机器学习项目的成功通常不仅与使用不同库的能力有关,而且与对数据来源领域的了解有关。 阿列克谢·卡尤琴科(Alexei Kayuchenko),谢尔盖·贝洛夫(Sergey Belov),亚历山大·德罗伯托夫(Alexander Drobotov)和阿列克谢·斯米尔诺夫(Alexey Smirnov)的团队在PIK Digital Day竞赛中提出的解决方案就是这一论断的一个很好的例证。 他们获得了第二名,几周后,他们谈论了他们的参与以及下一次
Yandex ML培训中的构建模型。
阿列克谢·卡尤琴科(Alexey Kayuchenko):
-下午好! 我们将谈论我们参加的PIK Digital Day竞赛。 关于团队的一些事。 我们四个人。 所有这些都具有完全不同的背景,来自不同的领域。 实际上,我们在决赛相遇了。 球队在决赛前一天组建。 我将谈论比赛的过程,工作的安排。 然后Seryozha会出来,他将介绍数据,Sasha将介绍提交的内容,最后的工作过程以及我们如何在排行榜上前进。

简要介绍比赛。 该任务非常适用。 PIC通过提供有关公寓销售的数据来组织这次比赛。 作为培训数据集,莫斯科和莫斯科地区有一个故事,具有两年半的属性。 比赛分为两个阶段。 这是一个在线阶段,每个参与者都分别尝试制作自己的模型,而离线阶段的时间不长,从早上到晚上只有一天。 它击中了在线舞台的领导者。
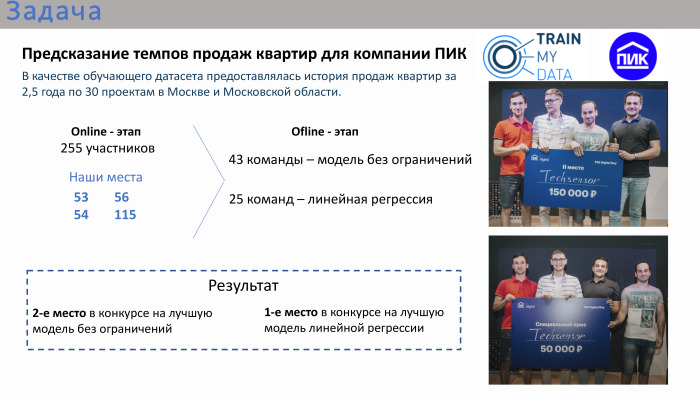
根据在线竞赛的结果,我们的排名甚至没有进入前10名,甚至没有进入前20名。 我们到过50多个地方。 在最后阶段,即离线阶段,有43个团队。 尽管有可能团结起来,但有很多团队由一个人组成。 大约三分之一的团队有一个以上的人。 决赛有两场比赛。 第一次比赛是没有限制的模型。 可以使用任何算法:深度学习,机器学习。 同时,举行了一场竞赛,争夺最佳线性回归解决方案。 组织者认为线性回归也很适用,因为比赛本身在整体上非常适用。 也就是说,任务已经提出-必须预测公寓的销售量,并具有过去2.5年的历史数据和属性。
我们的团队在无限制的最佳模型竞赛中排名第二,在最佳回归的竞赛中排名第一。 二等奖。

我可以说关于组织的总体过程,决赛非常紧张,非常紧张。 例如,我们的获胜决定是在停止游戏前两分钟上传的。 我认为先前的决定将我们排在第四或第五位。 也就是说,我们一直工作到最后,没有放松。 PIC组织得很好。 有这样的桌子,甚至还有阳台,这样您就可以坐在大街上,呼吸新鲜空气。 食物,咖啡,一切都提供了。 图片显示每个人都坐在团队中工作。
谢尔盖将提供有关数据的更多信息。
谢尔盖·贝洛夫(Sergey Belov):
谢谢 PIC为我们提供了几个数据文件。 主要的两个是train.csv和test.csv,其中PIC本身生成了大约50个功能。 火车由大约一万行组成,测试-两千行。
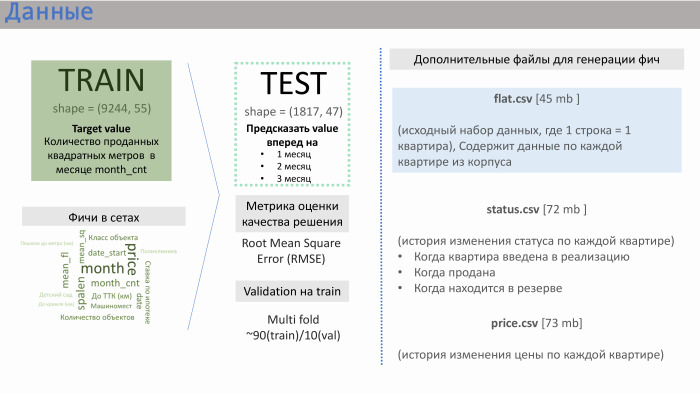
字符串提供了什么? 它包含销售数据。 也就是说,作为价值(在此例中为目标),我们对特定建筑物内的公寓平均销售了平方米。 大约有一万条这样的线路。 PIK本身生成的集合中的功能显示在幻灯片上,具有我们得到的近似意义。
我在开发公司的经验为我提供了帮助。 诸如距公寓到克里姆林宫或运输环的距离,停车位的数量等功能对您的销售影响不大。 影响是由对象的类别,休眠以及最重要的是当前实施中的套间数量引起的。 PIC没有生成此功能,但他们为我们提供了三个附加文件:flat.csv,status.csv和price.csv。 我们决定看一下flat.csv,因为这里只有有关公寓数量及其状态的数据。
如果有人想知道我们的决定成功与否,那么这无疑是一个团队合作。 从比赛一开始,我们就非常和谐地工作。 我们立即在大约20分钟内讨论了将要做什么。 我们得出的一般结论是,您需要使用数据的第一件事是因为任何数据科学家都知道数据中包含很多数据,而胜利通常是由于团队产生的某些功能。 处理数据后,我们主要使用了各种模型。 我们决定看看我们的功能在这些模型中给出的结果,然后我们专注于无限模型和线性回归模型。
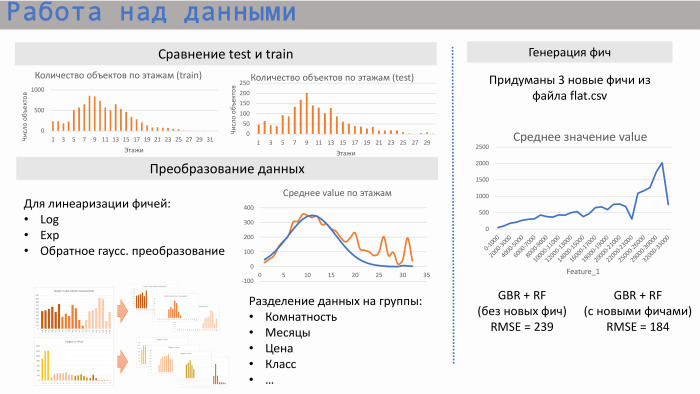
我们开始处理数据。 首先,我们研究了火车组测试如何相互关联,即该数据的区域是否相交。 是的,它们相交:在公寓数量,休眠状态以及一定的平均楼层数方面。
为了进一步进行线性回归,我们开始进行某些转换。 就像指数的标准对数一样。 例如,在中层的情况下,这是用于线性化的高斯逆变换。 我们还注意到,有时最好将数据分成几组。 例如,如果我们以从公寓到地铁或其房间的距离为例,那么市场会略有不同,因此最好对每个此类群体进行划分,制作不同的模型。
我们从flat.csv文件生成了三个功能。 这里介绍其中之一。 可以看出,除了沉降以外,它还具有相当好的线性关系。 这是什么功能? 它对应于当前正在实施的公寓数量。 而且此功能在低值时效果很好。 也就是说,售出的公寓数量不能超过销售数量。 但是实际上,在这些文件中,某些人为因素是被规定的,因为它们通常是由人编写的。 我们直接看到有一些点被打出该区域,因为它们被错误地堵塞了一些。
