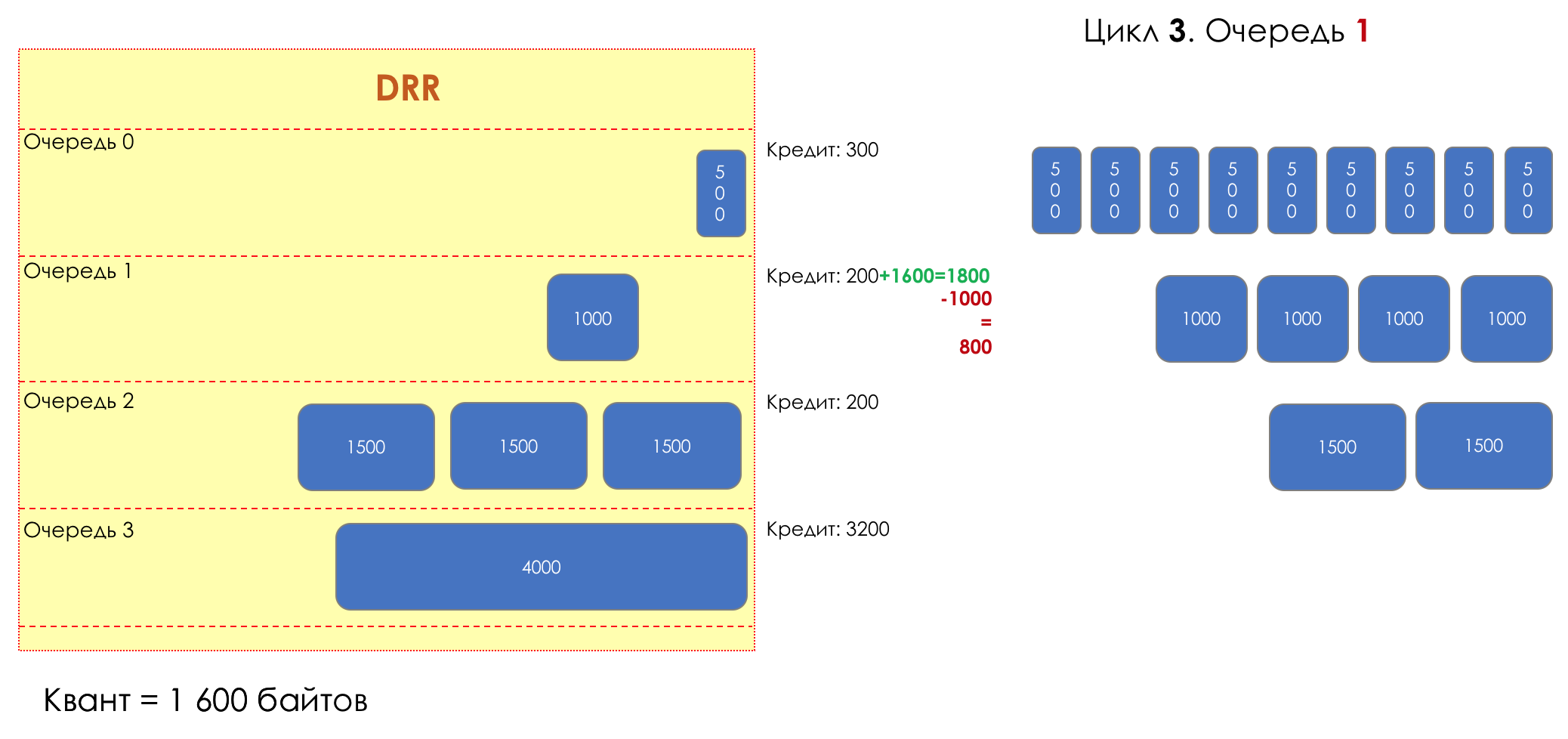
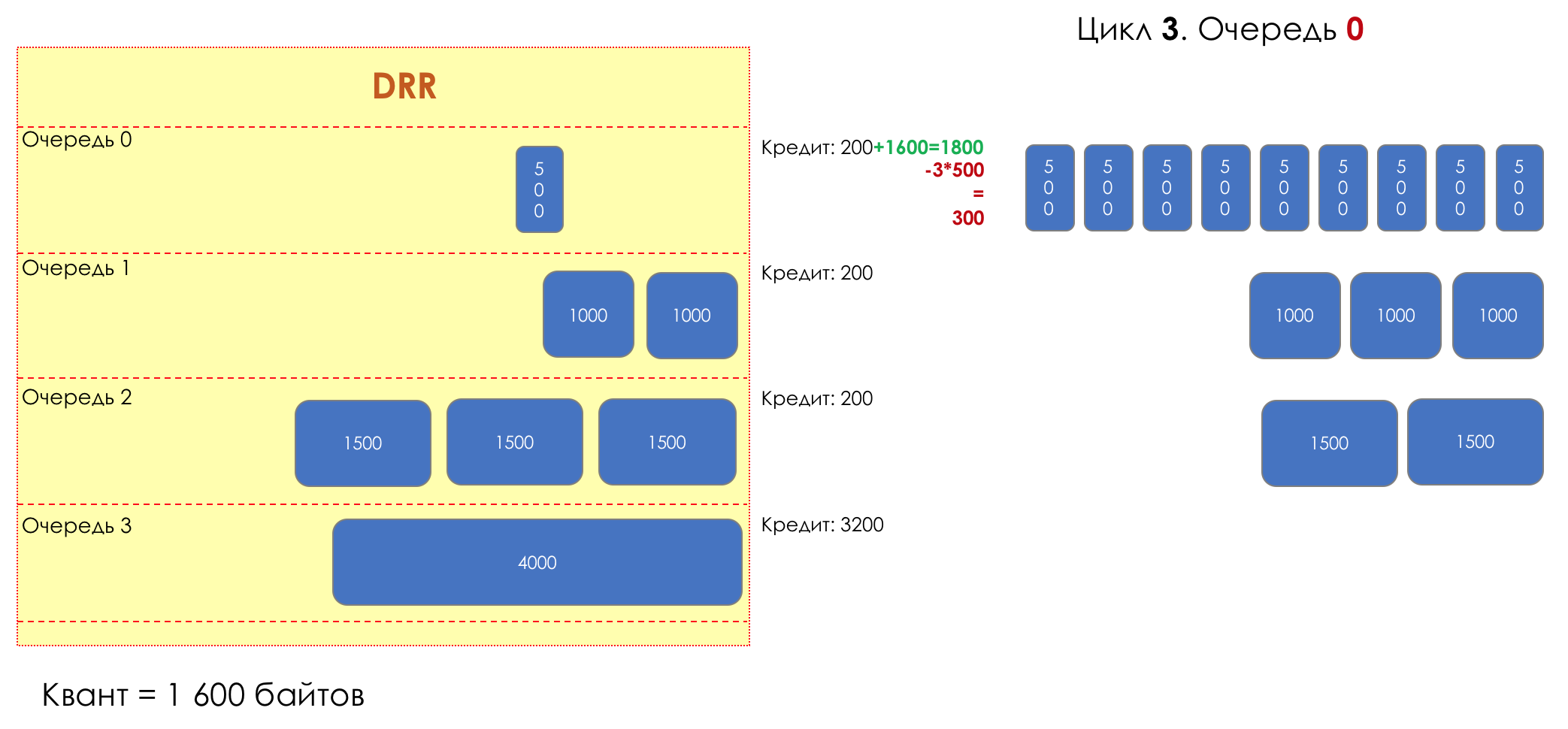 3. 1
3. 11800 (200 + 1600).
— (1800 — 1000 = 800).
— 800 .
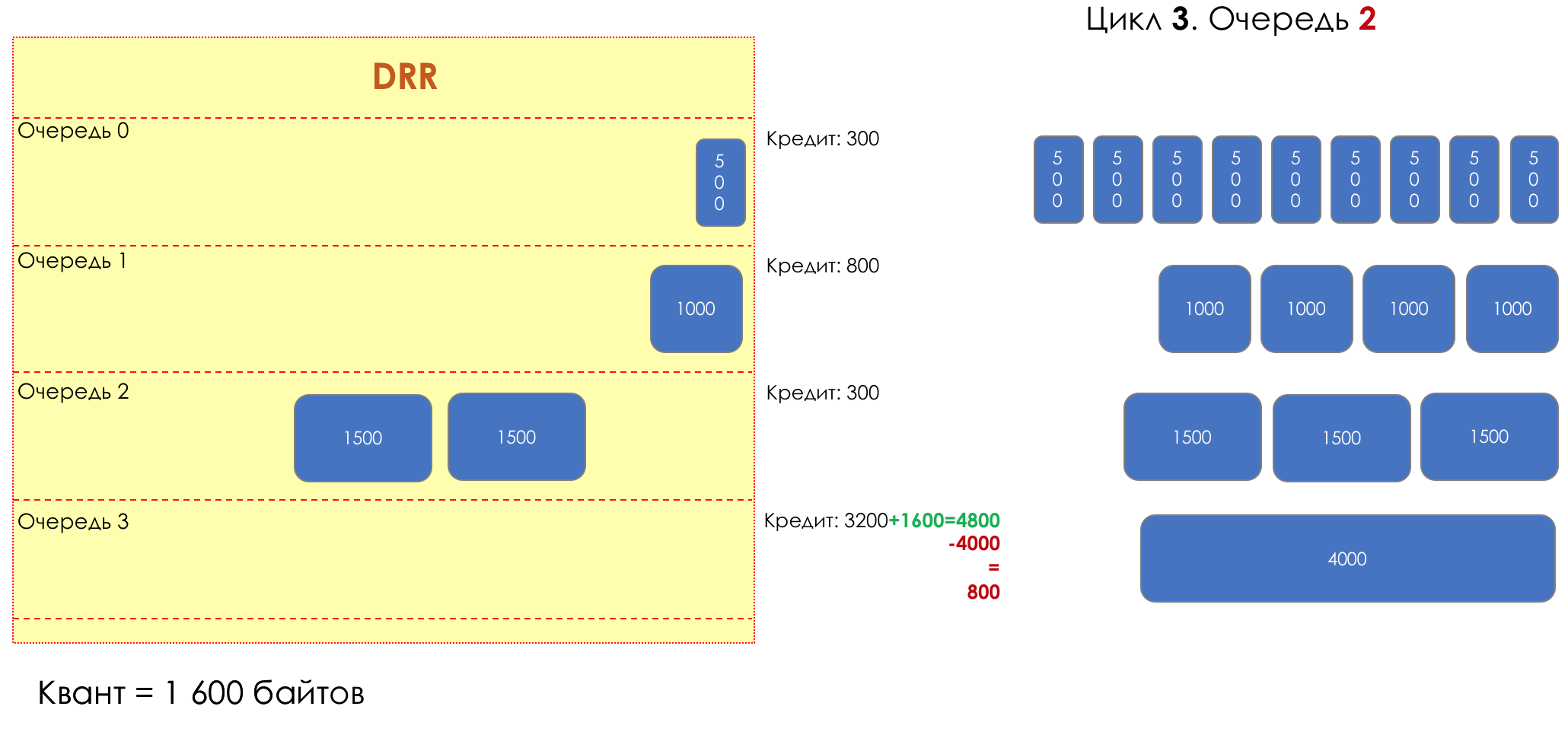
 3. 2
3. 21800 (200 + 1600).
— (1800 — 1500 = 300).
— 300 .
 3. 3
3. 33- !
4800 (3200 + 1600).
— (4800 — 4000 = 800).
— 800 .
