
今天,终于,会议的主要议程开始了。 今年的录取率只有8%,即 必须是最好的最好的最好的。 应用和研究流程明确分开,此外还有几个单独的相关活动。 应用流看起来更有趣,其中的报告主要来自专业(Google,Amazon,阿里巴巴等)。 我将告诉您我设法参加的表演。
数据很好
一天的开始是冗长的演示,数据应该有用并有益。 加利福尼亚大学的一位
教授正在
讲话 (值得注意的是,在KDD中,在学生中和在讲话者中都有很多女性)。 所有这些都用缩写FATES表示:
- 公平-模型预测没有偏见,所有内容均不分性别,并且可以包容。
- 可追究性-必须由某人或某物负责机器的决策。
- 透明度-决策的透明度和可解释性。
- 道德规范-处理数据时,应特别强调道德规范和隐私。
- 安全性-系统必须安全(无害)并受到保护(可抵抗来自外部的操纵影响)
不幸的是,这个宣言表达了一种愿望,并且与现实之间的联系微弱。 只有从模型中去除所有迹象后,该模型在政治上才是正确的。 转移给特定人的责任总是非常困难的; DS越发展,解释模型内部发生的事情就越困难; 在道德和隐私方面,第一天有一些很好的例子,但除此之外,通常会相当自由地处理数据。
好吧,人们不得不承认,现代模型通常不安全(自动驾驶仪可以让驾驶员抛弃汽车)并且不受保护(您可以拿取破坏神经网络工作的示例,甚至不知道神经网络的工作原理)。
DeepExplore公司最近的一项有趣的工作:用于搜索神经网络中漏洞的系统会生成图片,这些图片会使自动驾驶仪转向错误的方向。

以下是数据科学的另一种定义,即“ DS是对提取价值形式数据的研究”。 原则上,还不错。 演讲者在演讲开始时特别提到,DS通常仅在分析时才查看数据,而整个生命周期则要宽得多,这尤其反映在定义中。
好吧,这里有一些实验室工作的例子。
再次,我们将分析评估许多因素对结果的影响的任务,而不是从广告的位置,而是从总体上。 有
一篇文章尚未发表。 例如,考虑选择哪个演员来拍摄电影以取得良好票房的问题。 我们分析了票房最高的电影的演员表,并试图预测每个演员的贡献。 但是! 有些所谓的
混杂因素会影响演员的效率(例如,史泰龙在一部重磅动作电影中会表现出色,但在浪漫喜剧中却不会)。 要选择合适的人,您需要找到所有混杂因素并对其进行评估,但是我们永远不能确定我们找到了每个人。 实际上,本文提出了一种新方法-去混杂器。 我们没有突出显示混杂因素,而是明确引入了潜在变量,并在无监督的模式下对其进行了评估,然后基于它们研究模型。 这听起来似乎很奇怪,因为它看起来像是嵌入的简单变体,因此尚不清楚新功能。
