
在本文中,我们将构建一个卷积神经网络的基本模型,该模型能够执行图像中
的情感识别 。 在我们的案例中,识别情绪是一个二元分类任务,其目的是将图像分为正面和负面。
所有代码,笔记本文档和其他材料(包括Dockerfile)都可以在
此处找到。
资料
实际上,所有机器学习任务的第一步都是了解数据。 来吧
数据集结构
原始数据可以在
此处下载(在
Baseline.ipynb文档中,此部分中的所有操作都是自动执行的)。 最初,数据位于Zip *格式的存档中。 解压缩它并熟悉接收文件的结构。
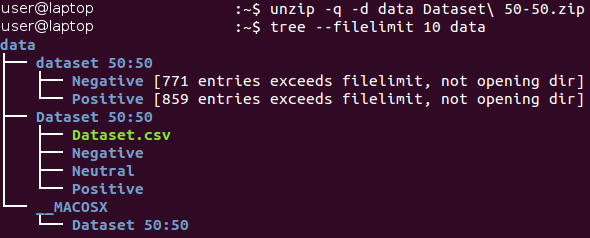
所有图像都存储在“数据集50:50”目录中,并分布在其两个子目录之间,两个子目录的名称对应于其类别-负数和正数。 请注意,该任务有点
不平衡 -53%的图像为正,只有47%的图像为负。 通常,如果不同类别中示例的数量变化非常大,则分类问题中的数据将被认为是不平衡的。 处理不平衡数据
的方法有很
多种 ,例如,过采样,过采样,更改数据权重等。在我们的案例中,不平衡无关紧要,不应严重影响学习过程。 只需要记住,幼稚的分类器总是产生“正”值,它将为该数据集提供约53%的精度值。
让我们看一下每个类的一些图像。
负数

 正面的
正面的


乍一看,来自不同类别的图像实际上彼此不同。 但是,让我们进行更深入的研究,并尝试找到不良示例-属于不同类别的相似图像。
例如,我们有大约90张蛇标记为负的图像和大约40张非常相似的蛇标记为正的图像。
蛇的正面形象 蛇的负像
蛇的负像
蜘蛛(130个负像和20个正像),裸露(15个负像和45个正像)和其他一些类别也会发生相同的对偶。 人们会觉得图像的标记是由不同的人执行的,他们对同一幅图像的感知可能会有所不同。 因此,标签包含其固有的不一致。 这两条蛇的图像几乎相同,而不同的专家将它们归为不同的类别。 因此,我们可以得出结论,由于其性质,在执行此任务时几乎无法确保100%的准确性。 我们认为,对准确性的更现实的估计将是80%的值-该值是基于在初步视觉检查期间在不同类别中发现的相似图像的比例得出的。
培训/验证过程分开
我们始终努力创造最佳模型。 但是,这个概念的含义是什么? 有许多不同的标准,例如:质量,交付时间(学习+输出)和内存消耗。 其中一些可以轻松,客观地衡量(例如,时间和内存大小),而其他(质量)则很难确定。 例如,当您从已经被多次使用的示例中学习时,您的模型可以证明100%的准确性,但是无法使用新的示例。 这个问题称为
过拟合 ,是机器学习中最重要的问题之一。 还有一个
不足的问题:在这种情况下,即使使用固定的训练数据集,模型也无法从显示的数据中学习,并且显示出较差的预测。
为了解决过度拟合的问题,使用了所谓的
保持部分样本的技术 。 其主要思想是将源数据分为两部分:
- 训练集 ,通常构成大部分数据集,用于训练模型。
- 测试集通常只是源数据的一小部分,在执行所有训练过程之前,它会分为两部分。 该集合根本不在训练中使用,并且被视为训练完成后测试模型的新示例。
使用这种方法,我们可以观察到模型的
概括性如何(也就是说,它适用于以前未知的示例)。