, :
- 0 — 4500
- 1 — 4000
- 2 — 4500
- 3 — 4000
:
- 0 — 300
- 1 — 800
- 2 — 300
- 3 — 800
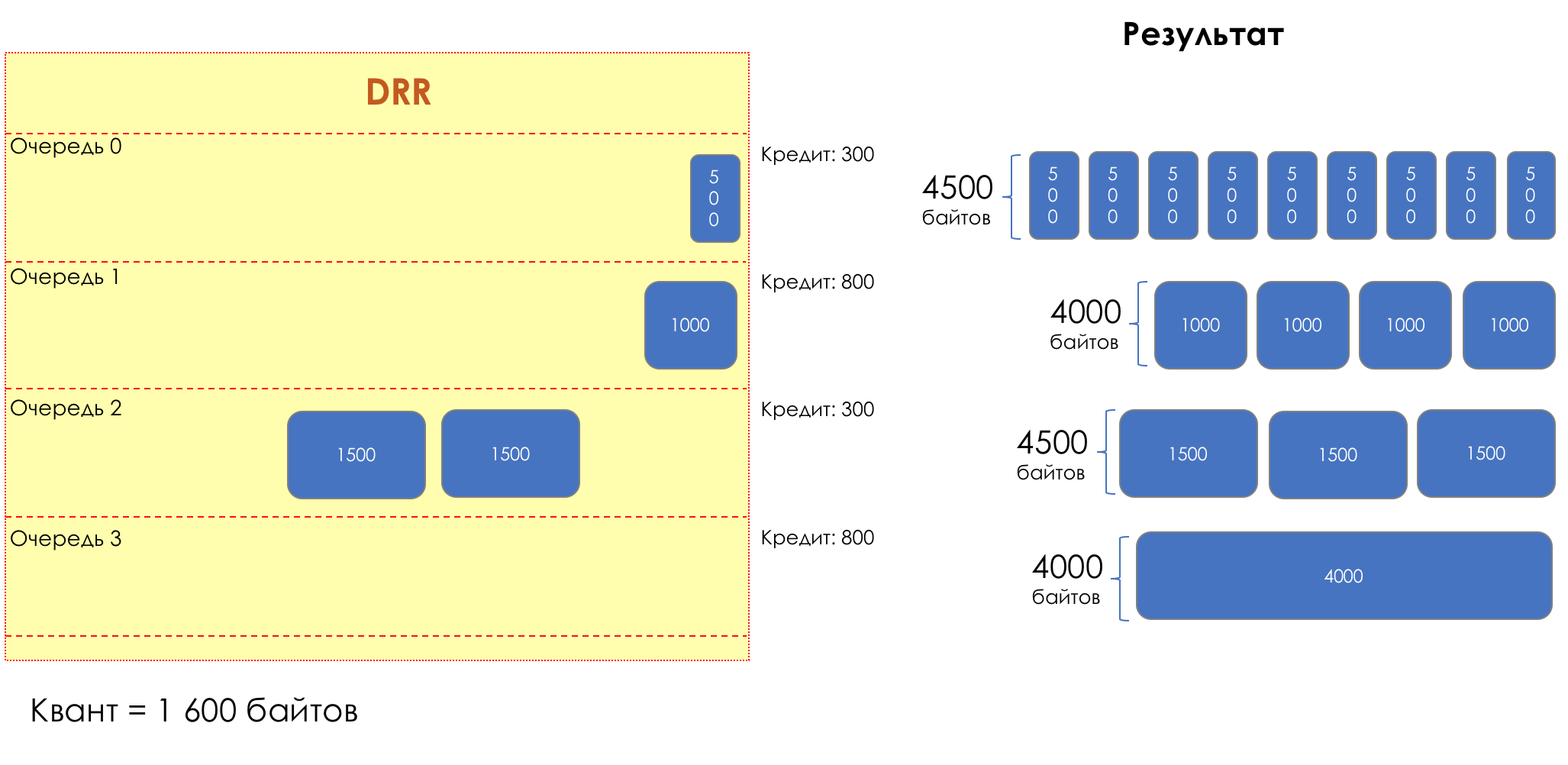
DRR. .
, .
DWRR DRR , , , .
DRR, — , .
: , . .
对于DWRR,问题仍然在于保证延迟和抖动-权重无法以任何方式解决。从理论上讲,您可以执行与CB-WFQ相同的操作,添加LLQ。但是,这只是当今日益流行的可能方案之一。PB-DWRR-基于优先级的DWRR
实际上,当今的主流正在成为PB-DWRR-基于优先级的赤字加权循环法。这与旧的邪恶DWRR相同,在其中添加了另一个队列-优先级,其中以更高的优先级处理数据包。这并不意味着给她更大的带子,而是要从那里更频繁地拿走包裹。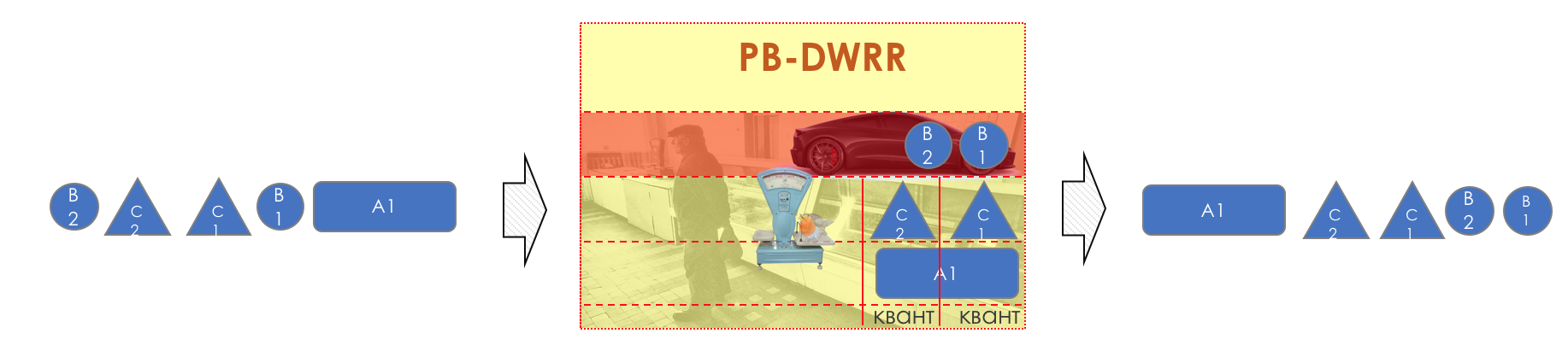 有几种实现PB-DWRR的方法。在某些情况下,如在PQ中一样,到达优先级队列的所有数据包都会立即被删除。在其他情况下,调度程序每次在队列之间移动时都可以访问它。第三,为此引入了信用和数量,从而优先级队列不能挤压整个条带。当然,我们不会分析它们。
有几种实现PB-DWRR的方法。在某些情况下,如在PQ中一样,到达优先级队列的所有数据包都会立即被删除。在其他情况下,调度程序每次在队列之间移动时都可以访问它。第三,为此引入了信用和数量,从而优先级队列不能挤压整个条带。当然,我们不会分析它们。调度机制的简短摘要
几十年来,人类一直在努力解决最困难的问题,即确保适当的服务水平和公平分配乐队。队列是主要工具;唯一的问题是如何从队列中获取数据包,并将其推入一个接口。从FIFO开始,它发明了PQ-声音能够与冲浪共存,但是毫无疑问要保证频段。出现了几个怪异的FQ,WFQ,即使不是按流运行,也是如此。 CB-WFQ进入了阶级社会,但这并没有变得容易。作为替代,他开发了RR。它成为WRR,然后成为DWRR。在每个调度员的深处都有FIFO。但是,正如您所看到的,没有通用调度程序可以按需处理所有类。它始终是调度程序的组合,其中一个解决了确保延迟,抖动和丢失少的问题,另一个解决了分配频带的问题。CBWFQ + LLQ或PB-WDRR或WDRR + PQ。在实际设备上,您可以指定要与哪个调度程序一起处理的队列。CBWFQ,WDRR及其衍生物是当今的最爱。PQ,FQ,WFQ,RR,WRR-我们不会感到悲伤和不记得(当然,除非我们正在为CCIE Clipper做准备)。
因此,调度员能够保证速度,但如何从上方限制速度呢?8.速度限制
乍一看,限制流量速度的需求很明显-根据协议,不要让客户离开自己的乐队。是的 但不仅如此。
假设通过1Gb / s端口连接的RRL跨度为620 Mb / s。如果将整个千兆放入其中,那么RRL上的某个地方(很可能不了解队列和QoS)将开始出现随机性的巨大下降,而与流量的实际优先级无关。但是,如果您在路由器上启用了高达600 Mb / s的整形,那么EF,CS6,CS7将完全不会被丢弃,在BE,AFx中,频段和丢包将根据其权重进行分配。 RRL将达到600 Mb / s,我们将获得可预测的图像。另一个例子是准入控制。例如,除了CS7(如果CS7中有东西),两家运营商同意彼此信任彼此的标记。对于CS6和EF-单独分配一个队列,以确保延迟和不丢失。但是,如果狡猾的合作伙伴开始将种子注入这些行呢?再见电话。协议很可能会崩溃。在这种情况下,与合作伙伴就试条达成共识是合乎逻辑的。符合合同的所有内容都会被跳过。不适合的内容-丢弃或转移到另一个队列-例如BE。因此,我们保护我们的网络和服务。速度限制有两种根本不同的方法:抛光和整形。他们解决了一个问题,但是方式不同。使用此类流量配置文件的示例来考虑差异:
流量监管
警务通过丢弃多余的流量来限制速度。超出设置值的所有内容,polyser都将被丢弃。 被割的东西被遗忘了。图片显示红色数据包在polyser之后没有流量。这是在polyser之后选定的配置文件的样子:
被割的东西被遗忘了。图片显示红色数据包在polyser之后没有流量。这是在polyser之后选定的配置文件的样子: 由于所采取措施的严重性,这称为硬监管。但是,还有其他可能的操作。警察通常与流量表配合工作。如您所记得,仪表会以绿色,黄色或红色为袋子上色。并且已经基于此颜色,polyser可能不会丢弃该数据包,而是将其放在另一个类中。这些是软措施- 软策略。它既可以应用于传入流量,也可以应用于传出流量。polyser的一个独特功能是能够吸收流量突发并通过令牌桶机制确定最大允许速度。就是说,实际上,不超过设定值的所有内容都不会被切断-允许超出设定值-跳过短脉冲或分配频带的少量过量。“管制”的名称由该工具与过剩流量的相当严格的比率决定-丢弃或降级到较低等级。
由于所采取措施的严重性,这称为硬监管。但是,还有其他可能的操作。警察通常与流量表配合工作。如您所记得,仪表会以绿色,黄色或红色为袋子上色。并且已经基于此颜色,polyser可能不会丢弃该数据包,而是将其放在另一个类中。这些是软措施- 软策略。它既可以应用于传入流量,也可以应用于传出流量。polyser的一个独特功能是能够吸收流量突发并通过令牌桶机制确定最大允许速度。就是说,实际上,不超过设定值的所有内容都不会被切断-允许超出设定值-跳过短脉冲或分配频带的少量过量。“管制”的名称由该工具与过剩流量的相当严格的比率决定-丢弃或降级到较低等级。流量整形
整形通过缓冲多余的流量来限制速度。所有传入的流量都通过缓冲区。整形器以恒定速度从此缓冲区中删除数据包。如果数据包到达缓冲区的速率低于输出速率,则它们不会在缓冲区中延迟-它们会一直通过。如果到达率高于输出,则它们开始累积。输出速度始终相同。因此,流量突发会添加到缓冲区中,并在到达队列时发送。因此,与队列中的调度一起,整形是导致总延迟的第二个工具。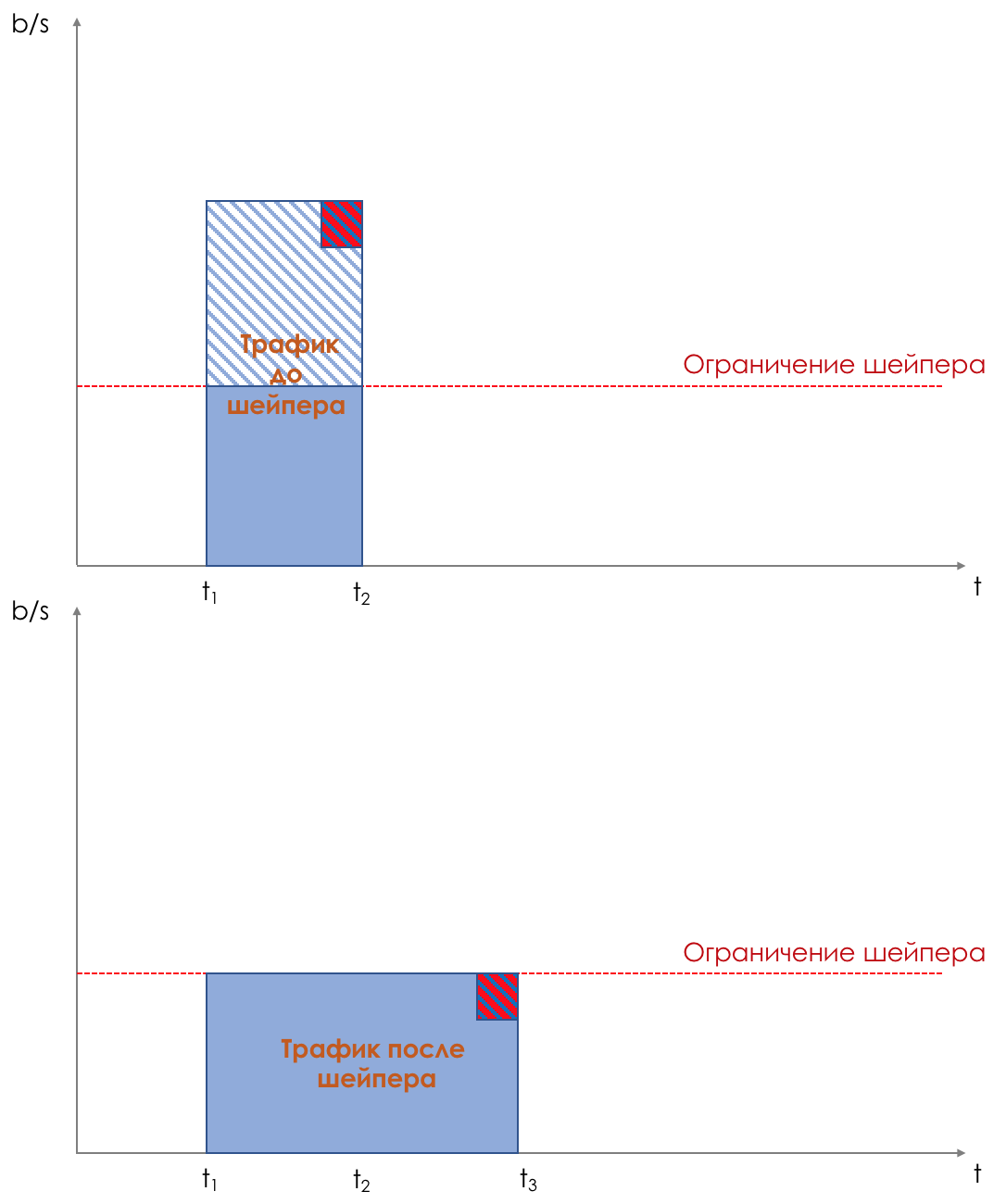 该图清楚地显示了到达时间t2的数据包如何在时间t3到达输出。t3-t2是整形器引入的延迟。整形器通常应用于传出流量。这是轮廓在修整器之后的外观。
该图清楚地显示了到达时间t2的数据包如何在时间t3到达输出。t3-t2是整形器引入的延迟。整形器通常应用于传出流量。这是轮廓在修整器之后的外观。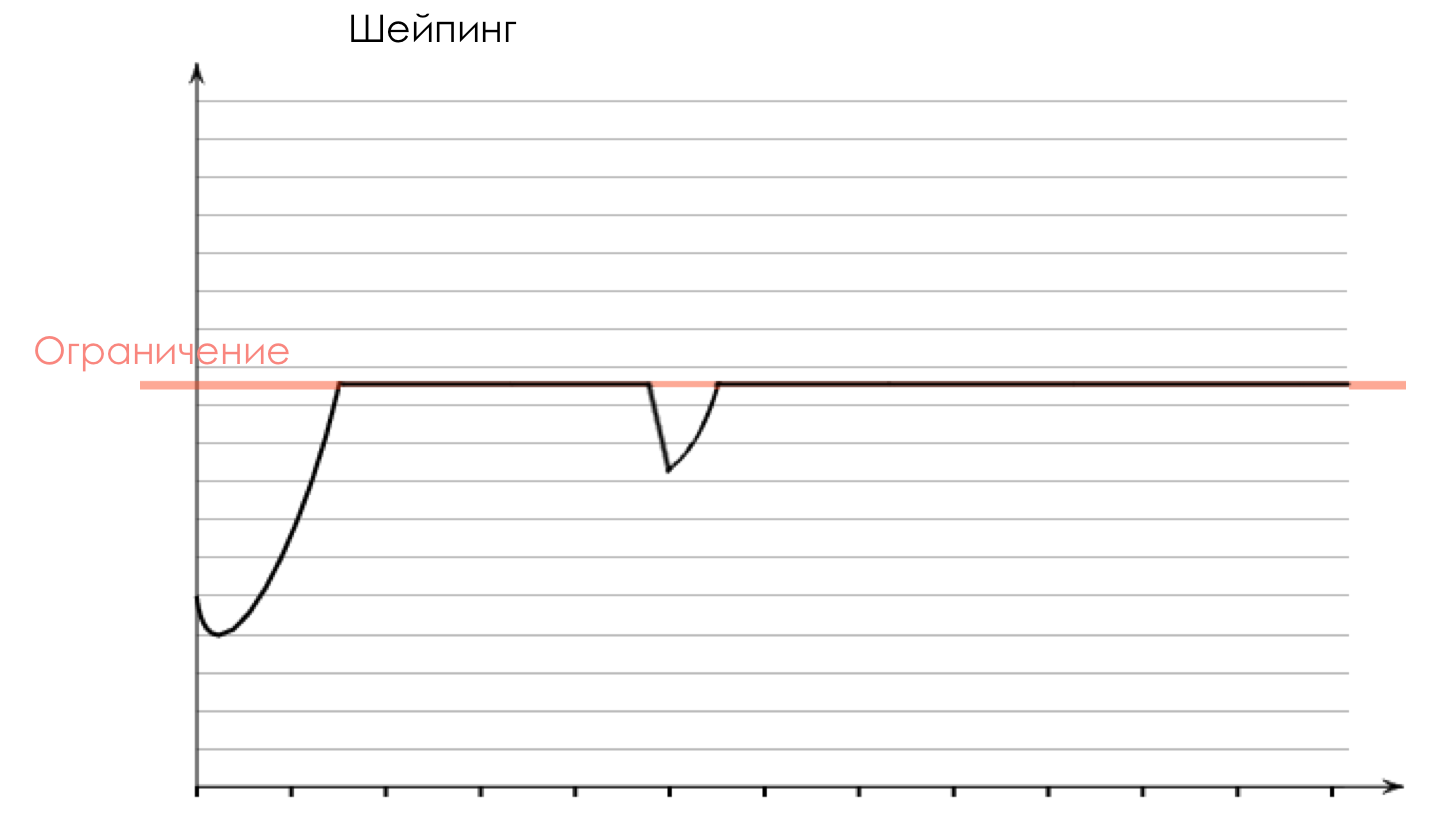 名称“整形”表示该工具为路况配置文件提供形状,使其平滑。这种方法的主要优点是可以最佳地利用现有频段-我们不会推迟过多的流量,而是将其推迟了。主要缺点是无法预料的延迟-当缓冲区已满时,数据包将在其中滞留很长时间。因此,整形不适用于所有类型的流量。整形使用“漏桶”机制。
名称“整形”表示该工具为路况配置文件提供形状,使其平滑。这种方法的主要优点是可以最佳地利用现有频段-我们不会推迟过多的流量,而是将其推迟了。主要缺点是无法预料的延迟-当缓冲区已满时,数据包将在其中滞留很长时间。因此,整形不适用于所有类型的流量。整形使用“漏桶”机制。塑造与抛光
