在具有人工智能的应用程序中使用von Neumann架构效率低下。 什么会代替她?
使用现有架构解决机器学习(MO)和人工智能(AI)的问题已变得不切实际。 AI消耗的能量已经大大增加,CPU和GPU似乎越来越不适用于此工作。
参加几次专题讨论会的与会者都认为,进行重大更改的最佳机会是在没有继承特征的情况下出现的,而这些继承特征必须被拖延。 随着时间的推移,大多数系统都在逐步发展-即使确保安全进行,这种方案也无法提供最佳解决方案。 当出现新事物时,可以重新审视事物并选择比传统技术所提供的方向更好的方向。 这正是在最近一次会议上讨论的内容,该会议上研究了以下问题:互补金属氧化物半导体(
CMOS )结构是否是值得构建AI应用程序的最佳基础技术。
由IBM任命为纳米电子研究计划(NRI)的执行董事的Chen Chen为讨论奠定了基础。 “多年来,我们一直在研究新的现代技术,包括寻找CMOS的替代品,特别是因为其与功耗和缩放有关的问题。 这些年来,人们逐渐形成一种观点,即我们没有发现更好的东西来创建逻辑电路。 如今,许多研究人员都在关注AI,它确实提供了新的思维方式和新模式,并且拥有了新的技术产品。 新的AI设备是否有能力替代CMOS?”
今天的AI
MO和AI的大多数应用程序都使用von Neumann架构。 “它使用内存存储数据阵列,而CPU执行所有计算,”新华国立大学电气工程学教授马文·陈(Marvin Chen)解释说。 “大量数据正在总线上移动。 如今,GPU也经常用于深度训练,包括卷积神经网络。 主要问题之一是得出结论所必需的中间数据的出现。 移动数据(尤其是移动到芯片之外)会导致能量损失和延迟。 这是技术瓶颈。”
 用于AI的架构
用于AI的架构您今天需要的是结合数据处理和内存。 “内存计算的概念已经由计算机体系结构专家提出了很多年,” Chen说。 -SRAM和非易失性存储器有几种方案,他们试图使用和实现这种概念。 理想情况下,如果成功,则可以消除CPU和内存之间的数据移动,从而节省大量能源。 但这是理想的。”
但是就今天而言,我们没有计算在内。 “我们仍然拥有使用冯·诺依曼(von Neumann)架构的AI 1.0,因为在内存中实现处理的硅设备从未出现过,”他抱怨道。 钟。 “以任何方式使用3D TSV的唯一方法是在GPU中使用高速内存来解决带宽问题。” 但这仍然是精力和时间的瓶颈。”
存储器中是否将进行足够的数据处理以解决能量损失的问题? 台积电(Taiwan Semiconductor Manufacturing Company)助理总监肖恩·李(Sean Lee)说:“人脑包含1000亿个神经元和10个
15个突触。” “现在看看IBM TrueNorth。” TrueNorth是IBM在2014年开发的多核处理器。它具有4,096个内核,每个内核具有256个可编程人工神经元。 “假设我们要缩放它并重现大脑的大小。 差异为5个数量级。 但是,如果我们直接增加数量并乘以TrueNorth,消耗65兆瓦功率,那么对于一台消耗25瓦功率的人的大脑来说,我们得到的功率为65千瓦。 消费量必须减少几个数量级。”
Lee提供了另一种方式来想象这个机会。 “迄今为止,最高效的超级计算机是日本的Green500,每瓦功率发出17 Gflops,或以59 pJ发出1 flops。” Green500网站表示,在日本高级计算和通信中心(RIKEN)上安装的ZettaScaler-2.2系统在Linpack测试运行期间的测量值为18.4 Gflops / W,这需要858 TFlops。 “将此与
Landauer原理进行比较,根据该
原理 ,在室温下晶体管的最小开关能量约为2.75 zJ [10
-21 J]。 同样,差异是几个数量级。 59 pJ约为10
-11 ,而理论上的低点约为10
-21 。 我们有广阔的研究领域。”
将此类计算机与大脑进行比较是否公平? 普渡大学电气工程和计算机科学系名誉教授Kaushik Roy说:“在研究了近期深入培训的成功经验之后,我们将发现在大多数情况下,人和机器已经连续7年竞争。” “ 1997年,深蓝击败了卡斯帕罗夫,2011年IBM沃森赢得了游戏Jeopardy!,2016年Alpha Go击败了李·塞多拉。 这些是最大的成就。 但是要花多少钱呢? 这些机器消耗了200至300 kW。 人脑消耗约20瓦。 巨大的差距。 创新将来自何处?
在大多数应用程序中,MO和AI是大规模执行的最简单的计算。 “如果采用最简单的神经网络,它将执行加权求和,然后进行阈值运算,” Roy解释说。 -这可以在各种类型的矩阵中完成。 它可以是自旋电子学或电阻式存储器中的设备。 在这种情况下,输入电压和产生的电导率将与每个交叉点关联。 在输出端,得到的电压总和乘以电导率。 这是当前的。 然后,您可以使用执行阈值操作的类似设备。 可以将架构想象为将这些节点连接在一起以进行计算的一堆。”
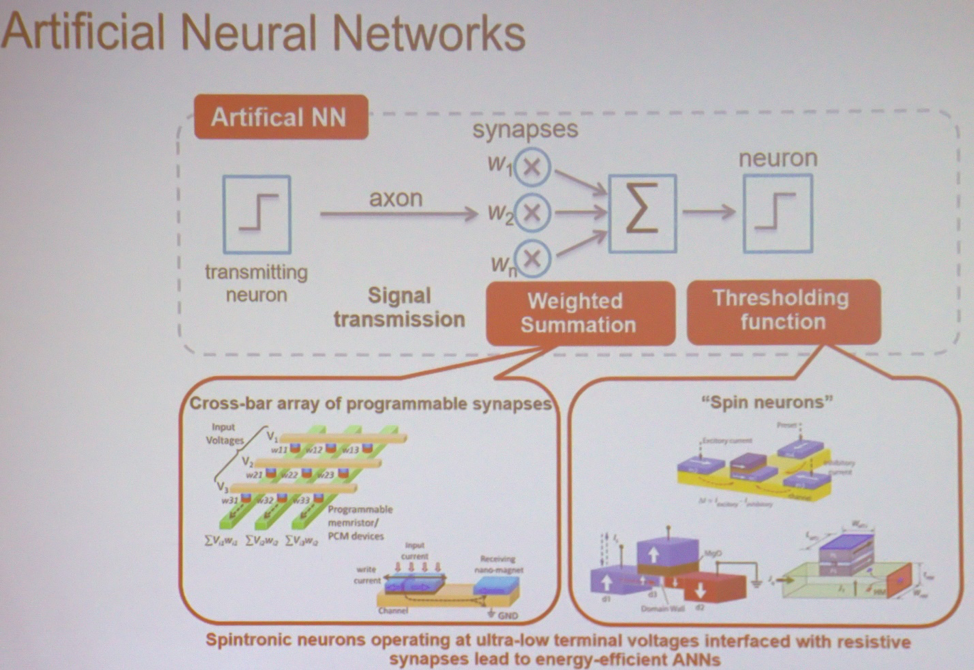 神经网络的主要组成部分
神经网络的主要组成部分新型内存
大多数潜在的体系结构与新兴类型的非易失性存储器相关。 “最重要的特征是什么?” “ Ass Jeffrey Barr,IBM Research的研究员。 “我会放置非易失性模拟电阻式存储器,例如具有相变的存储器,忆阻器等。 想法是,这些设备能够在一个周期内对神经网络的完全连接层进行所有乘法。 在处理器组上,这可能需要一百万个时钟周期,而在模拟设备中,这可以使用在数据位置工作的物理学来完成。 就时间和精力而言,有足够非常有趣的方面使这个想法发展成更多东西。”
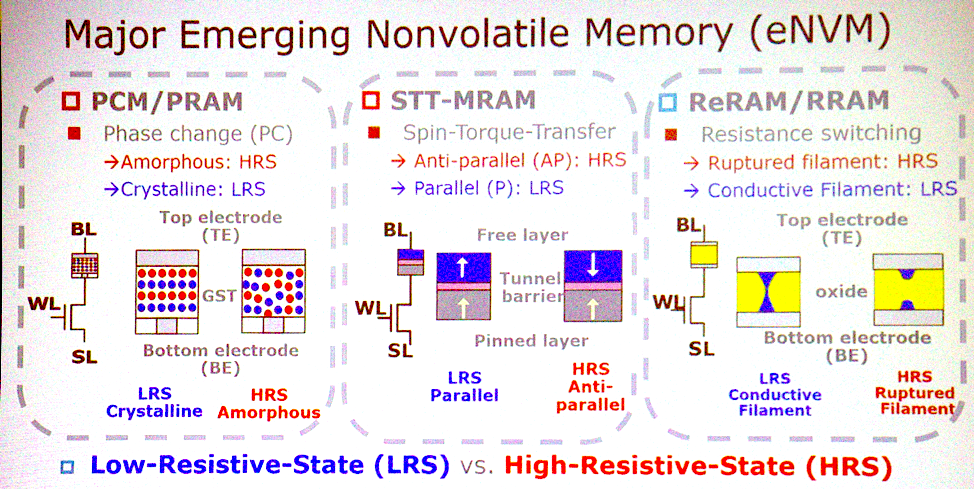 新内存技术
新内存技术陈对此表示赞同。 PCM,STT赢得了重大竞标。 这三种类型的内存是实现内存中计算的理想选择。 它们具有基本的逻辑运算能力。 有些物种存在可靠性问题,不能用于训练,但有可能得出结论。”
