在
上一篇文章中,我答应更详细地揭示调查期间省略的一些细节[Gmail挂在Windows的Chrome上-大约 [。],包括页表,锁,WMI和vmmap错误。 现在,我将与更新的代码示例一起填补这些空白。 但首先,简要概述一下要点。
关键是,支持
Control Flow Guard (CFG)的进程会分配可执行内存,同时还会分配Windows永不释放的CFG内存。 因此,如果您继续
在不同的地址分配和释放可执行内存,则该过程将累积任意数量的CFG内存。 Chrome浏览器会执行此操作,从而导致几乎无限的内存泄漏并在某些计算机上冻结。
应当指出,如果VirtualAlloc开始运行的速度比平常慢一百万倍,则很难避免冻结。
除了CFG,还有另一个浪费的内存,尽管它没有vmmap声称的那么多。
CFG和页面
程序存储器和CFG存储器最终都分配有4 KB的页面(稍后会有更多介绍)。 由于4 KB的CFG内存可以描述256 KB的程序存储器(稍后会有更多介绍),这意味着,如果您选择一个与256 KB对齐的256 KB内存块,则将获得一个4 KB的CFG页面。 而且,如果您分配了4 KB的可执行块,您仍将获得4 KB的CFG页面,但是大部分将不使用。
如果释放了可执行内存,一切都会变得更加复杂。 如果您在不是256 KB倍数或256 KB未对齐的可执行内存块上使用VirtualFree功能,则操作系统应进行一些分析并确认某些其他可执行内存未使用CFG页面。 CFG的作者决定不打扰-永远永远离开分配的CFG内存。 非常不幸 这意味着当我的测试程序分配并释放1 GB对齐的可执行内存时,它将留下16 MB的CFG内存。
实际上,事实证明,当Chrome JavaScript引擎分配并释放128 MB对齐的可执行内存(未使用全部内存,而是分配了整个范围并立即释放)时,最多将保留2 MB的CFG内存,尽管完全释放它很简单。 。 由于Chrome反复在随机地址处分配和释放内存,因此会导致上述问题。
额外的内存丢失
在任何现代操作系统中,每个进程都有其自己的虚拟内存地址空间,以便操作系统隔离进程并保护内存。 这是使用
内存管理单元 (MMU)和
页表完成的 。 内存分为4 KB页面。 这是操作系统为您提供的最小内存量。 每页由页表中的八字节记录表示,并且记录本身存储在4 KB页中。 它们每个都指向最多512个不同的内存页面,因此我们需要页面表的层次结构。 对于64位操作系统中的48位地址空间,系统如下:
- 1级表覆盖256 TB(48位),指向512个不同页面2级表
- 每个2级表覆盖512 GB,指向512级3表
- 每个3级表覆盖1 GB,指向512个4级表
- 每个4级表跨越2 MB,指向512个物理页
MMU在地址的前9位(共48位)中索引第一级表,在随后的9位中索引第二级表,其余级别指定为9位,即只有36位。 其余的12位用于从第4级表中索引4 KB页面。 好吧好吧
如果立即填写表的所有级别,则需要超过512 GB的RAM,因此将在必要时进行填充。 这意味着,在分配内存页面时,操作系统会根据分配的地址是位于2 MB的先前未使用区域,1 GB的先前未使用区域还是512 GB的先前未使用区域(第1级页面表)中选择一些页面表-从零到三个,从零到三总是脱颖而出)。
简而言之,分配给随机地址比分配给附近的地址昂贵得多,因为在第一种情况下无法共享页表。 CFG泄漏很少见,因此当
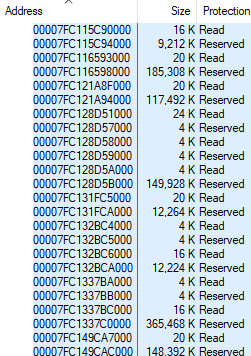
vmmap在Chrome中显示
412,480 KB的已用页表时,我认为数字是正确的。 这是vmmap的屏幕截图,带有上一篇文章的chrome.exe内存布局,但带有“页面表”行:
但是似乎有些问题。 我决定将页面表模拟器添加到我的
VirtualScan工具中。 它计算在扫描过程中所有分配的内存需要多少页的页表。 您只需要扫描分配的内存,就将每个2 MB,1 GB或512 GB的倍数添加到计数器中。
很快发现,模拟器结果与正常进程上的vmmap相对应,但与具有大量CFG内存的进程不对应。 差异大约对应于分配的CFG内存。 对于上述过程,vmmap讨论402.8 MB(412,480 KB)的页表,我的工具显示67.7 MB。
扫描时间,已提交,页表,已提交块
总计:41.763s,1457.7 MiB,67.7 MiB,32112、98个代码块
CFG:41.759s,353.3 MiB,59.2 MiB,24866
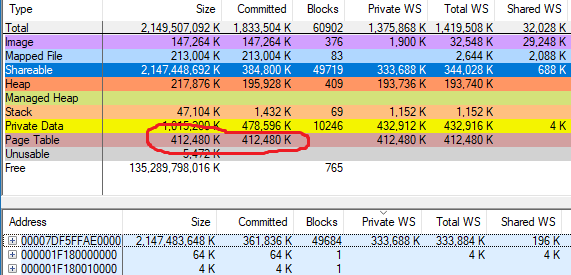
我通过运行
VAllocStress来确定vmmap错误,该错误在默认设置下会导致Windows分配2 GB的CFG内存。 vmmap声称已分配2 GB的页表:
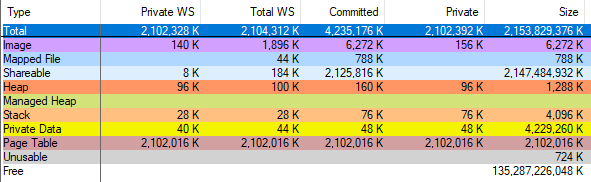
当我通过任务管理器完成该过程时,vmmap显示分配的内存量仅减少了2 GB。 因此,vmmap是错误的,我对页表的计算是正确的,并且
在Twitter上进行了富有成果的
讨论之后
,我发送了有关vmmap错误的报告,该错误应该得到修复。 CFG内存仍然消耗大量页表条目(在上面的示例中为59.2 MB),但不如vmmap所说的那样大,并且在修复后,它实际上不会花费任何东西。
什么是CFG和CFG?