展示了一些漂亮的图片,例如他们大学的AI如何发展的例子。
电子商务和分析
转到有关贸易的应用程序部分。 最初有一些非常有趣的报道,最后有一些稀饭,但首先要先做。
新用户建模和客户流失预测
Snapchat在预测流量方面的有趣
工作 。 伙计们使用了这个想法,我们也在大约4年前成功运行了这个想法:在预测流出之前,需要根据行为类型将用户分为几类。 同时,矢量空间的行为类型非常差,只有少数几种类型的交互(我们不得不在适当的时候选择符号,以便从三百个变为一百五十个),但是他们用额外的统计数据丰富了空间并将其视为时间序列,因此,获得群集的方式与用户执行操作无关,而与用户执行操作的
频率有关。
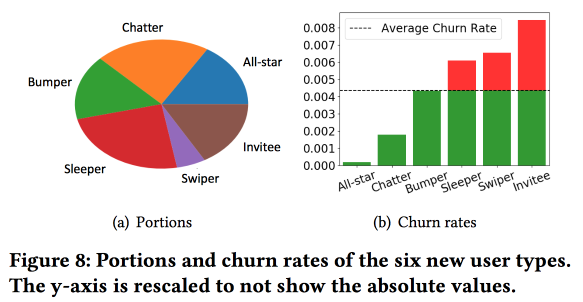
一个重要的观察结果:该网络是连接最紧密和最活跃的用户的“核心”,其规模为170万人。 同时,用户的行为和保留在很大程度上取决于他是否可以与“核心”人员通信。
然后我们开始建立模型。 让我们以两周(51.1万),简单的功能和自我网络(大小和密度)为新手,并查看它们是否与“核心”相关联。 我们使用LSTM来记录用户行为,并获得流出预测的准确性略高于logreg的准确性(提高7-8%)。 但是随后的乐趣开始了。 考虑到各个群集的具体情况,我们将并行训练多个LSTM,并在其顶部附加一个注意层。 结果,这种方案开始在聚类(哪些LSTM得到关注)和流出预测上起作用。 它的质量又提高了5-7%,logreg看上去已经很苍白。 但是! 实际上,将其与针对集群进行了单独训练的分段logreg(可以通过更简单的方式获得)进行比较是公平的。
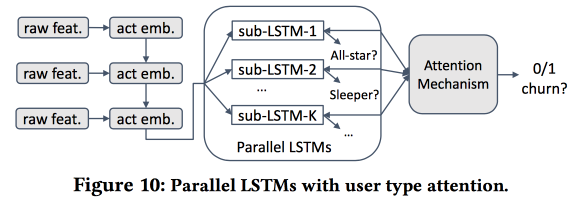
我问了一下可解释性:毕竟,流出的预测通常不是为了获得预测,而是为了了解影响它的因素。 发言者显然已经准备好解决这个问题:为此,使用和分析了专用群集,而不是将流出量较高的群集与其他群集区分开。
通用用户表示
阿里巴巴的家伙在
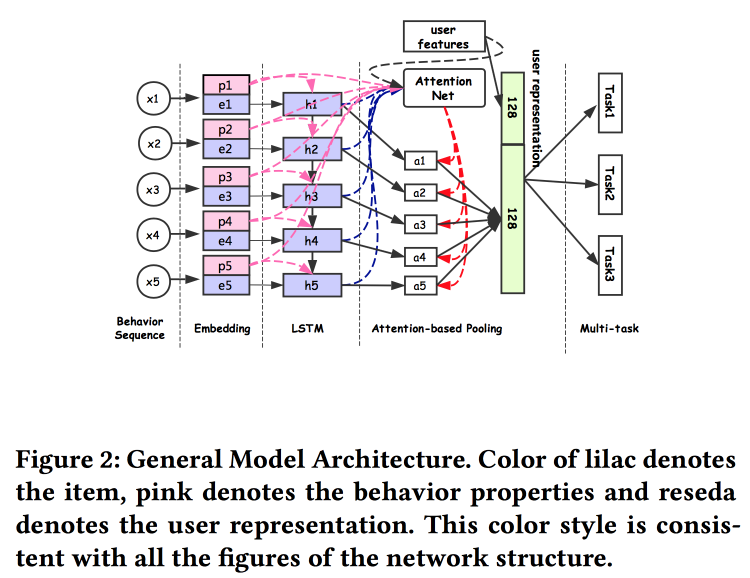
