
因此,KDD的第五天,即最后一天结束了。 我设法听到了来自Facebook和Google AI的一些有趣的报道,记住了足球战术并产生了一些化学物质。 关于这个,不仅-在削减。 一年后在阿拉斯加首都安克雷奇见!
关于小数据问题的大数据学习
这名
中国教授的早晨报告很难。 演讲者在准备过程中显然很轻松,经常误入歧途,开始跳过幻灯片,而不是终生讲话,而是试图给困倦的大脑装满数学。
故事的总体轮廓围绕着这样的想法,即总是存在大量数据。 例如,有一条长长的尾巴,其中有许多不同的示例。 存在具有大量类的数据集,尽管它们本身很大,但每个类只有很少的记录。 作为此类数据集的示例,他列举了
Omniglot-平均50个字母,1623个类别和每个类别20张图片的手写字符。 但是实际上,从这个角度来看,当我们有很多用户并且每个人的评分都不高时,您还可以考虑推荐任务的数据集。
在这种情况下,如何使ML的生活更轻松? 首先。 尝试将学科领域的知识带入其中。 这可以以多种形式完成:这是功能设计,特定的规范化以及网络体系结构的完善。 另一个常见的解决方案是转移学习,我认为几乎所有从事图片工作的人都始于从其数据中升级一些ImageNet。 在Omniglot的情况下,转移的自然捐助者将是
MNIST 。
转移的一种形式可以是
多任务学习 ,关于KDD的讨论已经有好几次了。 MTL的发展可以被认为是
元学习方法-通过在各种任务的样本上训练算法,我们不仅可以学习参数,还可以学习超参数(当然,只有在我们的过程可区分的情况下)。
继续执行多任务主题,我们可以得出终身持续学习的概念,机器人技术的例子可以最清楚地说明这一概念。 机器人必须能够解决不同的问题,并且在学习新任务时要利用以前的经验。 但是您可以在Omniglot的示例中考虑这种方法:在学习了其中一个角色之后,您可以利用积累的经验继续学习下一个角色。 的确,当算法开始忘记以前学到的东西时,就会遇到一条危险的
灾难性遗忘问题。
此外,发言人谈到了他在这个方向上的几项工作。
神经过程 (类似于神经网络的高斯过程)和
分布式学习与转移学习 (针对当我们不以先前训练的模型为基础,而是以多任务模式训练我们的情况下的转移学习的优化)。
图片和文字
今天,我决定在早上阅读有关文本,图像和视频的应用报告。
语料库转换服务
出版物的发布速度非常快,因此很难使用,尤其是考虑到几乎所有搜索都在文本中进行的事实。 IBM
