大家好! 这次我想写些关于如何赢得
Mini AI Cup 2竞赛的信息。 与我的
上一篇文章一样 ,几乎没有实现细节。 这次的任务不那么繁琐,但是仍然有很多细微差别和小事影响了机器人的行为。 结果,即使在机器人上进行了将近三周的积极工作之后,仍然存在有关如何改进该策略的想法。
下切了很多GIF和流量。
坚持不懈的人会解决这个问题,其余的人会惊恐地逃跑(摘自简短压缩部分的评论)。那些懒于阅读的人可以去本文倒数第二个扰流器,查看该算法的简要描述,然后从头开始阅读 。链接到
github上的源。
工具选择
和上次一样,我花了很多时间思考从哪里开始。 除其他事项外,选择是在两种语言之间进行的:Java,我很熟悉,并且在学生时代C ++早已被人们遗忘了。 但是由于从一开始我就觉得编写一个好的bot的主要障碍不是开发速度而是最终解决方案的生产率,因此选择仍然落在C ++中。
在使用我自己的可视化工具调试之前的比赛中获得成功的经验之后,这次我也不想做任何事情。 但是我在Qt for
CodeWars上为自己编写的可视化工具对我
来说似乎并不是理想的解决方案,因此我决定使用
此可视化工具。 它也是在CodeWars下制作的,但不需要认真处理即可在本次比赛中使用。 连接的相对简单性和在代码中任何地方调用渲染的便利性都对他有利。
和以前一样,我真的很想调试游戏中的任何滴答声-在测试的游戏的任意时刻运行策略的能力。 由于插件可视化工具无法解决此问题,因此在#ifdef对的帮助下(在其中我还包装了负责渲染的代码段),我在每个刻度上添加了Context类的保存,其中包含了来自上一个刻度的变量的所有必需值。 从本质上讲,该解决方案与我在代码向导中使用的解决方案相似,但是这次的方法并不是那么自发的。 模拟整个游戏后,要求您输入游戏滴答声的编号,必须重新启动它。 有关此滴答之前的变量状态的信息是从数组中获取的,以及从输入策略接收到的行,这使我可以按任何必要的顺序播放策略的动作。
开始
在制定规则的那天,我没有路过,而在第一个晚上,我们等待着我们。 他毫不犹豫地对json输入格式感到愤慨(是的,这很方便,但有些参与者在此类比赛中开始学习新的或被遗忘已久的旧YP,并且从json解析开始并不是最令人愉快的事情),研究了奇怪的运动公式并以某种方式开始形成未来的框架策略(对以后的文章有所了解,阅读