谈论如何建立用户关联。 事实证明,提交大量用户是不好的:许多未最终确定,浪费了力量。 他们设法做了一个通用的演示文稿,并表明它效果更好。 自然地在神经网络上。 该体系结构是相当标准的,已经在会议上重复描述过一种或另一种形式。 来自用户行为的事实被输入到输入中,我们在它们的基础上进行构建,将其全部交给LSTM,在其上悬挂一个注意层,然后在其旁边附加一个用于静态功能的网格,以一个多任务作为加冠(实际上,一个特定任务的几个小网格) 。 我们将所有这些训练在一起,注意的输出将是用户的嵌入。
还有一些更复杂的添加:除了简单的关注之外,它们还添加了“深度”关注网,并且还使用了LSTM的修改版本-属性门LSTM
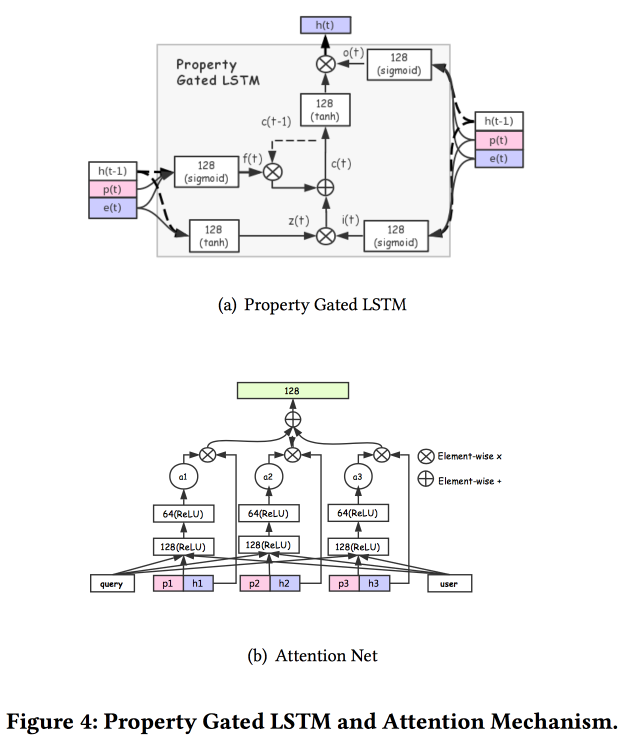
围绕这些任务执行的任务:点击率预测,价格偏好预测,学习排名,时尚追踪预测,商店偏好预测。 10天的数据集包括6 * 10
9个训练示例。
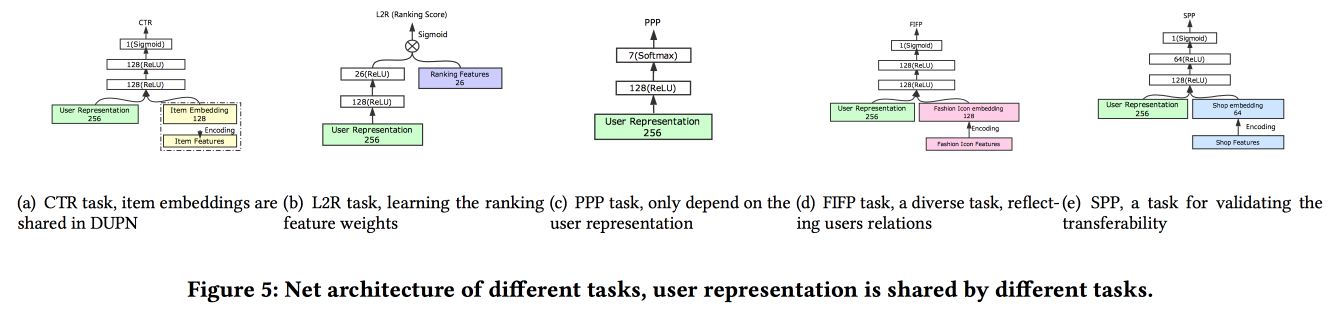
然后是一个意料之外的人:他们在TensorFlow上训练所有这一切,在2000台计算机的CPU集群上,每个集群有15个内核,需要4天才能完成10天的数据。 因此,他们继续日复一日地进行再培训(在此集群上为10个小时)。 关于GPU / FPGA,我没有时间问:(。添加新任务既可以通过整体重新训练,也可以通过对浅网格的重新训练(netwrok的微调)来完成。在进行推理时,它们存储表示(特定用户注意的输出),并且仅计算网格头具体任务A / B测试显示各种指标增加了2-3%。
电子尾巴产品退货预测
他们预测用户购买后的退货,这项
工作由IBM提出。 不幸的是,到目前为止,开放访问中还没有文本。 退货是一个严重的问题,每年价值2000亿美元。 为了建立回报预测,他使用了一个将产品和购物篮连接起来的超图模型,他们使用这个购物篮尝试通过超图查找最接近的产品,然后他们估计了返还的可能性。 为了防止退货,在线商店有很多可能性,例如,为从购物篮中取出某些产品提供折扣。
我们立即注意到,具有重复项(例如,两件相同的T恤衫,尺寸不同)和没有重复件的购物篮之间存在显着差异,因此,对于这两种情况,我们必须立即构建不同的模型。
通用算法称为HyperGo:
- 我们正在构建一个超图来表示购买和退货,并提供来自用户,产品,购物篮的信息。
- 接下来,我们使用基于随机游动的局部图割获得预测的局部信息。
- 我们分别考虑带和不带篮。
- 我们使用贝叶斯方法来评估单个产品在购物篮中的影响。
比较根据提花KNN加权的篮筐收益与KNN的预测质量,按重复项的数量进行配给,我们得到的结果是增加的。 幻灯片上闪烁了指向GitHub的链接,但他们找不到其来源,并且本文中没有链接。
OpenTag:从产品配置文件中打开属性值提取
来自亚马逊的足够有趣的
工作 。 挑战:挖掘各种事实,让Alexa更好地回答问题。 他们说一切都很复杂,旧系统不知道如何使用新单词,通常需要大量手写规则和启发式方法,结果是一般的。 当然,具有已经熟悉的embednig-LSTM注意架构的神经网络将有助于解决所有问题,但是我们将使LSTM倍增,并且还将
条件随机场放在最前面。

我们将解决标记单词序列的问题。 标签将显示我们在何处开始和结束某些属性的序列(例如,狗食的味道和成分),LSTM会尝试预测它们。 作为对“机械土耳其人”的bun头和屈膝礼,使用了主动模型训练。 要选择需要发送以进行进一步标记的示例,请使用试探法“以标记在各个时代之间最经常交换的示例”。
学习和转移电子商务中的ID表示
在
工作中,阿里巴巴的同事再次回到了建筑嵌入的问题,这一次不仅着眼于用户,还着眼于ID:产品,品牌,类别,用户等。 交互会话用作数据源,并且还考虑了其他属性。 跳过图用作主要算法。
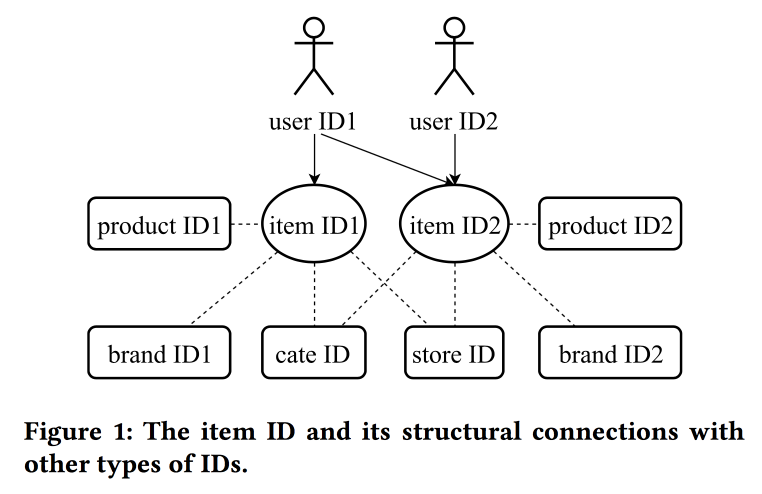
说话者的发音很重,带有强烈的汉语口音,要了解发生的事情几乎是不可能的。 这项工作的“技巧”之一是将缺乏信息的表示形式转移的机制,例如,从项目到用户的平均化(很快,您无需学习整个模型)。 从旧项目中,您可以初始化新项目(显然是通过内容相似性),以及将用户的视图从一个域(电子)转移到另一个域(衣服)。
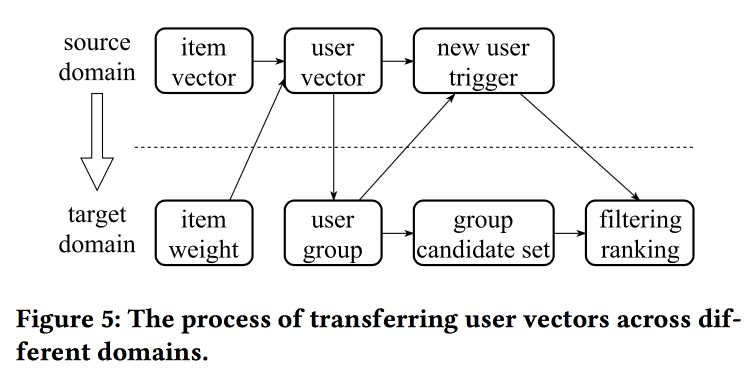
总体而言,目前尚不清楚新颖性在哪里,显然,需要挖掘细节。 此外,尚不清楚这与先前有关用户统一表示的故事相比如何。
基于Web的排名问题的在线参数选择
来自LinkedIn上朋友的非常有趣的
工作 。 工作的实质是考虑几个相互竞争的目标,在线选择算法操作的最佳参数。 作为范围,请考虑磁带,并尝试增加某些类型的会话数:
- 与一些病毒作用(VA)的会议。
- 恢复提交会话(JA)。
- Feed(EFS)会话中的内容交互。
算法中的排名函数是针对这三个目标的转化预测的加权平均值。 实际上,权重是我们将尝试在线优化的那些参数。 最初,他们将业务任务表述为“最大程度地增加病毒会话的数量,同时将其他两种类型的病毒至少保持在一定水平上”,但随后为了便于优化,对其进行了一些转换。