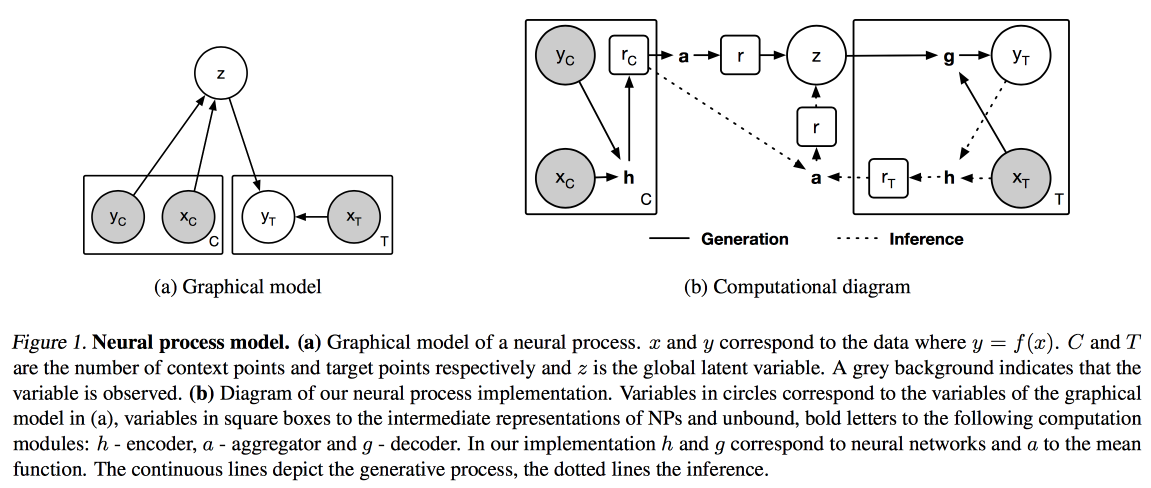
提供其标记科学知识3.0机箱的服务。 主要工作流程如下所示:
- Parsim PDF,识别图片中的文本。
- 我们检查是否存在这种形式的文本的模型,如果存在,则使用它进行语义提取。
- 如果没有模型,我们将发送注释并进行训练。
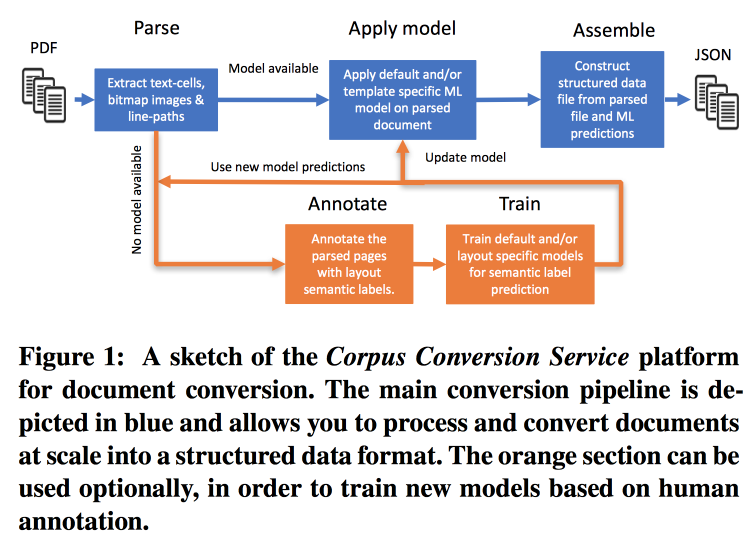
为了训练模型,我们从按结构聚类开始。 在使用众包的集群中,我们布置了多个页面。 事实证明,对200-300个文档进行标记培训时,其准确度> 98%。 标记中存在严重的类不平衡(几乎所有内容都标记为文本),因此您需要查看所有类和混淆矩阵的准确性。
模型具有层次结构。 例如,一个模型识别一个表,另一个模型切成行/列/标题(是的,一个表可以嵌套在一个表中)。 作为模型,使用卷积网络。
为此,他们在Docker上使用Kubernetes组装了一条传送带,并准备以合理的费用下载您的文本语料库。 它们不仅可以使用文本PDF,还可以使用扫描;它们支持东方语言。 除了仅提取文本外,他们还致力于提取知识图,并承诺在下一个KDD上讲详细信息。
搜索广告中通过生成对抗网络进行的罕见查询扩展
搜索引擎从广告中获利最多,根据用户的需求显示广告。 但是这种比较并不总是很明显。 例如,应机票要求,显示廉价巴士票广告不是很正确,但是expedia效果很好,但是您无法通过关键字来理解。 机器学习模型可能会有所帮助,但不适用于罕见查询。
为了解决这个问题,为了扩展搜索查询,
我们将根据序列到序列模型
训练条件GAN。 我们使用循环网络(2层GRU)作为体系结构。 我们正在从GAN修改min-max,以使其针对添加点击广告的关键字为目标。
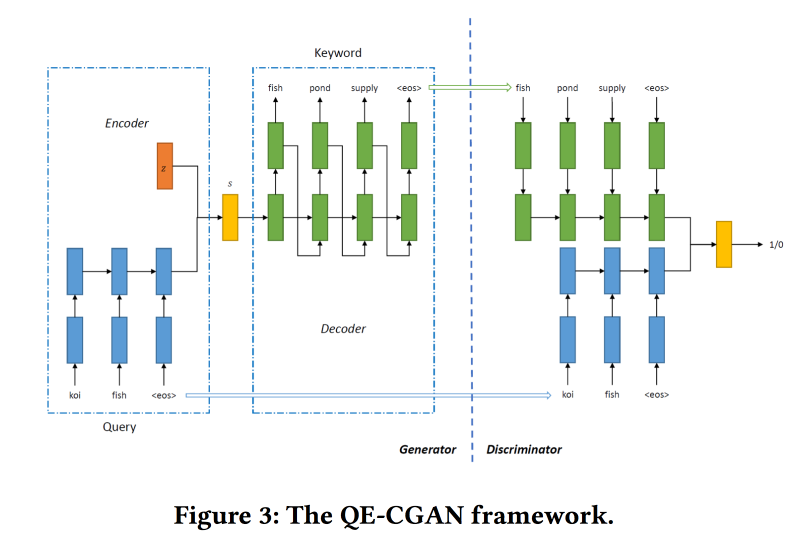
用于训练1400万个查询和400万个广告关键字的数据集。 提出的模型可以很好地解决请求的长尾问题。 但是在头脑中,性能并不高。
深度视频协作深度学习
这项工作是由来自Google AI的家伙介绍的。 他们希望建立良好的视频嵌入,然后在类似的视频,推荐,自动注释等中使用它们。 其工作方式如下:
- 从视频中,我们对帧进行采样-图片和一段音轨。
- 我们从Inception先前学到的图片中提取特征。