本文将对训练和测试集使用4/1的比率。 我们使用的另一种技术是所谓的
分层 。 该术语指的是独立于所有其他类的每个类的分区。 这种方法允许在训练和测试集中的班级规模之间保持相同的平衡。 分层隐式使用以下假设:当源数据更改时,示例的分布不会更改,而在使用新示例时,示例的分布将保持不变。
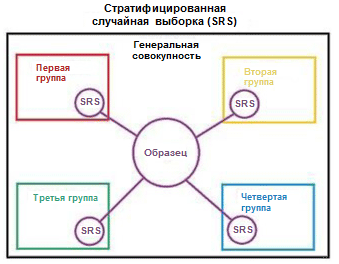
我们用一个简单的例子说明分层的概念。 假设我们有四个数据组/类别,其中包含适当数量的对象:儿童(5),青少年(10),成人(80)和老年人(5); 请参阅右侧的图片(来自
Wikipedia )。 现在我们需要将此数据按3/2的比例分为两组样本。 使用示例分层时,将独立于每个组来选择对象:儿童组2个对象,青少年组4个对象,成年人组32个对象和老年人组2个对象。 新数据集包含40个对象,恰好是原始数据的2/5。 同时,新数据集中的类之间的平衡与源数据中它们之间的平衡相对应。
以上所有动作均在一个称为
prepare_data的函数中实现; 该函数可以在
utils.py Python文件中找到。 此功能加载数据,使用固定的随机数将其分为训练集和测试集(以供稍后播放),然后在硬盘驱动器上的目录之间相应地分发数据,以备后用。
预处理和增强
在上一篇文章中,描述了预处理操作及其以数据增强形式使用的可能原因。 卷积神经网络是非常复杂的模型,训练它们需要大量数据。 在我们的案例中,只有1600个示例-当然,这还不够。
因此,我们想扩展数据
扩充所使用的数据集。 根据有关数据预处理的文章中包含的信息,当从硬盘驱动器读取数据时,Keras *库提供了即时扩充数据的功能。 这可以通过
ImageDataGenerator类完成。
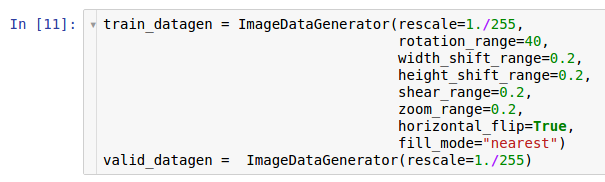
在这里创建了生成器的两个实例。 第一个实例用于训练,并在从磁盘读取数据并将其传输到模型时使用许多随机变换(例如旋转,移位,卷积,缩放和水平旋转)。 结果,模型接收转换后的示例,并且由于转换的随机性,模型接收的每个示例都是唯一的。 第二份副本用于验证,并且仅放大图像。 学习和测试生成器只有一种常见的转换-缩放。 为了确保模型的计算稳定性,必须使用范围[0; 1]代替[0; 255]。
模型架构
在研究和准备了初始数据之后,接下来就是创建模型的阶段。 由于只有少量数据可供我们使用,我们将建立一个相对简单的模型,以便能够对其进行适当的训练并消除过度拟合的情况。 让我们尝试一下
VGG样式的
体系结构 ,但使用更少的图层和过滤器。
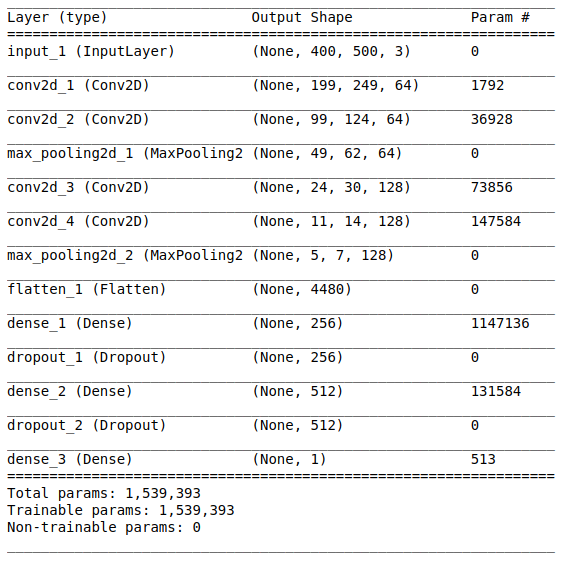

网络体系结构包括以下部分:
[卷积层+卷积层+最大值选择]×2第一部分包含两个叠加的卷积层,这些层具有64个滤波器(大小为3和2),以及位于其后的用于选择最大值(大小为2和2)的层。 这部分通常也称为
特征提取单元 ,因为过滤器可以从输入数据中高效提取有意义的特征(有关更多信息,请参阅文章“
卷积神经网络概述”中的图像分类 )。