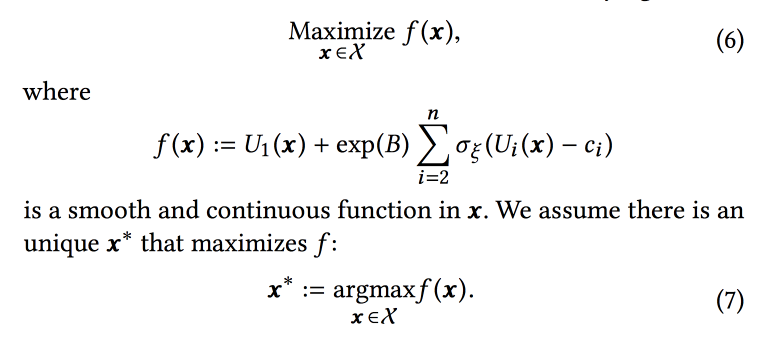
我们使用一组二项式分布来模拟数据(用户会看到带有特定参数的磁带,而用户是否会转换为所需的目标),其中使用给定参数成功的概率是一个
高斯过程 (每种转换类型都具有
高斯过程 )。 接下来,我们使用具有“无限
坚固 ”强盗的
Thompson采样器来选择最佳参数(不是在线的,而是在历史数据上离线,因此很长一段时间)。 他们给出了一些提示:使用粗体点构建初始网格,并确保添加
epsilon-greedy采样(具有epsilon在空间中尝试随机点的可能性),否则您可以忽略全局最大值。
他们模拟每小时一次离线取样(您需要大量样本),结果是最佳参数的一定分布。 此外,当用户从此分布进入时,他们会采用特定的参数来构造磁带(与初始化时使用的用户ID的种子保持一致,这一点很重要,这样用户的磁带才不会发生根本变化)。
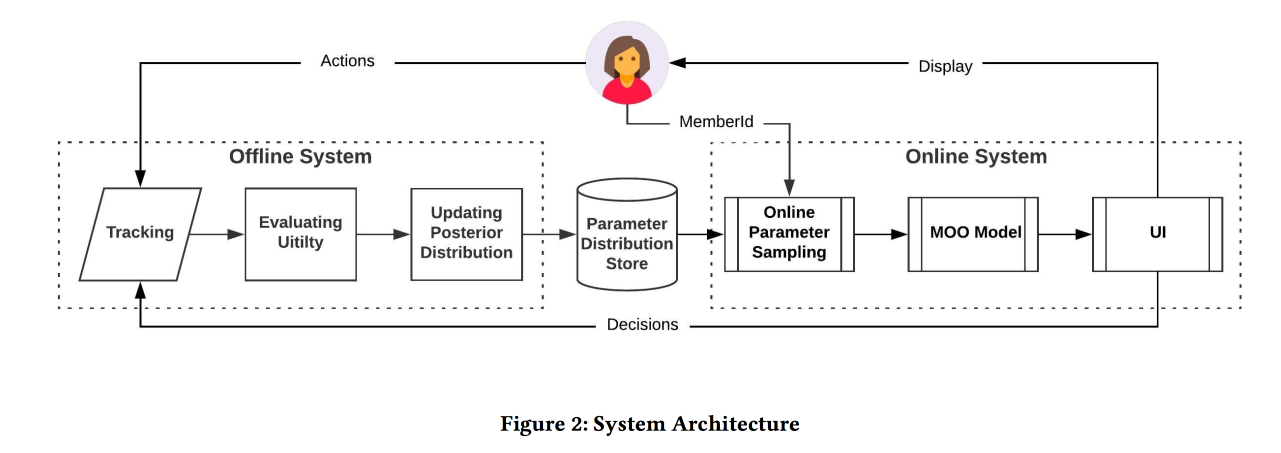
根据A / B实验的结果,他们收到的发送简历增加了12%,喜欢率增加了3%。 分享一些意见:
- 与尝试向模型中添加更多信息(例如,星期几/小时)相比,采样更多容易。
- 我们采用这种方法假设目标是独立的,但尚不清楚它是否(而不是)。 但是,该方法有效。
- 企业应设定目标和门槛。
- 将一个人排除在流程之外,让他做一些有用的事情很重要。
基于活动的通知的近实时优化
LinkedIn的另一项
工作 ,这次是关于管理通知。 我们拥有人员,事件,交付渠道和长期目标,以增加用户的参与度,而不会以抱怨和取消订阅的形式显着降低负面影响。 这项任务既重要又困难,您需要正确地做所有事情:在正确的时间向正确的人发送正确的内容,并在正确的数量上发送正确的内容。
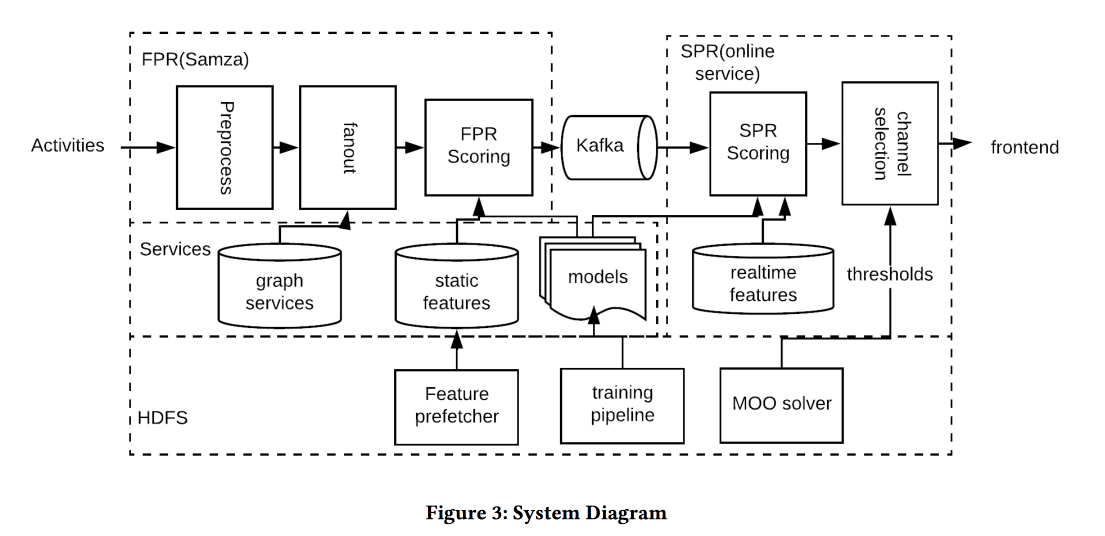
上图中的系统架构,正在发生的本质大致如下:
- 我们过滤输入处的所有垃圾邮件。
- 合适的人:适合与作者/内容紧密相关的每个人的头盔,平衡沟通强度的门槛,管理报道范围和相关性。
- 正确的时间:立即发送重要的时间(朋友活动)的内容,其余时间可保留以减少动态频道。
- 正确的内容:使用logreg! 分别针对有人在应用程序中和不在应用程序中时的情况,分别构建一个符号堆点击的预测模型。