我想退后一步,详细介绍一下CFG是什么。
CFG代表控制流防护。 这是一种通过重写函数指针来防止攻击的方法。 启用CFG后,编译器和OS会一起检查分支目标的有效性。 首先,从2 TB的保留CFG区域加载相应的CFG控制字节。 Windows中的64位进程管理着128 TB的地址空间,因此,将地址除以64可让您找到该对象的相应CFG字节。
uint8_t cfg_byte = cfg_base[size_t(target_addr) / 64];现在,我们有一个字节来描述64字节范围内的哪些地址是有效的分支目标。 为此,CFG将字节视为四个两位值,每个值对应一个16字节范围。 此两位数字(其值从零到三)
解释如下 :
- 0-此16字节块中的所有目标都是间接分支的无效目标
- 1-此16字节块中的起始地址是间接分支的有效目标
- 2- 与“抑制”的CFG呼叫相关 ; 地址可能无效
- 3-此16字节块中未对齐的地址是间接分支的有效目标,但是16字节对齐的地址可能无效
如果间接分支的目标无效,则过程结束,并阻止利用。 万岁!
从中我们可以得出结论,为了获得最大的安全性,分支的间接目标应该对齐16个字节,并且我们可以理解为什么该过程的CFG内存大约是程序内存的1/64。
实际上CFG一次加载32位,但这是实现细节。 许多资料都将CFG内存描述为8字节的单比特,而不是16字节的双比特。 我的解释更好。
这就是为什么一切都不好
Gmail挂起有两个原因。 首先,在Windows 10 16299或更早版本上扫描CFG内存
非常慢。 我看到了如何扫描进程的地址空间需要40秒或更长时间,而实际上,扫描了99.99%的保留CFG内存,尽管它仅占固定内存块的75%。 我不知道为什么扫描这么慢,但是他们在Windows 10 17134中修复了它,因此更详细地研究问题是没有意义的。
慢速扫描导致速度变慢,因为Gmail希望CFG冗余,而WMI在扫描期间保持锁定。 但是在整个扫描过程中并未保留内存保留锁。 在我的示例中,CFG区域中大约有49,000个块,并且接收和释放锁的
NtQueryVirtualMemory函数分别为它们调用了一次。 因此,获得了该锁并将其释放约49,000次,每次均保持不到1毫秒。
但是,尽管该锁被释放了49,000次,但由于某种原因,Chrome进程无法获得它。 这不公平!
这就是问题的实质。 正如我上次写的:
这是因为Windows锁本质上是不公平的 -如果线程释放该锁然后立即再次请求它,则它可以永远得到它。
公平锁定意味着两个竞争线程将依次接收它。 但这意味着很多昂贵的上下文切换,因此很长一段时间不会使用该锁。

不公平的锁更便宜,并且不会使线程排队等待。 正如
Joe Duffy的文章中所述,它们只是捕获了锁。 他还写道:
引入不正当锁无疑会导致饥饿。 但是从统计学的角度来看,并行系统中的时间往往变化很大,从概率的角度来看,每个线程最终都会获得执行的机会。
如何将乔(Joe)从2006年开始对饥饿的稀缺性的陈述与我对100%长期重复问题的经验进行关联? 我认为主要原因是2006年发生的事情。 英特尔
发布了Core Duo ,多核计算机无处不在。
毕竟,事实证明,这种饥饿问题仅发生在多核系统上! 在这样的系统中,WMI线程将释放锁定,通知Chrome线程唤醒,然后继续。 由于WMI流已经在运行,因此它在Chrome流前面有一个“障碍”,因此它可以轻松地再次调用
NtQueryVirtualMemory并再次获得锁定,然后Chrome才有机会执行此操作。
显然,在单核系统中,一次只能有一个线程可以工作。 通常,Windows会增加新线程的优先级,而增加优先级意味着释放锁定时,新的Chrome线程将准备就绪,并会立即
领先于 WMI线程。 这使Chrome浏览器线程有很多时间可以唤醒并获得锁定,并且饥饿永远不会发生。
你懂吗 在多核系统中,大多数情况下优先级的提高不会影响WMI流,因为它将在不同的内核上运行!