- 我们对音频片段执行相同的操作(未显示特定的网络体系结构)。 在获得的标志上,我们将完全连接的网格悬挂在框架的牵引下。 我们通过L2进行归一化。
- 接下来,有趣的一点是-我们正在努力确保类似视频在协作相似性方面很接近。 为此,我们在训练中使用三元组损失(我们提取了一个对象,对其进行了相似和相异的采样,确保相异的嵌入物比相似物的嵌入物离原始物更远)。 不要忘记,您需要使用否定挖掘。

它们用于类似视频的冷启动,但是存在两个问题:通过视觉相似性,他们可以找到另一种语言的视频或其他主题的视频(特别是与“董事会和讲师”视频格式有关)。 建议您使用有关视频的其他元信息。
这些建议存在问题:您需要匹配浏览历史记录和YouTube上的50亿个视频。 为了加快工作速度,我们为用户计算了观看视频的平均嵌入向量。 检查了
movielens ,从YouTube抽出预告片进行分析。 他们表明,对于评分较少的用户,效果更好。
在视频注释问题中,使用
了专家混合方法:他们在logreg上进行训练,以嵌入每种可能的注释。 检查了
Youtube-8并显示了很好的结果。
AMiner中的名称歧义消除:集群,维护和人为循环
AMiner-学院的图表,提供各种文学作品服务。 问题之一:作者和实体的名称冲突。 提供了一种具有某种形式的主动学习的自动算法作为解决方案。
该过程包括三个阶段:使用文本搜索,我们收集候选项(与作者姓名相似的文档),聚类(自动确定聚类数量)和构建配置文件。

要考虑聚类中的相似性,您需要某种表示形式(嵌入)。 可以使用全局模型(在整个图形中)或局部模型(对于那些采样的候选人)获得。 全局捕获模式可以转移到新文档中,而本地捕获则可以考虑到各个特征-我们将结合起来。 为了获得全局嵌入,他们还使用了经过三重损失训练的暹罗网络,而对于本地网络则使用了图自动编码器(为节省空间,我在本文中保留了图片)。
最痛苦的问题是我有多少个集群?
X均值方法无法扩展到大量聚类; RNN用于预测其数量:从标记集采样K个聚类,然后从这些聚类中抽取N个示例。 他们训练网络以揭示群集的初始数量。

数据足够迅速地到达,每月50万个,但是运行整个模型需要数周的时间。 为了进行快速初始化,他们使用候选文本的选择进行文本搜索,并使用IPN进行全局嵌入。 重要的一点:在学习过程中包括标记出应该和不应该在集群中什么的人。 根据此数据,可以对模型进行重新训练。
Rosetta:用于图像中文本检测和识别的大型系统
FB的家伙们
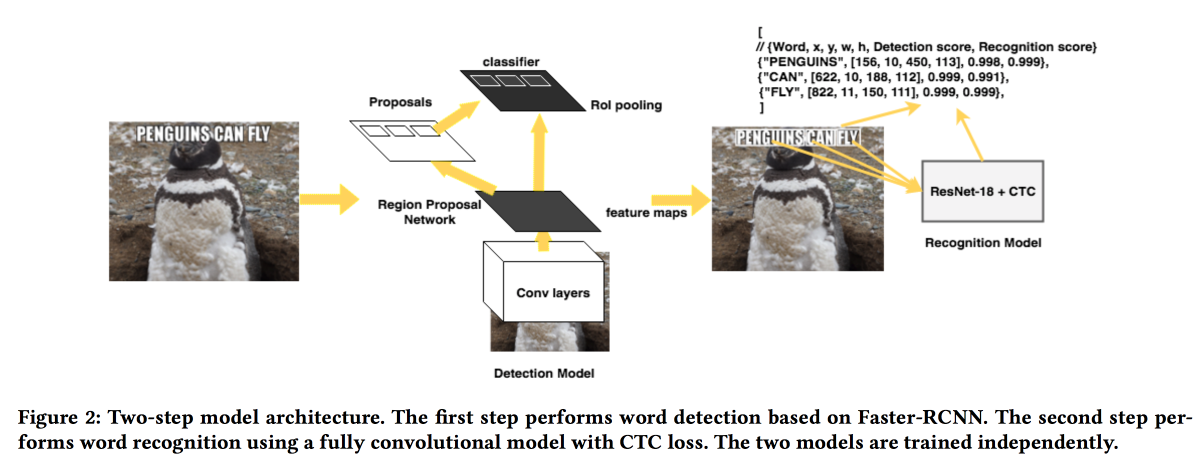
将展示他们从图片中提取文本的解决方案。 该模型分两个阶段工作:第一个网络确定文本,第二个网络识别文本。
Faster-RCNN用作检测器,用
SuffleNet代替ResNet以加快工作。 为了获得认可,他们使用了ResNet18并使用
CTC损失进行了培训。
为了提高收敛性,我们使用了一些技巧:
- 在训练过程中,检测器的结果会引入很小的噪音。
- 文本水平拉伸了20%。
- 二手课程学习-逐步复杂的示例(按字符数)。
自然科学
会议的最后一个内容部分专门讨论“自然科学”。 一点化学,足球等等。
在线控制实验的错误发现率控制的异构处理效果检测
关于A / B测试的分析
非常有趣的工作 。 大多数分析系统的问题在于,它们只能查看平均效果,而实际上,大多数用户通常会对更改做出积极和消极的反应,如果您了解该功能的开发者和用户,则可以实现更多效果不行

您可以预先将用户划分为同类群组并评估他们的效果,但是随着同类群组数量的增加,误报的数量也会增加(您可以尝试使用
Bonferoni方法来减少它们,但这太保守了)。 此外,您需要提前了解同类群组。 伙计们建议使用几种方法的组合:将异类效应检测机制(HTE)与假阳性过滤方法结合起来。
为了检测异类效应,将
x=0/1 0/1的矩阵(无论是否在组中)并将该效应转换为矩阵
(x — p)/p(1-p)而不是
0/1 ,其中
p是包含在其中的概率测试。 接下来,教导了用于预测
x的影响的模型(线性或套索回归)。 结果与预测有显着差异的那些用户是可以分离为“异构”效应的候选者。
接下来,我们尝试了两种用于误报过滤器的方法:
Benjamini-Hochberg和
Knockoffs 。 第一个更容易实现,但是第二个更灵活并且显示了更多有趣的结果。
优胜者的诅咒:在线控制实验中功能总效果的偏差估计
AirBnB的家伙们谈到了他们如何改进实验分析系统。 主要的问题是,当使用大量偏差进行实验时,这项工作会考虑选择偏差-我们选择
观察结果最佳的
实验 ,但这意味着我们将更多地选择观察结果相对于真实结果过高的实验。
结果,当组合实验时,最终效果小于实验效果的总和。 但是,知道了这种偏差后,您可以尝试使用统计仪器进行评估和减去(假设实际效果和观察到的效果之间的差异呈正态分布)。 简而言之,是这样的:

而且,如果添加
bootstrap ,甚至可以建立置信区间以对效果进行无偏估计。
时空足球比赛数据中策略的自动发现
关于公开足球队战术的
有趣工作 。 比赛数据以动作序列的形式提供(通过/触摸/命中等),每场比赛约有2000个动作。 组合连续(坐标/时间)和离散(玩家)属性。 使用主题区域的知识来扩展数据很重要(例如,增加玩家的角色和传球的类型),但并非总能奏效。 另外,不同类型的用户对不同类型的模式也很感兴趣:教练-成功,前锋-防守,记者-独特。
提出的方法如下:
- 将流程分为不同阶段,以实现团队之间球的过渡。
- 使用动态时间扭曲作为距离的聚类阶段。 如何确定簇的数量,不告诉。
- 我们按目的对集群进行排序(我们正在为他们寻找策略)。
- 最小化集群内部的模式(顺序模式挖掘CM-SPADE ),我们根据字段分段(左/右后翼,中点,罚点)抛弃坐标。
- 再次排列模式。
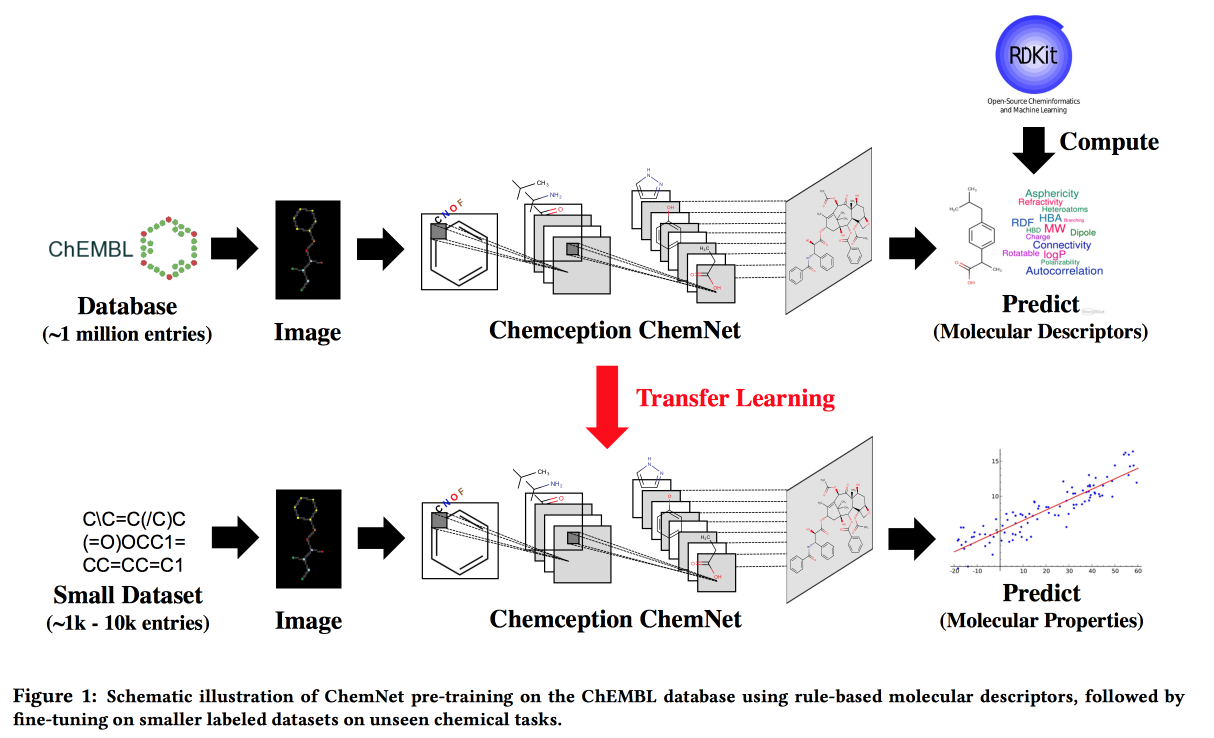
使用基于规则的标签进行弱监督学习:可转移化学性质P的ChemNet
适用于没有大数据但有层次规则的理论模型的情况。 利用理论,我们建立了一个“专家”神经网络。 适用于开发具有所需特性的化合物的任务。
我想通过类比图片来获得一个网络,其中的层将对应于不同的抽象级别:原子/功能团/片段/分子。 过去,有一些方法可以处理大型的标记数据集,例如SMILE2Vect:使用
SMILE将公式转换为文本,然后应用构建文本嵌入的技术。
但是,如果没有大的标记数据集怎么办? 我们使用
RDKit教
ChemNet以实现其可以预测的目标,然后我们进行转移学习来解决问题。 我们证明了我们可以与基于标签数据训练的模型竞争。 您可以分层次学习,这意味着要实现目标-按抽象级别分解层次。
PrePeP-一种鉴定和鉴定泛分析干扰化合物的工具
我们开发药物 ,使用数据科学来选择候选人。 有些分子会与许多物质发生反应。 它们不能用作药物,但通常会在测试的初始阶段弹出。 这些是我们将要过滤的
疼痛分子。
困难在于:数据出尽而傲慢(10.7万),类别不平衡(正数为0.5%),化学家想得到一个解释模型。 将来自分子的图结构(
gSpan )和化学指纹的数据结合起来。 他们通过袋装负面的欠采样,教导树木,以多数表决汇总的预测来平衡自己。