polyser的工作类似于一把刀,它沿着油的表面移动,切除了结节的锋利侧面。整形器的工作类似于滚子,它使结节变得光滑,均匀地分布在表面上。在缓存数据包时,Shaper尝试不丢弃数据包,但这会增加延迟。抛光器不会引入延迟,但是更容易丢弃数据包。对延迟不敏感,但不希望损失的应用程序应限于整形器。对于那些迟到的包裹与丢失的包裹相同的人,最好将其立即丢弃-然后进行抛光。整形器不会影响包头及其在节点外部的命运,而抛光后,设备可以在头中对类进行重新分类。例如,在输入端,数据包的等级为AF11,在设备内部通过计量将其涂成黄色,在输出端,数据包将其等级重新标记为AF12-在下一个节点,丢弃的可能性更高。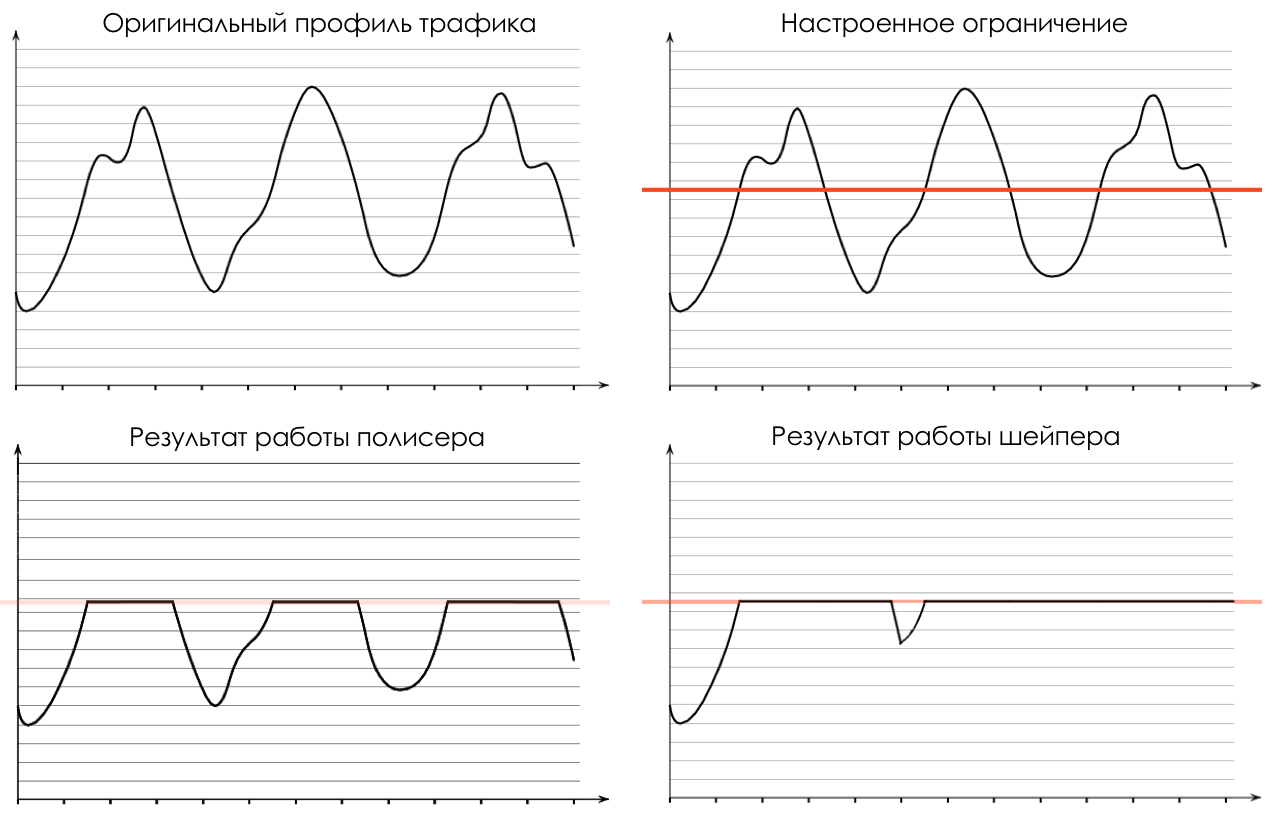
练习抛光和整形
方案相同:配置文件。 我们观察此图片时没有施加限制: 我们将按以下步骤进行:
我们将按以下步骤进行:- 在输入接口Linkmeup_R2(e0 / 1)上,我们将配置抛光-这将是输入控件。根据协议,我们给出10 Mb / s。
- 在输出接口Linkmeup_R4(e0 / 2)上,将整形配置为20 Mb / s。
让我们从Linkmeup_R4上的整形器开始。匹配所有内容: class-map match-all TRISOLARANS_ALL_CM match any
形状高达20Mb / s: policy-map TRISOLARANS_SHAPING class TRISOLARANS_ALL_CM shape average 20000000
适用于输出接口: interface Ethernet0/2 service-policy output TRISOLARANS_SHAPING
一切应该离开(输出)Ethernet0 / 2接口的设备,形状最高可达20 Mb / s。成型器配置文件。结果如下: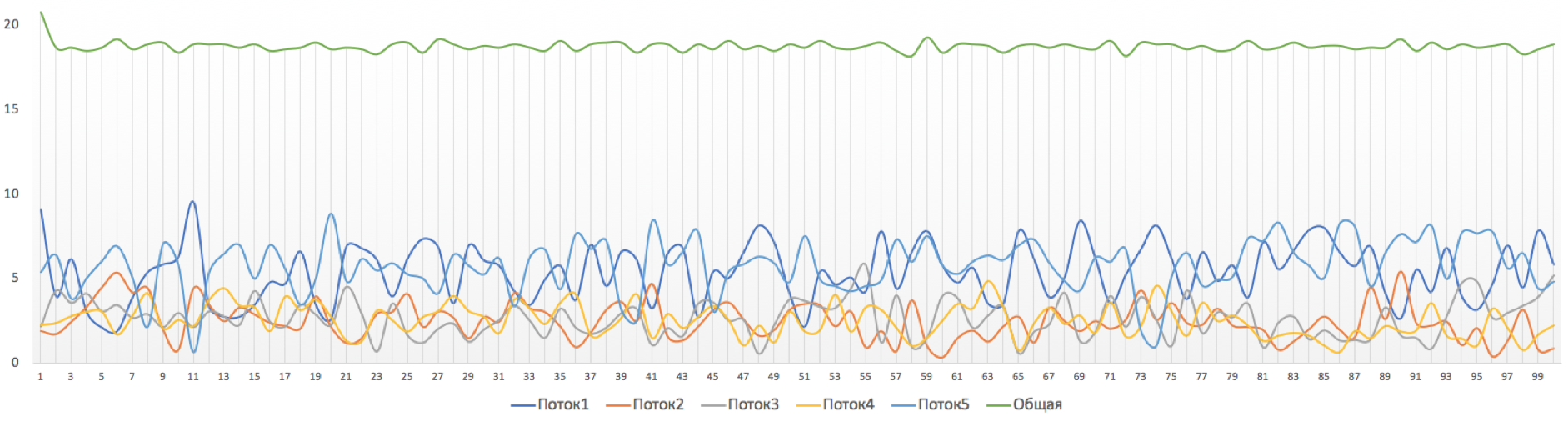 事实证明,每个单独的流的总吞吐量和图形残缺都相当平坦。事实是,我们将整形器限制在常规范围内。但是,根据平台的不同,单个流也可以单独成形,从而获得平等的机会。
事实证明,每个单独的流的总吞吐量和图形残缺都相当平坦。事实是,我们将整形器限制在常规范围内。但是,根据平台的不同,单个流也可以单独成形,从而获得平等的机会。
现在在Linkmeup_R2上配置抛光。我们将在现有政策中添加一个polyser。 policy-map TRISOLARANS_ADMISSION_CONTROL class TRISOLARANS_TCP_CM police cir 10000000 bc 1875000 conform-action transmit exceed-action drop
该策略已应用于接口: interface Ethernet0/1 service-policy input TRISOLARANS_ADMISSION_CONTROL
在这里,我们指出平均允许速度CIR(10Mb / s)和允许突发Bc(1,875,000字节,约14.6 MB)。稍后,在解释polyser的工作原理后,我将告诉您CIR和Bc是什么以及如何确定这些值。Polyser配置文件。这张照片是通过聚晶观察的。速度水平的突然变化是显而易见的: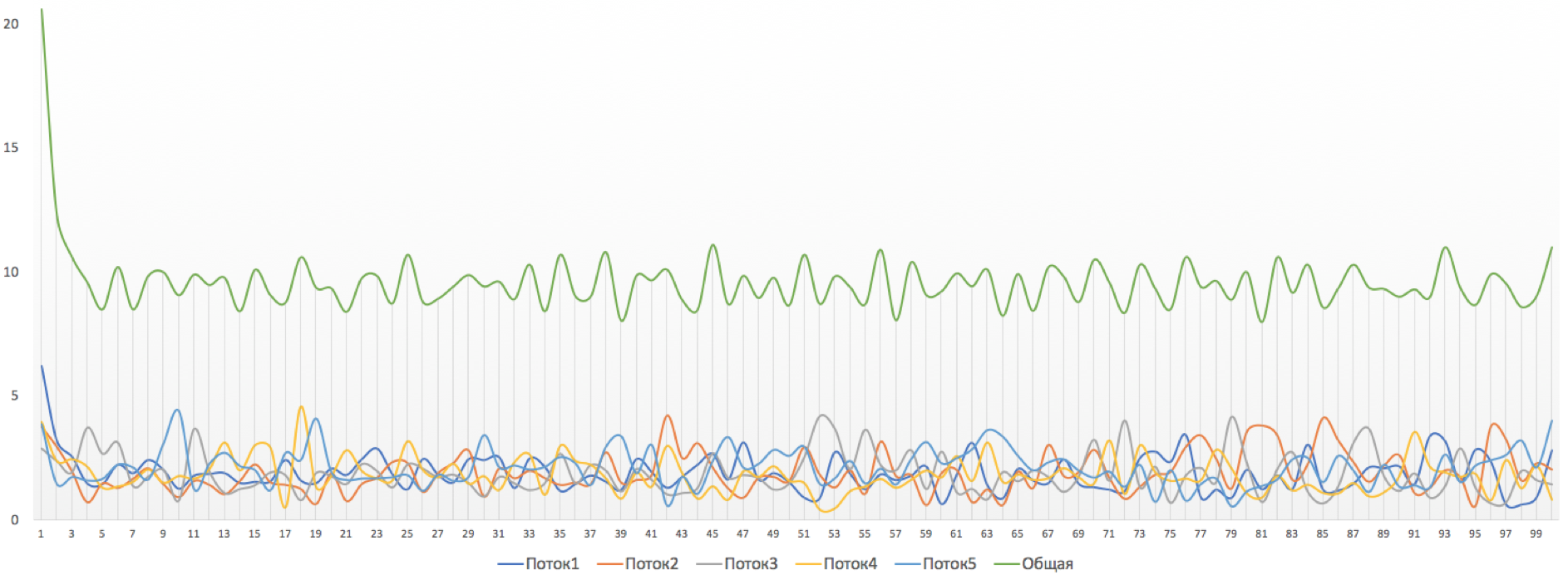
但是,如果我们将允许的突发大小设置得太小,例如10,000字节,就会获得如此有趣的图像。 police cir 10000000 bc 10000 conform-action transmit exceed-action drop