- 正确的渠道:我们为相关性设置了不同的阈值(对推送最严格的阈值),对于邮件(包含各种摘要/广告),如果用户现在在应用程序中,则设置较低的阈值,甚至更低。
- 正确的体积:包皮环切术模型在输出中,它也考虑相关性,建议单独进行(良好的阈值启发法是过去几天中已发送对象的最低分数)
在A / B测试中,会话数增加了百分之几。
在Airbnb上使用嵌入进行搜索排名的实时个性化
那是AirBnB
最好的应用论文 。 目标:优化类似展示位置和搜索结果的发布。 为了进一步评估相似度,我们决定在一个空间中构建展示位置和用户的嵌入。 重要的是要记住,有长期的历史记录(用户偏好)和短期的历史记录(当前用户/会话意图)。
事不宜迟,我们使用搜索会话(一个会话-一个文档)中的点击序列构建word2vec位置。 但是我们仍然要进行一些修改(毕竟是KDD):
- 我们参加有保留的会议。
- 最终保留的是,在w2v更新期间,我们将其作为会话所有元素的全局上下文。
- 培训中的负面人士在同一城市抽样。

通过三种标准方式来检查这种模型的有效性:
- 离线查看:我们可以在多长时间内在搜索会话中提升合适的酒店。
- 评估人员进行的测试:建立了一个特殊的工具来可视化相似的工具。
- A / B测试:剧透,点击率大幅增长,预订量没有增加,但现在它们发生得更早了
我们不仅尝试提前对搜索结果的结果进行排名,而且还尝试在收到响应后重新安排(因此是实时的)-单击一个句子,然后忽略另一个。 方法是收集两组中被单击和忽略的位置,在每个质心中找到嵌入(有一个特殊的公式),然后在排名中我们像单击一样提高,像跳过一样降低。
A / B测试的预订量有所增加,这种方法经受了时间的考验:它是一年半前发明的,并且仍在生产中。
如果您需要去另一个城市看看? 您将无法通过点击来确定优先级,也没有关于用户对此解决方案中的位置的态度的信息。 为了避免这个问题,我们引入了“内容嵌入”。 首先,我们将创建一个简单的离散的标志空间(便宜/昂贵,在中心/在郊区等),大小约为50万种(用于地方和人)。 接下来,我们按类型构建嵌入。 学习时,别忘了在拒绝时添加明确的否定(当场所的所有者尚未确认预订时)。
Web规模推荐系统的图卷积神经网络
Pinterest会根据引脚的推荐进行
工作 。 我们考虑了二部图用户引脚,并在建议中添加了网络功能。 该图非常大-30亿个图钉,160亿个交互;无法进行经典图嵌入。 ,
GraphSAGE , ( , message passing),
PinSAGE . , , .
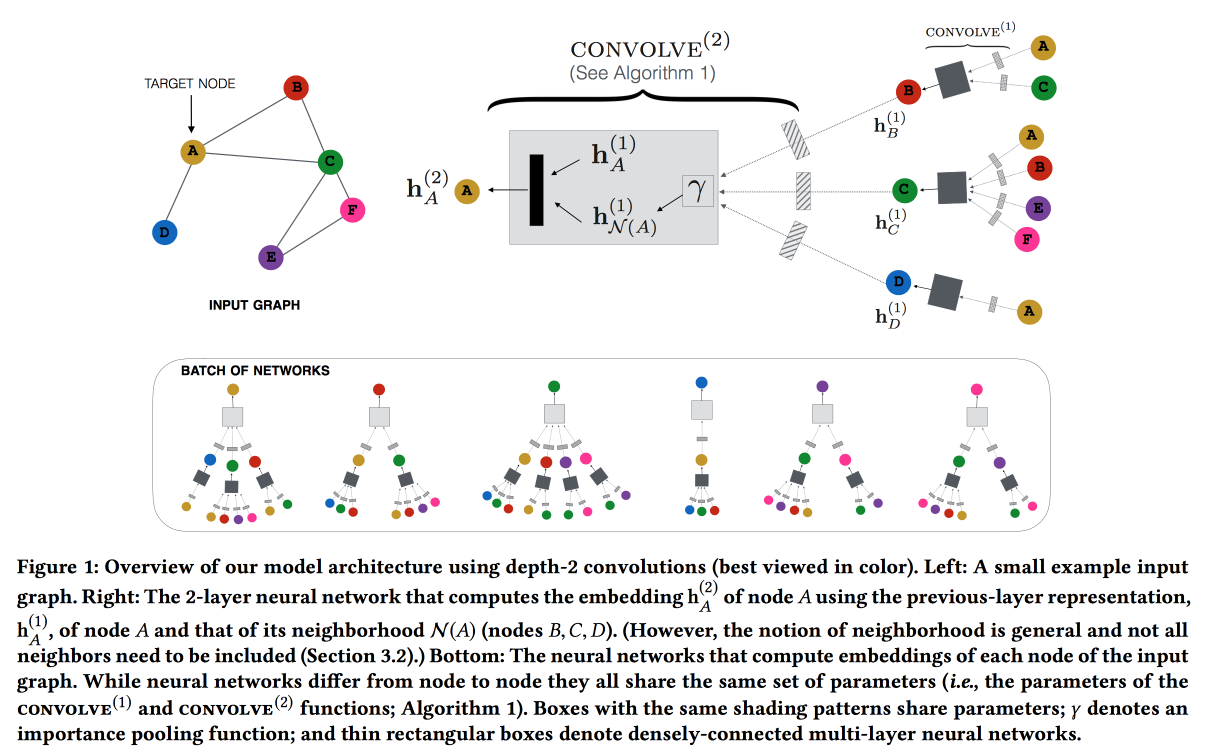
« »:
- max margin loss.
- CPU/GPU: CPU ( GPU ) GPU. , .
- , random walk-.
- Curriculum Learning: hard negative-. .
- Map reduce, .
, , . , /-.
Q&R: A Two-Stage Approach Toward Interactive Recommendation
« , , ?» — YouTube
. : « ?». «» (, , YouTube , ).
YouTube Video-RNN, ID . , ID , (post fusion). (- -
GRU , LSTM LSTM).

7 , 8-, . , 8 % , --. /-
interleaving- +0,7 % , +1,23 % .
: 18 % , +4 % .
Graph and social nets
, , , .
Graph Classification using Structural Attention
, « ». , , .
, , .
, LSTM , attention-, , . . , , , .
: , , . attention, , LSTM self-attention, ( ). «», , .