规则很有用)。 在两天的时间里,我编写了许多类,例如Ejection,Virus,Player和其他类,读取json,连接单个文件库以进行日志记录。在未评级的沙箱打开的当天晚上,我已经制定了有效的策略,并且原则上几乎重复了C ++中的基线,但是明显地,更大的代码。
然后...我开始弄清楚选项,以及如何开发它。 当时的想法:
- 对世界状态的搜索不能减少到可以超过极小极大值和修改的值。
- 潜在领域是好的,但它们却无法回答世界将如何改变接下来的n个滴答声的问题。
- 遗传学和类似的算法将起作用,但是每个笔划仅给出20毫秒,并且乍一看,需要比使用GA可以处理的感觉更多的计算深度。 是的,您可以“以后永远快乐”地选择突变参数。
我肯定决定了一件事情:我们需要对世界进行模拟。 毕竟,近似计算可以“击败”冷而精确的计算吗? 当然,这些考虑促使我研究了负责模拟服务器环境的代码,因为这一次它与规则一起放入了公共领域。 毕竟,没有什么比应该准确描述世界规则的代码更好的了?
所以我一直在思考,直到我开始研究应该在服务器和本地上测试我们的机器人的代码。 最初,就代码的可理解性和正确性而言,一切都不尽人意,组织者与参与者一起开始积极地进行处理。 在beta测试期间(捕获了几天),游戏引擎中的变化非常严重,许多游戏直到测试引擎不稳定时才开始参与。 但最终,以我的观点,他们等待着一款性能良好的引擎来开发一款非常适合比赛形式的游戏。 在本地跑步者稳定之前,我也没有开始采取任何严肃的方法,而且在第一周,我的机器人没有做出更明智的事情,除了拧紧的可视化仪。
在电报的第一个周末前夕,组织者创建了一个单独的小组,假设人们将能够帮助纠正和改善语言环境赛跑者。 我还参与了有关世界引擎的工作。 经过在此聊天中的讨论后,作为测试,我向跑步者的区域设置发出了2个请求:调整
饮食配方(以及饮食顺序的小变化),并在