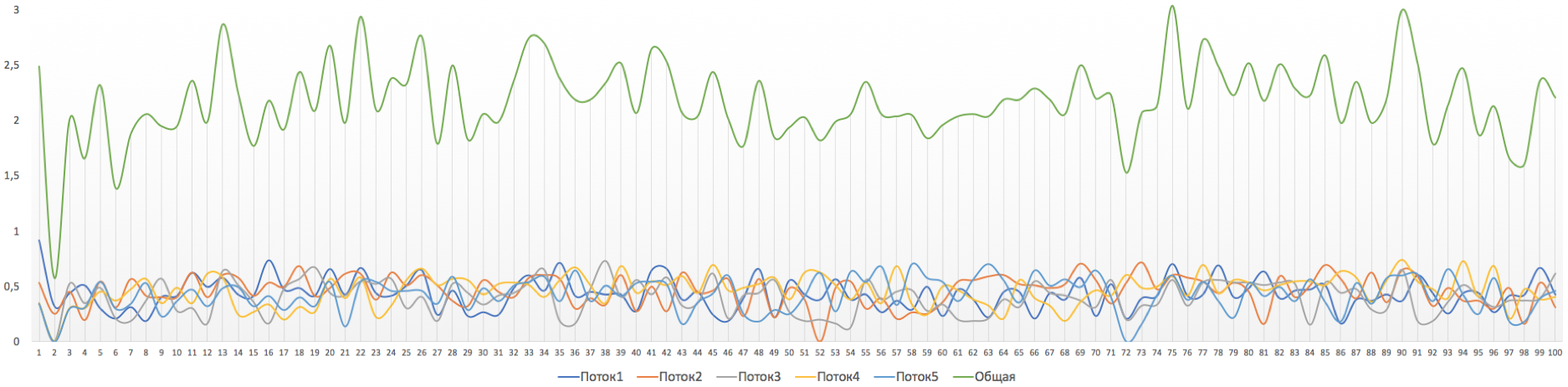 整体速度立即下降到大约2Mb / s。注意脉冲串的设置:)测试表。
整体速度立即下降到大约2Mb / s。注意脉冲串的设置:)测试表。
漏斗和令牌桶
听起来很简单清晰。但是它如何在实践中工作并在硬件中实现?一个例子。
400 Mb / s的限制是否很多(或少一点)?平均而言,一个客户端仅使用320。但是有时5分钟会上升到410。有时高达每分钟460。有时长达500秒。正如合同提供者linkmeup所说的-400就是这样!如果您想要更多,请连接到1Gb / s + 27个动漫频道的资费。如果不增加这种影响,我们可以提高客户忠诚度。如何只允许一分钟460 Mb / s,而不是30或永远?如果频段是免费的,如何允许500 Mb / s,如果出现其他消费者,如何压至400 Mb / s?现在休息一下,倒一桶浓酒。让我们从成型机使用的更简单的机制开始-漏斗。漏斗算法
漏斗是漏斗。 我们有一个在底部有给定尺寸的孔的水桶。将袋子从上方倒入/倒入该桶中。从下方开始,它们以恒定的比特率流动。当存储桶已满时,新的数据包开始被丢弃。孔的大小由指定的速度限制确定,对于漏斗,速度限制以每秒位数为单位进行测量。铲斗的体积,饱满度和输出速度决定了整形机引入的延迟。为方便起见,铲斗体积通常以ms或μs为单位。在实现方面,“漏桶”是基于SD-RAM的常规缓冲区。即使未明确配置整形,在没有传入接口的突发的情况下,数据包也会在接口释放时被临时缓冲和传输。这也在塑造。漏斗仅用于整形,不适合抛光。
我们有一个在底部有给定尺寸的孔的水桶。将袋子从上方倒入/倒入该桶中。从下方开始,它们以恒定的比特率流动。当存储桶已满时,新的数据包开始被丢弃。孔的大小由指定的速度限制确定,对于漏斗,速度限制以每秒位数为单位进行测量。铲斗的体积,饱满度和输出速度决定了整形机引入的延迟。为方便起见,铲斗体积通常以ms或μs为单位。在实现方面,“漏桶”是基于SD-RAM的常规缓冲区。即使未明确配置整形,在没有传入接口的突发的情况下,数据包也会在接口释放时被临时缓冲和传输。这也在塑造。漏斗仅用于整形,不适合抛光。令牌桶算法
许多人认为令牌桶和泄漏桶是同一回事。只有爱因斯坦犯了错误,增加了宇宙常数。交换芯片并不真正了解现在的时间,更糟糕的是每单位时间传输多少位。他们的工作是脱粒。是每秒接近400,000,000位,还是已经接近400,000 001? ASIC开发人员面临着不小的工程挑战。它分为两个子任务:
ASIC开发人员面临着不小的工程挑战。它分为两个子任务:- 通过基于非常简单的条件丢弃不必要的数据包来实际限制速度。在交换芯片上执行。
- 创建此简单条件将处理更复杂(更专业)的芯片,并跟踪时间。
解决第二个问题的算法称为令牌桶。他的想法优雅而简单(不)。令牌桶的任务是在限制范围内通过流量,否则将其丢弃/涂上红色。允许流量爆发很重要,因为这是正常现象。并且,如果在“泄漏桶”中,突发是通过缓冲区进行缓冲的,那么令牌桶将不会缓冲任何内容。单率-两种颜色标记
现在,不要关注名称=)我们有一个桶,硬币以恒定的速度掉入其中-例如每秒400兆字节。桶的数量是6亿个硬币。也就是说,它充满了一个半秒。附近有两条传送带:一条传送包裹,第二条传送带。要到达传送带,包裹必须付款。为此,他根据自己的大小从桶中取出硬币。粗略地说-多少位-这么多硬币。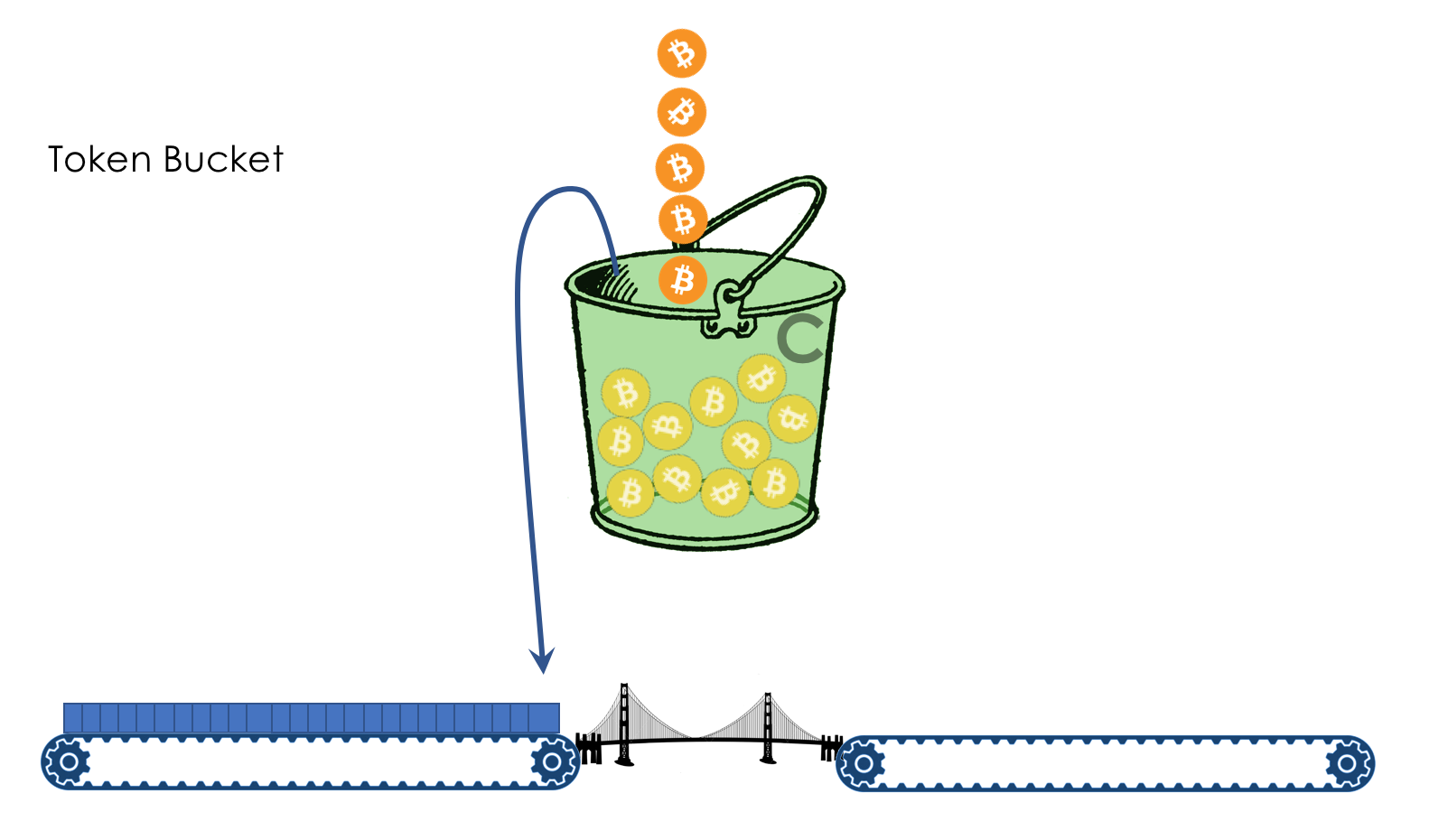
