
8月18日至19日,Tele2举办了一次数据科学黑客马拉松。 本次黑客马拉松集中于分析社交网络中的技术支持对话框,以加速和简化客户互动。
任务没有需要优化的特定指标;可以为您自己发明任务。 最主要的是改善服务。 竞赛的评审委员会是Tele2各个领域的主管,以及数据科学Pavel Pleskov中著名的Kaggle宗师社区。
在剪辑之下,团队的故事获得了第一名。
当一位同事邀请我参加这次黑客马拉松时,我很快就同意了。
我对NLP的主题很感兴趣,并且还有一些我想在实践中进行测试的神经网络开发。
Hackathon的组织者提前发送了一些数据集的小片段,以了解活动中将提供哪些数据。
结果数据很脏,对话框中出现了无关紧要的巨魔,操作员回答什么样的问题并不总是很明显。
显然,要在规定的24小时内实施该想法并不容易,所以我休假了1天,花了很多时间准备要尝试的神经网络。 这使我们不必浪费黑客马拉松时间来寻找错误,而将精力集中在应用程序和业务案例上。
Tele2办事处位于新莫斯科地区的Rumyantsevo商业园区。 对我来说,到达那里已经有一段时间了,但是商业园区给人留下了很好的印象(电源线除外)。
 商务中心背景下的电源线
商务中心背景下的电源线在地铁站,组织者与我们会面,向我们展示了如何到达办公室。 商务中心的建筑物本身被许多公司占用,Tele2办公室位于5楼。 黑客马拉松参加者在办公室内被分配了一个特殊区域,其中有厨房,带PlayStation和长椅的休闲区。 对于Wi-Fi的速度特别满意,没有发现大规模事件固有的问题。
 早餐吧
早餐吧Tele2提供的真实数据集由3个大型CSV文件组成,带有技术支持对话框:社交网络,电报和电子邮件对话框。 总共需要超过400万次点击才能训练神经网络。
什么是神经网络?
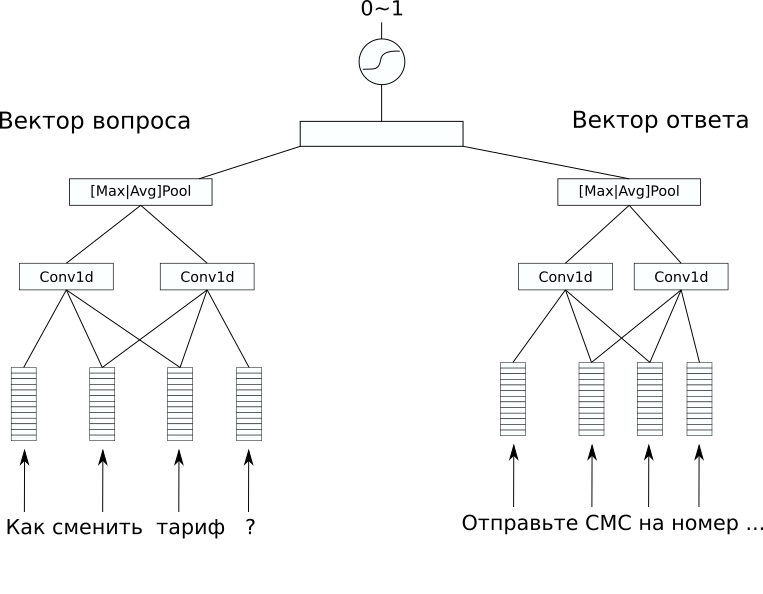 网络架构
网络架构在数据集中,没有其他有趣的标记可以预测,但是我想解决一个监督问题。 因此,我们决定尝试预测问题的答案,因此至少可以使用这种模型制作一个简单的聊天机器人。 为此,我们选择了CDSSM体系结构(卷积深度语义相似模型)。 这是用于通过意义比较文本的简单神经网络模型之一,最初是由Microsoft提出的,用于对Bing搜索结果进行排名。
其本质如下:首先,使用一系列卷积和池化层将每个文本转换为向量。
然后,以某种方式比较所得向量。 在我们的问题中,将两个向量与S型曲线作为激活函数的附加线性层给出了很好的结果。 对于一对文本,将句子编码成向量的网络的权重可以相同(此类网络称为暹罗语),并且可以不同。
在我们的案例中,具有不同权重的变体给出了最佳结果,因为问题和答案的文本明显不同。
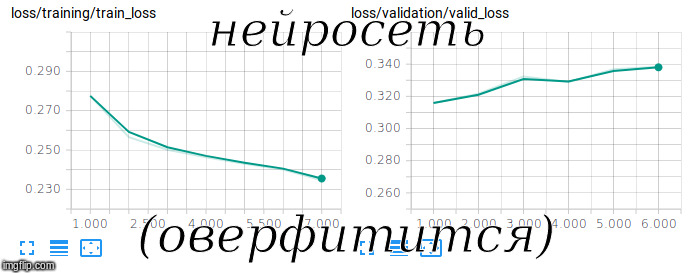 尝试训练连体网络
尝试训练连体网络带有RusVectōrēs的FastText用作预训练的
嵌入 ;它可以抵抗用户在用户问题中经常发现的拼写错误。
为了训练这样的模型,不仅需要对积极的模型进行培训,而且还需要对消极的示例进行培训。 为此,我们在训练集中以1到10的比率添加了随机的问题和答案对。
为了评估这种不平衡样品的质量,使用了ROC-AUC度量。 在GPU上进行了3个小时的培训后,我们成功达到了该指标0.92的值。
使用此模型,不仅可以解决直接问题(选择问题的适当答案),还可以解决相反的问题(查找操作员错误,低质量和用户问题的奇怪答案)。
我们设法在黑客马拉松上找到了一些答案,并将其包含在最终演示中。 在我看来,这给陪审团留下了最深刻的印象。
在网络在其工作过程中生成的文本的矢量表示中,也可以找到一个有趣的应用程序。
使用它,您可以通过
各种无监督的方法搜索问题和答案中的异常。
结果,无论从技术角度还是从业务角度来看,我们的决策都是明智的。 其余团队基本上都试图解决密钥分析和主题建模的问题,因此我们的解决方案差异很大。 结果,我们获得了第一名,感到既满意又累。
 照片中(从左到右):亚历山大·阿布拉莫夫,康斯坦丁·伊万诺夫,安德烈·维斯涅佐夫(作者)和谢韦佐夫·埃戈尔
照片中(从左到右):亚历山大·阿布拉莫夫,康斯坦丁·伊万诺夫,安德烈·维斯涅佐夫(作者)和谢韦佐夫·埃戈尔还有什么要读的: