
我们有两种灾难恢复方法:“拉伸”群集(主动-主动安装)和关闭了虚拟机(副本)的平台。 他们有几点可以保存快照。
要求有容灾能力,我们的许多客户确实需要它。 因此,我们开始制定这两种方案作为生产的一部分。
方法各有利弊,现在我将告诉您。
拉伸簇
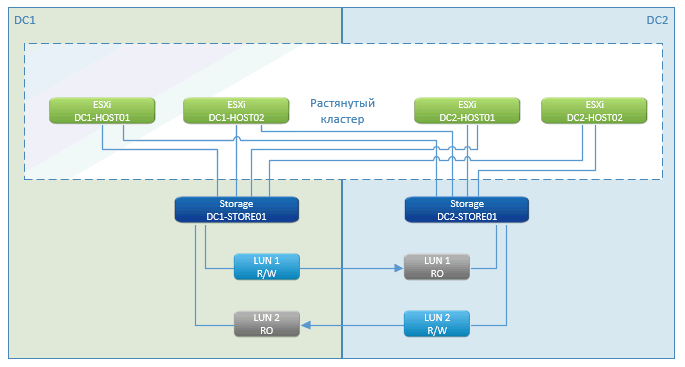
如您所见,这是一个标准的都市集群故事。 在专业人士中-停机时间几乎为零,仅在启动虚拟机时才暂停。 此功能有效-VMware高可用性(HA)。 她发现主机丢失,并立即重新启动远程站点上的VM。
立即从位于集群中的存储进行启动。
NetApp的营销功能是使用地理分布式群集进行存储。 其他制造商也有类似的名字。 本质上,这是经过深思熟虑的从一侧到另一侧的异步复制。 我们写入局域网中的一个节点,并通过专门的通信渠道与另一个节点进行同步。
万一其中一个存储系统发生故障,其余(在另一个站点)会将磁盘的路径提供给其余主机。 已死亡的虚拟机将在其上重新启动。 一切都会自动发生-数据中心崩溃,一切重新启动,存储正常运行,VMware正常运行。 客户端看到所有内容都闪烁并重新启动。
VM的唯一缓存可能会丢失。 但是,如果数据库将其丢弃,则时间损失为零。
如果我们在站点之间失去通信,则所有内容将继续在其位置工作,并且一旦恢复连接,它将开始同步。
缺点是价格高。 因为您实际上需要一个双SHD(此外,主站点上第一个SHD的磁盘在类型,速度和容量上都相似),除了作为备用磁盘之外,不能以某种方式使用它。 除了绑定到城域集群的存储外,还包括FC桥接器,FC网络等。
我们有两个DPC,它们之间是沿着两个光束的FC束(四个暗光学线路和DWDM)。 这是两块铁,分别为FC和以太网提供200 Gbps带宽。
DR的替代选择

有一个软件的名称直观易记-VMware vCloud Availability for Cloud-to-Cloud DR。
相对而言,这是一个用于在15分钟内一次在远程站点上创建相同VM的系统。 将用于以正确方式向云控制机制呈现所有这些内容的系统连接到电气磁带上。
也就是说,VMware Replication技术位于后端。 发生故障时,我们会在第二个站点上手动启动DR计划,它会自动停止尝试复制,然后在vCloud Director中注册VM,自定义IP地址(这样就不必将其更改为VM)并以必要的顺序启动VM。 在我们的解决方案中,无需更改地址,我们将网络扩展到两个数据中心。
机器一直在被复制,但不是整个数据中心,而是只有选定的是关键过程。 它会不时地复制一次,最小间隔为15分钟(这是理想的情况,因为一切都进行得很顺利,并且有专用的复制服务器,并且对VM的更改最少)。 实际上,您有一个半小时或一个小时前的副本。 如果出现问题,则丢失进入间隔的数据。 15分钟是收集新复制的代理的问题。 Veeam表示,这可能需要不到15分钟的时间,但实际上,如果不使用存储功能,这样做的时间也会更长。 我没有在工业机器上(没有经过测试)看到其他情况。
长期以来,NetApp与许多其他存储系统制造商一样,都具有SnapMirror技术,该技术可使您将复制工作从虚拟机管理程序转移到存储系统,VMware Replication可以使用它。
随着复制服务的运行,训练进行得很远。 但这很便宜。
为什么它仍然便宜-因为您可以在任何一侧(来自不同制造商,不同类别)使用任何存储,因此您无需事先分配大量磁盘。
无需分配一个较大的磁盘组,在该磁盘组中剪切卫星。 它仅在本地存储中占有一席之地,并在虚拟机中的记录可用的事实上被应用。 因此,如果将存储系统用于其他任务,则该位置将被最佳占用。 之所以使用它,是因为我们没有为所有客户提供这样的服务。
减号-您需要在VM级别配置复制,即控制所有内容均已正确配置,这是计算机,确保复制通过,并且没有错误。 为每个客户创建灾难恢复计划,进行测试。
在第一种情况下,有条件地,基础设施地几乎按扇区(更确切地说按对象)进行存储。 然后,由于与高级漏洞相关的某些软件原因,或由于可访问性问题,导致任务中断,一台机器可能中断。 这种情况发生的频率要比只服用少量维生素C的情况要多一些。
加号-DR存储几个点。 您可以回滚一些快照。
在来宾操作系统之外,您需要其他软件。
为了将所有必要的网络连接到Vcloud Director,我们需要管理员的工作。 通常,此版本中的所有网络连接均由我们的管理员负责。 对于云客户端,这意味着一个应用程序,这也需要时间。
还可以通过应用程序配置复制。 添加了VM-您需要发送一个需要复制它的请求。 它不会自动属于复制任务。 有必要注意管理员。
区别
结果,价格可能相差两倍以上。 复制将使磁盘空间成本增加两个或更多(两个完整副本+更改历史记录),再加上一些服务和预留的计算资源。 对于都市集群,空间成本将乘以2,但是空间本身的成本将高得多,此外,您还需要在远程站点上牢固地保留节点。 也就是说,计算资源必须乘以2,我们不能将其用于其他任何事情。
对于Metro群集,我们只能使用相同类型的磁盘,以便有完整的镜像。 如果在主数据中心上某些驱动器速度很快,而某些驱动器速度很慢,每分钟旋转一万转,则需要相同的配置。 在副本的情况下,备份站点上的磁盘可能会变慢,由于存储的原因,磁盘价格会更低。 但是当切换到备用时,它的性能会降低。 也就是说,如果将某些内容存储在主群集中的SSD上,并复制到常规磁盘上,则存储成本将大大降低,但会降低备用基础架构的速度。
现在,我们正在选择早期版本中将包含的内容,因此我们想咨询一下:您能否简要介绍一下如何组织灾难恢复站点以及您希望它们做什么?