 项目代码在存储库中可用。
项目代码在存储库中可用。引言
当我阅读书中人物形象的描述时,我总是对它们在生活中的样子很感兴趣。 完全可以想象一个人,但是描述最引人注意的细节是一项艰巨的任务,结果因人而异。 很多时候,直到工作结束时,我都无法想象除了角色的非常模糊的面孔。 只有当这本书变成电影时,模糊的面孔才会充满细节。 例如,我无法想象从《
火车上的女孩 》这本书中,蕾切尔的脸是怎样的。 但是当电影上映时,我能够使艾米莉·布朗特(Emily Blunt)的脸与雷切尔(Rachel)的角色相匹配。 当然,参与演员选择的人会花费大量时间正确描绘剧本中的角色。
这个问题启发并激励着我寻找解决方案。 之后,我开始研究有关深度学习的文献,以寻找类似的东西。 幸运的是,已经有许多关于从文本合成图像的研究。 这是我建立的一些工具:
[
项目使用生成对抗网络,GSS(生成对抗网络,GAN)/大约。 佩雷夫 ]
在研究了文献之后,我选择了一种与StackGAN ++相比得到简化的体系结构,并且很好地解决了我的问题。 在以下各节中,我将解释如何解决此问题并分享初步结果。 我还将描述我花费大量时间的一些编程和培训细节。
资料分析
毫无疑问,这项工作最重要的方面是用于训练模型的数据。 正如Andrew Eun教授在他的deeplearning.ai课程中所说:“在机器学习领域,并不是拥有最好算法的人,而是拥有最好数据的人。” 因此,我开始搜索具有良好,丰富和多种文字描述的面部数据集。 我遇到了不同的数据集-要么只是脸,要么是带有名称的脸,要么是带有眼睛颜色和脸形的描述的脸。 但是我不需要任何东西。 我的最后一个选择是使用
一个早期的项目 -用自然语言生成结构数据的描述。 但是这样的选择会给已经非常嘈杂的数据集增加额外的噪音。
时间流逝,在某个时候
出现了一个新的
Face2Text项目。 它是一个详细的人员文字描述数据库的集合。 我感谢该项目的作者提供的数据集。
数据集包含来自LFW数据库的400张随机选择的图像的文本描述(带标签的脸部)。 清理说明以消除歧义和次要特征。 一些描述不仅包含有关面部的信息,而且还包含基于图像得出的一些结论-例如,“照片中的人可能是罪犯”。 所有这些因素以及数据集的小规模导致了这样一个事实,即到目前为止,我的项目仅证明了该体系结构的可操作性。 随后,可以将该模型扩展为更大,更多样化的数据集。
建筑学
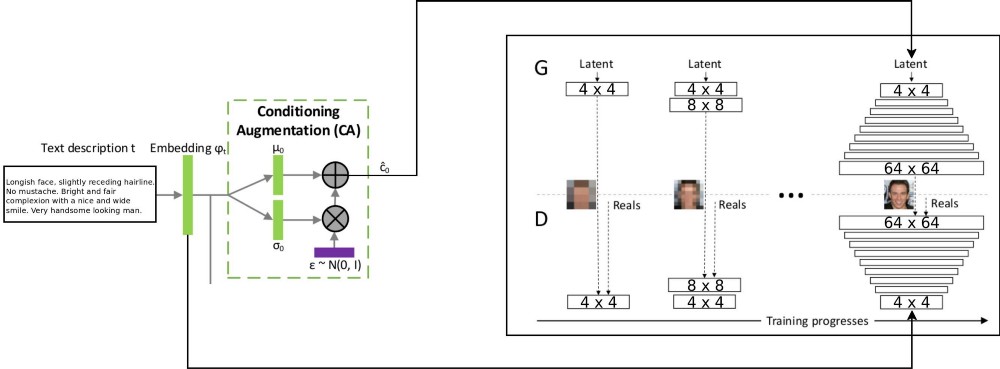
T2F项目的架构结合了两个stackGAN架构和ProGAN(
渐进式GSS增长 ),用于合成有条件的增量文本,该GAN架构用于对有条件的增量文本进行编码。 最初的stackgan ++体系结构使用了几个具有不同空间分辨率的GSS,因此我认为对于任何通信分发任务而言,这都是一种过于严肃的方法。 但是ProGAN仅使用一个GSS,并以更详细的分辨率进行逐步培训。 我决定将这两种方法结合起来。
这里有一个数据流的解释:通过将文本描述嵌入到网络LSTM(嵌入)(psy_t)中,将文本描述编码为最终向量(参见图)。 然后,通过条件增强块(一个线性层)传输嵌入,以获取GSS作为输入的特征向量的文本部分(使用VAE重新参数化技术)。 特征向量的第二部分是随机高斯噪声。 所得的特征向量被馈送到GSS生成器,并且嵌入被馈送到最后的鉴别器层,以进行对应的条件分布。 GSS过程的培训与ProGAN上的文章完全相同-分层,但空间分辨率有所提高。 使用淡入技术引入了一个新层,以避免擦除以前的学习结果。
实施及其他细节
该应用程序是使用PyTorch框架以python编写的。 我曾经使用过tensorflow和keras软件包,但现在我想尝试使用PyTorch。 我喜欢使用内置的python调试器来处理网络体系结构-这一切都要归功于早期执行策略。 Tensorflow最近还开启了渴望执行模式。 但是,我不想判断哪个框架更好,我只是想强调一下该项目的代码是使用PyTorch编写的。
在我看来,该项目的相当一部分是可重用的,尤其是ProGAN。 因此,我为它们编写了单独的代码,作为PyTorch模块的
扩展 ,它也可以用于其他数据集。 仅需要指出GSS功能的深度和大小。 可以针对任何数据集逐步训练GSS。
训练细节
我使用不同的超参数训练了很多网络版本。 工作细节如下:
- 鉴别器没有批处理或分层处理,因此WGAN-GP的损失会爆炸性增长。 我使用的λ等于0.001的漂移罚分。
- 为了控制从编码文本中获得的自己的多样性,有必要在生成器损耗中使用Kullback-Leibler距离。
- 为了使生成的图像更好地匹配传入的文本分布,最好使用相应的(匹配感知)鉴别器的WGAN版本。
- 较高级别的淡入时间应超过较低级别的淡入时间。 训练时,我使用85%作为淡入值。
- 我发现分辨率较高的示例(32 x 32和64 x 64)比分辨率较低的示例产生更多的背景噪声。 我认为这是由于缺乏数据所致。
- 在进行渐进式锻炼时,最好将更多的时间花费在较低的分辨率上,并减少花费在较高分辨率上的时间。
视频显示了发电机的运行时间。 该视频是根据GSS训练期间获得的具有不同空间分辨率的图像进行编译的。
结论
根据初步结果,可以判断T2F项目是可行的并且具有有趣的应用。 假设它可以用来组成照片机器人。 或者在需要增强想象力的情况下。 我将继续在Flicker8K,Coco字幕等数据集上扩展该项目。
GSS逐步增长是一项用于更快,更稳定的GSS训练的惊人技术。 它可以与其他文章中提到的各种现代技术相结合。 GSS可以在MO的不同区域中使用。