注意事项 佩雷夫 :原始文章的作者Nicolas Leiva是一位思科解决方案架构师,他决定与他的同行网络工程师分享Kubernetes网络在内部的工作方式。 为此,他积极利用常识,网络知识和标准Linux / Kubernetes实用程序,探索了集群中最简单的配置。 结果很多,但是很清楚。
除了Kelsey Hightower的
Kubernetes The Hard Way指南可以正常工作(
甚至在AWS上! )之外,我还喜欢网络保持干净简单。 这是了解容器网络接口(
CNI )角色的绝佳机会。 话虽如此,我还要补充说,Kubernetes网络实际上并不是很直观,尤其是对于初学者来说……而且也不要忘记“根本
就没有容器网络”。
尽管有关该主题的材料已经很丰富(请参阅
此处的链接),但我找不到这样的示例,无法将所有必要的内容与网络工程师喜欢和讨厌的团队的结论相结合,以说明幕后的实际情况。 因此,我决定从许多来源收集信息-希望这对您有所帮助,并且您可以更好地了解一切之间的联系。 这些知识不仅对测试自己很重要,而且对简化诊断问题的过程也很重要。 您可以从
Kubernetes The Hard Way中遵循集群中的示例:所有IP地址和设置都从那里获取(截至2018年5月的提交,使用
Nabla容器之前)。
我们将从头开始,当我们有三个控制器和三个工作节点时:
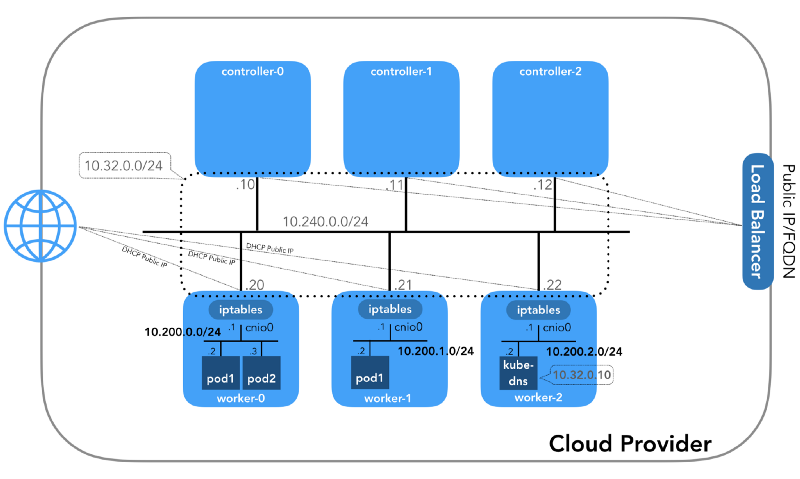
您可能会注意到,这里至少还有三个专用子网! 有点耐心,他们都会被考虑在内。 请记住,即使我们提到非常特定的IP前缀,它们也仅取自
Kubernetes The Hard Way ,因此它们仅具有本地意义,并且您可以根据
RFC 1918为您的环境自由选择任何其他地址块。 对于IPv6,将有单独的博客文章。
主机网络(10.240.0.0/24)
这是一个内部网络,所有节点都是其中的一部分。 分配计算资源时,由
GCP中的
--private-network-ip标志或
AWS中的
--private-ip-address选项定义。
在GCP中初始化控制器节点
for i in 0 1 2; do gcloud compute instances create controller-${i} \
(
controllers_gcp.sh )
在AWS中初始化控制器节点
for i in 0 1 2; do declare controller_id${i}=`aws ec2 run-instances \
(
controllers_aws.sh )
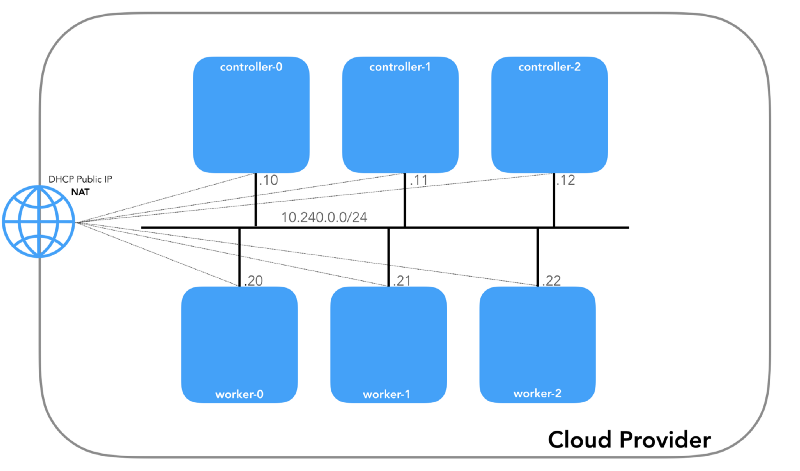
每个实例将具有两个IP地址:主机网络的私有IP地址(控制器
10.240.0.1${i}/24 ,工作人员
10.240.0.2${i}/24 ))和由云提供商指定的公共IP地址,我们将在后面讨论。如何到达
NodePorts 。
控制点
$ gcloud compute instances list NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS controller-0 us-west1-c n1-standard-1 10.240.0.10 35.231.XXX.XXX RUNNING worker-1 us-west1-c n1-standard-1 10.240.0.21 35.231.XX.XXX RUNNING ...