对齐方式这部分是强制性的,因为在卷积部分的输出处获得了四维张量(示例,高度,宽度和通道)。 但是,对于普通的全连接层,我们需要一个二维张量(示例,特征)作为输入。 因此,有必要
将张量围绕最后三个轴
对齐,以将它们组合成一个轴。 实际上,这意味着我们将每个要素图中的每个点视为一个单独的属性,并将它们对齐为一个矢量。 下图显示了一个具有128个通道的4×4图像的示例,该图像以一个扩展的向量对齐,长度为1024个元素。
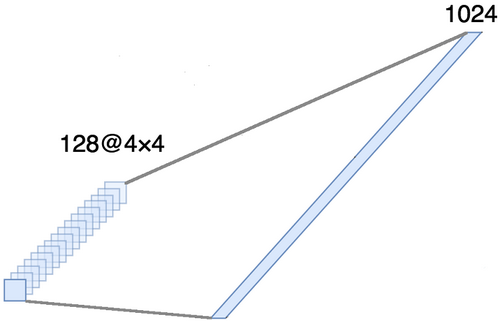 [全层+排除方法]×2
[全层+排除方法]×2这是网络的
分类部分 。 她对图像的特征采取一致的看法,并尝试以最佳方式对它们进行分类。 网络的这一部分由两个重叠的块组成,这些块由一个完全连接的层和
一个排除方法组成 。 我们已经熟悉了完全连接的层-通常这些层是具有完全连接的层。 但是什么是“排除方法”? 排除方法是有助于防止过度拟合的
正则化技术 。 过度拟合的可能迹象之一是权重系数的值完全不同(数量级)。 解决此问题的方法有很多,包括减轻重量和消除方法。 消除方法的思想是在训练过程中断开随机神经元的连接(断开的神经元的列表应在每个包装/训练时代之后进行更新)。 这非常有力地阻止了获得完全不同的加权系数值-通过这种方式对网络进行正则化。
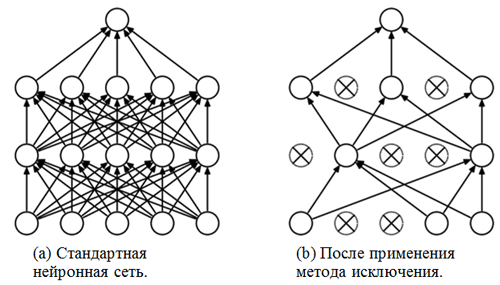
排除方法的应用示例(该图摘自“
排除方法:防止神经网络过度拟合的一种简单方法” ):
乙状结肠模块输出层应对应于问题陈述。 在这种情况下,我们正在处理二进制分类问题,因此我们需要一个具有
S型激活函数的输出神经元,它估计属于数字1的类别的概率P(在我们的情况下,这些是正像)。 然后,可以容易地将属于数字0(负图像)的类别的概率计算为1-P。
设置和培训选项
我们选择了模型架构,并使用Python语言的Keras库对其进行了指定。 另外,在开始模型训练之前,有必要对其进行
编译 。

在编译阶段,对模型进行调整以进行训练。 在这种情况下,必须指定三个主要参数:
- 优化器 。 在这种情况下,我们使用默认的优化器Adam *,它是一类具有时刻和自适应学习速度的随机梯度下降算法(有关更多信息,请参阅S. Ruder的博客文章梯度下降优化算法概述 )。
- 损失函数 。 我们的任务是二进制分类问题,因此将二进制交叉熵用作损失函数将是适当的。
- 指标 。 这是一个可选参数,您可以使用它指定在培训过程中要跟踪的其他指标。 在这种情况下,我们需要跟踪精度以及目标函数。
现在我们准备训练模型。 请注意,训练过程是使用上一节中初始化的生成器执行的。
时代数是可以自定义的另一个超参数。 在这里,我们简单地为其分配值10。我们还希望保存模型和学习历史记录,以便以后可以下载。

等级
现在,让我们看看我们的模型运行情况如何。 首先,我们考虑学习过程中指标的变化。
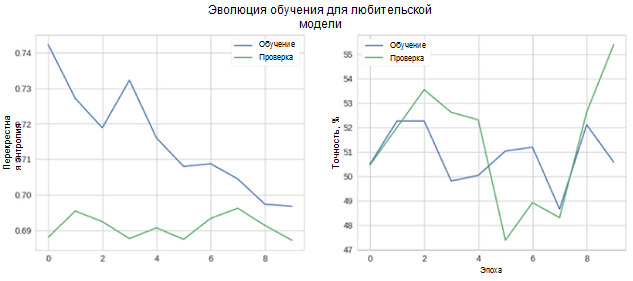
在图中,您可以看到验证和准确性的交叉熵不会随着时间的推移而降低。 此外,用于训练和测试集的准确性度量仅在随机分类器的值附近波动。 测试集的最终精度为55%,仅比随机估计值略好。
