
许多学习机器学习的人都熟悉OpenAI项目,该项目的创始人之一是Elon Musk,他们使用
OpenAI Gym平台来训练他们的神经网络模型。
健身房包含大量环境,其中一些环境是各种物理模拟:动物,人类,
机器人的运动。 这些模拟基于
MuJoCo物理引擎,该引擎免费用于教育和科学目的。
在本文中,我们将基于免费的物理引擎Bullet(
PyBullet )创建与OpenAI Gym环境类似的极其简单的物理模拟。 并创建一个可在此环境下工作的代理。
PyBullet是一个Python模块,用于基于
Bullet Physics物理引擎创建物理仿真环境。 与MuJoCo一样,它通常被用作各种机器人的刺激,这些机器人对habr感兴趣,有
一篇文章带有实际示例。
有一个很好的PyBullet
QuickStartGuide ,其中包含指向
GitHub源页面上的示例的链接。
PyBullet允许您以URDF,SDF或MJCF格式加载已创建的模型。 在源代码中,有这些格式的
模型库以及
真实机器人模拟器的完全现成的环境
。就我们而言,我们自己将使用PyBullet创建环境。 环境界面将
类似于 OpenAI Gym界面。 这样,我们可以在我们的环境和体育馆环境中训练代理。
所有代码(iPython)以及程序的操作都可以在
Google Colaboratory中看到。
环境环境
我们的环境将包含一个可以在一定高度范围内沿垂直轴移动的球。 球具有质量,并且重力作用在其上,并且代理必须控制施加在球上的垂直力,将其带到目标上。 目标海拔随每次体验重新启动而变化。

模拟非常简单,实际上可以看作是一些基本动子的模拟。
为了与环境配合使用,使用了3种方法:
重置 (重新启动实验并创建环境的所有对象),
步骤 (应用选定的动作并获得环境的最终状态),
渲染 (环境的可视显示)。
初始化环境时,有必要将我们的对象连接到物理模拟。 有2个连接选项:带图形界面(GUI)和不带(DIRECT),在我们的情况下为DIRECT。
pb.connect(pb.DIRECT)
重设
对于每个新实验,我们将重置
pb.resetSimulation()模拟并再次创建所有环境对象。
在PyBullet中,对象具有2个形状:碰撞
形状和
视觉形状 。 第一种方法由物理引擎用来计算对象的碰撞,并且为了加快物理计算速度,通常具有比真实对象更简单的形式。 第二个是可选的,仅在形成对象的图像时使用。
表单收集在单个对象(主体)
-MultiBody中 。 主体可以由一个形状(例如
CollisionShape / Visual Shape对)组成,也可以由多个形状组成。
除了组成身体的形式,还必须确定其质量,位置和空间方向。
关于多对象实体的几句话。通常,在实际情况下,为了模拟各种机制,将使用由多种形式组成的实体。 在创建物体时,除了碰撞和可视化的基本形式外,物体还传递了子对象形式的
链接 (
Links ),它们相对于先前对象的位置和方向以及它们之间对象之间的连接(关节)的类型(
Joint )。 连接类型可以是固定的,棱柱形的(在同一轴上滑动)或旋转的(在一个轴上旋转)。 最后两种类型的连接允许您设置相应类型的电动机(
JointMotor )的参数,例如作用力,速度或转矩,从而模拟机器人“关节”的电动机。
文档中有更多详细信息。
我们将创建3个实体:球形,平面(地球)和目标指针。 最后一个对象只有可视化形式且质量为零,因此它将不参与物体之间的物理交互:
定义模拟步骤的重力和时间。
pb.setGravity(0,0,-10) pb.setTimeStep(1./60)
为了防止球在开始模拟后立即掉落,我们平衡重力。
pb_force = 10 * PB_BallMass pb.applyExternalForce(pb_ballId, -1, [0,0,pb_force], [0,0,0], pb.LINK_FRAME)
一步
代理根据环境的当前状态选择操作,然后调用
步骤方法并接收新状态。
定义了两种作用类型:作用在球上的力的增加和减少。 受力限制是有限的。
更改作用在球上的力后,将
启动物理模拟的新步骤
pb.stepSimulation() ,并将以下参数返回给代理:
观察 -观察(环境状态)
奖励 -奖励完美动作
完成 -体验结束的标志
信息 -其他信息
作为环境状态,将返回3个值:到目标的距离,施加到球上的当前力以及球的速度。 这些值将归一化(0..1),因为确定这些值的环境参数可能会根据我们的需求而变化。
如果球接近目标(目标高度加上/减去可接受的滚动值
TARGET_DELTA ),则完美动作的奖励为1;在其他情况下,奖励为0。
如果球超出了区域(落到地面或高飞),则实验完成。 如果球到达球门,则实验也将结束,但仅在一定时间之后(实验的