ws
$ aws ec2 describe-instances --query 'Reservations[].Instances[].[Tags[?Key==`Name`].Value[],PrivateIpAddress,PublicIpAddress]' --output text | sed '$!N;s/\n/ /' 10.240.0.10 34.228.XX.XXX controller-0 10.240.0.21 34.173.XXX.XX worker-1 ...
如果
安全策略正确 (并且主机上
ping安装
ping ,则所有节点必须能够相互ping通。
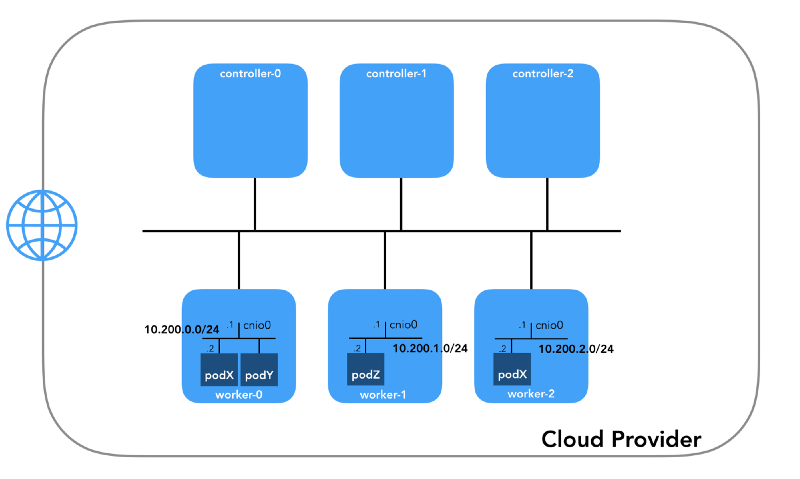
炉床网络(10.200.0.0/16)
这是Pod所在的网络。 每个工作节点都使用该网络的一个子网。 在我们的示例中,
POD_CIDR=10.200.${i}.0/24对于
worker-${i} 。
要了解所有内容的配置方式,请退后一步,看看
Kubernetes网络模型 ,该
模型需要满足以下条件:
- 所有容器都可以在不使用NAT的情况下与任何其他容器通信。
- 所有节点都可以与所有容器通信(反之亦然),而无需使用NAT。
- 容器看到的IP必须与其他人看到的IP相同。
所有这些都可以通过多种方式实现,Kubernetes将网络设置传递给
CNI插件 。
“ CNI插件负责将网络接口添加到容器的网络名称空间 (例如, veth对的一端),并在主机上进行必要的更改(例如,将veth的另一端连接到网桥)。 然后,他必须通过调用所需的IPAM插件来分配IP接口并根据IP地址管理部分配置路由。” (来自容器网络接口规范 )
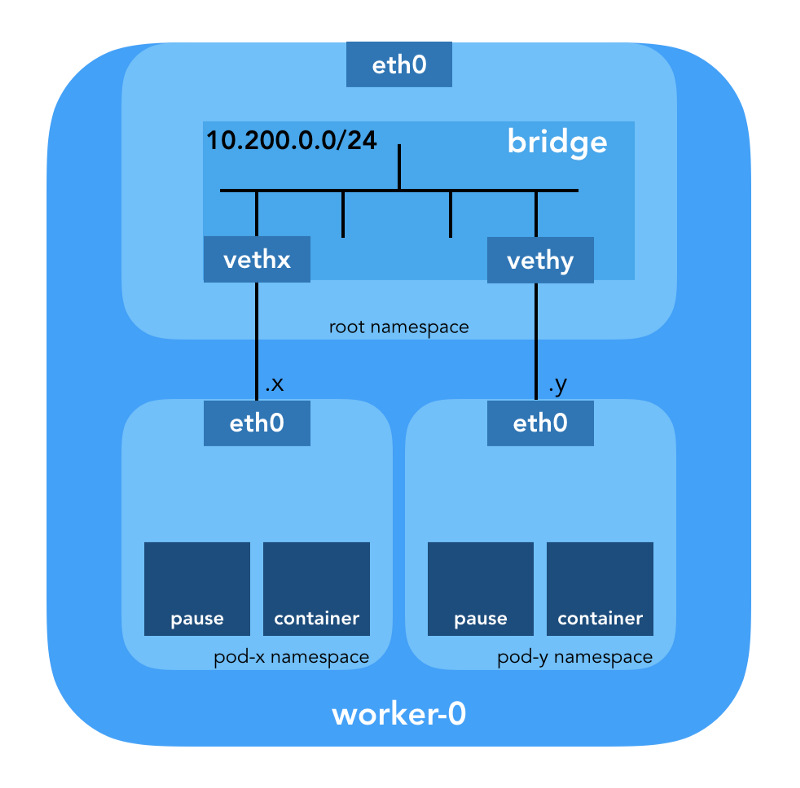
网络名称空间
“名称空间将全局系统资源包装成一个抽象,该名称空间中的进程可以通过这种抽象看到它们,使它们拥有自己的隔离的全局资源实例。 全局资源中的更改对于此名称空间中包含的其他进程可见,但对其他进程不可见。” ( 来自名称空间手册页 )
Linux提供了七个不同的名称空间(
Cgroup ,
IPC ,
Network ,
Mount ,
PID ,
User ,
UTS )。 网络名称空间(
CLONE_NEWNET )定义了该过程可访问的网络资源:“每个网络名称空间都有自己的网络设备,IP地址,IP路由表,
/proc/net目录,端口号等”
(摘自“ 操作中的命名空间 ”一文 。
虚拟以太网设备(Veth)
“虚拟网络对(veth)以“管道”的形式提供抽象,可用于在网络名称空间之间创建隧道或在另一个网络空间中创建到物理网络设备的桥接。 释放命名空间后,其中的所有veth设备都将被销毁。” (来自网络名称空间手册页 )
深入地面,看看它们与集群之间的关系。 首先,Kubernetes中的
网络插件是多种多样的,而CNI插件就是其中之一(
为什么不是CNM? )。 每个节点上的
Kubelet告诉容器
运行时使用哪个
网络插件 。 容器网络接口(
CNI )在容器运行时和网络实现之间。 CNI插件已经建立了网络。
“通过将命令行--network-plugin=cni传递给Kubelet,可以选择CNI插件。 Kubelet从--cni-conf-dir (默认值为/etc/cni/net.d )中读取文件,并使用该文件中的CNI配置为每个文件配置网络。 (根据网络插件要求 )
CNI插件的真实二进制文件位于
-- cni-bin-dir (默认值为
