
今天在KDD 2018上是研讨会日-以及将于明天开始的大型会议,几个小组聚集了一些特定主题的听众。 去过两个这样的政党。
时间序列分析
早上我想去参加一个关于
图形分析的研讨会,但是他被拘留了45分钟,所以我转到下一个研讨会,讨论时间序列分析。 突然,一位来自加利福尼亚的
金发教授打开了主题为“医学人工智能”的研讨会。 很奇怪,因为这个原因,隔壁房间有一个单独的轨道。 事实证明,她有几个研究生,将在这里讨论时间序列。 但是,实际上,要点。
医学人工智能
医疗错误是导致美国10%的死亡的原因,这是该国三大死亡原因之一。 问题是没有足够的医生。 那些超负荷运行的计算机,至少在医生看来,计算机更有可能为医生带来无法解决的问题。 但是,大多数数据并未真正用于决策。 所有这些都必须斗争。 例如,一种细菌
艰难梭菌 (
Clostridium difficile )具有高毒力和耐药性。 在过去的一年中,她造成了40亿美元的损失。 让我们尝试根据医疗记录的时间序列评估感染风险。 与以前的工作不同,我们采取了许多措施(每天使用1万个向量),并将为每个医院建立单独的模型(显然,由于所有医院都有自己的数据集,因此在很多方面,这显然是一种必要的措施)。 结果,我们获得了约0.82 AUC的准确度,并在5天后具有CDI风险预后。
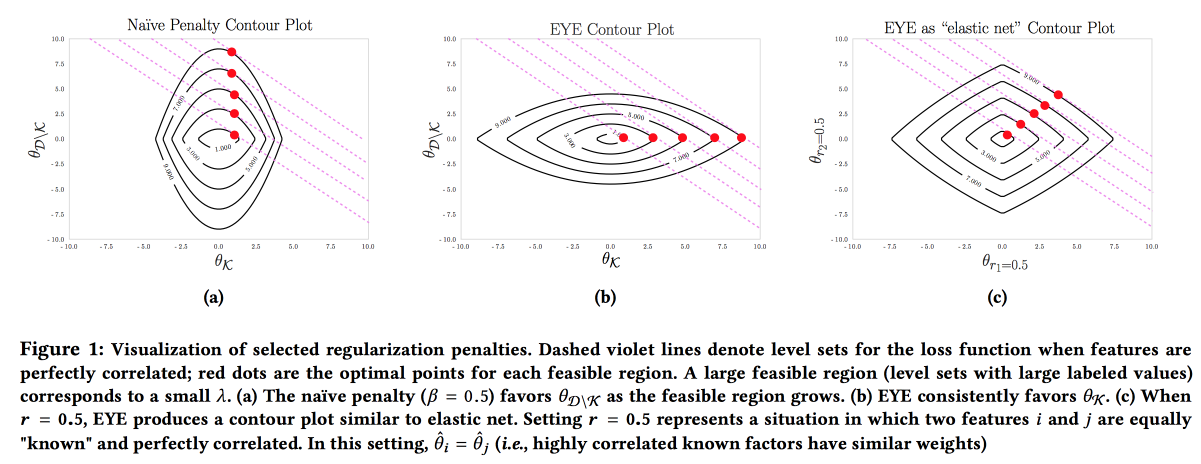
该模型的准确性,可解释性和鲁棒性很重要;我们需要展示我们可以采取的预防措施。 可以通过积极使用主题领域的知识来构建这种模型。 对可解释性的需求通常会减少功能部件的数量并导致创建简单模型。 但是,即使具有大量特征空间的简单模型也失去了可解释性,并且使用L1正则化经常导致以下事实:模型随机选择共线特征之一。 结果,尽管AUC良好,但医生仍不相信该模型。 作者建议使用其他类型的正则化
EYE (专家产量估算)。 给定是否存在关于结果影响的已知数据,事实证明该模型将重点放在必要的特征上。 通过将质量与标准正则化进行比较,即使专家搞砸了,它也可以提供良好的结果,您可以评估专家的正确程度。
接下来,我们继续分析时间序列。 事实证明,为了提高它们的质量,寻找不变量是很重要的(实际上-导致某些规范形式)。 在
最近的一篇文章中,一群教授提出了一种基于两个卷积网络的方法。 第一个是序列转换器,将序列变成规范形式,第二个是序列解码器,解决了分类问题。
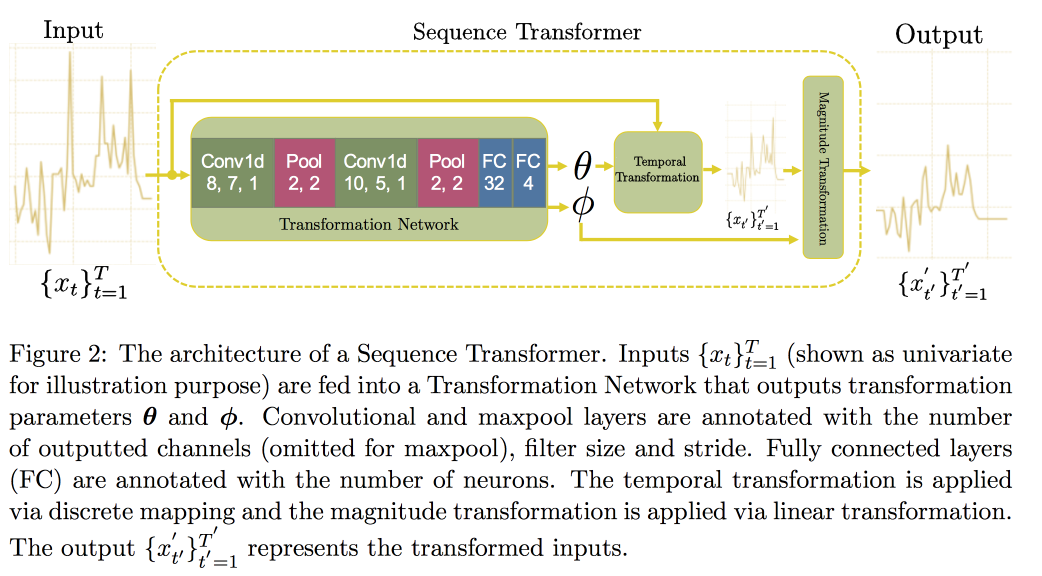
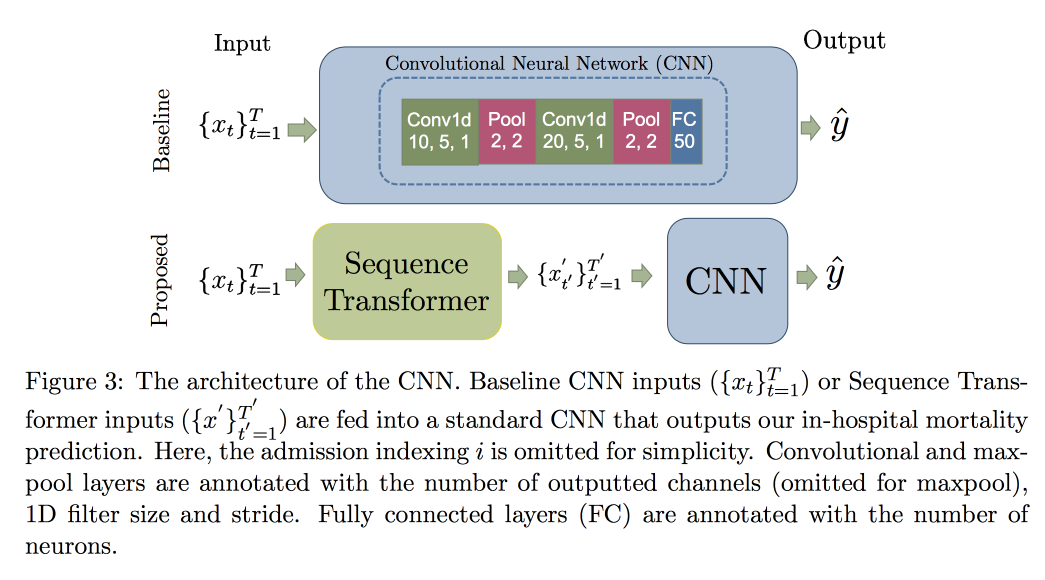
CNN而不是RNN的使用是因为它们适用于固定长度的行。 检查了MIMIC
数据集 ,试图预测医院在48小时内的死亡。 与带有附加层的普通CNN相比,结果是0.02 AUC的改善,但是置信区间重叠。
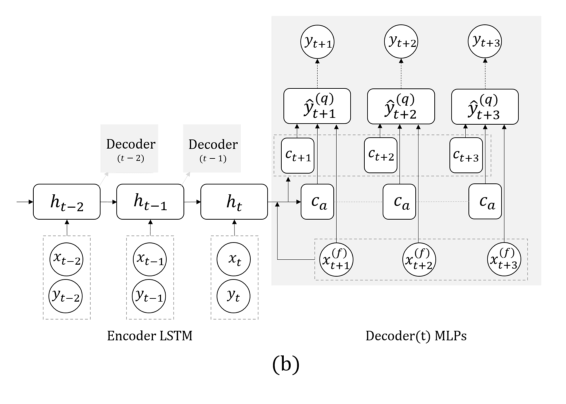
现在是另一项任务:我们将仅根据实际序列进行预测,而无需外部信号(即食等)。 在这里,团队建议用具有多个输出的网格替换RNN,以预测向前几步,并且在它们之间不进行递归。 此解决方案的解释是,递归期间不会累积错误。 将此技术与上一个技术(搜索不变量)结合起来。 教授演讲后,博士后立即详细讨论了该模型,因此在此结束,并指出,在验证时,不仅要考虑一般误差,而且还要注意血糖过高或过低的危险情况下的分类误差,这一点很重要。
我对模型的反馈提出了一个问题:虽然这是一个非常开放的问题,但他们说我们应该尝试了解由于干预的事实而导致的症状分布发生哪些变化,以及哪些是由外部因素引起的自然变化。 实际上,这种转变的存在使情况变得更加复杂:由于质量下降,随机混合(不对某人进行治疗并检查其是否会死)是不道德的,因此无法对模型进行重新训练,但可以保证从根据模型建议对每个人进行治疗的数据中学习偏见
样本路径生成
如何不进行演示的示例:非常快,很难听甚至难以理解。 作品本身可以
在这里找到 。
他们将先前的预测结果向前发展了几步。 以前的工作中有两个主要思想:代替RNN,使用在不同时间点具有多个输出的网络,再加上我们尝试预测分布和评估分位数的方法,而不是特定的数字。 这全称为
MQ-RNN / CNN (多视点预测分位数回归)。
这次我们尝试使用后处理来完善预测。 考虑了两种方法。 作为第一步的一部分,我们尝试使用后验数据“校准”神经网络的分布,并学习输出和观测值的协方差矩阵,即所谓的协方差收缩。 该方法非常简单并且可以使用,但是我想要更多。 第二种方法是使用生成模型来构建“路径样本”:他们使用生成方法进行预测(GAN,VAE)。 在为声音
产生而开发的
WaveNet的帮助下获得了良好但不稳定的结果。
图结构网络
关于神经网络中“主题领域知识”的转移
的有趣工作 。 他们以预测空间(按城市地区)和时间(按天数和小时)的犯罪水平为例。 主要困难:数据稀疏和罕见的本地事件的存在。 结果,许多方法效果不佳,平均而言,仍然可以每天进行猜测,但不能针对特定区域和时间进行猜测。 让我们尝试在一个神经网络中结合高级结构和微模式。
我们使用邮政编码构建一个通信图,并使用
多元霍克斯过程确定一个对另一个的影响。 接下来,根据获得的图表,我们构建神经网络的拓扑结构,将城市区域的区域与显示出相关性的犯罪联系起来。
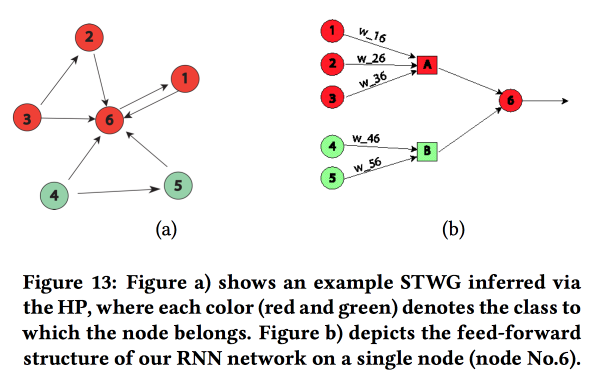
我们将该方法与其他两种方法进行了比较:在一个地区的网格上或在一组犯罪率相似的地区的网格上进行培训,显示出准确性的提高。 对于每个区域,引入了具有两个完全连接的层的两层LSTM。
除了犯罪,他们还展示了交通预测方面的工作实例。 在这里,kNN已经在地理上获取了用于构建网络的图形。 尚不完全清楚他们的结果可以与其他人进行比较(他们自由更改了分析中的指标),但是总的来说,建立网络的启发式方法似乎是足够的。
整体预测的非参数方法
合奏是一个非常受欢迎的话题,但是如何从单个预测中得出结果并不总是很明显。 在他们的工作中,作者提出了一种
新的方法 。
通常,简单的合奏效果很好,甚至更好。 比新的
贝叶斯模型平均和平均NN。 回归也不错,但是在权重选择方面通常会给出奇怪的结果(例如,某些预测会给负权重等)。 实际上,其原因通常是由于聚合方法使用了一些有关预测误差的分布的假设(例如,根据高斯或正态分布),但是当使用该假设时,他们忘记了检查该假设。 作者试图提出一种无假设的方法。
我们考虑两个随机过程:数据生成过程(DGP)对现实进行建模并且可以依赖于时间,而预测生成过程(FGP)对预测的构建进行建模(其中有很多-每个集合成员一个)。 这两个过程之间的差异也是一个随机过程,我们将尝试对其进行分析。
- 我们收集历史数据,并使用核密度估计为预测变量构造误差分布密度。
- 接下来,我们构建一个预测,并通过添加所构建的误差将其转换为随机变量。
- 然后我们解决了似然性最大化的问题。
生成的方法几乎类似于具有高斯误差的EMOS(集成模型输出统计),而对于非高斯误差则更好。 实际上,例如(
Wikipedia Page Traffic Dataset )通常是非高斯错误。
嵌套LSTM:基于位置的社交网络中的分类和时间动态建模
该作品由Google的作者提交。 我们正在尝试预测下一次用户检查。 利用他最近的搜索历史和地点的元数据,首先是它们与标签/类别的关系。 类别分为三个级别,我们使用两个较高级别:父类别描述用户的意图(例如,吃饭的欲望),子类别描述用户的偏好(例如,用户喜欢西班牙美食)。 应该显示下一张支票的辅助类别,以从在线广告中获得更多收入。
我们使用两个嵌套的LSTM:根据检查顺序,通常使用最上面的LSTM;根据类别树中从父级到子级的转换,嵌套LSTM。
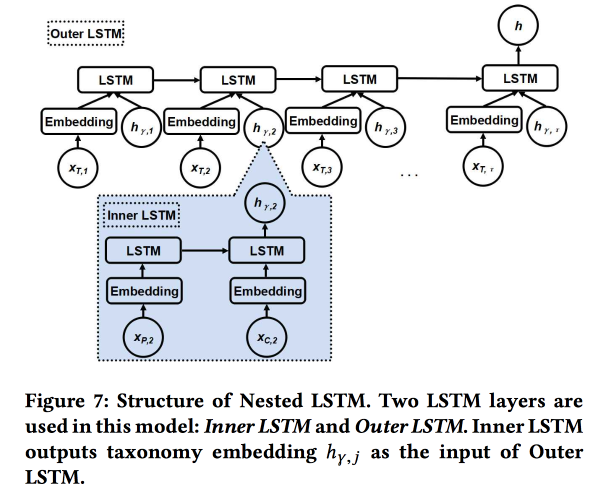
事实证明,与带有原始类别嵌入的简单LSTM相比,这种方法要好5-7%。 此外,我们证明了类别树中的LSTM过渡连接看起来比简单连接更漂亮,并且聚集更好。
识别进化语义空间的转变
中国教授的演讲很开朗。 底线是试图理解单词如何改变其含义。
现在,每个人都在成功地训练单词嵌入,它们可以很好地工作,但是在不同时间接受训练不适合进行比较-您需要做所有的事情。
- 您可以使用旧的进行初始化,但这不能保证。
- 您可以学习用于转换的转换功能,但由于尺寸并不总是相等地共享,因此它并不总是有效。
- 您可以使用拓扑空间,而不是矢量空间!