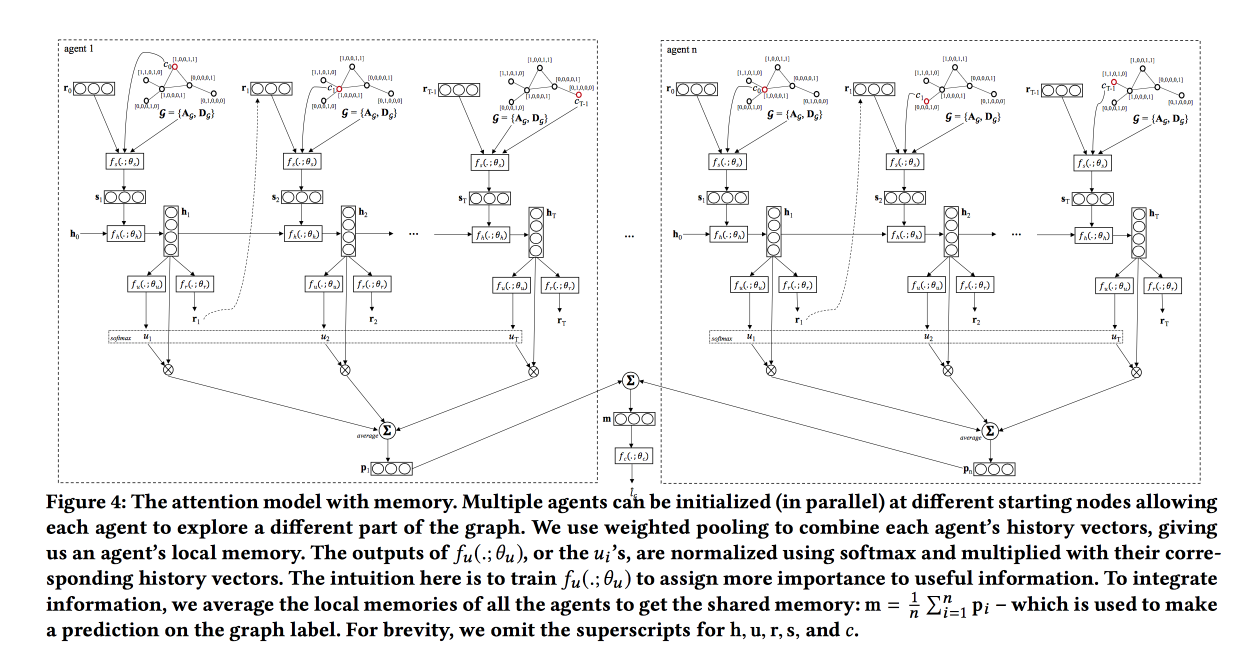
, baseline — . ,
TreeLSTM .
SpotLight: Detecting Anomalies in Streaming Graphs
, , -, , . « ». , , .
«» . - - , .
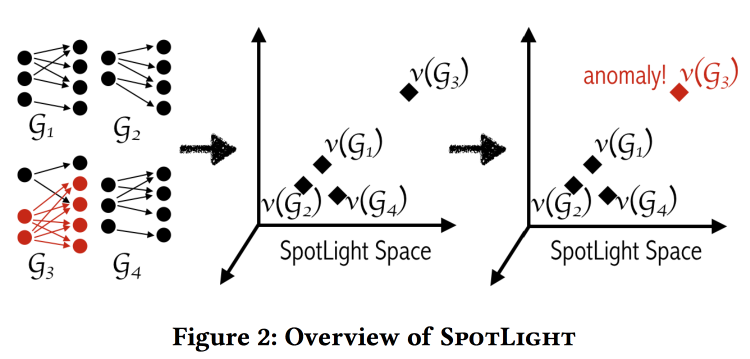
: , . . . , / .
, .
labeled DARPA dataset . , baseline- (.. ).
Adversarial Attacks on Graph Networks
. Adversary , , ..: / . , — ( — )? .
, :
- «» .
- «» .
- «» .
- , (poisoning).
. , , , — . . .
, unnoticeability: , ?
Multi-Round Influence maximization
. , , .
, ( , ).
-- :
- : , .
- : , .
- - : inffluencer- . , .
Reverse-Reachable sets: inffluencer-, , .
EvoGraph: An Effective and Efficient Graph Upscaling Method for Preserving Graph Properties
. ,
, .
, , power law. , , «» , : «» .

, , .
.
data science . 其实 , . .
All models are wrong, but some are useful — data science, , , . «» ( , , adversarial ..)
www.embo.org/news/articles/2015/the-numbers-speak-for-themselves — (overfitting, selection bias, , ..)
1762
The Equitable Life Assurance Society , .
现在,保险公司度过了艰难的时刻:2011年,最终禁止基于性别的歧视,现在保险中无法考虑性别(这确实很困难-即使您明确隐藏了“性别”这一特征,该模型也可能由于其他原因而近似)。这在英国引起了有趣的影响:- 妇女开车时比较准确,发生事故的可能性较小,因此保险对她们而言便宜。
- 平整后,女性的保险费用上升,而男性的保险费用下降。
- 市场有效:结果,道路上的男人更多,女人更少。
- 随着道路上驾驶员平均“准确性”的降低,发生了更多的事故。
- 之后,保险当然开始涨价了。
- 旅行保险开始更加严格地淘汰整洁的驾驶员。
结果,他们陷入了“死亡螺旋”。
这个主题呼应了当天的开幕表演。 F-公平,这是一些无法企及的云堡。 机器学习模型学习在属性空间中分离示例(包括人),因此从定义上讲它们不能“公平”。