/opt/cni/bin )。
请注意,
kubelet.service调用
kubelet.service包括
--network-plugin=cni :
[Service] ExecStart=/usr/local/bin/kubelet \\ --config=/var/lib/kubelet/kubelet-config.yaml \\ --network-plugin=cni \\ ...
首先,甚至在调用任何插件之前,Kubernetes都会为壁炉创建一个网络名称空间。 这是通过使用特殊的
pause容器来实现的,该容器“充当所有炉膛容器的“父容器”
(来自“ 全能暂停容器 ”一文) 。 然后Kubernetes执行CNI插件以将
pause容器连接到网络。 所有pod容器都使用此
pause容器的
netns 。
{ "cniVersion": "0.3.1", "name": "bridge", "type": "bridge", "bridge": "cnio0", "isGateway": true, "ipMasq": true, "ipam": { "type": "host-local", "ranges": [ [{"subnet": "${POD_CIDR}"}] ], "routes": [{"dst": "0.0.0.0/0"}] } }
用于CNI的
配置表示使用
bridge插件在名为
cnio0的根名称空间中配置Linux(L2)软件网桥(
默认名称为
cni0 ),该网关充当网关(
"isGateway": true )。

veth对还将配置为将炉床连接到新创建的桥:
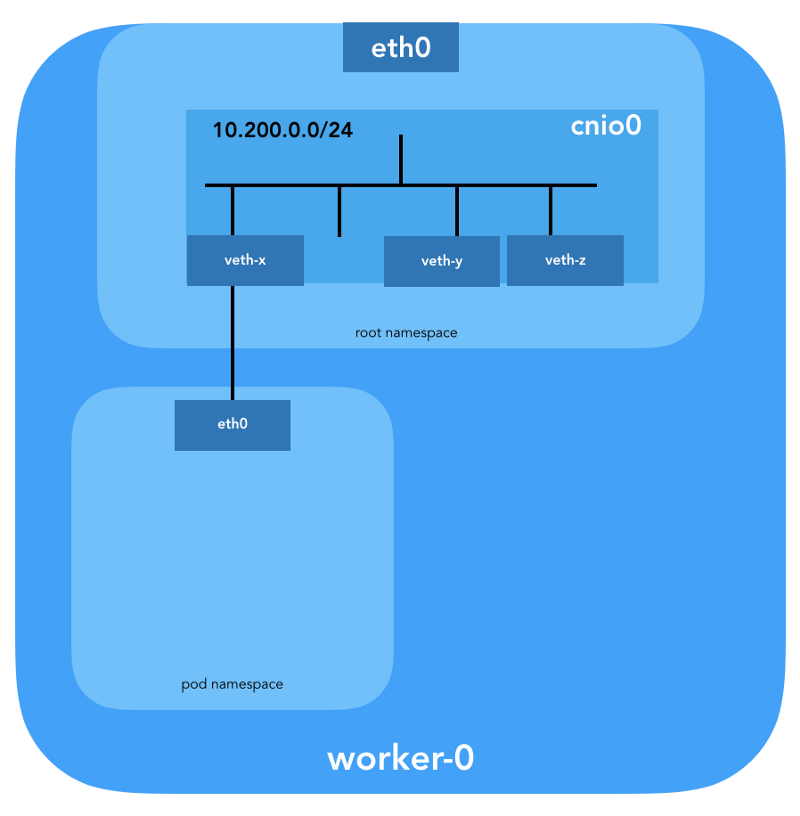
要分配L3信息(例如IP地址),将调用
IPAM (
ipam )
插件 。 在这种情况下,将使用
host-local类型,“将状态本地存储在主机文件系统上,以确保一台主机上IP地址的唯一性”
(来自 host-local的 host-local ) 。 IPAM插件将此信息返回到先前的插件(
bridge ),以便可以配置配置中指定的所有路由(
"routes": [{"dst": "0.0.0.0/0"}] )。 如果未指定
gw ,
则从子网中获取 。 还在炉床的网络名称空间中配置默认路由,指向桥(桥被配置为炉床的第一个IP子网)。
最后一个重要细节:我们要求对来自壁炉网络的流量进行伪装(
"ipMasq": true )。 我们这里实际上并不需要NAT,但这是
Kubernetes The Hard Way中的配置。 因此,为了完整起见,我必须提到
bridge插件的
iptables的条目是为此特定示例配置的。 来自炉床的所有数据包(其接收者不在
224.0.0.0/4范围内)
将位于NAT后面,NAT不能完全满足“所有容器都可以与任何其他容器通信而无需使用NAT”的要求。 好吧,我们将证明为什么不需要NAT ...

炉膛路由
现在我们可以自定义豆荚了。 让我们看一下其中一个工作节点名称的所有网络空间,并在
从此处创建
nginx部署之后分析其中一个。 我们将使用带有
-t选项的
lsns选择所需的名称空间类型(即
net ):
ubuntu@worker-0:~$ sudo lsns -t net NS TYPE NPROCS PID USER COMMAND 4026532089 net 113 1 root /sbin/init 4026532280 net 2 8046 root /pause 4026532352 net 4 16455 root /pause 4026532426 net 3 27255 root /pause
