如今,光纤已成为人类生活中最多样化领域不可或缺的一部分:从家庭互联网到内窥镜检查。 光纤的使用具有许多优势:传输速度,物理强度,带宽,信息安全性等。
为了增加吞吐量,当在几个并行信道上传输信息时,创建了多模光纤(MMF)。 尽管具有所有优点,但MMF也有许多缺点,研究人员决定消除其中之一,以改善图像转印过程。 底线是这样的:当将样本投影到MMF的近端时,我们在远端获得的图像是斑点,因为它的传入数据分布在许多模式中,沿着光纤的长度具有不同程度的传播。 科学家建议将多模光纤和深度学习相结合用于人工神经网络,以获取准确的图像,包括使用内窥镜检查时。 让我们深入研究人员的报告,并尝试了解其工作原理以及产生结果的原因。 走吧
学习基础使用人工神经网络解密通过MMF传输的图像的技术已经开发了很长时间。 因此,在早期作品中,描述了一个两层网络,该网络能够识别穿过10米缝合光纤的大约10张图像。
在这项研究中,该系统更为复杂,但据科学家称,效率更高。 第一步是收集大量的斑点样本,这些样本是通过将图像通过MMF来获得的。 它们已成为训练DNN(基于
深度学习*的人工神经网络)的知识库。
 斑点图像示例
斑点图像示例深度学习* -基于演示的机器学习方法的组合,而不是针对特定任务的专门算法。
DNN架构非常复杂,大约有14个
隐藏层* 。
隐藏层* -人工神经网络由计算单元(神经元)组成,分为3类:输入,隐藏和输出。 输入接收信息,隐藏的输入执行各种计算,而周末则进一步传输信息。
为了在DNN上进行实验,创建了一个包含20,000个手动输入数字的数据库。 接下来,将基地随机分为几组:
- 16,000位数字-培训;
- 2,000位数字-验证;
- 2,000位数-测试。
准备实验下图显示了用于收集数据的光学系统图。
 图片编号1:安装图:
图片编号1:安装图:
激光源-激光辐射源(光束);
HWP-半波片;
M1是一面镜子;
SLM-空间光调制器;
P是线性偏振器;
L是镜头;
BS-分束器;
OBJ-显微镜物镜;
OF-光纤;
CCD-CCD相机。现在按顺序。 波长为560 nm的激光束将光线引导通过
渐变光纤* ,该
光纤的纤芯直径为62.5μm,
数值孔径为* 0.275。
渐变MMF *是一种折射率不均匀的光纤,当折射率从边缘到光纤轴逐渐减小时。