最后,解决方案的实质是:我们在不同时期在单词的邻居中构建一个knNN图,以评估含义的变化,并尝试了解是否存在重大变化。 为此,我们使用
贝叶斯惊喜模型。 实际上,我们查看了一个假设(先前)和一个受观察的假设(后验)
的分布的
KL差异 -这是一个令人惊讶的事实。 通过单词和cnn图,我们使用基于过去邻居频率的Dirichlet作为先验分布,并将其与最近历史中的实多项式进行比较。 总计:
- 我们剪了故事。
- 我们构建嵌入(保留初始化的LINE)。
- 我们在嵌入上考虑了KNN。
- 感激不已。
我们通过采用两个相同频率的随机词进行验证,并互相交换-令人惊讶的是,质量提高了80%。 然后,我们选取21个单词,这些单词具有已知的含义漂移,看看是否可以自动找到它们。 开源尚未对此方法进行详细描述,但
SIGIR 2018上有一个 。
AdKDD和TargetAd
午餐后,我转到了在线广告研讨会。 这个行业有更多的演讲者,每个人都在思考如何赚更多的钱。
Airbnb的广告技术
作为拥有庞大DS团队的大型公司,AirBnB投入了大量资金来正确地宣传自己及其在外部网站上的内部报价。 一位开发人员谈论了一些挑战。
让我们从在搜索引擎中投放广告开始:在Google上搜索酒店时,前两页是广告:(。但是用户经常甚至不理解这一点,因为广告非常相关。城市,便宜还是豪华等)
选择候选人之后,我们将在他们之间安排拍卖(现在到处都使用“
通用第二价格” )。 参与拍卖时,目标是使用具有点击概率和收入的组合的模型来最大化固定预算的影响:出价= P(点击|搜索查询)*预订价值。 重要的一点:不要把所有的钱花得太快,所以要增加“支出起搏器”。
AirBnB具有用于A / B测试的功能强大的系统,但由于它可以控制大多数Google流程,因此无法在此处应用。 他们承诺在那里会为广告商添加更多工具,大型参与者确实很期待。
单独的问题:用户在多个地方接触广告。 我们平均每年旅行两次,准备旅行和预订的周期非常长(数周甚至数月),可以通过几个渠道与用户联系,因此需要按渠道划分预算。 这个主题非常痛苦,有简单的方法(线性地,仔细地,最后一次单击或
隆起测试的结果)。 AirBnB尝试了两种新方法:基于Markov模型和
Shapley模型 。
使用马尔可夫模型,一切都差不多了:我们正在构建一个离散的链,其中的节点对应于与广告的接触点,还存在一个转换节点。 根据数据,我们为过渡选择权重,为那些过渡可能性更大的节点分配更多预算。 我向他们提出了一个问题:为什么使用简单的马尔可夫链,而使用MDP更合乎逻辑; 他们说他们正在研究这个话题。
Shapley的使用更有趣:实际上,这是一种评估累加效果的众所周知的方案,其中考虑了效果的不同组合,评估了每种效果,然后确定每种效果的特定汇总。 困难在于效果之间可能存在协同作用(较少的拮抗作用),并且总和的结果不等于结果的总和。 一般来说,我
建议您阅读一个相当有趣和优美的理论。
对于AirBnB,Shapley模型的应用如下所示:
- 我们在观察到的数据示例中具有不同的效果和实际结果组合。
- 使用ML填写数据中的空白(并非所有组合都显示)。
- 我们为每种Shapley影响计算贷款。
微软:突破{AI}边界
进一步一点。 由于Microsoft从事广告业务,现在从网站的侧面开始主要是Bing。 一点屠杀:
- 广告市场发展非常迅速(呈指数增长)。
- 一页上的广告会互相蚕食,您需要分析整个页面。
- 尽管CTP较差,但某些页面上的转化率更高。
Bing广告引擎中大约有70个模型,离线有2000个实验,在线有400个。 每周都会对该平台进行一次重大更改。 通常,他们不知疲倦地工作。 平台有哪些变化:
- 一个指标的神话:它无法以这种方式解决,指标会增长并竞争。
- 我们重新设计了将匹配请求从NLP发布到DL的系统,该系统是在FPGA上计算的。
- 他们使用联邦模型和情境强盗:内部模型会产生概率和不确定性,上方的强盗会做出决定。 她谈到了很多土匪,它们被用来启动模型并以巡航速度发射,它们规避了经常改进模型会导致收入降低的事实:(