使用
-i选项可以找到它们的inode号:
ubuntu@worker-0:~$ ls -1i /var/run/netns 4026532352 cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af 4026532280 cni-7cec0838-f50c-416a-3b45-628a4237c55c 4026532426 cni-912bcc63-712d-1c84-89a7-9e10510808a0
您还可以使用
ip netns列出所有网络名称空间:
ubuntu@worker-0:~$ ip netns cni-912bcc63-712d-1c84-89a7-9e10510808a0 (id: 2) cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af (id: 1) cni-7cec0838-f50c-416a-3b45-628a4237c55c (id: 0)
要查看在网络空间
cni-912bcc63–712d-1c84–89a7–9e10510808a0 (
4026532426 )中运行的所有进程,您可以运行例如以下命令:
ubuntu@worker-0:~$ sudo ls -l /proc/[1-9]*/ns/net | grep 4026532426 | cut -f3 -d"/" | xargs ps -p PID TTY STAT TIME COMMAND 27255 ? Ss 0:00 /pause 27331 ? Ss 0:00 nginx: master process nginx -g daemon off; 27355 ? S 0:00 nginx: worker process
可以看出,除了在此pod中
pause之外,我们还启动了
nginx 。
pause容器与所有其他容器容器共享
net和
ipc名称空间。 记住
pause的PID-27255; 我们将回到它。
现在,让我们看看
kubectl讲述了这个pod:
$ kubectl get pods -o wide | grep nginx nginx-65899c769f-wxdx6 1/1 Running 0 5d 10.200.0.4 worker-0
更多详细信息:
$ kubectl describe pods nginx-65899c769f-wxdx6
Name: nginx-65899c769f-wxdx6 Namespace: default Node: worker-0/10.240.0.20 Start Time: Thu, 05 Jul 2018 14:20:06 -0400 Labels: pod-template-hash=2145573259 run=nginx Annotations: <none> Status: Running IP: 10.200.0.4 Controlled By: ReplicaSet/nginx-65899c769f Containers: nginx: Container ID: containerd://4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 Image: nginx ...
