
我能够以学生身份收集工作站。 从逻辑上讲,我更喜欢AMD计算解决方案。 因为它 便宜的 在价格/质量方面有利可图。 我花了很长时间才拿起这些组件,最后我用一套FX-8320和RX-460 2GB装了40k。 起初,这个工具包似乎很完美! 我和我的室友略微挖掘了Monero,我的设备显示650h / s,而i5-85xx和Nvidia 1050Ti的设备显示为550h / s。 没错,从我房间里的房间看,晚上有点热,但这是在我为CPU购买塔式散热器时决定的。
故事结束了
直到我对计算机视觉领域的机器学习感兴趣之前,一切都像童话故事一样。 更精确地讲-直到我必须使用分辨率超过100x100px的输入图像为止(到目前为止,我的8核FX轻而易举地应对了)。 第一个困难是确定情绪的任务。 4个ResNet层,在训练集中输入图像100x100和3000个图像。 现在-9小时的CPU训练150个时代。
当然,由于这种延迟,迭代开发过程会受到影响。 在工作中,我们使用了Nvidia 1060 6GB并进行了类似结构的培训(尽管在那里对回归进行了培训以定位对象),它飞行了15-20分钟-8秒,飞行了3.5k图像。 当您的鼻子底下形成对比时,呼吸会变得更加困难。
好吧,猜猜我这一切之后的第一步吗? 是的,我和邻居一起讨价还价1050Ti。 关于CUDA对他无用的争论,并提出交换我的卡的附加费用。 但是都是徒劳的。 现在,我将RX 460发布到Avito上,并在Citylink和TechnoPoint网站上查看珍贵的1050Ti。 即使成功售出该卡,我也必须另找一万(我是学生,尽管是工作中的)。
谷歌
好吧 我要去谷歌谷歌如何在Tensorflow下使用Radeon。 知道这是一项艰巨的任务,所以我并不特别希望找到任何明智的选择。 在Ubuntu下收集,无论它是否启动,都会遇到麻烦-从论坛上抢夺些短语。
所以我走了另一条路-我不是用Google Tensorflow AMD Radeon,而是用Keras AMD Radeon。 它立即将我引到PlaidML的页面。 我在15分钟内启动了它 (尽管我不得不将Keras降级为2.0.5)并设置了网络以进行学习。 第一次观察-时代是35秒而不是200秒。
爬上探索
PlaidML的作者是vertex.ai ,它是英特尔项目组(!)的一部分。 开发目标是最大程度地跨平台。 当然,这增加了产品的信心。 他们的文章说,由于“全面优化”,PlaidML与Tensorflow 1.3 + cuDNN 6竞争。
但是,我们继续。 以下文章在某种程度上向我们揭示了库的内部结构。 与所有其他框架的主要区别在于计算内核的自动生成(在Tensorflow表示法中,“核心”是在图中执行特定操作的完整过程)。 对于在PlaidML中自动生成内核,所有张量,常量,步长,卷积大小和边界值的确切尺寸(以后必须使用这些尺寸)非常重要。 例如,有人认为有效内核的进一步创建对于1和32批处理大小或3x3和7x7大小的卷积是不同的。 有了这些数据,框架本身将生成最有效的方式来并行化和执行具有特定特性的特定设备的所有操作。 如果您看一下Tensorflow,则在创建新操作时,我们也需要为其实现内核-对于单线程,多线程或与CUDA兼容的内核,实现方式大不相同 。 即 PlaidML显然更加灵活。
我们走得更远。 该实现以自写语言Tile编写。 该语言具有以下主要优点-语法接近于数学符号(但要疯了!):
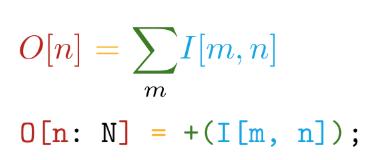
并自动区分所有已声明的操作。 例如,在TensorFlow中,创建新的自定义操作时,强烈建议您编写一个函数来计算梯度。 因此,在使用Tile语言创建自己的操作时,我们只需要说出要计算的内容,而无需考虑如何针对硬件设备考虑这一点。
此外,还对DRAM和GPU中L1高速缓存的类似物进行了工作优化。 调用原理图设备:
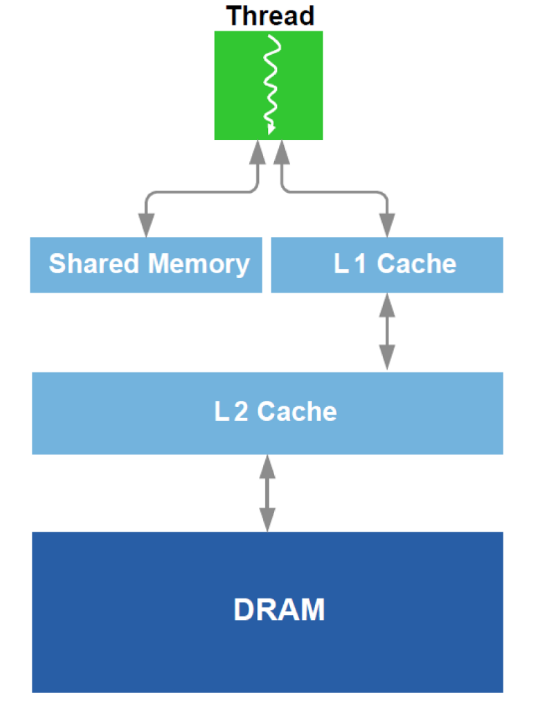
为了进行优化,使用了有关设备的所有可用数据-缓存大小,缓存线宽,DRAM带宽等。 主要方法是从DRAM同时读取足够大的块(避免寻址到不同区域的尝试),并实现多次使用加载到高速缓存中的数据(避免多次重载相同数据的尝试)。
所有优化都在训练的第一个时代进行,同时大大增加了第一次训练的时间:
另外,值得注意的是,此框架与OpenCL绑定。 OpenCL的主要优点是它是异构系统的标准,没有什么可以阻止您在CPU上运行内核 。 是的,这是跨平台PlaidML的主要秘密之一。
结论
当然,RX 460的培训仍然比1060慢5-6倍,但是您可以比较显卡的价格类别! 然后我得到了RX 580 8gb(他们借给了我!),运行该时代所需的时间减少到20秒,几乎是可比的。
vertex.ai博客具有诚实的图表(越多越好):
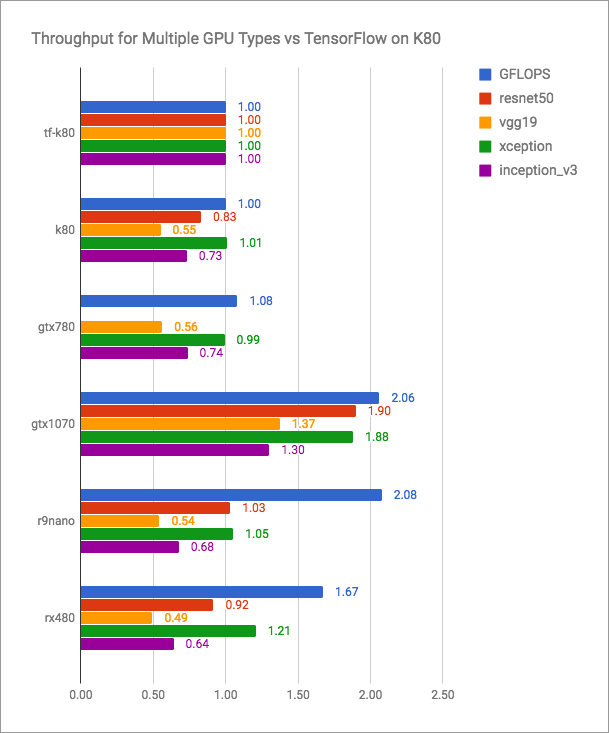
可以看出,PlaidML与Tensorflow + CUDA相比具有竞争优势,但是对于当前版本而言肯定不会更快。 但是PlaidML开发人员可能不打算参加这样的公开战。 他们的目标是通用性,跨平台。
我将在这里留下一个不太可比较的表格,其中列出了我的效果指标:
| 计算装置 | 时代的运行时间(第16批),秒 |
|---|
| AMD FX-8320 TF | 200 |
| RX 460 2GB格子 | 35 |
| RX 580 8 GB格子 | 20 |
| 1060 6GB TF | 8 |
| 1060 6GB格子 | 10 |
| 英特尔i7-2600 TF | 185 |
| 英特尔i7-2600格子 | 240 |
| GT 640格子 | 46 |
最新的vertex.ai博客文章和对该存储库的最新编辑日期为2018年5月。 似乎,如果该工具的开发人员没有停止发布新版本,并且越来越多的人被Nvidia冒犯,他们对PlaidML熟悉,那么他们会更频繁地谈论vertex.ai。
发现你的radeons!