 光纤类型的比较:阶梯多模,梯度多模和单模(从上到下)。
光纤类型的比较:阶梯多模,梯度多模和单模(从上到下)。
数值孔径*是光束与轴之间最大角度的正弦值。 在这种情况下,在光纤上的辐射分布中存在全内反射。
在特定波长下,光纤能够支持约4,500个空间模式。 输入样本(图像)显示在空间光调制器上,然后使用4f系统将其重定向到MMF的近端(靠近中心)面。 在光纤的远端,另一个4f系统可视化从光纤的远侧(远离中心)面到CCD相机的散斑。
CCD *是一种电荷耦合器件,它实现了半导体体积中受控电荷传输的技术。
为了检查相位和幅度模型作为梯度MMF的输入信号,在SLM之前安装了一个半波片,在SLM之后安装了一个线性偏振片。
如前所述,人工编写的数字充当示例。 它们来自
MNIST数据库 。
在通过DNN处理之前,记录在CCD1或CCD2上的每个图像都被裁剪为1024×1024像素。 此外,将获得的斑点图像缩小为32×32像素,并用作DNN的输入。
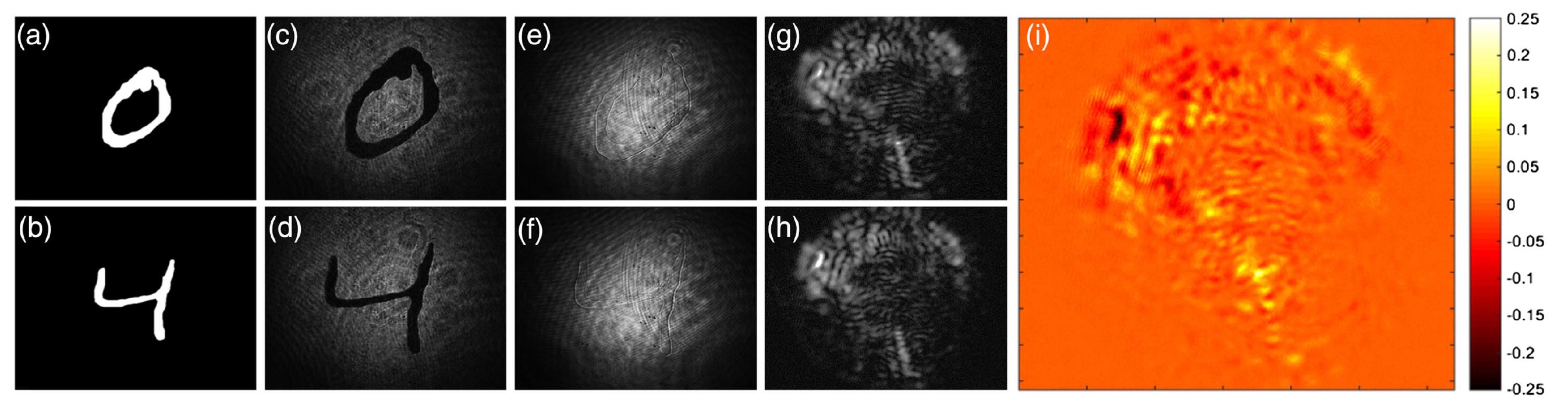
图片编号2在图像
2a和
2b中,我们看到了数字模式(0和4)。
2c和
2d是相同的数字,但是在振幅调制之后,当发送信号的振幅发生变化时。
图2e和
2f是当载波振荡的相位与信号成正比变化时的相位调制之后的采样数字。 我们还可以看到斑点本身,斑点在经过2 cm的距离后被固定在光纤的远端。
区分斑点(
2g和
2h )是非常困难的。 但是,如果我们比较图像
2d和
2h (例如,考虑样本“ 4”),则可以隔离DNN可以确定的差异(
2i )。 因此,这些独特的功能将允许系统区分“ 0”和“ 4”,“ 2”和“ 9”,等等。
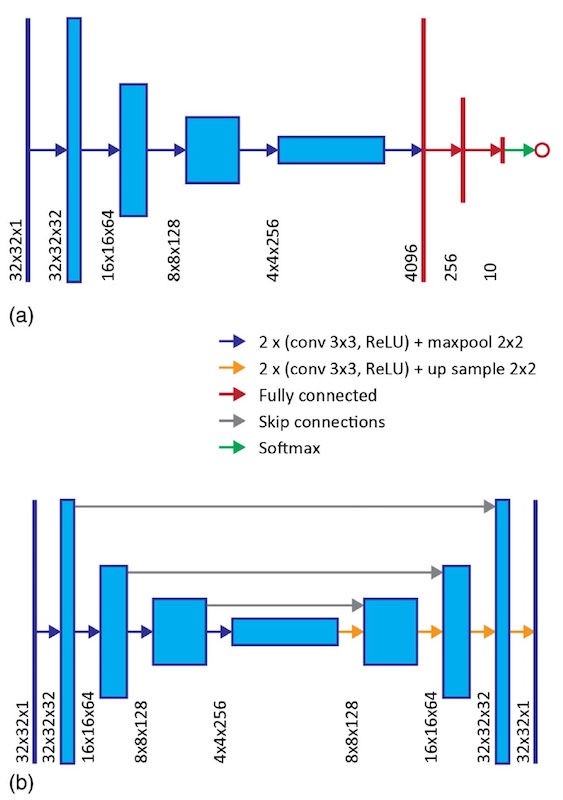
资料处理视觉几何组(VGG)类型(3a)的
卷积神经网络*成为确定斑点和重建输入图像的系统的基础。
卷积神经网络* -ANN架构,其特征在于卷积运算,当图像的每个片段逐元素乘以卷积矩阵时,然后将结果相加并写入输出图像中的相同位置。

卷积神经网络架构的一个例子。
这种系统的引入允许以更高的精度解密图像。 为了重建图像,使用了具有14个隐藏层的“ U-net”类型的卷积神经网络(