保持惯性和质心的同时将几个部分合并为一个木耳。 然后我开始考虑如何将合理的碰撞物理方法插入此代码中,因为当时游戏世界中存在的物理方法非常不合逻辑。 由于没有在规则中描述两个木耳之间的冲突,因此我要求组织者提供一些标准,根据这些标准,我可以接受这种逻辑。 答案是这样的:在碰撞中的木耳应该是“软的”(也就是说,它们可能会相互碰到一点),而与墙碰撞的逻辑不应被触及(即,壁应仅使木耳停止而不是将其推开)。 我的下一个
要求是对物理学进行认真的修改。
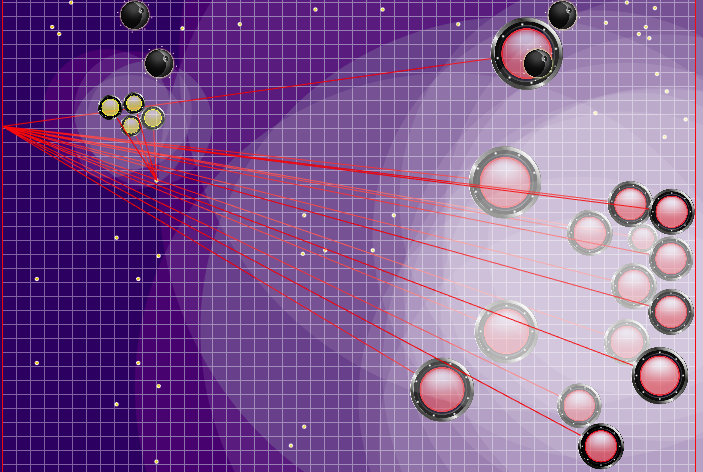
物理学改变之前和之后这样的碰撞物理是: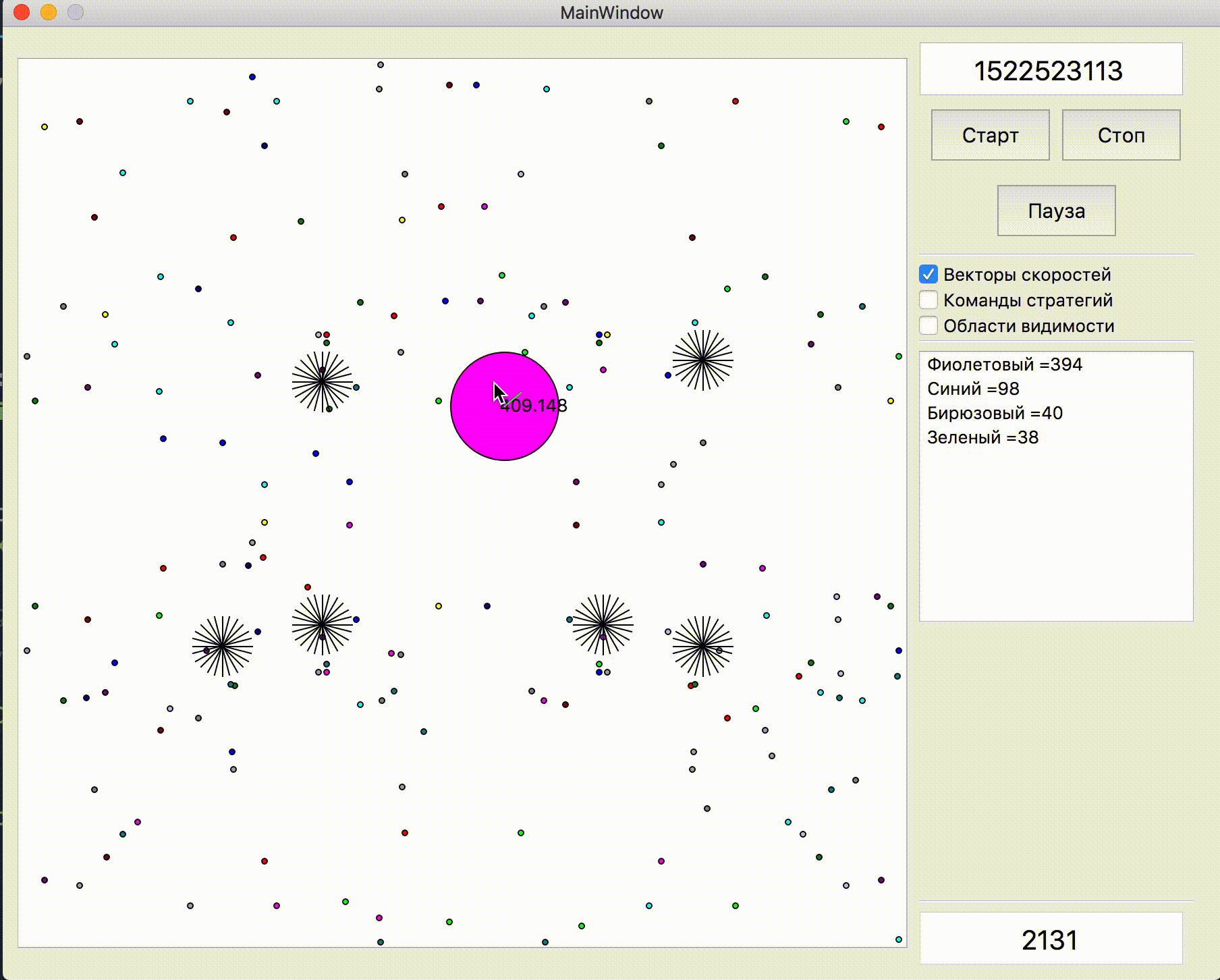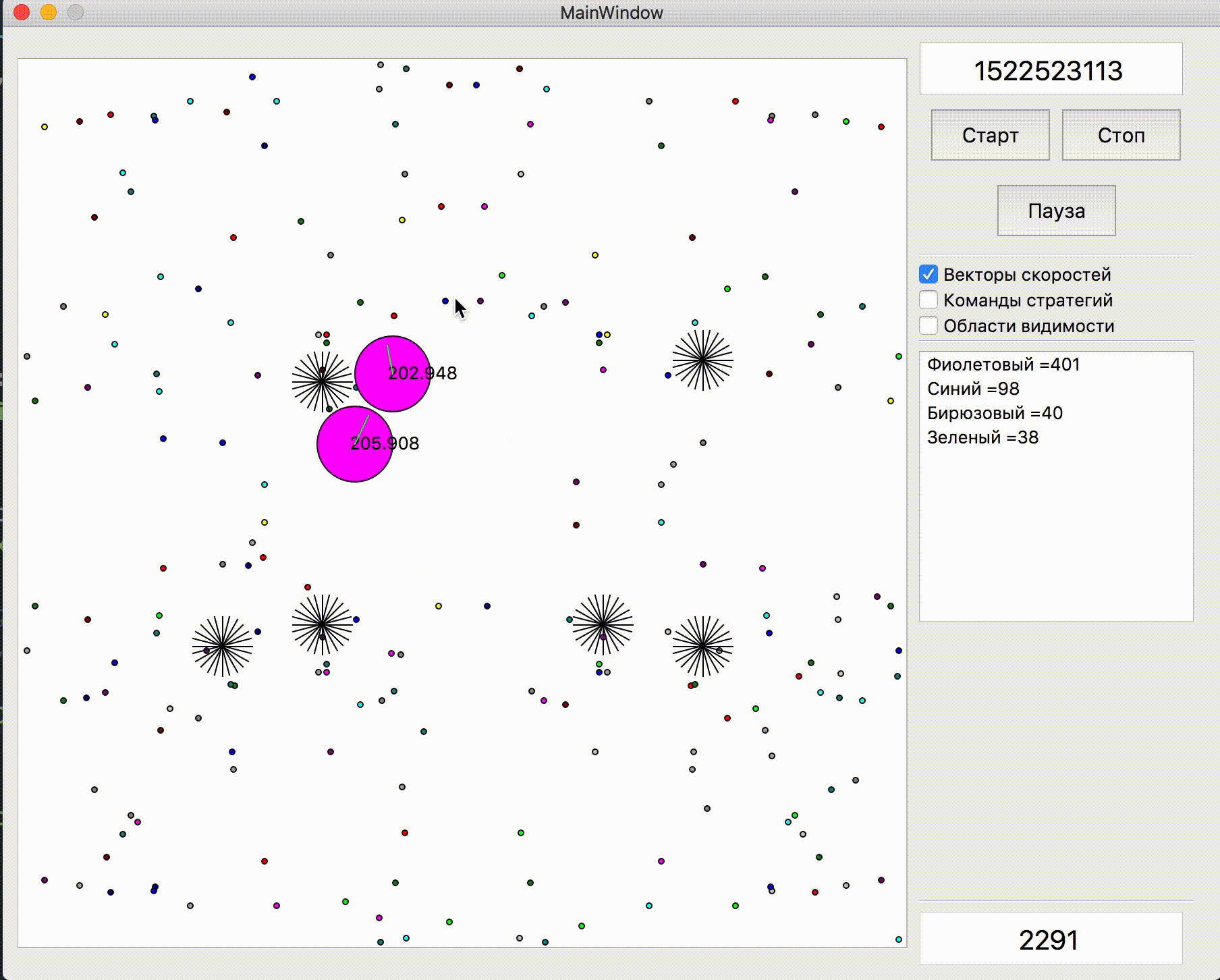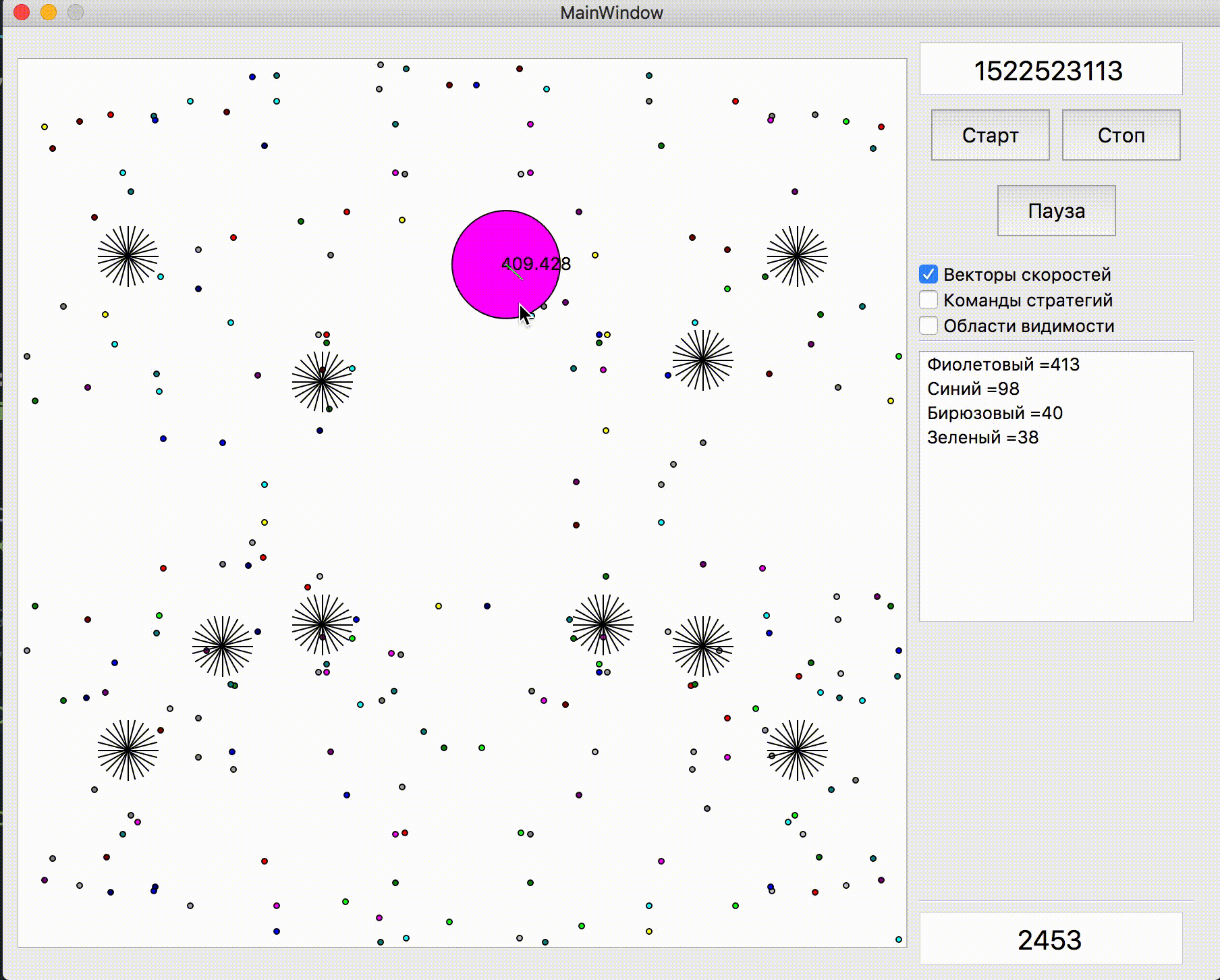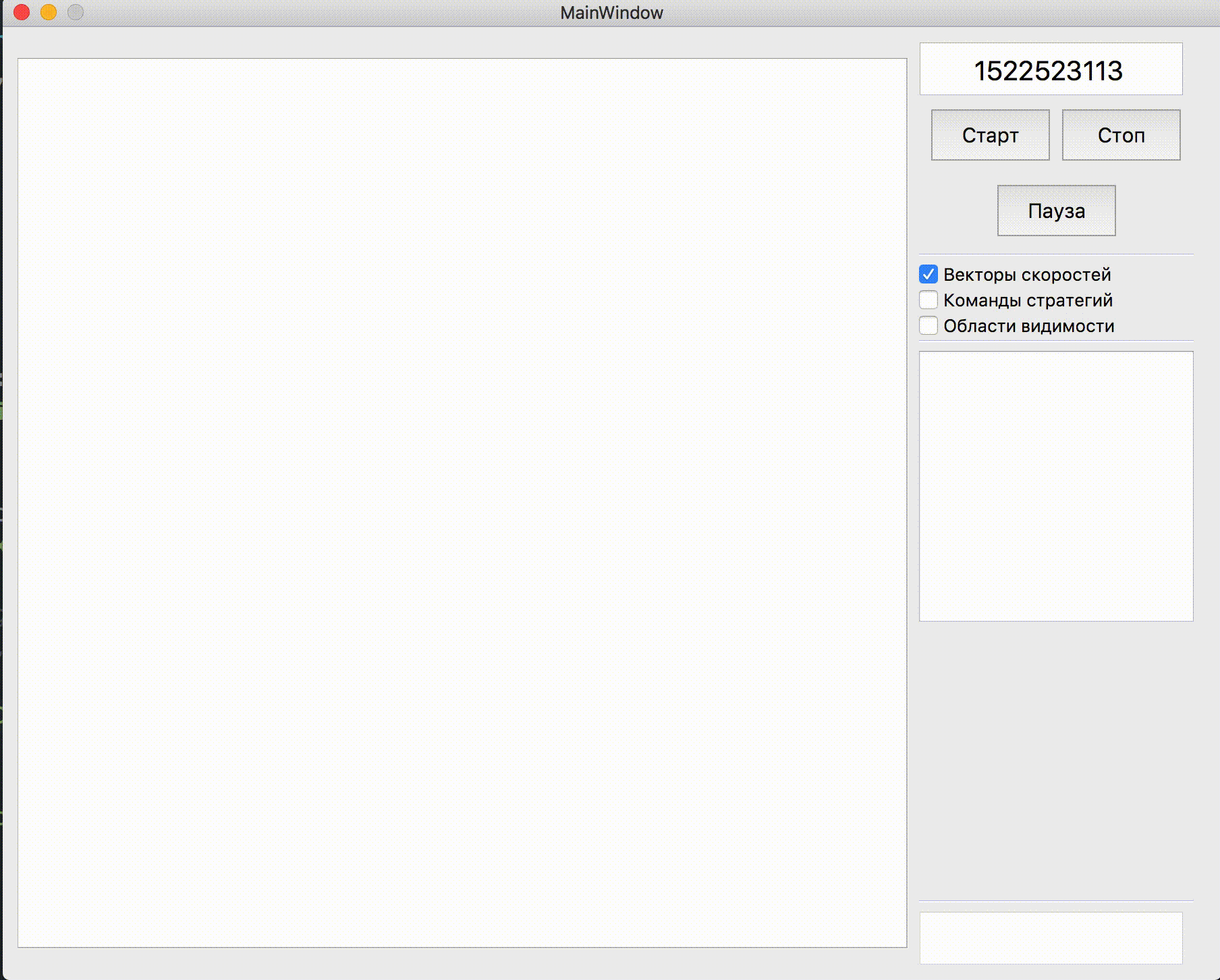 在更新之后,她变得如此:
在更新之后,她变得如此:
我还要强调
这个拉取请求,它大大减少了状态分析带来的混乱代码,并将大量发现的(和潜在的)错误简化为更加易懂的东西。
编写模拟
在将跑步者区域设置代码转换为合理的形式后,我逐渐开始将世界模拟代码从跑步者区域设置转移到我的机器人。 首先,它当然是用于模拟木耳运动的代码,同时也是用于计算碰撞物理的代码。 花了两个晚上的时间来保存重新设计的代码,使其免于重写错误(根本不通过复制代码来完成逻辑传输),并估算了应进行的计算深度。
那时每个each的评级函数是我吃的食物+1,敌人吃的食物-1,以及彼此食用木耳的数值稍大。 在食用其他木耳藻的常数中,起初我的对手,我的对手(当然还有对手吃我的最后一个琼脂卡的罚款非常大)之间以及彼此的两个不同的对手之间存在差异(几天后最后一个系数变为0)。 另外,模拟的所有先前滴答声的总速度,每个滴答声都乘以1 + 1e-5,以鼓励我的机器人至少早一点执行更多有用的动作,并且在模拟结束时,最后一个滴答声的速度作为奖励被添加,也很小。 为了模拟木耳的运动,在地图边缘上从所有我的木耳的算术平均坐标以15度为步长选择点,并在模拟估计函数所取值最大的运动时选择一个点。 当时已经有了看似原始的模拟和简单的评估,该机器人就很自信地跻身前十。
点的演示,算法最初模拟的运动命令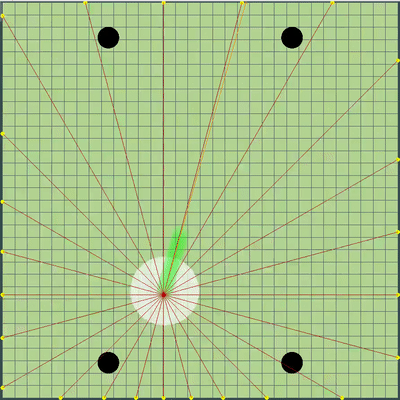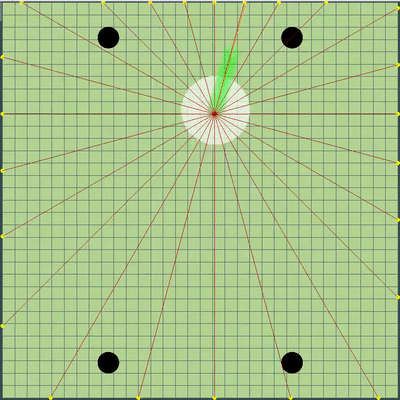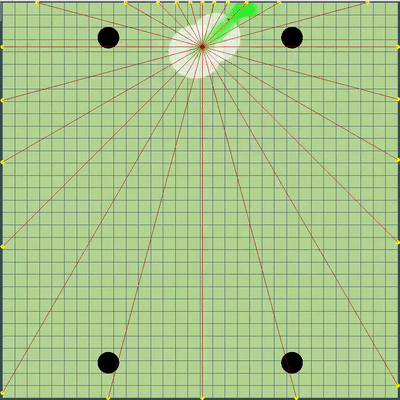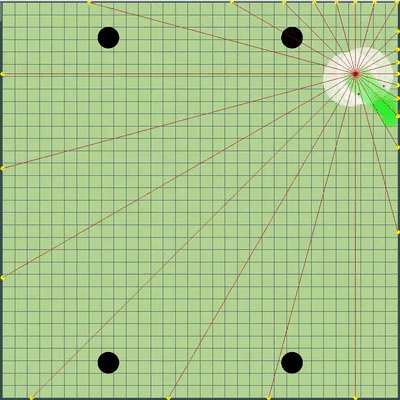 点,在各种模拟中给出的运动命令。 如果仔细观察,最终给出的命令有时会相对于要搜索的点发生偏移,但这是将来更改的结果。
点,在各种模拟中给出的运动命令。 如果仔细观察,最终给出的命令有时会相对于要搜索的点发生偏移,但这是将来更改的结果。 在星期五和星期六的晚上,添加了模拟木耳融合,模拟“破坏”病毒以及猜测对手的TTF的模拟。 对手的TTF是一个非常有趣的计算值,仅通过捕捉不受控制的飞行时刻,就可以了解对手在什么时候分裂或感染了病毒,这可能会持续非常短的几秒钟且粘性很大,直到整个地图飞行为止。 由于琼脂糖碰撞可能会导致其最大速度略有超出,因此为了计算对手的TTF,我检查了他连续两刻的速度确实与您在自由飞行中连续获得两刻的速度相对应(在自由飞行中,琼脂飞行严格笔直,减慢每个滴答,使其严格等于粘度)。 这几乎完全消除了误报的可能性。 另外,在测试此逻辑时,我注意到较大的TTF始终对应于较大的木耳ID(后来我确信,当
在病毒上传递
爆炸代码并
处理split时,我相信这是值得的)。
在查看了前三名的不断分裂之后(这使他们可以在地图上大量收集食物),作为测试,如果可见范围内没有敌人,我向该机器人添加了一个永久拆分命令,并且在周日早上,我在等级的第二行找到了我的机器人。 管理少量的小木耳菌可以大大提高排名,但是如果您偶然遇到对手,则将它们丢掉要容易得多。 而且由于担心被我的木耳菌吃掉是有条件的(惩罚只是在模拟中进食,而不是逼近可以吃东西的对手),因此第一件事就是与与可以吃东西的对手越过而增加了惩罚。 同样的评估就像追逐对手一样有好处。 在用我的策略检查了CPU消耗之后,我决定在第一个刻度完成拆分后再增加一轮仿真(当然,这种逻辑也必须从运行器语言环境转移到我的代码中),然后仿真与之前完全相同。 这种逻辑不太适合对敌人进行“射门”(尽管有时是偶然的,它确实在一个非常合适的时刻分裂了),但对于更快地收集食物非常有好处,这就是当时整个上层所做的。 这样的修改使我们可以在下周进入评级的第一行,尽管利润率不高。
