不久前,在我们租用服务器的数据中心发生了另一起小事件。 结果,不会对我们的服务造成严重后果;根据可用的度量标准,我们能够在一分钟内了解发生了什么。 然后我想象如果只缺少两个简单的指标,我将如何绞尽脑汁。 在剪辑下,图片中有一个短篇小说。
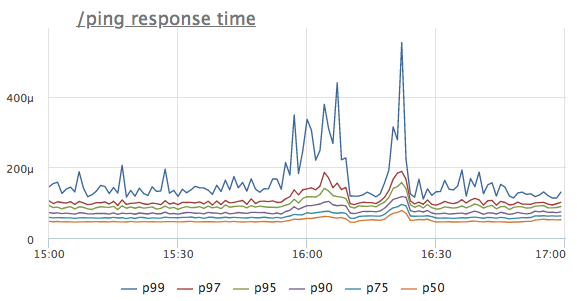
想象一下,我们在某项服务的响应时间轴上看到了异常。 为简单起见,我们采用/ ping处理程序,该处理程序不访问数据库或相邻服务,而仅返回“ 200 OK”(负载均衡器需要此参数,而k8s需要运行状况检查服务)

第一个想法是什么? 是的,该服务没有足够的资源,很可能是CPU! 我们看一下处理器的消耗:
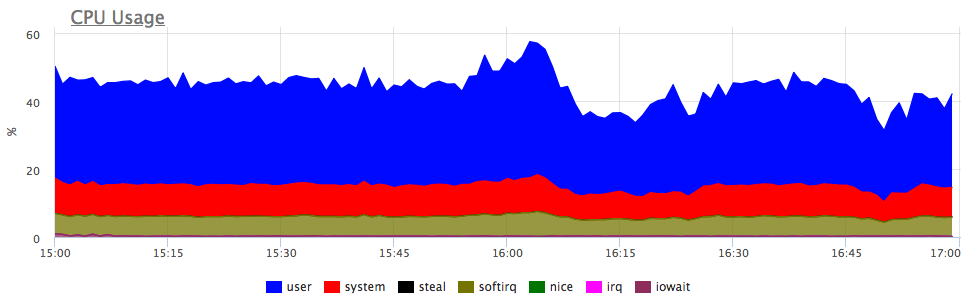
是的,也有类似的爆发。 接下来,我们查看服务器上服务的消耗情况:
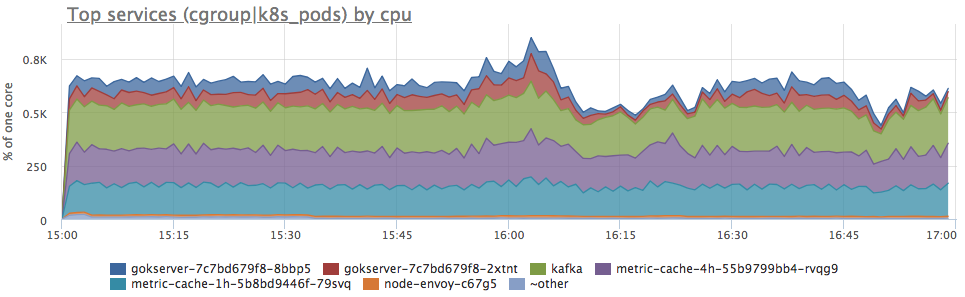
我们看到,所有服务的Proca消耗量均按比例增加。 您无法进一步明确地说出任何话:您可以查看负载配置文件是否已更改(因为所有组件都已连接并且输入请求的增加实际上会导致资源消耗成比例地增加)或了解服务器资源的状况。
当然,我尽力保持了这种吸引力,但是在本文开始时,您可能已经猜到服务器只是减少了可用CPU报价的数量。 在dmesg中,它看起来像这样:
CPU3: Core temperature above threshold, cpu clock throttled (total events = 88981)
粗略地说,由于处理器过热,我们降低了频率。 我们看一下温度:
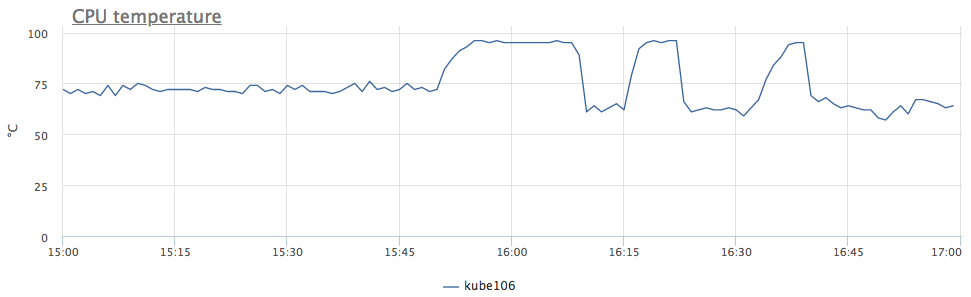
现在一切都清楚了。 由于我们在6台服务器上立即具有类似的行为,因此我们意识到问题出在DC中,而不是所有问题中,而仅在某些机架中。
但是回到指标。 我们可能想知道服务器将来是否会过热,但这并不是将处理器温度图表添加到所有仪表板并每次检查的原因。
通常,触发器用于跟踪一些指标以优化流程。 但是我应该根据处理器温度为触发选择哪个阈值?
由于难以为触发选择合适的阈值,许多工程师梦想着使用一个异常检测器,如果不进行设置,该检测器将自行发现,我不知道这是什么:)首先想到的是设置服务开始出现问题的阈值温度。 如果您从未过热过? 当然,您可以看一下我的日程安排,并自己决定是否需要95°C,但让我们考虑一下。
我们的问题不是因为度数,而是因为频率降低了! 让我们跟踪此类事件的数量。
在linux上,可以从sysfs中删除它:
/sys/devices/system/cpu/cpu*/thermal_throttle/package_throttle_count

坦白说,我们什至没有在任何地方显示该指标,我们只有在达到“> 10个事件/秒”阈值时触发的所有客户端自动触发。 根据我们的统计,在此阈值上几乎没有误报。
是的,这种触发器很少起作用,但是一旦发生,它会使生活变得非常轻松!
大部分时间,我们在okmeter.io上从事自动触发器数据库的开发,这使我们的客户更容易找到他们所未知的问题。