让我们看一下模型预测如何在类之间分配。 为此,有必要使用Sklearn *包中用于Python语言的相应函数来创建和可视化
不准确度的
矩阵 。
误差矩阵中的每个像元都有其自己的名称:
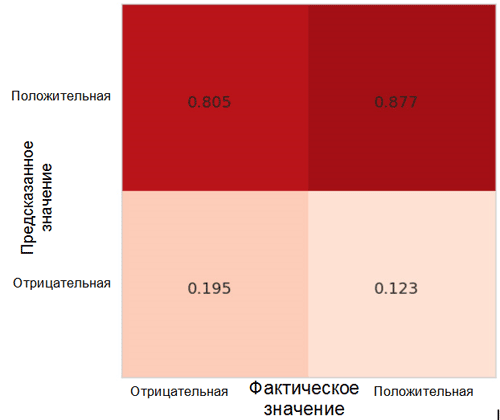
- 真实阳性率= TPR(右上方的单元格)代表阳性示例(类别1,即本例中为阳性情绪)的比例,正确分类为阳性。
- 误报率= FPR(右下角的单元格)代表被错误分类为负面 (类别0,即负面情绪)的正面示例的比例。
- 真实否定率= TNR(左下单元格)代表正确分类为否定性的否定示例的比例。
- 假阴性率= FNR(左上方的单元格)代表被错误分类为阳性的阴性示例的比例。
在我们的情况下,TPR和FPR都接近1。这意味着几乎所有对象都被归为阳性。 因此,我们的模型与具有较大类别的恒定预测的朴素基础模型相距不远(在我们的情况下,这些是正像)。
另一个值得关注的有趣指标是接收机性能曲线(ROC曲线)和该曲线下的面积(ROC AUC)。 这些概念的正式定义可以在
这里找到。 简而言之,ROC曲线显示了二进制分类器的工作情况。
卷积神经网络的分类器具有一个S型模块作为输出,该模块将示例的概率分配给类别1。现在假设我们的分类器显示出良好的工作效果,并为类别0的示例(下图中的绿色直方图)分配了低概率值,例如1类(蓝色直方图)。
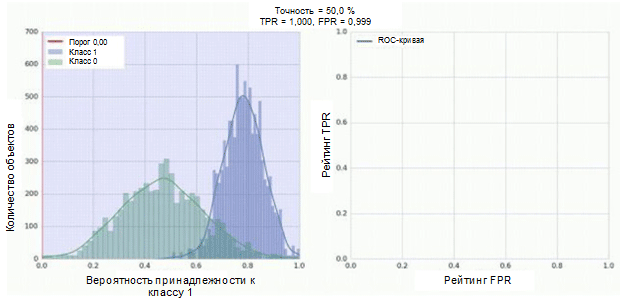
ROC曲线显示了在将分类阈值从0移到1时,TPR指标如何依赖FPR指标(右图,上部)。 为了更好地理解阈值的概念,请记住,每个示例都有属于1类的可能性。 但是,概率还不是分类标签。 因此,应将其与阈值进行比较,以确定该示例属于哪个类别。 例如,如果阈值为1,则所有示例都应归为0类,因为概率值不能大于1,而FPR和TPR指标的值将等于0(因为所有样本均未归类为正) ) 这种情况对应于ROC曲线上最左边的点。 在曲线的另一侧,有一个阈值为0的点:这意味着所有样本都归为1类,并且TPR和FPR的值都等于1。中间点表示阈值更改时TPR / FPR依赖性的行为。
图上的对角线对应于随机分类器。 分类器的效果越好,其曲线越接近图形的左上点。 因此,分类器质量的客观指标是ROC曲线下的面积(ROC AUC指标)。 该指标的值应尽可能接近1。AUC值为0.5对应于随机分类器。
我们模型中的AUC(请参见上图)为0.57,远非最佳结果。
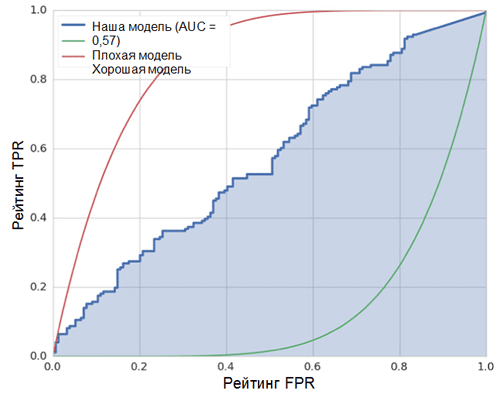
所有这些指标表明,所得模型仅比随机分类器略好。 造成这种情况的原因有很多,主要原因如下:
- 用于训练的数据非常少,不足以突出图像的特征。 在这种情况下,甚至数据扩充也无济于事。
- 具有大量参数的相对复杂的卷积神经网络模型(与其他机器学习模型相比)。
结论
在本文中,我们创建了一个简单的卷积神经网络模型来识别图像中的情绪。 同时,在训练阶段,使用了许多方法来进行数据扩充,并且还使用一组度量标准(例如准确性,ROC曲线,ROC AUC和不准确性矩阵)对模型进行了评估。 该模型显示了结果,只有少数最佳随机。 .