我们看到了Pod的名称
nginx-65899c769f-wxdx6及其容器之一(
nginx )的ID,但是关于
pause并没有说什么。 挖掘更深的工作节点以匹配所有数据。 请记住,
Kubernetes The Hard Way不使用
Docker ,因此有关容器的详细信息,请参阅控制台实用程序
containerd -ctr
(另请参见文章``将容器化与Kubernetes集成,替换Docker,准备投入生产 ''- 大约Transfer ) :
ubuntu@worker-0:~$ sudo ctr namespaces ls NAME LABELS k8s.io
了解容器化(
k8s.io )
k8s.io ,您可以获得
nginx容器ID:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep nginx 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 docker.io/library/nginx:latest io.containerd.runtime.v1.linux
...并
pause一下:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep pause 0866803b612f2f55e7b6b83836bde09bd6530246239b7bde1e49c04c7038e43a k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux 21640aea0210b320fd637c22ff93b7e21473178de0073b05de83f3b116fc8834 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux
以
…983c7结尾的
nginx容器ID与我们从
kubectl获得的
kubectl 。 让我们看看是否可以确定哪个
pause容器属于
nginx pod:
ubuntu@worker-0:~$ sudo ctr -n k8s.io task ls TASK PID STATUS ... d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 27255 RUNNING 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 27331 RUNNING
还记得
cni-912bcc63–712d-1c84–89a7–9e10510808a0网络名称空间中运行的PID为27331和27355的进程吗?
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 { "ID": "d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6", "Labels": { "io.cri-containerd.kind": "sandbox", "io.kubernetes.pod.name": "nginx-65899c769f-wxdx6", "io.kubernetes.pod.namespace": "default", "io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382", "pod-template-hash": "2145573259", "run": "nginx" }, "Image": "k8s.gcr.io/pause:3.1", ...
...和:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 { "ID": "4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7", "Labels": { "io.cri-containerd.kind": "container", "io.kubernetes.container.name": "nginx", "io.kubernetes.pod.name": "nginx-65899c769f-wxdx6", "io.kubernetes.pod.namespace": "default", "io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382" }, "Image": "docker.io/library/nginx:latest", ...
现在,我们确切地知道此容器(
nginx-65899c769f-wxdx6 )和网络名称空间(
cni-912bcc63–712d-1c84–89a7–9e10510808a0 )中正在运行的容器:
- nginx(ID:
4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 ); - 暂停(ID:
d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 )。

(
nginx-65899c769f-wxdx6 )下的该如何连接到网络? 我们使用先前从
pause接收到的PID 27255在其网络名称空间(
cni-912bcc63–712d-1c84–89a7–9e10510808a0 )中运行命令:
ubuntu@worker-0:~$ sudo ip netns identify 27255 cni-912bcc63-712d-1c84-89a7-9e10510808a0
为此,我们将
nsenter与
-t选项一起使用,该选项定义了目标PID,而
-n没有指定文件以进入目标进程的网络名称空间(27255)。 这是
ip link show内容:
ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ip link show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 3: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether 0a:58:0a:c8:00:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0
...和
ifconfig eth0 :
ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ifconfig eth0 eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.200.0.4 netmask 255.255.255.0 broadcast 0.0.0.0 inet6 fe80::2097:51ff:fe39:ec21 prefixlen 64 scopeid 0x20<link> ether 0a:58:0a:c8:00:04 txqueuelen 0 (Ethernet) RX packets 540 bytes 42247 (42.2 KB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 177 bytes 16530 (16.5 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
这确认先前在
eth0接口上配置了通过
kubectl get pod获得的IP地址。 此接口是
veth对的一部分,其一端在炉膛中,另一端在根名称空间中。 为了找到第二端的接口,我们使用
ethtool :
ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ethtool -S eth0 NIC statistics: peer_ifindex: 7
我们看到
ifindex盛宴的
ifindex为7。检查它是否在根名称空间中。 这可以使用
ip link完成:
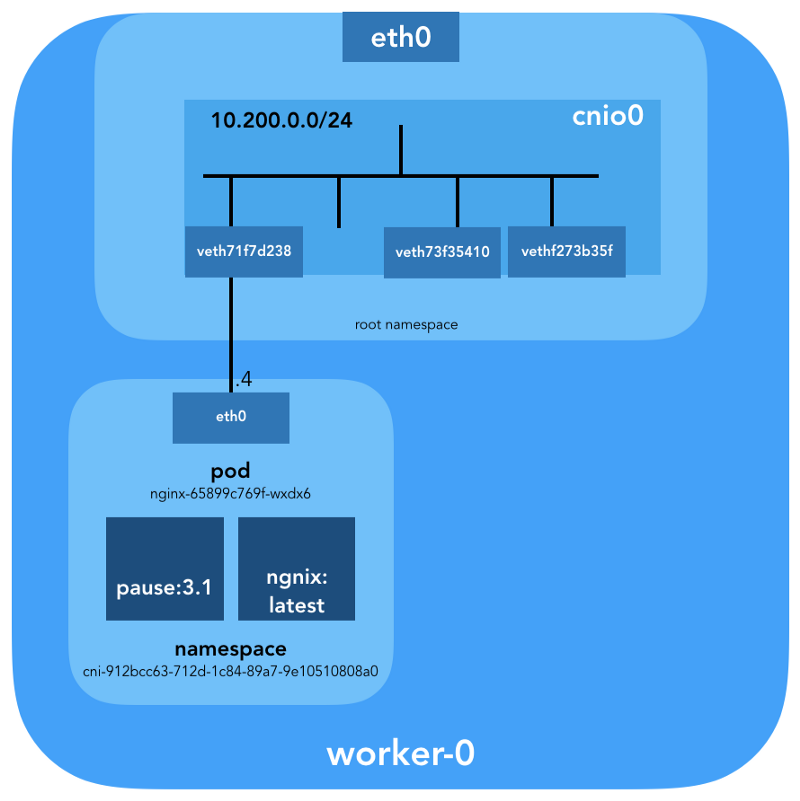
ubuntu@worker-0:~$ ip link | grep '^7:' 7: veth71f7d238@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cnio0 state UP mode DEFAULT group default
最后要确定这一点,让我们看看:
ubuntu@worker-0:~$ sudo cat /sys/class/net/veth71f7d238/ifindex 7
太好了,虚拟链接现在一切都清晰了。 使用
brctl让我们看看还有谁连接到Linux网桥:
ubuntu@worker-0:~$ brctl show cnio0 bridge name bridge id STP enabled interfaces cnio0 8000.0a580ac80001 no veth71f7d238 veth73f35410 vethf273b35f
因此,图片如下:
路由检查
我们实际上如何转发流量? 让我们看一下网络名称空间窗格中的路由表:
ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ip route show default via 10.200.0.1 dev eth0 10.200.0.0/24 dev eth0 proto kernel scope link src 10.200.0.4
至少我们知道如何到达根名称空间(
default via 10.200.0.1 )。 现在让我们看一下主机路由表:
ubuntu@worker-0:~$ ip route list default via 10.240.0.1 dev eth0 proto dhcp src 10.240.0.20 metric 100 10.200.0.0/24 dev cnio0 proto kernel scope link src 10.200.0.1 10.240.0.0/24 dev eth0 proto kernel scope link src 10.240.0.20 10.240.0.1 dev eth0 proto dhcp scope link src 10.240.0.20 metric 100
我们知道如何将数据包转发到VPC路由器(VPC
具有 “隐式”路由器,该路由器
通常具有子网主IP地址空间中的
第二个地址 )。 现在:VPC路由器知道如何访问每个炉床的网络吗? 不,他没有,因此,假定路由将由CNI插件配置或
手动配置 (如手册中所述)。 显然,
AWS CNI插件正是在AWS上为我们完成的。 请记住,有
很多CNI插件 ,我们正在考虑一个
简单的网络配置示例:
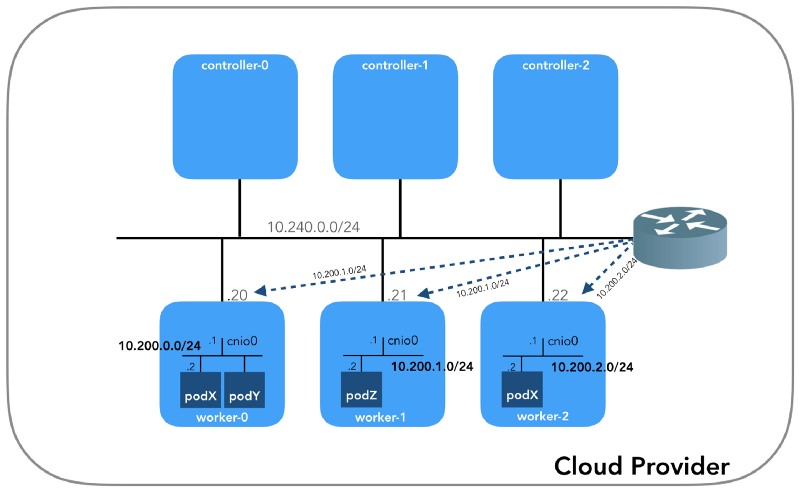
深浸在NAT中
kubectl create -f busybox.yaml使用Replication Controller创建两个相同的
busybox容器:
apiVersion: v1 kind: ReplicationController metadata: name: busybox0 labels: app: busybox0 spec: replicas: 2 selector: app: busybox0 template: metadata: name: busybox0 labels: app: busybox0 spec: containers: - image: busybox command: - sleep - "3600" imagePullPolicy: IfNotPresent name: busybox restartPolicy: Always
(
busybox.yaml )
我们得到:
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE busybox0-g6pww 1/1 Running 0 4s 10.200.1.15 worker-1 busybox0-rw89s 1/1 Running 0 4s 10.200.0.21 worker-0 ...
从一个容器到另一个容器的ping操作应该成功:
$ kubectl exec -it busybox0-rw89s -- ping -c 2 10.200.1.15 PING 10.200.1.15 (10.200.1.15): 56 data bytes 64 bytes from 10.200.1.15: seq=0 ttl=62 time=0.528 ms 64 bytes from 10.200.1.15: seq=1 ttl=62 time=0.440 ms --- 10.200.1.15 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.440/0.484/0.528 ms
要了解流量的移动,可以使用
tcpdump或
conntrack查看数据包:
ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.15 icmp 1 29 src=10.200.0.21 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1
来自Pod 10.200.0.21的源IP被转换为主机10.240.0.20的IP地址。
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.15 icmp 1 28 src=10.240.0.20 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1
在iptables中,您可以看到计数在增加:
ubuntu@worker-0:~$ sudo iptables -t nat -Z POSTROUTING -L -v Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination ... 5 324 CNI-be726a77f15ea47ff32947a3 all -- any any 10.200.0.0/24 anywhere /* name: "bridge" id: "631cab5de5565cc432a3beca0e2aece0cef9285482b11f3eb0b46c134e457854" */ Zeroing chain `POSTROUTING'
另一方面,如果从CNI插件配置中删除
"ipMasq": true ,则可以看到以下内容(此操作仅出于教育目的而执行-我们不建议在工作集群上更改配置!):
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE busybox0-2btxn 1/1 Running 0 16s 10.200.0.15 worker-0 busybox0-dhpx8 1/1 Running 0 16s 10.200.1.13 worker-1 ...
Ping应该仍然通过:
$ kubectl exec -it busybox0-2btxn -- ping -c 2 10.200.1.13 PING 10.200.1.6 (10.200.1.6): 56 data bytes 64 bytes from 10.200.1.6: seq=0 ttl=62 time=0.515 ms 64 bytes from 10.200.1.6: seq=1 ttl=62 time=0.427 ms --- 10.200.1.6 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.427/0.471/0.515 ms
在这种情况下-不使用NAT:
ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.13 icmp 1 29 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1
因此,我们检查了“所有容器都可以在不使用NAT的情况下与任何其他容器进行通信”。
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.13 icmp 1 27 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1
群集网络(10.32.0.0/24)
您可能已经在
busybox示例中注意到,分配给
busybox的IP地址在每种情况下都是不同的。 如果我们想使这些容器可用于其他炉床之间的通信呢? 一个人可能会使用Pod的当前IP地址,但是它们会改变。 因此,您需要配置
Service资源,该资源会将请求代理到许多短暂的炉膛。
“ Kubernetes中的服务是一种抽象,定义了炉膛的逻辑集和可访问它们的策略。” (来自Kubernetes Services文档)
有多种发布服务的方式。 默认类型为
ClusterIP ,它从群集的CIDR块设置IP地址(即只能从群集访问)。 一个这样的示例是在Kubernetes The Hard Way中配置的DNS群集附加组件。
# ... apiVersion: v1 kind: Service metadata: name: kube-dns namespace: kube-system labels: k8s-app: kube-dns kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "KubeDNS" spec: selector: k8s-app: kube-dns clusterIP: 10.32.0.10 ports: - name: dns port: 53 protocol: UDP - name: dns-tcp port: 53 protocol: TCP # ...