到那时,这已经足够了,制定了该策略的“骨干”,该策略看起来相当原始且可扩展。 但是我真正注意到的是CPU消耗和整体代码稳定性。 因此,主要是一周中下一个工作日的傍晚专门用于提高模拟的准确性(可视化工具提供了很大帮助),稳定了代码(valgrind)并优化了工作速度。
来吧
我的下一个发送策略显示了明显更好的结果并且领先于对手(当时),它包含两个重大变化:增加了收集食物的潜力,并且如果附近有一个未知的TTF的对手,则模拟次数增加了一倍。
第一个版本中收集食物的潜在领域非常简单,其全部本质是记住从可见区域消失的食物,从而减少敌方机器人所位于的那些地方的潜力,并在我的可见区域归零(随后每n恢复一次按照规则打勾)。 这似乎是一种有用的改进,但是在我看来,实际上,差异很小或完全没有。 例如,在具有高惯性和高速度的卡片上,机器人通常会跳过食物,然后试图返回食物,同时又损失了很多速度。 但是,如果他决定保持速度,而只是忽略了跳过的食物,那么他的饮食将大大增加。
潜在的食物收集场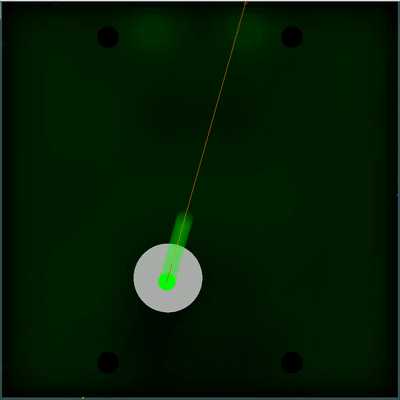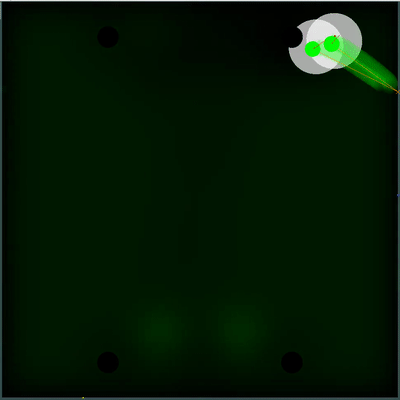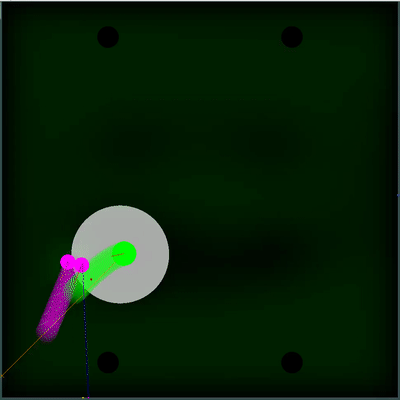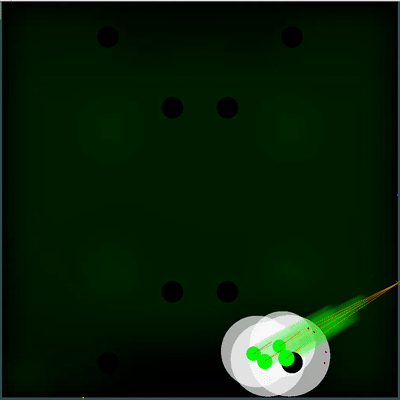 您可以注意每40个滴答声如何使字段变亮一些。 每隔40个滴答声,将根据在地图上添加食物的方式更新该字段,并且整个字段会均匀地“涂抹”食物出现的可能性。 如果在此刻度上我们看到有在前一个刻度上看到的食物,则该食物出现的可能性不会被“涂抹”,而是由特定点设置(食物每40个刻度严格对称地出现一次)。
您可以注意每40个滴答声如何使字段变亮一些。 每隔40个滴答声,将根据在地图上添加食物的方式更新该字段,并且整个字段会均匀地“涂抹”食物出现的可能性。 如果在此刻度上我们看到有在前一个刻度上看到的食物,则该食物出现的可能性不会被“涂抹”,而是由特定点设置(食物每40个刻度严格对称地出现一次)。 完全不同的主观效用被证明是对具有不同TTF的敌人的双重模拟-可能的最小和最大(以防我不知道地图上所有可见菌的TTF)。 如果以前我的机器人认为敌人的木耳菌会变成一个整体并缓慢移动,那么现在他选择了这两种情况中的最坏情况,并且没有冒险靠近敌人,因为他对敌人的了解比他想要的要少。
在获得明显优势之后,我尝试通过添加一个定义来指示对手指示其菌落移动的点来增加该点,尽管尽管在大多数情况下该点的计算非常准确,但仅此一项并不能改善机器人的结果。 根据我的观察,与对手的木耳只向相同的方向,以相同的速度移动(好像对手什么也没做)的情况相比,情况变得更糟,因此这些修改被保存在一个单独的吉他分支中,直到出现更好的情况为止。
后来使用的对方球队的定义 对手的木耳发出的光线显示了对方在前一个滴答声中给其木耳的所谓团队。 蓝线是菌丝在最后一个刻度线改变方向的确切方向。 黑色是预期的。 仅当琼脂完全在我们的可见区域内时,才可能更准确地确定团队的方向(可以计算碰撞对其速度变化的影响)。 光线的交点是对手的目标队伍。 基于游戏aicups.ru/session/200710制作的Gif,大约3,000滴答。
对手的木耳发出的光线显示了对方在前一个滴答声中给其木耳的所谓团队。 蓝线是菌丝在最后一个刻度线改变方向的确切方向。 黑色是预期的。 仅当琼脂完全在我们的可见区域内时,才可能更准确地确定团队的方向(可以计算碰撞对其速度变化的影响)。 光线的交点是对手的目标队伍。 基于游戏aicups.ru/session/200710制作的Gif,大约3,000滴答。 也有尝试将评估功能转移到获得的质量评估上,试图改变评估对手危险性的功能。但是,所有这些感觉改变都变得更加糟糕。 评估靠近敌人的危险的功能的唯一有用的功能是另一项性能优化,同时将该估计范围扩展到比与敌人的交点半径大得多的半径(基本上是整个地图,但是如果略微简化,则呈二次递减关系-在敌人被吃掉的最大危险的1/25范围内,以五个或五个以上的半径出现。 最后的变化也是计划外的,导致我的伞兵变得非常害怕接近更大的敌人,并且如果它们的尺寸非常大,他们更倾向于向对手移动。 因此,事实证明这是对将来计划的代码的成功而不是资源密集的替代,而该代码原本应该负责担心对手会通过分裂而发动攻击(以及稍后对我的这种攻击有所帮助)。
经过漫长而相对无济于事的尝试来改善某些东西后,我再次回到预测对手运动的方向。 我决定尝试一下,如果不只是替换虚拟对手,然后像我使用最小和最大TTF选项那样做-模拟两次并选择最佳的。 但是为此,CPU可能不够用,在我的机器人的许多游戏中,由于食欲不振,它们可能仅与系统断开连接。 因此,在实施此选项之前,我添加了所花费时间的近似定义,如果超出了限制,我将开始减少仿真动作的数量。 在我知道他要去的地方的情况下,通过对敌人添加双重模拟,我再次在大多数游戏设置中获得了相当严重的增长,除了最消耗资源的(惯性/低速/粘性低)外,这是由于深度的大幅降低模拟可能会变得更糟。
在开始进行25k滴答游戏之前,进行了两项更有用的改进:终止远离地图中心的模拟的惩罚,以及如果对手离开视线时记住对手的先前位置(以及模拟当时的移动)。
在模拟中对机器人的最终位置进行惩罚的方法是预先计算的静态危险区域,该危险区域的零危险半径略大于游戏场地长度的一半,并且随着您离开游戏场地而逐渐增加。在模拟的终点应用该字段几乎不需要CPU,并防止了额外的冲撞,有时可以避免敌人的攻击。记忆和随后模拟对手的大部分情况使我们避免了两个有时表现出来的问题。第一个问题在下面的GIF中提出。第二个问题是,如果从视野范围内失去了更大的敌人(例如,在其部分合并之后),则有可能“成功”地团结到其中,并为已经很危险的对手提供食物。转弯结束时的危险区域示例和滴答作响 ,
,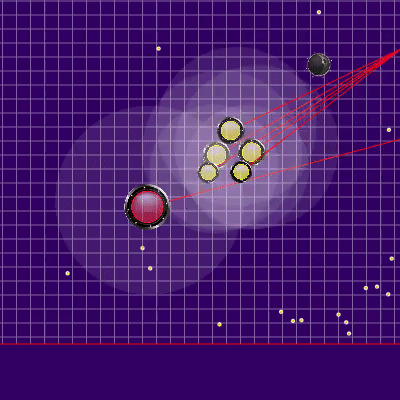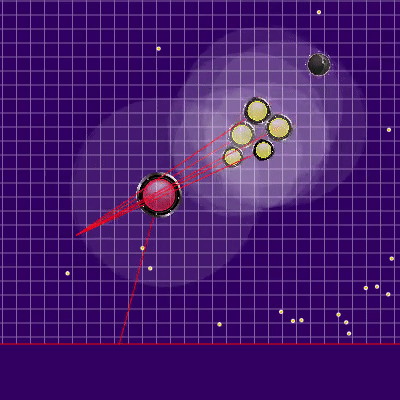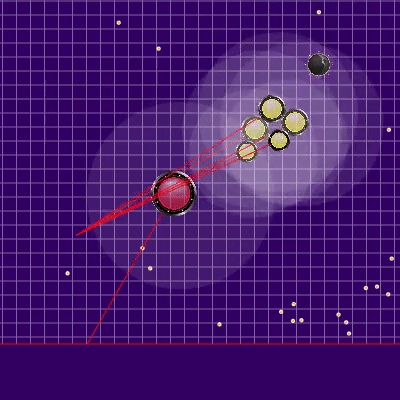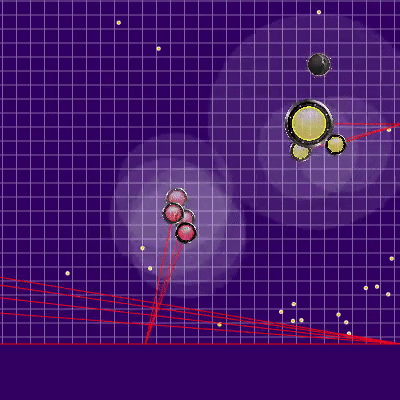 , . , .
, . , . 另外,将运动模拟点添加到地图边缘上的点:对手的每个agarik,并在每45度我的agariki算术平均坐标的半径内。从我的木耳的算术平均坐标将半径设置为avgDistance。新的模拟点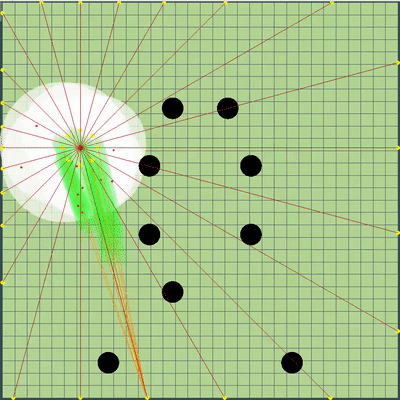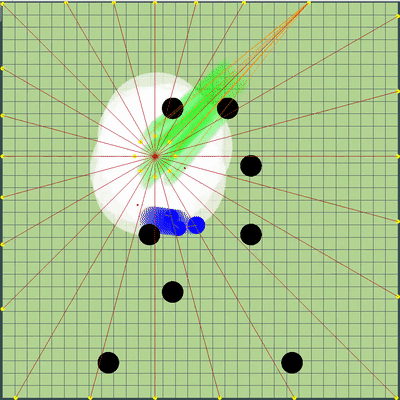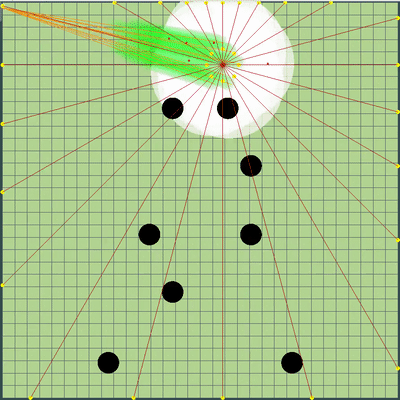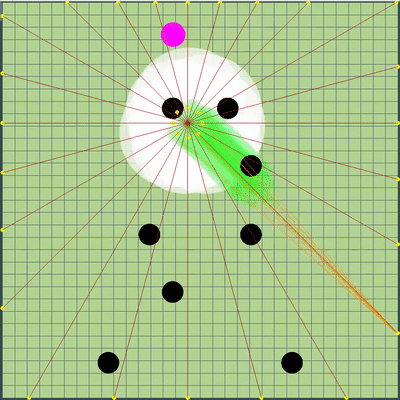 . «» , . .
. «» , . . 最终准备
在比赛开始进行25k滴答声并进入决赛之前,我的利润率很高,但我并不打算放松。随着新的25k游戏的出现,消息传出:决赛期间的比赛也将达到25k,而策略的壁垒时间限制变得更长了。在评估了我的策略在新条件下花费在游戏上的时间之后,我决定添加另一版本的模拟:我们照常进行所有操作,但在进行过程中进行模拟拆分。除其他外,这需要使用在上一步中找到的模拟,但要移动1步(例如,如果我们发现从当前的刻中分离了7个滴答,则接下来的步骤我们将重复同样的步骤,但是我们已经在第六步进行了拆分)。这显着增加了对竞争对手的攻击性攻击,但是却花费了更多的战略时间。应该对算法进行简要说明:
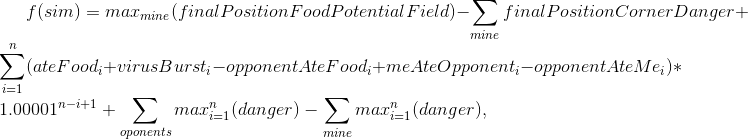
- f — , ;
- sim — ( , , TTF , );
- finalPositionFoodPotentialField — , , ;
- finalPositionCornerDanger — . , ;
- n — , . 10 50 ;
- ateFood — i;
- virusBurst — i;
- opponentAteFood — i;
- meAteOpponent — ;
- opponentAteMe — ;
- mine/opponents — . 即 — ;
- danger — , , .
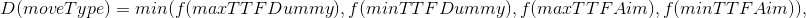
- moveType — , ;
- max/min TTF — , TTF ( TTF );
- dummy/aim — Dummy ( , ).
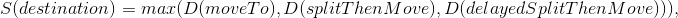
- destination — , ;
- moveTo — , n “ ” ;
- splitThenMove — split ;
- delayedSplitThenMove — , split .
1 . 即 splitThenMove moveTo, delayedSplitThenMove 7 6 , 6 5 .. , — 7 . .
destination :
- 15 ( — ). 24 ;
- , ( );
- :
- “” , ;
- 8 . .
destination , .
在缺少TL的情况下,所有进一步的改进都与仿真的效率完全相关:根据CPU消耗,优化断开逻辑某些部分的顺序。在大多数游戏中,这不应该改变任何东西,但是想出一个更正确的东西却没有用。决赛中的决赛点. 808 2424 , . .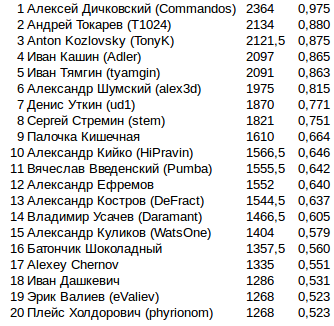
而不是结论
总的来说,本次比赛的开始注定要加油,但是在前半个星期的时间里,在参与者的帮助下,这项任务变成了一种相当可玩的形式。最初,任务是非常多变的,并且选择正确的方法来解决它似乎并不容易。更有趣的是想出一种改进算法而又不超出CPU消耗限制的方法。非常感谢组织者参加比赛,并为世界范围内的开放访问提供了源代码。当然,后者从一开始就给他们增加了很多问题,但是极大地促进了参与者(如果不是说,从原则上来说是可能的)使人们对世界模拟器的设备的理解。特别感谢您有机会选择奖品!因此,奖品变得更加有用:-) 为什么我需要另一台MacBook?