STEPS_AFTER_TARGET步骤)。 因此,我们的代理人不仅受过训练以朝着目标前进,而且还受制于停止并接近目标。 假设您接近目标的奖励为1,那么完全成功的体验应获得的总奖励等于
STEPS_AFTER_TARGET 。
作为显示统计信息的附加信息,将返回实验内执行的步骤总数以及每秒执行的步骤数。
渲染
PyBullet有2个图像渲染选项-基于OpenGL的GPU渲染和基于TinyRenderer的CPU。 在我们的情况下,仅CPU实现是可能的。
为了获得模拟的当前帧,有必要确定
种类矩阵和
投影矩阵 ,然后从摄像机获取给定大小的
rgb图像。
camTargetPos = [0,0,5]
在每个实验结束时,都会根据收集的图像生成视频。
ani = animation.ArtistAnimation(plt.gcf(), render_imgs, interval=10, blit=True,repeat_delay=1000) display(HTML(ani.to_html5_video()))
代理人
GitHub
jaara用户代码被用作Agent的基础,是为Gym环境实施强化培训的简单易懂的示例。
该代理包含2个对象:
内存 -用于形成训练示例的存储器,
大脑本身就是他训练的神经网络。
经过训练的神经网络使用Keras库在TensorFlow上创建,该库最近已完全
包含在TensorFlow中。
神经网络具有简单的结构-3层,即 仅1个隐藏层。
第一层包含512个神经元,输入数量等于介质状态的参数数量(3个参数:距目标的距离,球的强度和速度)。 隐藏层的尺寸等于第一层-512个神经元,在输出处将其连接到输出层。 输出层的神经元数量与代理执行的动作数量相对应(2个动作:作用力的减小和增加)。
因此,系统状态被提供给网络输入,并且在输出处,我们对每个操作都有好处。
对于前两层,将
ReLU (整流线性单元)用作激活函数,最后一层-
线性函数 (输入值的总和很简单)。
作为误差的函数,
MSE (标准误差)作为一种优化算法
-RMSprop (均方根传播)。
model = Sequential() model.add(Dense(units=512, activation='relu', input_dim=3)) model.add(Dense(units=512, activation='relu')) model.add(Dense(units=2, activation='linear')) opt = RMSprop(lr=0.00025) model.compile(loss='mse', optimizer=opt)
在每个模拟步骤之后,Agent均以列表
(s,a,r,s_)的形式保存该步骤的结果:
s-先前的观察(环境状态)
-完成的动作
r-收到的已执行动作的奖励
s_-行动后的最终观察
之后,Agent从内存中接收前一段时间的随机示例集,并形成训练包(
批处理 )。
从存储器中选择的随机步长的初始状态
s被用作分组的输入值(
X )。
学习输出(
Y' )的实际值计算如下:在s的神经网络的输出(
Y )处,每个动作
Q(s)都有
Q函数的值。 代理从该集合中选择具有最高值
Q(s,a)= MAX(Q(s))的动作 ,完成该动作并获得奖励
r 。 所选动作
a的新
Q值将为
Q(s,a)= Q(s,a)+ DF * r ,其中
DF是折扣因子。 其余的输出值将保持不变。
STATE_CNT = 3 ACTION_CNT = 2 batchLen = 32
网络培训在形成的包装上进行
self.model.fit(x, y, batch_size=32, epochs=1, verbose=0)
实验完成后,会生成一个视频
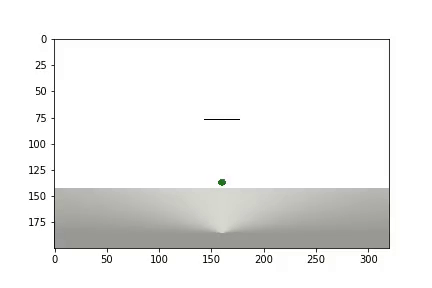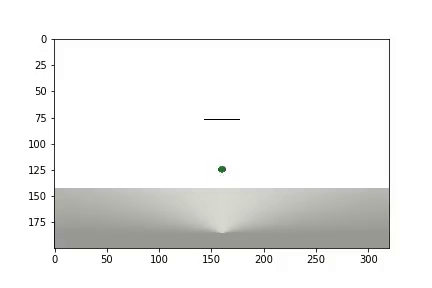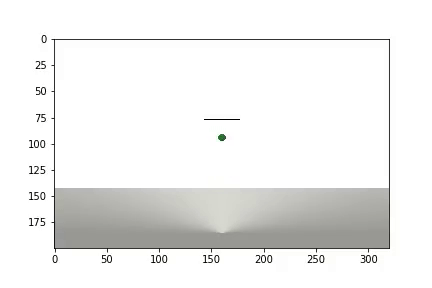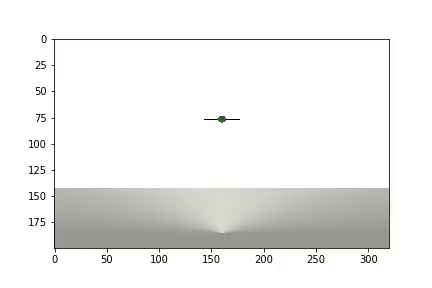
显示统计信息
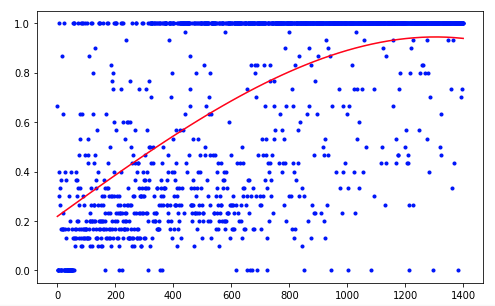
该代理需要进行1200次试验才能获得大约95%的结果(成功步骤的数量)。 到第50次实验时,特工已学会将球移至目标(失败的实验消失)。
为了改善结果,您可以尝试更改网络层的大小(LAYER_SIZE),折扣系数的参数(GAMMA)或选择随机操作的可能性的降低率(LAMBDA)。
我们的代理具有最简单的架构-DQN(深度Q网络)。 在如此简单的任务上,足以获得可接受的结果。
例如,使用DDQN(双DQN)体系结构应提供更流畅,更准确的培训。 RDQN网络(递归DQN)将能够跟踪环境随时间变化的模式,这将使摆脱球速参数成为可能,从而减少了网络输入参数的数量。
您还可以通过添加可变的球质量或其运动的倾斜角度来扩展我们的模拟。
但这是下一次。