来自scikit-learn的示例。 来自GBR和Random Forest的无功能模型给出了RMSE 239,并具有这三个功能-184。
Sasha将讨论我们使用的模型。
亚历山大·德罗伯托夫(Alexander Drobotov):
-关于我们的方法的几句话。 正如你们所说,我们都是不同的,来自不同的领域,不同的教育。 我们有不同的方法。 在最后阶段,Lesha更多地使用了来自Yandex的XGBoost(最有可能的是,我的意思是CatBoost-ed。),Seryozha-scikit-learn库,I-LightGBM和线性回归。

XGBoost模型,线性回归和Prophet是向我们展示最佳分数的三个选项。 对于线性回归,我们混合了两个模型,对于一般竞争,XGBoost,我们添加了一些线性回归。

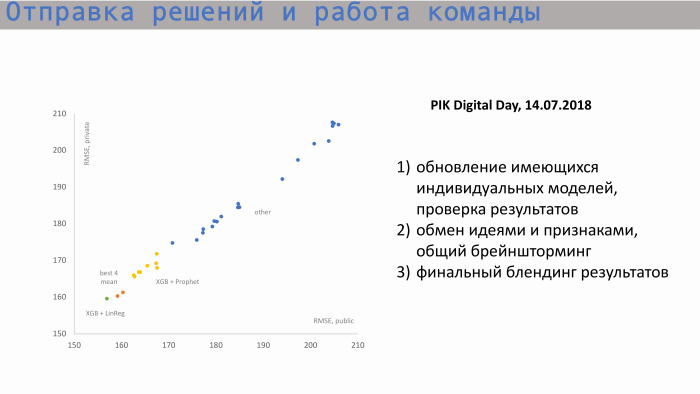
这是发送决策和团队合作的过程。 在左侧的图中,X轴是公制RMSE(度量标准值),Y轴是私密分数RMSE。 我们从这些职位开始。 这是每个参与者的个人模型。 然后,在交换想法并创建新功能之后,我们开始寻求最佳成绩。 我们对各个模型的值大致相同。 最好的个人模型是XGBoost和Prophet。 先知创建了一个累计销售的预测。 有一个开始广场的迹象。 也就是说,我们知道我们总共有多少套公寓,我们了解了什么历史价值和寻求增值的增值。 先知对未来进行了预测,并在接下来的时期内发布了值并将其提交给XGBoost。
我们最好的个人成绩的融合在这附近,这两个橙色的点。 但是,这个分数不足以使我们达到最高水平。
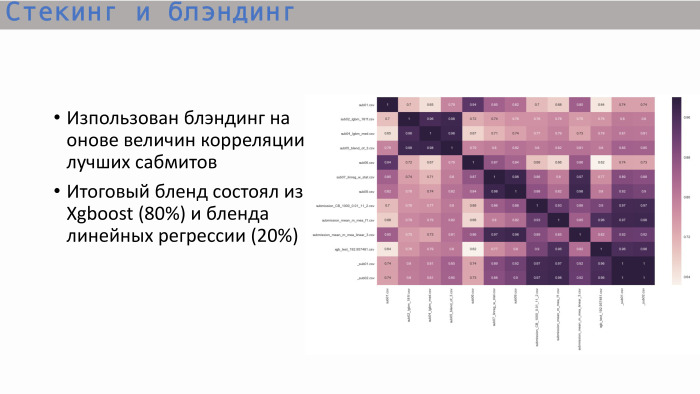
在研究了最佳提交的通常相关矩阵之后,我们看到了以下内容:树木-这是合乎逻辑的-显示出接近于1的相关性,而最佳树给出了XGBoost。 与线性回归的相关性不是很高。 我们决定以8比2的比例混合这两个选项。这就是我们获得最佳最终解决方案的方式。
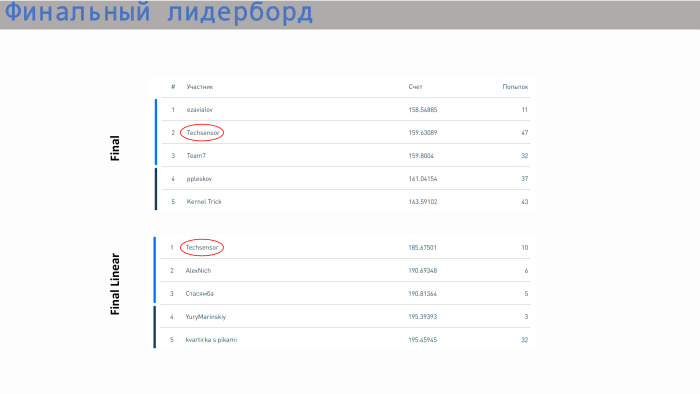
这是结果排行榜。 我们的团队在无限模型中排名第二,在线性模型中排名第一。 至于得分-在这里所有的值都非常接近。 差别不是很大。 线性回归已经在区域5中迈出了一步。谢谢!