3b )。
 图片编号3
图片编号3回想一下,将20,000个数字的基数分为三组(用于培训的16,000,用于测试的2,000和用于测试的2,000)。
培训小组以50个批次(针对重建网络)和500个(针对确定网络)进行处理。 同时,各方为了避免
重新培训*进行了更改。
重新训练* -系统很好地处理训练集中的示例,但不能很好地应对测试示例的示例的情况。
为了最小化均方根误差,使用了学习速度为1 x 10
-4的优化算法。
蚊帐经过训练阶段的时间不超过50个纪元(反向传播周期)。 对于每种情况,训练都要重复10次,以收集有关训练系统准确性的统计数据。
所有DNN均使用Python TensorFlow 1.5库在单个NVIDIA GeForce GTX 1080Ti GPU的基础上实现。
研究成果改建科学家决定更详细研究的第一个参数是系统重建输入数据的能力。

上图显示了将数据通过长度为0.1 m,10 m和1000 m的光纤传递后,数字(0 ... 9)的重构结果。
如我们所见,该过程的结果非常准确,这证实了U-net系统能够隔离未来图像的极端区别特征。
还验证了重建的准确性。 随着纤维长度从96.9%(0.1 m)增加到90.0%(1000 m),该指标降低。
精度降低是由于以下事实:当光纤长度为1 km时,其中会出现温度不均匀性(由于热量和/或折射率变化而导致的材料膨胀),从而改变了信号的光路。 这些过程导致在远端的斑点图案变得不稳定的事实,这使得更难以重构成期望的图像。
研究人员指出,外部暴露于光纤还会降低图像重建的准确性。 因此,随着系统的进一步改进,应当为光纤提供隔热和等温介质,以实现最大程度的重建精度。
重建程序还可以完美地平整已处理图像上的伪像。

例如,该系统将图像(
2a )与远侧散斑(
2g )隔离开,同时去除投影到纤维(
2c和
2e )近端边缘上的缺陷。 另外,该系统试图消除由于样品中的污染或缺陷或光纤本身的结构误差而产生的伪影。
赛弗样本的分类该系统可以重新创建图像,并且此过程的准确性非常出色。 现在我们来分析系统能够多么准确地确定哪个图像(数字)在哪里,也就是在重建后对数据进行分类。
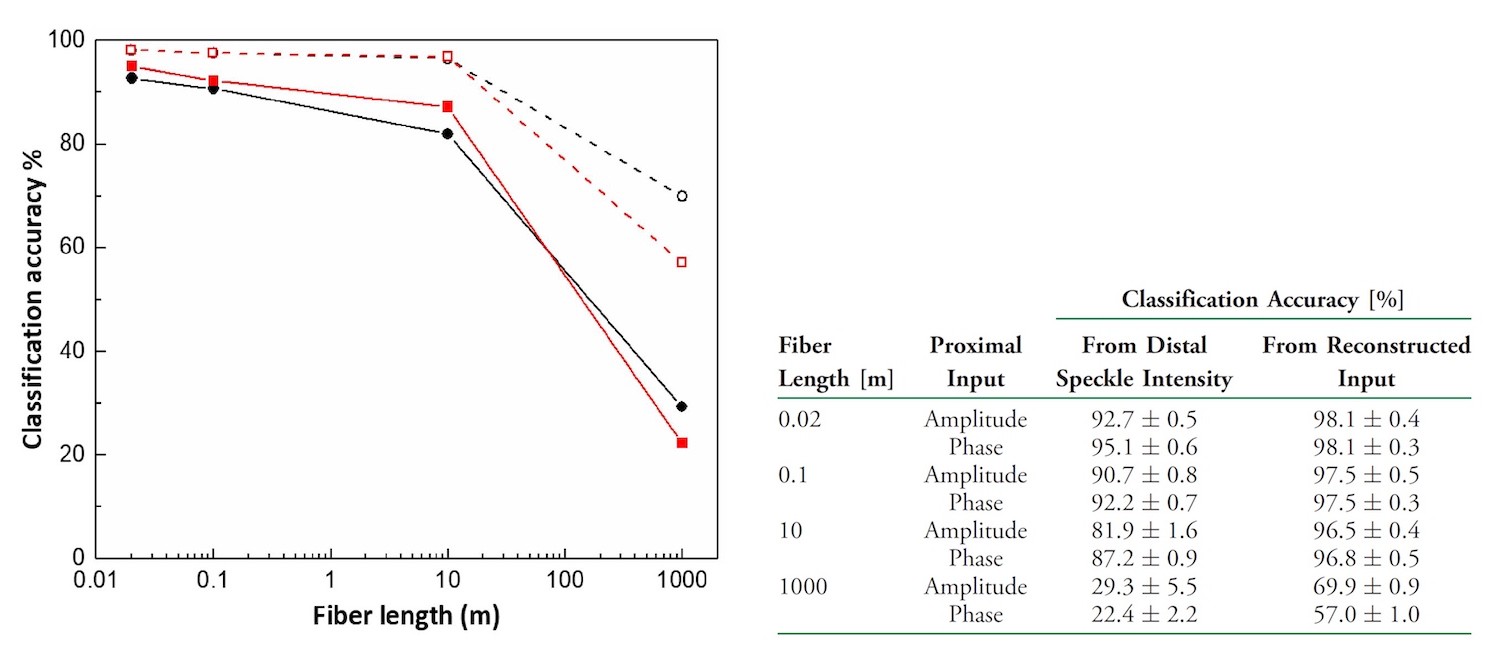