(
kube-dns.yaml )
kubectl表明
Service记住端点并进行转换:
$ kubectl -n kube-system describe services ... Selector: k8s-app=kube-dns Type: ClusterIP IP: 10.32.0.10 Port: dns 53/UDP TargetPort: 53/UDP Endpoints: 10.200.0.27:53 Port: dns-tcp 53/TCP TargetPort: 53/TCP Endpoints: 10.200.0.27:53 ...
究竟是什么?..
iptables又一次。 让我们看一下为该示例创建的规则。 可以使用
iptables-save命令查看其完整列表。
一旦数据包由进程(
OUTPUT )创建或到达网络接口(
PREROUTING ),它们便通过以下
iptables链:
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES -A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
以下目标对应于发送到10.32.0.10处的第53个端口的TCP数据包,并通过第53个端口发送给接收者10.200.0.27:
-A KUBE-SERVICES -d 10.32.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp cluster IP" -m tcp --dport 53 -j KUBE-SVC-ERIFXISQEP7F7OF4 -A KUBE-SVC-ERIFXISQEP7F7OF4 -m comment --comment "kube-system/kube-dns:dns-tcp" -j KUBE-SEP-32LPCMGYG6ODGN3H -A KUBE-SEP-32LPCMGYG6ODGN3H -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp" -m tcp -j DNAT --to-destination 10.200.0.27:53
对于UDP数据包也是如此(收件人10.32.0.10:53→10.200.0.27:53):
-A KUBE-SERVICES -d 10.32.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU -A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns" -j KUBE-SEP-LRUTK6XRXU43VLIG -A KUBE-SEP-LRUTK6XRXU43VLIG -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.200.0.27:53
Kubernetes中还有其他类型的
Services 。 特别是,Kubernetes The Hard Way
NodePort了
NodePort ,请参阅
Smoke Test:Services 。
kubectl expose deployment nginx --port 80 --type NodePort
NodePort在每个节点的IP地址上发布服务,并将其放置在静态端口(称为
NodePort )上。
NodePort可以从群集外部访问
NodePort 。 您可以使用
kubectl检查专用端口(在本例中为31088):
$ kubectl describe services nginx ... Type: NodePort IP: 10.32.0.53 Port: <unset> 80/TCP TargetPort: 80/TCP NodePort: <unset> 31088/TCP Endpoints: 10.200.1.18:80 ...
Under现在可以从Internet上获得,网址为
http://${EXTERNAL_IP}:31088/ 。 此处
EXTERNAL_IP是
任何工作实例的公共IP地址。 在此示例中,我使用
worker-0的公共IP地址。 内部IP地址为10.240.0.20的主机(云提供商从事公共NAT)接收到该请求,但是,该服务实际上是在另一台主机上启动的(
worker-1 ,可以通过端点的IP地址-10.200.1.18看到):
ubuntu@worker-0:~$ sudo conntrack -L | grep 31088 tcp 6 86397 ESTABLISHED src=173.38.XXX.XXX dst=10.240.0.20 sport=30303 dport=31088 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=30303 [ASSURED] mark=0 use=1
数据包从
worker-0发送到
worker-1 ,在其中找到接收者:
ubuntu@worker-1:~$ sudo conntrack -L | grep 80 tcp 6 86392 ESTABLISHED src=10.240.0.20 dst=10.200.1.18 sport=14802 dport=80 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=14802 [ASSURED] mark=0 use=1
这样的电路理想吗? 也许不行,但是行得通。 在这种情况下,已编程的
iptables规则如下:
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/nginx:" -m tcp --dport 31088 -j KUBE-SVC-4N57TFCL4MD7ZTDA -A KUBE-SVC-4N57TFCL4MD7ZTDA -m comment --comment "default/nginx:" -j KUBE-SEP-UGTFMET44DQG7H7H -A KUBE-SEP-UGTFMET44DQG7H7H -p tcp -m comment --comment "default/nginx:" -m tcp -j DNAT --to-destination 10.200.1.18:80
换句话说,带有端口31088的数据包接收方的地址在10.200.1.18上广播。 该港口还在广播,从31088到80。
我们没有涉及另一种类型的服务
LoadBalancer ,它使用云提供商的负载平衡器使该服务公开可用,但事实证明这篇文章很大。
结论
似乎有很多信息,但我们只触及到了冰山一角。 将来,我将讨论IPv6,IPVS,eBPF和几个当前有趣的CNI插件。
译者的PS
另请参阅我们的博客: