
现在,每个人都在谈论人工智能及其在公司各个领域的应用。 但是,在某些地区,自远古时代起,一种类型的模型就占主导地位,即所谓的“白盒”-Logistic回归。 这样的领域之一就是银行信用评分。
这有几个原因:
- 可以很容易地解释回归系数,这与诸如boosting的黑匣子不同,它可以包含500多个变量
- 由于难以解释模型,因此管理层仍然不信任机器学习
- 监管机构对模型的可解释性有未成文的要求:例如,在任何时候,中央银行都可能要求作出解释-为什么拒绝对借款人的贷款
- 公司使用外部数据挖掘程序(例如,快速矿机,SAS Enterprise Miner,STATISTICA或任何其他程序包),使您可以快速学习如何构建模型,甚至不需要编程技能
这些原因使得在某些领域几乎不可能使用复杂的机器学习模型,因此重要的是要能够从简单的逻辑回归中“压缩最大”,这很容易解释和解释。
在本文中,我们将讨论在建立评分时,我们如何放弃外部数据挖掘程序包,而以Python形式支持开放源代码解决方案,如何多次提高开发速度,并改善所有模型的质量。
计分程序
在回归上建立评分模型的经典过程如下所示:
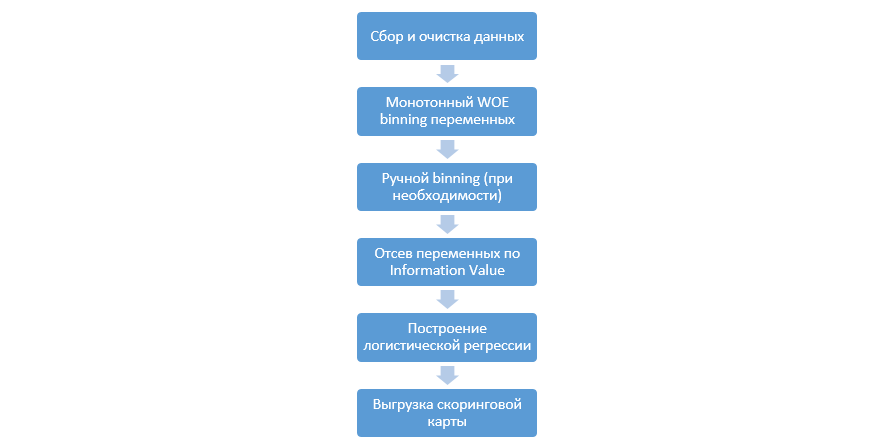
各个公司可能会有所不同,但是主要阶段保持不变。 我们始终需要对变量进行装箱(与机器学习范例相反,在大多数情况下,机器学习范例仅需要分类编码),通过信息值(IV)对其进行筛选,并手动上载所有系数和bin,以便随后集成到DSL中。
这种构建计分卡的方法在90年代效果很好,但是经典数据挖掘程序包的技术已经过时了,并且不允许使用新技术,例如回归中的L2正则化,这可以显着提高模型的质量。
在某一时刻,作为一项研究,我们决定重现分析人员在建立评分时所执行的所有步骤,并向他们补充数据科学家的知识,并尽可能使整个过程自动化。
Python增强
作为开发工具,我们选择Python是因为它的简单性和良好的库,并开始按顺序进行所有步骤。
第一步是收集数据并生成变量-此阶段是分析师工作的重要组成部分。
在Python中,您可以使用pymysql从数据库加载收集的数据。
从数据库下载的代码def con(): conn = pymysql.connect( host='10.100.10.100', port=3306, user='******* ', password='*****', db='mysql') return conn; df = pd.read_sql(''' SELECT * FROM idf_ru.data_for_scoring ''', con=con())
接下来,我们将稀有和遗漏值替换为一个单独的类别以防止进行匹配,选择目标,删除多余的列,然后按训练和测试进行划分。
资料准备 def filling(df): cat_vars = df.select_dtypes(include=[object]).columns num_vars = df.select_dtypes(include=[np.number]).columns df[cat_vars] = df[cat_vars].fillna('_MISSING_') df[num_vars] = df[num_vars].fillna(np.nan) return df def replace_not_frequent(df, cols, perc_min=5, value_to_replace = "_ELSE_"): else_df = pd.DataFrame(columns=['var', 'list']) for i in cols: if i != 'date_requested' and i != 'credit_id': t = df[i].value_counts(normalize=True) q = list(t[t.values < perc_min/100].index) if q: else_df = else_df.append(pd.DataFrame([[i, q]], columns=['var', 'list'])) df.loc[df[i].value_counts(normalize=True)[df[i]].values < perc_min/100, i] =value_to_replace else_df = else_df.set_index('var') return df, else_df cat_vars = df.select_dtypes(include=[object]).columns df = filling(df) df, else_df = replace_not_frequent_2(df, cat_vars) df.drop(['credit_id', 'target_value', 'bor_credit_id', 'bchg_credit_id', 'last_credit_id', 'bcacr_credit_id', 'bor_bonuses_got' ], axis=1, inplace=True) df_train, df_test, y_train, y_test = train_test_split(df, y, test_size=0.33, stratify=df.y, random_state=42)
现在开始进行回归评分的最重要阶段-您需要为数字和分类变量编写WOE合并。 在公共领域,我们没有找到适合自己的合适选择,因此决定自己写。 2017年的
这篇文章被用作数字分箱的基础,并且他们自己也从头开始进行了分类。 结果令人印象深刻(与外部数据挖掘程序的分箱算法相比,测试的基尼系数提高了3-5)。
之后,您可以查看图表或表格(然后我们在excel中编写),如何将变量分为几组并检查单调性:
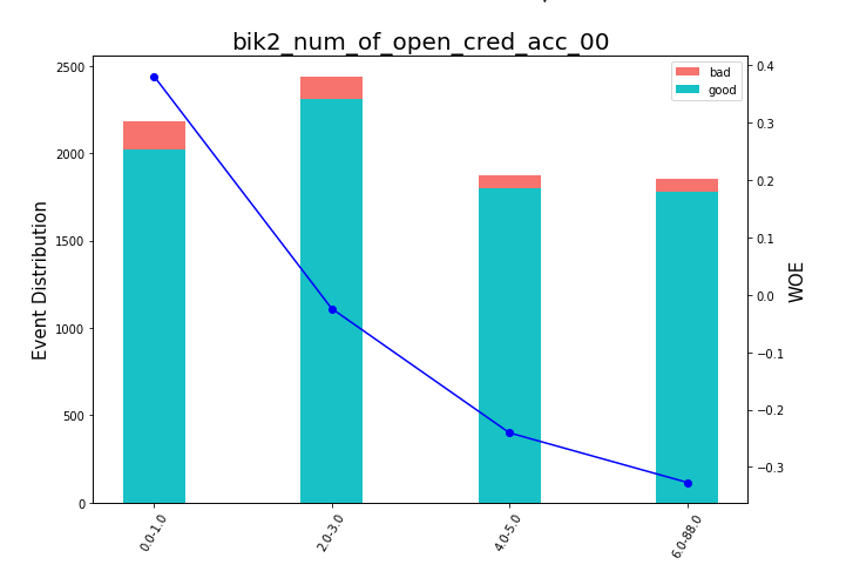
渲染豆图 def plot_bin(ev, for_excel=False): ind = np.arange(len(ev.index)) width = 0.35 fig, ax1 = plt.subplots(figsize=(10, 7)) ax2 = ax1.twinx() p1 = ax1.bar(ind, ev['NONEVENT'], width, color=(24/254, 192/254, 196/254)) p2 = ax1.bar(ind, ev['EVENT'], width, bottom=ev['NONEVENT'], color=(246/254, 115/254, 109/254)) ax1.set_ylabel('Event Distribution', fontsize=15) ax2.set_ylabel('WOE', fontsize=15) plt.title(list(ev.VAR_NAME)[0], fontsize=20) ax2.plot(ind, ev['WOE'], marker='o', color='blue')
手动分箱功能是单独编写的,例如,在变量“ OS version”的情况下很有用,在该变量中,所有Android和iOS手机都进行了手动分组。
手动分箱功能 def adjust_binning(df, bins_dict): for i in range(len(bins_dict)): key = list(bins_dict.keys())[i] if type(list(bins_dict.values())[i])==dict: df[key] = df[key].map(list(bins_dict.values())[i]) else:
下一步是通过信息值选择变量。 默认值是0.1(所有下面的变量都没有很好的预测能力)。
之后,进行相关检查。 在两个相关变量中,您需要删除IV较小的变量。 截止去除为0.75。
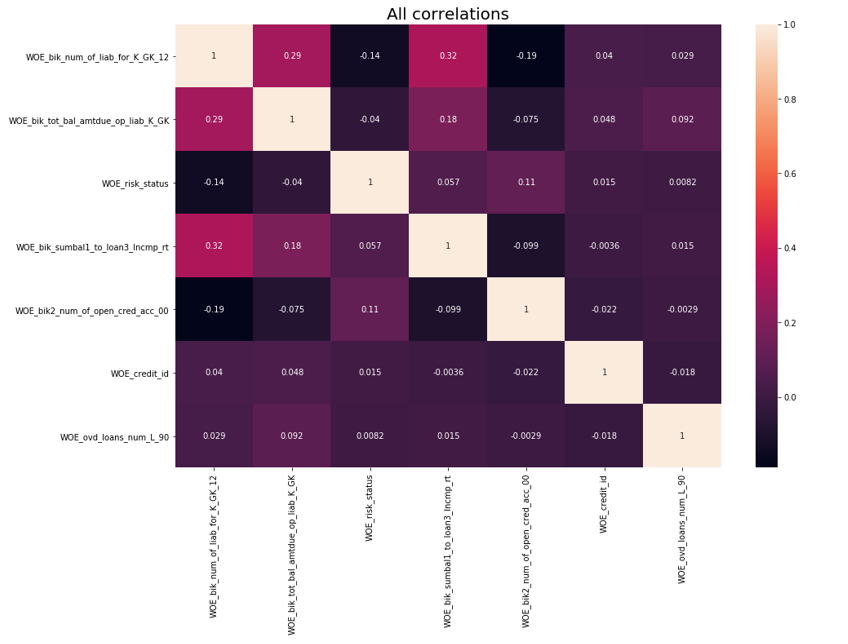
去除相关 def delete_correlated_features(df, cut_off=0.75, exclude = []):
除了通过IV进行选择外,我们还通过sklearn的
RFE方法添加了递归搜索以找到最佳变量数。
正如我们在图中看到的那样,在13个变量之后,质量不会改变,这意味着多余的变量可以删除。 对于回归,评分中超过15个变量被认为是不良形式,在大多数情况下,可以使用RFE进行纠正。
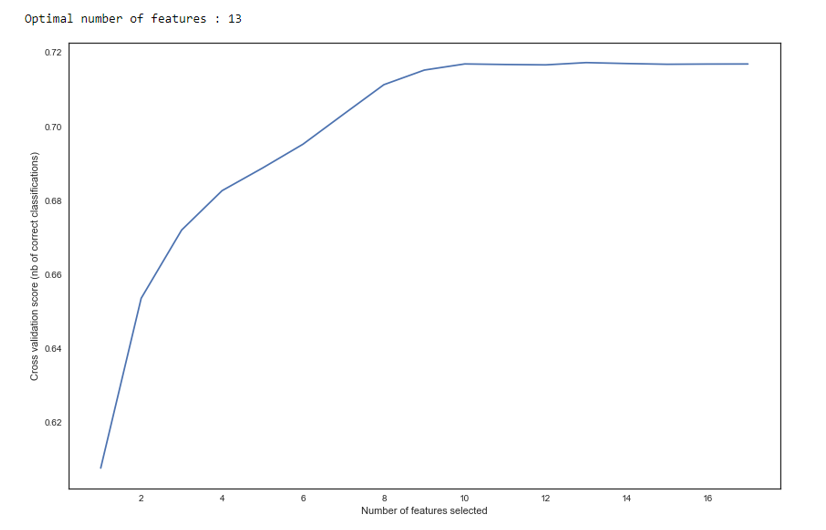
RFE def RFE_feature_selection(clf_lr, X, y): rfecv = RFECV(estimator=clf_lr, step=1, cv=StratifiedKFold(5), verbose=0, scoring='roc_auc') rfecv.fit(X, y) print("Optimal number of features : %d" % rfecv.n_features_)
接下来,建立了回归,并在交叉验证和测试抽样中评估了其指标。 通常,每个人都在看基尼系数(这是一篇有关他的好文章)。
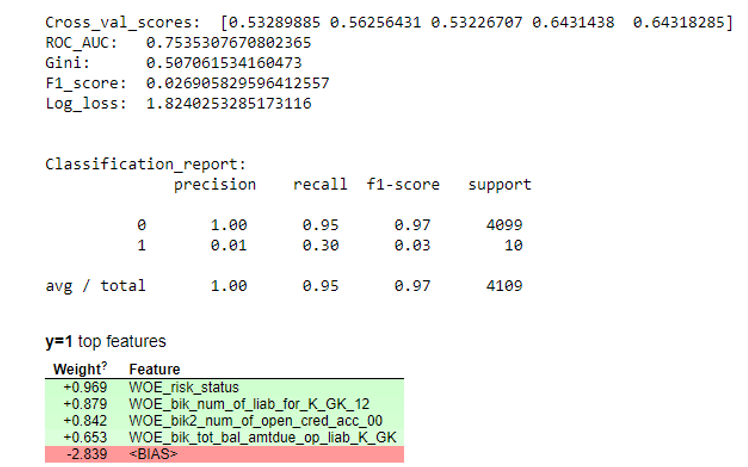
仿真结果 def plot_score(clf, X_test, y_test, feat_to_show=30, is_normalize=False, cut_off=0.5):
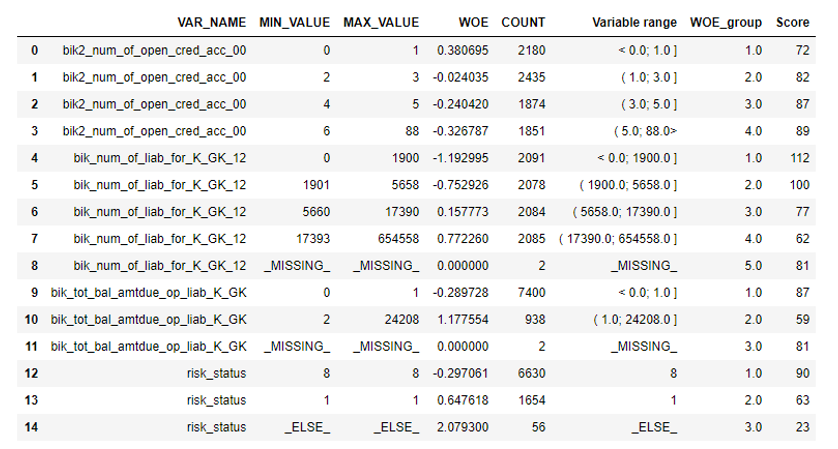
当我们确保模型质量适合我们时,有必要在excel中编写所有结果(回归系数,bin组,Gini稳定性图和变量等)。 为此,使用xlsxwriter很方便,它可以同时处理数据和图像。
Excel工作表示例:
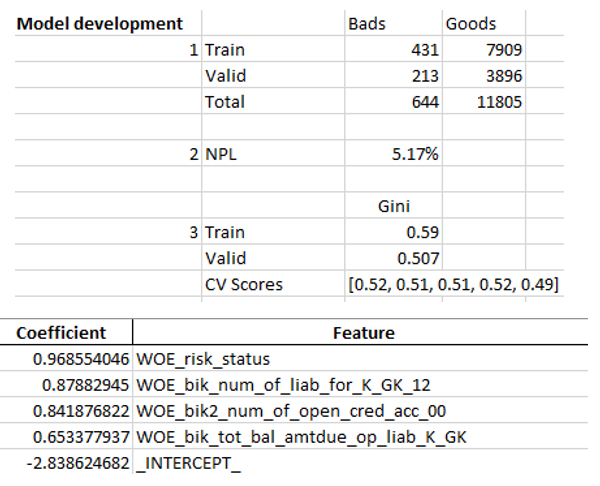
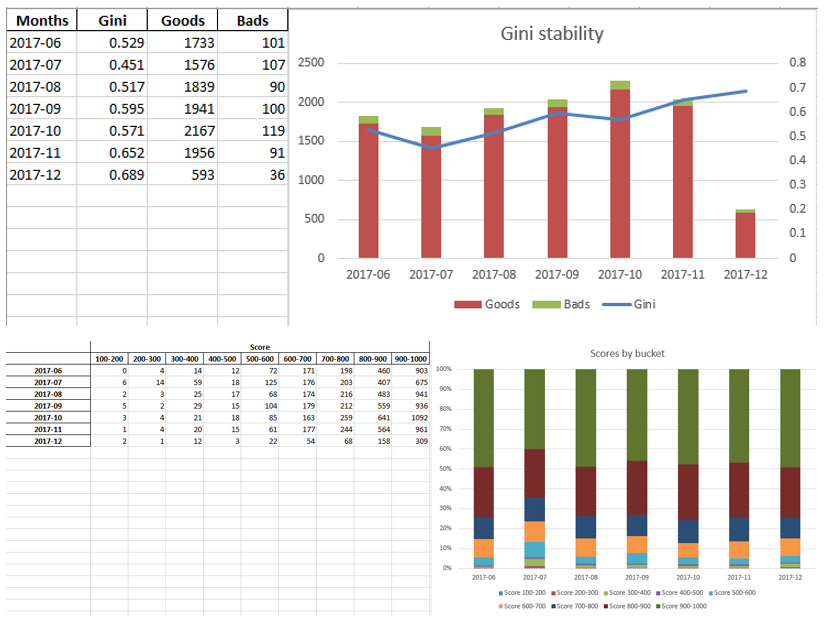
最后,最终的excel再次由管理人员查找,然后将其交给IT部门以将模型嵌入生产中。
总结
如我们所见,计分的几乎所有阶段都可以自动化,因此分析人员不需要编程技能即可建立模型。 在我们的案例中,创建此框架后,分析师仅需要收集数据并指定几个参数(指示目标变量,要删除的列,最小仓数,变量相关的截止系数等),然后可以在python中运行脚本,这将建立模型并产生具有期望结果的excel。
当然,有时有必要针对特定项目的需要更正代码,并且无法在建模过程中使用一个按钮来运行脚本,但是即使是现在,由于优化和单调的装仓,相关性检查等技术,我们看到的质量也比市场上使用的数据挖掘包更好。 ,RFE,回归的正则化版本等。
因此,由于使用了Python,我们大大减少了计分卡的开发时间,并减少了分析人员的人工成本。