从上面的图表可以看出,分类精度随着传输中所涉及的光纤长度的增加而降低。 类似的趋势是重建的准确性。 无论是振幅模型还是相位,精度都会下降。 在2厘米光纤处-90%的精度。 这是一个很好的指标,但是光纤太短。 但是,如果长度为1 km,精度会下降到30%。 研究人员将其归因于散射损耗增加,模式耦合和远端斑点漂移。 所有这些“干扰”是由光纤长度的增加引起的。
 远处斑点变化
远处斑点变化录制速度为83 fps。 作为在1 km光纤上的实验,传输了空图像。
 (a)和(b)-取自上述记录的2帧,(c)-比较。
(a)和(b)-取自上述记录的2帧,(c)-比较。记录这些帧的时间差为2秒。 正如我们在图(c)中看到的那样,它们之间的差异非常明显。 斑点的这种急剧变化可能与环境温度波动或设备上的气流有关(图1),这可能导致光纤的微小干扰。 但是,当纤维长度增加时,这种干扰的强度就会变得明显。
事实证明,由于这些“干扰”,系统的所有操作都是徒劳的。 但是,科学家们并没有阻止这些困难,而是鼓励他们思考。
决定进行散斑位移及其对图像分类准确性的影响的研究。 为此,在10,000个样本(可用样本的一半)的基础上对VGG网络进行了训练,然后进行了测试,但对另一半样本进行了测试。 重复该过程,更换2组样品。 结果表明,分类的准确性没有显着变化,因为斑点的移动不是偶然的,这意味着ANN能够在此过程中进行学习,记忆和确定。
幅度调制和相位调制之间的差异可以忽略不计。 在光纤长度为10 m且进行相位调制的情况下,分类比幅度调制要好一些。 这是由于在光纤的模上光分布更加均匀。 使用幅度调制时,由于光纤的选择性空间激发,限制了传输中涉及的模式数量。
如果考虑使用1公里长的光纤,则振幅调制已经超过相位。 当光穿过一条长光纤时,所有模式都会立即参与信息传输。
 误差矩阵(混淆矩阵)
误差矩阵(混淆矩阵)为了提高分类精度,还使用已经重构的样本对ANN进行了训练。 还应用了误差矩阵,这大大提高了分类准确性。
例如,对于1公里长的光纤,数字4和9之间以及3、5、6和8之间会造成混淆。
要确认,仅查看重建结果。
 数字4和9
数字4和9 数字3、5、6和8
数字3、5、6和8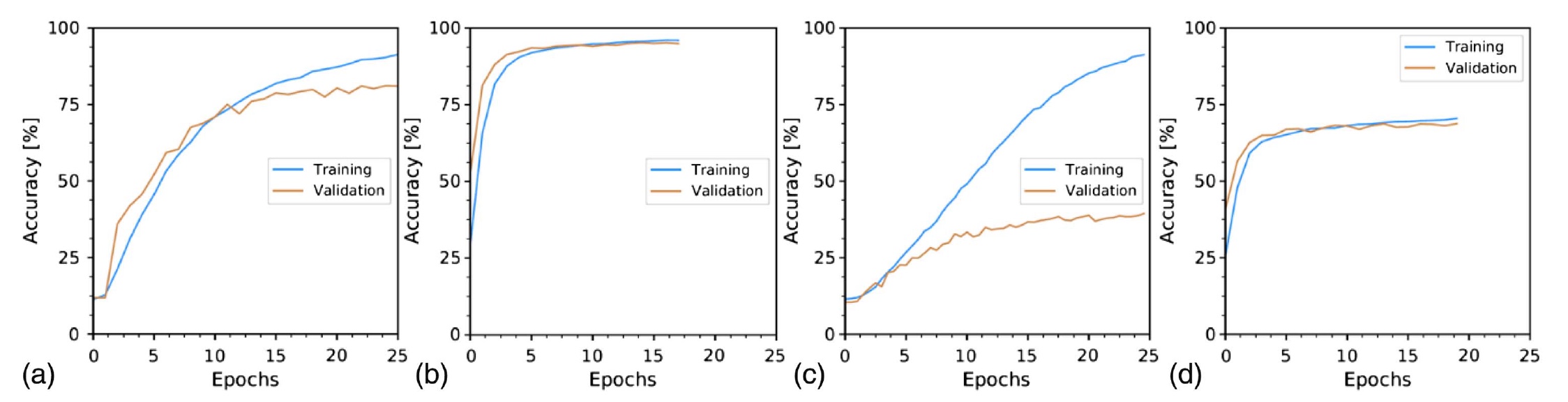
上图显示了图像分类精度随时间的变化:
a-10 m的纤维和远端斑点;
b-10 m的光纤和重建的图像;
s-1公里的光纤和远端斑点;
d-1公里的光纤和重建图像。
要详细了解这项研究的细微差别,我强烈建议您查看科学家的报告。 在同一页面上也可以使用PDF版本(“获取PDF”按钮)。
结语这项研究显示出极好的结果,表明了它的未来发展和实际实施。 以上方法可以应用于电信(在多路复用中解码),甚至在医学(内窥镜)中。
在计算了时间成本后,科学家发现他们中的大多数人都去准备系统,或者去训练系统。 这表明,一个已经受过训练的系统可以非常快地执行其功能,最长可达毫秒。 唯一的限制将是硬件功率。
当然,在基于深度学习的人工神经网络领域中,还需要进行更多的研究。 但是它们的作用现在可见。 改进现有系统(无论其应用程序如何)与创建新系统一样重要。 毕竟,如果您可以对其进行简单地改进,就不一定总是需要重新发明轮子。 正如实践所示,主要的事情是跳出框框思考,从我们自己和他人的错误中学习,设定有时不可能的任务并相信自己。 如果一个想法可以造福人类,那么必须实现它。
感谢您与我们在一起。 你喜欢我们的文章吗? 想看更多有趣的资料吗? 通过下订单或将其推荐给您的朋友来支持我们,
为我们为您发明的入门级服务器的独特模拟,为Habr用户提供
30%的折扣: 关于VPS(KVM)E5-2650 v4(6核)的全部真相10GB DDR4 240GB SSD 1Gbps从$ 20还是如何划分服务器? (RAID1和RAID10提供选件,最多24个内核和最大40GB DDR4)。
购买六个月的新Dell R630
可免费获得3个月
-2个Intel Deca-Core Xeon E5-2630 v4 / 128GB DDR4 / 4x1TB HDD或2x240GB SSD / 1Gbps 10 TB-每月99.33美元起 ,仅直到8月底,订购可以在
这里 。
戴尔R730xd便宜2倍? 仅
在荷兰和美国,我们有
2台Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100电视(249美元起) ! 阅读有关
如何构建基础架构大厦的信息。 使用价格为9000欧元的Dell R730xd E5-2650 v4服务器的上等课程?