- 评估不确定性非常重要(嗯,是的,没有它,您就无法建立土匪)。
- 对于小型广告客户而言,通过强盗进行广告宣传的机构不起作用,统计数据很少,因此有必要为冷启动创建单独的模型。
- 监视不同用户群的性能很重要,他们具有根据实验结果进行切片的自动系统。
我们讨论了一些流出分析。 卖方关于外流原因的假设并不总是正确的,您需要更深入地研究。 为此,您必须构建可解释的模型(或用于解释预测的特殊模型),并要三思而后行。 然后做实验。 但是对流出进行实验总是很困难,他们建议使用二阶指标和
Google的文章 。
他们还使用诸如商业知识图之类的东西来描述主题领域:品牌,产品等。 该图是完全自动构建的,不受监督。 品牌带有类别标记,这一点很重要,因为通常不总是可以无监督地将品牌整体隔离,但是在特定类别主题内,信号更强。 不幸的是,我没有通过他们的方法找到开放作品。
Google广告
昨天谈到伯爵的那个家伙告诉我们,一切都一样悲惨和自大。 讨论了几个主题。
第一部分:稳健的随机广告分配。 我们有预算的节点(广告)和在线节点(用户),它们之间也有一些权重。 现在,您需要选择要显示新节点的广告。 您可以贪婪地进行此操作(始终按最大权重进行操作),但是这样做会冒过早制定预算并获得无效解决方案的风险(理论极限为最佳值的1/2)。 您可以用不同的方式处理此问题,实际上,在这里,我们在收益与公平之间存在传统冲突。
当选择分配方法时,可以根据某种分布假定在线节点的出现顺序是随机的,但实际上也可能存在对抗顺序(即具有某些相反作用的元素)。 在这些情况下,方法不同,它们提供了最新文章的链接:
1和
2 。
第二部分:感知感知的学习/稳健的定价。 现在,我们正在尝试解决选择保留价格以增加广告网站收入的问题。 我们也考虑使用其他拍卖,例如
Myerson拍卖 ,
BINTAC和回退到第一笔价格的拍卖,以与预订联系。 他们不详细介绍,而是发送至
文章 。
第三部分:在线捆绑。 再次,我们解决了增加收入的问题,但是现在我们从另一个角度出发。 如果您可以批量购买广告(脱机捆绑销售),那么在许多情况下,您可以提供更好的解决方案。 但是您无法在在线拍卖中做到这一点,您需要使用内存构建复杂的模型,并且在恶劣的条件下RTB不会这么做。
然后出现一个魔术模型,其中所有内存都减少到一位数字(银行帐户),但是时间用完了,扬声器开始疯狂地翻动幻灯片。 , ,
.
Deep Policy optimization by Alibaba
«sponsored search». RL, — .
.
offline- , , online-, .
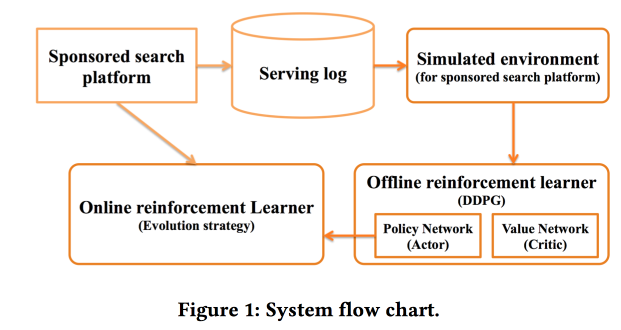
CTR ,
DDPG .
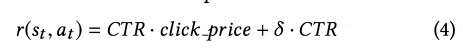
- , « »:
Criteo Large Scale Benchmark for Uplift Modeling
( ). Criteo
Criteo-UPLIFT1 (450 ) .
. -, , ( ). — (, ).
? . - , — , (AUUC).
Qini- (
Gini ), Qini, .
. : , . .
revert label. , , , , ; . , , .
, . .
Deep Net with Attention for Multi-Touch Attribution
, ,
Adobe . , , ! , attention- LSTM, . LSTM- .
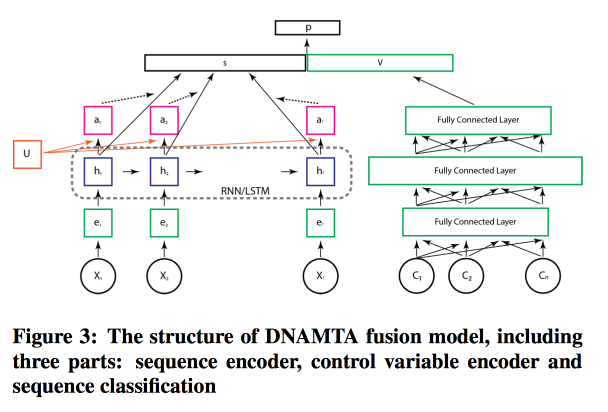
, attention- .
结论
然后是一场开场白电影的开场会议,它以最经典的大片预告片录制,非常感谢所有帮助组织这一切的人-在各个方面都创下了KDD纪录(包括120万美元的赞助),还有Bytes勋爵(创新部长)的话英国)和海报会议,现在已经没有任何力量。我们必须为明天做准备。