 如果桶是空的并且袋子中没有足够的硬币,则将桶涂成红色信号色并丢弃。 las,Selyava。在这种情况下,不会从桶中取出硬币。
如果桶是空的并且袋子中没有足够的硬币,则将桶涂成红色信号色并丢弃。 las,Selyava。在这种情况下,不会从桶中取出硬币。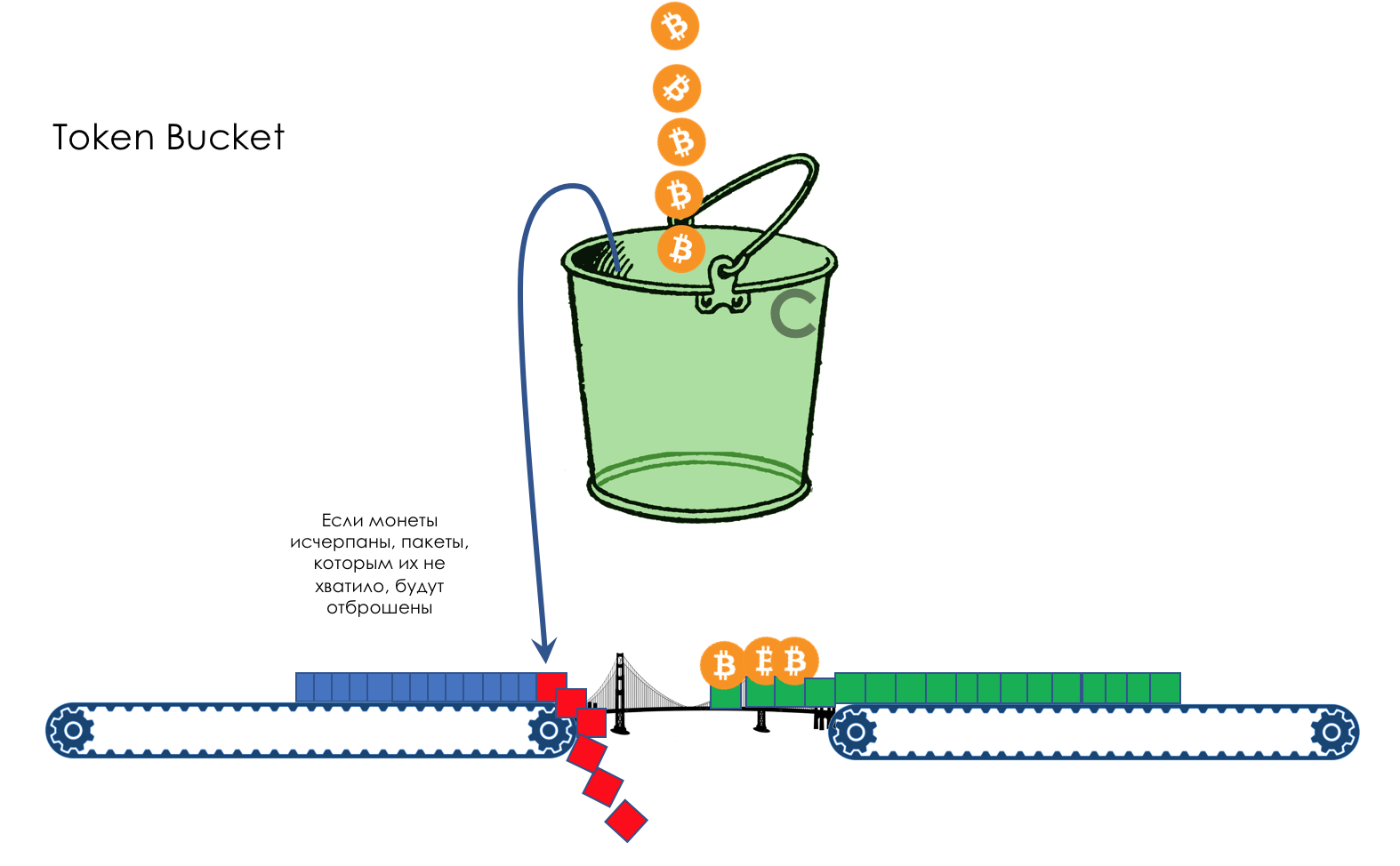 下一个硬币包装可能已经足够了-首先,包装可能会更小,其次,在此期间它会攻击更多的硬币。如果存储桶已满,则所有新硬币将被丢弃。
下一个硬币包装可能已经足够了-首先,包装可能会更小,其次,在此期间它会攻击更多的硬币。如果存储桶已满,则所有新硬币将被丢弃。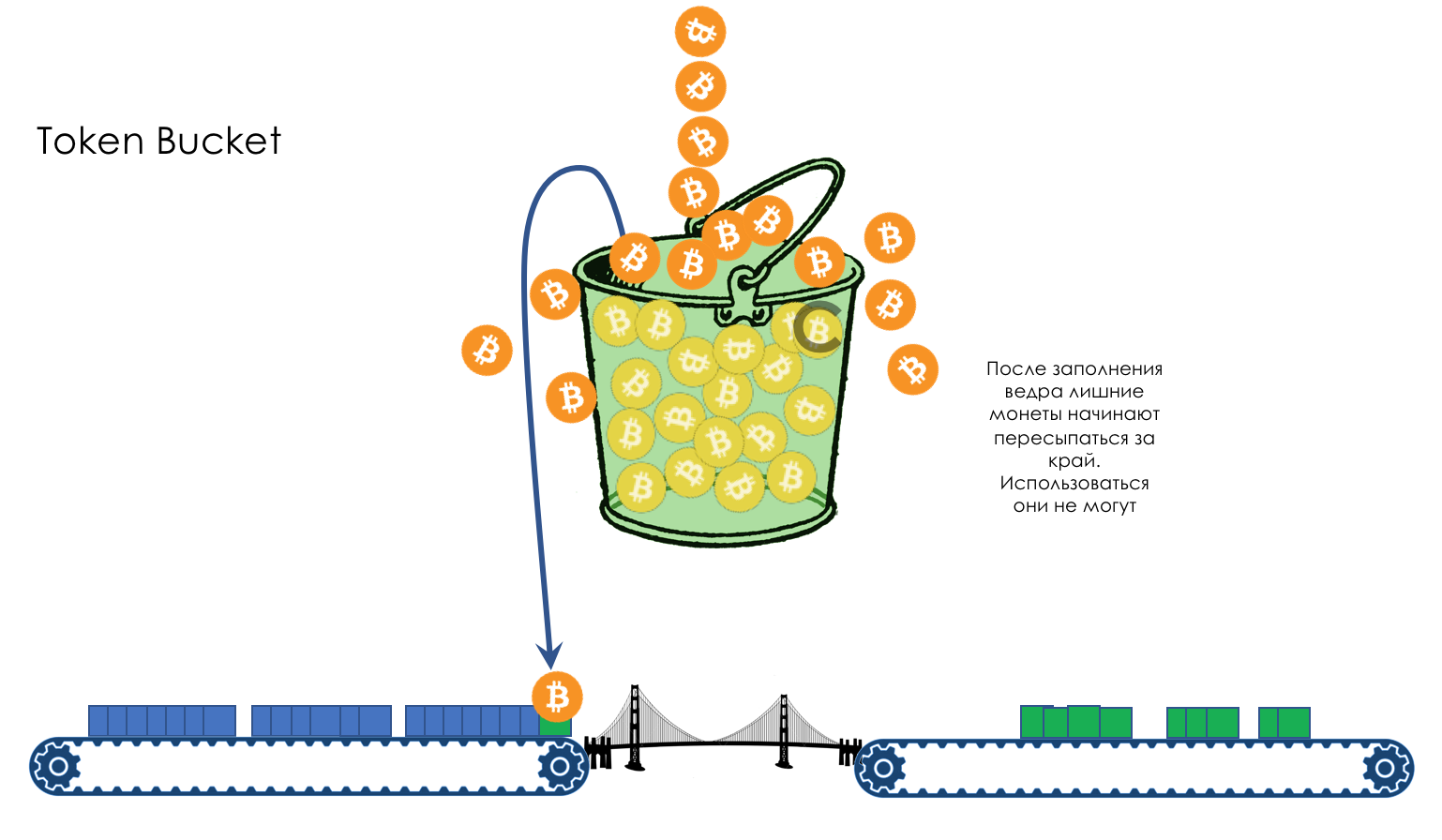 这完全取决于数据包的到达速率及其大小。如果它稳定地低于或等于每秒400 MB,则将始终有足够的硬币。如果更高,则某些数据包将丢失。
这完全取决于数据包的到达速率及其大小。如果它稳定地低于或等于每秒400 MB,则将始终有足够的硬币。如果更高,则某些数据包将丢失。我们都喜欢的一个带有gif的更具体示例。
- 有一个容量为2500字节的存储桶。最初,它包含550个令牌。
管道上有三个要发送到接口的1000字节的数据包。
在每个时隙中,有500个字节落入存储桶(500 * 8 = 4,000位/时隙-polyser限制)。 - 500 . . 1000 , 1050 — . . 1000 .
50 . - 500 — 550. — 1000 — .
, . - 500 — 1050. — 1000 — .
, .
2500 , 2500 — . MTU , , , 1,5-2 .
:
CBS = CIR ( )*1,5 ()/8 ( )
, (Bc), , (1 875 000 ) . (10 000 ), , MTU, .
为什么要用桶装水?比特流并不总是统一的,这是显而易见的。限制为400 Mb / s不是渐近线-流量可以穿越它。所存储硬币的数量允许小脉冲串飞过而不会被丢弃,但将平均速度保持在400Mb / s。例如,在600秒内稳定的399 Mb / s的流量将使铲斗充满边缘。此外,流量可以上升到1000Mb / s,并在此级别停留1秒钟-600 Mm(Megamonet)的库存和400 Mm / s的保证频带。或者,流量可以达到410 Mb / s,并保持60秒。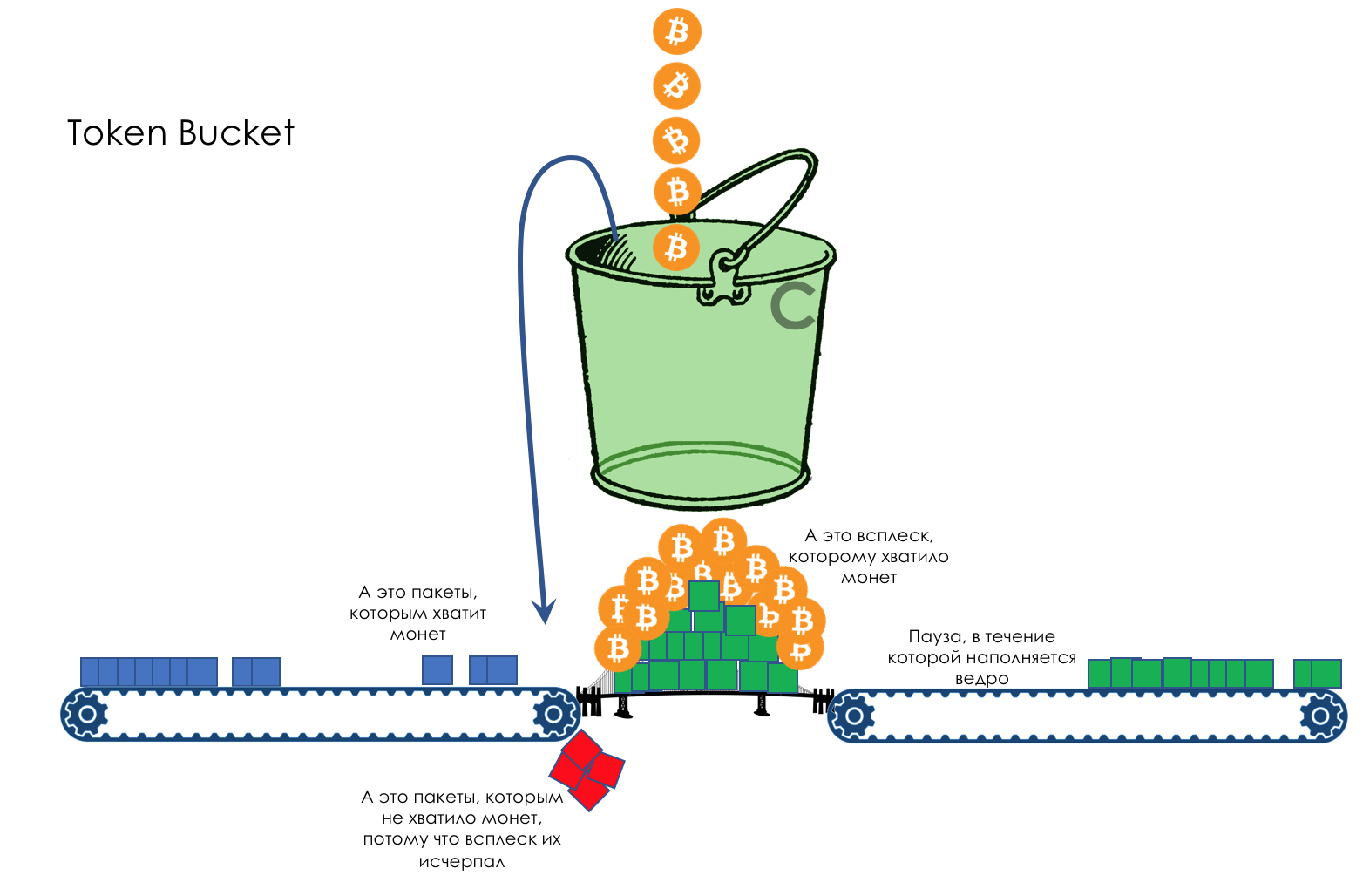 就是说,硬币的供应使您可以长时间长时间超出限制,或者抛出短暂但高昂的波动。现在到术语。存储桶中硬币的接收速率-CIR-承诺信息速率(保证的平均速度)。以每秒位数为单位。可以存储在存储桶中的硬币数量-CBS承诺的突发大小。允许的最大突发大小。以字节为单位。您可能已经注意到,有时将其称为Bc。Tc-目前C桶(CBS)中的硬币数量(令牌)。
就是说,硬币的供应使您可以长时间长时间超出限制,或者抛出短暂但高昂的波动。现在到术语。存储桶中硬币的接收速率-CIR-承诺信息速率(保证的平均速度)。以每秒位数为单位。可以存储在存储桶中的硬币数量-CBS承诺的突发大小。允许的最大突发大小。以字节为单位。您可能已经注意到,有时将其称为Bc。Tc-目前C桶(CBS)中的硬币数量(令牌)。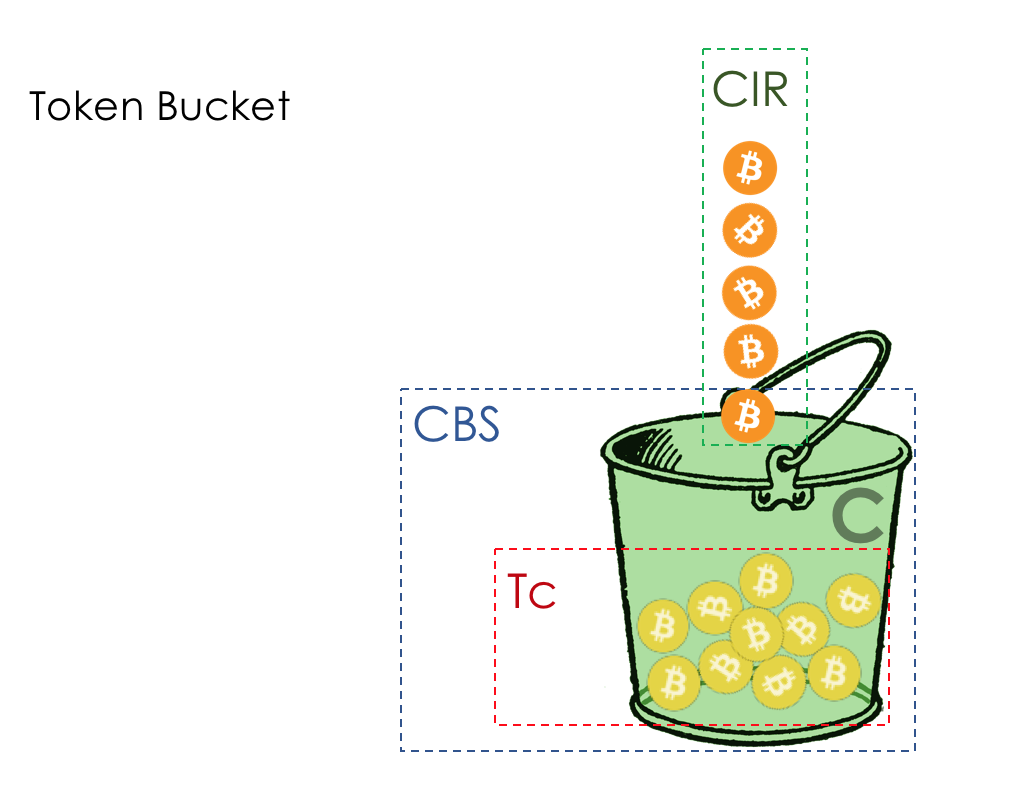
" Tc ", , RFC 2697 ( A Single Rate Three Color Marker ).
Tc, , .
.
, , Token Bucket, TDM (Time-Division Multiplexing) — .
— , , .
CIR . .
, — , — , — .
, .
( Cisco) Tc , — Bc . Bc = CIR*Tc .
Tc Bc .
这是最简单的情况。它被称为单一速率-两种颜色。“单一费率”表示只有一种平均允许速度,“ 两种颜色” -您可以使用两种颜色之一对交通进行着色:绿色或红色。- 如果存储桶C中可用硬币(位数)的数量大于此刻需要跳过的位数,则该数据包显示为绿色-将来掉线的可能性很小。从桶中取出硬币。
- 否则,包装将涂成红色-掉落的可能性很高(或更常见的是瞬间掉落)。硬币从而桶C被撤回。
用于PHB CS和EF中的抛光,在这些抛光中不会出现加速现象,但如果确实会出现加速现象,则最好立即将其丢弃。此外,我们将考虑更困难:单率-三种颜色。单率-三色标记
先前方案的缺点是只有两种颜色。如果我们不想让一切都超出允许的平均速度,而是希望更加忠诚,该怎么办?中医-SR(单速率-三个颜色扣分)进入第二桶- Ë。此时,硬币不会被放置在充满桶的C,倒入ë。EBS已 添加到CIR和CBS中-超出突发大小 -峰值期间允许的突发大小。特 -硬币在桶数Ë。
添加到CIR和CBS中-超出突发大小 -峰值期间允许的突发大小。特 -硬币在桶数Ë。 假设有一个大小为B的数据包沿着管道进入。
假设有一个大小为B的数据包沿着管道进入。然后
- C , . C B (: Tc — B).
- C , E . , ( ), E B .

- E , , .

注意,对于特定的封装,Tc和Te 不是累积的。也就是说,即使在存储桶C中有3000个硬币,在E -7000个硬币中,一个8000字节大小的数据包也不会通过。在C中,这是不够的,在E中,这是不够的-我们从此处打上红色标记-shurai。这是一个非常优雅的设计。所有落在平均CIR + CBS限制之内的流量(作者知道不可能直接添加位/ s和字节)-变为绿色。在高峰时段,当客户C桶中的硬币用完时,在停机期间,他仍然在E桶中积累了Te库存。也就是说,您可以略微跳过一些,但是在拥塞的情况下,它们更有可能被丢弃。sr-TCM在RFC 2697中进行了描述。用于PHB AF中的抛光。好吧,最后一个系统是最灵活的,因此也是最复杂的-两个比率-三种颜色。二率-三色标记
Tr-TCM模型的诞生是因为它不会损害其他用户和流量类型,为什么不给客户带来更多愉悦的机会或更好地销售。告诉他,保证给他400 Mb / s,如果有免费资源,则保证500 Mb / s。您准备多付30卢布吗?添加了另一个桶P。因此:CIR-保证平均速度。CBS是相同的允许飞溅大小(桶体积C)。PIR-峰值信息速率-最大平均速度。EBS-峰值期间允许的突发大小(桶体积P)。与sr-TCM不同,在tr-TCM中,硬币现在独立地输送到两个桶中。在C-中以CIR的速度在P -PIR中。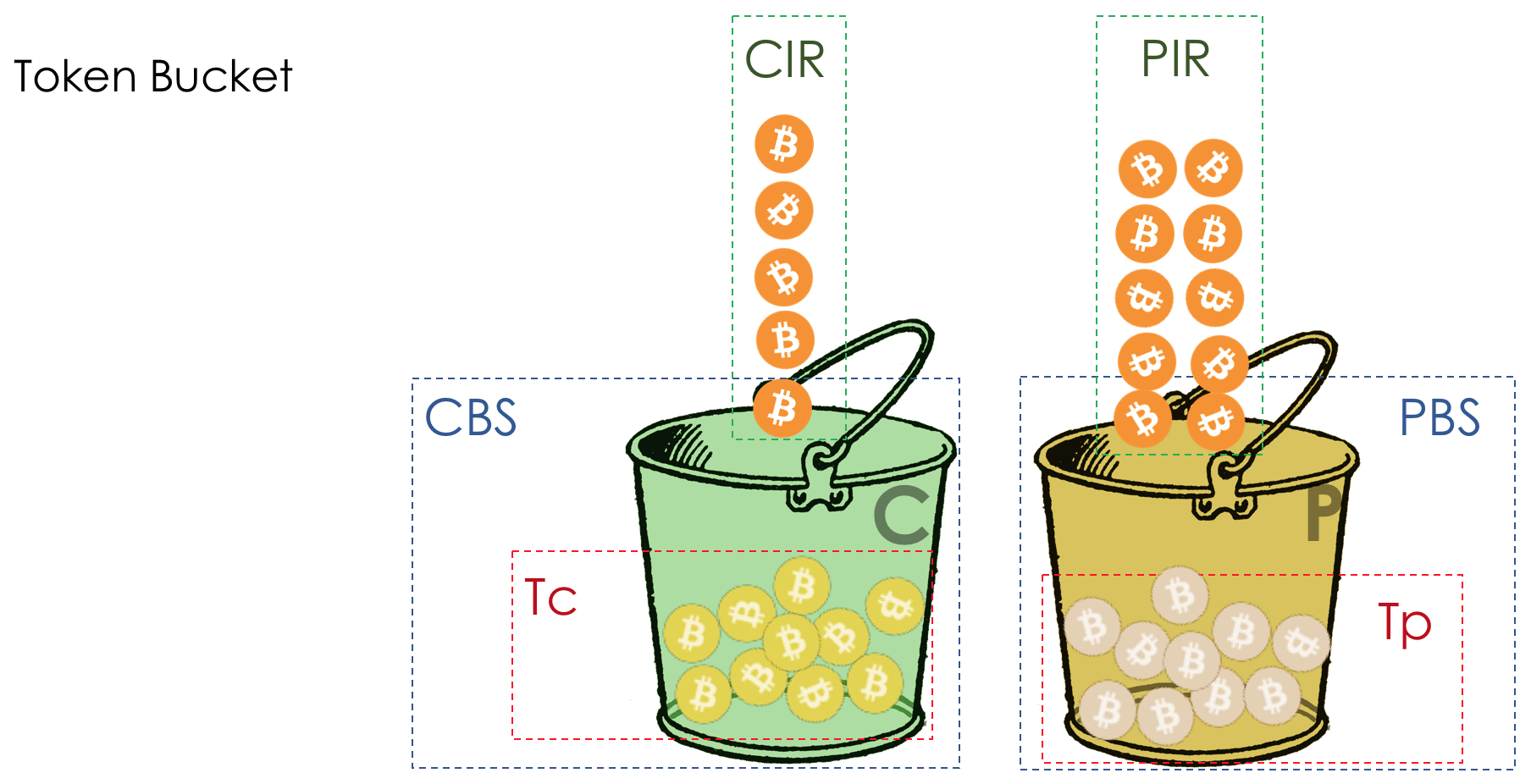 有什么规则?一个大小为B字节的数据包到达。
有什么规则?一个大小为B字节的数据包到达。- 如果存储桶P中没有足够的硬币,则该包将标记为红色。硬币没有被拔出。否则:
- 如果存储桶C中没有足够的硬币,则将数据包标记为黄色,然后从存储桶P中取出B个硬币。否则:
- 包装上用绿色标记,并且从两个桶中抽出B硬币。
 也就是说,tr-TCM中的规则是不同的。只要交通量处于保证的速度之内,就会从两个桶中都卸下硬币。因此,当硬币在存储桶C中用完时,它们将保留在P中,但不会超过PIR(如果仅从C中取出,则P会填满更多的东西并提供更快的速度)。因此,如果它高于保证水平但低于峰值,则仅从P中删除硬币,因为在C中已经没有任何东西。tr-TCM不仅监视突发,而且还监视恒定的峰值速度。tr-TCM在RFC 2698中进行了描述。也用于PHB AF中的抛光。
也就是说,tr-TCM中的规则是不同的。只要交通量处于保证的速度之内,就会从两个桶中都卸下硬币。因此,当硬币在存储桶C中用完时,它们将保留在P中,但不会超过PIR(如果仅从C中取出,则P会填满更多的东西并提供更快的速度)。因此,如果它高于保证水平但低于峰值,则仅从P中删除硬币,因为在C中已经没有任何东西。tr-TCM不仅监视突发,而且还监视恒定的峰值速度。tr-TCM在RFC 2698中进行了描述。也用于PHB AF中的抛光。
限速摘要
整形会在流量超出时阻止流量,而抛光则会丢弃流量。整形不适用于对延迟和抖动敏感的应用。为了在硬件中实现抛光,使用令牌桶算法进行整形-泄漏桶。令牌桶可以是:- 一桶-单率-两种颜色标记。允许有效的突发。
- 有两个铲斗-单速-三色标记(sr-TCM)。铲斗C(CBS)的多余部分倒入铲斗E。允许浪涌和冗余浪涌。
- 有两个铲斗-两个等级-三个颜色标记(tr-TCM)。铲斗C和P(PBS)以不同的速度独立补充。允许峰值速度以及允许和过度的爆发。
sr-TCM着重于超出限制的流量。 tr-TCM-以到达的速度。可以在设备的输入和输出处使用抛光。成型主要在出口处。对于PHB CS和EF,使用单速率两种颜色标记。对于AF,sr-TCM或tr-TCM。为了更好地理解,我建议参考原始RFC或在此处阅读。Token Bucket . , , , , .
, — , . , , , — .
, . — . .
上面,我介绍了QoS的所有基本机制,如果不深入介绍分层QoS。复杂的系统,带有许多活动部件。到目前为止一切都很好(对吗?)听起来不错,但是路由器的香草外部面板下发生了什么?多年来,供应商一方面增加了轮廓,开发了先进的芯片,扩展了缓冲区,以适应不断增长的流量及其新类别,另一方面则解决了由第一段引起的日益增长的问题。正在进行的比赛。如果竞争对手没有丢包,则一定不能丢包。如果对手在客户的门下站着,您将无法拒绝其功能。艾达进入独资企业的巢穴!9. QoS的硬件实现
在本章中,我承担了不感恩的任务。如果您尽可能简单地描述它,那么总会有人说现实并非如此。如果按原样描述,则读者会丢弃该文章,因为它将变成一张海底图画,更准确地说,是一张在一张纸上用不同颜色的铅笔绘制的三艘船的图画。总的来说,我将声明现实中的一切与现实都不相同,并且我将按照一个简单演示的版本进行操作。请原谅我的完美主义者。是什么控制节点的行为并触发与包有关的适当机制?它在标题之一中具有优先级吗?是的,没有。
 如上所述,在网络设备内,标准交换报头通常不复存在。
如上所述,在网络设备内,标准交换报头通常不复存在。 数据包一到达交换芯片,就会立即从中删除标头并发送以进行分析,并且有效负载会在某种临时缓冲区中消失。基于标题,将进行分类(BA或MF),并做出有关转发的决定。片刻之后,带有有关该程序包的元数据的内部标头被挂在该程序包上。该元数据包含许多重要信息-发送方和接收方的地址,输出芯片,信元序列号,如果有数据包分段,则必须具有类标记(CoS)和丢弃优先级。仅以内部格式标记-它可能与DSCP一致,也可能不一致。原则上,在包装盒内您可以设置任意的标记长度,而不必依赖于标准,并且可以在包装中定义非常灵活的动作。在思科,内部标记称为QoS组,在瞻博网络-转发类,华为尚未决定:在其内部称为内部优先级,在本地优先级,在服务级以及仅在CoS的位置。在评论中添加其他供应商的名称-我将添加。根据节点执行的分类来分配此内部标记。重要的是,除非另有说明,否则内部标签仅在节点内部起作用,而不会出现在将从节点发送的数据包的报头中的标签上-内部标签将保持不变。但是,在分类后进入DS域的入口处,通常对该网络中接受的特定服务类别进行重新标记。然后,内部标签将转换为网络上该类别所接受的值,并记录在要发送的数据包的报头中。CoS和Drop Precedence内部标记仅在给定节点内定义行为,除非重新标记头,否则不会显式传递给邻居。CoS和丢弃优先级定义了PHB,其机制和参数:拥塞预防,拥塞管理,调度和重新标记。
数据包一到达交换芯片,就会立即从中删除标头并发送以进行分析,并且有效负载会在某种临时缓冲区中消失。基于标题,将进行分类(BA或MF),并做出有关转发的决定。片刻之后,带有有关该程序包的元数据的内部标头被挂在该程序包上。该元数据包含许多重要信息-发送方和接收方的地址,输出芯片,信元序列号,如果有数据包分段,则必须具有类标记(CoS)和丢弃优先级。仅以内部格式标记-它可能与DSCP一致,也可能不一致。原则上,在包装盒内您可以设置任意的标记长度,而不必依赖于标准,并且可以在包装中定义非常灵活的动作。在思科,内部标记称为QoS组,在瞻博网络-转发类,华为尚未决定:在其内部称为内部优先级,在本地优先级,在服务级以及仅在CoS的位置。在评论中添加其他供应商的名称-我将添加。根据节点执行的分类来分配此内部标记。重要的是,除非另有说明,否则内部标签仅在节点内部起作用,而不会出现在将从节点发送的数据包的报头中的标签上-内部标签将保持不变。但是,在分类后进入DS域的入口处,通常对该网络中接受的特定服务类别进行重新标记。然后,内部标签将转换为网络上该类别所接受的值,并记录在要发送的数据包的报头中。CoS和Drop Precedence内部标记仅在给定节点内定义行为,除非重新标记头,否则不会显式传递给邻居。CoS和丢弃优先级定义了PHB,其机制和参数:拥塞预防,拥塞管理,调度和重新标记。
通过该圆通过我已经在所考虑的输入和输出接口之间的数据包的前条。实际上,事实证明这是计划外的,因为在某些时候,很明显,如果不了解体系结构,谈论QoS还为时过早。但是,让我们重复一遍。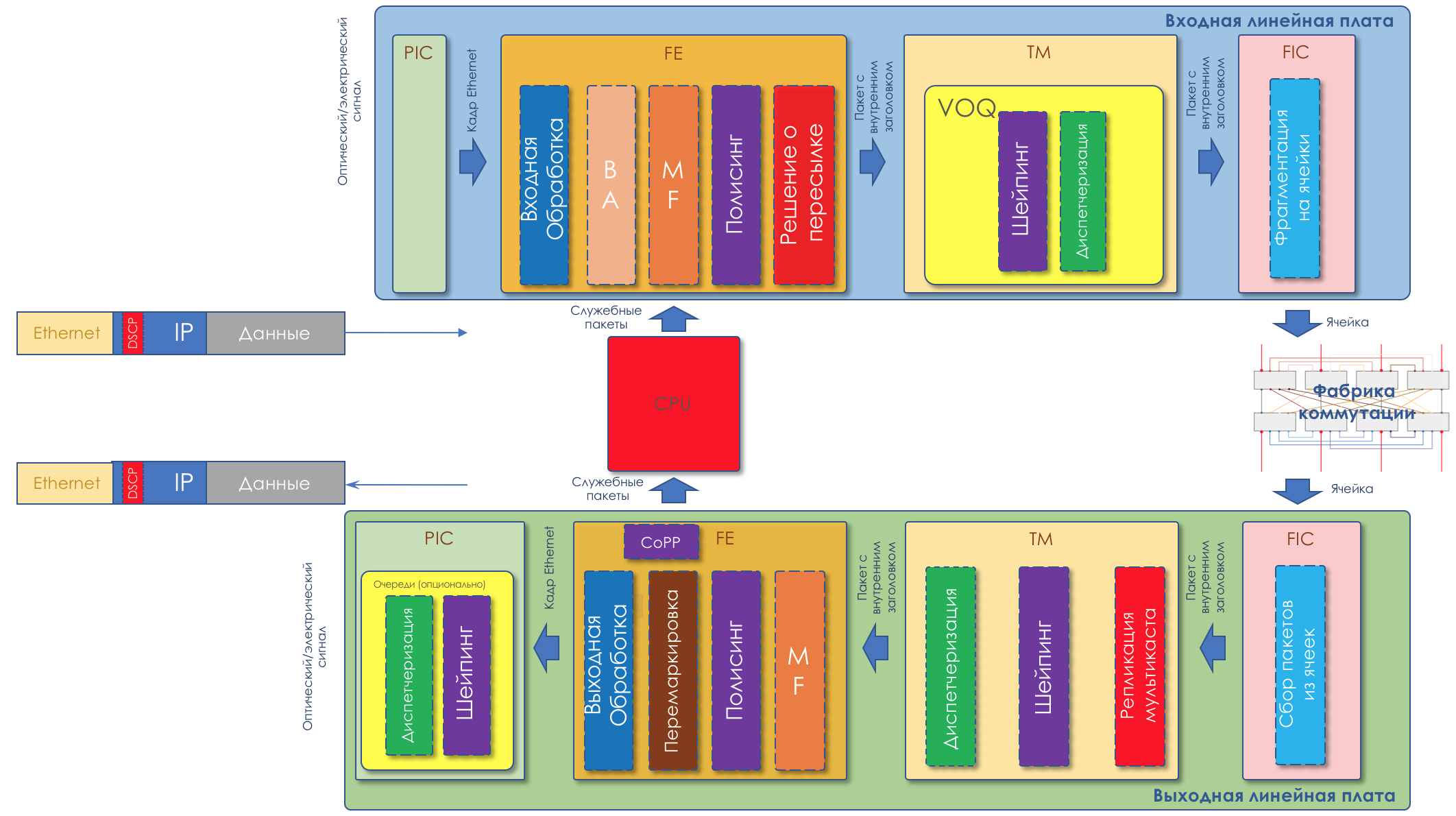
- 信号到达物理输入接口及其芯片(PIC)。比特流从中流过,然后是带有所有报头的数据包。
- 在输入交换芯片(FE)旁边,标头与数据包主体分开。进行分类,并确定需要将数据包进一步发送到何处。
- 输入队列旁边(TM / VOQ)。此处已经根据包的类别将包布置在不同的队列中。
- 到交换工厂(如果有)的地方。
- 在输出队列(TM)旁边。
- (FE), .
- (, ) (PIC).
在这种情况下,路由器必须求解一个复杂的方程式。将所有内容扩展到类中,为某人提供宽带,某人低延迟,某人确保没有损失。并且在可能的情况下,同时有时间跳过所有流量。此外,您需要进行整形,也可能需要抛光。如果突然发生过载,请进行处理。这不包括查找,ACL处理,统计信息的计数。令人羡慕的份额。但是,机器人注入的不是人。实际上,QoS机制仅在两个地方起作用-交换芯片和流量管理芯片/队列。同时,在交换芯片上进行的操作需要分析或对标头进行操作。TM负责其余的工作。基本上,这些是具有预定义算法和自定义参数的常规操作:TM是一个智能缓冲区,通常基于SD-RAM。他很聪明,因为,a)可编程,b)他可以使用队列来完成各种棘手的事情。它通常是分布式的-SD-RAM芯片位于每个接口板上,并将它们组合在一起成为VOQ(虚拟输出队列),从而解决了行头阻塞问题。事实是,如果交换芯片或输出接口被阻塞,它们会要求输入芯片减速,并且一段时间内不发送流量。如果在所有方向上只有一个队列,那么所有其他队列都受一个输出接口的困扰是非常令人失望的。这是行阻塞的负责人。输入接口板上的VOQ为每个现有的输出接口创建多个虚拟输出队列。此外,现代设备中的这些生产线还考虑了包装的标签。有关VOQ的详细说明,请参见此处的一系列说明。顺便说一句,它们实际上是放置在队列中,正在被提升,不是从它们本身中取出数据包本身,而只是从它们中取出记录了。用大位数组进行这么多手势是没有意义的。当在记录上模拟QoS时,数据包完美地存储在它们的内存中,并从该地址处检索到。VOQ是一个软件队列(英文术语Software Queue更准确)。在此之后,紧接在接口之前,还有一个硬件队列,该队列始终严格按照FIFO工作。几乎不可能控制其任何参数(例如,Cisco允许您使用tx-ring-limit命令仅配置深度)。在软件和硬件队列之间,您可以运行任意调度程序。 Head / Tail-drop和AQM,抛光和定型工作在程序队列中。硬件队列的大小非常小(以数据包为单位),因为调度程序会完成所有堆叠线速的工作。不幸的是,您可以在这里进行很多保留,并确实用红笔划掉了所有内容,并说“供应商X并非如此”。
我想再谈一下服务包。它们的处理方式不同于中转用户数据包。由于是在本地生成的,因此不会检查它们是否符合ACL规则和速度限制。基于协议类型,来自外部的数据包将从输出交换芯片发送给CPU,这些数据包进入其他队列-到达CPU。例如,BFD具有最高优先级,OSPF可以等待更长的时间,并且ICMP通常不会令人恐惧。也就是说,数据包对于网络而言越重要,发送到CPU时其服务等级就越高。这就是为什么在ping或跟踪过程中在传输跃点上看到变化的延迟是正常的-ICMP不是CPU的优先级流量。另外,协议包被应用CoPP-控制平面保护(或管制)-避免CPU高利用率的速度限制-同样,在问题开始之前,低优先级队列中的可预测下降更好。当大量广播流量开始进入设备时,CoPP将从目标DoS和异常网络行为(例如环路)中获得帮助。
有用的链接
- 有关QoS的理论和哲学的最佳书籍:启用QOS的网络:工具和基础。
某些摘录可在此处阅读,但我建议从头至尾阅读,不要交换。 - QoS Huawei: Special Edition QoS(v6.0) . PHB .
- sr-TCM tr-TCM : Understanding Single-Rate and Dual-Rate Traffic Policing .
- VOQ: What is VOQ and why you should care?
- QoS MPLS: MPLS and Quality of Service .
- QoS Juniper: Juniper CoS notes .
- QoS TCP UDP. : The TCP/IP Guide
- , , : TCP .
- , FQ: Queuing and Scheduling .
, , An Introduction to Computer Networks , , Introduction, . .
- WFQ , , , , , : Weighted Fair Queueing: a packetized approximation for FFS/GP.
- 另外,我也没有涉及LFI机制,因为在我们现有的100 GB接口中,这也很困难,但熟悉一下它可能会很有趣:链接分段和交织。
结论
此版本有许多评论者。谢谢啦
Alexander Fatin(LoxmatiyMamont)的介绍性文字和有关文本表达力和清晰度的宝贵建议。Alexander Clipper(@ metallicat20)进行了同行评审。亚历山大·克里姆年科(@ v00lk)提出了严厉的批评和最近几天发生的最大变化。Andrey Glazkov(@glazgoo)对结构,术语和逗号进行了评论。KDPV的Artyom Chernobay。Anton Klochkov(@NAT_GTX)与Miran联络。Miran(miran.ru)用于用Eva组织服务器并进行广播。传统上,我的家人这次遭受的损失最少,因为在最困难的时刻她不在附近。