这意味着具有更多内核的系统比具有相同工作负载和更少内核的系统的
响应速度更慢 。 另一个结论很好奇:如果我的计算机负担很重-相应优先级的线程可以在所有处理器内核上工作-那么就可以避免挂起(不要在家尝试重复此操作)。
因此,
不正当的锁可以提高生产率,但会导致饥饿。 我怀疑解决方案可能是我所谓的“有时是公平的”锁。 假设有99%的时间他们将是不公平的,但有1%的时间将锁定权交给了另一个流程。 这将保留更多的生产力优势,避免了饥饿问题。 以前,Windows中的锁是公平分配的,您可能可以部分恢复到原来的状态,从而找到完美的平衡。 免责声明:我不是锁专家或OS工程师,但是我有兴趣听取有关它的想法,至少我
不是第一个提供类似想法的人。
莱纳斯·托瓦尔兹(Linus Torvalds)最近意识到了公平锁的重要性:
这里和
这里 。 也许现在也该在Windows上进行更改了。
总结一下 :锁定几秒钟是不好的,它限制了并发性。 但是在具有不公平锁的多核系统上,删除然后立即再次收到锁的行为
完全相同,其他线程无法工作。
ETW几乎失败
对于所有这些研究,我都依赖于ETW跟踪,因此当调查开始时发现Windows Performance Analyzer(WPA)无法加载Chrome字符时,我有些害怕。 我敢肯定,实际上上周一切正常。 发生什么事了...
Chrome M68碰巧出现了,它是使用lld-link而不是VC ++链接器链接的。 如果运行
dumpbin并查看调试信息,则会看到:
C:\b\c\b\win64_clang\src\out\Release_x64\./initialexe/chrome.exe.pdb好吧,WPA可能不喜欢这些斜线。 但这仍然没有意义,因为我将链接器更改为lld-link,并且我记得之前曾测试过WPA,所以发生了什么...
原来,原因是在新的WPA版本17134中。我测试了lld-Link布局-并在WPA 16299中运行良好。真是巧合! 新的链接器和新的WPA不兼容。
我安装了旧版本的WPA继续进行调查(从装有旧版本的计算机上进行xcopy),并报告了
lld-link错误 ,开发人员迅速修复了该
错误 。 现在,当M69与固定连接器组装在一起时,您可以返回WPA 17134。
Wmi
WMI冻结触发器是
Windows Management Instrumentation管理单元 ,我不太擅长。 我发现在
2014年或更早的时候,有人在
perfproc!GetProcessVaData内的
WmiPrvSE.exe中
遇到了 CPU使用率
过高的问题,但他们没有提供足够的信息来了解错误的原因。 在某个时候,我犯了一个错误,试图找出疯狂的WMI请求可能使Gmail挂起几秒钟的原因。 我联系了
一些 专家进行调查,并花了很多时间试图找到这个神奇的查询。 我在ETW跟踪中记录了
Microsoft-Windows-WMI-Activity活动,尝试使用PowerShell查找所有Win32_Perf查询,并以其他一些无聊的回旋方式迷路了。 最后,我发现Gmail挂起导致此计数器
Win32_PerfRawData_PerfProc_ProcessAddressSpace_Costly ,由单行PowerShell触发:
measure-command {Get-WmiObject -Query “SELECT * FROM Win32_PerfFormattedData_PerfProc_ProcessAddressSpace_Costly”}
然后,由于计数器的名称(“亲爱的??是真的?”),而且由于这个计数器根据我不了解的因素出现和消失,我
变得更加困惑。
但是WMI的细节并不重要。 WMI没做错-并不是真的-它只是扫描内存。 事实证明,编写自己的扫描代码对调查问题有用得多。
微软麻烦
Chrome浏览器已经发布了补丁,其余的则是针对微软的。
加快CFG区域扫描 -好的,完成了- 释放可执行内存时释放CFG内存-至少在256K对齐的情况下,这很容易
- 考虑允许在没有CFG内存的情况下分配可执行内存的标志,或为此目的使用PAGE_TARGETS_INVALID。 请注意, Windows Internals Part 1第7版手册指出:“您应该选择[CFG]页面,并且至少设置一个位{1,X}”-如果Windows 10实现了此功能,则PAGE_TARGETS_INVALID标志( 引擎当前使用该标志) v8 )将避免内存分配
- 修复vmmap中针对具有大量CFG分配的进程的页表的计算
代码更新
我更新了
代码示例 ,尤其是VAllocStress。 其中包括20行,以演示如何为流程查找CFG预留。 我还添加了使用
SetProcessValidCallTargets检查CFG位的值并演示成功调用它们的技巧的测试代码(提示:通过GetProcAddress调用很可能违反CFG!)