但是事实证明,没有必要切换到该存储器。 “人们正在谈论完全出于相同目的使用SRAM,” Lee补充说。 “他们使用SRAM进行模拟计算。” 唯一的缺点是SRAM太大-每位6或8个晶体管。 因此,在模拟计算中使用这些新技术并不是事实。”
向模拟计算的过渡还意味着不再需要计算的准确性。 他说:“人工智能专业,分类和预测。” “他做出的决定是无礼的。” 在准确性方面,我们可以放弃一些东西。 我们需要确定哪些计算可以抗错误。 然后可以应用某些技术来降低功耗或加快计算速度。 自2003年以来,概率CMOS一直在研究。 这包括降低电压,直到出现几个错误为止,但仍然可以容忍该错误的数量。 今天,人们已经在使用近似计算技术,例如量化。 您将拥有8位整数,而不是32位浮点数。 模拟计算机是已经提到的另一个功能。”
离开实验室
将技术从实验室转移到公众面前可能会充满挑战。 巴尔说:“有时您必须寻找替代方案。” -当二维闪存没有起飞时,三维闪存似乎不再是一项艰巨的任务。 如果我们继续改进现有技术,在这里获得双倍的特性,再到那里双倍,那么内存中的模拟计算将被放弃。 但是,如果以下改进变得微不足道,则模拟存储器将显得更具吸引力。 作为研究人员,我们必须为新的机会做好准备。”
经济通常会减慢发展速度,特别是在内存领域,但是Barr说在这种情况下不会发生这种情况。 “我们的优势之一是该产品不会与内存相关。 不会有什么小的改进。 这不是消费产品。 这是与GPU竞争的一件事。 它们的价格是放置在其上的DRAM成本的70倍,因此,这显然是非内存产品。 并且产品的成本与内存不会有太大差异。 听起来不错,但是当您做出价值数十亿美元的决策时,所有成本和产品开发计划都应该明确。 为了克服这一障碍,我们需要提供令人印象深刻的原型。”
CMOS更换
内存中数据处理可以提供令人印象深刻的好处,但是要实现该技术还需要更多。 除了CMOS以外,其他材料还能帮助吗? “从低功耗CMOS到隧道FET的过渡,我们正在谈论将功耗降低1至2倍,” Lee说。 -另一种可能性是三维集成电路。 它们使用TSV缩短了接线长度。 这减少了功耗和等待时间。 看一下数据中心,它们都去除了金属布线并连接了光纤。”
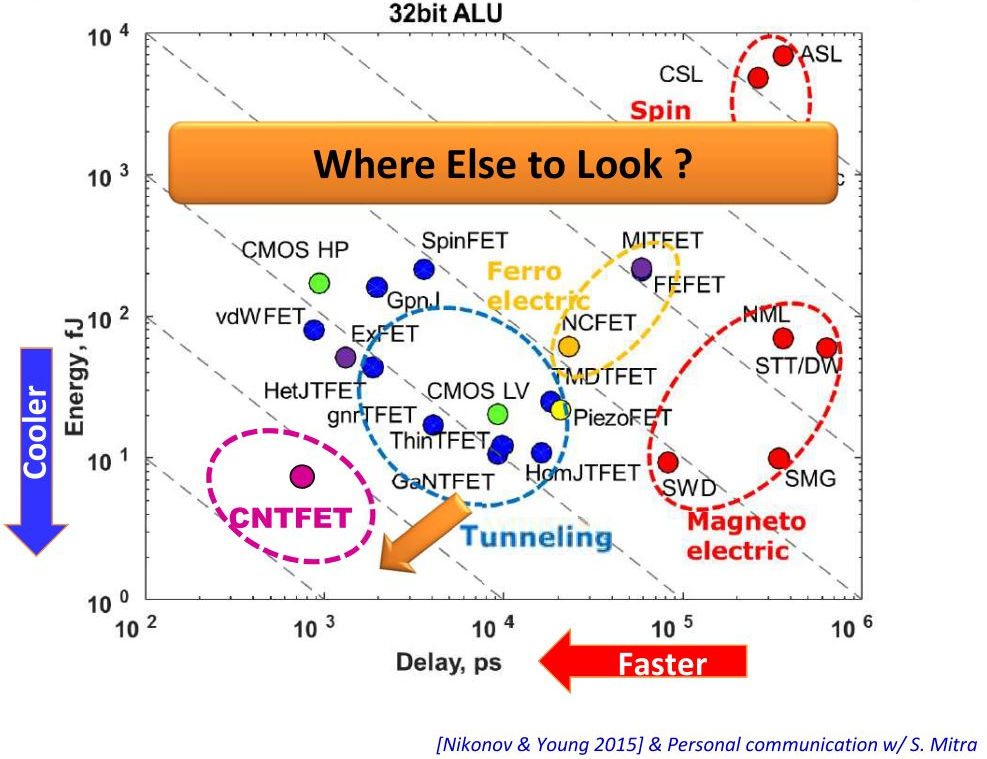 垂直-功耗,水平-设备延迟
垂直-功耗,水平-设备延迟尽管您在使用其他技术时可以获得一些好处,但可能不值得。 Roy说:“更换CMOS将会非常困难,但是所讨论的某些设备可以补充CMOS技术,以便在内存中执行计算。” -CMOS可以模拟形式(可能在8T单元中)支持内存中计算。 是否有可能创建一种具有比CMOS明显优势的体系结构? 如果一切都正确完成,那么CMOS将为我提供数千倍的能源效率。 但这需要时间。”
显然,CMOS不会替代。 巴尔总结道:“新技术不会拒绝旧技术,也不会在CMOS以外的任何基板上制造这种技术。”