 为了使监视有用,我们必须解决可能出现的问题的不同情况,并设计仪表板和触发器,使它们能够立即了解事件的原因。
为了使监视有用,我们必须解决可能出现的问题的不同情况,并设计仪表板和触发器,使它们能够立即了解事件的原因。
在某些情况下,我们非常了解基础结构的这一部分或该部分的工作方式,然后预先知道哪些指标将很有用。 有时我们会删除几乎所有可能的度量标准,并提供最大程度的详细信息,然后查看它们上某些可见的问题。
今天,我们将研究预写日志(WAL)postgres如何膨胀以及为什么膨胀。 像往常一样-现实生活中的图片示例。
PostgreSQL中的一些WAL理论
数据库中的任何更改都首先记录在WAL中,只有在更改缓冲区高速缓存中的页面中的数据并将其标记为“脏”之后,才将其保存到磁盘中。 此外, CHECKPOINT进程会定期启动,这会将所有脏页保存到磁盘,并保存WAL段号,在此之前,所有更改的页均已写入磁盘。
如果由于某种原因突然使PostgreSQL崩溃并重新开始,则在恢复过程中将播放最后一个检查点的所有WAL段。
在检查点之前的WAL段对于我们在崩溃后的数据库恢复中将不再有用,但是在postgres中,WAL也参与复制过程,并且还可以为即时恢复-PITR配置所有段的备份。
一位经验丰富的工程师可能已经了解了一切,以及它们在现实生活中是如何破裂的:)
让我们看一下图表!
沃尔膨胀#1
我们针对每个找到的postgres实例的监视代理使用wal计算磁盘上目录的路径,并删除文件的总大小和数量(段):
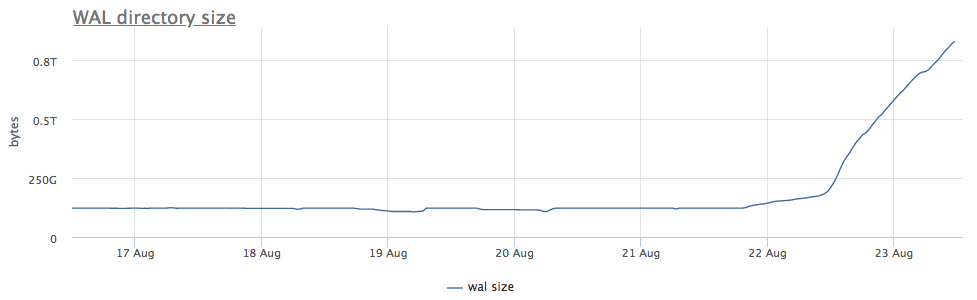
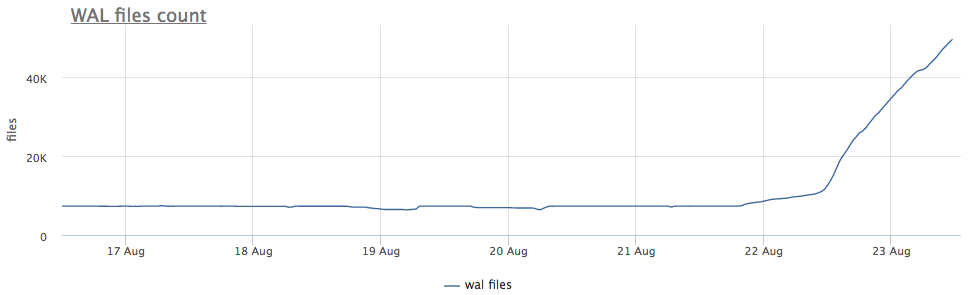
首先,我们看一下运行CHECKPOINT多久了。
我们从pg_stat_bgwriter获取指标:
- checkpoints_timed-在距最后一个检查点的时间超过pg_settings.checkpoint_timeout的情况下发生的检查点启动计数器
- checkpoints_req-通过从最后一个检查点开始超出沃尔玛大小的条件来开始检查点的计数器
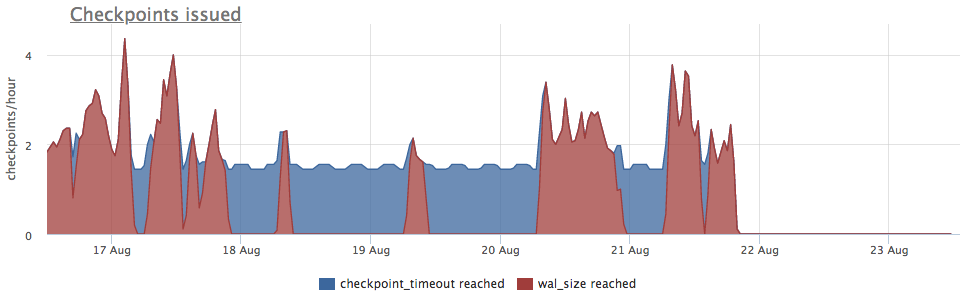
我们看到检查点已经很长时间没有启动了。 在这种情况下,不可能直接理解不启动该过程的原因(但是这当然很酷),但是我们知道在postgres中,由于长时间的交易会产生很多问题!
我们检查:

进一步明确该怎么做:
- 取消交易
- 处理漫长的原因
- 等待,但是请检查是否有足够的空间
另一个要点: 在连接到该服务器的副本上,wal也肿了 !
WAL存档器
我偶尔提醒您:复制不是备份!
良好的备份应该可以让您在任何给定的时间进行恢复。 例如,如果某人“意外”执行了
DELETE FROM very_important_tbl;
然后,我们应该能够将数据库还原到此事务之前的状态。 这称为PITR(时间点恢复),是在postgresql中实现的,它具有数据库的定期完整备份+在转储后保存所有WAL段。
archive_command设置负责备份wal,postgres只是启动您指定的命令,如果它完成而没有错误,则认为该段已成功复制。 如果发生错误,它将尝试直到胜利,该段将位于磁盘上。
好了,作为一个例子-破碎的沃尔玛图形:
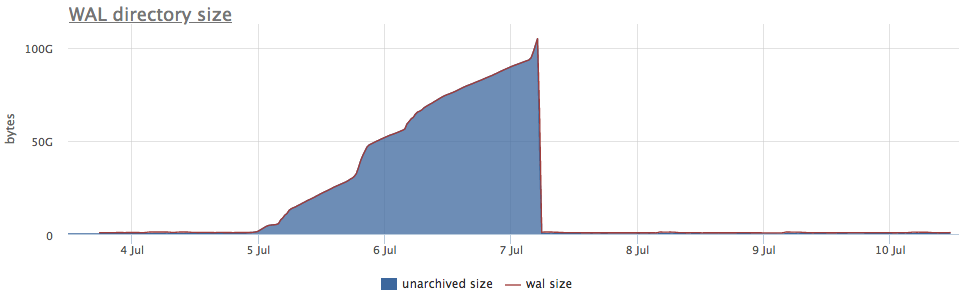
在这里,除了所有wal段的大小之外,还有一个未归档的大小 -这是尚未被成功保存的段的大小。
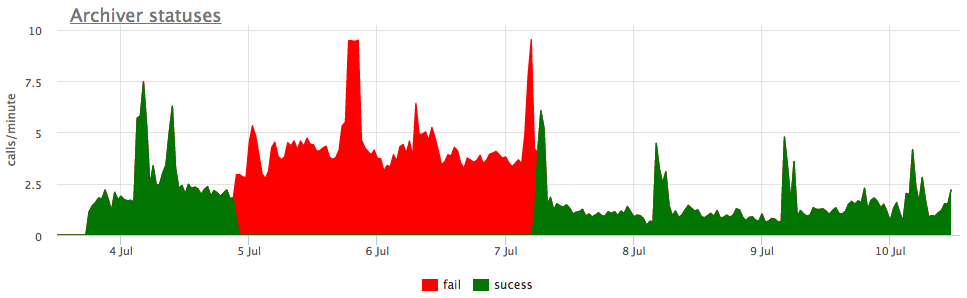
我们根据pg_stat_archiver的计数器来考虑状态。 对于文件数,我们对所有客户端进行了自动触发,因为它经常崩溃,尤其是当某些云存储用作目标时(例如,S3)。
复制滞后
正在进行的流复制工作是通过在副本上传输和播放wal进行的。 如果由于某种原因副本在后面并且没有丢失一定数量的段,则向导将为其存储pg_settings.wal_keep_segments段。 如果副本在较大数量的段上落后,它将不再能够连接到主副本(必须重新浇注)。
为了保证保留任何所需数量的段,复制插槽的功能出现在9.4中,稍后将对此进行讨论。
复制插槽
如果使用复制插槽配置了复制,并且至少有一个成功的副本连接到该插槽,则如果副本消失,则postgres将存储所有新的wal段,直到该位置用完为止。
也就是说,遗忘的复制插槽会导致沃尔玛膨胀。 但是幸运的是,我们可以通过pg_replication_slots监视插槽的状态。
这是一个实时示例的外观:
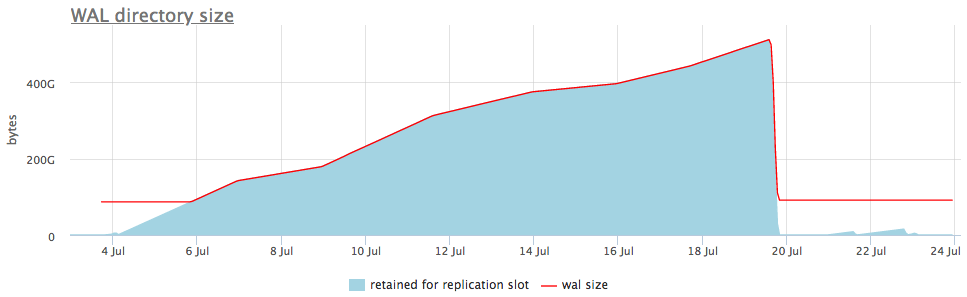

在上方的图形中,在沃尔码尺寸旁边,我们始终显示一个槽,该槽具有最大数量的累积段,但也有一个详细的图形将显示哪个槽膨胀了。
一旦了解了哪种插槽正在收集数据,就可以修复与其关联的副本,也可以简单地删除它。
我列举了沃尔玛肿胀的最常见情况,但我敢肯定还有其他情况(有时也会发现postgres中的错误)。 因此,在磁盘空间用完并且数据库将停止处理请求之前,监视wal的大小并响应问题非常重要。
我们的监控服务已经知道如何收集所有这些信息,正确可视化并发出警报。 对于云不适合的用户,我们还有一个本地交付选项。